一文搞懂如何用 QLoRA 高效微调大语言模型
随着大语言模型规模不断增长,显存瓶颈成为微调大模型的最大难题。QLoRA(Quantized LoRA)作为结合了量化技术和低秩微调的创新方案,极大降低了显存占用,实现了资源有限设备上对超大模型的高效微调。
·
📚 微调系列文章
一文了解微调技术的发展与演进
一文搞懂 LoRA 如何高效微调大模型
LoRA详细步骤解析
随着大语言模型规模不断增长,显存瓶颈成为微调大模型的最大难题。
QLoRA(Quantized LoRA)作为结合了量化技术和低秩微调的创新方案,极大降低了显存占用,实现了资源有限设备上对超大模型的高效微调。
在深入了解 QLoRA 之前,我们可以带着这三个问题来读本文:
- 传统 LoRA 面临哪些显存和计算挑战?
- QLoRA 如何通过量化结合低秩适配实现显存节省?
- 采用 QLoRA 微调时,需要注意哪些技术细节和应用场景?
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、背景与挑战
LoRA 通过低秩分解减少微调参数,大幅降低训练资源需求,但面对超大模型(百亿参数及以上)时,显存仍然紧张。
这是因为:
- 大模型原始权重和激活仍占用大量显存;
- 传统 16/32 位浮点训练难以在单卡或小规模集群上运行。
为此,社区尝试引入量化技术,将模型权重压缩至更低比特表示,减少显存占用。
QLoRA 正是将 LoRA 和 4-bit 量化完美结合,兼顾微调灵活性和显存优化。
二、QLoRA 的核心技术原理
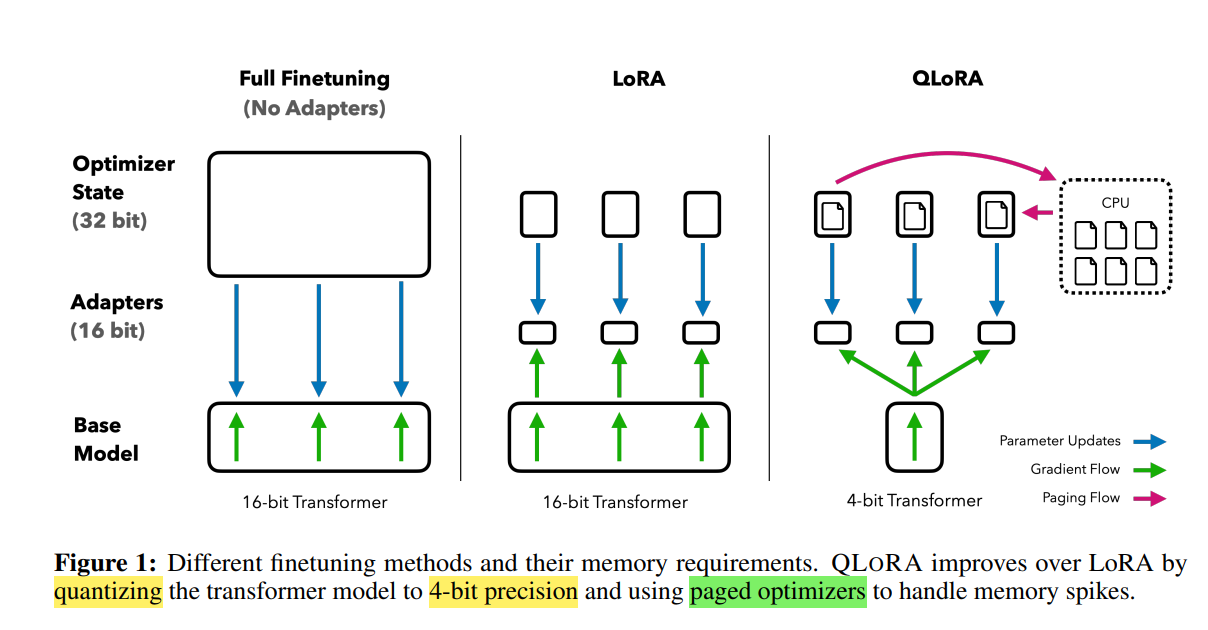
QLoRA 基于以下两大技术点:
- 4-bit 权重量化
利用如 SmoothQuant、GEMMLOWP 等先进量化方法,将预训练模型的权重压缩到 4-bit 表示,显存占用减少约4倍,且对精度影响极小。
这种量化支持混合精度推理和训练,有效缓解硬件瓶颈。
# 1. 加载 4-bit 量化模型
model = AutoModelForCausalLM.from_pretrained(
"huggingface/llama-7b",
load_in_4bit=True,
device_map="auto",
quantization_config={
"bnb_4bit_compute_dtype": "float16",
"bnb_4bit_use_double_quant": True,
"bnb_4bit_quant_type": "nf4"
}
)
- 低秩增量微调(LoRA)
在量化模型基础上,继续使用 LoRA 低秩矩阵 A,B 对权重增量进行微调。
由于只微调小量参数,训练过程的显存开销更小。
# 2. 配置 LoRA 微调
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
- 分页优化(Paged Optimizer)
引入分页优化机制,将优化器状态和梯度按页(page)分块管理,避免一次性加载全部数据到显存。
通过分页技术,训练过程中显存占用更加均衡且可控,进一步降低显存峰值,提升训练大模型的稳定性和效率。
# 3. 配置分页优化器
optimizer = PagedAdamW(
model.parameters(),
lr=2e-5
)
结合这几点,QLoRA 能在极低显存下完成超大模型微调,且训练效果接近全精度微调。
三、QLoRA 训练流程简介
- 模型权重量化
将原始预训练权重量化为 4-bit 表示,同时保持关键层激活的高精度,以保证模型稳定。 - 冻结量化权重
量化权重保持不变,冻结所有原始参数,避免反向传播计算量激增。 - 添加 LoRA 低秩适配器
在关键线性层插入 LoRA 低秩矩阵,作为可训练增量。 - 训练 LoRA 参数
仅训练 LoRA 模块的 A,B 矩阵参数,极大减少训练显存和计算资源。 - 推理阶段
结合量化权重和 LoRA 增量,支持快速推理,无需额外合并步骤。
四、QLoRA 的优势与适用场景
- 显存消耗极低
支持在单张 24GB 显卡(如 RTX 3090)甚至更低配置上微调百亿级大模型。 - 训练效率高
结合量化与低秩微调,减少计算资源浪费,训练速度更快。 - 性能几乎无损
在多个下游任务上,QLoRA 微调模型表现与全精度微调接近,且泛化能力良好。 - 灵活性强
适合多任务训练和多模型快速切换,极大节省存储空间。
五、应用建议与技术要点
- 量化细节需注意
4-bit 量化方法要选择精度与效率平衡的方案,如 SmoothQuant,避免训练不稳定。 - 低秩大小 r 的调优
结合任务复杂度与硬件资源,合理设置 LoRA 秩大小,保证训练性能。 - 混合精度训练支持
推荐采用 FP16 或 FP8 混合精度,进一步优化显存和吞吐量。 - 训练框架兼容
当前 Hugging Face PEFT 已集成 QLoRA,支持快速部署和实验。
最后我们回答一下文章开头提出的三个问题:
- 传统 LoRA 的挑战是什么?
主要是大模型权重和激活显存占用仍然较大,限制了微调规模。 - QLoRA 如何实现显存节省?
通过将预训练权重量化至 4-bit,结合 LoRA 低秩增量微调,极大降低显存消耗。 - 使用 QLoRA 需要注意什么?
需关注量化方法的稳定性、LoRA 秩大小调优及混合精度训练配置。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)