OpenAI Responses API 申请及使用
OpenAI 最近提供了一个创建模型响应的接口。提供文本或图像输入以生成文本或图像输出。让模型调用您自己的自定义代码或使用内置工具,如 web 搜索或文件搜索,以使用您自己的数据作为模型响应的输入。本文档主要介绍 OpenAI Responses API 操作的使用流程,利用它我们可以轻松使用官方 OpenAI 的创建模型响应功能。
OpenAI 最近提供了一个创建模型响应的接口。提供文本或图像输入以生成文本或图像输出。让模型调用您自己的自定义代码或使用内置工具,如 web 搜索或文件搜索,以使用您自己的数据作为模型响应的输入。
本文档主要介绍 OpenAI Responses API 操作的使用流程,利用它我们可以轻松使用官方 OpenAI 的创建模型响应功能。
申请流程
要使用 OpenAI Responses API,首先可以到 OpenAI Responses API 页面点击「Acquire」按钮,获取请求所需要的凭证:

如果你尚未登录或注册,会自动跳转到登录页面邀请您来注册和登录,登录注册之后会自动返回当前页面。
在首次申请时会有免费额度赠送,可以免费使用该 API。
基本使用
接下来就可以在界面上填写对应的内容,如图所示:
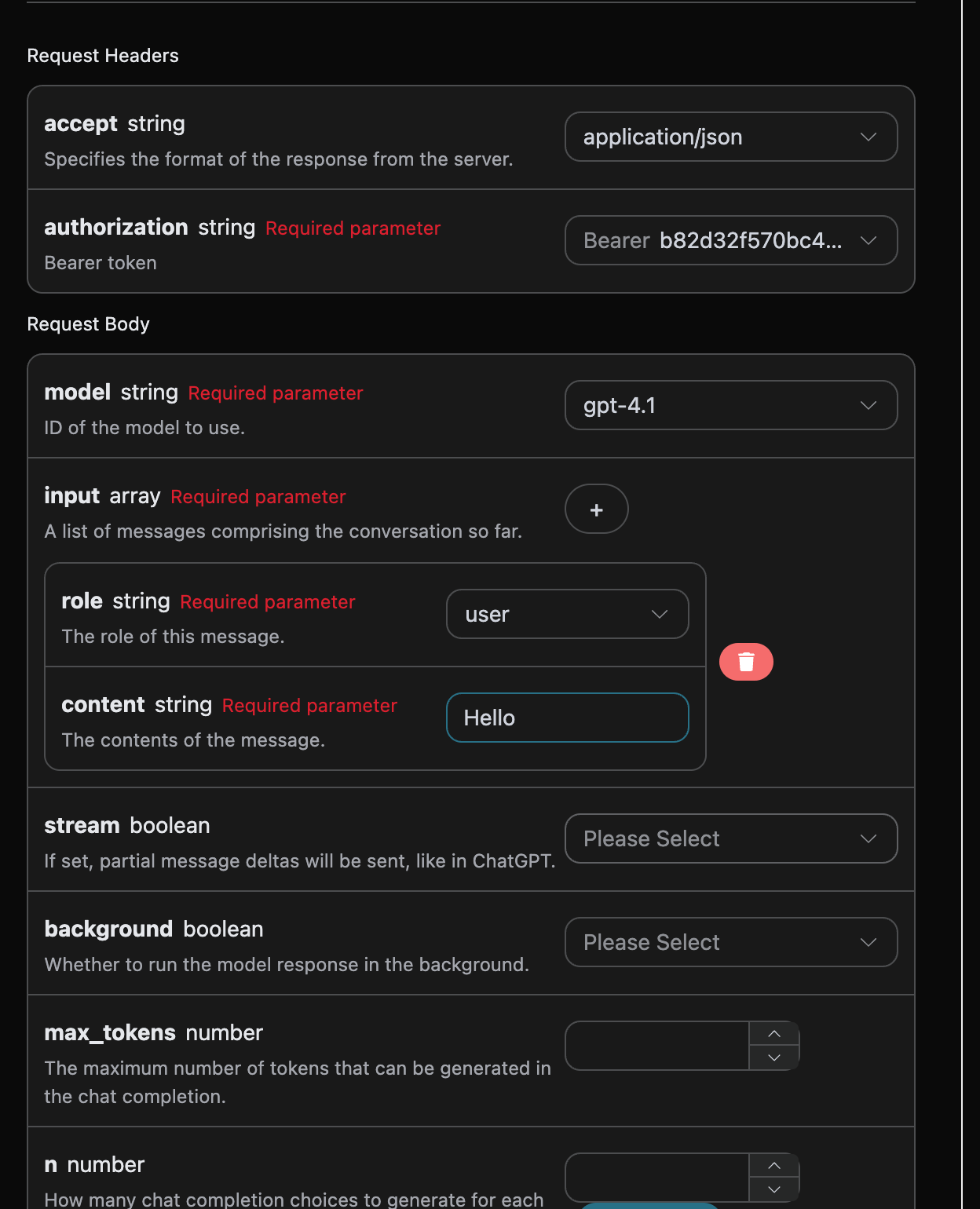
在第一次使用该接口时,我们至少需要填写三个内容,一个是 authorization,直接在下拉列表里面选择即可。另一个参数是 model, model 就是我们选择使用 OpenAI ChatGPT 官网模型类别,这里我们主要有 20 种模型,详情可以看我们提供的模型。最后一个参数是input,input是我们输入的提问词数组,它是一个数组,表示可以同时上传多个提问词,每个提问词包含了 role 和 content,其中 role 表示提问者的角色,我们提供了三种身份,分别为 user 、assistant、system 。另一个 content 就是我们提问的具体内容。
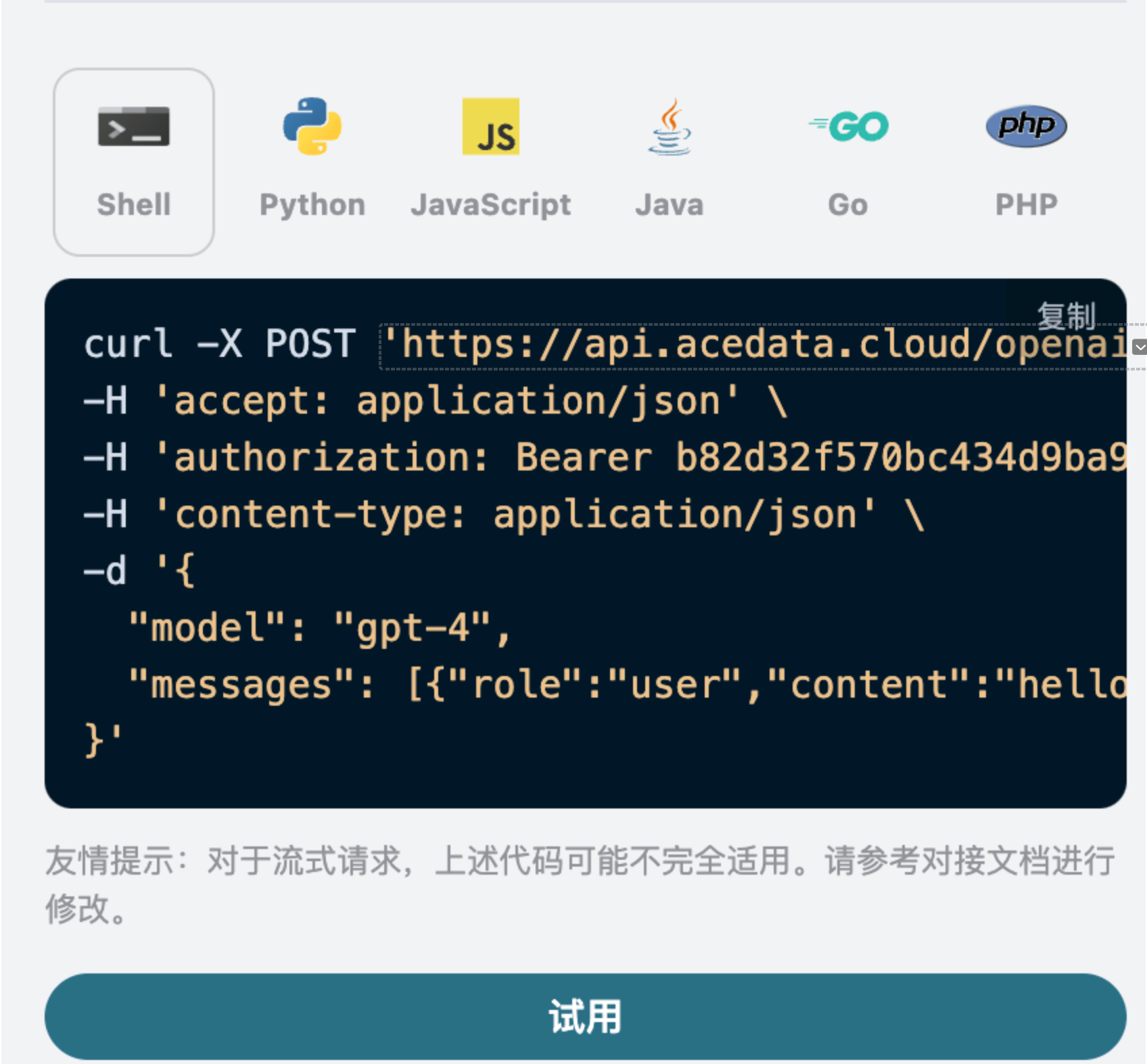
同时您可以注意到右侧有对应的调用代码生成,您可以复制代码直接运行,也可以直接点击「Try」按钮进行测试。
调用之后,我们发现返回结果如下:
json { "id": "resp_68a98322e3c88191a027de2711a02a490554cad0b36c0400", "object": "response", "created_at": 1755939618, "status": "completed", "background": false, "content_filters": null, "error": null, "incomplete_details": null, "instructions": null, "max_output_tokens": null, "max_tool_calls": null, "model": "gpt-4.1", "output": [ { "id": "msg_68a98323422c8191a7f383eea48ba5160554cad0b36c0400", "type": "message", "status": "completed", "content": [ { "type": "output_text", "annotations": [], "text": "Hello! How can I assist you today?" } ], "role": "assistant" } ], "parallel_tool_calls": true, "previous_response_id": null, "prompt_cache_key": null, "reasoning": { "effort": null, "summary": null }, "safety_identifier": null, "service_tier": "default", "store": true, "temperature": 1, "text": { "format": { "type": "text" } }, "tool_choice": "auto", "tools": [], "top_p": 1, "truncation": "disabled", "usage": { "input_tokens": 8, "input_tokens_details": { "cached_tokens": 0 }, "output_tokens": 10, "output_tokens_details": { "reasoning_tokens": 0 }, "total_tokens": 18 }, "user": null, "metadata": {} }
返回结果一共有多个字段,介绍如下:
id,生成此次对话任务的 ID,用于唯一标识此次对话任务。model,选择的 OpenAI ChatGPT 官网模型。output,ChatGPT 针对提问词给于的回答信息。usage:针对本次问答对 token 的统计信息。
其中 output 是包含了 ChatGPT 的回答信息,它里面的 output 是 ChatGPT,可以发现如图所示。
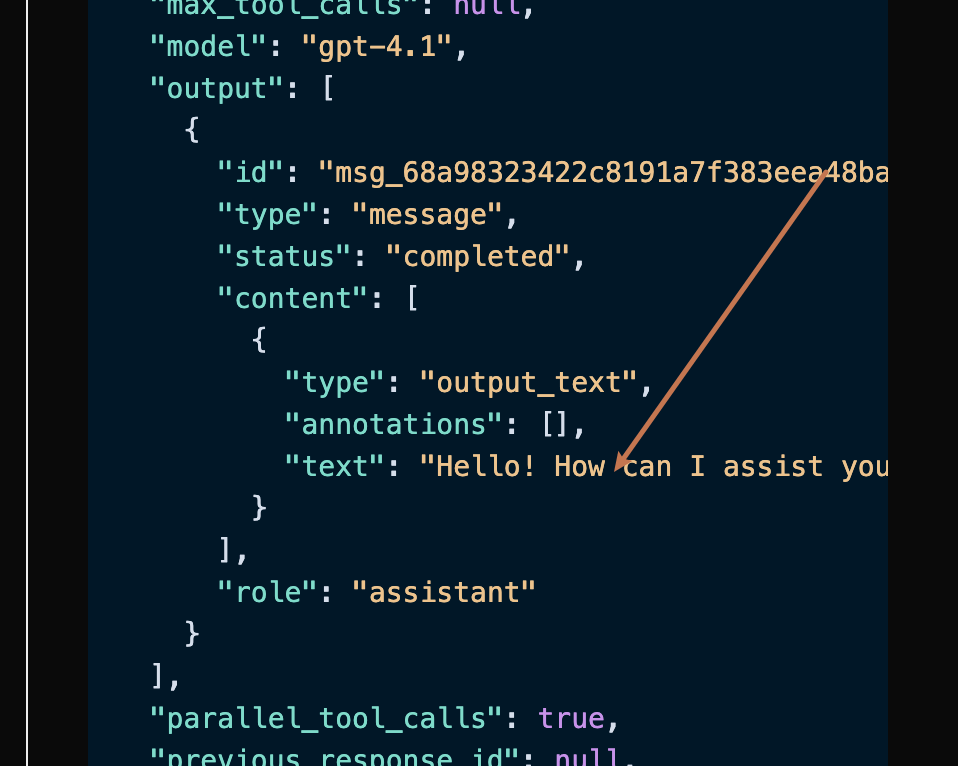
可以看到,output 里面的 content 字段包含了 ChatGPT 回复的具体内容。
流式响应
该接口也支持流式响应,这对网页对接十分有用,可以让网页实现逐字显示效果。
如果想流式返回响应,可以更改请求头里面的 stream 参数,修改为 true。
修改如图所示,不过调用代码需要有对应的更改才能支持流式响应。
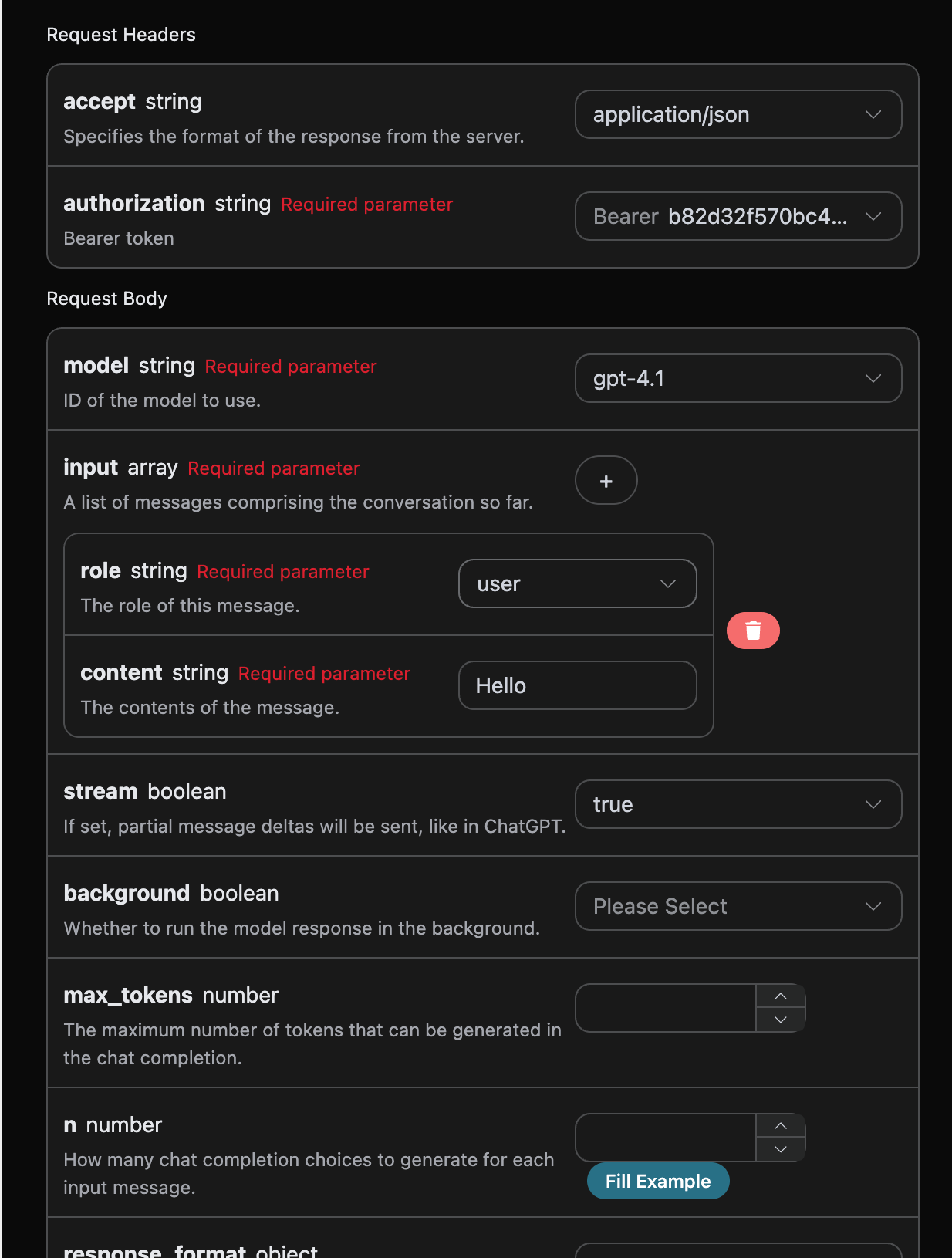
将 stream 修改为 true 之后,API 将逐行返回对应的 JSON 数据,在代码层面我们需要做相应的修改来获得逐行的结果。
Python 样例调用代码:
```python import requests
url = "https://api.acedata.cloud/openai/responses"
headers = { "accept": "application/json", "authorization": "Bearer {token}", "content-type": "application/json" }
payload = { "model": "gpt-4.1", "input": [{"role":"user","content":"Hello"}], "stream": True }
response = requests.post(url, json=payload, headers=headers) print(response.text) ```
输出效果如下:
```json data: {"type": "response.created", "sequence_number": 0, "response": {"id": "resp_68a9837bb9bc8190b403947311db6faa0721186e8fbb89d0", "object": "response", "created_at": 1755939707, "status": "in_progress", "background": false, "content_filters": null, "error": null, "incomplete_details": null, "instructions": null, "max_output_tokens": null, "max_tool_calls": null, "model": "gpt-4.1-data", "output": [], "parallel_tool_calls": true, "previous_response_id": null, "prompt_cache_key": null, "reasoning": {"effort": null, "summary": null}, "safety_identifier": null, "service_tier": "auto", "store": true, "temperature": 1.0, "text": {"format": {"type": "text"}}, "tool_choice": "auto", "tools": [], "top_p": 1.0, "truncation": "disabled", "usage": null, "user": null, "metadata": {}}, "model": "gpt-4.1"}
data: {"type": "response.in_progress", "sequence_number": 1, "response": {"id": "resp_68a9837bb9bc8190b403947311db6faa0721186e8fbb89d0", "object": "response", "created_at": 1755939707, "status": "in_progress", "background": false, "content_filters": null, "error": null, "incomplete_details": null, "instructions": null, "max_output_tokens": null, "max_tool_calls": null, "model": "gpt-4.1-data", "output": [], "parallel_tool_calls": true, "previous_response_id": null, "prompt_cache_key": null, "reasoning": {"effort": null, "summary": null}, "safety_identifier": null, "service_tier": "auto", "store": true, "temperature": 1.0, "text": {"format": {"type": "text"}}, "tool_choice": "auto", "tools": [], "top_p": 1.0, "truncation": "disabled", "usage": null, "user": null, "metadata": {}}, "model": "gpt-4.1"}
data: {"type": "response.output_item.added", "sequence_number": 2, "output_index": 0, "item": {"id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "type": "message", "status": "in_progress", "content": [], "role": "assistant"}, "model": "gpt-4.1"}
data: {"type": "response.content_part.added", "sequence_number": 3, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "part": {"type": "output_text", "annotations": [], "text": ""}, "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 4, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": "Hello", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 5, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": "!", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 6, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": " How", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 7, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": " can", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 8, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": " I", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 9, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": " help", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 10, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": " you", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 11, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": " today", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 12, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": "?", "model": "gpt-4.1"}
data: {"type": "response.output_text.delta", "sequence_number": 13, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "delta": " 😊", "model": "gpt-4.1"}
data: {"type": "response.output_text.done", "sequence_number": 14, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "text": "Hello! How can I help you today? 😊", "model": "gpt-4.1"}
data: {"type": "response.content_part.done", "sequence_number": 15, "item_id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "output_index": 0, "content_index": 0, "part": {"type": "output_text", "annotations": [], "text": "Hello! How can I help you today? 😊"}, "model": "gpt-4.1"}
data: {"type": "response.output_item.done", "sequence_number": 16, "output_index": 0, "item": {"id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "type": "message", "status": "completed", "content": [{"type": "output_text", "annotations": [], "text": "Hello! How can I help you today? 😊"}], "role": "assistant"}, "model": "gpt-4.1"}
data: {"type": "response.completed", "sequence_number": 17, "response": {"id": "resp_68a9837bb9bc8190b403947311db6faa0721186e8fbb89d0", "object": "response", "created_at": 1755939707, "status": "completed", "background": false, "content_filters": null, "error": null, "incomplete_details": null, "instructions": null, "max_output_tokens": null, "max_tool_calls": null, "model": "gpt-4.1-data", "output": [{"id": "msg_68a9837c49f081908f568bf9c6065c620721186e8fbb89d0", "type": "message", "status": "completed", "content": [{"type": "output_text", "annotations": [], "text": "Hello! How can I help you today? 😊"}], "role": "assistant"}], "parallel_tool_calls": true, "previous_response_id": null, "prompt_cache_key": null, "reasoning": {"effort": null, "summary": null}, "safety_identifier": null, "service_tier": "default", "store": true, "temperature": 1.0, "text": {"format": {"type": "text"}}, "tool_choice": "auto", "tools": [], "top_p": 1.0, "truncation": "disabled", "usage": {"input_tokens": 8, "input_tokens_details": {"cached_tokens": 0}, "output_tokens": 11, "output_tokens_details": {"reasoning_tokens": 0}, "total_tokens": 19}, "user": null, "metadata": {}}, "model": "gpt-4.1"}
```
可以看到,响应里面有许多 data ,data 里面的 delta 即为最新的回答内容,与上文介绍的内容一致。delta 是新增的回答内容,您可以根据结果来对接到您的系统中。同时流式响应的结束是根据 data 的内容来判断的,如果 type 的内容为 response.completed,则表示流式响应回答已经全部结束。返回的 data 结果一共有多个字段,介绍如下:
item_id,生成此次对话任务的 ID,用于唯一标识此次对话任务。type,生成此次对话 Responses 任务的类型。model,选择的 OpenAI ChatGPT 官网模型。delta,ChatGPT 针对提问词给于的回答信息。
JavaScript 也是支持的,比如 Node.js 的流式调用代码如下:
```javascript const options = { method: "post", headers: { accept: "application/json", authorization: "Bearer b82d32f570bc434d9ba9923aa0e7dce0", "content-type": "application/json", }, body: JSON.stringify({ model: "gpt-4.1", input: [{ role: "user", content: "Hello" }], stream: true, }), };
fetch("https://api.acedata.cloud/openai/responses", options) .then((response) => response.json()) .then((response) => console.log(response)) .catch((err) => console.error(err)); ```
Java 样例代码:
```java JSONObject jsonObject = new JSONObject(); jsonObject.put("model", "gpt-4.1"); jsonObject.put("input", [{"role":"user","content":"Hello"}]); jsonObject.put("stream", true); MediaType mediaType = "application/json; charset=utf-8".toMediaType(); RequestBody body = jsonObject.toString().toRequestBody(mediaType); Request request = new Request.Builder() .url("https://api.acedata.cloud/openai/responses") .post(body) .addHeader("accept", "application/json") .addHeader("authorization", "Bearer b82d32f570bc434d9ba9923aa0e7dce0") .addHeader("content-type", "application/json") .build();
OkHttpClient client = new OkHttpClient(); Response response = client.newCall(request).execute(); System.out.print(response.body!!.string()) ```
其他语言可以另外自行改写,原理都是一样的。
多轮对话
如果您想要对接多轮对话功能,需要对 input 字段上传多个提问词,多个提问词的具体示例如下图所示:
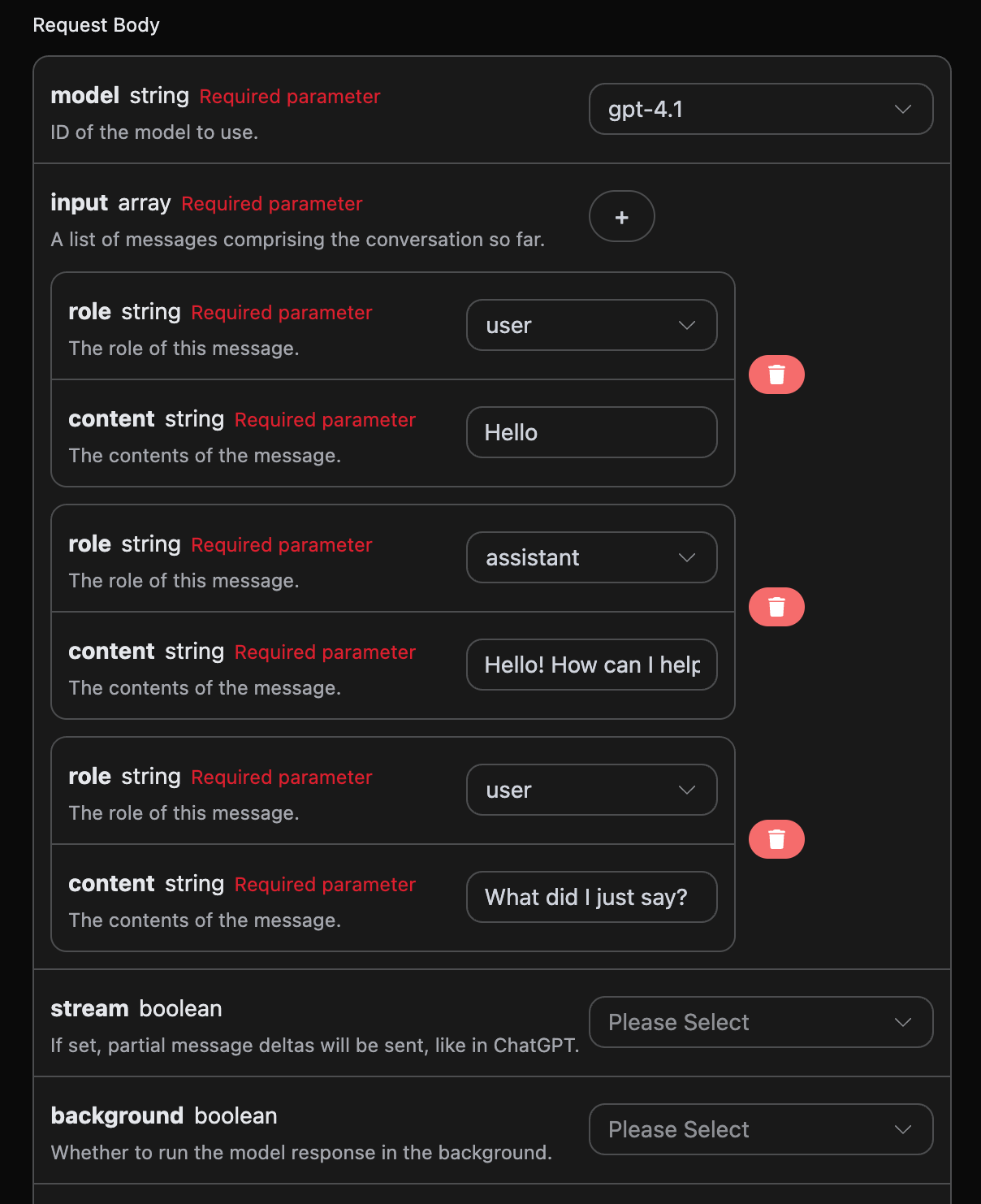
Python 样例调用代码:
```python import requests
url = "https://api.acedata.cloud/openai/responses"
headers = { "accept": "application/json", "authorization": "Bearer {token}", "content-type": "application/json" }
payload = { "model": "gpt-4.1", "input": [{"role":"user","content":"Hello"},{"role":"assistant","content":"Hello! How can I help you today? 😊"},{"role":"user","content":"What did I just say?"}] }
response = requests.post(url, json=payload, headers=headers) print(response.text) ```
通过上传多个提问词,就可以轻松实现多轮对话,可以得到如下回答:
json { "id": "resp_68a989c03c508191a1dd82ce2e37e88a0932a4328c0a5d5b", "object": "response", "created_at": 1755941312, "status": "completed", "background": false, "content_filters": null, "error": null, "incomplete_details": null, "instructions": null, "max_output_tokens": null, "max_tool_calls": null, "model": "gpt-4.1", "output": [ { "id": "msg_68a989c092e4819189821a9eb8247e1e0932a4328c0a5d5b", "type": "message", "status": "completed", "content": [ { "type": "output_text", "annotations": [], "text": "You just said \"Hello.\" \n\nWould you like to continue the conversation or ask a question?" } ], "role": "assistant" } ], "parallel_tool_calls": true, "previous_response_id": null, "prompt_cache_key": null, "reasoning": { "effort": null, "summary": null }, "safety_identifier": null, "service_tier": "default", "store": true, "temperature": 1, "text": { "format": { "type": "text" } }, "tool_choice": "auto", "tools": [], "top_p": 1, "truncation": "disabled", "usage": { "input_tokens": 32, "input_tokens_details": { "cached_tokens": 0 }, "output_tokens": 20, "output_tokens_details": { "reasoning_tokens": 0 }, "total_tokens": 52 }, "user": null, "metadata": {} }
可以看到,output 包含的信息与基本使用的内容是一致的,这个包含了 ChatGPT 针对多个对话进行回复的具体内容,这样就可以根据多个对话内容来回答对应的问题了。
视觉模型
gpt-4o 是 OpenAI 开发的多模态大型语言模型,它在 GPT-4 的基础上增加了视觉理解能力。这个模型可以同时处理文本和图像输入,实现了跨模态的理解和生成。
使用 gpt-4o 模型的文本处理是与上文的基本使用内容一致的,下面将简要介绍一下如果使用模型的图像处理能力。
使用 gpt-4o 模型的图像处理能力主要是通过在原有的 content 内容基础上添加一个 type 字段,通过该字段可以知道上传的是文本还是图片,从而使用 gpt-4o 模型的图像处理能力,下面主要讲述采用 Curl 和 Python 俩种方式来调用该功能。
- Curl 脚本方式
curl -X POST 'https://api.acedata.cloud/openai/responses' \ -H 'accept: application/json' \ -H 'authorization: Bearer {token}' \ -H 'content-type: application/json' \ -d '{ "model": "gpt-4.1", "input": [ { "role": "user", "content": [ {"type": "input_text", "text": "what is in this image?"}, { "type": "input_image", "image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg" } ] } ] }'
- Python 脚本方式
```python import requests
url = "https://api.acedata.cloud/openai/chat/completions"
headers = { "accept": "application/json", "authorization": "Bearer {token}", "content-type": "application/json" }
payload = { "model": "gpt-4.1", "input": [ { "role": "user", "content": [ {"type": "input_text", "text": "what is in this image?"}, { "type": "input_image", "image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg" } ] } ] }
response = requests.post(url, json=payload, headers=headers) print(response.text) ```
然后可以得到下面的结果,结果里面的字段信息是与上文一致的,具体的如下:
json { "id": "resp_68a98c1bb784819e9b9f622007a2d37602483949012d2193", "object": "response", "created_at": 1755941915, "status": "completed", "background": false, "content_filters": null, "error": null, "incomplete_details": null, "instructions": null, "max_output_tokens": null, "max_tool_calls": null, "model": "gpt-4.1", "output": [ { "id": "msg_68a98c1dd030819e97fb71e6ee33f5a902483949012d2193", "type": "message", "status": "completed", "content": [ { "type": "output_text", "annotations": [], "text": "This image shows a scenic path, possibly a boardwalk, running through a lush green field or meadow. The sky above is bright blue with some white clouds, and there are green trees and bushes in the background. It looks like a peaceful nature scene, possibly in a park, wetland, or prairie area. The image conveys a sense of tranquility and natural beauty." } ], "role": "assistant" } ], "parallel_tool_calls": true, "previous_response_id": null, "prompt_cache_key": null, "reasoning": { "effort": null, "summary": null }, "safety_identifier": null, "service_tier": "default", "store": true, "temperature": 1, "text": { "format": { "type": "text" } }, "tool_choice": "auto", "tools": [], "top_p": 1, "truncation": "disabled", "usage": { "input_tokens": 1118, "input_tokens_details": { "cached_tokens": 0 }, "output_tokens": 75, "output_tokens_details": { "reasoning_tokens": 0 }, "total_tokens": 1193 }, "user": null, "metadata": {} }
可以看到回答的内容是基于图片进行回答的,因此通过上述俩种方式可以轻松使用 gpt-4.1 模型的文本和图像处理能力。
除了,gpt-4.1,还有一个更低成本的模型,叫做 gpt-4o-mini。gpt-4o-mini 是 OpenAI 开发的最新一代大型语言模型,它不仅响应速度快,同时价格也更便宜,也支持多模态。vision 功能的使用可参考上文 gpt-4.1 模型的使用的内容。
文件处理模型的创建
请求样例:
json { "model": "gpt-4.1", "input": [ { "role": "user", "content": [ { "type": "input_text", "text": "what is in this file?" }, { "type": "input_file", "file_url": "https://www.berkshirehathaway.com/letters/2024ltr.pdf" } ] } ] }
样例结果:
json { "id": "resp_68a98d7bb57c819ba25424f5f50a29a300a1af2af822e88a", "object": "response", "created_at": 1755942267, "status": "completed", "background": false, "content_filters": null, "error": null, "incomplete_details": null, "instructions": null, "max_output_tokens": null, "max_tool_calls": null, "model": "gpt-4.1", "output": [ { "id": "msg_68a98d7d9b80819b9b0f09b7bcd00bf900a1af2af822e88a", "type": "message", "status": "completed", "content": [ { "type": "output_text", "annotations": [], "text": "The file you posted contains the **2024 annual letter to shareholders from Berkshire Hathaway Inc.**, written by Warren E. Buffett, Chairman of the Board. This document is a comprehensive communication that is typically included in Berkshire's annual report to shareholders.\n\n### What's Inside the File:\n\n#### 1. **Chairman's Letter to Shareholders**\n - **Introduction & Philosophy:** Warren Buffett discusses the purpose of the annual report, Berkshire Hathaway’s communication style, and his philosophy for transparency and candid discussion of both successes and failures.\n - **Discussion of Mistakes:** He talks openly about the mistakes made in capital allocation and personnel decisions, emphasizing the importance of admitting errors and acting promptly to correct them.\n - **Succession Comments:** Buffett references his eventual retirement, and that Greg Abel will succeed him as CEO and writer of these letters.\n - **Anecdotal Story:** The story of Pete Liegl, founder of Forest River (an RV manufacturer acquired by Berkshire), is told to illustrate management philosophy and business decision-making.\n\n#### 2. **2024 Business and Financial Performance**\n - **Key Results:** Summary of how Berkshire performed financially in 2024 vs. 2023, including operating earnings breakdown by business segments such as insurance, BNSF railroad, and energy.\n - **Insurance Business:** GEICO and the property-casualty insurance division had a standout year, with commentary on the industry and how Berkshire approaches insurance risk, pricing, and investment of insurance \"float.\"\n - **Investments:** Discussion on Berkshire’s strategy of owning both full businesses and partial stakes (marketable securities) in large companies (e.g., Apple, American Express, Coca-Cola), and its deployment of cash.\n - **Taxes:** Reference to Berkshire breaking records in corporate tax payments ($26.8 billion to the IRS in 2024).\n\n#### 3. **Long-term Philosophy & Capitalism Commentary**\n - **On Equities:** Buffett explains why Berkshire prioritizes ownership of businesses (equities) over cash or bonds, and why the company favors long-term investments.\n - **On Capitalism:** There’s a reflection on America’s growth, the role of capitalism, savings, and capital allocation in the nation’s success, and a nod to the importance of maintaining a stable currency.\n\n#### 4. **Japanese Investments**\n - **Update on Japanese Holdings:** Berkshire’s growing investments in five Japanese trading companies, and the positive view of their management and governance.\n\n#### 5. **Berkshire Hathaway Annual Meeting**\n - **Annual Gathering Info:** Details about the annual meeting in Omaha, including social events, book sales, and charitable initiatives related to the meeting.\n - **Personal Stories:** Personal anecdotes involving Buffett’s family, (including his sister Bertie), to add a human touch to the letter.\n\n#### 6. **Performance Tables**\n - **Berkshire vs S&P 500 (1965-2024):** Two detailed tables showing annual percentage change in Berkshire’s share price vs. total return for the S&P 500, as well as long-term compounded and overall gains.\n\n---\n\n### In Summary\n\nThis file is the **2024 Berkshire Hathaway annual letter to shareholders**, primarily written by Warren Buffett. It covers business performance, management philosophy, investment strategy, earnings and taxes, insurance operations, significant holdings, capital allocation, succession updates, and more. Tables show a remarkable outperformance of Berkshire Hathaway vs. the S&P 500 over nearly six decades – a central point of pride in the letter.\n\nIf you want specifics from any particular section, let me know!" } ], "role": "assistant" } ], "parallel_tool_calls": true, "previous_response_id": null, "prompt_cache_key": null, "reasoning": { "effort": null, "summary": null }, "safety_identifier": null, "service_tier": "default", "store": true, "temperature": 1, "text": { "format": { "type": "text" } }, "tool_choice": "auto", "tools": [], "top_p": 1, "truncation": "disabled", "usage": { "input_tokens": 8438, "input_tokens_details": { "cached_tokens": 0 }, "output_tokens": 731, "output_tokens_details": { "reasoning_tokens": 0 }, "total_tokens": 9169 }, "user": null, "metadata": {} }
可以看到,我们对输入的文件也进行了处理文件,结果与上文类似。
错误处理
在调用 API 时,如果遇到错误,API 会返回相应的错误代码和信息。例如:
400 token_mismatched:Bad request, possibly due to missing or invalid parameters.400 api_not_implemented:Bad request, possibly due to missing or invalid parameters.401 invalid_token:Unauthorized, invalid or missing authorization token.429 too_many_requests:Too many requests, you have exceeded the rate limit.500 api_error:Internal server error, something went wrong on the server.
错误响应示例
{ "success": false, "error": { "code": "api_error", "message": "fetch failed" }, "trace_id": "2cf86e86-22a4-46e1-ac2f-032c0f2a4e89" }
结论
通过本文档,您已经了解了如何使用 OpenAI Responses API 轻松实现官方 OpenAI 的创建 Responses 功能。希望本文档能帮助您更好地对接和使用该 API。如有任何问题,请随时联系我们的技术支持团队。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 35
35 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)