Claude Code:极简架构 + 万字提示词 = 最强开发者智能体?
所以,Claude Code 的“强得离谱”究竟从何而来?答案就藏在那些看似“笨拙”的选择里:用一个主循环对抗多智能体的混乱,用小模型分担大模型的重负,用ripgrep代替复杂的 RAG,甚至用“IMPORTANT”大吼来约束模型的任性。它没有追求技术的炫目,而是回归了工程的本质——用最简单的架构,解决最复杂的问题。它让开发者从写测试、改 bug 的泥潭中挣脱,得以将宝贵的脑力投入到真正的架构与创
Claude Code 凭借极简架构与精妙提示词,为开发者带来“愉悦感”十足的编程体验。本文探索其设计哲学,揭示“强得离谱”背后的工程智慧。

Claude Code 各版本更新一目了然
大家好,我是肆〇柒。今天要和大家聊的,是让无数开发者直呼“强得离谱”的 AI 编程助手——Claude Code。它究竟凭什么能提供如此“愉悦”的体验,甚至超越 Cursor 和 GitHub Copilot?
在众多 AI 编程助手的激烈角逐中,Claude Code 脱颖而出,被许多开发者誉为“最令人愉悦的 AI 智能体/工作流”。有用户坦言,使用它一个多月,开发效率提升了至少 60%,得以将精力从琐碎工作如写测试、改 bug 中解放出来,专注于架构设计。甚至有人直言其能力“远超 Cursor”,是小型项目的效率利器。
那么,究竟是什么让它如此“强得离谱”,创造出浑然一体、对新手友好的使用体验?其背后的“魔法”能否被复制?基于 MinusX 团队的深度分析,我们一起探索一下 Claude Code 的成功秘诀。
核心哲学——“Keep Things Simple, Dummy” (KISS 原则)
Claude Code 的卓越并非源于复杂的架构,而是对“简单性”的极致追求。其核心设计哲学是“保持简单”,认为任何额外的复杂性都会让本就难以调试的 LLM(Large Language Model)系统变得更加脆弱。在架构上,它摒弃了时下流行的多智能体系统,坚持使用单一的主控制循环和扁平的消息历史,这极大地简化了调试过程。
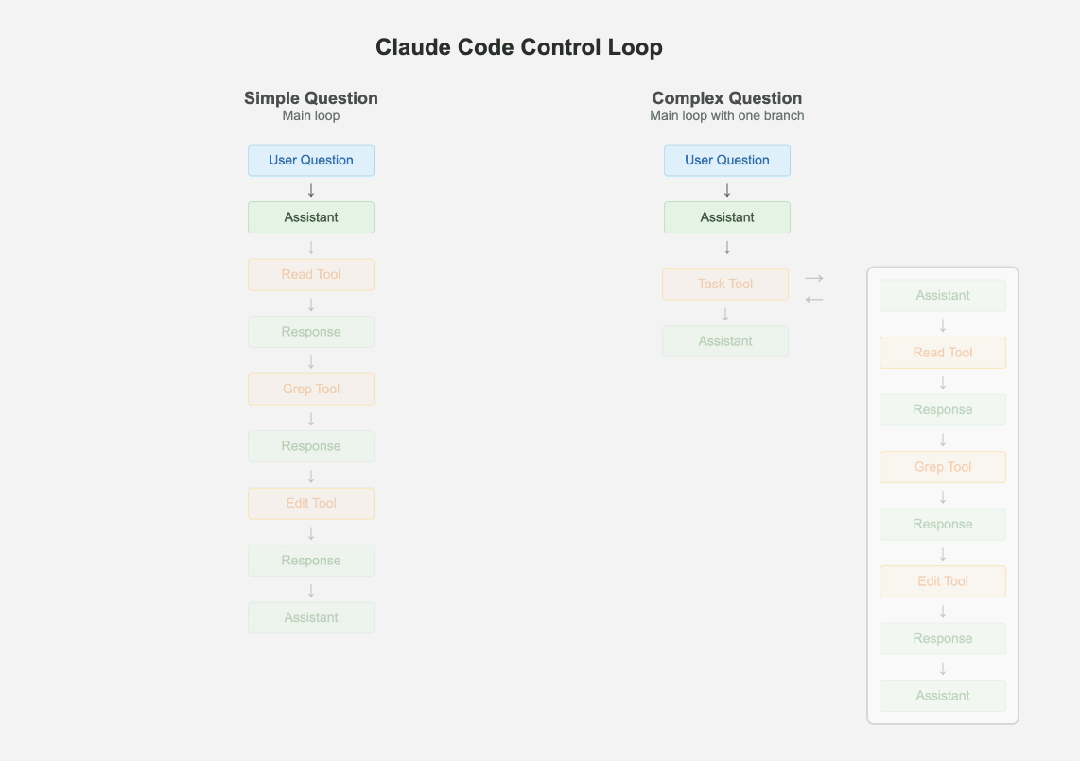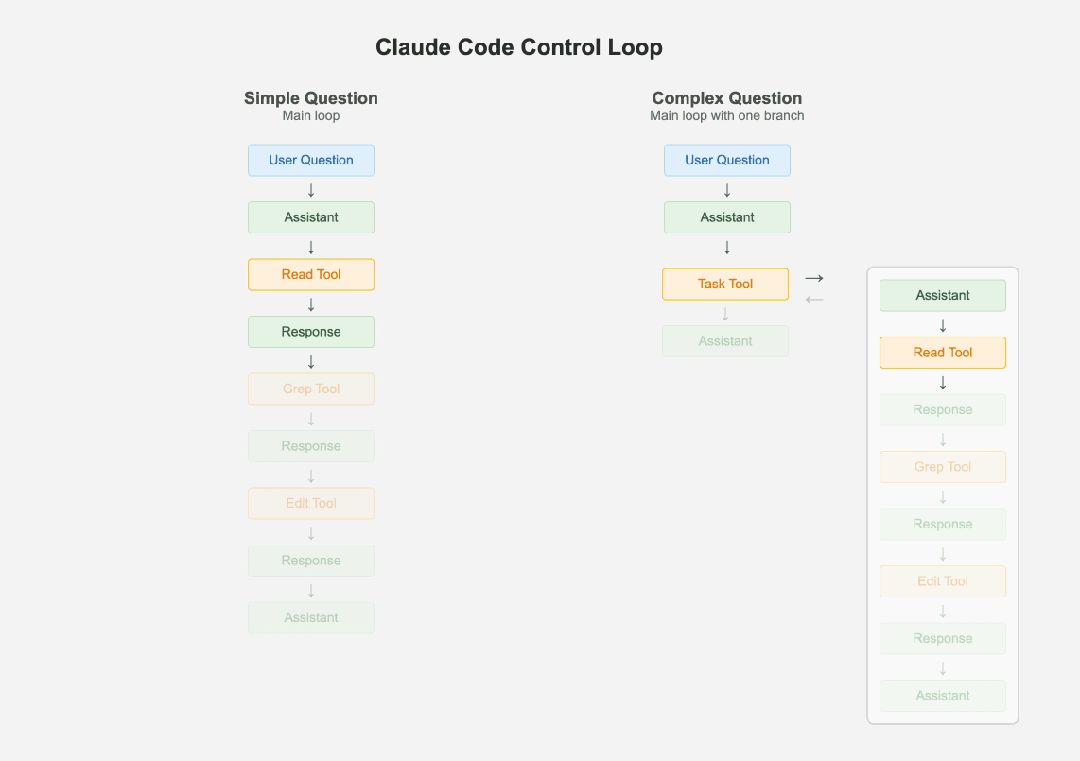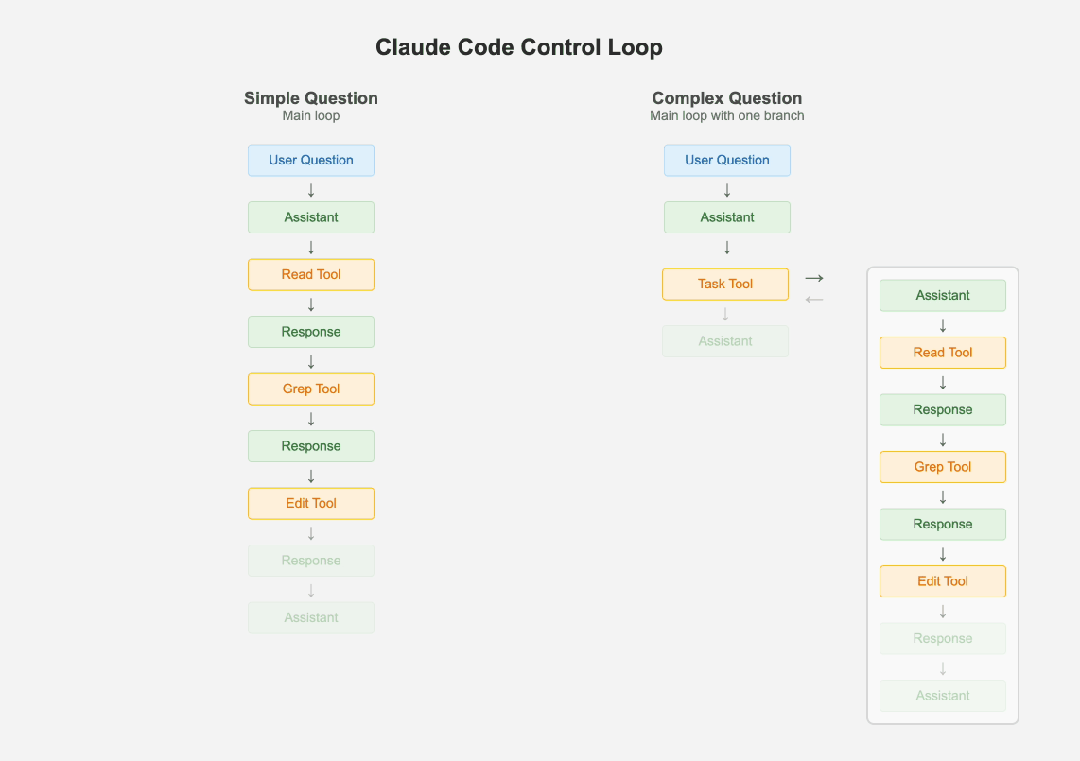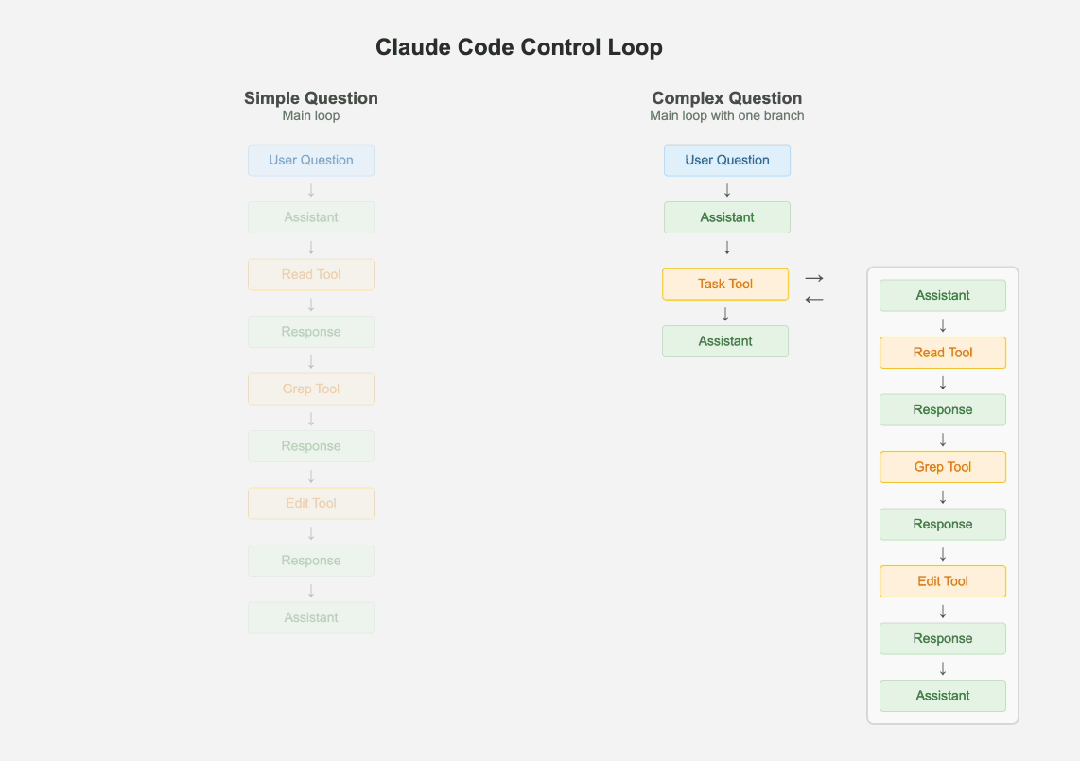
Control Loop
当遇到复杂任务时,它并非引入多个独立智能体,而是创建自身的“子智能体”来处理,且严格限制分支深度,确保最终结果能无缝整合回主流程。这种设计巧妙地平衡了任务分解的灵活性与系统稳定性的需求。在成本与效率优化上,Claude Code 大量依赖小型、低成本模型。
数据显示,超过 50% 的重要 LLM 调用都使用了 claude-3-5-haiku 这样的小模型,用于读取大文件、解析网页、处理 Git 历史或总结长对话。想象一下,一个顶级大厨(主模型)只负责最关键的烹饪,而洗菜、切配、打扫等繁杂工作都交给高效的助手(小模型)完成。这不仅带来了约 70-80% 的成本骤降(相比 Sonnet 4 或 GPT-4.1 等标准模型),更重要的是,它解放了主模型的“脑力”,使其能专注于最需要创造力的核心任务,从而保证了整体体验的流畅与高效。这种对简单性的坚持,被作者类比为 AI 领域的“Bitter Lesson”(苦涩的教训),即相信通用模型的能力,而非过度工程化的复杂系统。
构建基石——精心设计的提示词 (Prompts)
Claude Code 的“智能”很大程度上是其庞大且结构化提示词精心引导的结果。这些提示词长达上万 Token,如同一份详尽的操作手册,旨在弥补模型的短板并放大其优势。其中,claude.md 文件扮演着至关重要的角色。这个位于项目根目录的特殊文件,会在每次对话时被自动加载,用于记录项目背景、常用命令、代码规范和团队偏好。它的存在,使得 Claude Code 能够“记住”项目的独特上下文,从而提供高度定制化的服务,其表现有无 claude.md 可谓天壤之别。为了使如此庞大的指令集清晰有效,Claude Code 广泛采用了 XML 标签(如 <system-reminder>、<good-example>、<bad-example>)和 Markdown 标题来组织内容。这种结构化方式,相当于为模型绘制了一张清晰的地图,帮助它在复杂的决策点上选择最优路径。
例如,在指导模型如何执行测试时,提示词中会明确给出正反示例:
<good-example>
pytest /foo/bar/tests
</good-example>
<bad-example>
cd /foo/bar && pytest tests
</bad-example>这种具体到命令行的对比,有效引导模型养成使用绝对路径、避免不必要 cd 操作的良好习惯,将抽象的“最佳实践”转化为可执行的“行为准则”。
能力延伸——强大且易用的工具 (Tools)
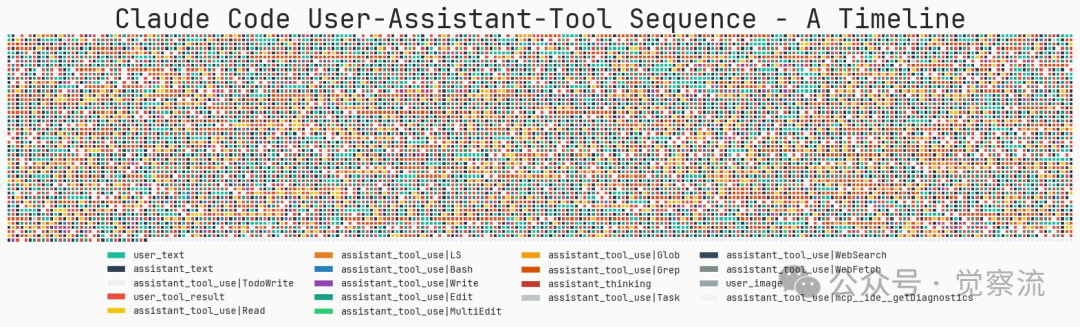
最常用的工具是“编辑”,其次是“阅读”和“待办写入”
工具是 Claude Code 将意图转化为行动的桥梁,其设计策略是“让模型做擅长的事”。一个显著的创新是它摒弃了复杂的检索增强生成 (RAG) 技术,转而采用“LLM 搜索”。这意味着它像人类开发者一样,直接使用 ripgrep、jq 和 find 等命令行工具在代码库中进行搜索。当其他智能体还在为 RAG 的“相似度函数选哪个?”、“代码块怎么切分?”这些隐藏的失败模式而头疼时,Claude Code 选择了一条更“笨”却更可靠的路——像人类开发者一样思考。
它直接调用 ripgrep 和 jq,让 LLM 自己决定看哪十行代码。这不仅避免了 RAG 引入的复杂性和不确定性,更让整个搜索过程变得可预测、可调试,就像开发者自己在终端敲命令一样自然。作者甚至将其比作“LLM 时代的摄像头与激光雷达之争”,暗示简单直接的方案往往更胜一筹。在工具层级上,Claude Code 提供了从低级(Bash, Read, Write)到中级(Edit, Grep, Glob)再到高级(WebFetch, TodoWrite)的完整工具链。这种分层设计非常务实:高频操作如搜索和文件编辑被封装成专用工具以保证准确率。从这张工具调用频率图中,我们可以窥见 Claude Code 的“工作日常”。Edit 工具的调用次数一骑绝尘,这印证了其核心价值——精准、高效地修改代码。紧随其后的是 Read 和 ToDoWrite,前者是它“阅读”代码库的眼睛,后者则是它“管理思维”的大脑。这三个工具构成了 Claude Code 最核心的工作流闭环。尤为关键的是其“待办事项列表”(Todo List)功能,通过 TodoWrite 和 TodoRead 工具,模型可以自主管理任务列表。这不仅有效对抗了长对话中常见的“上下文腐烂”问题,还能让模型在执行过程中动态调整计划,保持对最终目标的聚焦。
用户体验——精雕细琢的可引导性 (Steerability)
Claude Code 之所以“感觉”好用、专业且不啰嗦,源于其对智能体行为美学和可靠性的精细控制。在系统提示词中,有专门的章节(如“语气和风格”、“主动性”)来规定交互方式。它被明确要求避免不必要的开场白或总结,除非用户主动要求;禁止在无法帮助时进行说教;并且严格限制表情符号的使用,仅在用户明确请求时才可使用。然而,引导模型并非总是优雅的。
当前技术下,要让模型坚决避免某些行为,最有效的方式依然是使用“THIS IS IMPORTANT”、“NEVER”等强提示词。当然,引导一个 LLM 有时就像在教一个天才但又有点叛逆的学生。即使你苦口婆心地讲道理,它可能还是会我行我素。于是,Claude Code 的提示词里也不得不充斥着“PLEASE THIS IS IMPORTANT”和“NEVER”这样的“大吼大叫”。作者在文中无奈地标注“tch-tch”,并承认这“不幸地仍然是 State of the Art”。这不仅是 Claude Code 的“小秘密”,也是当前整个行业的“小尴尬”——我们仍在用最笨的方法,解决最前沿的问题。为了进一步结构化决策过程,Claude Code 在“任务管理”、“执行任务”和“工具使用政策”等部分,为模型编写了清晰的“算法”流程。
这些流程辅以大量的启发式规则和正反示例,将复杂的决策转化为一步步的指令,有效避免了因提示词冲突而导致的模型行为不稳定。
为何关注大厂提示词设计?
分析 Claude Code 这样的大厂产品,其价值在于为我们理解行业最佳实践和模型能力边界提供了宝贵的参考。它的设计是高度“意见化”的,从数据格式(XML/Markdown)到状态管理(单一循环),都体现了其对“什么有效”的深刻理解。开发者可以从中汲取灵感,用于指导自己的应用设计。
Claude Code 的成功有力地证明,一个架构简单、配合强大模型和精心调校提示词的系统,足以创造出极其强大且用户体验极佳的工具。它提醒我们,在追求技术创新的同时,不应忽视“简单”的力量。展望未来,随着模型自身可引导性的提升,我们有望告别对“IMPORTANT”等笨拙提示词的依赖,迎来更自然、更强大的人机协作新时代。
总结一下
所以,Claude Code 的“强得离谱”究竟从何而来?答案就藏在那些看似“笨拙”的选择里:用一个主循环对抗多智能体的混乱,用小模型分担大模型的重负,用 ripgrep 代替复杂的 RAG,甚至用“IMPORTANT”大吼来约束模型的任性。它没有追求技术的炫目,而是回归了工程的本质——用最简单的架构,解决最复杂的问题。它让开发者从写测试、改 bug 的泥潭中挣脱,得以将宝贵的脑力投入到真正的架构与创新中。这或许就是它让人“感觉”如此愉悦的终极技巧:它不是一个冰冷的工具,而是一个真正懂你、帮你、让你能“Happy Coding”的伙伴。正如 MinusX 团队所感慨的:Claude Code 真正让人相信,一个“智能体”可以既简单又极其强大。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献245条内容
已为社区贡献245条内容

所有评论(0)