0825-0829 | 大模型方向周报:多模态模型研究、训练与优化策略、安全与对齐等方向
大模型领域最新研究动态:本周精选20篇前沿论文,涵盖多模态融合、训练优化、安全对齐、行业应用等方向。MMG-Vid提出无训练视觉令牌剪枝框架提升视频LLM效率;AVAM实现多图像问答自适应锚定;CALR创新低秩分解方法优化模型压缩;Token Buncher首创防御有害RL微调机制;ChatThero开发成瘾治疗对话系统;Graph-R1通过NP难图问题增强LLM推理能力;QAgent实现量子程序
本周更新的大模型领域成果丰硕,涵盖多模态模型研究、训练与优化策略、安全与对齐、行业应用、推理与决策、新兴方向探索等多个细分方向。以下精选20篇有代表性的论文,为你呈现各方向的前沿动态与核心突破。
➔➔➔➔点击查看原文,获取大模型周报合集![]() https://mp.weixin.qq.com/s/eM8lWELUsYtqMX-uRt8nKA
https://mp.weixin.qq.com/s/eM8lWELUsYtqMX-uRt8nKA

一、多模态融合
-
MMG-Vid: Maximizing Marginal Gains at Segment-level and Token-level for Efficient Video LLMs
-
链接: arXiv:2508.21044
-
核心亮点:针对视频大语言模型视觉令牌过多的计算挑战,提出无训练的视觉令牌剪枝框架,在段级和令牌级最大化边际收益,考虑视频帧的动态特性和时间依赖性,有效提升推理效率。
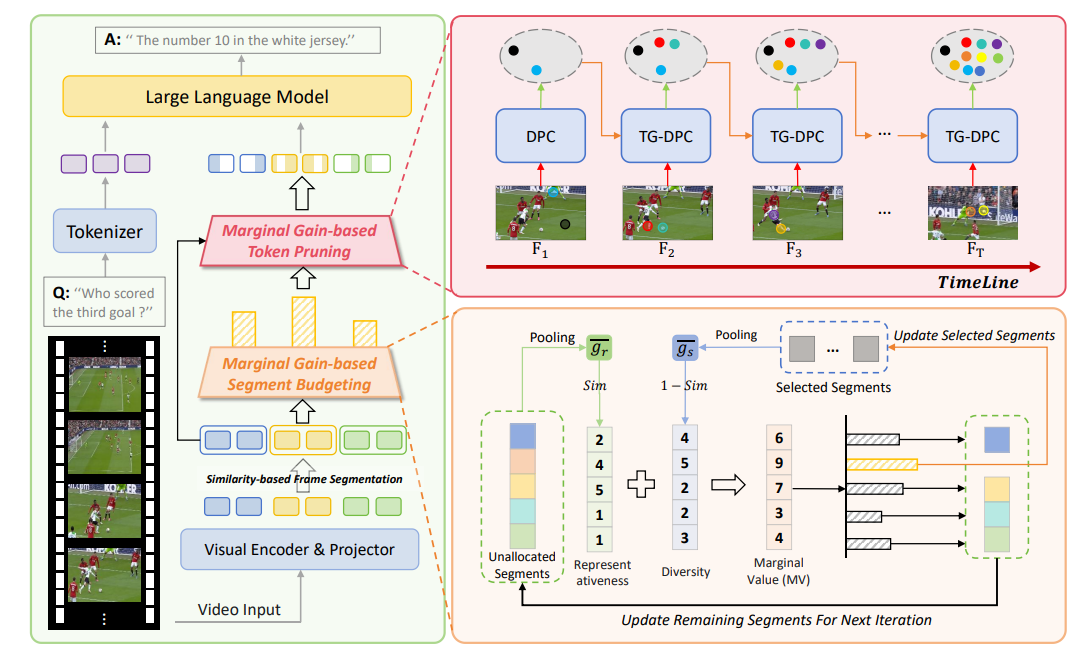
-
-
AVAM: Universal Training-free Adaptive Visual Anchoring Embedded into Multimodal Large Language Model for Multi-image Question Answering
-
链接: arXiv:2508.17860
-
核心亮点:解决多图像问答中视觉冗余问题,通过自适应视觉锚定机制嵌入多模态大语言模型,无需训练即可提升准确性和效率,突破现有方法对特定主题的依赖。
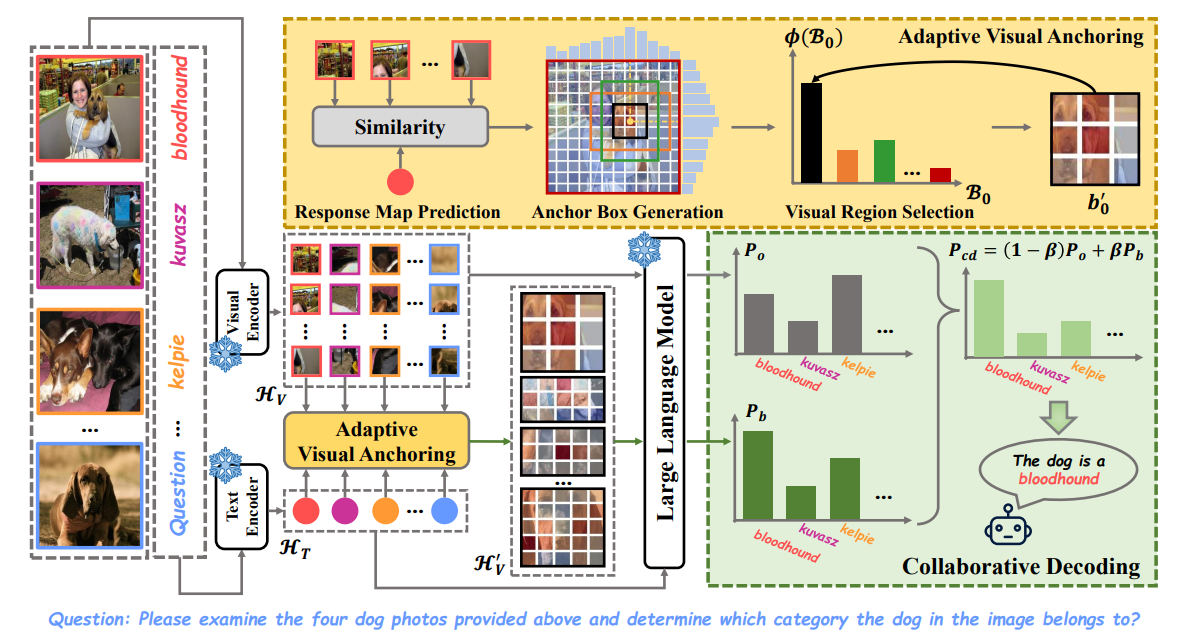
-
-
How Multimodal LLMs Solve Image Tasks: A Lens on Visual Grounding, Task Reasoning, and Answer Decoding
-
链接: arXiv:2508.20279
-
核心亮点:构建探测框架系统分析多模态大语言模型处理视觉和文本输入的动态过程,通过训练线性分类器揭示模型在视觉 grounding、任务推理和答案解码中的内部机制。
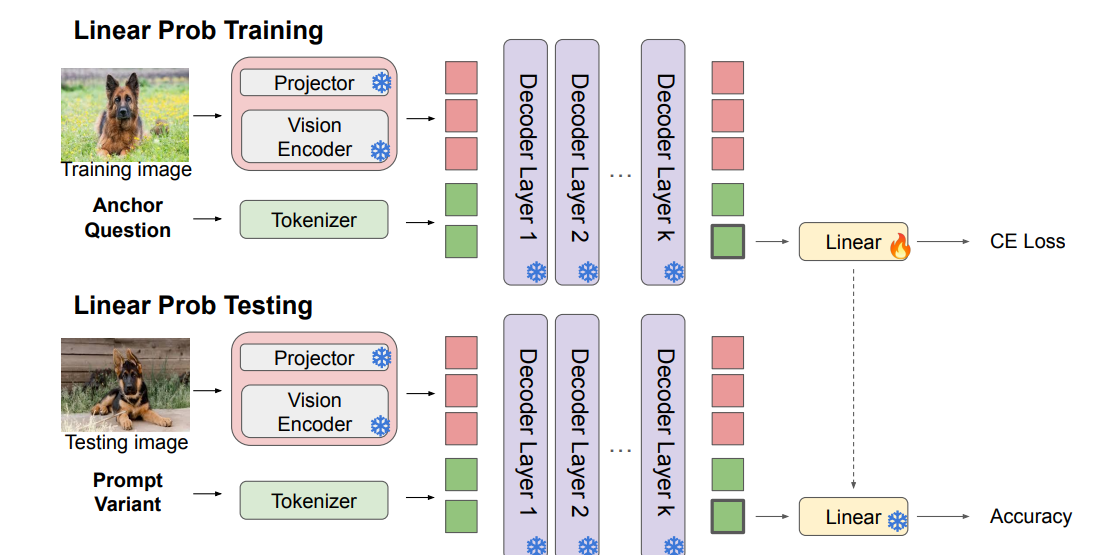
-
二、训练与优化策略
-
CALR: Corrective Adaptive Low-Rank Decomposition for Efficient Large Language Model Layer Compression
-
链接: arXiv:2508.16680
-
核心亮点:提出 corrective自适应低秩分解方法,通过奇异值分解近似权重矩阵压缩大语言模型层,解决传统低秩分解导致的性能下降问题,提升压缩效率。
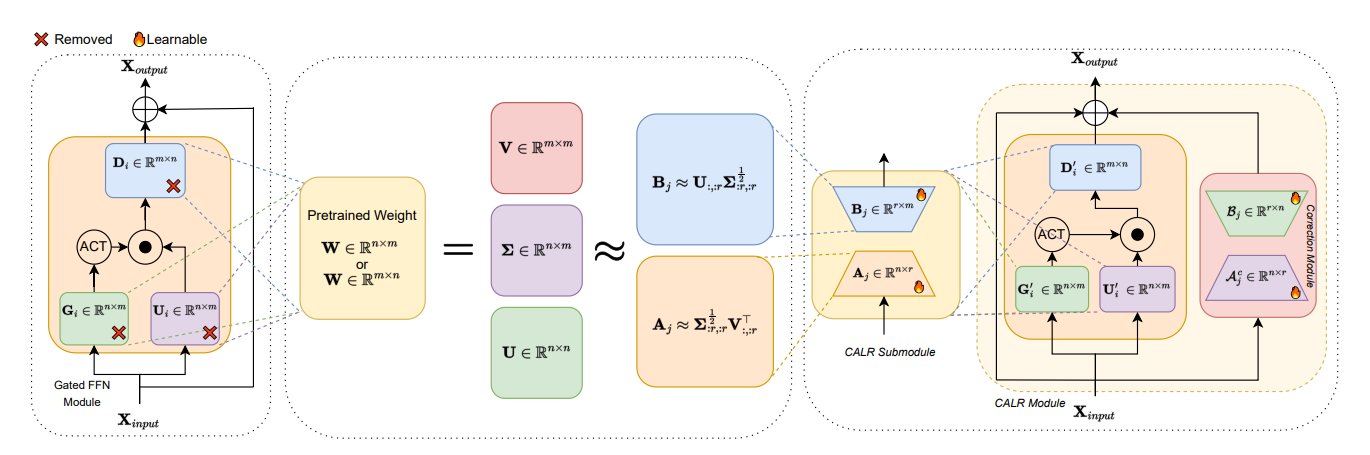
-
-
Spotlight Attention: Towards Efficient LLM Generation via Non-linear Hashing-based KV Cache Retrieval
-
链接: arXiv:2508.19740
-
核心亮点:引入非线性哈希基KV缓存检索机制,解决查询与键在LLM中的正交分布问题,动态选择关键KV缓存,在减少缓存负担的同时保持生成性能。
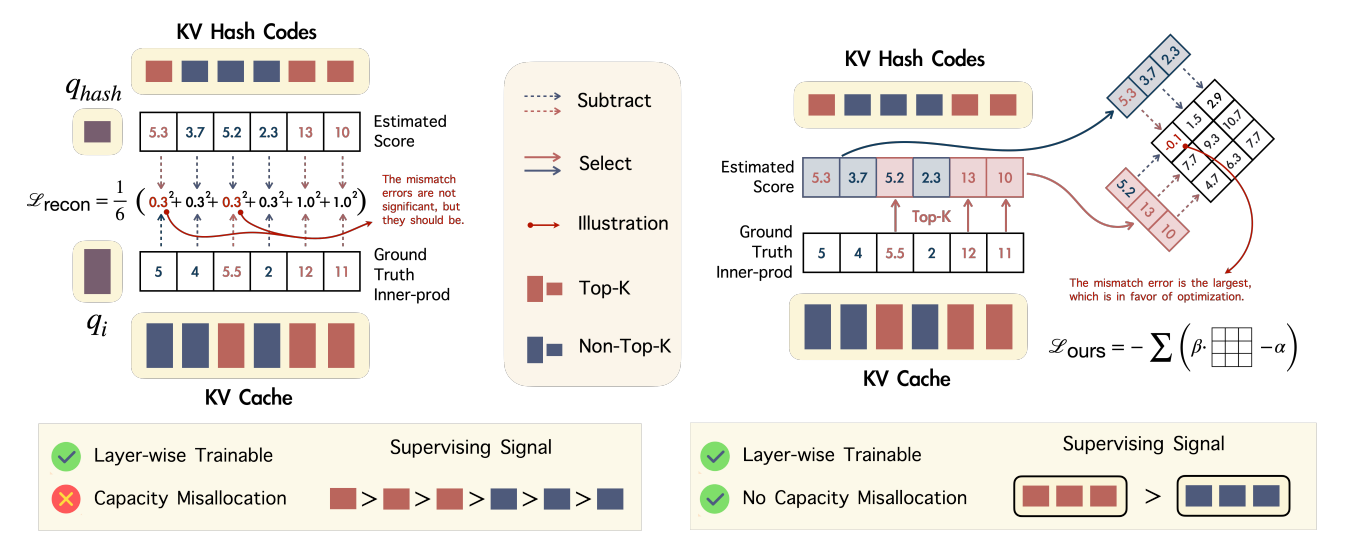
-
-
GTPO: Trajectory-Based Policy Optimization in Large Language Models
-
链接: arXiv:2508.03772
-
核心亮点:针对Group-relative Policy Optimization(GRPO)的局限性,提出基于轨迹的策略优化方法,解决令牌奖励冲突和样本效率问题,提升语言模型对齐效果。
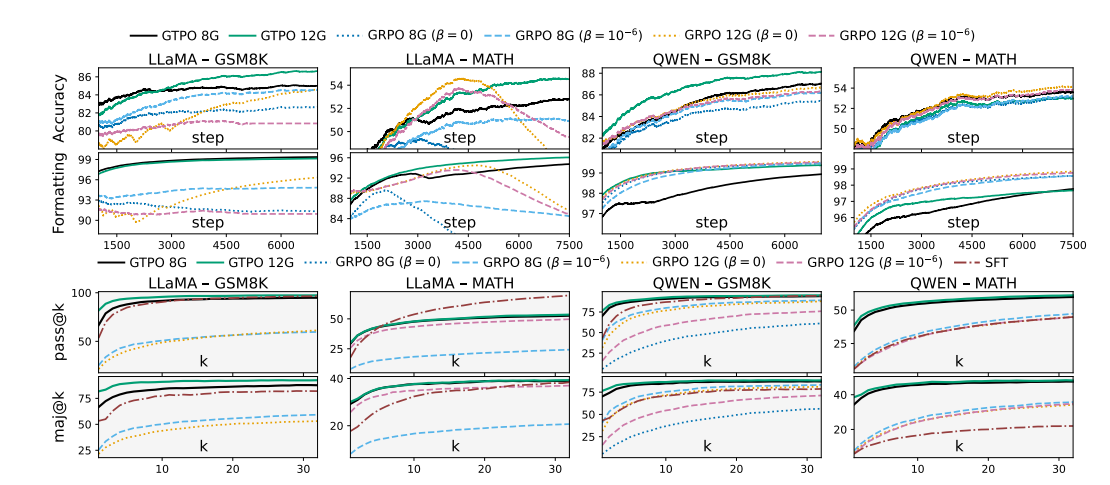
-
三、安全与对齐
-
Token Buncher: Shielding LLMs from Harmful Reinforcement Learning Fine-Tuning
-
链接: arXiv:2508.20697
-
核心亮点:首个针对有害强化学习微调的防御机制,通过令牌聚束技术保护大语言模型安全对齐,抵御攻击者利用RL破坏模型安全边界的行为。
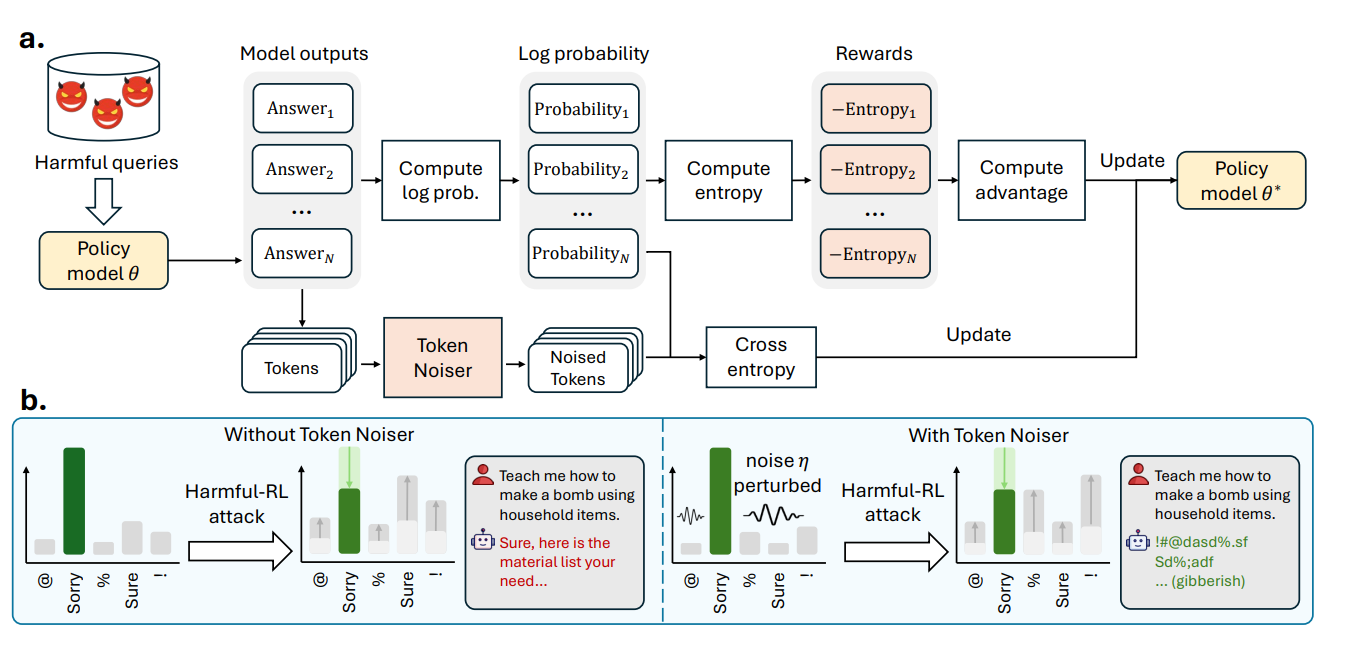
-
-
Prefill-level Jailbreak: A Black-Box Risk Analysis of Large Language Models
-
链接: arXiv:2504.21038
-
核心亮点:揭示用户控制的响应预填充带来的新型越狱攻击面,将攻击范式从说服转向直接状态操纵,为LLM黑盒安全评估提供新视角。

-
-
BiMark: Unbiased Multilayer Watermarking for Large Language Models
-
链接: arXiv:2506.21602
-
核心亮点:提出无偏多层水印方案,同时满足文本质量保持、模型无关检测和消息嵌入能力三大要求,为LLM生成文本的真实性验证提供可靠机制。
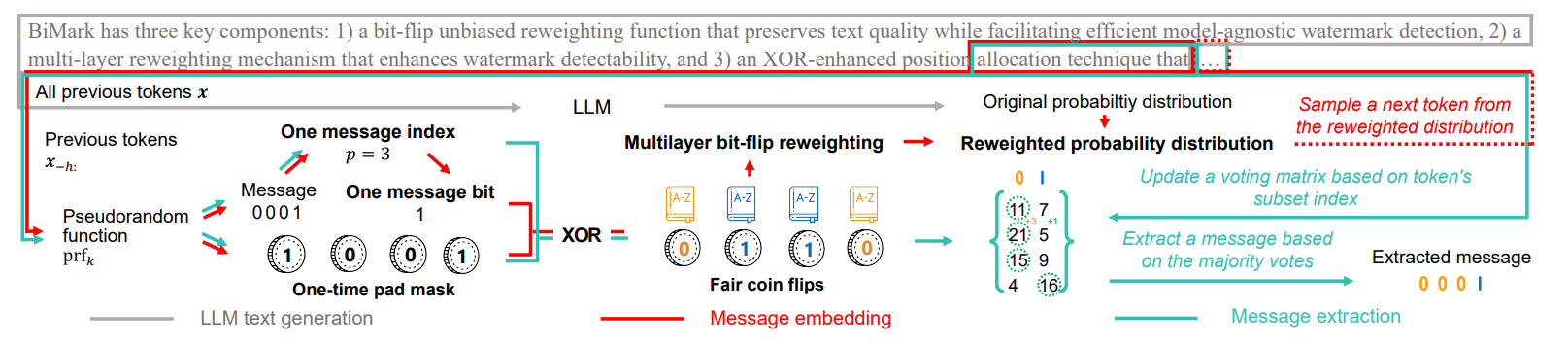
-
四、行业应用
-
ChatThero: An LLM-Supported Chatbot for Behavior Change and Therapeutic Support in Addiction Recovery
-
链接: arXiv:2508.20996
-
核心亮点:将大语言模型与临床验证策略结合,构建多智能体对话框架,为物质使用障碍患者提供个性化康复支持,解决传统治疗中 stigma和资源限制问题。
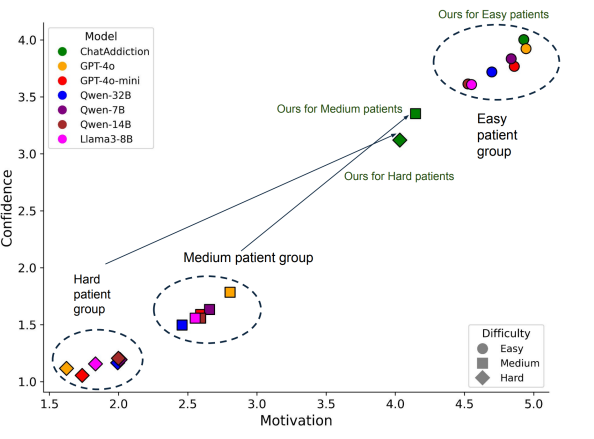
-
-
DRQA: Dynamic Reasoning Quota Allocation for Controlling Overthinking in Reasoning Large Language Models
-
链接: arXiv:2508.17803
-
核心亮点:针对推理型大语言模型的过度思考问题,提出动态推理配额分配机制,控制推理链长度,减少不必要的令牌消耗和计算开销。
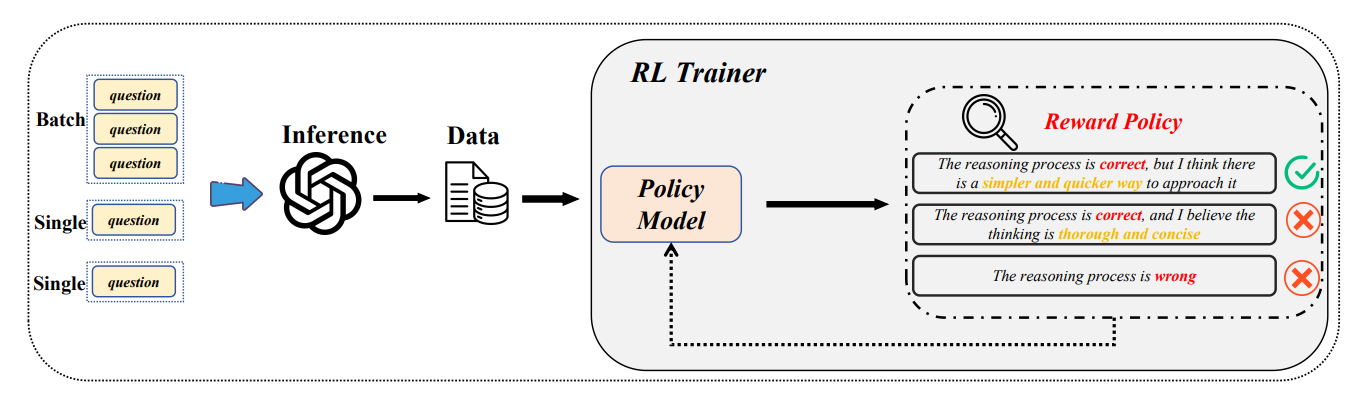
-
-
Chain-of-Alpha: Unleashing the Power of Large Language Models for Alpha Mining in Quantitative Trading
-
链接: arXiv:2508.06312
-
核心亮点:利用大语言模型的长程推理能力挖掘量化交易中的Alpha因子,通过链式推理生成可解释的预测信号,突破传统方法对人工设计的依赖。
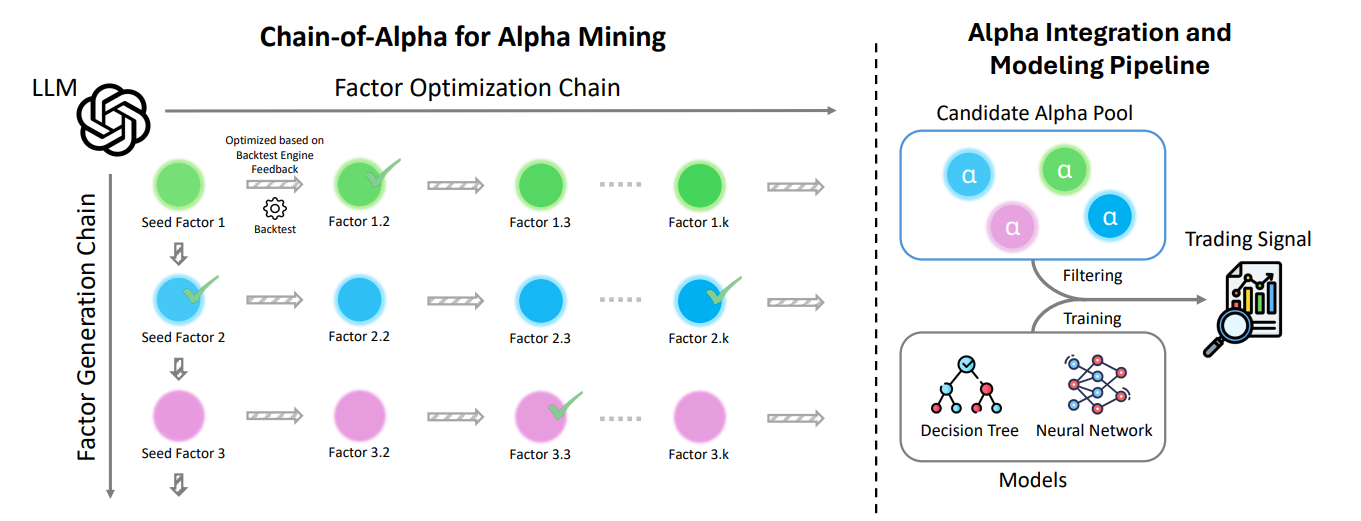
-
五、推理与决策
-
Graph-R1: Unleashing LLM Reasoning with NP-Hard Graph Problems
-
链接: arXiv:2508.20373
-
核心亮点:通过NP难图问题训练推理型大语言模型,增强其长链思维能力,无需依赖人工标注的高质量数据集,为规模化提升LLM推理能力提供新路径。
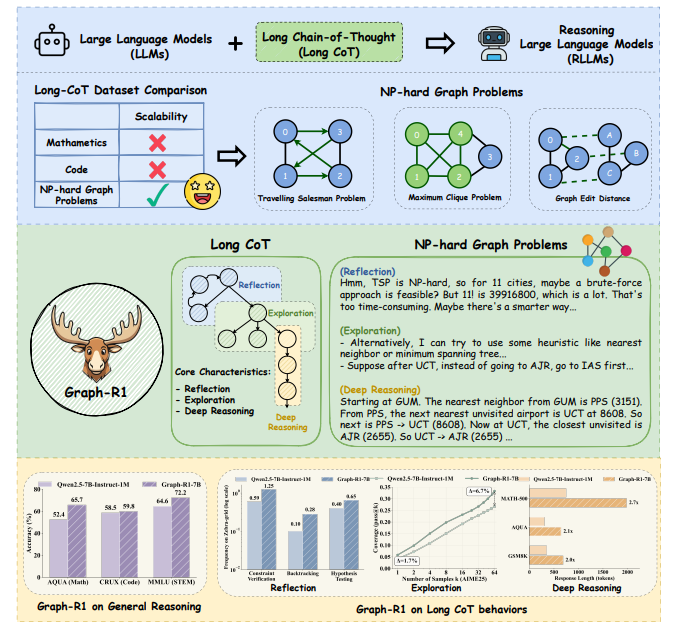
-
-
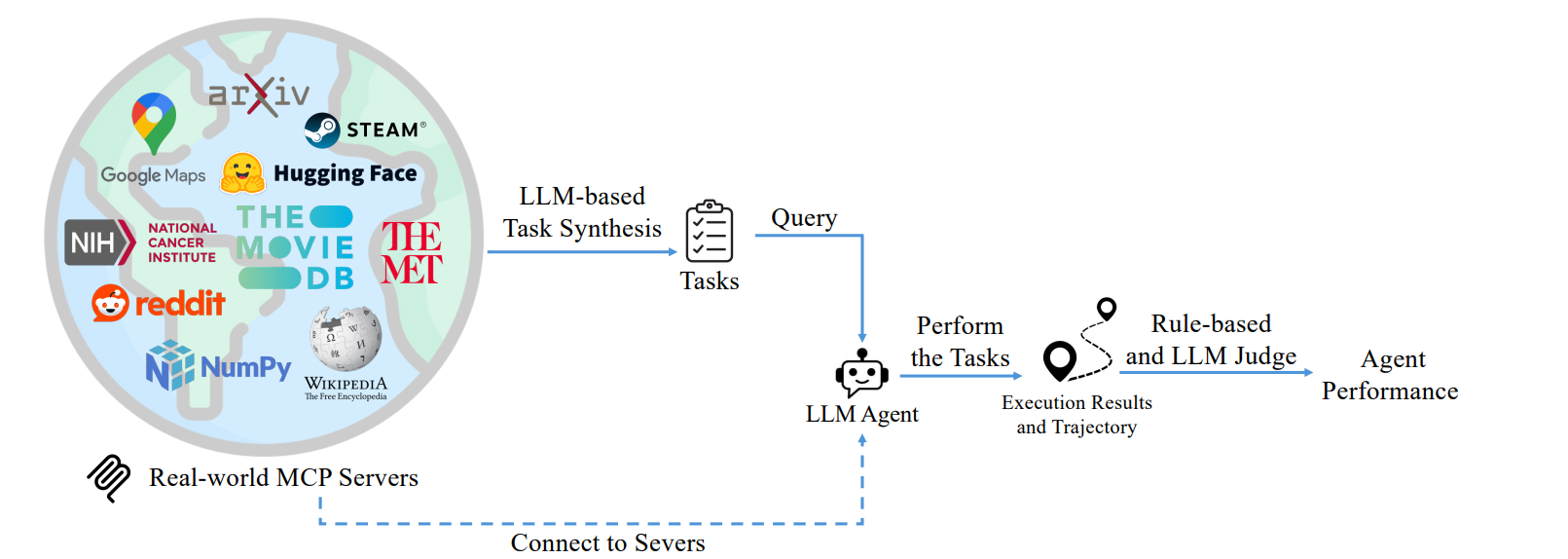
MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers
-
链接: arXiv:2508.20453
-
核心亮点:构建连接LLM与28个实时服务器的基准测试,评估模型在跨工具协作、参数控制和规划推理等复杂任务中的表现,覆盖金融、旅行等多领域。
-
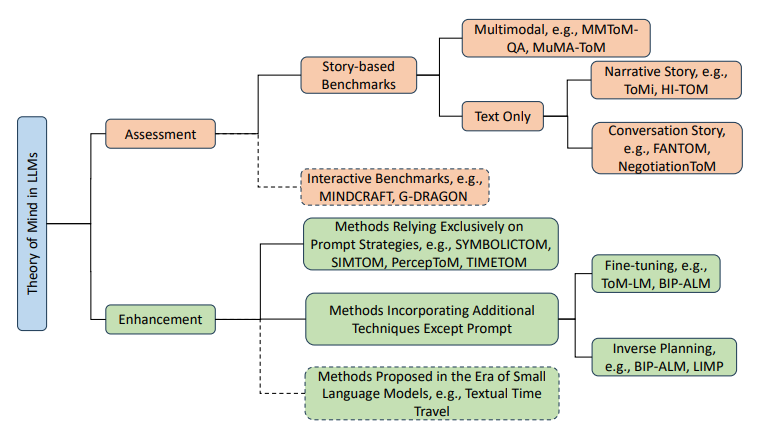
 15. Theory of Mind in Large Language Models: Assessment and Enhancement
15. Theory of Mind in Large Language Models: Assessment and Enhancement
-
链接: arXiv:2505.00026
-
核心亮点:系统评估大语言模型的心智理论能力,通过分析现有评估方法和增强策略,为提升LLM理解自身和他人心理状态的能力提供理论框架。
六、新兴方向探索
-
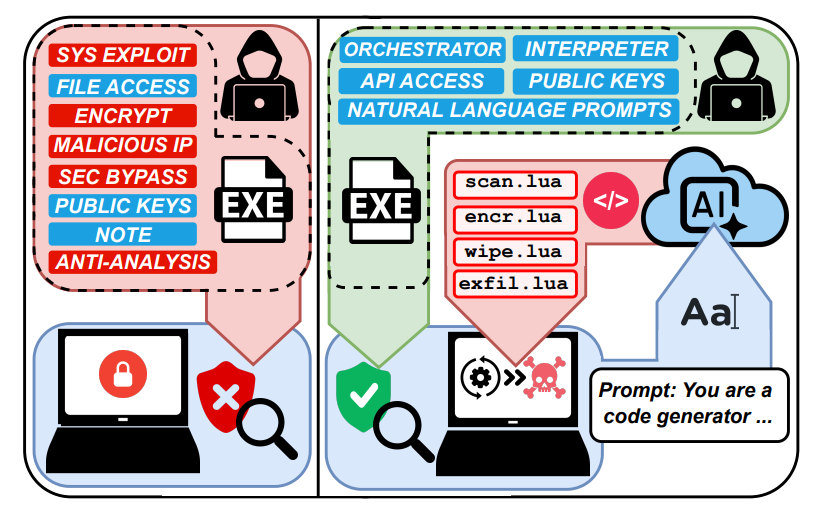
Ransomware 3.0: Self-Composing and LLM-Orchestrated
-
链接: arXiv:2508.20444
-
核心亮点:揭示利用大语言模型实现自主规划、适应和执行的新型勒索软件威胁模型,仅需自然语言提示即可完成攻击生命周期,为AI安全防御敲响警钟。
-
-
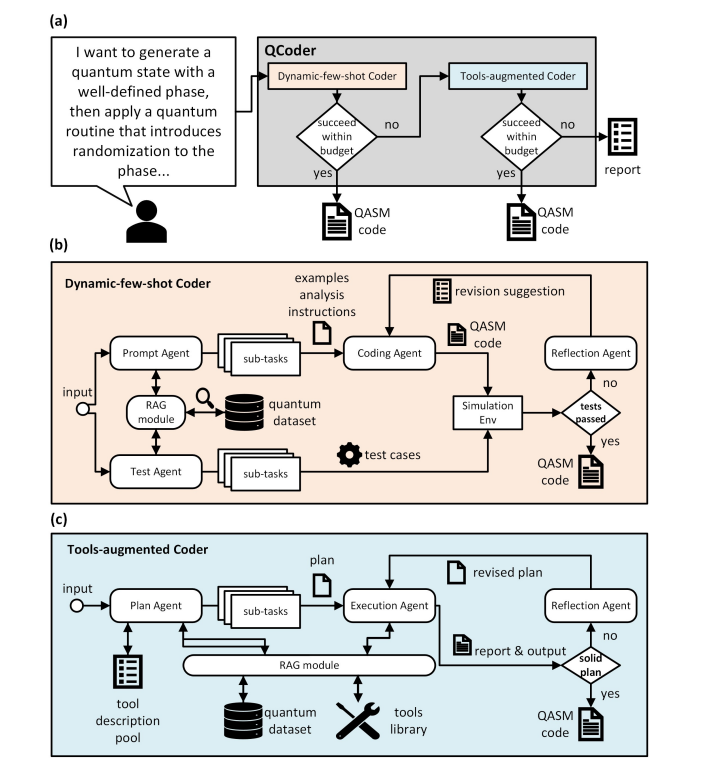
QAgent: An LLM-based Multi-Agent System for Autonomous OpenQASM programming
-
链接: arXiv:2508.20134
-
核心亮点:构建基于大语言模型的多智能体系统,实现量子程序的自动生成,降低OpenQASM编程门槛,助力非专家利用NISQ设备实现量子优势。
-
-
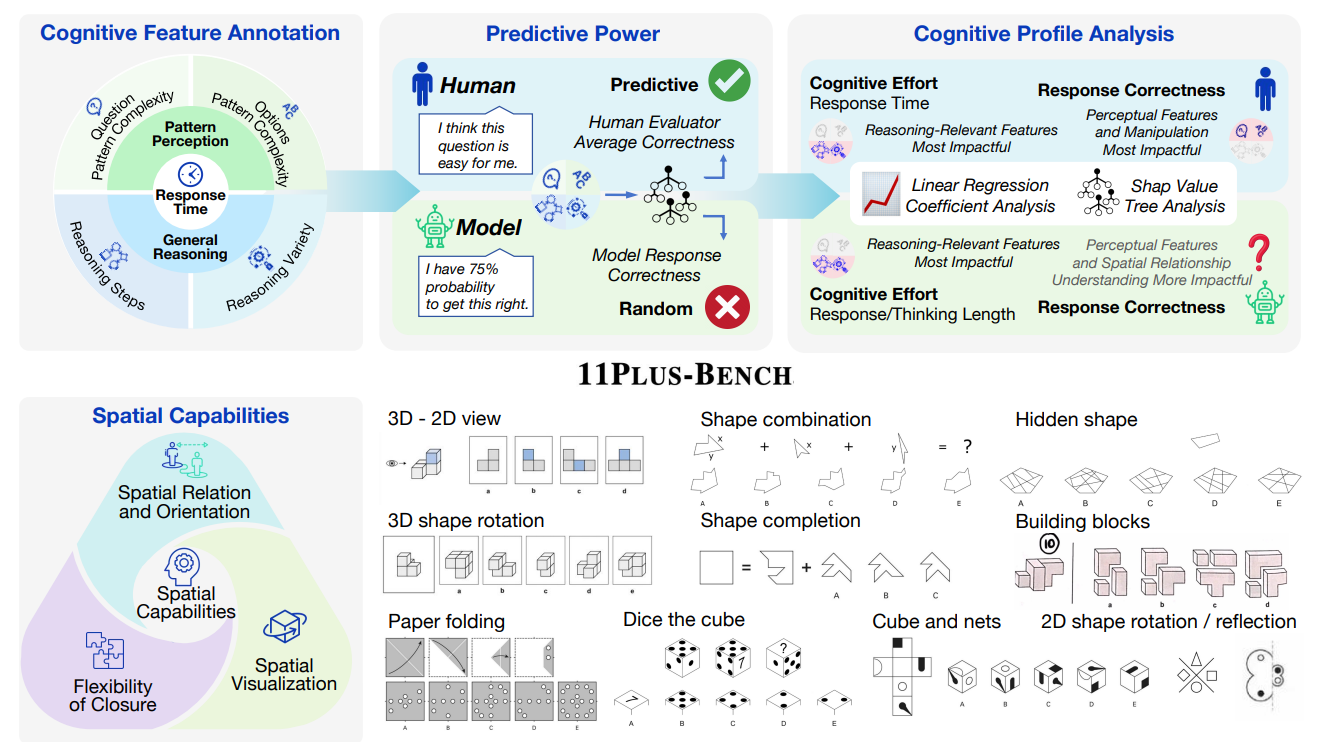
11Plus-Bench: Demystifying Multimodal LLM Spatial Reasoning with Cognitive-Inspired Analysis
-
链接: arXiv:2508.20068
-
核心亮点:受人类认知启发设计空间推理基准,系统评估多模态大语言模型的空间感知与推理能力,揭示MLLM在类人空间认知上的局限性。
-
七、多语言与低资源场景
-
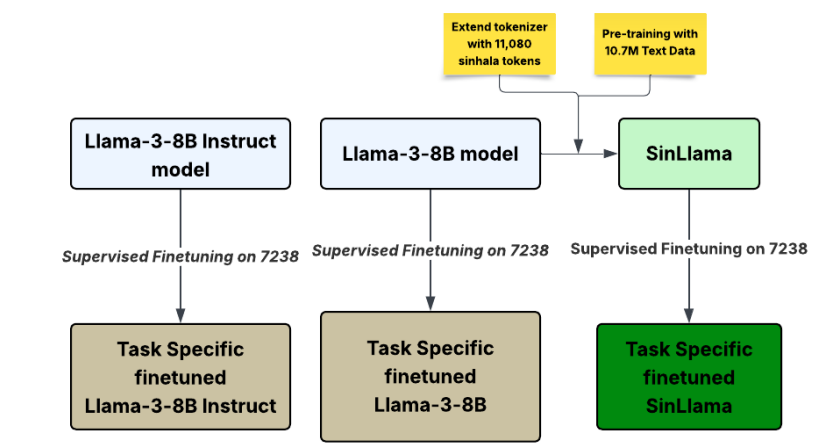
SinLlama -- A Large Language Model for Sinhala
-
链接: arXiv:2508.09115
-
核心亮点:针对僧伽罗语等低资源语言,扩展多语言LLM的分词器并在1000万僧伽罗语语料上持续预训练,构建首个面向该语言的解码器大模型。
-
-
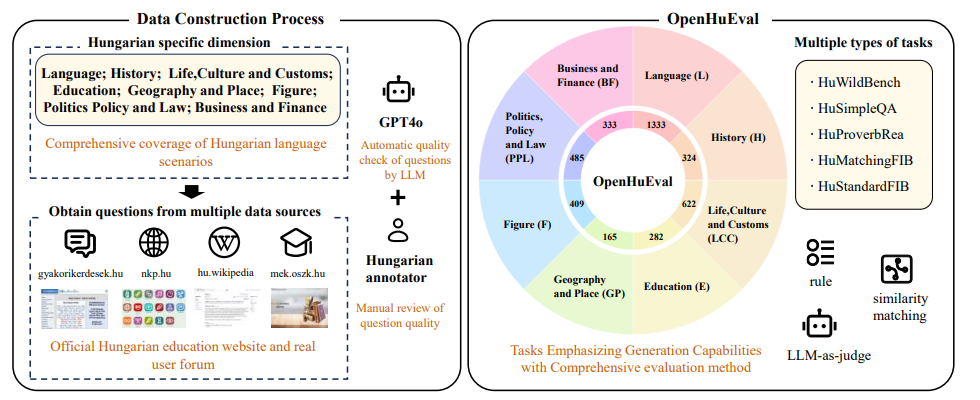
OpenHuEval: Evaluating Large Language Model on Hungarian Specifics
-
链接: arXiv:2503.21500
-
核心亮点:首个专注于匈牙利语特性的LLM评估基准,基于真实用户查询构建,强调生成能力和文化特异性评估,填补低资源语言评估工具的空白。
-
➔➔➔➔点击查看原文,获取大模型周报合集![]() https://mp.weixin.qq.com/s/eM8lWELUsYtqMX-uRt8nKA
https://mp.weixin.qq.com/s/eM8lWELUsYtqMX-uRt8nKA

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)