联邦学习与大模型结合
联邦学习(Federated Learning, FL)与大模型(如深度神经网络、大规模预训练模型等)结合,已成为当前人工智能研究和应用中的重要方向。这种结合能够发挥二者各自的优势,推动分布式学习和大规模预训练模型在实际应用中的发展。
联邦学习(Federated Learning, FL)与大模型(如深度神经网络、大规模预训练模型等)结合,已成为当前人工智能研究和应用中的重要方向。这种结合能够发挥二者各自的优势,推动分布式学习和大规模预训练模型在实际应用中的发展。
 以下是对联邦学习与大模型结合的简要介绍:
以下是对联邦学习与大模型结合的简要介绍:
1. 背景与挑战
-
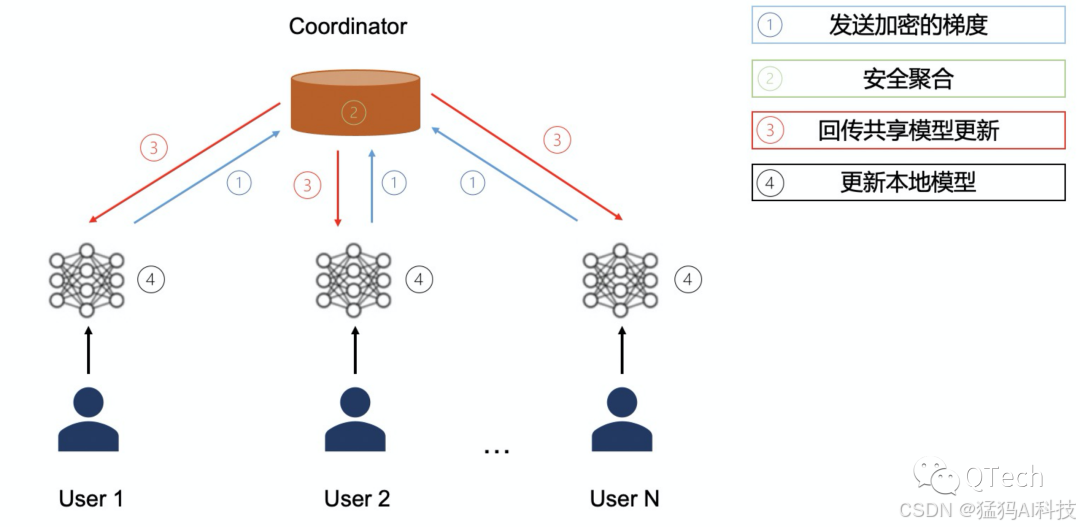
联邦学习:联邦学习是一种分布式机器学习方法,允许多个客户端在本地数据上训练模型,之后通过聚合本地更新来共同优化一个全局模型。联邦学习的优势在于它可以保护数据隐私,减少数据传输,避免集中存储敏感信息。
-
大模型:大模型(如GPT系列、BERT、T5等)通常指包含大量参数和层次的深度学习模型。这些模型在处理复杂任务时表现出色,如自然语言处理、计算机视觉等。然而,训练这些大模型需要大量的计算资源和数据,这使得其在传统的集中式训练中成本极高。
2. 结合的动机与优势
-
隐私保护:联邦学习通过在客户端本地进行训练,并仅交换模型更新而非原始数据,能够有效保护用户数据隐私。结合大模型时,可以在不暴露敏感数据的情况下,利用多个客户端的数据进行大规模训练。
-
分布式训练:大模型的训练通常需要极为庞大的计算资源,单个设备往往无法承载。联邦学习提供了一个通过多设备协同训练的框架,使得大模型的训练过程可以在多个客户端之间分担,从而降低了每个设备的计算压力。
-
计算资源优化:结合大模型和联邦学习,能够通过智能调度和分配计算任务来优化资源利用。例如,可以利用终端设备(如智能手机、物联网设备)的计算能力,进行局部训练,并通过聚合模型更新来实现大规模模型的训练。
3. 技术挑战
-
模型通信与同步:大模型通常包含数亿甚至数百亿的参数,如何高效地在客户端和服务器之间同步这些大量的模型参数,成为一个重大挑战。传输的带宽、延迟和设备的计算能力都可能成为瓶颈。
-
模型压缩与剪枝:为了减少通信开销,可以对大模型进行压缩,如参数剪枝、量化等方法。这些技术在联邦学习的场景下尤为重要,因为客户端的计算资源和网络带宽有限。
-
异构数据和设备问题:不同客户端的数据分布和计算能力可能存在差异。如何确保大模型能够适应各种设备和数据场景,特别是在非IID(非独立同分布)数据情况下,仍然保持高效的学习效果,是一个亟待解决的问题。
-
模型精度与收敛性:大模型往往需要大量的数据和长时间的训练才能收敛。而在联邦学习中,客户端的训练数据往往较少,且训练次数有限,因此如何在有限的本地计算和数据上获得足够的精度,是一个关键挑战。
4. 应用场景
-
智能手机与移动设备:联邦学习与大模型结合在智能手机中有着广泛的应用前景。例如,Google的Gboard输入法就使用了联邦学习,通过在用户的手机上本地训练大规模语言模型,来提高输入法的精准度,而无需上传用户的输入数据。
-
医疗健康:在医疗领域,数据隐私和安全性至关重要。联邦学习与大模型的结合能够让不同医院和医疗机构在保持数据隐私的情况下,利用分散的数据进行大规模疾病预测模型的训练。
-
金融与智能家居:在金融风控和智能家居领域,联邦学习与大模型的结合能够利用多个金融机构或智能设备提供的数据,在本地训练并优化大模型,以提供个性化的服务或风控决策,而无需将敏感数据上传至云端。
5. 未来发展趋势
-
高效的模型聚合策略:随着大模型的不断发展,研究者正在探索如何设计更加高效的聚合策略(如异步更新、增量学习等),以适应大规模的联邦学习环境,减少通信成本和加速模型的训练过程。
-
边缘计算与联邦学习结合:随着边缘计算的发展,边缘设备的计算能力逐渐增强。将联邦学习与边缘计算结合,可以将大模型的训练和推理任务更加高效地分配到终端设备上,实现分布式大规模计算和智能决策。
-
自动化优化与自适应学习:通过自动化的优化算法和自适应的训练策略,可以进一步提升大模型在联邦学习中的训练效率和收敛速度,尤其是在数据分布不均、设备异构性较大的情况下。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)