模型微调算力成本精准评估:从理论计算到实战演练的完整指南
【摘要】揭示大模型微调的算力成本构成,提供从理论估算到实战验证的系统化评估方法,助力精准规划资源。
【摘要】揭示大模型微调的算力成本构成,提供从理论估算到实战验证的系统化评估方法,助力精准规划资源。

引言
大模型微调,这个词汇如今在技术圈几乎无人不晓。它像是赋予通用大模型特定灵魂的魔法,让模型能够更好地服务于具体的业务场景。然而,施展这个“魔法”的代价不菲,其背后是巨大的算力消耗。许多团队满怀激情地投入,却常常在项目进行中遭遇资源瓶颈或预算超支的窘境。究其原因,往往是在项目启动之初,对微调所需的算力资源缺乏一个清晰、准确的评估。
算力评估并非简单的加减乘除,它是一门融合了模型理论、工程实践与项目管理的综合艺术。一次精准的评估,不仅能帮助我们合理规划硬件资源、严控项目成本,更能有效提升微调效率,为项目的顺利推进保驾护航。它要求我们像一位经验丰富的船长,在启航前就必须洞悉航线上的每一处暗礁与洋流,从模型规模、数据特性,到微调策略、硬件选型,进行全方位的系统性考量。
这篇文章,旨在为你提供一张详尽的“航海图”。我们将一起从理论计算的源头出发,深入剖析影响算力消耗的每一个变量,并最终通过实战演练,将理论落地为可操作的评估方案。无论你是项目决策者、算法工程师还是系统架构师,都能从中找到精准评估模型微调算力成本的钥匙。
一、🎯 评估的罗盘-系统化的流程与框架

要精准评估算力消耗,一套系统化的流程必不可少。它能确保我们不遗漏任何关键环节,让评估过程有条不紊。这个流程可以被看作一个由粗到精、从理论到实践的循环迭代过程。
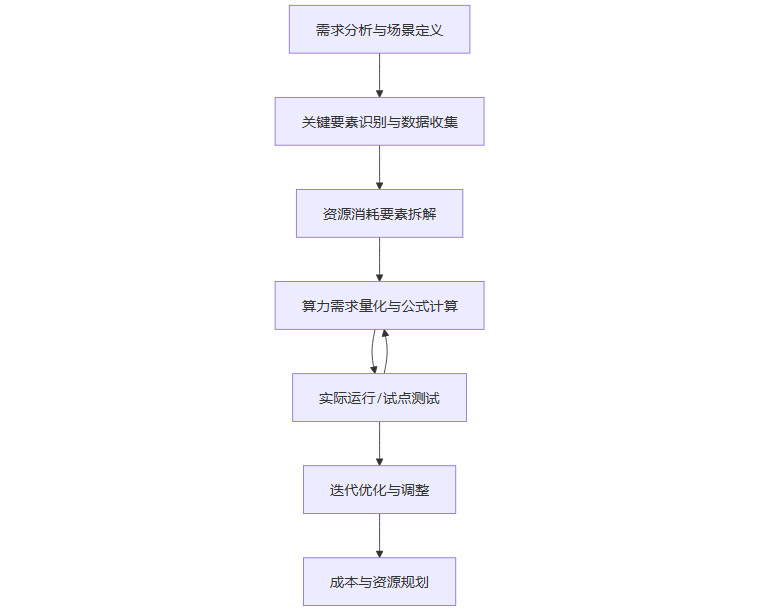
1.1 航向确立-需求分析与场景定义
一切评估的起点,都源于对需求的清晰定义。在这一阶段,我们需要明确回答以下几个核心问题。
-
微调目标是什么? 是为了做文本分类、情感分析,还是进行特定领域的对话生成或代码编写?不同的任务对模型能力的要求不同,进而影响模型选型和微调深度。
-
模型规模选多大? 是选择一个灵活的7B模型,还是一个能力更强的70B甚至更大规模的模型?模型参数量是算力消耗最基础的决定因素。
-
数据集有多大,多复杂? 训练数据的规模、样本的平均长度(Token数)以及数据的多样性,直接关系到训练的总时长和动态显存的占用。
-
业务对实时性有何要求? 这决定了我们对训练效率的期望,可能会影响是否采用分布式训练等高级策略。
尤其重要的一点是,必须在初期就明确微调的技术路线。是采用全量微调(Full Fine-Tuning),即训练模型的所有参数;还是选择参数高效微调(Parameter-Efficient Fine-Tuning, PEFT),例如LoRA、QLoRA等方法。这两条路线对算力资源的消耗有着天壤之别,前者是“重装集团军”,后者则是“轻骑特种兵”。
1.2 资源拼图-关键要素识别与数据收集
明确了航向,接下来就是收集绘制“航海图”所需的各种信息。这些信息如同拼图的碎片,共同构成了算力评估的基础。
-
模型信息
-
参数量(Parameters) 模型的核心指标,如7B、13B、70B。
-
模型架构(Architecture) Transformer模型的层数(num_layers)、隐藏层维度(hidden_size)、注意力头数(num_attention_heads)等。这些深层参数影响着计算的复杂度和中间激活值的大小。
-
计算精度(Precision) 模型参数在计算时所用的数据类型。FP32(单精度,4字节)、FP16(半精度,2字节)、BF16(脑浮点数,2字节)或INT8(整型,1字节)。目前主流微调普遍采用FP16或BF16,它们能在保证模型性能基本不降的同时,将显存占用和计算速度提升近一倍。
-
-
数据信息
-
数据集规模(Dataset Size) 训练样本的总条数。
-
样本长度(Sequence Length) 每条输入样本被处理成的Token数量。这是一个极其敏感的参数,序列长度的增加会显著推高动态显存的消耗。
-
-
微调策略与超参数
-
微调方法(Fine-tuning Method) 全量微调还是PEFT。
-
训练轮数(Epochs) 整个数据集被重复训练的次数。
-
批处理大小(Batch Size) 每次迭代(step)中模型处理的样本数量。它在训练速度和显存占用之间形成一种权衡。
-
梯度累积步数(Gradient Accumulation Steps) 一种在不增加显存的情况下,模拟大Batch Size训练效果的技术。
-
这些关键信息通常可以在模型的官方发布文档、Hugging Face的模型卡(Model Card)或相关技术论文中找到。
1.3 庖丁解牛-资源消耗的精细拆解
总的算力消耗是一个笼统的概念,为了精准评估,我们需要将其拆解为更具体的、可量化的组成部分。其中,显存消耗和训练时长是两个最核心的指标,它们直接决定了硬件选型和项目周期。
1.3.1 显存消耗的构成
GPU显存是微调过程中最为宝贵且最易耗尽的资源。其消耗主要分为两大部分。
-
固定显存(Static Memory) 这部分显存在训练开始后基本保持不变,主要由三块组成。
-
模型参数(Model Parameters) 加载模型本身所占用的显存。
-
梯度(Gradients) 在反向传播过程中,为每个可训练参数计算出的梯度值。其大小与模型参数相当。
-
优化器状态(Optimizer States) 优化器(如AdamW)在更新参数时需要存储的中间变量。常用的AdamW优化器会为每个参数存储两个状态(一阶动量和二阶动量),因此其显存占用通常是模型参数的两倍。
-
-
动态显存(Dynamic Memory) 这部分显存随着训练的进行而动态变化,主要来源是中间激活值(Activations)。在模型前向传播时,每一层的输出(即激活值)都需要被缓存下来,以备反向传播时计算梯度使用。它的大小与Batch Size和序列长度强相关。
1.4 沙盘推演-算力需求的量化计算
收集完数据并理解了消耗构成后,我们就可以进入量化计算阶段。沙盘推演的核心,就是要把模糊的算力需求,变成具体的数字。记住一个基本原则,先算清显存、步时、FLOPs。这三者是构成算力成本的三大支柱,也是我们后续所有决策的数据基础。
1.4.1 显存消耗估算
总显存 ≈ 固定显存 + 动态显存
我们以一个典型的全参数微调场景为例,使用FP16精度和AdamW优化器。
-
固定显存估算
一个参数在FP16下占用2字节。-
模型参数显存 = 参数量 × 2字节
-
梯度显存 ≈ 参数量 × 2字节
-
优化器状态显存 ≈ 参数量 × 2 × 2字节 = 参数量 × 4字节
因此,总的固定显存占用可以简化估算为:
固定显存 ≈ 参数量 × (2 + 2 + 4)字节 = 参数量 × 8字节一个更通用的快速估算公式是,对于FP16精度的全参数微调,模型参数、梯度和优化器状态的显存占用比例大致为1:1:2。因此,加载模型进行训练所需的固定显存大约是模型本身大小的4倍。
【实战案例:LLaMA-7B全参数微调】
-
模型参数量 P = 70亿
-
模型参数显存 = 7B × 2 bytes ≈ 14 GB
-
梯度显存 ≈ 14 GB
-
优化器显存 ≈ 28 GB
-
总固定显存 ≈ 14 + 14 + 28 = 56 GB
-
-
动态显存估算
动态显存的计算相对复杂,但可以近似估算。动态显存 ≈ Batch Size × 序列长度 × 隐藏层维度 × 层数 × 精度字节数这个公式虽然精确,但在实际操作中,由于各种CUDA内核和框架的额外开销,通常会有一个浮动。不过,它足以帮我们理解各参数的影响力。
【实战案例:LLaMA-7B全参数微调续】
假设我们使用以下超参数。-
Batch Size = 32
-
序列长度 = 1024
-
模型信息(Llama-7B) 隐藏层维度 4096,层数 32
-
精度 FP16(2字节)
-
动态显存 ≈ 32 × 1024 × 4096 × 32 × 2 bytes ≈ 8.6 GB,我们估算为 9 GB。
-
-
总显存需求
总显存 ≈ 56 GB (固定) + 9 GB (动态) ≈ 65 GB这个计算结果告诉我们,要在上述配置下对一个7B模型进行全参数微调,至少需要一张显存大于65GB的GPU,例如NVIDIA A100 80GB。这个估算为我们的硬件选型提供了直接依据。
1.4.2 训练时长估算
总训练时长 ≈ 总训练步数 × 每步耗时 × 重试系数
-
总训练步数(Total Steps)
总训练步数 = (数据集样本数 / (Batch Size × 梯度累积步数)) × 训练轮数【实战案例】
-
数据集大小 = 10,000条
-
Batch Size = 32
-
梯度累积步数 = 1
-
训练轮数 = 3个Epoch
-
总训练步数 = (10,000 / 32) × 3 ≈ 313 × 3 = 939步
-
-
每步耗时(Time per Step)
这个值与硬件性能(如GPU的浮点运算能力TFLOPs)、模型大小、数据I/O速度、网络带宽等多种因素强相关。理论上很难精确计算,最可靠的方法是通过实际测试获得。我们可以先用少量数据(如100步)进行一次试运行,记录下单步的平均耗时,然后用这个值来推算总时长。 -
重试系数(Retry Factor)
这是一个非常重要的工程考量。实际的微调过程很少一帆風順,总会伴随着调参、修正数据、修复bug等意外情况。因此,在理论计算出的时长基础上,乘以一个1.5到3之间的重试系数,可以得到一个更贴近现实的项目周期预估。
1.5 实战检验-试点测试与迭代优化
理论计算为我们提供了一个基准,但永远无法替代真实世界的检验。这就引出了我们评估流程的下一个关键环节,再小跑校准,决定最终方案。在投入大规模资源之前,进行一次小规模的**试点测试(Pilot Test)或压力测试(Stress Test)**是极其明智的选择。
-
目的 验证理论估算的准确性,获取真实的“每步耗时”数据,并观察显存占用的峰值。
-
方法 使用一小部分代表性的数据(例如1%),在目标硬件上完整地跑一遍微调流程。
-
收益 通过试点测试,我们可以发现理论模型中未考虑到的工程细节,例如数据预处理的瓶颈、特定算子(Operator)的性能问题等。根据测试结果,我们可以回头修正我们的计算公式和超参数,使最终的评估结果更加精准。
1.6 运筹帷幄-成本与资源规划
在获得精准的算力消耗评估后,最后一步就是将其转化为具体的成本和资源规划。
-
硬件选型 根据峰值显存需求和期望的训练时长,选择合适的GPU/TPU型号和数量。
-
成本核算 结合硬件的租赁成本(如云服务)或采购成本、电力消耗、网络带宽费用等,制定详细的项目预算。
-
并发需求 如果项目涉及多个模型的并行微调,还需要考虑整体的资源调度和并发能力。
通过这样一套完整的流程,我们就能将“模型微调算力评估”这个模糊的问题,转化为一个清晰、可量化、可执行的规划方案。
二、⚙️ 工具箱揭秘-核心算法与技术手段
了解了评估流程,我们还需要熟悉工具箱里的各种“兵器”。不同的微调算法和技术,对算力消耗的影响截然不同。选择合适的工具,是实现降本增效的第一步。
2.1 重量级选手-全量微调
全量微调,顾名思义,就是对模型的所有参数进行训练更新。
-
优点 能够最大程度地激发模型潜力,使其深度适应目标任务,通常能达到最佳的性能表现。
-
缺点 算力消耗巨大。正如前文计算所示,其对显存的要求极高,训练时间也相对较长。
-
适用场景 资源充足,且对模型性能有极致要求的场景,例如构建核心业务的基座模型。
2.2 轻量级奇兵-参数高效微调(PEFT)
面对全量微调高昂的成本,社区发展出了一系列参数高效微调(PEFT)方法。其核心思想是冻结预训练模型的大部分参数,仅训练少量新增或指定的参数。
2.2.1 LoRA(Low-Rank Adaptation)
LoRA是目前最流行的一种PEFT方法。它通过在模型的某些层(通常是注意力层)旁边增加两个小型的、“低秩”的矩阵(A和B)来实现微调。训练时,只更新这两个小矩阵的参数,而原始模型的巨大权重矩阵保持不变。
-
优势
-
显存骤降 由于可训练参数量极少(通常不到原始模型的1%),梯度和优化器状态所占用的显存可以忽略不计。这使得在消费级GPU(如24GB显存的RTX 3090)上微调大模型成为可能。
-
切换灵活 微调产物只是一个很小的适配器文件(几十MB),可以即插即用地加载到原始模型上,方便管理和部署多个任务的微调版本。
-
2.2.2 QLoRA(Quantized Low-Rank Adaptation)
QLoRA是LoRA的极致优化版。它在LoRA的基础上,引入了**量化(Quantization)**技术。
-
核心技术
-
4-bit NormalFloat量化 将预训练模型的权重从16位浮点数(FP16)量化为4位,极大地压缩了模型本体的显存占用。
-
双重量化 对量化过程中产生的量化常数再次进行量化,进一步节省显存。
-
分页优化器 利用NVIDIA统一内存特性,防止在处理长序列时因梯度检查点导致的内存溢出。
-
-
效果 QLoRA的效果是惊人的。它使得在单张48GB的GPU(如A6000)上微调650亿参数的模型成为现实,极大地降低了超大模型微调的硬件门槛。
2.3 空间魔法-梯度累积与混合精度
除了选择不同的微调算法,还有一些通用的训练技巧可以帮助我们“压榨”硬件性能。
-
梯度累积(Gradient Accumulation)
当我们的显存无法支持一个较大的Batch Size时,梯度累积就派上了用场。它将一次大的批处理计算分解为多次小的批处理计算。在每次小批量的前向和反向传播后,计算出的梯度会被累积起来,而不是立即用于更新模型参数。直到累积了指定次数后,才用累积的梯度统一更新一次参数。有效Batch Size = 单次迭代Batch Size × 梯度累积步数通过这种方式,我们可以在不增加显存占用的情况下,实现大Batch Size训练的效果,有助于提升模型的训练稳定性和最终性能。
-
混合精度训练(Mixed Precision Training)
这是一种结合使用FP32和FP16/BF16的训练技术。在训练过程中,大部分计算(如矩阵乘法)使用半精度(FP16/BF16)来加速并减少显存,而某些关键部分(如梯度累积和权重更新)则保持使用单精度(FP32)以维持数值稳定性。现代深度学习框架(如PyTorch)已经内置了自动混合精度(AMP)功能,只需几行代码即可开启。
2.4 集团作战-分布式训练与并行策略
当单张GPU的算力或显存无法满足需求时,就需要动用多卡或多机进行分布式训练。
-
数据并行(Data Parallelism) 最常见的并行策略。将模型复制到多张GPU上,然后将一个大的Batch数据切分到不同的GPU上并行计算。最后将所有GPU计算出的梯度同步并平均,再更新各自的模型副本。
-
模型并行(Model Parallelism) 当模型大到单张GPU无法容纳时使用。将模型的不同部分(例如不同的层)切分到不同的GPU上。
-
流水线并行(Pipeline Parallelism) 模型并行的变种,通过流水线机制减少GPU之间的等待时间,提升训练效率。
选择合适的并行策略,可以让我们突破单卡的物理限制,高效地完成超大规模模型的微调任务。
三、💡 案例透视-从数据看算力消耗

理论和技术最终要通过实际案例来检验。下面我们通过几个具体的例子,更直观地感受不同因素对算力消耗的影响。
3.1 硬件的抉择-模型与GPU的匹配艺术
不同的模型和硬件组合,其效率差异巨大。以微调一个视觉语言模型Qwen2.5-VL 7B为例。
|
硬件方案 |
单卡算力(FP16) |
所需卡数(估算) |
方案特点 |
|---|---|---|---|
|
NVIDIA RTX 3060 |
约12 TFLOPs |
8-16张 |
消费级方案,单卡成本低,但需要多卡并行,对通信和集群管理要求高。 |
|
NVIDIA A100 80GB |
约312 TFLOPs |
1-2张 |
专业级方案,单卡性能强劲,显存充裕,能简化部署,但单卡成本高昂。 |
这个对比清晰地显示了,硬件的选择是一个综合考量性能、成本和运维复杂度的决策过程。对于初创团队或个人开发者,利用多张消费级显卡可能是更经济的选择;而对于追求极致效率和稳定性的企业级应用,高性能计算卡依然是首选。
3.2 显存的博弈-LLaMA-7B全参数微调实录
我们在第一部分已经理论计算过LLaMA-7B全参数微调的显存需求。
-
模型 LLaMA-7B
-
策略 全参数微调
-
超参 Batch Size 32, 序列长度 1024
-
理论显存需求 约65GB
-
实际训练时长 在单张A100 80GB GPU上,使用优化后的代码库,完成3个Epoch的训练,大约需要2-3小时。
这个案例再次印证了理论计算的指导意义。如果当时我们错误地选择了A100 40GB或者V100 32GB的卡,项目一开始就会因显存不足(Out of Memory)而卡住。
3.3 数据的重量-数据集规模的影响
数据不仅影响训练时长,其存储本身也是成本的一部分。
-
场景 假设一个包含1亿条样本的数据集,每条样本平均500个词。
-
原始数据大小 1亿 × 500词 × 5字节/词(估算) ≈ 250 GB。如果数据格式复杂,包含大量元信息,原始大小可能达到TB级别。
-
处理后数据大小 经过清洗、Tokenize并以高效格式(如Arrow或Parquet)存储后,数据大小可能会显著减小,但依然是TB量级。
这意味着,在规划算力时,不能忽视数据存储和I/O的成本与瓶颈。高效的数据加载和预处理流水线,对于保障GPU的“喂饱”至关重要。
3.4 效率的标杆-源2.0-M32的低耗实践
一些模型在设计之初就考虑了微调的效率。例如,浪潮发布的源2.0-M32模型,在进行全量微调时展现了出色的资源利用率。
-
场景 使用1万条长度为1024 Token的样本进行全量微调。
-
算力消耗 官方数据显示,其算力消耗仅为0.0026 PD(PetaFLOPs/s-day),远低于同规模的其他大模型。
这个案例告诉我们,模型本身的架构和实现细节也会影响微调的资源消耗。在选型时,关注社区或官方发布的微调效率评测报告,可以帮助我们找到性价比更高的模型。
四、🛠️ 实践者的利器-评估工具与优化建议

掌握了理论和方法,我们还需要一些趁手的工具和实用的建议来辅助我们的评估与实践。
4.1 趁手的兵器-主流框架与云平台
-
开源框架与工具
-
Hugging Face Transformers 事实上的行业标准,提供了丰富的预训练模型和易于使用的微调脚本。
-
Colossal-AI 一个专注于大规模模型训练和部署的开源系统,提供了多种并行策略和内存优化方案。
-
LlamaFactory 一个集成了多种PEFT方法、支持多种模型和数据集的一站式微调平台,对新手非常友好。
-
-
云平台
-
AWS, Azure, Google Cloud, 百度智能云等 这些云服务商提供了弹性的GPU/TPU算力资源。使用云平台的最大好处是按需付费和弹性伸缩,可以让我们在评估阶段用较小的成本进行试点测试,在确认方案后再扩展到大规模集群,有效避免了前期一次性投入过大的硬件成本。
-
4.2 降本增效的锦囊妙计
在整个微调过程中,始终贯彻以下几个简单而强大的原则,可以帮助我们最大化资源利用率。
-
能LoRA就别全参
这是最核心的降本原则。除非有充分理由证明全量微调的必要性,否则始终优先考虑使用参数高效微调方法,尤其是QLoRA。它能在绝大多数场景下,以极小的资源代价达到与全量微调相当甚至更好的效果。这是当前平衡效果与成本的最佳实践。 -
能单卡就不复杂并行
分布式训练虽然强大,但也引入了额外的通信开销和工程复杂性。如果通过优化(如使用QLoRA、梯度累积、减小Batch Size)能让任务在单张或少数几张卡上完成,就尽量避免复杂的并行策略。简单的架构意味着更少的调试时间和更高的稳定性。 -
从小处着手,逐步扩展
严格遵循“试点测试-迭代优化”的流程。先用小批量数据跑通流程,摸清资源消耗底细,再逐步放大到全量数据。这种“小步快跑”的策略,能有效避免资源浪费和方向性错误。 -
数据质量重于数量
与其盲目堆砌海量低质量数据,不如精心构造一个规模适中但高质量、高多样性的数据集。这不仅能提升微调效果,还能直接降低训练时长和成本。 -
善用工具监控
在训练过程中,持续使用nvidia-smi、wandb或TensorBoard等工具监控GPU的显存占用、利用率和温度。及时的监控能帮助我们发现潜在的性能瓶颈。 -
合理设置验证集
在训练过程中,定期在验证集上评估模型性能,并启用**早停(Early Stopping)**机制。一旦模型在验证集上的性能不再提升,就及时停止训练,防止过拟合,同时也能节省不必要的算力开销。
结论
模型微调的算力成本评估,是一项贯穿项目始终的动态过程,而非一蹴而就的静态计算。它始于对业务需求的深刻理解,依赖于对模型、数据、算法的精细拆解与量化,最终通过实际的试点测试得以验证和修正。
我们从系统化的评估框架出发,掌握了显存和时长的核心计算方法;我们检阅了从全量微调到QLoRA的各类技术兵器,并知晓了如何根据场景选择最合适的工具;我们通过真实案例,直观感受了不同因素对算力消耗的实际影响;最后,我们还收获了实用的工具和优化建议。
精准评估的最终目的,不仅仅是为了得出一个数字,更是为了在效果、成本和效率之间找到那个最佳的平衡点。这背后贯穿着一个朴素但至关重要的理念,省钱靠稳定,不是靠碰运气。一个经过深思熟虑、反复验证的计划,远比一次次仓促上马、寄希望于运气的尝试要经济得多。希望这篇指南能成为你驾驭大模型微调这艘巨轮时,手中那张最可靠的航海图,助你在AI的浪潮中行稳致远。
📢💻 【省心锐评】
别空谈理论,也别盲目开跑。算力评估的精髓在于“理论估算打底,小跑实测修正”,把钱花在刀刃上才是硬道理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献154条内容
已为社区贡献154条内容

所有评论(0)