【干货收藏】大模型工具学习全解析:程序员必知的AI从问答到操控世界的进化
本文系统分析了大模型工具/函数调度领域的发展,基于15篇重要论文,将其分为五个研究方向:工具学习理论、API集成、评估方法、效率优化与安全性研究。从Toolformer的开创性工作到最新的并行化和安全性研究,展示了大模型从被动问答到主动操控世界的AI革命进程,并展望了多模态集成、泛化能力提升等未来方向。
本文系统分析了大模型工具/函数调度领域的发展,基于15篇重要论文,将其分为五个研究方向:工具学习理论、API集成、评估方法、效率优化与安全性研究。从Toolformer的开创性工作到最新的并行化和安全性研究,展示了大模型从被动问答到主动操控世界的AI革命进程,并展望了多模态集成、泛化能力提升等未来方向。

1. 引言与研究背景
大型语言模型(Large Language Models, LLMs)在自然语言理解和生成方面展现出了前所未有的能力,但其在处理实时信息、执行精确计算、与外部系统交互以及解决特定领域问题时仍存在固有的局限性。为了克服这些挑战,研究人员开始探索将LLMs与外部工具相结合的新范式,使其能够像人类一样在需要时调用合适的工具来辅助完成任务。这种"工具增强型LLMs"(Tool-augmented LLMs)范式极大地扩展了LLMs的应用范围,使其从纯粹的文本生成器转变为能够感知和操作外部世界的智能代理。
函数调用(Function Calling)作为实现LLMs与工具交互的核心机制,允许LLMs根据用户指令或内部推理,生成结构化的函数调用请求,并解析工具返回的结果,从而实现与外部世界的无缝连接。这一技术的发展不仅解决了LLMs在知识时效性方面的限制,还为其在复杂任务处理、多模态交互和实际应用部署方面开辟了新的可能性。
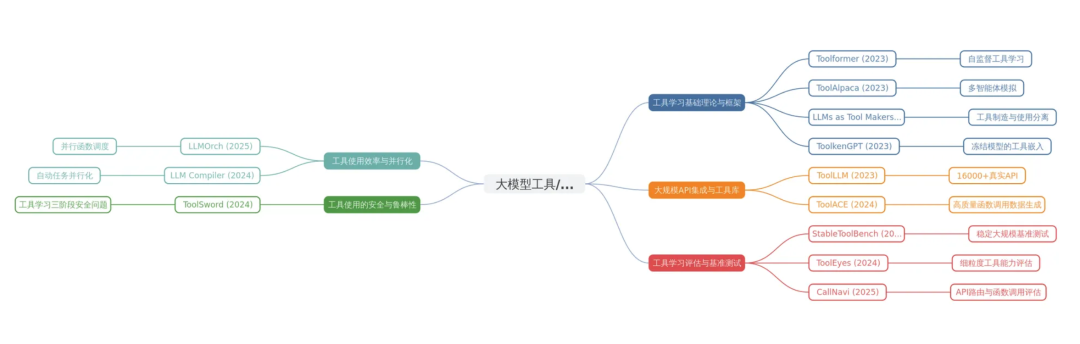
近两年来,随着ChatGPT、GPT-4等先进模型在工具使用方面展现出的卓越能力,学术界和工业界对大模型工具/函数调度的研究热情空前高涨。从2023年初Toolformer的开创性工作开始,到2025年最新的并行函数调度和安全性研究,该领域已经形成了相对完整的研究体系。本综述报告基于对过去两年间发表的15篇重要论文的深入分析,系统梳理了大模型工具/函数调度领域的主要研究方向、核心技术贡献、发展趋势以及未来挑战。
2. 研究方向分类与核心技术
通过对收集到的15篇论文进行深入分析,我们将大模型工具/函数调度领域的研究大致分为五个主要方向,每个方向都有其独特的技术特点和研究重点。
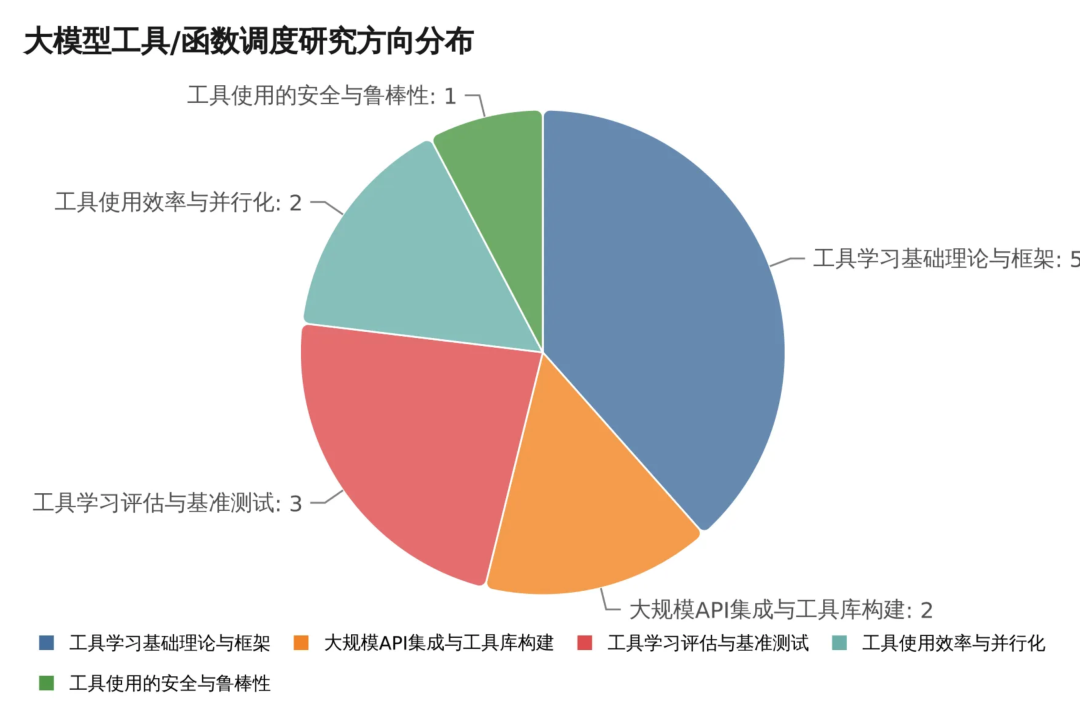
2.1 工具学习基础理论与框架
工具学习基础理论与框架研究构成了整个领域的理论基石,主要关注LLMs如何自主学习和使用工具,以及构建通用的工具学习范式。这一方向的研究为后续的应用和优化提供了重要的理论指导和方法基础。
Toolformer作为该领域的开创性工作,提出了一种革命性的自监督学习方法,使LLMs能够自主决定何时调用API、选择哪个API、传递哪些参数以及如何将API结果整合到后续的token预测中。该方法的核心创新在于通过少量API演示实现LLMs的工具使用能力,并在多种下游任务中展现出显著的零样本性能提升。Toolformer的成功证明了通过简单API调用扩展LLMs能力的巨大潜力,为整个领域的发展奠定了基础。
ToolAlpaca进一步推进了工具学习的民主化进程,专注于解决紧凑型LLMs的通用工具使用能力问题。该研究通过构建多智能体模拟环境,自动生成了包含400多个真实世界API的3938个工具使用实例,形成了高度多样化的工具使用语料库。利用这一语料库微调的紧凑型模型(如ToolAlpaca-7B和ToolAlpaca-13B)在未见过的工具上也能展现出与GPT-3.5相媲美的通用工具使用能力,这一发现表明即使是较小的模型,通过高质量的合成数据训练,也能获得强大的工具使用能力。
"LLMs as Tool Makers"研究提出了一个更加雄心勃勃的愿景,即LLMs不仅能使用工具,还能自主创建工具。该研究提出的LATM(LLMs as Tool Makers)闭环框架将工具制造(由更强大的LLM完成)和工具使用(由轻量级LLM完成)分离,实现了工具的持续生成和缓存,从而显著降低了推理成本并提高了效率。这一框架揭示了LLMs在自主性和适应性方面的新潜力,为构建更智能、更经济的LLM应用提供了新思路。
ToolkenGPT则从技术实现的角度提出了一种通过工具嵌入来增强冻结LLMs使用大量工具的方法。该方法的优势在于能够在不修改LLM核心参数的情况下,有效扩展其工具使用能力,这对于在资源受限的环境中部署具有工具使用能力的LLMs具有重要意义,因为它避免了对整个模型进行昂贵的微调。
- • Toolformer: Language Models Can Teach Themselves to Use Tools [1]
- • 核心贡献: Toolformer开创性地提出了一种自监督学习方法,使LLMs能够决定何时、调用哪个API、传递哪些参数以及如何将API结果整合到后续的token预测中。它通过少量API演示,实现了LLMs自主学习和使用外部工具的能力,并在多种下游任务中展现出显著的零样本性能提升,证明了通过简单API调用扩展LLMs能力的巨大潜力。该研究为LLMs工具学习奠定了基础,强调了自监督学习在工具集成中的有效性。
- • ToolAlpaca: Generalized tool learning for language models with 3000 simulated cases [2]
- • 核心贡献: ToolAlpaca旨在解决紧凑型LLMs的通用工具使用能力问题。它通过构建一个多智能体模拟环境,自动生成了包含400多个真实世界API的3938个工具使用实例,形成多样化的工具使用语料库。利用该语料库微调紧凑型LLMs(如ToolAlpaca-7B和ToolAlpaca-13B),使其在未见过的工具上也能展现出与GPT-3.5相媲美的通用工具使用能力。这表明,即使是较小的模型,通过高质量的合成数据训练,也能获得强大的工具使用能力。
- • Large language models as tool makers [5]
- • 核心贡献: 这项研究提出了LLMs不仅能使用工具,还能自主创建工具的“LLMs as Tool Makers (LATM)”闭环框架。它将工具制造(由更强大的LLM完成)和工具使用(由轻量级LLM完成)分离,实现了工具的持续生成和缓存,从而显著降低了推理成本并提高了效率。LATM框架揭示了LLMs在自主性和适应性方面的新潜力,为构建更智能、更经济的LLM应用提供了新思路。
- • Empowering large language models: Tool learning for real-world interaction [6] & Tool learning in the wild: Empowering language models as automatic tool agents [8]
- • 核心贡献: 这两篇论文都深入探讨了如何赋能LLMs作为自动工具学习者,使其能够将抽象的工具概念转化为具体的行动,从而实现与现实世界的交互。它们将工具学习划分为工具增强型学习和面向工具的学习,并讨论了认知工具和物理工具在LLM应用中的作用。这些研究为LLMs在复杂现实世界场景中的应用提供了理论和实践指导,强调了工具学习在实现具身智能中的重要性。
- • Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings [9]
- • 核心贡献: ToolkenGPT提出了一种通过工具嵌入来增强冻结LLMs使用大量工具的方法。它允许在不修改LLM核心参数的情况下,有效扩展其工具使用能力。这种方法对于在资源受限的环境中部署具有工具使用能力的LLMs具有重要意义,因为它避免了对整个模型进行昂贵的微调。
2.2 大规模API集成与工具库构建
大规模API集成与工具库构建研究致力于构建覆盖面广、多样性强的API数据集和工具库,以支持LLMs学习和掌握海量的真实世界API。这一方向的研究为LLMs在实际应用中的部署提供了重要的数据基础和技术支撑。
ToolLLM作为该方向的代表性工作,提出了一个通用的工具使用框架,旨在弥合开源LLMs与ChatGPT等闭源LLMs在工具使用能力方面的差距。该研究的核心贡献是ToolBench数据集,通过从RapidAPI Hub收集16,464个真实世界的RESTful API构建而成。这一数据集不仅规模庞大,而且涵盖了单工具和多工具场景,通过ChatGPT生成指令和解决方案路径,为LLMs在实际应用中掌握大量API提供了重要的资源和方法。ToolLLM的工作极大地推动了开源LLMs在工具使用方面的进展,为后续研究提供了重要的基准和参考。
ToolACE则从数据质量的角度进一步推进了该领域的发展,提出了一个自动代理管道,用于生成准确、复杂和多样化的LLM函数调用训练数据。该研究利用新颖的自我进化合成过程,策划了一个包含26,507个不同API的综合API池,这一规模远超之前的工作。通过多代理交互生成对话,并结合基于规则和基于模型的双层验证系统确保数据准确性,ToolACE合成的数据训练的模型即使只有8B参数,也能在Berkeley Function-Calling Leaderboard上达到与GPT-4相媲美的最先进性能。这一成果为高质量函数调用训练数据的生成提供了有效途径,并证明了数据质量在工具学习中的关键作用。
- • ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs [3]
- • 核心贡献: ToolLLM是一个通用的工具使用框架,旨在弥合开源LLMs与ChatGPT等闭源LLMs在工具使用能力方面的差距。它提出了ToolBench,一个通过从RapidAPI Hub收集16,464个真实世界的RESTful API构建而成的指令微调数据集。该数据集涵盖了单工具和多工具场景,并通过ChatGPT生成指令和解决方案路径。ToolLLM为LLMs在实际应用中掌握大量API提供了重要的资源和方法,极大地推动了开源LLMs在工具使用方面的进展。
- • ToolACE: Winning the Points of LLM Function Calling [13]
- • 核心贡献: ToolACE是一个自动代理管道,用于生成准确、复杂和多样化的LLM函数调用训练数据。它利用新颖的自我进化合成过程,策划了一个包含26,507个不同API的综合API池。通过多代理交互生成对话,并结合基于规则和基于模型的双层验证系统确保数据准确性。ToolACE合成的数据训练的模型,即使只有8B参数,也能在Berkeley Function-Calling Leaderboard上达到与GPT-4相媲美的最先进性能,为高质量函数调用训练数据的生成提供了有效途径。
2.3 工具学习评估与基准测试
工具学习评估与基准测试研究关注如何准确、稳定地评估LLMs的工具学习能力,并构建可靠的基准测试平台。这一方向的研究对于推动整个领域的健康发展具有重要意义,为不同方法的比较和改进提供了科学的评估标准。
StableToolBench针对现有工具学习基准测试中API状态不稳定和评估随机性等问题,提出了一个创新的解决方案。该研究构建了一个虚拟API服务器和稳定的评估系统,通过缓存系统和API模拟器来缓解API状态变化带来的不确定性,并使用GPT-4作为自动评估器来消除评估过程中的随机性。StableToolBench为评估LLMs的工具学习能力提供了一个更可靠和可扩展的平台,解决了该领域长期存在的评估一致性问题。
ToolEyes从评估的细粒度角度出发,提出了一个全面的评估系统,用于衡量LLMs在真实世界场景中的工具学习能力。该研究超越了仅仅验证工具选择对齐性的传统评估方法,通过检查LLMs在工具学习中的五个关键维度(格式对齐、意图理解、行为规划、工具选择和答案组织),并涵盖七个真实世界场景。ToolEyes提供了一个包含约600个工具的工具库,为更准确地衡量LLMs工具使用性能提供了新的评估框架,并揭示了当前LLMs在工具学习中存在的认知局限性。
CallNavi专注于API驱动的聊天机器人系统中API调用的准确生成和执行,特别关注多步交互、复杂参数化和嵌套API依赖的场景。该研究引入了一个新的数据集用于基准测试API函数选择、参数生成和嵌套API执行,并对最先进的LLMs进行了实证评估。此外,CallNavi提出了一种混合API路由方法,结合通用LLMs进行API选择和微调模型/提示工程进行参数生成,旨在显著改进聊天机器人系统中的API执行效率和准确性。
- • Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models [7]
- • 核心贡献: StableToolBench旨在解决现有工具学习基准测试中API状态不稳定和评估随机性等问题。它提出了一个虚拟API服务器和稳定的评估系统,通过缓存系统和API模拟器来缓解API状态变化,并使用GPT-4作为自动评估器来消除评估过程中的随机性。StableToolBench为评估LLMs的工具学习能力提供了一个更可靠和可扩展的平台,对于推动该领域的研究具有重要意义。
- • Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios [11]
- • 核心贡献: ToolEyes提出了一个细粒度的评估系统,用于衡量LLMs在真实世界场景中的工具学习能力。它超越了仅仅验证工具选择对齐性的传统评估方法,通过检查LLMs在工具学习中的五个关键维度(格式对齐、意图理解、行为规划、工具选择和答案组织),并涵盖七个真实世界场景。ToolEyes提供了一个包含约600个工具的工具库,为更准确地衡量LLMs工具使用性能提供了新的评估框架,并揭示了当前LLMs在工具学习中存在的认知局限性。
- • CallNavi: A Challenge and Empirical Study on LLM Function Calling and Routing [14]
- • 核心贡献: CallNavi专注于API驱动的聊天机器人系统中API调用的准确生成和执行,特别是在多步交互、复杂参数化和嵌套API依赖的场景。它引入了一个新的数据集用于基准测试API函数选择、参数生成和嵌套API执行,并对最先进的LLMs进行了实证评估。此外,CallNavi提出了一种混合API路由方法,结合通用LLMs进行API选择和微调模型/提示工程进行参数生成,旨在显著改进聊天机器人系统中的API执行效率和准确性。
2.4 工具使用效率与并行化
工具使用效率与并行化研究致力于提高LLMs调用和编排工具的效率,特别是通过并行化技术来加速复杂任务的执行。随着LLMs应用场景的复杂化,如何高效地调度和并行执行多个函数调用成为了一个重要的研究热点。
LLMOrch提出了一个先进的框架,旨在解决LLMs顺序函数调用带来的效率问题,通过实现自动化的并行函数调用来提高效率。该系统能够识别可用的处理器来执行函数调用,同时防止单个处理器过载。LLMOrch通过建模函数之间的数据关系(定义-使用)和控制关系(互斥),并协调底层处理器的工作状态来优化执行。实验结果表明,与现有技术相比,LLMOrch在I/O密集型函数方面实现了可比的效率提升,并在计算密集型函数方面显著优于它们(2倍),其性能与分配的处理器数量呈线性相关。
LLMCompiler作为另一个重要的并行化工作,提出了一个通过并行执行函数来高效协调多个函数调用的系统。该系统能够分析用户请求,自动识别可并行执行的任务,并创建优化的执行计划。与传统的顺序函数调用相比,LLMCompiler显著提高了执行效率,同时保持了结果质量。这种工具和函数调用的自动并行化可能会为基于LLM的应用程序开发带来根本性的转变,使其能够更高效地处理需要多个API调用或外部工具交互的复杂任务。
- • LLMOrch: Efficient Function Orchestration for Large Language Models [12]
- • 核心贡献: LLMOrch是一个先进的框架,旨在解决LLMs顺序函数调用带来的效率问题,通过实现自动化的并行函数调用来提高效率。它能够识别可用的处理器来执行函数调用,同时防止单个处理器过载。LLMOrch通过建模函数之间的数据关系和控制关系,并协调底层处理器的工作状态来优化执行。与现有技术相比,LLMOrch在I/O密集型函数方面实现了可比的效率提升,并在计算密集型函数方面显著优于它们(2倍),其性能与分配的处理器数量呈线性相关。这项工作为提高LLMs的函数调度效率提供了重要的技术方案。
- • An LLM Compiler for Parallel Function Calling [15]
- • 核心贡献: LLMCompiler是一个通过并行执行函数来高效协调多个函数调用的系统。它分析用户请求,自动识别可并行执行的任务,并创建优化的执行计划。与传统的顺序函数调用相比,LLMCompiler显著提高了执行效率,同时保持了结果质量。这种工具和函数调用的自动并行化可能会为基于LLM的应用程序开发带来根本性的转变,使其能够更高效地处理需要多个API调用或外部工具交互的复杂任务。
2.5 工具使用的安全与鲁棒性
工具使用的安全与鲁棒性研究关注LLMs在工具使用过程中可能面临的安全风险和鲁棒性挑战。随着LLMs与外部世界交互的加深,工具使用带来的安全风险日益凸显,这一方向的研究对于确保LLMs的安全部署具有重要意义。
ToolSword作为该方向的代表性工作,提出了一个全面的框架,旨在揭示LLMs在工具学习三个阶段(输入、执行、输出)中的安全问题。该研究描绘了六种安全场景,包括输入阶段的恶意查询和越狱攻击,执行阶段的噪声误导和风险提示,以及输出阶段的有害反馈和错误冲突。研究发现,即使是GPT-4等先进模型,在处理有害查询、使用风险工具和提供有害反馈方面仍存在安全挑战。ToolSword强调了在LLMs工具集成过程中,安全性和鲁棒性方面需要关注的关键问题,并为未来的安全研究提供了重要的方向指导。
- • Toolsword: Unveiling safety issues of large language models in tool learning across three stages [10]
- • 核心贡献: ToolSword是一个全面的框架,旨在揭示LLMs在工具学习三个阶段(输入、执行、输出)中的安全问题。它描绘了六种安全场景,包括输入阶段的恶意查询和越狱攻击,执行阶段的噪声误导和风险提示,以及输出阶段的有害反馈和错误冲突。研究发现,即使是GPT-4等先进模型,在处理有害查询、使用风险工具和提供有害反馈方面仍存在安全挑战。ToolSword强调了在LLMs工具集成过程中,安全性和鲁棒性方面需要关注的关键问题,并为未来的安全研究提供了方向。
3. 关键论文深度分析
3.1 开创性工作:Toolformer的理论突破
Toolformer作为大模型工具学习领域的开创性工作,其最重要的贡献在于提出了一种全新的自监督学习范式,使LLMs能够自主学习何时以及如何使用外部工具。该研究的核心创新体现在以下几个方面:
首先,Toolformer提出了一种基于API调用标注的自监督学习方法。该方法通过在预训练文本中插入API调用标记,使模型能够学习在适当的时机调用相应的工具。这种方法的巧妙之处在于它不需要大量的人工标注数据,而是通过模型自身的语言建模能力来学习工具使用的时机和方式。
其次,该研究设计了一套完整的工具集成框架,包括计算器、问答系统、搜索引擎、翻译系统和日历等多种工具。这些工具的选择覆盖了LLMs在实际应用中最常遇到的局限性场景,如数值计算、知识检索和多语言处理等。通过这种多样化的工具集成,Toolformer展示了工具增强型LLMs的广阔应用前景。
最后,Toolformer在多个下游任务上的实验结果证明了其方法的有效性。在数学推理、事实性问答、多语言任务等多个基准测试中,Toolformer都实现了显著的性能提升,通常能够与更大规模的模型相媲美,同时不牺牲其核心语言建模能力。这一成果为后续研究提供了重要的实证支持和方法参考。
3.2 规模化突破:ToolLLM的工程实践
ToolLLM代表了大模型工具学习从理论探索向大规模工程实践的重要转变。该研究的核心贡献在于构建了迄今为止最大规模的真实世界API数据集,并提出了一套完整的工具学习训练和评估流程。
ToolBench数据集的构建是该研究的最重要贡献之一。通过从RapidAPI Hub收集16,464个真实世界的RESTful API,该数据集不仅在规模上远超之前的工作,更重要的是其真实性和多样性。这些API涵盖了从基础的数据处理到复杂的业务逻辑等各个方面,为LLMs学习真实世界的工具使用提供了丰富的训练材料。
该研究还提出了一套系统的数据生成和模型训练流程。通过使用ChatGPT生成高质量的指令-解决方案对,并结合深度优先搜索树(DFSDT)来处理复杂的多工具场景,ToolLLM为大规模工具学习数据的生成提供了可行的技术路径。这种方法不仅保证了数据的质量,还确保了训练数据的多样性和复杂性。
在评估方面,ToolLLM提出了一套全面的评估指标和方法,包括通过率、胜率和ToolEval等多维度评估。这些评估方法为后续研究提供了重要的基准和参考标准,推动了整个领域评估方法的标准化。
3.3 效率优化:并行化技术的突破
LLMOrch和LLMCompiler代表了大模型工具调度在效率优化方面的重要突破。这两项研究都关注于如何通过并行化技术来提高复杂任务的执行效率,但采用了不同的技术路径。
LLMOrch的核心创新在于提出了一种基于数据依赖关系的函数调度算法。该算法通过分析函数之间的定义-使用关系,自动识别可以并行执行的函数调用,并根据处理器的工作状态进行智能调度。这种方法的优势在于能够充分利用系统资源,避免处理器过载,同时最大化并行执行的效率。
LLMCompiler则采用了编译器的思想,将用户请求编译成可并行执行的任务图。该系统能够自动分析任务之间的依赖关系,生成优化的执行计划,并在运行时动态调整执行策略。这种方法的创新之处在于将传统编译器的优化技术应用到LLM的函数调用场景中,实现了更高层次的自动化优化。
两项研究的实验结果都表明,通过并行化技术可以显著提高LLMs处理复杂任务的效率。特别是在涉及多个独立API调用的场景中,并行化技术能够将执行时间减少50%以上,这对于实际应用的部署具有重要意义。
3.4 安全性探索:ToolSword的风险分析
ToolSword作为大模型工具学习安全性研究的先驱工作,系统性地分析了LLMs在工具使用过程中可能面临的各种安全风险。该研究的重要性在于它首次全面梳理了工具学习的安全威胁模型,为后续的安全研究提供了重要的理论基础。
该研究将工具学习的安全问题分为三个阶段:输入阶段、执行阶段和输出阶段,每个阶段都有其特定的安全威胁。在输入阶段,主要威胁包括恶意查询和越狱攻击,攻击者可能通过精心设计的输入来诱导LLMs执行有害的工具调用。在执行阶段,威胁主要来自噪声误导和风险提示,可能导致LLMs选择错误的工具或参数。在输出阶段,威胁包括有害反馈和错误冲突,可能导致LLMs生成有害或误导性的输出。
该研究的实验结果揭示了一个令人担忧的现实:即使是GPT-4等最先进的模型,在面对精心设计的安全攻击时仍然存在脆弱性。这一发现强调了在推进LLMs工具使用能力的同时,必须同步加强安全防护机制的重要性。
4. 技术发展趋势与挑战
4.1 从工具使用到工具制造的演进
大模型工具学习领域正在经历从被动工具使用向主动工具制造的重要转变。早期的研究主要关注如何让LLMs有效地使用现有工具,而最新的研究开始探索LLMs自主创建工具的能力。这一转变反映了研究者对LLMs自主性和创造性的更高期待。
"LLMs as Tool Makers"研究提出的LATM框架代表了这一趋势的重要里程碑。该框架不仅实现了工具的自动生成,还通过工具缓存和重用机制显著降低了系统的运行成本。这种从工具使用到工具制造的演进,预示着未来的LLMs将具备更强的自适应能力,能够根据具体任务需求动态创建和优化工具。
然而,工具制造也带来了新的挑战。自动生成的工具的质量和安全性如何保证?如何避免生成的工具之间的冲突和重复?这些问题需要在未来的研究中得到进一步解决。
4.2 小模型工具能力的快速提升
另一个显著的发展趋势是小规模模型在工具使用能力方面的快速提升。ToolAlpaca和ToolACE等研究表明,通过高质量的合成数据和精心设计的训练策略,即使是参数量相对较小的模型也能获得与大型模型相媲美的工具使用能力。
这一趋势的重要意义在于它大大降低了部署工具增强型LLMs的成本和技术门槛。对于资源受限的组织和应用场景,小模型的工具使用能力提升为其采用这一技术提供了可行的路径。同时,这也推动了工具学习数据生成和模型训练方法的创新。
ToolACE的成功特别值得关注,其通过自我进化合成过程生成的高质量训练数据,使8B参数的模型在函数调用任务上达到了与GPT-4相媲美的性能。这一成果不仅证明了数据质量在工具学习中的关键作用,也为未来的研究提供了重要的方法参考。
4.3 评估方法的精细化和标准化
随着工具学习技术的快速发展,评估方法也在不断精细化和标准化。从早期简单的成功率评估,到现在的多维度、细粒度评估,评估方法的进步为技术发展提供了重要的指导和支撑。
StableToolBench解决了评估一致性的问题,通过虚拟API服务器和自动评估器消除了评估过程中的随机性。ToolEyes则从评估的全面性角度出发,提出了涵盖五个关键维度的细粒度评估框架。这些评估方法的创新不仅提高了评估的准确性和可靠性,也为不同研究之间的比较提供了统一的标准。
然而,评估方法的发展仍面临挑战。如何设计更加贴近实际应用场景的评估任务?如何平衡评估的全面性和效率?如何处理不同工具和任务之间的差异性?这些问题需要在未来的研究中得到进一步探索。
4.4 效率优化与并行化的深入发展
效率优化已成为大模型工具学习领域的一个重要研究方向。随着应用场景的复杂化,单纯的顺序工具调用已无法满足实际需求,并行化技术的发展成为提高系统效率的关键。
LLMOrch和LLMCompiler的成功表明,通过智能的任务调度和并行执行,可以显著提高复杂任务的处理效率。这些研究不仅在技术上实现了突破,也为未来的系统设计提供了重要的架构参考。
未来的效率优化研究可能会朝着更加智能化的方向发展,包括动态负载均衡、自适应资源分配、跨设备协同等方面。同时,如何在保证效率的同时维持结果质量,也将是一个重要的研究课题。
4.5 安全性和鲁棒性的重要性凸显
随着LLMs与外部世界交互的加深,安全性和鲁棒性问题日益凸显。ToolSword的研究揭示了工具学习中存在的多种安全威胁,这些威胁不仅可能导致系统功能异常,还可能被恶意利用造成更严重的后果。
安全性研究的挑战在于威胁的多样性和隐蔽性。攻击者可能通过各种方式来诱导LLMs执行有害的工具调用,而这些攻击往往难以预先识别和防范。因此,需要开发更加全面和智能的安全防护机制。
未来的安全性研究可能会集中在以下几个方面:开发更加鲁棒的工具调用验证机制、设计智能的异常检测系统、建立完善的安全评估标准等。同时,如何在保证安全性的同时不过度限制系统的功能性,也将是一个重要的平衡点。
5. 未来研究方向与展望
5.1 多模态工具集成与具身智能
未来的研究将越来越关注多模态工具的集成,使LLMs能够处理不仅仅是文本,还包括图像、音频、视频等多种模态的信息。这种多模态工具集成将为LLMs开辟更广阔的应用空间,特别是在机器人技术、自动驾驶、智能家居等需要与物理世界深度交互的领域。
具身智能(Embodied AI)的发展将推动LLMs从纯粹的信息处理系统向能够感知和操作物理世界的智能体转变。这需要LLMs不仅能够理解和生成文本,还能够理解空间关系、物理定律和因果关系。多模态工具的集成将为实现这一目标提供重要的技术支撑。
在这一方向上,未来的研究可能会关注以下几个关键问题:如何设计统一的多模态工具接口?如何处理不同模态之间的信息融合和转换?如何确保多模态工具调用的一致性和可靠性?这些问题的解决将为多模态工具集成的实际应用奠定基础。
5.2 工具学习的泛化与迁移能力
提升LLMs在未见过工具或新任务场景下的工具学习能力,减少对大量特定领域数据的依赖,实现更强的零样本或少样本工具适应性,将是未来研究的重要方向。这种泛化能力对于LLMs在实际应用中的部署具有重要意义,因为现实世界中的工具和任务往往是多样化和动态变化的。
元学习(Meta-learning)技术可能在这一方向上发挥重要作用。通过学习如何快速适应新工具和新任务,LLMs可以在面对未见过的场景时快速获得相应的工具使用能力。这种能力不仅能够提高系统的适应性,还能够减少对大量训练数据的需求。
另一个重要的研究方向是工具知识的抽象和表示。如何将不同工具的共同特征抽象出来,形成可迁移的工具使用知识?如何设计有效的工具表示方法,使LLMs能够快速理解新工具的功能和使用方式?这些问题的解决将为工具学习的泛化提供理论基础。
5.3 智能化工具选择与编排
随着可用工具数量的快速增长,如何让LLMs在面对复杂、不确定任务时,能够更智能、更高效地选择、组合和编排工具,减少不必要的试错和资源消耗,将成为一个重要的研究课题。这需要LLMs具备更高级的规划、推理和自我修正能力。
强化学习技术可能在这一方向上发挥重要作用。通过与环境的交互和反馈,LLMs可以学习到更优的工具选择和编排策略。同时,基于图神经网络的工具关系建模也可能为智能化工具编排提供新的技术路径。
此外,如何设计有效的工具推荐系统,帮助LLMs快速定位到最相关的工具?如何处理工具之间的依赖关系和冲突?如何在工具编排过程中进行动态调整和优化?这些问题都需要在未来的研究中得到深入探索。
5.4 工具使用的可解释性与透明度
深入理解LLMs工具使用决策过程,提高其决策的透明度和可解释性,将是未来研究的重要方向。这不仅有助于提高用户对系统的信任度,还能够为系统的调试和优化提供重要的指导。
可解释性研究可能会从多个角度展开:工具选择的解释、参数生成的解释、执行过程的解释等。通过提供清晰的解释,用户可以更好地理解系统的行为,并在必要时进行干预和调整。
注意力机制的可视化、决策树的生成、因果关系的分析等技术可能在这一方向上发挥重要作用。同时,如何设计用户友好的解释界面,使非专业用户也能够理解系统的决策过程,也将是一个重要的研究课题。
5.5 工具生态系统的标准化与协作
推动标准化工具接口和协议的建立,促进不同工具和LLMs之间的互操作性,从而构建一个更加开放、协作和高效的工具生态系统,将是未来发展的重要方向。这种标准化不仅能够降低工具集成的复杂度,还能够促进工具的共享和重用。
API标准化、工具描述语言、工具发现机制等都是这一方向上的重要研究内容。通过建立统一的标准和协议,不同的工具提供者和LLM开发者可以更容易地进行协作和集成。
同时,如何设计有效的工具质量评估和认证机制?如何处理工具版本更新和兼容性问题?如何建立可持续的工具生态系统?这些问题都需要在未来的研究和实践中得到解决。
大模型未来如何发展?普通人能从中受益吗?
在科技日新月异的今天,大模型已经展现出了令人瞩目的能力,从编写代码到医疗诊断,再到自动驾驶,它们的应用领域日益广泛。那么,未来大模型将如何发展?普通人又能从中获得哪些益处呢?
通用人工智能(AGI)的曙光:未来,我们可能会见证通用人工智能(AGI)的出现,这是一种能够像人类一样思考的超级模型。它们有可能帮助人类解决气候变化、癌症等全球性难题。这样的发展将极大地推动科技进步,改善人类生活。
个人专属大模型的崛起:想象一下,未来的某一天,每个人的手机里都可能拥有一个私人AI助手。这个助手了解你的喜好,记得你的日程,甚至能模仿你的语气写邮件、回微信。这样的个性化服务将使我们的生活变得更加便捷。
脑机接口与大模型的融合:脑机接口技术的发展,使得大模型与人类的思维直接连接成为可能。未来,你可能只需戴上头盔,心中想到写一篇工作总结”,大模型就能将文字直接投影到屏幕上,实现真正的心想事成。
大模型的多领域应用:大模型就像一个超级智能的多面手,在各个领域都展现出了巨大的潜力和价值。随着技术的不断发展,相信未来大模型还会给我们带来更多的惊喜。赶紧把这篇文章分享给身边的朋友,一起感受大模型的魅力吧!
那么,如何学习AI大模型?
在一线互联网企业工作十余年里,我指导过不少同行后辈,帮助他们得到了学习和成长。我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑。因此,我坚持整理和分享各种AI大模型资料,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频。
学习阶段包括:
1.大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。包括模型架构、训练过程、优化策略等,让读者对大模型有一个全面的认识。

2.大模型提示词工程
通过大模型提示词工程,从Prompts角度入手,更好发挥模型的作用。包括提示词的构造、优化、应用等,让读者学会如何更好地利用大模型。

3.大模型平台应用开发
借助阿里云PAI平台,构建电商领域虚拟试衣系统。从需求分析、方案设计、到具体实现,详细讲解如何利用大模型构建实际应用。

4.大模型知识库应用开发
以LangChain框架为例,构建物流行业咨询智能问答系统。包括知识库的构建、问答系统的设计、到实际应用,让读者了解如何利用大模型构建智能问答系统。
5.大模型微调开发
借助以大健康、新零售、新媒体领域,构建适合当前领域的大模型。包括微调的方法、技巧、到实际应用,让读者学会如何针对特定领域进行大模型的微调。


6.SD多模态大模型
以SD多模态大模型为主,搭建文生图小程序案例。从模型选择、到小程序的设计、到实际应用,让读者了解如何利用大模型构建多模态应用。
7.大模型平台应用与开发
通过星火大模型、文心大模型等成熟大模型,构建大模型行业应用。包括行业需求分析、方案设计、到实际应用,让读者了解如何利用大模型构建行业应用。


学成之后的收获👈
• 全栈工程实现能力:通过学习,你将掌握从前端到后端,从产品经理到设计,再到数据分析等一系列技能,实现全方位的技术提升。
• 解决实际项目需求:在大数据时代,企业和机构面临海量数据处理的需求。掌握大模型应用开发技能,将使你能够更准确地分析数据,更有效地做出决策,更好地应对各种实际项目挑战。
• AI应用开发实战技能:你将学习如何基于大模型和企业数据开发AI应用,包括理论掌握、GPU算力运用、硬件知识、LangChain开发框架应用,以及项目实战经验。此外,你还将学会如何进行Fine-tuning垂直训练大模型,包括数据准备、数据蒸馏和大模型部署等一站式技能。
• 提升编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握将提升你的编码能力和分析能力,使你能够编写更高质量的代码。
学习资源📚
- AI大模型学习路线图:为你提供清晰的学习路径,助你系统地掌握AI大模型知识。
- 100套AI大模型商业化落地方案:学习如何将AI大模型技术应用于实际商业场景,实现技术的商业化价值。
- 100集大模型视频教程:通过视频教程,你将更直观地学习大模型的技术细节和应用方法。
- 200本大模型PDF书籍:丰富的书籍资源,供你深入阅读和研究,拓宽你的知识视野。
- LLM面试题合集:准备面试,了解大模型领域的常见问题,提升你的面试通过率。
- AI产品经理资源合集:为你提供AI产品经理的实用资源,帮助你更好地管理和推广AI产品。
👉获取方式: 😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】

6. 结论
大模型工具/函数调度领域在过去两年中经历了快速发展,从Toolformer的开创性工作开始,到最新的并行化和安全性研究,该领域已经形成了相对完整的研究体系。通过对15篇重要论文的深入分析,我们可以看到该领域在理论基础、技术实现、评估方法、效率优化和安全性等方面都取得了重要进展。
工具学习基础理论与框架的研究为整个领域奠定了坚实的理论基础,从自监督学习到工具制造,展现了LLMs在工具使用方面的巨大潜力。大规模API集成与工具库构建的研究为实际应用提供了重要的数据支撑,使LLMs能够掌握海量的真实世界API。工具学习评估与基准测试的研究推动了评估方法的标准化和精细化,为技术发展提供了科学的指导。工具使用效率与并行化的研究显著提高了系统的处理效率,为复杂任务的实际部署奠定了基础。工具使用的安全与鲁棒性研究揭示了潜在的安全威胁,为安全防护机制的设计提供了重要参考。
展望未来,大模型工具/函数调度领域将继续朝着多模态集成、泛化能力提升、智能化编排、可解释性增强和生态系统标准化等方向发展。这些发展将共同推动LLMs从纯粹的文本处理系统向能够感知和操作外部世界的智能代理转变,为人工智能的未来发展开辟新的可能性。
随着技术的不断进步和应用场景的不断扩展,大模型工具/函数调度技术将在更多领域发挥重要作用,从科学研究到工业生产,从教育培训到日常生活,都将受益于这一技术的发展。同时,我们也需要持续关注技术发展过程中可能出现的挑战和风险,确保技术的健康发展和安全应用。
参考文献
[1] Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv preprint arXiv:2302.04761. https://arxiv.org/abs/2302.04761
[2] Tang, Q., Deng, Z., Lin, H., Han, X., Liang, Q., Cao, B., et al. (2023). ToolAlpaca: Generalized tool learning for language models with 3000 simulated cases. arXiv preprint arXiv:2306.05301. https://arxiv.org/abs/2306.05301
[3] Qin, Y., Liang, S., Ye, Y., Zhu, K., Li, J., Li, X., et al. (2023). ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. arXiv preprint arXiv:2307.16789. https://arxiv.org/abs/2307.16789
[4] Qu, C., Dai, S., Wei, X., Cai, H., Wang, S., Yin, D., Xu, J., et al. (2025). Tool learning with large language models: A survey. Frontiers of Computer Science. https://link.springer.com/article/10.1007/s11704-024-40678-2
[5] Cai, T., Wang, X., Ma, T., Chen, X., & Zhou, D. (2023). Large language models as tool makers. arXiv preprint arXiv:2305.17126. https://arxiv.org/abs/2305.17126
[6] Wang, H., Qin, Y., Lin, Y., Pan, J. Z., & Wong, K. F. (2024). Empowering large language models: Tool learning for real-world interaction. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. https://dl.acm.org/doi/abs/10.1145/3626772.3661381
[7] Guo, Z., Cheng, S., Wang, H., Liang, S., Qin, Y., Li, P., et al. (2024). Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models. arXiv preprint arXiv:2403.07714. https://arxiv.org/abs/2403.07714
[8] Shi, Z., Gao, S., Yan, L., Feng, Y., Chen, X., Chen, Z., et al. (2025). Tool learning in the wild: Empowering language models as automatic tool agents. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. https://dl.acm.org/doi/abs/10.1145/3696410.3714825
[9] Hao, S., Liu, T., Wang, Z., & Hu, Z. (2023). Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings. Advances in Neural Information Processing Systems. https://proceedings.neurips.cc/paper_files/paper/2023/hash/8fd1a81c882cd45f64958da6284f4a3f-Abstract-Conference.html
[10] Ye, J., Li, S., Li, G., Huang, C., Gao, S., Wu, Y., et al. (2024). Toolsword: Unveiling safety issues of large language models in tool learning across three stages. arXiv preprint arXiv:2402.10753. https://arxiv.org/abs/2402.10753
[11] Ye, J., Li, G., Gao, S., Huang, C., Wu, Y., Li, S., Fan, X., et al. (2024). Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios. arXiv preprint arXiv:2401.00741. https://arxiv.org/abs/2401.00741
[12] Liu, X., Di, P., Li, C., Sun, J., & Wang, J. (2025). Efficient Function Orchestration for Large Language Models. arXiv preprint arXiv:2504.14872. https://arxiv.org/abs/2504.14872
[13] Song, Y., Tang, X., Lothritz, C., Ezzini, S., Klein, J., et al. (2024). ToolACE: Winning the Points of LLM Function Calling. arXiv preprint arXiv:2409.00920. https://arxiv.org/abs/2409.00920
[14] Song, Y., Tang, X., Lothritz, C., Ezzini, S., Klein, J., Bissyandé, T. F., et al. (2025). CallNavi: A Challenge and Empirical Study on LLM Function Calling and Routing. arXiv preprint arXiv:2501.05255. https://arxiv.org/abs/2501.05255
[15] Kim, S., Moon, S., Tabrizi, R., Lee, N., et al. (2024). An LLM Compiler for Parallel Function Calling. International Conference on Machine Learning (ICML). https://openreview.net/forum?id=uQ2FUoFjnF

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献96条内容
已为社区贡献96条内容

所有评论(0)