VOC、COCO、YOLO、YOLO OBB格式的介绍
PASCAL VOC (XML格式)
在计算机视觉中,PASCAL VOC 数据集格式是进行目标检测任务时非常常见的一种标注格式。它使用 XML 文件来存储图像中目标的位置和类别信息
文件结构
VOC2012/
├── Annotations/ # 存放与 JPEGImages 文件夹中图像一一对应的 XML 标注文件。
├── JPEGImages/ # 存放所有原始图像文件
└── ImageSets/Main/ # 存放用于训练、验证和测试的图像列表文件train.txt、val.txt 和 test.txt
xml格式
<annotation>
<folder>VOC2007</folder>
<filename>000001.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>341012865</flickrid>
</source>
<owner>
<flickrid>Junk Food</flickrid>
<name>E.J.</name>
</owner>
<size>
<width>353</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>dog</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>48</xmin>
<ymin>240</ymin>
<xmax>195</xmax>
<ymax>371</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>8</xmin>
<ymin>12</ymin>
<xmax>352</xmax>
<ymax>498</ymax>
</bndbox>
</object>
</annotation>
标签说明:
`
annotation: 整个 XML 文件的根标签。
folder: 包含图像的文件夹名称。
filename: 图像文件的名称,例如 000001.jpg。这是最重要的信息之一,用于将标注文件与图像文件对应起来。
size: 描述图像的尺寸。
width: 图像的宽度(像素)。
height: 图像的高度(像素)。
depth: 图像的通道数,通常为 3(RGB)。
object: 每个目标都用一个 object 标签来描述。一个图像可以有多个 object 标签,代表多个目标。
name: 目标的类别名称,例如 dog、car、person 等。
pose: 目标的姿态信息,如 Unspecified。
truncated: 标记目标是否部分被截断或超出图像边界,1 表示是,0 表示否。
difficult: 标记目标是否难以识别(例如,目标很小或严重遮挡),1 表示是,0 表示否。在评估时,通常会忽略这些 difficult 的目标。
bndbox: 目标的边界框坐标。这是目标检测任务中最核心的信息。
xmin: 边界框左上角的 x 坐标。
ymin: 边界框左上角的 y 坐标。
xmax: 边界框右下角的 x 坐标。
ymax: 边界框右下角的 y 坐标。
COCO (JSON格式)
与 VOC 格式不同,COCO 数据集的所有标注信息都集中在一个巨大的 JSON 文件中,例如 instances_train2017.json。这个 JSON 文件包含多个顶级键,每个键对应一类信息,这种集中式的存储方式非常适合大规模数据的管理和自动化处理。
coco/
├── train2017/ # 训练图片
├── val2017/ # 验证图片
└── annotations/ # 标注文件
├── instances_train2017.json
└── instances_val2017.json
{
"info": {
"description": "COCO 2017 Dataset"
},
"licenses": [],
"images": [
{
"id": 1,
"width": 640,
"height": 480,
"file_name": "000000000001.jpg"
},
],
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 1,
"bbox": [198.8, 142.3, 37.8, 88.6],
"area": 3350.28,
"iscrowd": 0,
"segmentation": [
[200.0, 150.0, 230.0, 160.0, 235.0, 220.0, ...]
]
},
],
"categories": [
{
"id": 1,
"name": "person",
"supercategory": "person"
},
{
"id": 2,
"name": "bicycle",
"supercategory": "vehicle"
}
]
}
images:
id: 图像的唯一 ID。这个 ID 用于在 annotations 中引用该图像。
file_name: 图像的文件名,例如 000000000001.jpg。
width 和 height: 图像的宽度和高度,以像素为单位。
annotations:
id: 标注的唯一 ID。
image_id: 关联的图像 ID。这是将标注与特定图像关联起来的关键。
category_id: 目标的类别 ID。这个 ID 对应 categories 列表中的 id。
bbox: 边界框。这是一个包含四个浮点数的列表,格式为 [x, y, width, height]。这里的坐标是非归一化的,即像素值。
x: 边界框左上角的 x 坐标(水平位置)。
y: 边界框左上角的 y 坐标(垂直位置)。
width: 边界框的 宽度。
height: 边界框的 高度。
area: 边界框的面积,单位为像素平方。
iscrowd: 标记该标注是否代表一个群组或密集区域。0 表示单个物体,1 表示一群物体。
segmentation: 实例分割的标注信息。对于目标检测任务,这个字段通常不使用或可以忽略。它通常是一个多边形点列表。
categories:
id: 类别的唯一 ID。
name: 类别的名称,例如 person、car。
supercategory: 超类别,用于组织相关联的类别,例如 bicycle 和 car 的超类别可以是 vehicle。
YOLO (TXT格式)
yolov5_dataset/
├── images/
│ ├── train/ # 训练图片
│ └── val/ # 验证图片
├── labels/
│ ├── train/ # 标签(.txt)
│ └── val/
└── dataset.yaml # 这是一个配置文件,用于指定数据集的路径、类别名称等信息
<class_id> <x_center> <y_center> <width> <height>
0 0.534884 0.354167 0.170543 0.291667
1 0.768133 0.655833 0.457805 0.583333
class_id: 这是一个整数,代表目标的类别索引。通常从 0 开始。例如,0 可能代表“人”,1 代表“自行车”。这些索引与 data.yaml 文件中定义的类别名称列表相对应。
x_center, y_center: 这是边界框中心的归一化坐标。
width, height: 这是边界框的归一化宽度和高度。
归一化的意思是,坐标值已经被缩放到 0.0 到 1.0 的范围内。
x_center = 边界框中心x坐标 / 图像宽度
y_center = 边界框中心y坐标 / 图像高度
width = 边界框宽度 / 图像宽度
height = 边界框高度 / 图像高度
YOLO OBB格式
5参数表示法
它在原始的 YOLO 格式基础上增加了一个旋转角度参数
<class_id> <x_center> <y_center> <width> <height> <angle>
class_id: 类别 ID,从 0 开始。
x_center、y_center: 旋转边界框中心点的归一化坐标(0 到 1 之间)。
width、height: 旋转边界框的宽度和高度的归一化值。
angle: 旋转角度,通常也是归一化值,或以弧度、度为单位。
角度的表示方法:
角度的表示方式非常关键,因为它直接影响模型的训练和预测。常见的角度定义方式有:
弧度制: [-pi/2, pi/2] 或 [-pi, pi]。
角度制: [-90, 90] 或 [-180, 180]。
归一化角度: 将角度归一化到 [0, 1] 范围内。
角度的定义方向和范围需要明确。 例如,是逆时针旋转还是顺时针旋转?0 度代表什么方向?通常,width 是长边,height 是短边,angle 是 width 边与水平轴的夹角。
这种格式的缺点是,由于 width 和 height 的互换性,以及角度的周期性,可能会产生歧义。比如,一个 90 度旋转的边界框,其 width 和 height 互换后,角度就变成了 0 或 180 度,但表示的是同一个框。
8参数表示法
这种方法通过直接列出旋转边界框的四个角点坐标,来完全避免角度表示的歧义。
<class_id> <x1> <y1> <x2> <y2> <x3> <y3> <x4> <y4>
class_id: 类别 ID。
x1 y1 … x4 y4: 旋转边界框四个角点的归一化坐标。
角点的顺序需要预先约定,通常是顺时针或逆时针,从某个固定的点(如左上角)开始
优点:
无歧义: 直接用四个点唯一确定一个旋转框,没有角度周期性或宽高的互换问题。
表达更直接: 特别适合那些不规则形状的旋转目标。
缺点:
参数更多: 相比 5 参数,需要表示更多的信息。
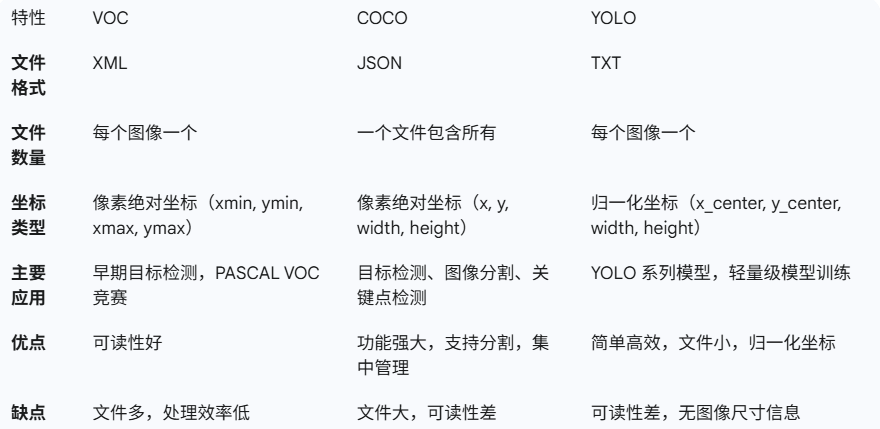
异同

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)