通过工具增强 LLM Agent 能力:veRL+ReTool 的完整实践指南
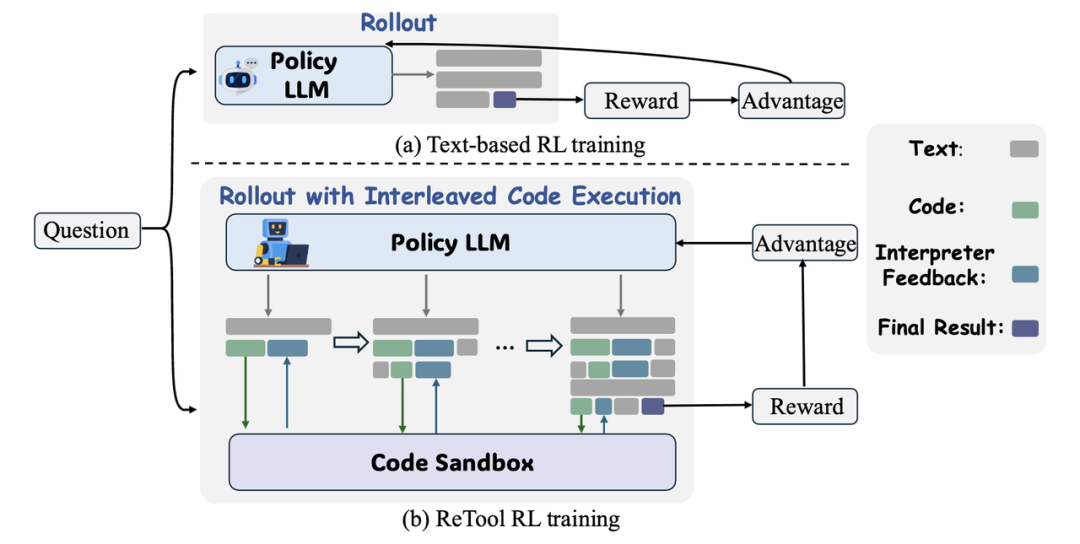
具体而言,Retool 在推理时会生成自然语言思考与代码片段的混合轨迹,当检测到代码终止标记时,将代码发送至异步沙盒执行,再将结果(含成功输出或错误信息)反馈给模型以指导后续推理,这种 “思考 - 执行 - 反馈” 的循环机制,配合基于最终答案准确性的奖励设计,使模型能自主发现最优工具调用模式,既提升推理效率又增强计算准确性。Trace 功能通过记录函数的输入、输出和对应的时间戳,帮助在复杂的多轮
资料来源:火山引擎-开发者社区
LLM 的“结构化任务痛点”与 ReTool 的破局
大语言模型(LLM)擅长开放式对话,但面对数学推理、复杂逻辑计算等结构化任务时,往往会陷入两个困境:
-
靠文本推理 “拍脑袋”,结果错误率高;
-
不会主动调用工具(比如代码沙箱),无法利用工具的精确计算能力。
字节跳动的 ReTool 框架,用 “冷启动 SFT+RL 策略学习” 的组合拳,让 LLM 学会 “思考 - 执行 - 反馈” 的闭环:先通过监督微调(SFT)掌握基础工具调用,再用强化学习(RL)优化策略,最终在 AIME2024 数学数据集上达到 67% 准确率(仅 400 步训练),远超文本基线 RL 的 40%(需 1080 步)。
我们基于火山引擎 veRL 强化学习框架,完整复现了 ReTool 的 SOTA 效果。今天就把从 “环境搭建” 到 “训练调优” 的全流程,拆成通俗易懂的步骤分享给大家。
ReTool 的核心逻辑:让 LLM 学会 “用工具解决问题”
Retool 是一个专为大语言模型(LLM)设计的工具增强强化学习框架,核心在于通过动态交织的代码执行与强化学习策略优化,提升模型在结构化问题(如数学推理)中的解决能力。其工作分为两个关键阶段:
-
首先,通过冷启动数据生成流水线构建包含代码增强推理轨迹的高质量数据集,以监督微调方式让模型掌握基础的工具调用与执行结果分析能力。
-
随后进行工具调用策略学习。具体而言,Retool 在推理时会生成自然语言思考与代码片段的混合轨迹,当检测到代码终止标记时,将代码发送至异步沙盒执行,再将结果(含成功输出或错误信息)反馈给模型以指导后续推理,这种 “思考 - 执行 - 反馈” 的循环机制,配合基于最终答案准确性的奖励设计,使模型能自主发现最优工具调用模式,既提升推理效率又增强计算准确性。
论文链接:https://arxiv.org/pdf/2504.11536
实验设置:论文在训练过程中采用了 VeRL 框架,并选用 PPO 作为强化学习方法,其余设置详见论文。
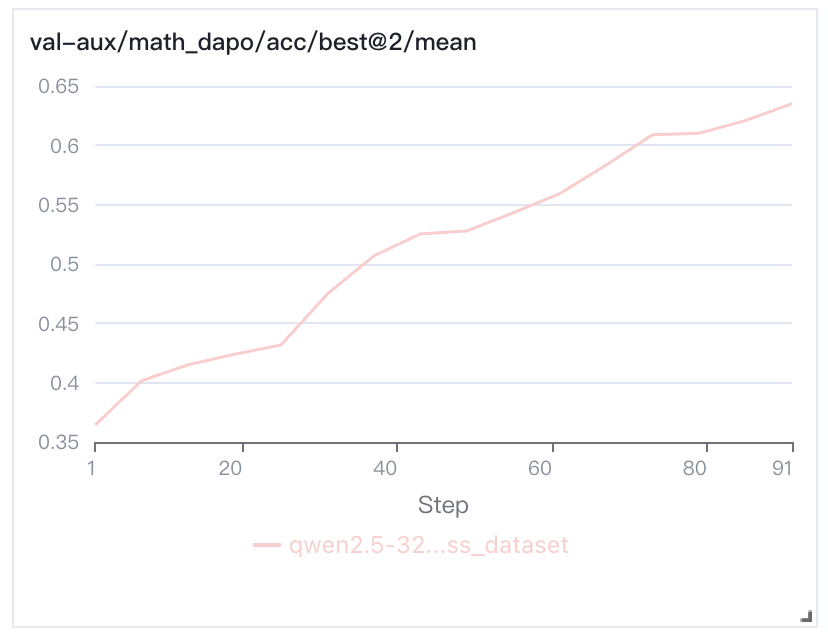
实验结果:论文中在数学场景(如 AIME2024 数据集)验证,准确率提升至 67.0%(仅需 400 步训练),远超文本基线 RL 的 40.0%(需 1080 步)。下为在机器学习平台上的复现效果,验证集为 AIME2024,实验结果可在机器学习平台的实验管理中查看。
veRL:支撑 ReTool 复现的 “RL 基建”
要复现 ReTool,得有一个灵活、高效、支持生产环境的 RL 框架,veRL 是火山引擎推出的用于大语言模型(LLM)的强化学习库,具有灵活性、高效性且适用于生产环境。借助 veRL 强化学习框架,可以使模型在推理过程中动态插入代码块并与沙盒环境实时交互,根据执行反馈(如正确 / 错误结果)迭代优化工具使用策略。veRL 具有以下特点:
-
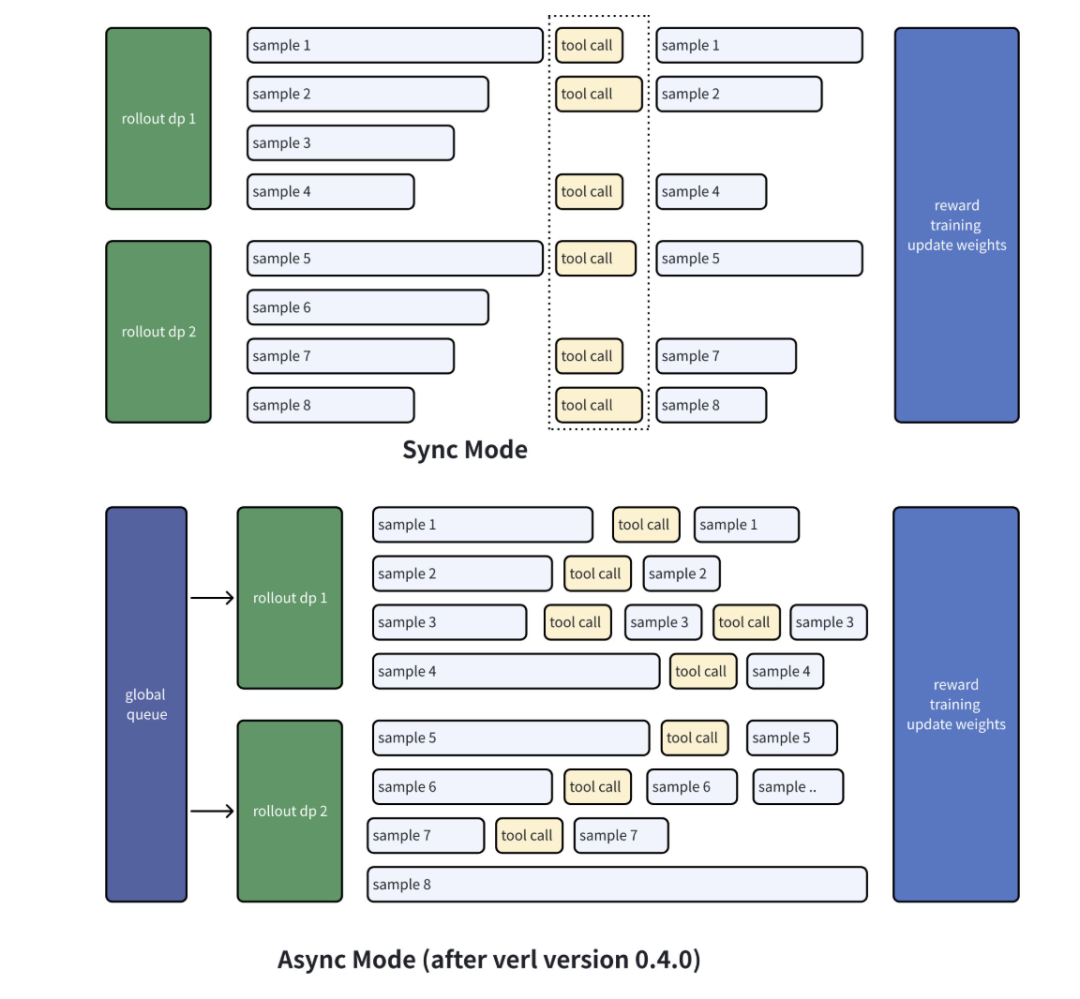
异步推理请求机制:veRL Agent loop 采用异步机制,主要通过 Python 的
asyncio库实现。在AgentLoopWorker的generate\_sequences方法中,为每个输入消息创建异步任务\_run\_agent\_loop,并使用asyncio.gather并发执行这些任务,让工具调用和GPU计算能够同时执行,提高处理效率。工作流程如下:
-
自定义工具:veRL 支持多种工具调用,并且可以让用户自定义工具。目前已经提供的工具包括 Search tool、代码沙箱、MCP 等,想接什么工具自己定;
-
扩展 Agent loop,支持 LangGraph 等 Agent 框架:veRL AgentLoop 具备良好扩展性,可支持各类 agent 框架。开发者能将这些框架的独特优势集成到 Agent loop 里,例如利用 LangGraph 在图处理和智能推理方面的长处,提升 Agent 处理复杂任务的能力。
从 0 到 1 复现 ReTool 的完整步骤
获取详细实践文档:账号登录-火山引擎
目标:复现 ReTool 论文效果,通过 Multi-turn 协作机制,提升模型在数据领域内的效果(如数学推理任务),同时确保训练效率和安全。
能力依赖
-
Multi-turn 交互:支持模型与沙盒的异步反馈循环。
-
Async-Rollout:实现非阻塞式执行,提升并发效率。
组件:
-
火山引擎机器学习平台
-
veRL 强化学习训练框架
-
vePFS
-
veFaaS
Step1:环境准备:搭好 “工具调用的基建”
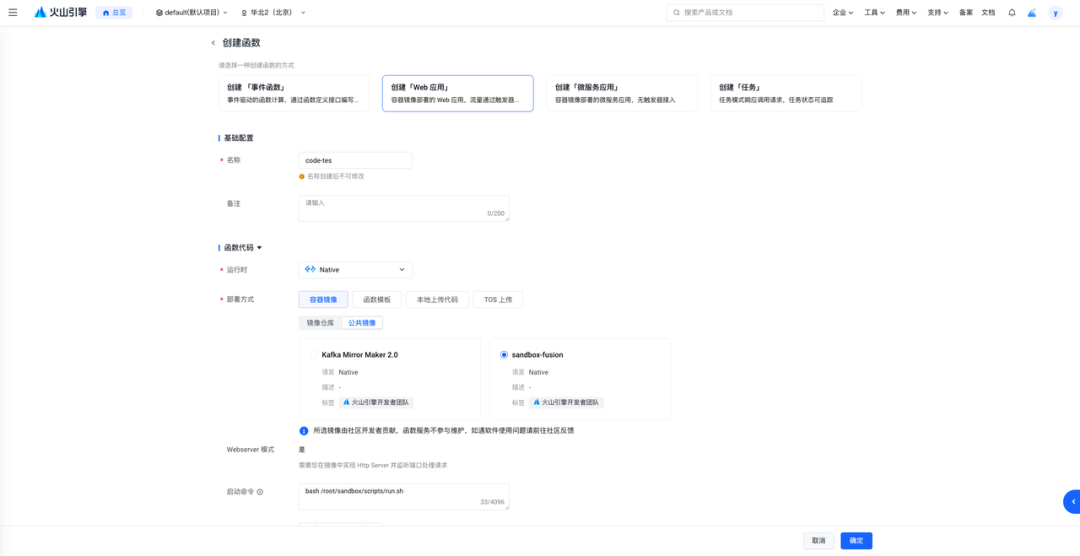
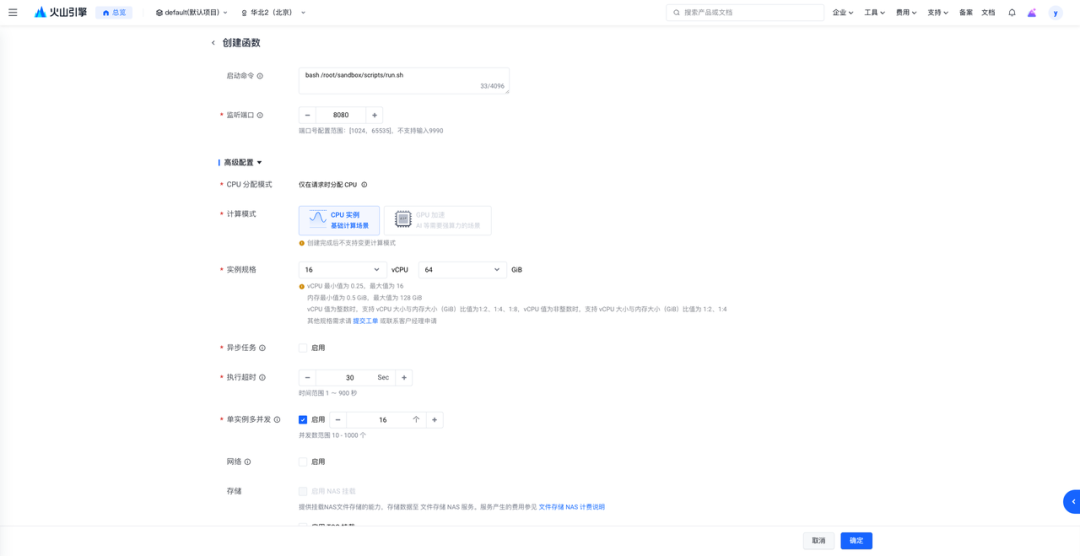
创建 veFaaS 服务
veFaaS 云沙箱管理--函数服务-火山引擎:https://www.volcengine.com/docs/6662/1656341
-
Sandbox 实例规格:16c / 64G
-
并发设置:16/实例
-
实例数上限:需要根据 reward_model.sandbox_fusion.max_concurrent 进行设置,若 reward_model.sandbox_fusion.max_concurrent =256,则实例数上限为256/16(并发)=16
-
获取函数服务域名
准备代码
创建开发机,在 vePFS 对应目录克隆代码:
暂时无法在飞书文档外展示此内容
准备数据集、模型
创建开发机,在 vePFS 对应目录下载数据集
-
sft 数据集 swordfaith/ReTool-SFT-multi-turn
-
RL 数据集 BytedTsinghua-SIA/DAPO-Math-17k
-
评测数据集 BytedTsinghua-SIA/AIME-2024
暂时无法在飞书文档外展示此内容
预处理数据集,生成 ReTool 需要的 sft 及 RL 数据集。
如果不能直连 huggingface,将脚本里的数据集改为下载好的数据集路径:
暂时无法在飞书文档外展示此内容
-
火山引擎提供 TOS 对象存储预置模型权重文件,方便客户自助复制,加速试验。以 Qwen/Qwen2.5-32B-Instruct 模型为例。
暂时无法在飞书文档外展示此内容
如果不使用预置模型,可以自行下载。
暂时无法在飞书文档外展示此内容
编辑脚本
在 verl/recipe/retool 目录下插入 run_qwen2-32b_sft.sh,脚本内容如下。
可以根据存储空间大小调整 trainer.save_freq
暂时无法在飞书文档外展示此内容
在 verl/recipe/retool 目录下插入 run_qwen2-32b_dapo.sh,脚本内容如下:
暂时无法在飞书文档外展示此内容
修改 recipe/retool/sandbox_fusion_tool_config.yaml,将 sandbox_fusion_url 填写为 step1-1 中建立的 veFaaS 地址:
暂时无法在飞书文档外展示此内容
设置训练参数
当前我们已经预置了一些调优后的参数,您还可以进一步自定义超参数。了解更多参数的含义和进行训练调优,可参考 veRL 官方调优指南 perf_tunning:https://verl.readthedocs.io/en/latest/perf/perf\_tuning.html
提交自定义任务
环境变量配置
volc cli 配置
volc cli 为机器学习平台的命令行工具,可以以命令行的方式便捷的进行任务提交,任务管理等操作。预置镜像已经安装 volc 命令行工具,进行升级操作。
暂时无法在飞书文档外展示此内容
可通过以下操作配置好 volc cli 和 jupyter notebook 需要的的环境依赖。
如果您不知道您的 AK/SK,可以通过 API 访问密钥(https://console.volcengine.com/iam/keymanage) 获得您当前身份的密钥对。
暂时无法在飞书文档外展示此内容
镜像配置
这里配置该文档所提交的所有任务,所用到的镜像信息,会默认使用你开机机所在 region 的镜像,如有其他需求,请更换为您所在的区域,以获取更好的体验。
暂时无法在飞书文档外展示此内容
资源配置
您可通过以下方式获取相关运行配置:
-
访问文件存储 vePFS (https://console.volcengine.com/vepfs/region:vepfs+%7BVOLC\_REGION%7D/instance) 获取关于 vePFS 的配置信息。
-
访问实例规格与定价 (https://www.volcengine.com/docs/6459/72363) 获取您希望使用的规格。
-
请确保本 notebook 挂载配置与下列文件系统配置完全一致。
暂时无法在飞书文档外展示此内容
提交 sft 任务
在进行 RL 训练前,需要先执行 sft 任务,冷启动模型。
暂时无法在飞书文档外展示此内容
通过 volc 命令行工具查询作业状态:
暂时无法在飞书文档外展示此内容
提交 RL 任务
请注意:RL 任务需要在 sft 任务执行完成后再提交,否则没有相应的 checkpoint。
首先配置自定义任务的启动参数,并通过 volc cli 命令行工具提交自定义任务。使用 Ray 框架进行分布式训练,执行下面的命令新建一个 yaml 任务配置文件:
暂时无法在飞书文档外展示此内容
观察训练中任务日志/实验过程/资源利用率
使用实验管理记录训练过程
veRL 中参数设置为 trainer.logger=['console','vemlp_wandb']
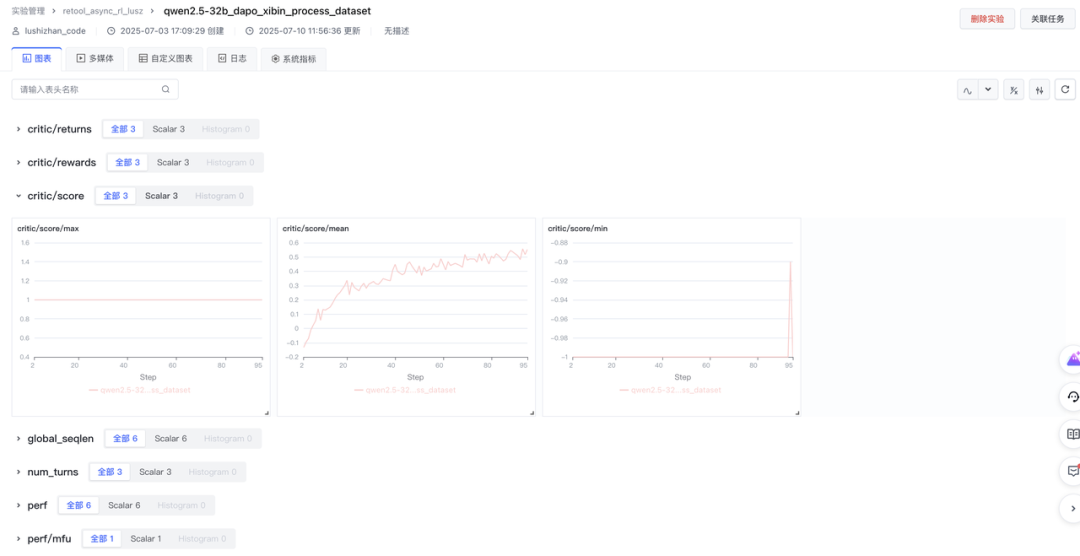
使用 Trace 工具分析训练过程
Agentic RL 在 rollout 过程中会有多轮对话、工具调用,以及用户交互的场景。在模型训练过程中,需要追踪函数调用、输入和输出,来了解数据在应用程序中的流动路径。Trace 功能通过记录函数的输入、输出和对应的时间戳,帮助在复杂的多轮对话中,查看数据在每次交互时的转换,最终得到输出的整个过程,有助于理解模型对数据的处理细节,来优化训练效果。
veRL Trace 功能集成了常用的 Agent trace 工具,已经支持的有 wandb weave 和 mlflow。用户可以根据自己的需求和习惯选择合适的 trace 工具。这里以 weave 为例,介绍下 trace 工具的使用方法。
基础配置
1.设置 WANDB_API_KEY 环境变量
2.veRL 配置参数
-
trainer.rollout_trace.backend=weave
-
trainer.logger=['console','wandb'] 。此项是可选项,trace 和 logger 是互相独立的功能,推荐使用 weave 时,也开启 wandb logger,在一个系统实现两项功能。
-
trainer.project_name=$project_name
-
trainer.experiment_name=$experiment_name
查看 Trace 日志
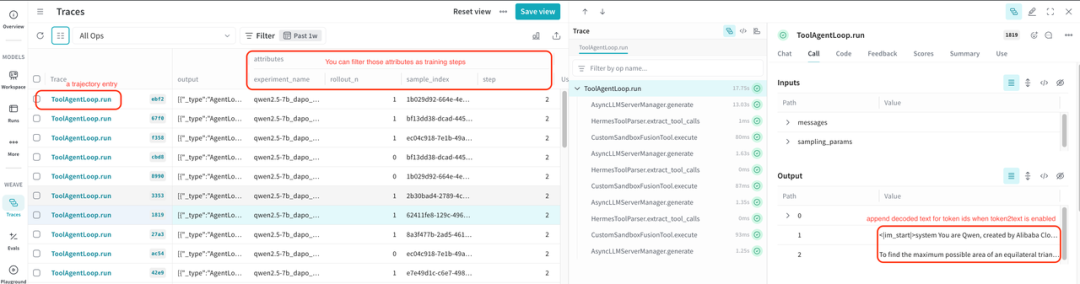
执行训练后,在项目页面中,可以看到 WEAVE 的侧边栏,点击 Traces 来查看。
每个 Trace 项目对应一个 trajectory。可以通过 step、sample_index、rollout_n、experiment_name 来过滤筛选需要查看的 trajectory。
开启 token2text 后,会自动在 ToolAgentLoop.run 的输出里面,增加 prompt_text 和 response_text,方便查看输入和输出的内容。
比较 Trace 日志
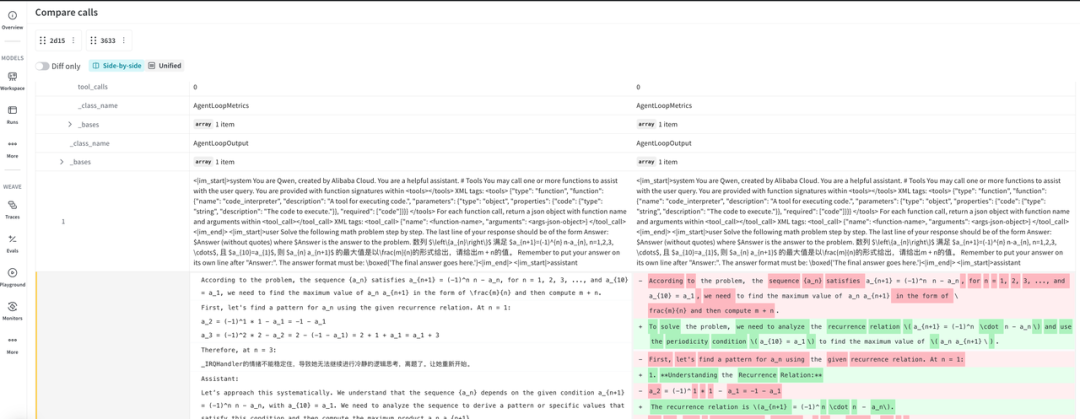
weave 可以选择多个 trace 项目,然后比较其中的差异。
复现 SOTA 的“关键经验”总结
Agent 在 RL 训练中需要使用 token 作为输入和输出
我们发现 decode 消息得到的 token_ids 可能与每一轮中通过合并 prompt_ids 和 response_ids 得到的 token_ids 不一致。对训练的影响是训练到 100 步左右时,模型性能会突然下降,同时 actor/grad_norm 指标也会变成 NaN。
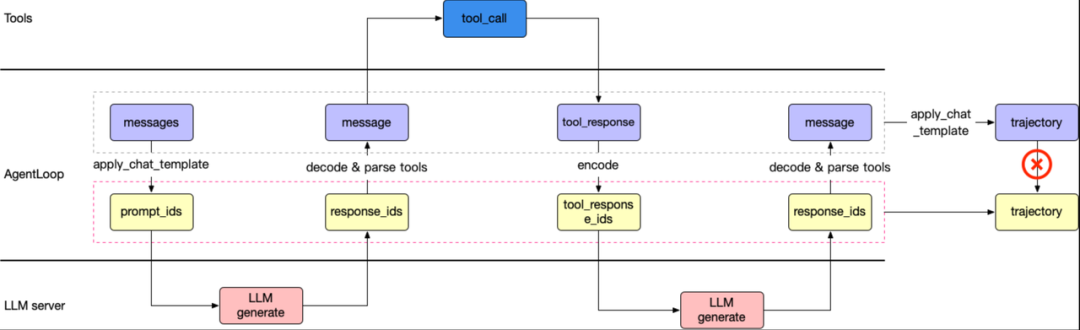
这种不一致发生在哪里呢?
因为解码-编码有很多情况不可逆,比如生成 ”helloworld” 的 token 可能有几种组合情况,但是根据 ”helloworld” 转成的 token 只有一种组合,可能跟原来的 token 不同。
所以 veRL 采用了 token in and token out 的方式,让 agent 调用 llm generate 方法时,输入和输出都使用 token,来避免 token 和明文消息互相转换不一致的问题。
使用 SGLang 和 FlashInfer 算子时,Qwen2.5 模型大概率不会调用工具
下面是该现象的一个例子:

推测跟 FlashInfer 精度有关,SGLang 支持的其他算子并没有这个现象,已经通过在 veRL 中固定使用 FlashAttention 来避免这个问题。
对 SGLang 支持的算子做了测试,具体情况见下表,目前只发现 FlashInfer 有这个现象。

更多问题和解决方案参考
LLM
问题 1:qwen3 有深度思考模式,倾向于文本推理,很少输出代码,所以训练效果不佳。
解决方案:按 ReTool 论文用的 qwen2.5-32b 来复现。
问题 2:使用 SGLang + FlashInfer 算子时,模型不会调用工具。
解决方案:跟 FlashInfer 精度有关,SGLang 支持的其他算子并没有这个现象,已经通过在 veRL 中固定使用 Flashatten3 来避免这个问题。
sandbox
问题:因为 sft 后模型的行为是生成交互式代码,最后一行是变量名,不包含 print 函数,导致不会返回代码输出。
解决方案:在输入给 code sandbox 前对代码做处理,自动在最后一行添加 print。
模型性能
问题 1:训练 100 步之后模型能力下降。
解决方案:这是 veRL 早期实现问题,在最新版本已经解决。该问题是因为 LLM 输出的是 text 明文,训练时转换成 token 后,跟原始的 token 有差异,导致训练精度不佳。原因是 token 和 text 的转换不可逆,比如
转换成 token 之后,跟原始的 token 不一致。
问题 2:遇到性能提升不上去时,有哪些方法能帮助定位问题?
解决方案:
1.因为训练的数据只能包含 LLM 自己生成的内容,不应该包含 tool 生成的,所以需要把 tool 生成的部分 mask 遮住后再训练,并且保证 token 级别一致。
2.配置 trainer.log_val_generations=10 参数可以打印测试集的输入和输出,用于判断模型能力变化。
3.tool 本身也有可能出错,可以打印出 tool 输出内容,看是否有异常。在训练过程中识别到了多个 sandbox fusion 的 bug,均已解决。
4.规划了 trace 功能,用于分析训练过程,观测 LLM 和 tool 输出。可以关注改功能开发进展:https://github.com/volcengine/verl/issues/2188
问题 3:如何提升 acc 的 tricks?
解决方案:修改写 Python 代码时候的提示词+对应修改答案提取方式,带来了可观的涨点。
修改前:
暂时无法在飞书文档外展示此内容
修改后:
暂时无法在飞书文档外展示此内容
想试试?从 veRL 开始
复现 ReTool 不是终点,而是起点 —— 用 ReTool+veRL,你可以让 LLM 在数据处理、逻辑推理、复杂计算等任务中更靠谱。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)