如何训练微调本地模型(进阶)?从 Llama3 到 ChatGLM 的实战指南
本文将为你提供一份详尽的《本地大模型训练与微调指南》,涵盖主流模型如 Llama3、ChatGLM、Qwen 等,并结合 工具资源,助你实现个性化 AI 模型定制。
随着开源大模型的普及,越来越多开发者和研究者希望不仅仅“使用”这些模型,而是能够 根据自己的需求对它们进行训练或微调 。本文将为你提供一份详尽的《本地大模型训练与微调指南》,涵盖主流模型如 Llama3、ChatGLM、Qwen 等,并结合 工具资源,助你实现个性化 AI 模型定制。
1
一、什么是模型训练与微调?
✅模型训练(Training)
指的是从头开始训练一个语言模型,通常需要大量数据和强大的算力资源(如多块 GPU),适合研究机构或大型团队。
✅ 模型微调(Fine-tuning)
是指在已有预训练模型的基础上,针对特定任务或领域进行进一步训练,例如:
让模型更懂中文提升代码生成能力构建企业知识问答系统微调门槛相对较低,普通开发者也能操作,是当前最实用的技术路径之一。
2
二、微调本地模型的核心流程
📌 步骤概览:
准备环境(Python + CUDA + 显卡)下载基础模型(Llama3、ChatGLM、Qwen 等)准备训练数据集(JSON/CSV 格式)使用 LoRA 或 QLoRA 进行高效微调导出模型并部署到本地推理环境(如 Ollama、vLLM)
3
三、推荐模型与工具清单
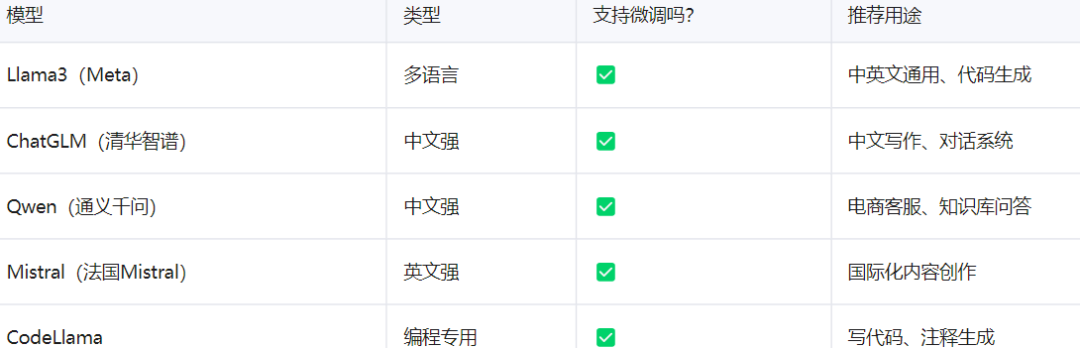
📌 微调工具推荐:
LLaMA-Factory (一站式训练框架)LoRA / QLoRA (低资源微调技术)Hugging Face TransformersPEFT (Parameter-Efficient Fine-Tuning 工具包)
4
四、实战教程:用 LLaMA-Factory 微调 Llama3 模型(中文字幕版)
✅ 步骤 1:安装 LLaMA-Factory(基于 HuggingFace)

✅ 步骤 2:启动训练界面(支持 Web UI)

打开浏览器访问 ( http://localhost:7860 ) 即可进入图形化界面。
✅ 步骤 3:选择模型 & 加载数据集
模型名称:meta-llama/Llama-3-8B 数据集格式:支持 JSON、TXT、CSV、Alpaca 格式
数据示例:

✅ 步骤 4:设置训练参数(建议初学者使用默认配置)
Training Type:SFT(监督式微调)Model Type:Llama3Output Dir:./saves/llama3-chinese
✅ 步骤 5:开始训练
点击“Start Training”,系统会自动下载模型并开始微调过程。
⚠️ 建议使用 NVIDIA RTX 3090 或更高显卡,内存至少 24GB。
5
五、进阶技巧:如何高效微调本地模型?
5.1
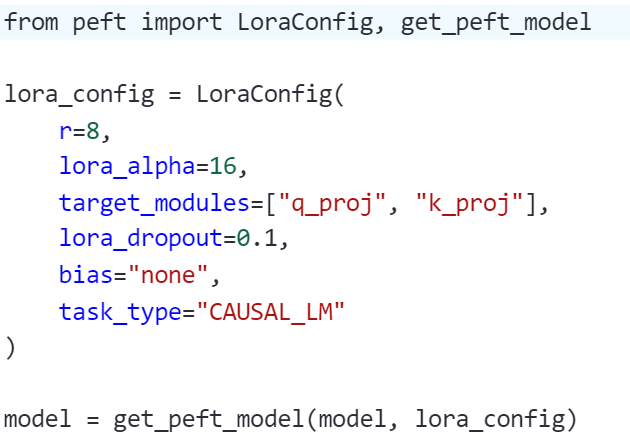
1. 使用 LoRA 技术(低秩适配)
LoRA 是一种轻量级微调技术,它不会修改原始模型权重,而是通过新增少量参数来调整输出行为,具有以下优势:
节省显存快速切换不同风格模型可叠加多个 LoRA 模型用于多场景切换
示例命令(使用 PEFT):
5.2
2. 使用 QLoRA(量化 + LoRA)
QLoRA 是一种结合了 模型量化 和 LoRA 微调 的高效训练方法,可以在 24G 显存下运行 Llama3-8B 的训练任务。
**实现步骤:**安装依赖:

加载量化模型:

配置 LoRA 并训练即可。
5.3
3. 使用 Prompt Tuning(无需训练)
如果你不想训练整个模型,也可以使用 Prompt Tuning(前缀提示词学习)方式,让模型记住你设定的“前置指令”。
示例思路:

6
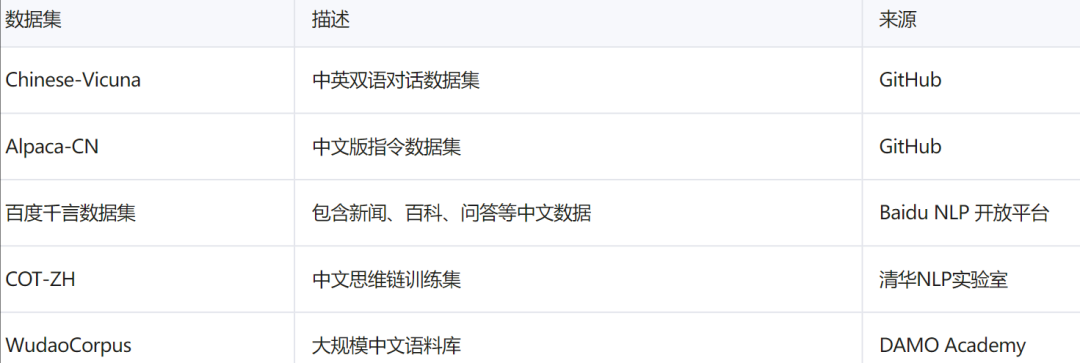
六、推荐中文训练数据集(适合中文模型)
7
七、模型训练后如何部署?
训练完成后,你可以将模型部署为以下形式:
7.1
✅ 方法 1:转换为 GGUF 格式供 llama.cpp 使用

然后使用 llama.cpp 启动:

7.2
✅ 方法 2:部署到 Ollama(需支持自定义模型)
目前 Ollama 不支持直接加载自定义模型,但你可以构建一个 Modelfile 来封装你的微调模型:

然后构建并运行:

7.3
✅ 方法 3:部署为本地 API 服务(FastAPI + Transformers)
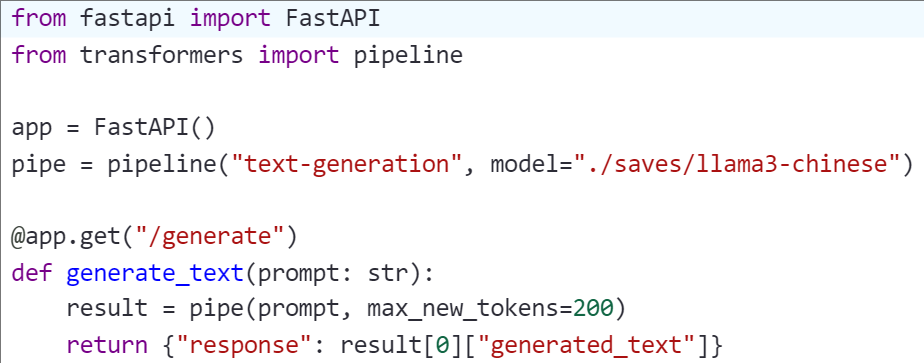
启动服务后,即可通过 /generate?q=xxx 发起请求。
8
八、常见问题解答(FAQ)
❓ Q1:没有高端显卡能微调吗?
✅ A1:可以使用 QLoRA 技术,在 24G 显存下训练 8B 模型;若无 GPU,也可使用云服务(如 Google Colab、阿里云 PAI、腾讯云 TI-ONE)
❓ Q2:微调后的模型还能用 Ollama 吗?
✅ A2:目前 Ollama 不支持直接加载微调模型,但可以通过 Modelfile 封装 LoRA 模型。
❓ Q3:微调后性能下降怎么办?
✅ A3:检查数据质量、学习率设置、是否过拟合。尝试使用早停(Early Stopping)、数据增强、正则化等方式优化。
❓ Q4:如何评估模型效果?
✅ A4:使用测试集、BLEU、ROUGE、METEOR 等指标进行评估,也可以人工打分对比输出质量。
9
九、结语:打造属于你的专属 AI 模型
微调本地大模型,不再是遥不可及的技术门槛。无论你是学生、AI 爱好者,还是企业用户,都可以通过本文介绍的方法,打造一个更懂你、更适合你业务场景的 AI 模型 。
从 Llama3 到 ChatGLM,从 LoRA 到 QLoRA,从训练到部署,我们已经进入了一个“人人可用、人人可改”的 AI 新时代。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献236条内容
已为社区贡献236条内容

所有评论(0)