李沐深度学习论文精读(二)Transformer + GAN
这篇博客精解了两大深度学习里程碑:Transformer与GAN。Transformer凭借自注意力机制,取代RNN/CNN,解决了长程依赖与并行化的核心难题,成为当今大模型的基础。GAN开创了生成器与判别器对抗的训练范式,无需复杂概率计算,直接生成高质量样本,定义了生成模型的新方向。文章对比了二者的核心创新、优势(并行/高质生成)与缺陷(自回归瓶颈/训练不稳定),并概述了其深远影响。
目录
3. Introduction -- RNN痛点与Transformer优势
5. Why Self-Attention 自注意力机制及优势
6.2 逐位置前馈网络 (Position-wise Feed-Forward Networks) FFN
6.3 位置编码(Positional Encoding, PE)
6. Advantages and disadvantages 优缺点
7. Conclusions and future work
1. Transformer
李宏毅深度学习教程 第6-7章 自注意力机制 + Transformer
1. 摘要
序列转换(如机器翻译、文本摘要)的主流模型是编码器-解码器(Encoder-Decoder) 结构
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks(CNN&RNN) that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism注意力机制.
摒弃CNN RNN;提出完全建立在注意力机制的 Transformer
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with摒弃 recurrence and convolutions entirely.
两个机器翻译任务,更并行 训练耗时短,BLEU score更高(效果更好)
Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. English-to-German translation task, English-to-French translation task,BLEU score 衡量机器翻译的分数
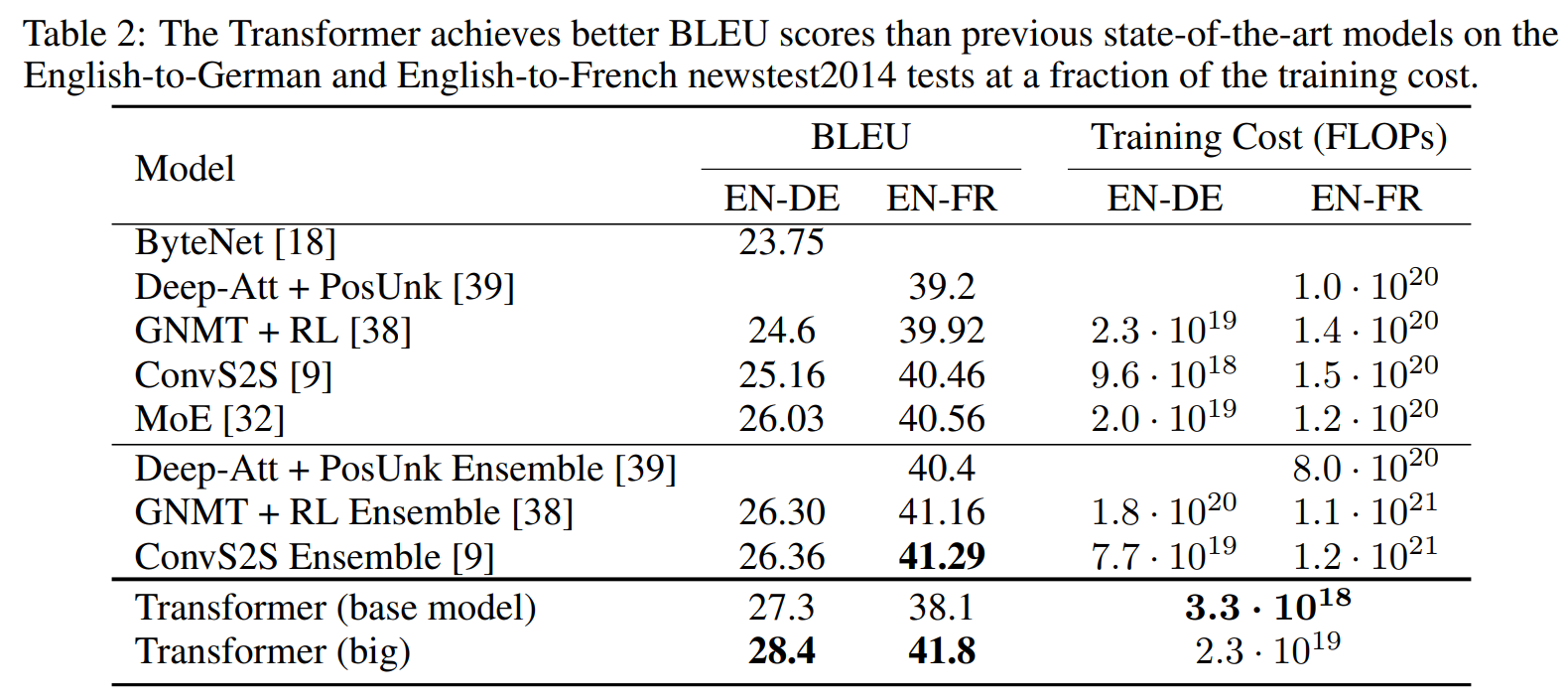
We show that the Transformer generalizes well泛化能力 to other tasks...
Despite the lack of task-specific tuning our model performs surprisingly well 没微调就表现很好
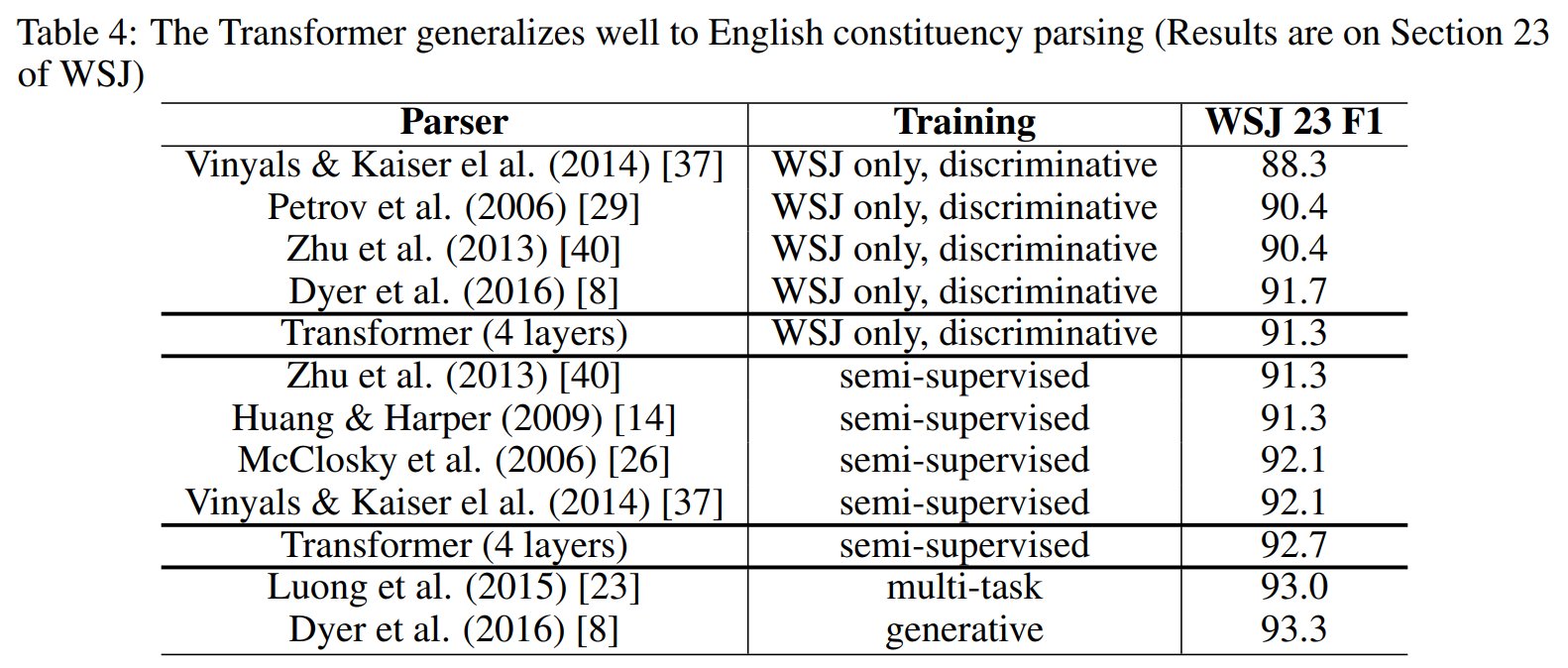
2. 结论 结果+优势+未来
凝练成果: 第一个完全基于注意力机制的序列转换模型。
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
凸显优势: 用最有力的实验数据(超越集成模型的结果)来支撑论文的价值。
特别指出在英德翻译任务上,他们最好的单一模型甚至超过了之前所有报告的集成模型(ensembles)
In the former task our best model outperforms even all previously reported ensembles.
展望未来:
1)从机器翻译文本到图像、音频、视频 多模态 images, audio and video.
-
Vision Transformer (ViT):直接将Transformer应用于图像分类,性能超越CNN。
-
多模态模型:如CLIP(图文匹配)、DALL-E、Stable Diffusion(文生图)、Whisper(语音识别)等,其核心都是Transformer架构。
2)Making generation less sequential 减少序列化 更加并行。
自回归生成模型(如GPT),在生成文本时需要一个词一个词地顺序生成,无法并行,导致推理速度较慢。
3. Introduction -- RNN痛点与Transformer优势
当时最先进的方法:RNN LSTM GRU。
The fundamental constraint of sequential computation:RNN的核心缺陷 按时间步(符号位置)顺序计算,当前时刻的隐藏状态 h_t 依赖于前一时刻的隐藏状态 h_{t-1} 和当前输入。
Allowing modeling of dependencies without regard to their distance in the input or output sequences 注意力机制优势:允许模型直接建立远距离依赖关系,而不受其之间距离的限制。
Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
提出Transformer,彻底抛弃循环结构,完全依赖注意力作为核心架构。
新模型实现了并行化,在取得更高性能的同时,训练速度大大加快。
4. Background 相关研究的区别和联系
现有工作-并行CNN 痛点:关联两个任意位置所需的计算操作次数(可理解为信息需要经过的“步数”或“层数”)会随着两者之间距离的增加而增加——长距离依赖捕捉困难。
自注意力不是新概念,但将其作为整个模型的唯一核心基础是前所未有的。
5. Why Self-Attention 自注意力机制及优势
自注意力是一种让序列中的每个元素(例如一句话中的每个词)与同一序列中的所有其他元素进行交互,并根据其相关性重新分配权重的机制。其目的是为序列中的每个位置计算一个新的、融入了全局上下文信息的表示。
例:想象你在阅读一句话:“The animal didn't cross the street because it was too tired.”
人类会立刻明白“it”指的是“animal”而不是“street”。自注意力机制的工作就是让模型学会这种指代关系。在计算“it”的新表示时,自注意力机制会赋予“animal”很高的权重(即非常“关注”animal),而赋予“street”或其他词很低的权重。
可并行 O(1)顺序操作数(对RNN优势) 网络中的长程依赖路径长度 O(1) (对CNN RNN优势)

限制注意力范围(restricted 只关注周围r个词) 还能使得 n^2*d -> r*n*d
As side benefit, self-attention could yield more interpretable models.
-
额外好处(Side Benefit):自注意力机制产出的模型更具可解释性。通过检查注意力权重的分布,我们可以看到模型在关注什么。例如,不同的注意力头可能专门负责学习不同的语法或语义关系(如指代消解、修饰关系等)。
6. Model Architecture 模型架构
Add&Norm + 层标准化
残差连接 x + Sublayer(x) 缓解深度网络中的梯度消失问题。统一维度: 为了便于进行残差相加,模型中所有子层以及词嵌入层的输出维度都统一为一个常数 d_model = 512。
编码器 encoder
每个块block 两个层:多头注意力 + Feed Forward 前馈 FFN
解码器 decoder
需要预测下一个字概率;把之前的输出outputs(shifted right)右移 作为解码器的输入
每个块三个层:masked掩码多头注意力 + 编码器-解码器注意力 + 前馈网络FFN
Masked Self-Attention 在训练时,解码器应该只能看到当前时刻之前的已知输出,而不能“偷看”未来的答案。通过一个掩码(Mask),将当前位置之后的所有位置的值设为负无穷(经过softmax后变为0),从而阻止了模型关注到未来的词。
编码器-解码器注意力(Encoder-Decoder Attention)它的Key和Value来自编码器最终的输出,而它的Query来自解码器第一子层的输出。
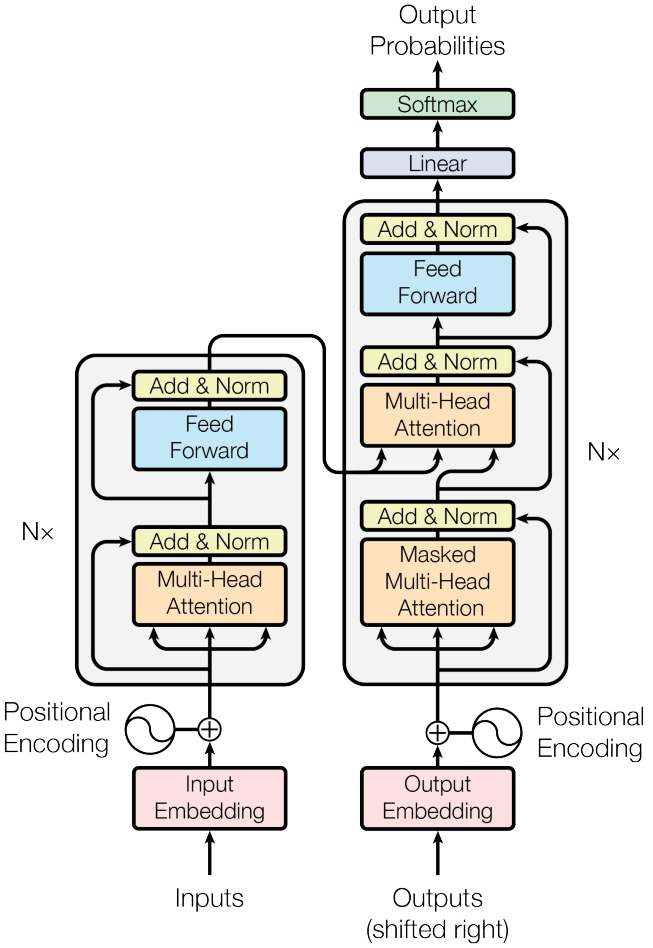
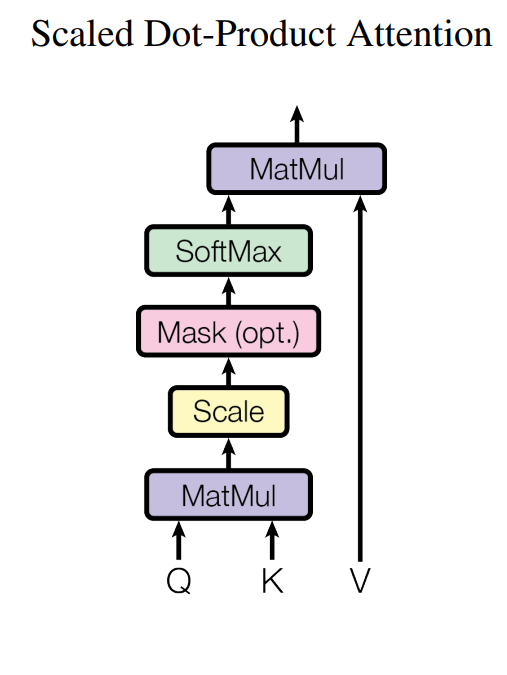
6.1 Attention 注意力
-
计算权重(Alignment Score): 通过一个兼容性函数(compatibility function) 计算Query和每个Key的相似度分数。在Transformer中,这个函数是点积(Dot-Product)。
-
计算加权和(Weighted Sum): 将上一步得到的权重分数作用在对应的Value上,并进行加权求和,得到最终的输出向量。
缩放(Scale): 将点积结果除以一个缩放因子 √(d_k)(即键向量维度的平方根)
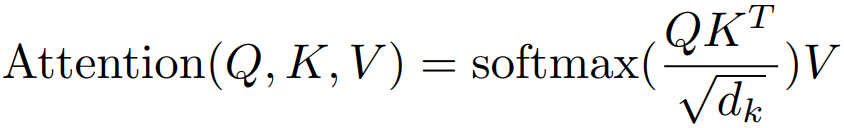
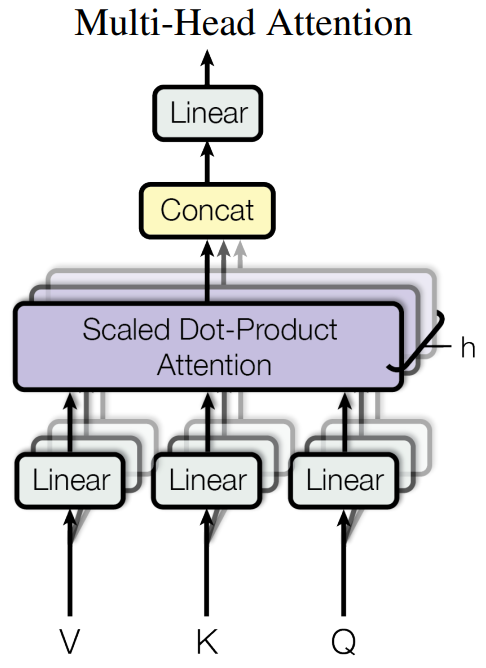
多头注意力 (Multi-Head Attention) 与其只使用一个d_model维的注意力函数,不如将查询、键、值线性投影h次到不同的、更低维的子空间(d_k, d_k, d_v)上,然后在每个投影后的版本上并行地执行注意力函数。最后将h个结果拼接起来,再投影回d_model维。
好处:允许模型同时关注来自不同表示子空间的信息

6.2 逐位置前馈网络 (Position-wise Feed-Forward Networks) FFN
第一层线性变换,使用ReLU激活函数;第二层线性变换。
![]()
6.3 位置编码(Positional Encoding, PE)
模型本身无法感知词的顺序信息。为了让它能利用序列的顺序,必须注入关于词的位置信息。比如正弦余弦。
将位置编码 与词嵌入(Word Embedding) 相加,作为编码器和解码器堆栈最底部的输入。
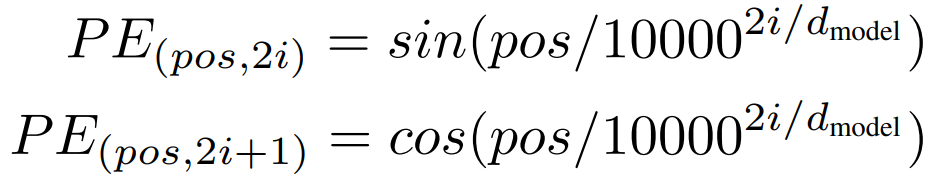
7. Train 精心调优的训练策略
两个翻译的数据集 English-German、English-French dataset
序列长度相近的句子对组合在同一个批次(batch)中。减少了因为序列长度不一而产生的填充(padding),提高了计算效率。
硬件:8块 NVIDIA P100 GPU 跑最大的模型 3.5天(远少于同时期需要一个月的模型)
Adam优化器 学习率调度 动态预热(Warmup)
![]()
正则化 (Regularization) 提升泛化能力 防止过拟合
1. 残差Dropout 2.标签平滑 (Label Smoothing)
-
传统做法:在分类任务中,真实标签的分布是
[0, 0, 1, 0](one-hot),即模型被鼓励以100%的信心输出正确类别。 -
标签平滑:将真实标签分布调整为
[0.025, 0.025, 0.9, 0.025](以ϵ_ls=0.1,类别数=4为例)。它让正确类别的概率不再是1,而是1 - ϵ_ls,并将ϵ_ls平均分给其他所有类别。
2. GAN
1. 摘要
两个网络 对抗训练的原理与目标 + 相比之前生成方法的 优势。
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G.
通过对抗过程建立 同时训练两个模型:生成模型(Generative Model, G)学习真实训练数据的分布,从而能够生成以假乱新的新样本(比如图片、文字等)。判别器(Discriminator, D)用于判断输入样本是来自真实数据(输出接近1)还是来自生成器(输出接近0)。它的目标是尽可能准确地区分真假样本。
The training procedure for G is to maximize the probability of D making a mistake.
生成器的训练目标:最大化判别器犯错的概率。
This framework corresponds to a minimax two-player game.
-
生成器不希望只是被动学习,而是主动地、有针对性地去欺骗判别器。
-
结合判别器的目标(最小化自己犯错的概率),整个训练过程形成了一个二元极小极大博弈
“In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere.”
当G和D的能力足够强(可以表示为任意函数)时,这个博弈游戏存在一个唯一的、最优的均衡点。G覆盖训练数据分布 以假乱真到 D无法区分(两个概率均为1/2)
“In the case where G and D are defined by multilayer perceptrons MLP, the entire system can be trained with backpropagation反向传播.”
优势:训练高效。它利用可以深度学习中最成熟、最强大的优化工具。
“There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples.”
与之前的生成模型(如玻尔兹曼机(RBMs) 或变分自编码器(VAEs))进行对比
-
马尔可夫链(Markov Chains): 像RBMs这类模型需要依赖耗时的采样过程(如吉布斯采样)来生成样本或进行训练。
-
近似推断网络(Approximate Inference Networks): VAEs需要在训练过程中对 latent variable(潜在变量)进行近似推断,这通常涉及复杂的计算。
-
GAN的优势: GAN完全避免了这些复杂且计算成本高的步骤。一旦训练完成,生成样本非常简单:只需向生成器输入一个随机噪声向量,它就会瞬间前向传播输出一个样本,速度极快。
2. Introduction
以前的痛点和困难 + 我们的处理 + 我们的优势。
深度学习的宏伟目标是发现丰富的、层次化的模型,用以理解和表示各种复杂数据(如图像、音频、文本)背后的概率分布。然而,迄今为止深度学习最引人注目的成功都集中在判别式模型(Discriminative Models) 上。这些成功很大程度上得益于反向传播(Backpropagation)、Dropout 等优化技术,以及使用分段线性激活函数(如ReLU),这些函数能提供良好、稳定的梯度,使得训练非常深的网络成为可能。
深度生成模型(Deep Generative Models)难以发展的两大原因:
-
难以处理的概率计算: 生成模型的核心是定义一个概率分布
P(x),用来表示“一张图片x有多大的可能性出现在真实世界中”。在最大似然估计(Maximum Likelihood Estimation)等传统方法中,涉及到许多计算上难以处理(Intractable) 的概率计算。例如,计算一个复杂模型的归一化常数(Partition Function)往往需要极其耗时的近似方法(如马尔可夫链蒙特卡洛,MCMC)。 -
难以利用现代网络组件的优势: 像ReLU、Dropout这类在判别模型中非常有效的组件,在生成模型的语境下难以直接发挥其优势。生成模型的结构和优化目标往往更为复杂。
-
警察与造假者比喻: 作者用了一个非常生动的比喻来解释这个框架:
-
生成模型(G) = 造假币的团队(Counterfeiters)。目标是制造出无法被识别的假钞。
-
判别模型(D) = 警察(Police)。目标是准确地识别出假钞。
-
-
动态博弈过程: 这种竞争关系会迫使双方不断改进自己的技术:警察鉴别能力越强,造假者就必须做出更逼真的假钞;而假钞越逼真,又反过来促使警察提升侦查技术。最终,理想的结果是生成模型产生的样本与真实数据“无法区分”。
In this case, we can train both models using only the highly successful backpropagation and dropout algorithms and sample from the generative model using only forward propagation.
-
巨大优势: 这正是GAN的巧妙和强大之处。在这个设定下:
-
训练: 只需要使用已经在判别模型中验证极其成功的反向传播和Dropout算法。生成器和判别器都是神经网络,可以完美地利用现代深度学习的工具链。
-
采样/生成: 一旦训练完成,生成新样本只需要一次前向传播。输入一个随机噪声,通过网络计算,瞬间输出一个样本。极其高效。
-
No approximate inference or Markov chains are necessary.
这句话再次强调,新方法完全不需要传统生成模型所依赖的 近似推断 或马尔可夫链 等复杂、耗时的步骤。这大大简化了训练和生成的流程,提高了效率。
相关工作:
变分自编码器VAE、深度玻尔兹曼机DBM 的核心是显式地定义一个概率密度函数p(x),并通过最大化对数似然(Maximizing Log-Likelihood) 来训练模型。它们的优点是提供了一个明确的显式的概率框架。 核心缺陷:难以处理的似然函数(Intractable Likelihood Functions)
GAN 放弃了显式定义概率密度函数,其核心目标变得更直接:只要能学会从目标分布中采样,生成高质量的样本就行,而不关心具体的概率值是多少。
GAN先驱工作:生成随机网络(Generative Stochastic Networks, GSNs)[4]。GSNs的优点是它可以通过精确的反向传播(Exact Backpropagation) 来训练,而不需要DBM那样复杂的分解近似。
NCE噪声对比估计:通过对比数据与固定噪声来学习分布。 “对手” 是固定的、简单的噪声分布 q(x)(如高斯分布)GAN相比更灵活。
LSTM之父 Jürgen 的PM(Prophetic Model) 同为GAN的审稿人
-
PM的任务是,基于智能体当前的状态和采取的行动,预测世界下一个状态(或传感器的下一个输入)。
-
智能体的内在目标是:采取那些能让PM感到“惊喜”或“学习进步”的行动。具体来说,就是寻找那些PM当前预测误差很大的情境。
人工智能中一种强大的通用范式:通过设计内部竞争或对抗的组件,可以产生强大的内在驱动信号,从而让系统自主学习或创造。
3. Adversarial nets 网络简介
生成器 (G) 输入: 先验噪声变量 z,通常从简单分布(如均匀分布、高斯分布)中采样,记作 p_z(z)
训练G(z; θ_g)网络;生成的数据 x_g = G(z),它遵循生成分布 p_g。
G 的目标是让 p_g 无限接近真实数据分布 p_data。
判别器 (D):输入: 数据 x,可以来自真实训练数据,也可以来自生成器。
训练D(x; θ_d)网络,输出: 一个标量,代表 x 来自真实数据而非生成器的概率。
D 的目标是尽可能准确地区分真假数据。
价值函数-D G最小最大博弈式:
D要使得最大,对于真实分布 前一项 D(x)越大越好;对于G生成的分布z D(G(z))越小越好
G要使得 最小化;影响第二项 让D(G(z)) D对它的生成打高分
![]()
两个网络的训练速度需要平衡 如果G比D强太多,G生成的所有图片 D都区分不了,G就无法根据D的反馈继续进步学习了(所以需要保证D跟上G的速度)
解决方案: 采用交替优化的迭代数值方法:
-
循环k次: 固定G,训练D k步。这使D保持在其最优解附近。
-
循环1次: 固定D,训练G 1步。要求G变化得足够慢(学习率不能太大)
在训练早期,G还很差,生成的样本很容易被D识别出来(即 D(G(z)) 接近0)。
此时,梯度∇θ_g log(1 - D(G(z))) 会变得非常小(梯度饱和),导致G学习缓慢。
不最小化 log(1 - D(G(z))), 转而最大化 log D(G(z))。
接近收敛时,p_g 接近 p_data,D成为一个部分准确的分类器。
优化D 使其收敛到理论最优值 ![]()
最终,当 p_g = p_data 时,D无法区分,处处输出 1/2。
4. Theoretical Results 理论证明
命题1:对于任意给定的生成器G,存在一个最优的判别器D*。

对于每个独立的x,最大化问题可以简化为:在y = D(x)处,最大化 a log(y) + b log(1 - y),其中 a = p_data(x), b = p_g(x)。
函数 y -> a log y + b log(1 - y) 在 y = a / (a + b) 处取得最大值。
定理1:整个极小极大博弈的全局最优解当且仅当生成分布 p_g 等于真实数据分布 p_data 时达到。并推导出此时的价值函数值。
博弈论知识,由命题1 给定G 最好的D*已知,那么G的任务就变成了代入 D=D*后 最小化价值函数 C(G):
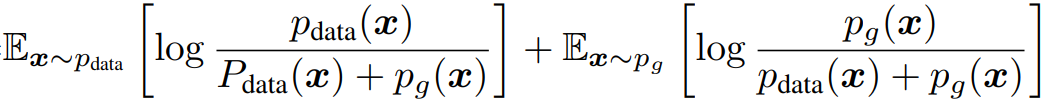
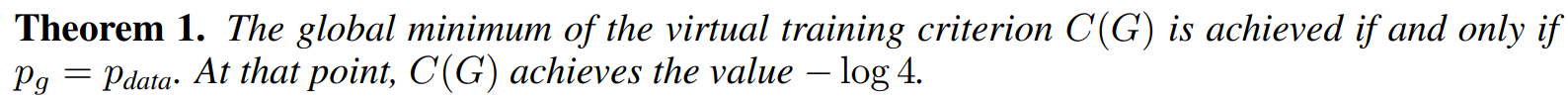

两个KL散度之和正好是Jensen-Shannon散度(JSD) 定义的两倍。
当且仅当两个分布完全相等时,JSD为零。
5. Experiments 实验结果
三个数据集评估:MNIST: 手写数字。 TFD: 人脸数据库 。 CIFAR-10: 自然物体图像 。
定性评估 看生成的图像效果:
1. 证明 “生成”而非“记忆”
每行最右侧样本为 与生成的一些图片最接近的 训练集的样本。
可以看出 生成图片和训练集图片还是有显著区别的,由此说明“生成”而非“记忆”。

2. 证明了潜在空间z的连续性和平滑性。
展示了生成器G学会了从噪声到数据的平滑映射。
在潜在空间 z 中,对两个随机点进行线性插值,然后将插值点输入生成器G。 可以看出数字渐变。

定量评估:
-
挑战: 由于GAN不提供显式的似然函数
p_g(x),无法直接计算测试集数据的对数似然(Log-Likelihood)这个传统评估指标。
-
步骤:要实现 对随机噪声z 取一个生成结果的平均。
-
从训练好的生成器
G中抽取大量样本。 -
用一个高斯分布拟合每一个生成样本(想象在每个生成样本点上放一个小的 Gaussian “窗”)。
-
将所有这些小高斯分布混合起来,形成一个对
p_g的近似分布。 -
在这个近似分布下计算测试集数据的平均对数似然。
-
6. Advantages and disadvantages 优缺点
缺点1. 没有显式的概率密度函数(No explicit p_g(x))
难以评估生成模型的好坏; 也难以将GAN应用于那些需要概率估计的任务
缺点2. 训练需要精心同步
判别器 D 和生成器 G 的训练必须保持平衡。这是一个动态博弈,一方不能远强于另一方。
否则会 模式崩溃(Mode Collapse)丧失多样性
原因:如果 G 更新得太多而 D 没有相应更新(即内部循环没有训练 D 足够的步数 k),G 会很快发现一个能有效欺骗当前弱判别器 D 的样本(例如,一个看起来还算真实的图片)。
结果: G 会塌陷到这个模式,开始只生成这个或极少数类似的样本,丢失了数据的多样性。因为它发现只输出这个样本就能轻松“赢”得游戏。
A.计算优势(Computational Advantages)
训练时 无需DBM那样的MCMC 马尔可夫链(No Markov chains)
无需VAE编码器网络那样的推断(No inference needed)
仅使用反向传播(Only backpropagation)
模型设计灵活(Great flexibility)只要函数是可微的,就可以融入GAN的框架中。这意味着可以使用最先进的网络架构。
B.统计优势(Statistical Advantages)
生成器 G 的更新不是直接来自于数据样本,而是来自于从判别器 D 反向传播回来的梯度,生成器是在学习数据的本质特征和结构,而不是简单地记忆和拼接训练样本。这通常能带来更好的泛化能力。
基于马尔可夫链的方法(如DBM)要求分布不能是过于尖锐或退化的,由于GAN不依赖马尔可夫链,它的生成器可以学会生成非常清晰、逼真的样本,可以完美地表示高度尖锐的分布。这是GAN生成的图像通常比VAE等模型更清晰的原因之一。
以下为几个模型 在训练方式、推断方式、采样方式、评估方式与模型设计上的特点。
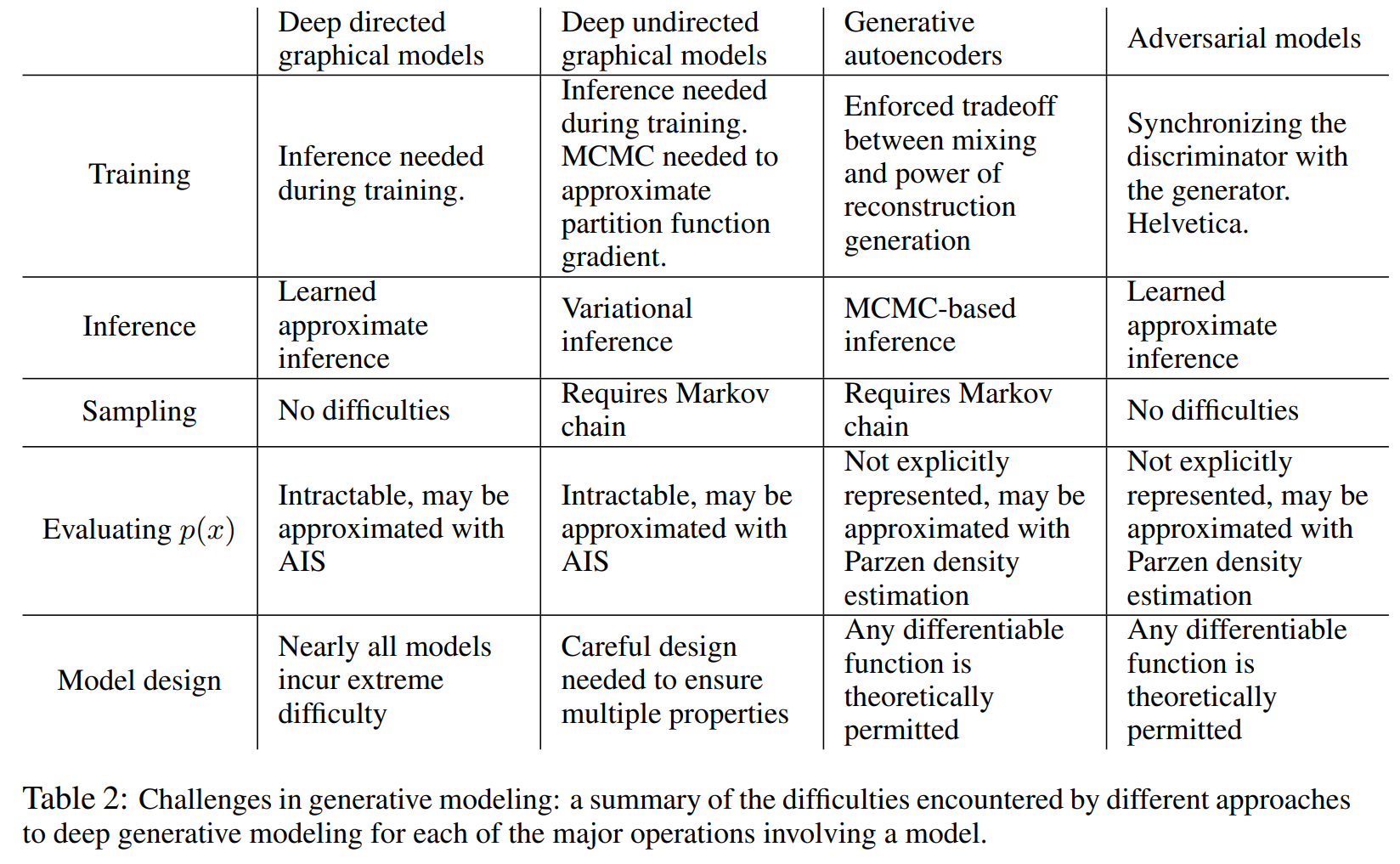
GAN用牺牲显式概率密度估计和引入训练不稳定性为代价,换来了无与伦比的计算效率、灵活性和生成样本的高质量。
7. Conclusions and future work
1. 条件生成模型 (Conditional GAN)
通过在生成器G和判别器D的输入中同时加入一个条件信息 c。p(x) -> p(x|c)
2. 学习近似推断 (Learned Approximate Inference) x反推z 输出反推输入
可以训练一个辅助网络,根据数据x来预测其对应的噪声z(反向)。这个网络就是一个编码器(Encoder)
模型不仅学习一个生成器G: z -> x,还学习一个编码器E: x -> z,并通过对抗训练让两者匹配。
3. 条件概率建模 (Modeling All Conditionals) 对输出要求加条件
通过训练一系列共享参数的条件模型,可以近似地建模所有可能的条件分布。例如,给定图像的一部分x_¬S,生成缺失的部分x_S(图像补全)。
4. 半监督学习 (Semi-supervised Learning)
当带标签数据很少时,判别器D(或推断网络)学习到的特征可以用于提升分类器的性能。
让判别器D不仅执行“真/假”二分类,还同时执行一个“K+1”分类(其中K是真实类别,+1代表“假”的类别)。利用大量无标签数据训练D学习好的特征,再用少量有标签数据微调分类层。
5. 效率提升 (Efficiency Improvements) 训练技巧
通过设计更好的G和D协调方法或确定更好的噪声z采样分布,可以大大加速训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)