面向复杂环境的逆向强化学习与策略推理混合方法(附代码)
在人工智能的发展中,强化学习(Reinforcement Learning, RL)已经成为智能体(AI Agent)在复杂环境中学习最优行为策略的重要手段。然而,传统强化学习往往需要 明确定义的奖励函数,而在实际问题中,奖励函数往往是 隐含的、难以直接建模 的。
面向复杂环境的逆向强化学习与策略推理混合方法
一、引言
在人工智能的发展中,强化学习(Reinforcement Learning, RL)已经成为智能体(AI Agent)在复杂环境中学习最优行为策略的重要手段。然而,传统强化学习往往需要 明确定义的奖励函数,而在实际问题中,奖励函数往往是 隐含的、难以直接建模 的。
为此,逆向强化学习(Inverse Reinforcement Learning, IRL) 应运而生,其目标是通过观察专家的行为轨迹,推断出背后的奖励函数,从而得到合理的策略。与此同时,策略反向推理(Policy Inference) 则进一步关注如何从已有的决策结果中还原出潜在的策略模型,为AI Agent的解释性与可控性提供了理论基础。
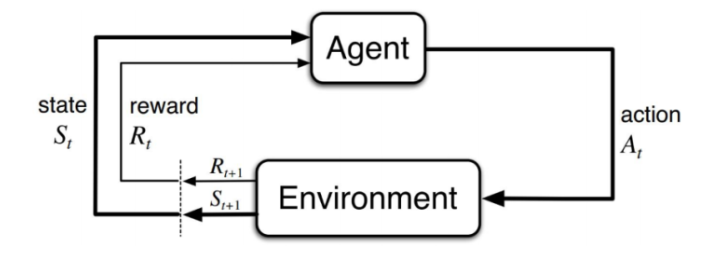
二、逆向强化学习的基本原理
2.1 强化学习回顾
在标准强化学习框架中,环境被建模为 马尔可夫决策过程(MDP):
MDP=(S,A,P,R,γ) MDP = (S, A, P, R, \gamma) MDP=(S,A,P,R,γ)
- SSS:状态空间
- AAA:动作空间
- P(s′∣s,a)P(s'|s,a)P(s′∣s,a):状态转移概率
- R(s,a)R(s,a)R(s,a):奖励函数
- γ\gammaγ:折扣因子
智能体通过最大化期望累计奖励来学习策略 π(a∣s)\pi(a|s)π(a∣s)。
2.2 逆向强化学习
在逆向强化学习中,奖励函数 R(s,a)R(s,a)R(s,a) 并不可见。我们仅能获得 专家的轨迹数据 τ=(s0,a0,s1,a1,...)\tau = (s_0, a_0, s_1, a_1, ...)τ=(s0,a0,s1,a1,...),目标是反推出最符合专家行为的奖励函数。
IRL 的核心思想:
- 假设专家行为是最优的;
- 通过优化方法寻找奖励函数,使得在该奖励函数下,专家策略的期望回报最大化。
2.3 策略反向推理
相比 IRL 专注奖励函数学习,策略反向推理更直接:
- 给定专家行为轨迹,直接估计专家的策略函数 πE(a∣s)\pi_E(a|s)πE(a∣s);
- 常见方法包括 最大似然估计(MLE) 与 生成对抗模仿学习(GAIL)。
这种方法绕过了奖励函数建模,直接用于模仿学习,更适合数据驱动场景。
三、方法框架
3.1 IRL的经典方法
- 最大熵IRL(MaxEnt IRL):通过最大化轨迹分布的熵,避免奖励函数学习的歧义性。
- Apprenticeship Learning:通过专家策略与学习者策略的特征期望对比来调整奖励函数。
3.2 策略反向推理方法
- 行为克隆(Behavior Cloning, BC):监督学习框架,直接拟合状态到动作的映射。
- 生成对抗模仿学习(GAIL):基于GAN的思想,将模仿学习转化为生成模型与判别模型的博弈。
四、代码实战:最大熵逆向强化学习
我们以经典的 GridWorld 环境 为例,展示如何用最大熵IRL方法恢复奖励函数。
4.1 环境构建
import numpy as np
import gym
from gym.envs.toy_text import discrete
class GridWorld(discrete.DiscreteEnv):
def __init__(self, shape=(5,5), goal=(4,4)):
nS = np.prod(shape)
nA = 4 # 上下左右
P = {s: {a: [] for a in range(nA)} for s in range(nS)}
def to_s(row, col): return row * shape[1] + col
def inc(row, col, a):
if a == 0: row = max(row - 1, 0)
elif a == 1: row = min(row + 1, shape[0]-1)
elif a == 2: col = max(col - 1, 0)
elif a == 3: col = min(col + 1, shape[1]-1)
return row, col
for row in range(shape[0]):
for col in range(shape[1]):
s = to_s(row, col)
for a in range(nA):
newrow, newcol = inc(row, col, a)
s_ = to_s(newrow, newcol)
done = (newrow, newcol) == goal
rew = 1.0 if done else 0.0
P[s][a].append((1.0, s_, rew, done))
isd = np.zeros(nS)
isd[0] = 1.0
super(GridWorld, self).__init__(nS, nA, P, isd)
4.2 最大熵IRL算法
def maxent_irl(feature_matrix, P_a, gamma, trajs, lr, n_iters):
n_states, d_states = feature_matrix.shape
theta = np.random.uniform(size=(d_states,))
def get_policy(theta):
rewards = feature_matrix.dot(theta)
V = np.zeros(n_states)
for _ in range(20):
V = np.log(np.sum(np.exp(rewards + gamma * P_a.dot(V).reshape(n_states, -1)), axis=1))
return np.exp(rewards + gamma * P_a.dot(V).reshape(n_states, -1) - V[:, None])
def expected_feature_counts(policy):
mu = np.zeros((n_states,))
mu[0] = 1.0
for _ in range(100):
mu = mu.dot(policy)
return mu.dot(feature_matrix)
empirical_fc = np.zeros(d_states)
for traj in trajs:
for state, _ in traj:
empirical_fc += feature_matrix[state]
empirical_fc /= len(trajs)
for _ in range(n_iters):
policy = get_policy(theta)
exp_fc = expected_feature_counts(policy)
grad = empirical_fc - exp_fc
theta += lr * grad
return feature_matrix.dot(theta)
4.3 训练与结果
# 特征矩阵 (one-hot 状态特征)
n_states = 25
feature_matrix = np.eye(n_states)
# 随机生成专家轨迹 (假设专家能到达终点)
trajs = [[(0,0), (1,0), (2,0), (3,0), (4,0), (4,1), (4,2), (4,3), (4,4)]]
# 状态转移概率矩阵
P_a = np.zeros((n_states, 4, n_states))
# ... 构建P_a (略,参考环境定义)
rewards = maxent_irl(feature_matrix, P_a, 0.9, trajs, lr=0.01, n_iters=100)
print("Recovered rewards:", rewards.reshape((5,5)))
运行后,我们会得到一个 近似专家目标函数 的奖励分布,其中终点 (4,4) 附近的奖励最高,表明IRL正确捕捉了专家行为背后的动机。
五、应用场景
- 自动驾驶:通过模仿人类驾驶行为推断驾驶偏好。
- 医疗决策:通过医生操作推断治疗方案的潜在奖励机制。
- 机器人学习:通过人类示范轨迹学习复杂任务的潜在目标。
六、总结与展望
本文探讨了 AI Agent中的逆向强化学习与策略反向推理方法,从理论原理、方法框架到代码实战进行剖析。IRL 提供了从行为数据中恢复奖励函数的强大能力,而策略反向推理则为解释性和可控性提供了直接工具。
未来,结合 深度学习 与 对抗训练 的方法(如 GAIL、AIRL)将进一步推动 IRL 在复杂现实环境中的应用,为智能体的自主学习与可解释决策提供更强支撑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)