智能简历筛选案例拆解:基于LlamaIndex+LangChain的框架开发
框架的核心价值在于抽象化处理。LangChain 的 RunnableWithMessageHistory 把复杂的多轮对话状态管理抽象成简单的封装调用,很大程度提升开发效率。但是,高层抽象也带来调试挑战。相比之下,原生开发虽然繁琐,但问题定位相对直接。
简历筛选场景的三大核心痛点、包含数据处理流水线、双层知识存储引擎,以及基于 LCEL 对话式 RAG 应用链的核心架构,最后完整的演示下框架化的开发流程并进行效果验证。

上一篇文章介绍了使用基础组件,实现企业规章制度 RAG 问答的案例。这种原生开发方式虽然有助于更直观的理解 RAG 原理,但在面对更复杂的业务场景时,开发效率和功能扩展性方面的局限就会很明显。尤其是包含异构文件整合、结构化信息提取和多轮对话交互的综合性应用,引入成熟的开发框架成为合理选择。
正本清源:原生RAG入门案例拆解(企业规章制度问答)+ 技术栈全景
这篇基于两个月前,我给一家猎头公司做项目咨询中的简历筛选场景,来演示下如何利用 LlamaIndex 和 LangChain 两大主流框架,构建一个智能简历筛选系统。
这篇试图说清楚:
简历筛选场景的三大核心痛点、包含数据处理流水线、双层知识存储引擎,以及基于 LCEL 对话式 RAG 应用链的核心架构,最后完整的演示下框架化的开发流程并进行效果验证。
1、业务背景
传统的简历处理方式,无论是人工审阅还是基于关键词的初步筛选,都存在固有的局限性。这篇以当下比较火热的 AI 产品经理岗位招聘为例,从异构文件的统一接入、精准筛选与模糊检索的平衡,以及信息检索到决策辅助三个维度,拆解下该场景面临的三个潜在痛点。
1.1异构文件的统一问题
企业在招聘过程中,收到的简历文件格式通常横跨 PDF、DOCX 等多种类型。这两种主流格式在内部结构上差别很大。PDF 文件注重版式的精确固定,文本内容的提取往往伴随着换行、分页等格式噪声;而 DOCX 文件则以内容流为核心,结构相对清晰但同样存在样式多变的问题。
在不使用框架的情况下,需要给每一种文件格式编写独立的解析逻辑,例如使用 PyMuPDF 库处理 PDF 文件,使用 python-docx 库处理 DOCX 文件。这将导致数据加载模块的代码维护起来有些费劲。每次需要支持新的文件格式时,都必须对核心代码进行修改和扩展。
1.2精准筛选与模糊检索的平衡
招聘需求(JD)中通常包含必须满足的硬性指标,如”工作经验超过 5 年且具备 RAG 项目实战经验“。智能简历筛选系统需要能够像数据库一样,对这类条件进行精准识别和逻辑判断。但是,传统的关键词匹配方式严重依赖精确的字符串匹配,无法处理表述方式的差异。当候选人简历中使用“检索增强生成技术”而不是“RAG”的时候,关键词检索就会漏掉这部分信息。
同时,许多候选人的能力描述可能与招聘需求的字面表述不完全一致,但语义上高度相关。例如,招聘需求中要求“LangChain 框架实践项目经验”,但是候选人简历中可能表述为“负责 RAG 流水线技术实现”或“主导智能问答系统构建”。这些表述在语义上高度关联,基于向量的语义检索能够有效识别这种潜在匹配。
1.3从信息检索到决策辅助
招聘决策的关键在于对多个候选人进行标准化的横向对比。这也就要求智能简历筛选系统不仅能找到信息,更能以结构化且一目了然的方式,展示每个候选人的评估档案。例如,自动生成所有候选人的核心能力对比列表。以及进一步支持招聘人员通过连续的追问,这要求系统具备上下文记忆和深度推理的能力。
2、核心架构
整个系统采用分层架构设计,由三个核心模块构成:位于底层的数据处理流水线、双层知识存储引擎,以及面向用户的对话式 RAG 应用链。
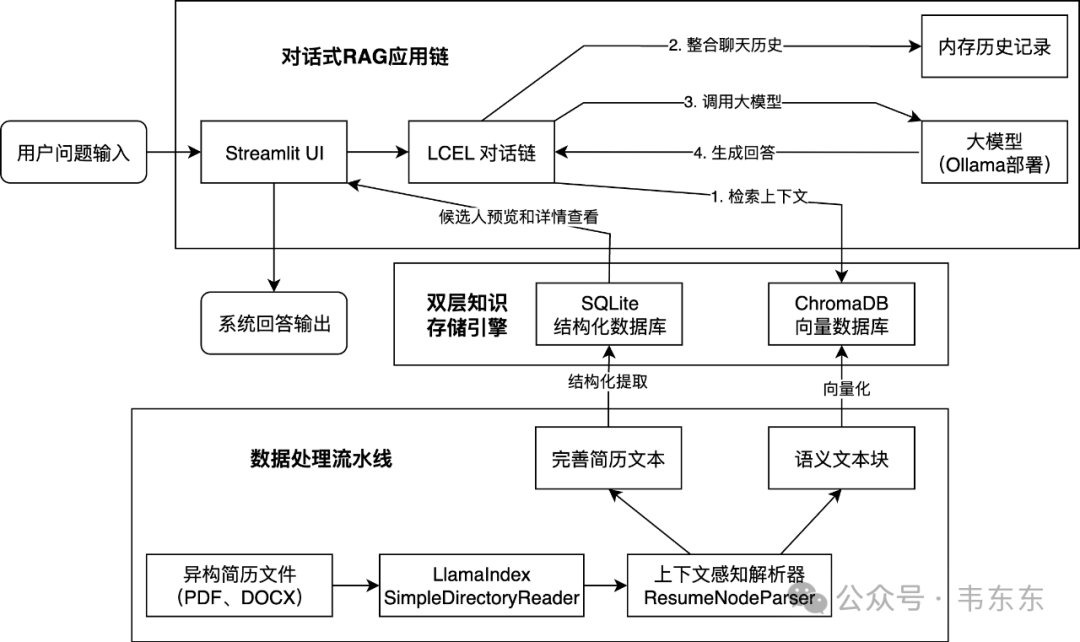
2.1数据处理流水线
数据处理流水线的入口是多格式的简历文件(PDF、DOCX 等)。系统利用 LlamaIndex 提供的 SimpleDirectoryReader 组件,实现对指定目录下不同格式文件的自动加载。这个组件统一了底层不同文件类型的解析接口,为上层处理提供了标准化的 Document 对象输入。
为了更加精准的实现分块,这里设计了一个上下文感知解析器(ResumeNodeParser)。这个解析器专门针对简历的结构特点,通过正则表达式识别“工作经历”、“项目经历”等章节标题,进行语义导向的切分。这种方式可以保证切分出的文本块在语义上的完整性,还能在解析阶段就为文本块赋予类型元数据。
2.2双层知识存储引擎
这个双层设计是这个系统架构的重要特点,通过不同的存储方式,分别支撑 RAG 问答和结构化概览两种不同的应用需求。
ChromaDB 向量数据库
数据处理流水线输出的语义文本块,会经过向量化处理,即通过嵌入模型将其转换为高维数学向量。这些向量与原始文本块一同存入 ChromaDB 向量数据库。ChromaDB 作为专门的向量数据库,相比上篇文章使用的 FAISS 索引库,在集成便利性和数据管理方面具有优势。
SQLite 结构化数据库
与此同时,数据处理流水线输出的完整简历文本,会经历一个结构化提取过程。这个过程调用大模型,根据预定义的 Pydantic 模型(Python 数据验证库,用于定义结构化数据格式),从纯文本中抽取出候选人的姓名、工作年限、项目经验、优劣势分析等关键信息,形成一份标准化的结构化档案。这份档案最终被存入 SQLite 结构化数据库(一个轻量级的关系型数据库)。这个数据库的作用是为最后的用户界面提供即时候选人信息查询服务,支撑系统的候选人概览和详情展示功能。
2.3对话式 RAG 应用链
这个模块采用 Streamlit UI 作为前端界面(一个 Python Web 应用框架),关键逻辑由基于 LCEL 构建的对话链驱动。当用户输入问题后,系统启动以下 RAG 流程:
1.检索上下文:LCEL 对话链首先将用户问题向量化,并向 ChromaDB 向量数据库发起检索请求,获取与问题语义最相关的简历文本块作为上下文。
2.整合聊天历史:为了支持多轮对话,对话链会从内存历史记录中读取之前的交互内容,理解当前问题的完整语境。
3.调用大模型:对话链将用户问题、检索到的上下文以及聊天历史,一同组装成一个结构化的提示,并发送给大模型进行处理。
4.生成回答:大模型在充分理解所有输入信息的基础上,生成一个精准、连贯的回答,并将结果返回给对话链。最终,该回答通过 Streamlit UI 呈现给用户,完成一次交互。
3、技术实现
这部分来演示下上述三个模块背后的一些核心代码逻辑。整个过程依赖 LlamaIndex 进行数据处理与索引构建,借助 Pydantic 模型实现结构化信息提取,并利用 LCEL 灵活编排带记忆功能的对话链。最终,通过 Streamlit 把所有后端能力封装成一个直观的 Web 应用界面,并进行实战效果验证。
3.1数据处理引擎
全局模型配置
在进行任何数据处理之前,首先需要为 LlamaIndex 进行全局模型配置,指定后续流程中使用的大模型(用于结构化信息提取)和嵌入模型(用于向量化)。系统通过 config.py 配置文件统一管理模型参数和环境设置
# config.py 配置示例
def get_config():
"""
提供应用程序的配置。
"""
return {
"model": {
"llm_model": "qwen3:30b", # 大模型
"ollama_embedding_model": "bge-m3", # 嵌入模型
"collection_name": "resume_collection"
},
"env": {
"ollama_host": "http://localhost:11434", # Ollama服务地址
"ollama_timeout": 120.0 # 请求超时时间
}
}配置字典随后在 RAGEngine 的初始化过程中被加载,并通过 _setup_llamaindex_settings 方法应用到 LlamaIndex 的全局配置中。
# core/rag_engine.py ->_setup_llamaindex_settings 方法
from llama_index.core import Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import
OllamaEmbedding
# ...
Settings.llm = Ollama(
model=self.config['model']['llm_model'],
base_url=self.config['env']['ollama_host'],
request_timeout=float(self.config['env']['ollama_timeout'])
)
Settings.embed_model = OllamaEmbedding(
model_name=self.config['model']['ollama_embedding_model'],
base_url=self.config['env']['ollama_host']
)通过这种配置与代码分离的策略,后续所有 LlamaIndex 组件都会自动调用此处指定的 Ollama 本地化部署模型,确保了模型调用的一致性。
数据处理流水线
RAGEngine 类的 build_index 方法负责编排完整的数据处理流水线。这个方法首先使用 SimpleDirectoryReader 统一加载 documents 目录下的 PDF 和 DOCX 文件,然后调用自定义解析器 ResumeNodeParser,把原始 Document 对象转换为结构化的 TextNode 对象列表(LlamaIndex 中表示文本块的标准化数据结构)。
# core/rag_engine.py -> build_index 方法核心逻辑
from llama_index.core import SimpleDirectoryReader
# ...
# 1. 统一加载异构文件
reader =
SimpleDirectoryReader(input_files=files_to_process)
documents = reader.load_data()
# 2. 调用自定义解析器生成节点
parser = ResumeNodeParser()
all_nodes =
parser.get_nodes_from_documents(documents)
#
... 后续的索引构建与结构化提取将基于 all_nodes 和 documents 进行3.2简历节点解析器
通用文本分块策略对于简历这类具有明确章节结构的文档,往往效果不好。这个系统实现了一个自定义的 ResumeNodeParser,能够识别简历的上下文结构,实现更精准的语义分割。这个组件的实现位于 core/rag_engine.py中,设计思想包含以下三点。
1.基于章节标题分割:解析器通过正则表达式识别“核心技能”、“工作经历”等章节标题,把这些标题出现的位置作为文本块的分割点。
2.注入语义元数据:在创建 TextNode 时,解析器会把识别出的章节类型(如 work_experience)作为元数据附加到节点上。
3.二次精细分割:对于内容较长的章节(如“工作经历”),解析器会进行二次分割,确保每个文本块的长度适中。
# core/rag_engine.py ->ResumeNodeParser._parse_nodes 方法
import re
from llama_index.core.node_parser import
NodeParser
from llama_index.core.schema import TextNode
# ...
class ResumeNodeParser(NodeParser):
def
_parse_nodes(self, documents: List[Document], **kwargs: Any) ->
List[BaseNode]:
all_nodes: List[BaseNode] = []
# ...
# 1. 定义章节标题与类型的映射
section_map = {
"核心技能":
"skills", "工作经历": "work_experience",
"项目经历":
"projects", "教育背景": "education",
}
# 2. 使用正则表达式在文本中找到所有章节标题
pattern = r"^\s*(?i)(" +
"|".join(section_map.keys()) + r")[\s\n:]*"
matches = list(re.finditer(pattern, full_text, re.MULTILINE))
# 3. 遍历匹配结果,根据标题边界创建块
for i, match in enumerate(matches):
# ... 省略边界计算代码 ...
chunk_text = full_text[chunk_start:chunk_end].strip()
# 4. 获取标题并分配元数据
title = match.group(1)
chunk_type = section_map.get(title, "others")
# 5. 创建并添加带有元数据的TextNode
node = TextNode(text=chunk_text, metadata=doc_parts[0].metadata.copy())
node.metadata["chunk_type"] = chunk_type
all_nodes.append(node)
# ...
return all_nodes3.3结构化信息存储
系统选用轻量级的 SQLite 数据库,实现持久化地存储从简历中提取出的结构化信息,并通过一个专门的数据访问类 StructuredStore 来封装所有数据库操作,实现业务逻辑与数据存储的解耦。这个实现过程可以分为以下两个主要步骤。
设计数据存储表
在 core/structured_store.py 的 _create_table 方法中,定义了名为 candidates 的数据表结构。这个表将最常用于候选人概览和排序的字段设为独立列,而把完整的候选人档案序列化为 JSON 字符串后存储在 profile_json 列中,兼顾了查询效率与信息完整性。
# core/structured_store.py ->_create_table 方法
import sqlite3
class StructuredStore:
def
_create_table(self):
with sqlite3.connect(self.db_path) as conn:
conn.execute("""
CREATE TABLE IF NOT EXISTS
candidates (
name TEXT PRIMARY KEY,
file_name TEXT,
overall_score INTEGER,
recommendation TEXT,
summary TEXT, profile_json
TEXT
)
""")数据的写入和查询接口
数据表的写入操作由 save_profile 方法实现,接收一个 CandidateProfile Pydantic 对象,序列化后存入数据库。这个方法使用 INSERT OR REPLACE 语句,保证了数据摄取流程的幂等性(多次执行相同操作产生相同结果的特性)。
# core/structured_store.py -> save_profile方法
from .schemas import CandidateProfile
class StructuredStore:
def
save_profile(self, profile: CandidateProfile, file_name: str):
with sqlite3.connect(self.db_path) as conn:
conn.execute("""
INSERT OR REPLACE INTO
candidates (...) VALUES (?, ?, ?, ?, ?, ?)
""", (
profile.name, file_name,
profile.overall_match_score,
profile.recommendation,
profile.summary, profile.json()
))3.4基于 Pydantic 的结构化信息提取链
结构化提取的实际效果,在很大程度上取决于提示词的设计质量。智能简历筛选系统在 core/application.py 中构建了一个高指令性的提示词模板,其中包括了角色扮演、动态注入招聘需求、明确评估规则以及集成格式指令等关键要素。提示词模板的示例内容如下。
# core/application.py -> _initialize_extraction_chain 提示词模板
prompt_template_str = """
你是一位极其严格和挑剔的AI招聘专家。你的唯一目标是根据下面提供的"职位描述(JD)",对"简历原文"进行无情的、差异化的评估。
**职位描述 (JD):**
---
{jd_content}
---
**核心评估指令:**
1. **严格对照**: 严格将简历内容与JD中的"任职要求"进行逐条比对。
2. **RAG经验是关键**: ...
**JSON输出格式指令:**
{format_instructions}
**简历原文:**最后,系统利用 LCEL 把输入、提示词、大模型和输出解析器优雅地串联起来,形成一条自动化的处理链。其中关键的 _initialize_extraction_chain 方法的代码实现示例如下。
# core/application.py ->_initialize_extraction_chain
from langchain_core.prompts import
ChatPromptTemplate
from langchain_core.output_parsers import
PydanticOutputParser
from langchain_core.runnables import
RunnablePassthrough
# ...
parser =
PydanticOutputParser(pydantic_object=CandidateProfile)
prompt =
ChatPromptTemplate.from_template(template=prompt_template_str)
self.extraction_chain = (
{
"resume_content": RunnablePassthrough(),
"jd_content": lambda x: jd_processor.get_full_jd_text()
}
|
prompt.partial(format_instructinotallow=parser.get_format_instructions())
|
self.llm
|
parser
)
3.5集成带记忆的对话式 RAG 链
为了提供流畅的多轮对话体验,智能简历筛选系统必须具备管理对话记忆的能力。LangChain 的 RunnableWithMessageHistory 类为此提供了标准化的解决方案。
支持历史消息的提示词
与单次提取任务不同,对话式任务的提示词需要包含历史交互信息。系统在 _initialize_rag_chain_with_history 方法中,使用了 LangChain 的 MessagesPlaceholder 来实现这一点。
# core/application.py ->_initialize_rag_chain_with_history 提示词模板
from langchain_core.prompts import
ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的AI简历筛选助手...职位描述(JD):\n{jd_content}"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "候选人简历上下文:\n{context}\n\n问题: {question}")
])MessagesPlaceholder(variable_name="chat_history")的作用是在提示词中预留一个占位符,LangChain 的记忆机制会自动将历史对话消息填充到这个位置,从而大模型能够基于完整的对话上下文生成回答。
基于会话的内存管理
为了隔离不同用户的对话,系统需要为每个独立的会话维护一份独立的聊天历史。ResumeApplication 类通过一个字典 self.chat_histories 和一个辅助方法 get_session_history 来实现此功能。
# core/application.py -> 内存管理核心逻辑
from langchain_core.chat_history import
BaseChatMessageHistory
from langchain_community.chat_message_histories
import ChatMessageHistory
# ...
class ResumeApplication:
def
__init__(self, ...):
# ...
self.chat_histories: Dict[str, BaseChatMessageHistory] = {}
def
get_session_history(self, session_id: str) -> BaseChatMessageHistory:
"""根据session_id获取或创建聊天历史记录。"""
if session_id not in self.chat_histories:
self.chat_histories[session_id] = ChatMessageHistory()
return self.chat_histories[session_id]当处理请求的时候,系统会传入一个唯一的 session_id。get_session_history 方法会根据此 ID 查找或创建一个 ChatMessageHistory 实例,确保每个用户的对话历史得到独立管理。
封装 RAG 链
最后一步是将基础的 RAG 链与内存管理机制进行绑定。RunnableWithMessageHistory 承担了封装和连接的功能。它封装了一个基础 RAG 链,并自动为其注入了状态管理(记忆)能力。
3.6Streamlit 应用与效果验证
系统选用 Streamlit 框架,把所有后端能力封装在 app.py 脚本中。前端的具体实现这部分不做赘述了,感兴趣的可以后续在星球查看源码,这部分直接介绍下测试文档后进行效果演示。
JD 要求
所有筛选和评估逻辑围绕“AI 产品经理”职位展开。该岗位主要负责 RAG、AI 工作流等前沿技术在新能源汽车制造领域的产品化应用。具体查看下面截图

四份简历
测试使用四份背景各异的候选人简历(人名为虚构),分别以 PDF 和 DOCX 格式存储。这四位候选人在关键评估维度上形成了很好的对比样本。
|
候选人 |
工作年限 |
产品经验 |
RAG技术能力 |
制造业背景 |
|
张伟 |
8年 |
丰富 |
实战经验 |
高度匹配 |
|
李静 |
6年 |
转型中(2年) |
技术专家 |
无 |
|
赵敏 |
6年 |
丰富 |
应用经验 |
无 |
|
王磊 |
10年 |
非常丰富 |
无 |
高度匹配 |

候选人预览
在后台执行 streamlit run app.py 命令启动应用后,在前端界面的侧边栏点击“执行数据摄取”按钮,系统会自动完成对 documents 目录下所有简历的解析、结构化提取和索引构建。候选人概览标签页展示了数据处理与分析的结果。
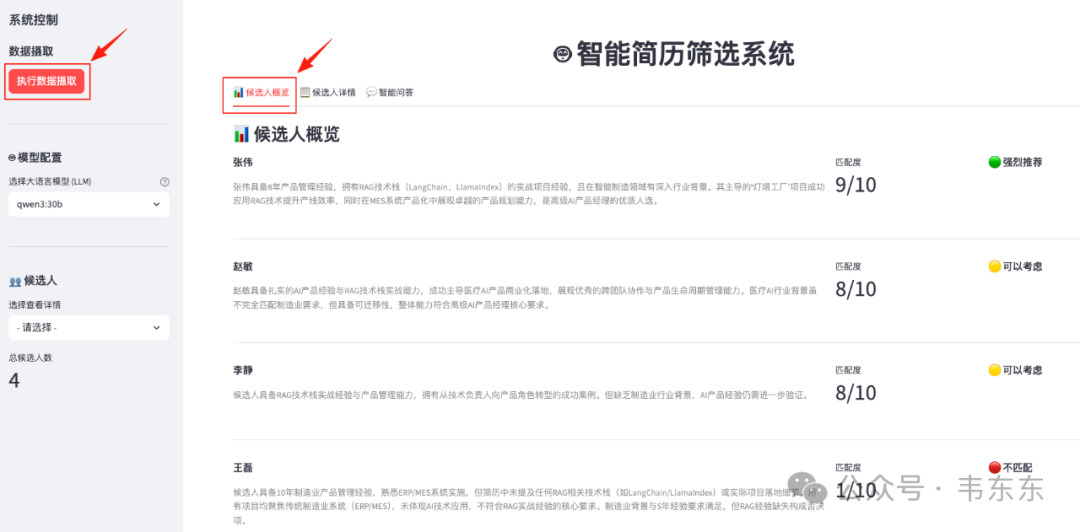
这个页面直观地呈现了四个候选人的 AI 评估摘要,包括匹配度评分、推荐等级(强烈推荐、可以考虑、不匹配)和一句话总结。这体现了结构化信息提取链的处理效果,以及 SQLite 结构化存储引擎的支撑作用。系统通过 1-10 分的量化评分机制,结合“强烈推荐”、“可以考虑”、“不匹配”等直观的推荐等级,以及大模型生成的核心能力摘要,实现了候选人的快速筛选和排序。
候选人详情
在候选人概览视图的基础上,招聘人员可以对感兴趣的候选人进行进一步了解。比如在左侧边栏的“候选人”下拉列表中选择“李静”,并切换到“候选人详情”标签页后,系统会呈现一份由 AI 自动生成的完整评估报告。
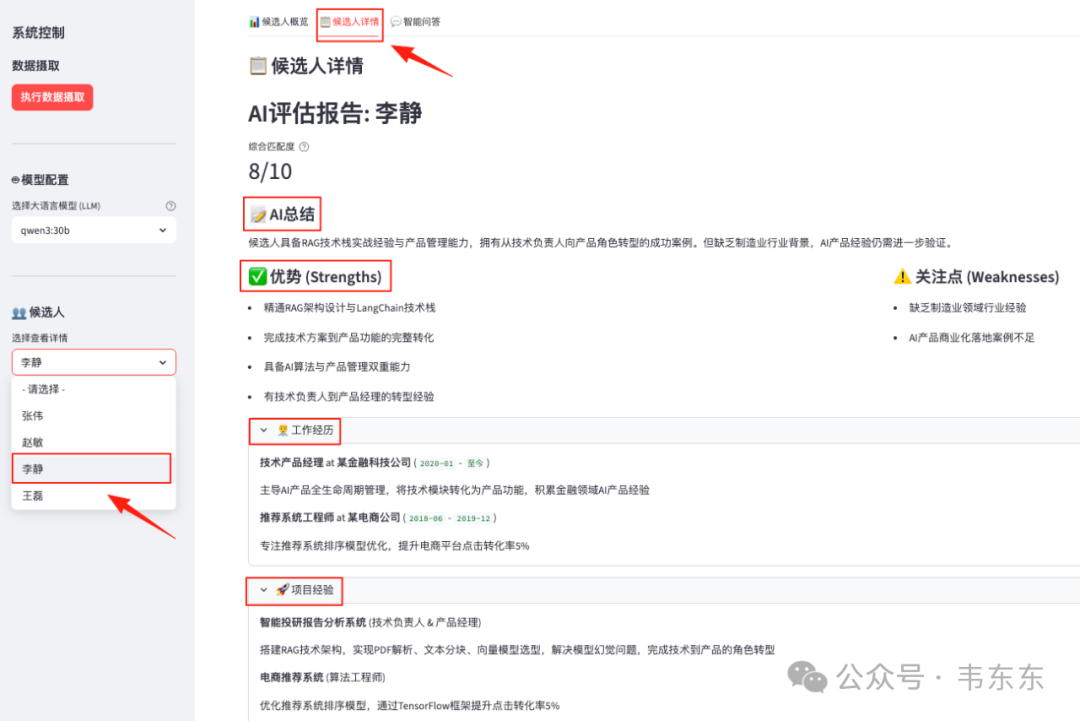
智能问答页面
系统侧边栏的“模型配置”下拉框,允许招聘人员根据本地 Ollama 服务中已下载的模型列表,随时切换驱动问答的大模型。
单轮问答:“请找出所有具备 RAG 项目实战经验的候选人,并以表格形式展示他们的姓名、相关项目名称、使用的技术栈和量化成果。”
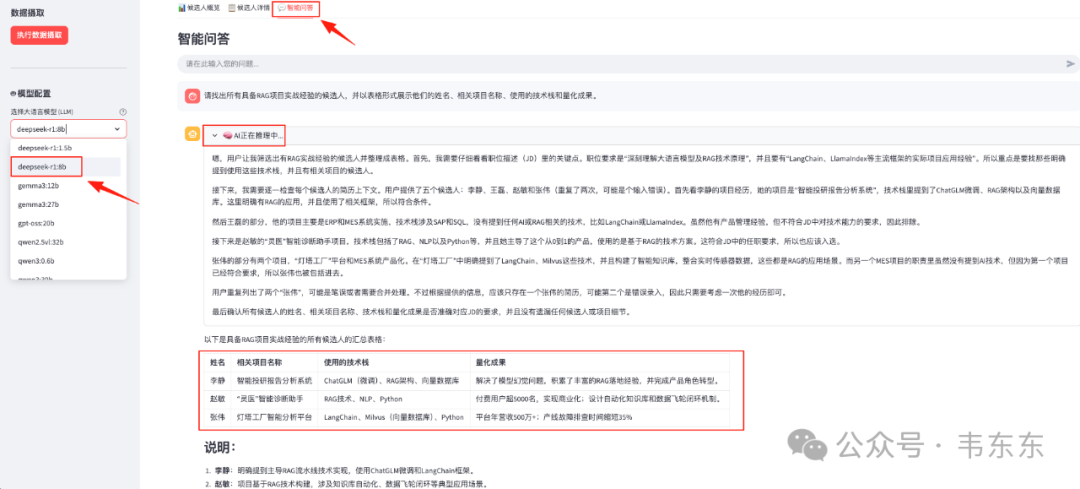
系统不仅返回了格式规整的 Markdown 表格,还在答案上方提供了一个可以折叠的思维链。
多轮问答 1:“张伟和李静哪个更适合这个岗位?”
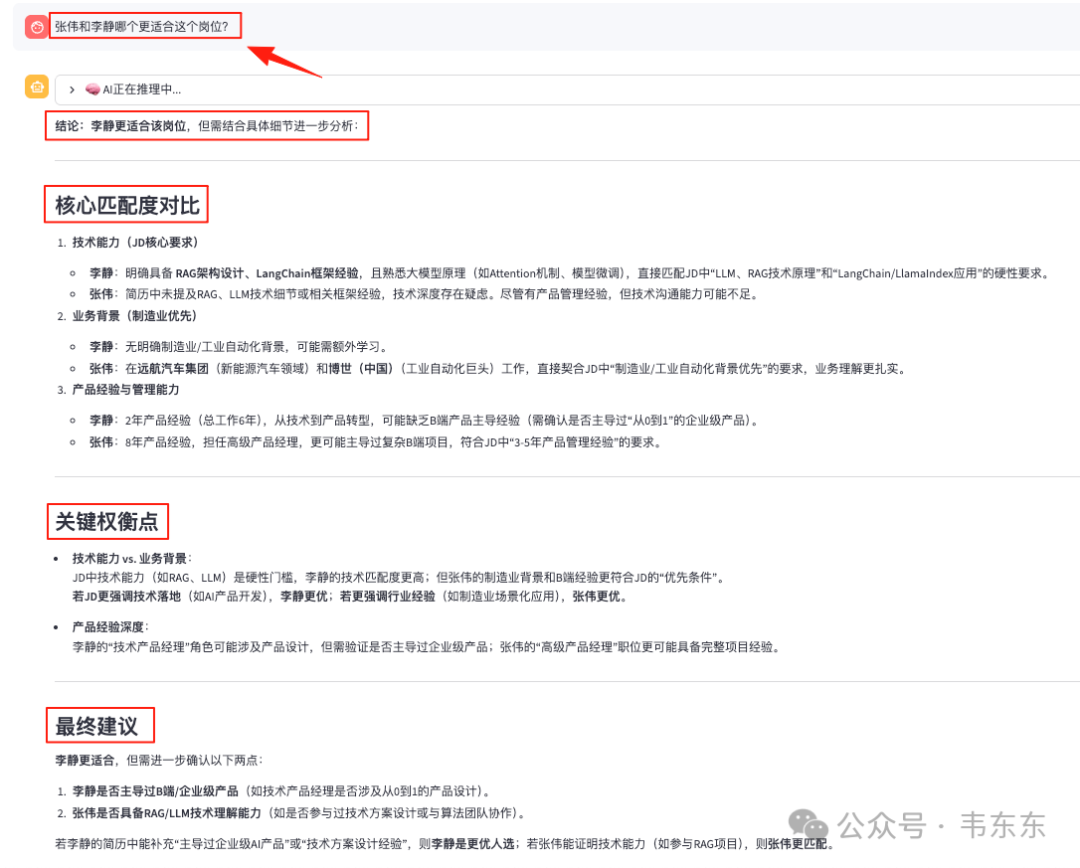
多轮问答 2:“这个 RAG 架构设计的经验,在她的哪个项目得到了体现?”
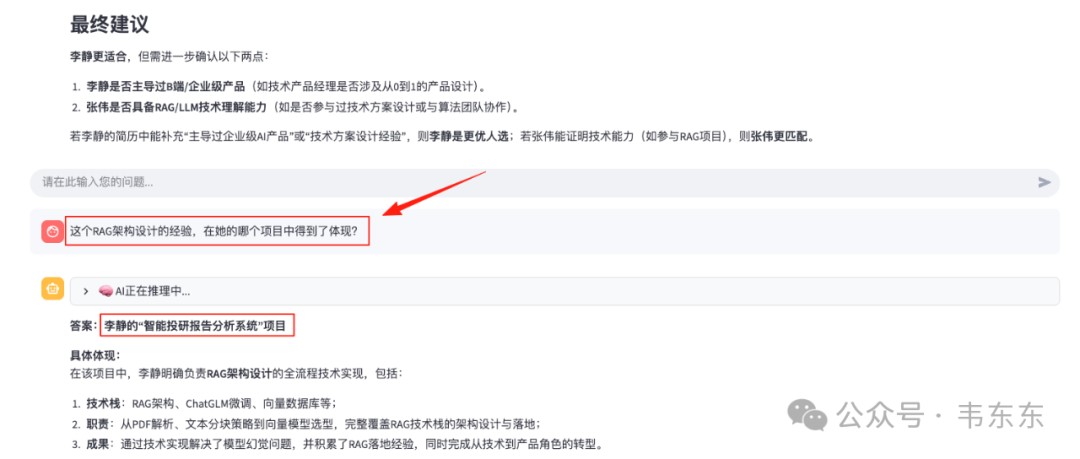
系统成功地理解了代词“她”(指代李静)和上下文中提及的“RAG 架构设计经验”,并精准地将这项抽象技能与“智能投研报告分析系统”这一具体项目关联起来。这有力地证明了 RunnableWithMessageHistory 组件的有效性,系统具备了真正连贯、有深度的对话能力。
4、写在最后
框架的核心价值在于抽象化处理。LangChain 的 RunnableWithMessageHistory 把复杂的多轮对话状态管理抽象成简单的封装调用,很大程度提升开发效率。但是,高层抽象也带来调试挑战。相比之下,原生开发虽然繁琐,但问题定位相对直接。
4.1框架选型
LlamaIndex 在数据处理与索引构建方面较为专业,丰富的 NodeParser、Reader 等组件可以支持精细化数据处理。LangChain 在应用链编排、Agent 构建等方面更具优势,LCEL 的灵活性和强大组件生态使其成为构建复杂应用逻辑的首选。在复杂项目中,采用混合模式——使用 LlamaIndex 构建高效的数据处理引擎,将其作为 LangChain 应用链中的组件进行调用往往能实现更好的效果。
4.2从问答到自主 Agent
这篇文章定位上还是个面向初学者的入门案例演示,本质上仍是“被动式”系统。对于有基础的盆友,可以在此基础上把 LCEL 对话链升级为基于 ReAct 思想的 Agent。封装一系列外部 API 作为 Agent 可调用的工具,例如 schedule_interview 调用公司日历系统安排面试,send_assessment_test 调用在线测评系统发送技术笔试,request_portfolio 调用邮件系统索要候选人作品集,这样可以实现更加实用的招聘助理的价值。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献216条内容
已为社区贡献216条内容

所有评论(0)