【详细教程】本地部署DeepSeek+构建私有知识库+调用大模型API
本文主要介绍了用LMStudio部署大模型,并结合AnythingLLM构建本地知识库,后续简单介绍了如何调用大模型的在线API。
本文写于2月,正值DeepSeek横空出世之际,在全国掀起了一股本地部署的风潮,我也学习了一下,并将过程记录整理成文章。
本文主要介绍了用LMStudio部署大模型,并结合AnythingLLM构建本地知识库,后续简单介绍了如何调用大模型的在线API。
本教程部署方式简单,均采用可视化软件,易于上手,适合初学AI的小白感受和入门。
一、本地部署DeepSeek
1.下载安装LM Studio
https://lmstudio.ai/
下载文件后双击exe文件,根据下图安装提示按步骤进行安装
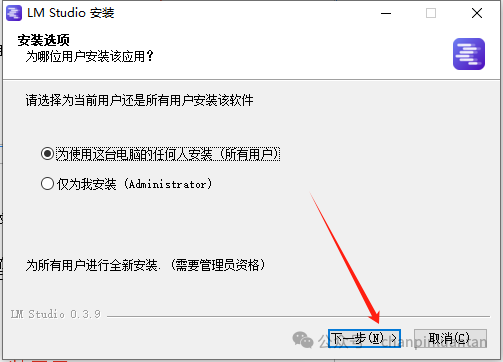
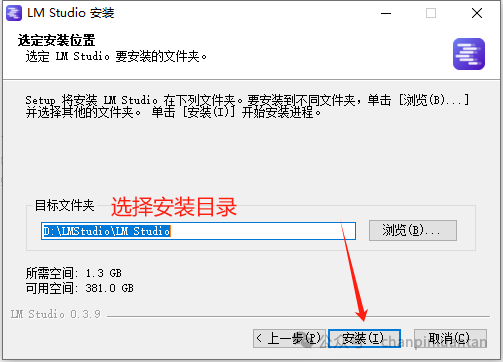
2.下载大模型文件
| 参数模型硬件要求如下,请根据本机的配置选择合适的模型 ✅ DeepSeek-R1-1.5B **CPU:**最低 4 核(推荐 Intel/AMD 多核处理器) **内存:**8GB+ **硬盘:**3GB+ 存储空间(模型文件约 1.5-2GB) **显卡:**非必需(纯 CPU 推理),若 GPU 加速可选 4GB+ 显存(如 GTX 1650) **场景:**低资源设备部署,如树莓派、旧款笔记本、嵌入式系统或物联网设备 ✅ DeepSeek-R1-7B **CPU:**8 核以上(推荐现代多核 CPU) **内存:**16GB+ **硬盘:**8GB+(模型文件约 4-5GB) **显卡:**推荐 8GB+ 显存(如 RTX 3070/4060) **场景:**中小型企业本地开发测试、中等复杂度 NLP 任务,例如文本摘要、翻译、轻量级多轮对话系统 ✅ DeepSeek-R1-8B **CPU:**8 核以上(推荐现代多核 CPU) **内存:**16GB+ **硬盘:**8GB+(模型文件约 4-5GB) **显卡:**推荐 8GB+ 显存(如 RTX 3070/4060) **场景:**需更高精度的轻量级任务(如代码生成、逻辑推理) ✅ DeepSeek-R1-14B **CPU:**12 核以上 **内存:**32GB+ **硬盘:**15GB+ **显卡:**16GB+ 显存(如 RTX 4090 或 A5000) **场景:**企业级复杂任务、长文本理解与生成 ✅ DeepSeek-R1-32B CPU: 16 核以上(如 AMD Ryzen 9 或 Intel i9) 内存: 64GB+ 硬盘: 30GB+ 显卡: 24GB+ 显存(如 A100 40GB 或双卡 RTX 3090) 场景:高精度专业领域任务、多模态任务预处理 ✅ DeepSeek-R1-70B **CPU:**32 核以上(服务器级 CPU) **内存:**128GB+ **硬盘:**70GB+ 显卡: 多卡并行(如 2x A100 80GB 或 4x RTX 4090) **场景:**科研机构/大型企业、高复杂度生成任务 |
| 从百度网盘下载 链接: https://pan.baidu.com/s/1x_Hj2QiQcwENbuCx6ysL1w 提取码: gdku |
| 网页在线下载(也可以在该网站下载其他本地模型,下载文件的格式为gguf) * 1.5B:https://hf-mirror.com/bartowski/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/tree/main * 7B:https://hf-mirror.com/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF/tree/main * 14B:https://hf-mirror.com/bartowski/DeepSeek-R1-Distill-Qwen-14B-GGUF/tree/main * 32B:https://hf-mirror.com/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/tree/main * 70B:https://hf-mirror.com/unsloth/DeepSeek-R1-Distill-Llama-70B-GGUF/tree/main 注:图中Q2、Q3、Q4等通常是指模型的量化级别,数字越大精度越高,一般选择Q4 |
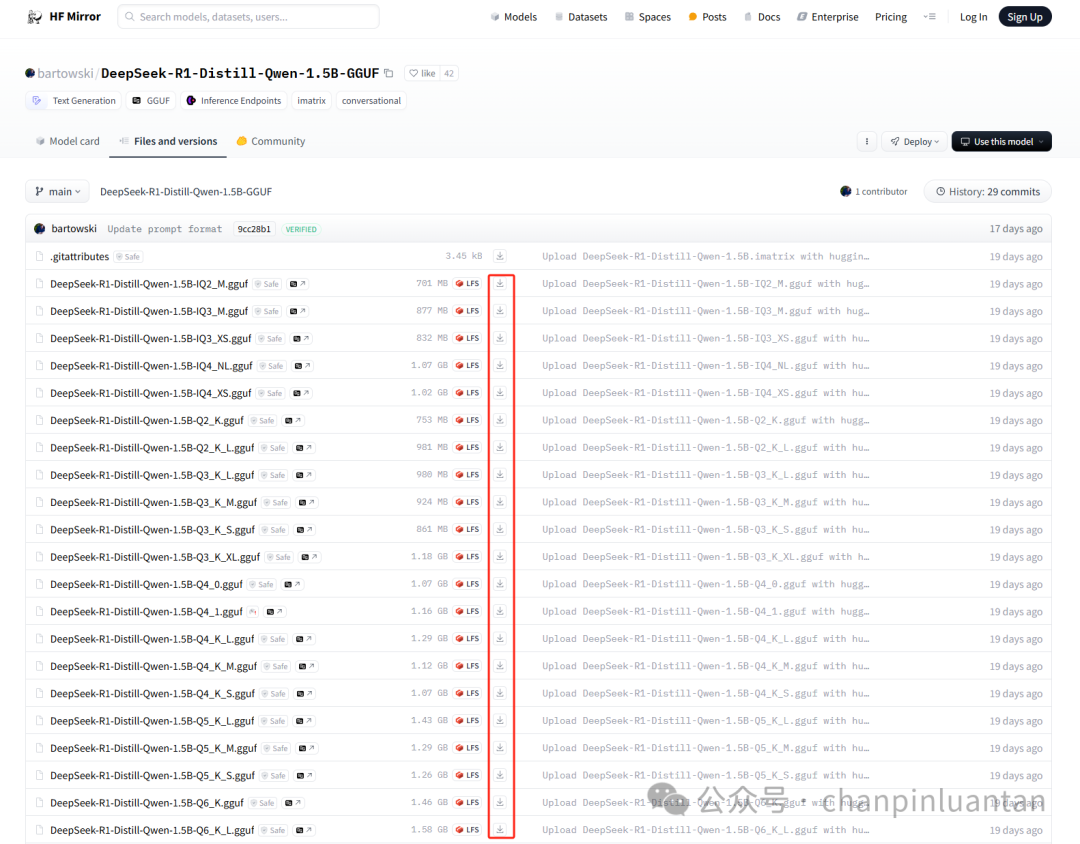
3.配置本地模型
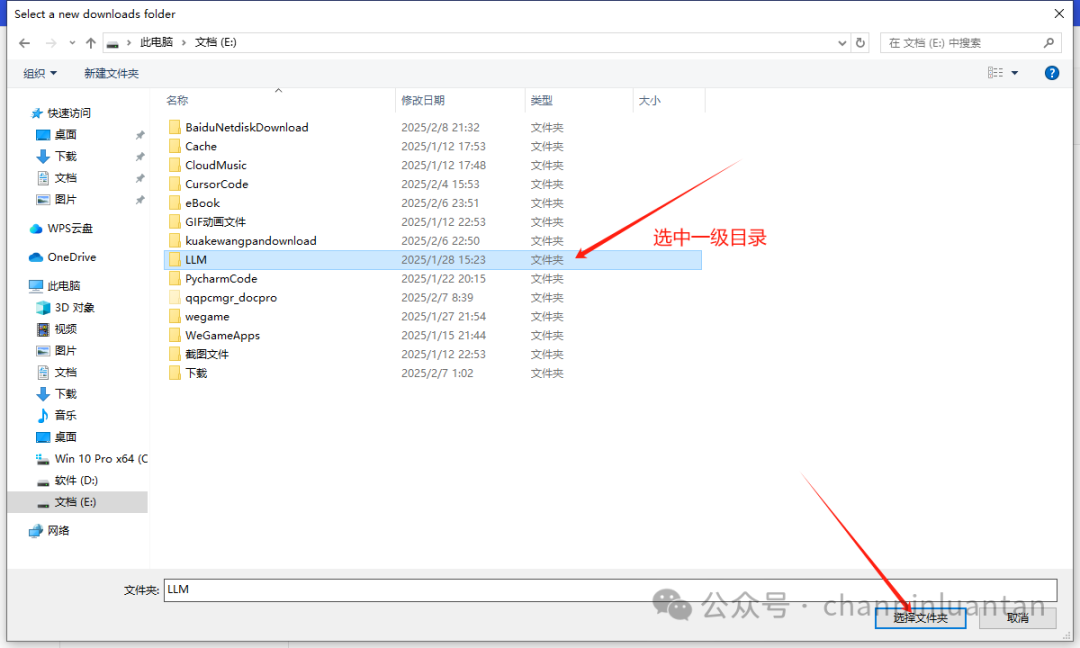
| 在磁盘下创建三级文件夹(如图所示,LLM→DeepSeek→1.5B),将gguf模型文件放置于第三层文件夹中注:这步很重要,如果没有按照要求设置,会导致读取不到本地模型 |

打开LM Studio,进入文件页面,更改模型目录
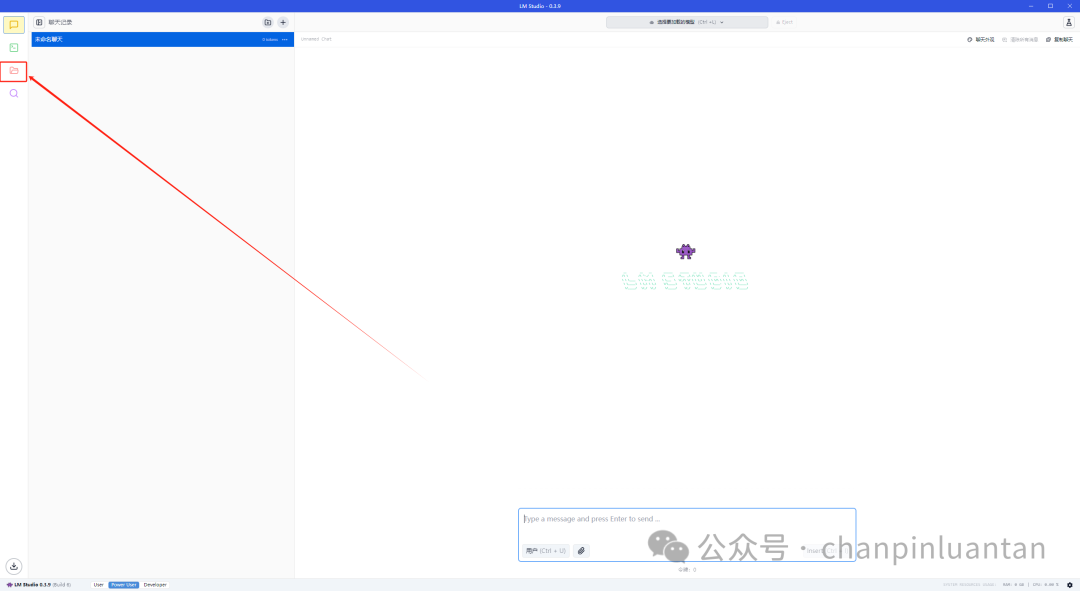
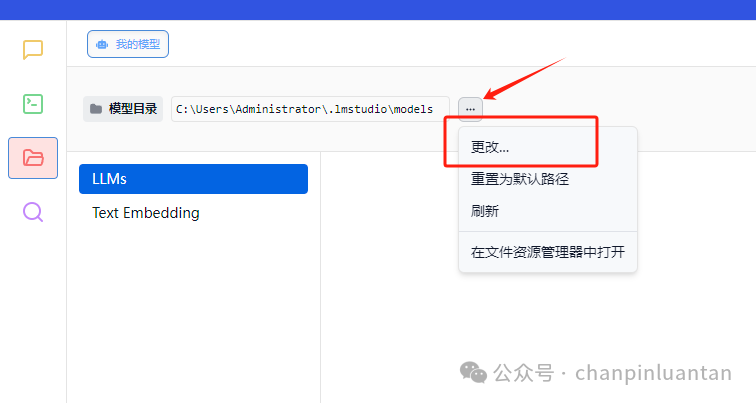
| 选择刚刚创建的三级文件夹中的第一级,即可看到本地模型,若仍没显示,可点击刷新按钮 |

4.加载本地模型
进入聊天页面,点击顶部加载模型会自动显示本地模型,选中一个模型
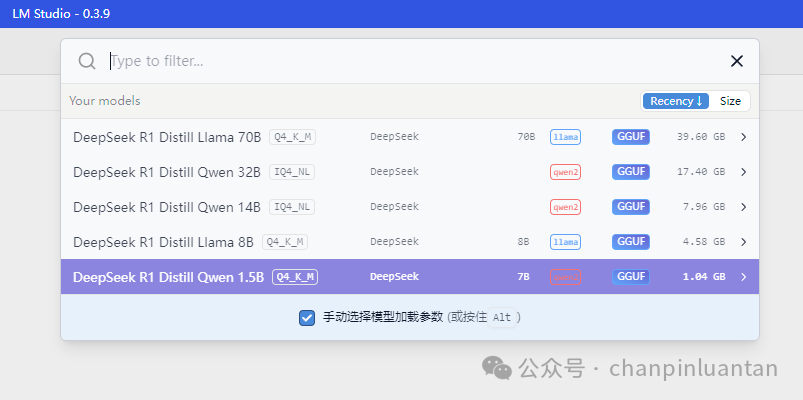
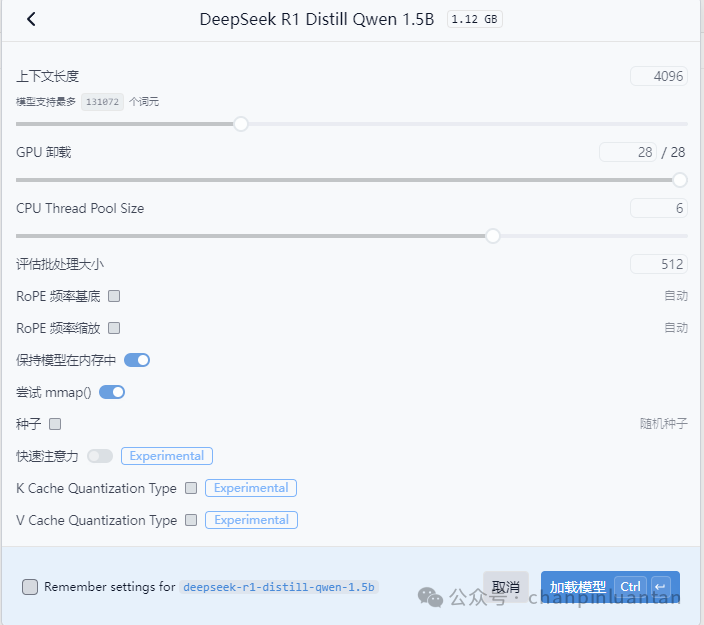
| 选择模型后需要配置模型的参数,前三个参数可根据自己的硬件调整,后面的参数按照默认设置即可,设置完成后点击“加载模型”按钮 * 上下文长度: 含义:模型处理文本时能够考虑的最大词元(token)数量。 调整效果:增加上下文长度可以提高模型理解长文本的能力,但会增加内存消耗和计算时间。 一般设置为2048的倍数 * GPU 挂载: 含义:指定用于模型计算的GPU数量。 调整效果:增加GPU数量可以提高模型的推理速度,但需要更多的硬件资源。 * CPU Thread Pool Size: 含义:指定用于模型计算的CPU线程池大小。 调整效果:增加线程池大小可以提高CPU的并行处理能力,从而提高模型的推理速度,但也会增加CPU的负载。 * 评估批处理大小: 含义:指定每次模型评估时处理的样本数量。 调整效果:增加批处理大小可以提高模型的推理速度,但也会增加内存消耗。 * RoPE 频率基底: 含义:控制旋转位置编码(RoPE)的频率基底。 调整效果:影响模型对位置信息的处理方式,可以优化模型在某些任务上的性能。 * RoPE 频率缩放: 含义:控制旋转位置编码(RoPE)的频率缩放。 调整效果:影响模型对位置信息的处理方式,可以优化模型在某些任务上的性能。 * 保持模型在内存中: 含义:是否将模型常驻内存,以加快加载速度。 调整效果:保持模型在内存中可以加快模型的加载速度,但会占用更多的内存资源。 * 尝试 mmap(): 含义:使用内存映射文件(mmap)技术来加载模型。 调整效果:使用mmap可以提高模型加载的速度和效率,特别是在处理大模型时。 * 种子: 含义:设置随机数生成器的种子值。 调整效果:设置种子值可以确保实验的可重复性,使得每次运行的结果一致。 * 快速注意力: 含义:启用快速注意力机制。 调整效果:快速注意力机制可以提高模型的推理速度,但可能会对模型的性能产生一定影响。 * K Cache Quantization Type: 含义:指定键缓存(K Cache)的量化类型。 调整效果:量化可以减少模型的内存占用和计算量,但可能会对模型的性能产生一定影响。 * V Cache Quantization Type: 含义:指定值缓存(V Cache)的量化类型。 调整效果:量化可以减少模型的内存占用和计算量,但可能会对模型的性能产生一定影响。 * Remember settings for deepseek-r1-distill-qwen-1.5b: 含义:是否记住当前模型的设置。 调整效果:勾选此选项可以在下次加载模型时自动应用当前设置,无需重新配置。 |
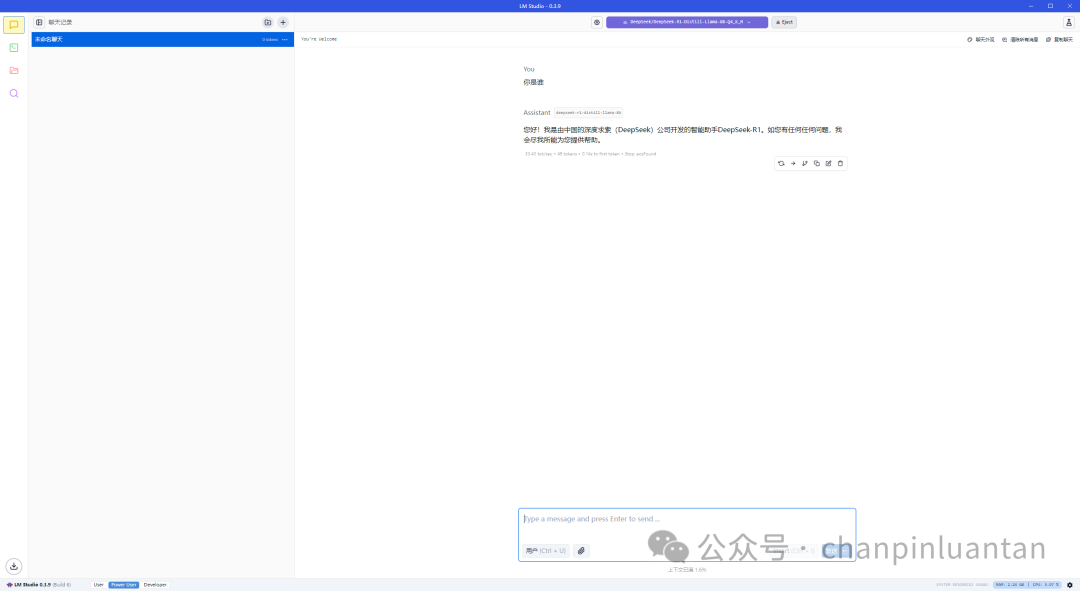
加载成功后即可开始对话
5.关闭软件联网保护隐私
| 本步骤非必须,如果想更好的保护隐私不被泄露,可遵循下述步骤将软件断网 |
进入高级安全Windowsdefender防护墙
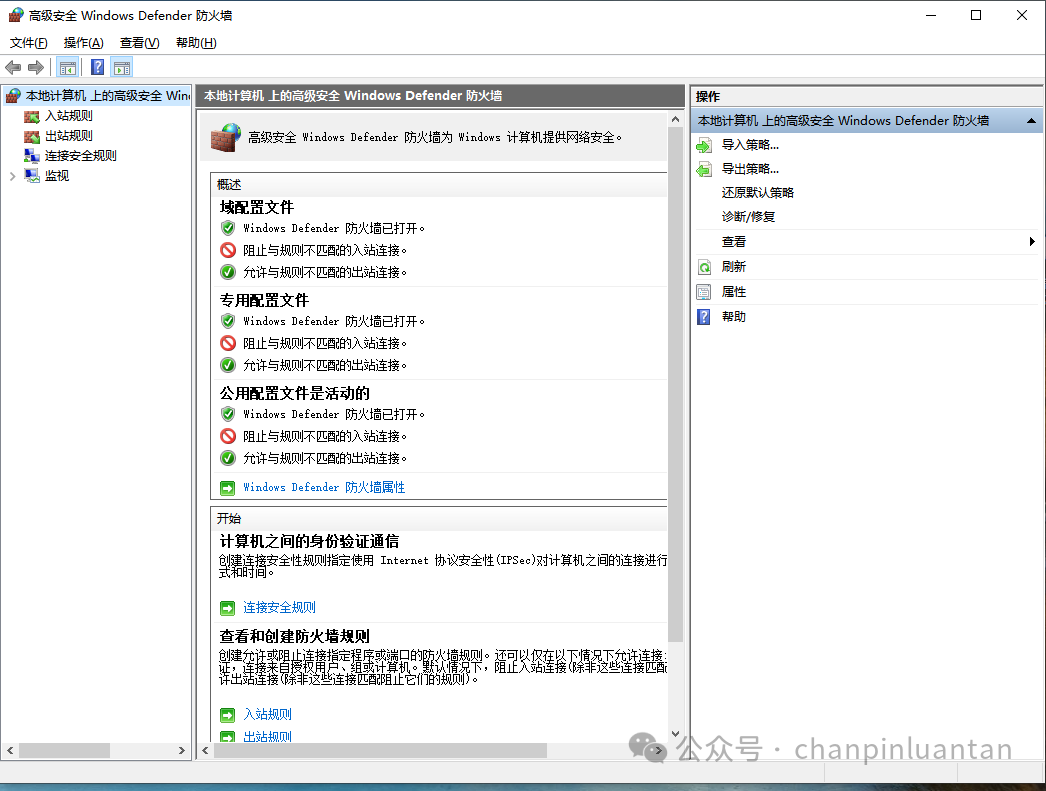
选择入站规则-新建规则
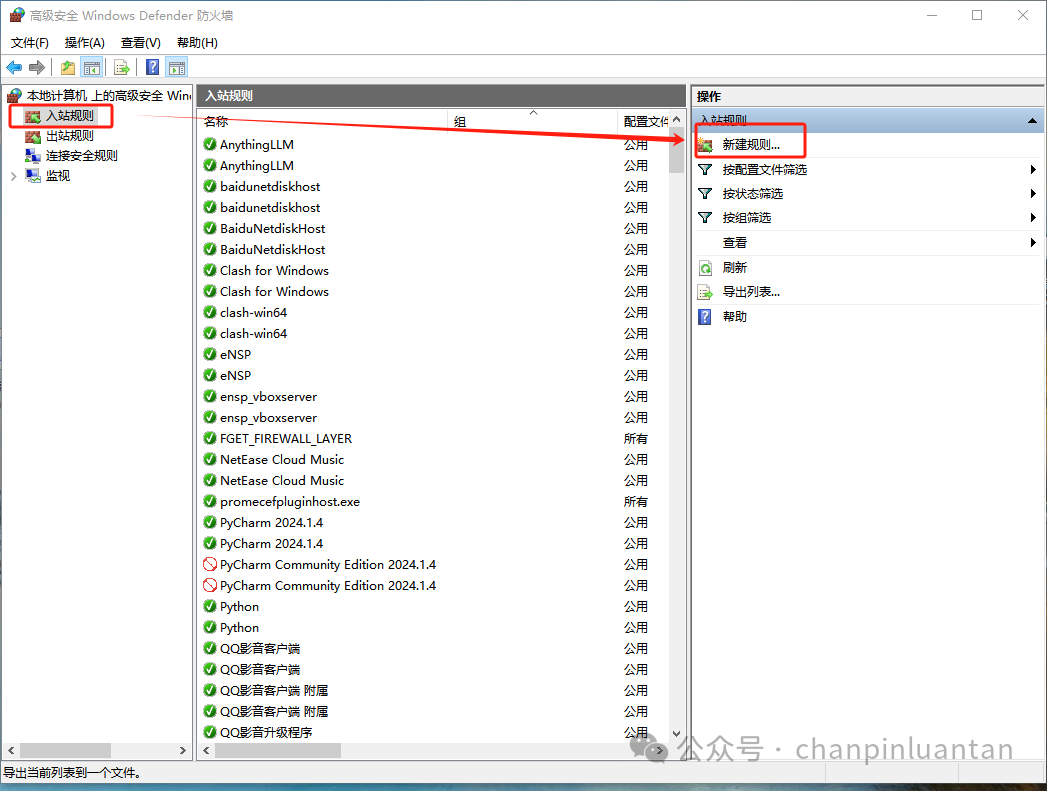
选择程序-下一步-选择路径
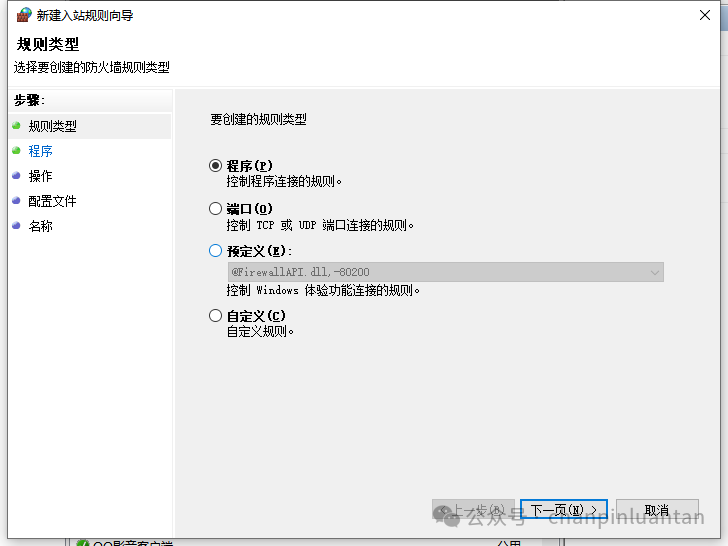
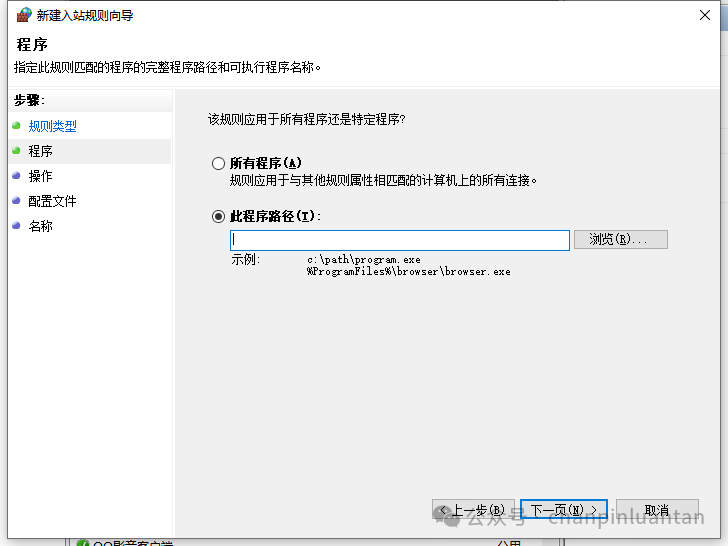
选择安装lmstudio的路径中名字叫LM Studio.exe文件
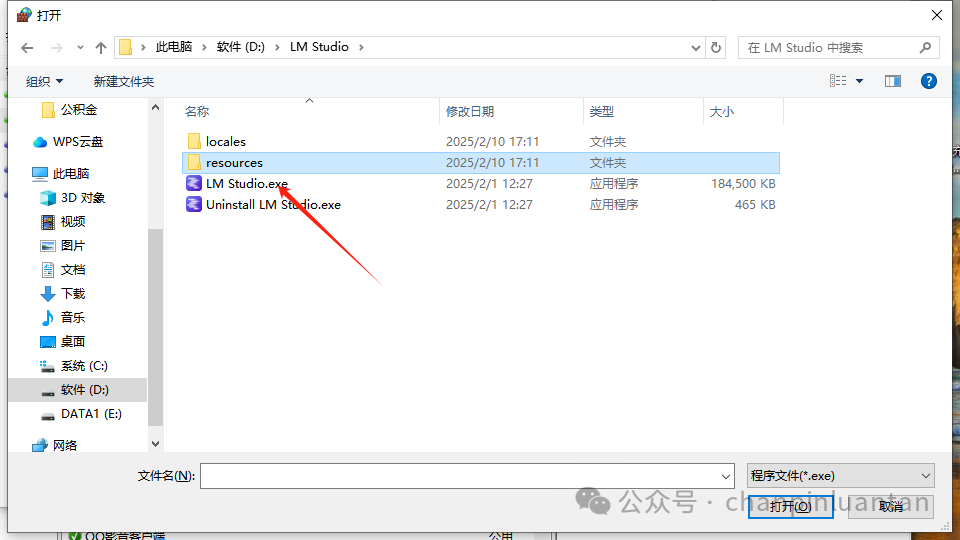
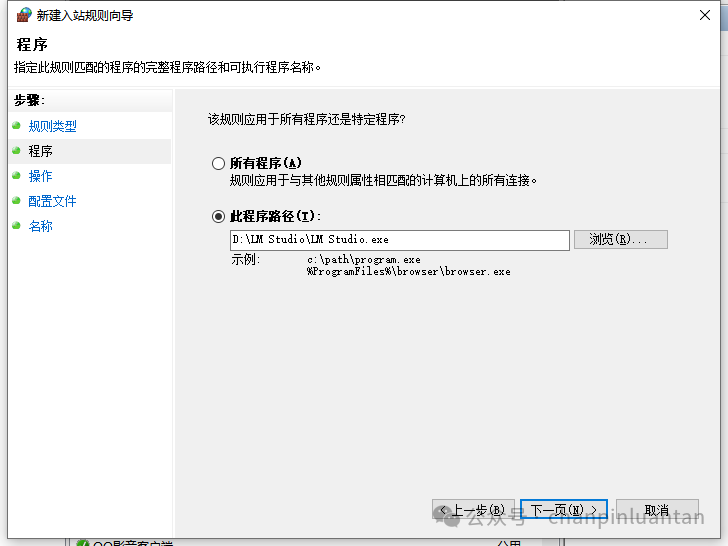
阻止连接
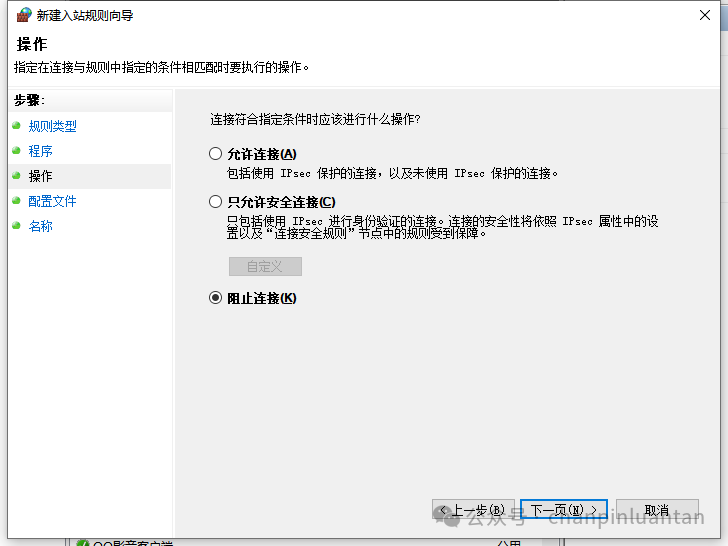

输入这条规则的名称,点击完成即可
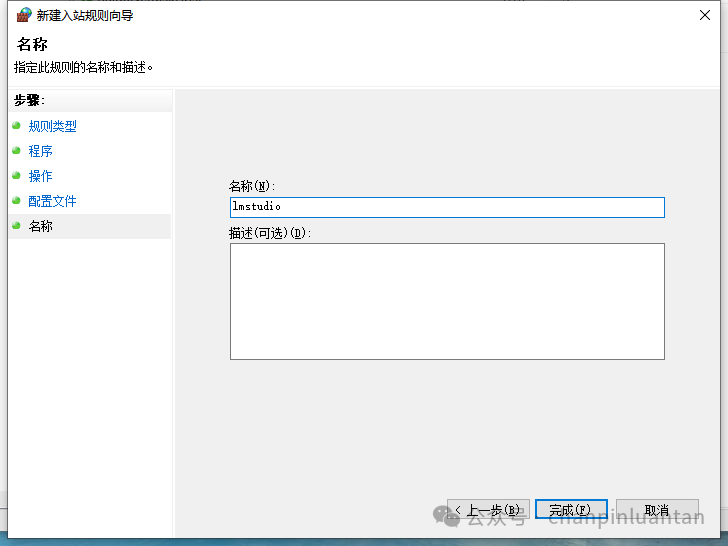
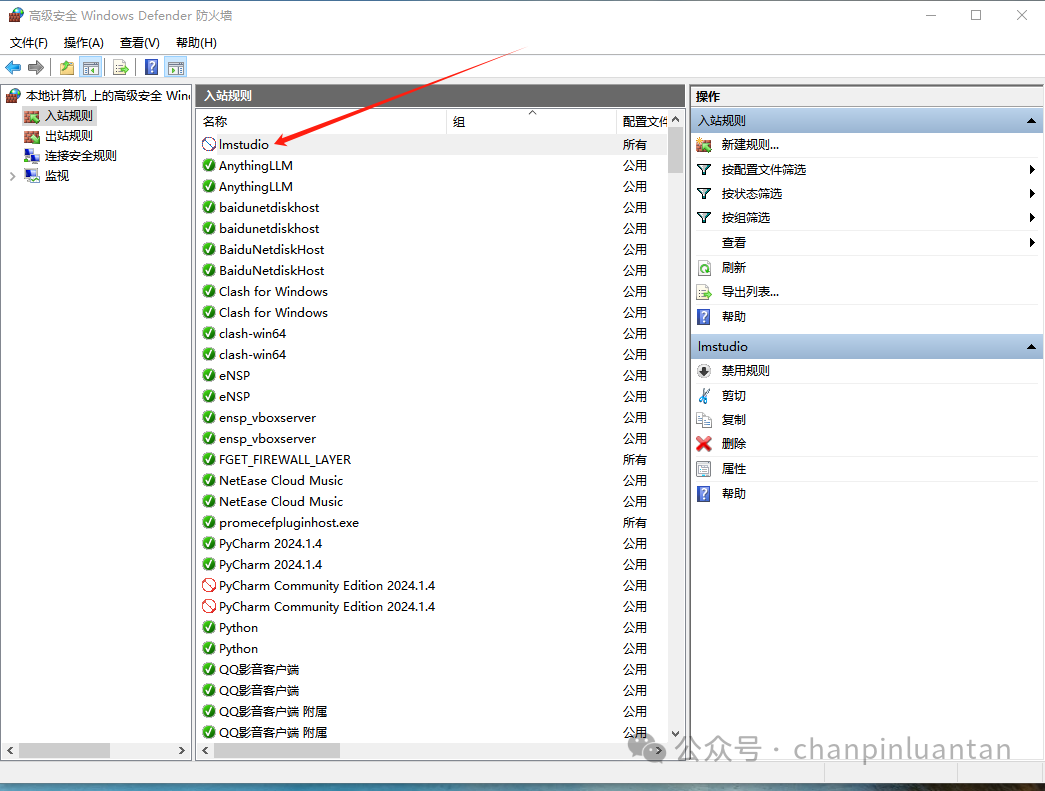
再次新建禁止联网规则,分别添加另外两个文件
| LM Studio所在目录\resources\elevate.exe C:\Users\Administrator.lmstudio\bin\lms.exe |
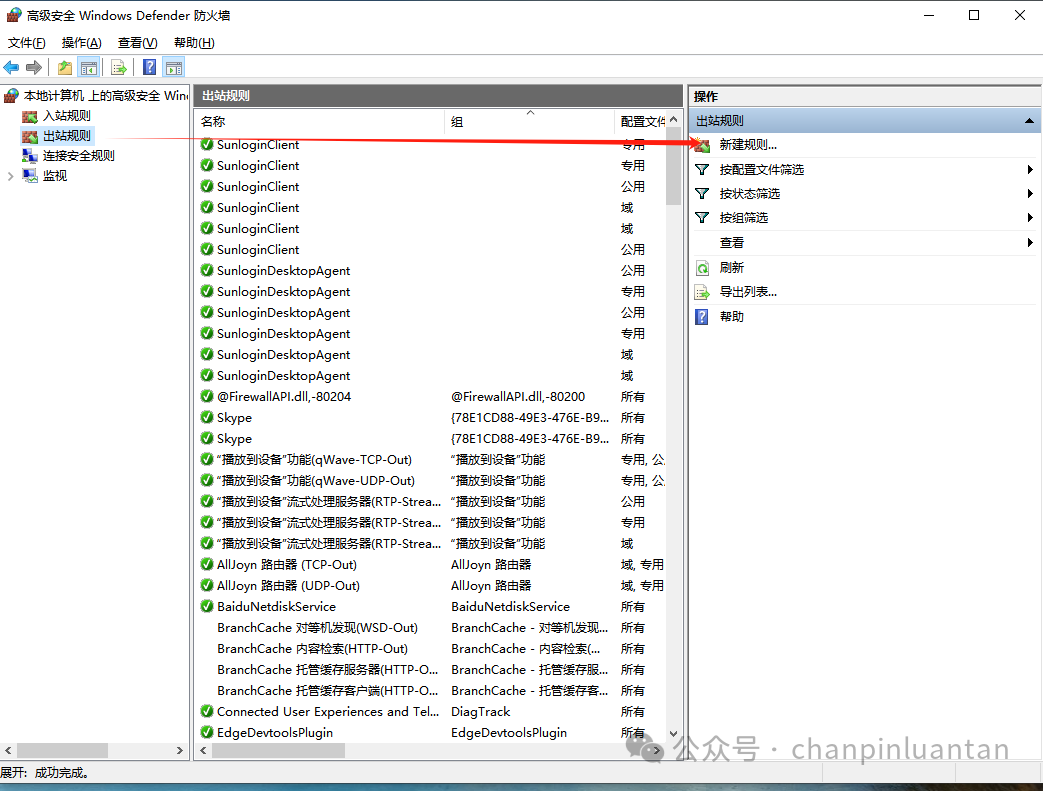
在出站规则中也将以上三个文件设置禁止联网,步骤同上

二、构建私有知识库

1.下载安装AnyThingLLM
https://anythingllm.com/
按步骤安装
安装成功后打开软件,跳过前面的引导页,都按默认选择
创建一个工作区
2.切换到LM Studio,打开本地服务
进入开发者页面
选择要加载的模型(见第一部分第4节)
开启本地服务
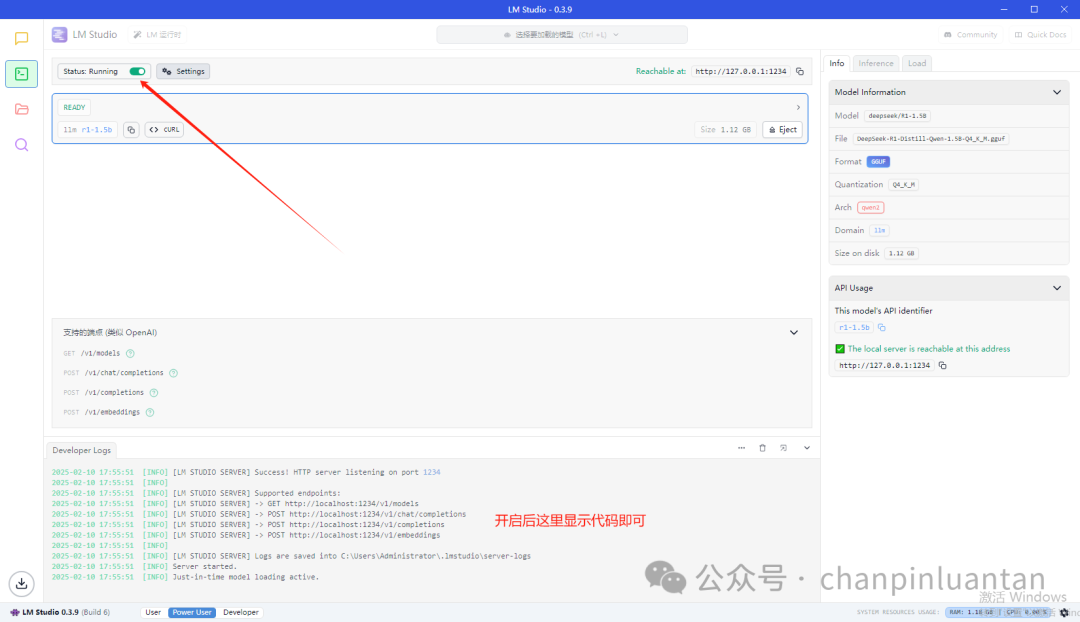
3.配置anythingllm
回到anythingllm软件,点击设置按钮
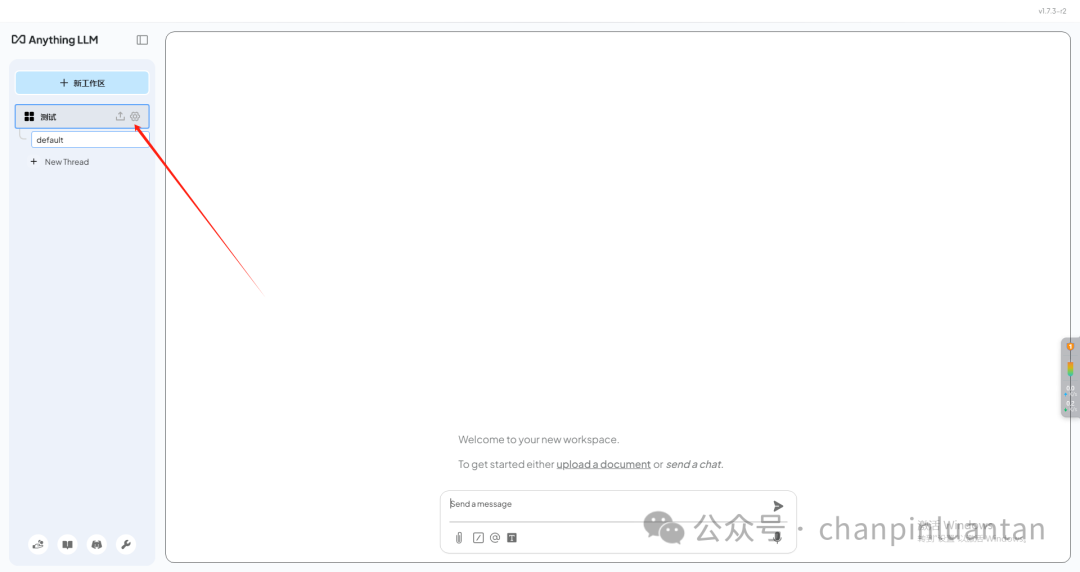
进入聊天设置,切换LLM供应商
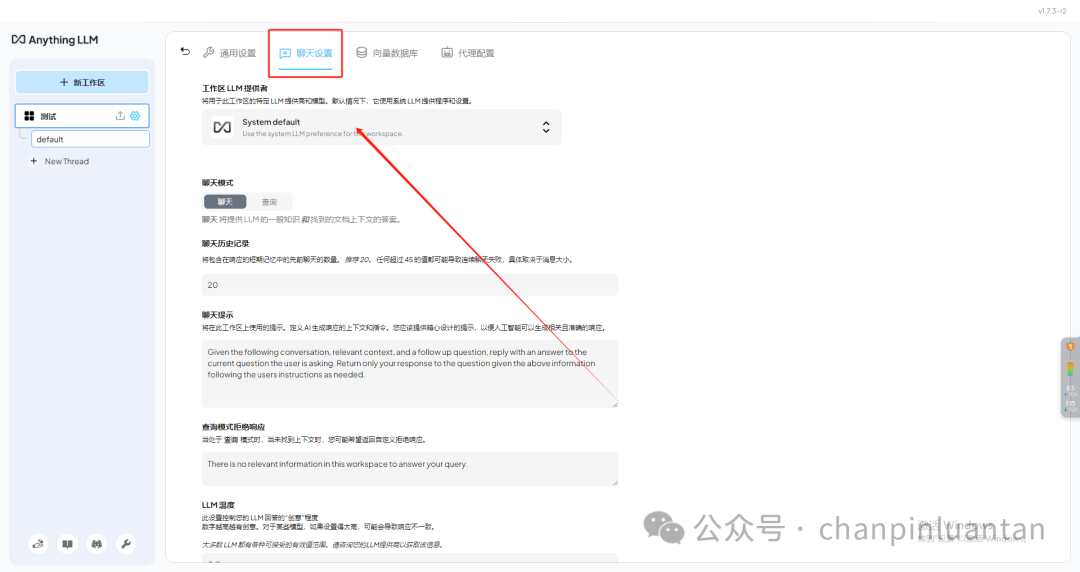
找到LMstudio
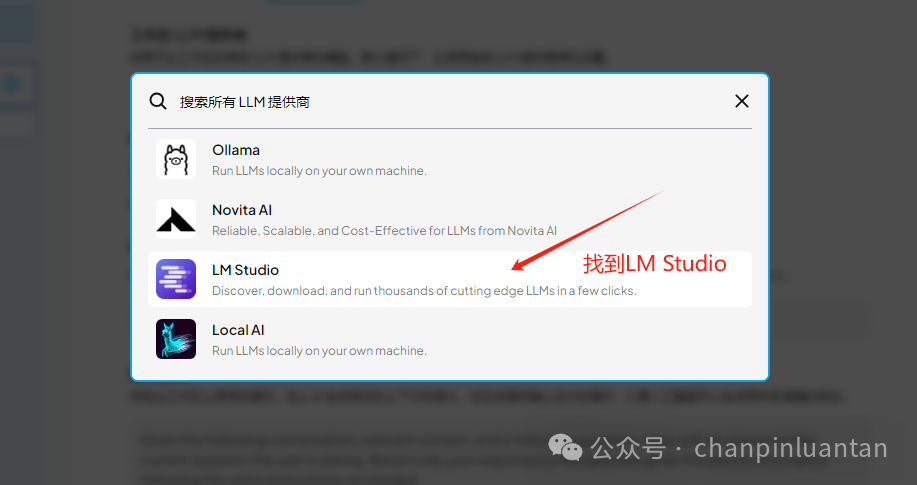
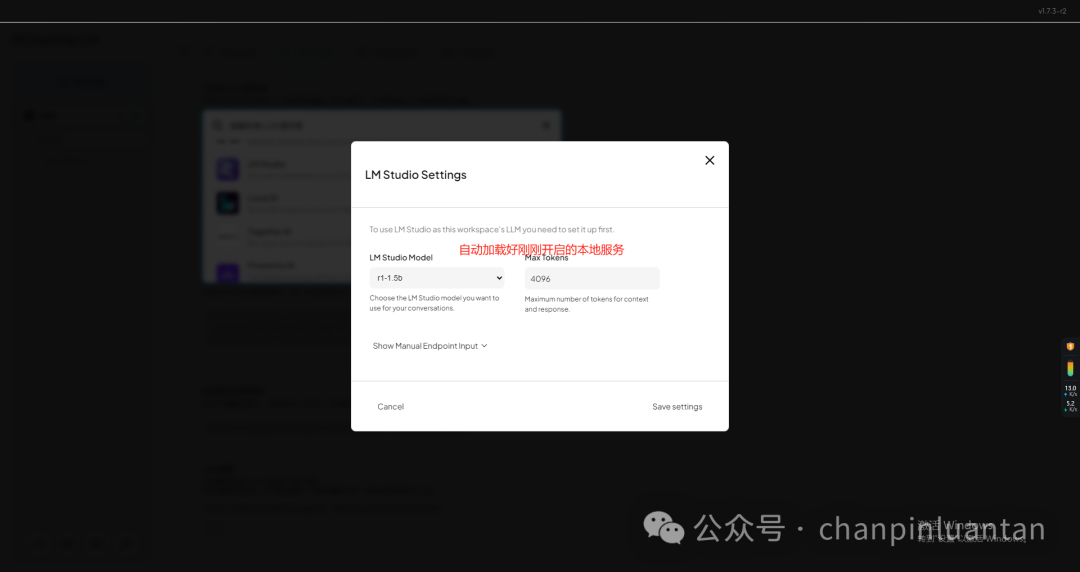
要记得点击update进行保存
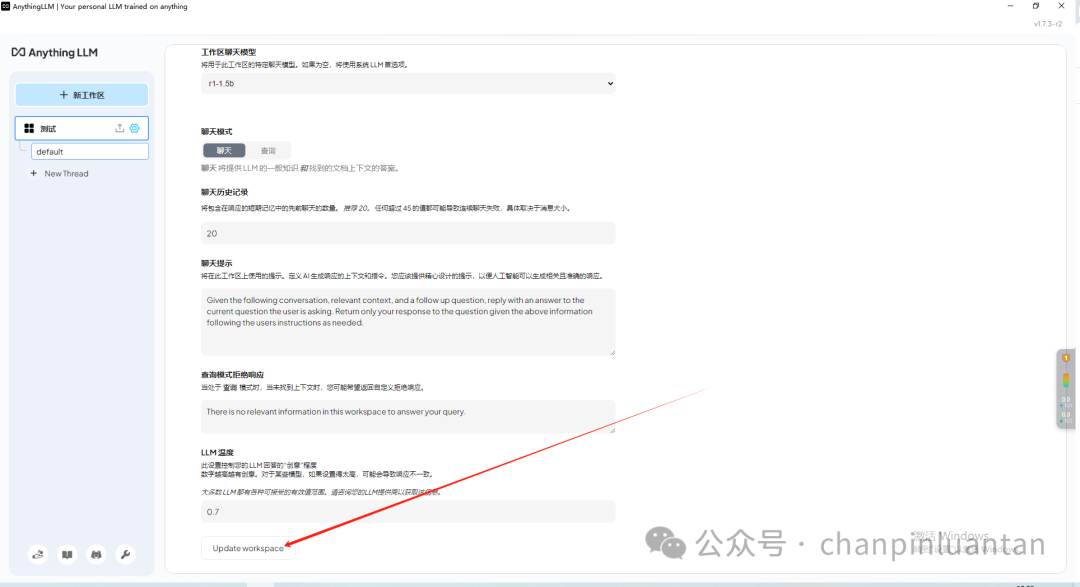
在代理配置中也选上LM Studio(注意要点击configure进行保存)
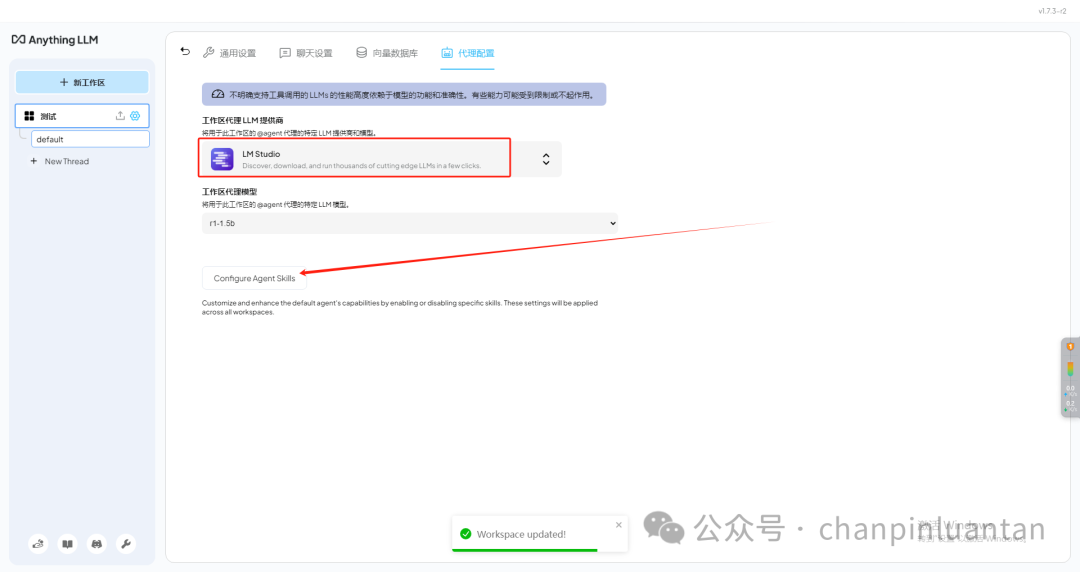
返回对话页,这样就建立了与LMstudio的本地连接
4.构建本地知识库
| 本地知识库:使用lmstudio上的本地模型创建的知识库 若不放心安全问题,在配置完成后,可参照一.5关闭anythingLLM联网 |
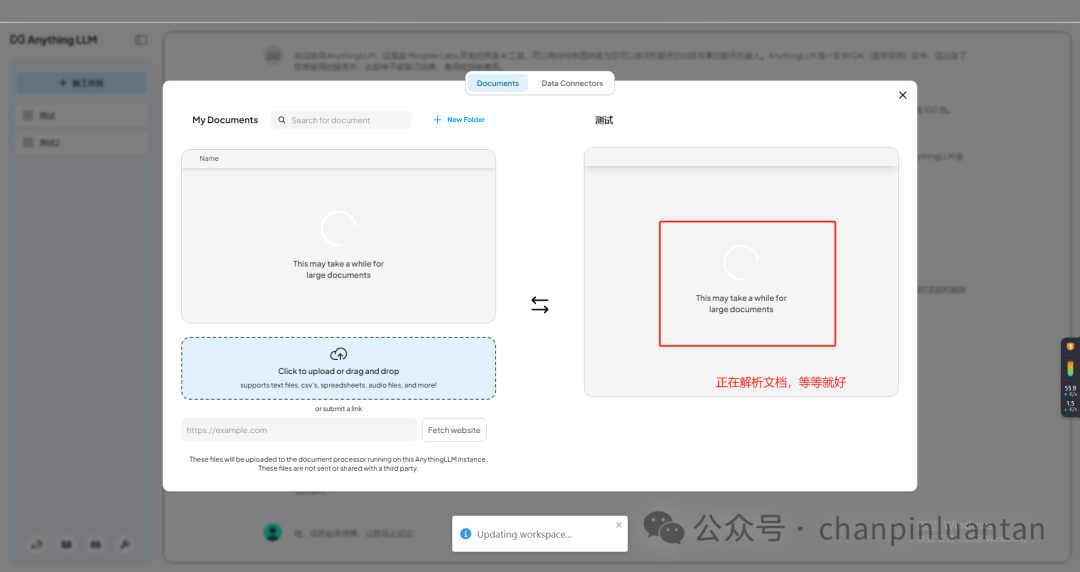
点击上传按钮
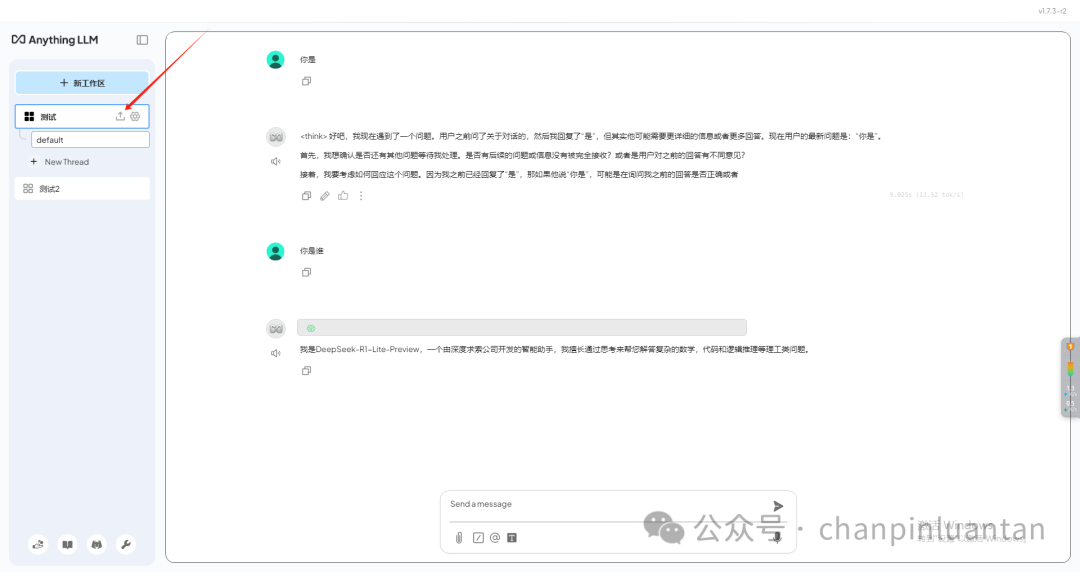
上传本地文件
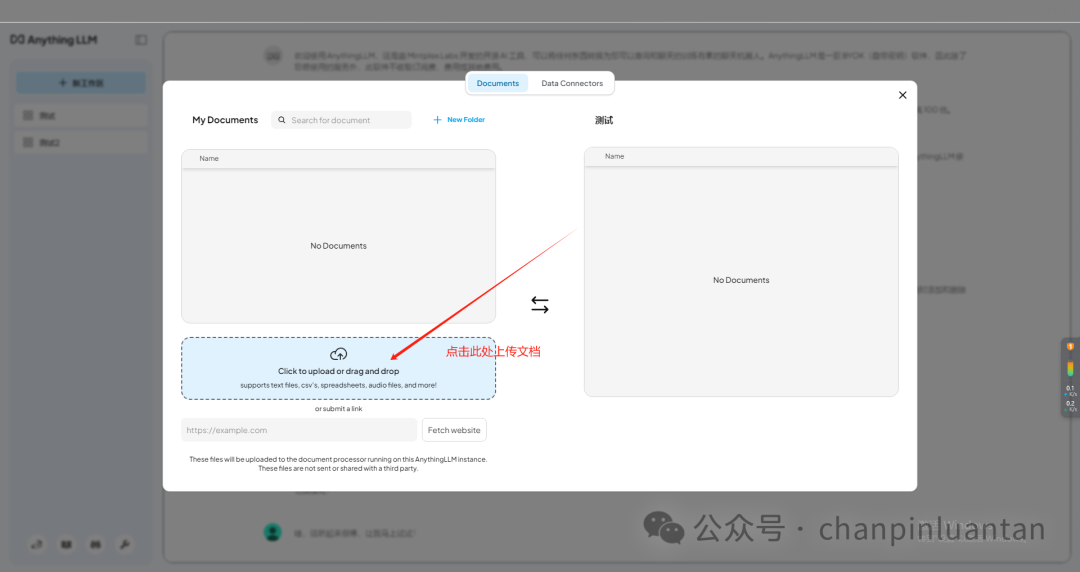
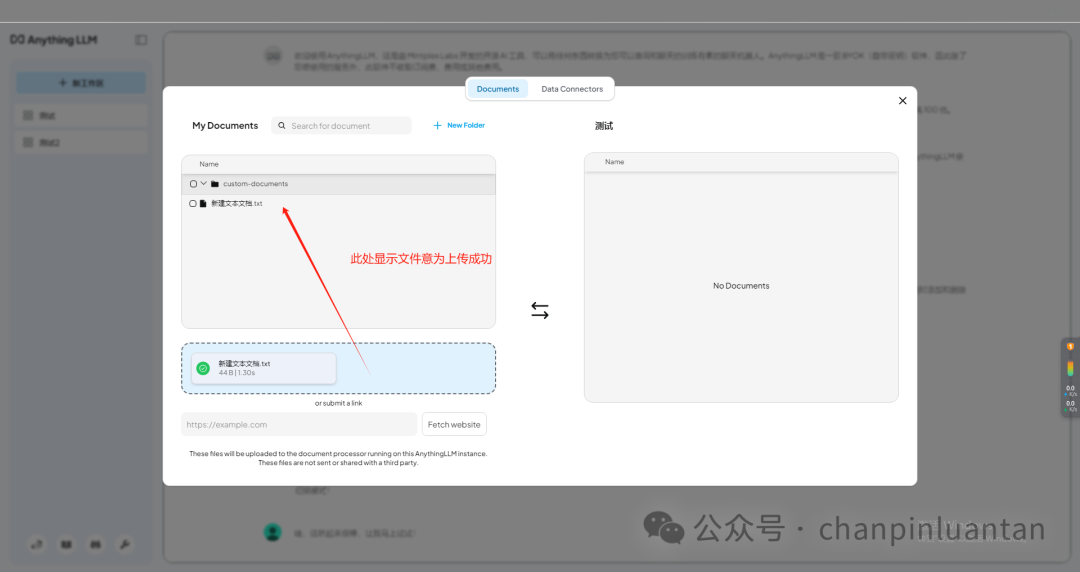
将上传的文件移入工作区
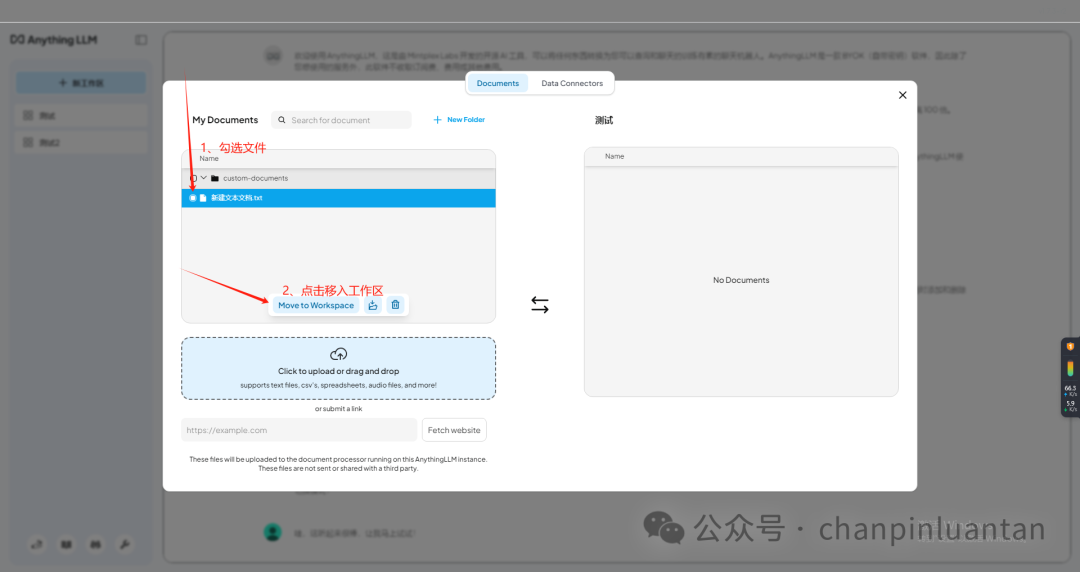
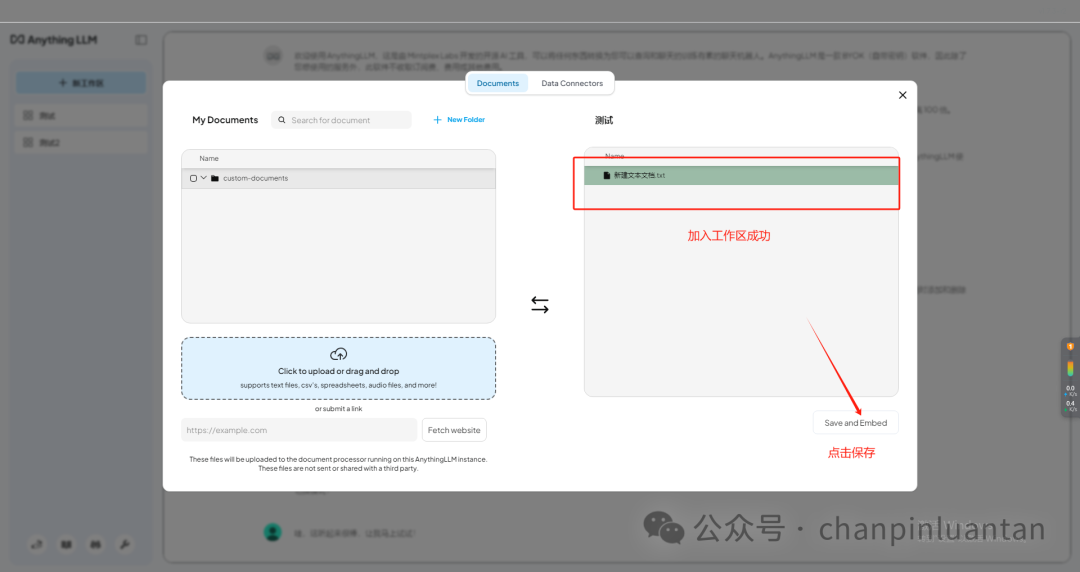
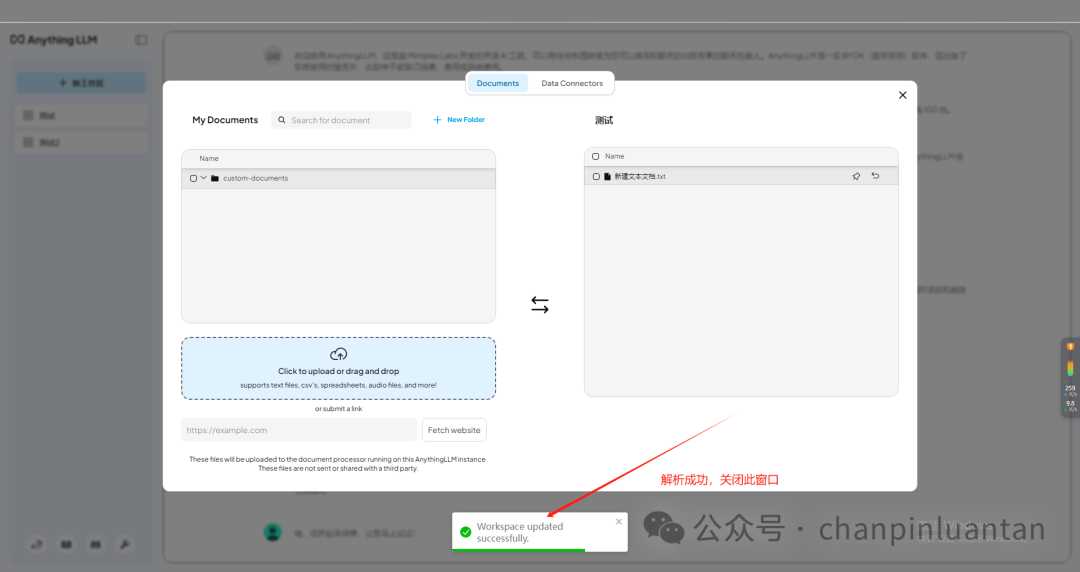
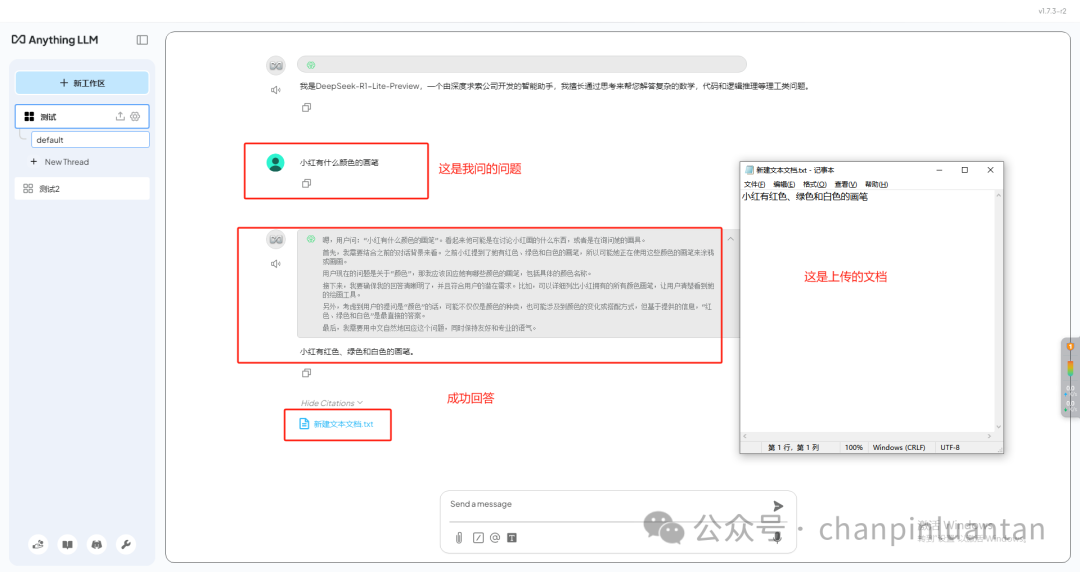
5.构建在线知识库
| 在线知识库:通过API调用在线大模型,再创建知识库 |
新建工作区,进入设置,选择其他LLM提供商,以deep seek为例
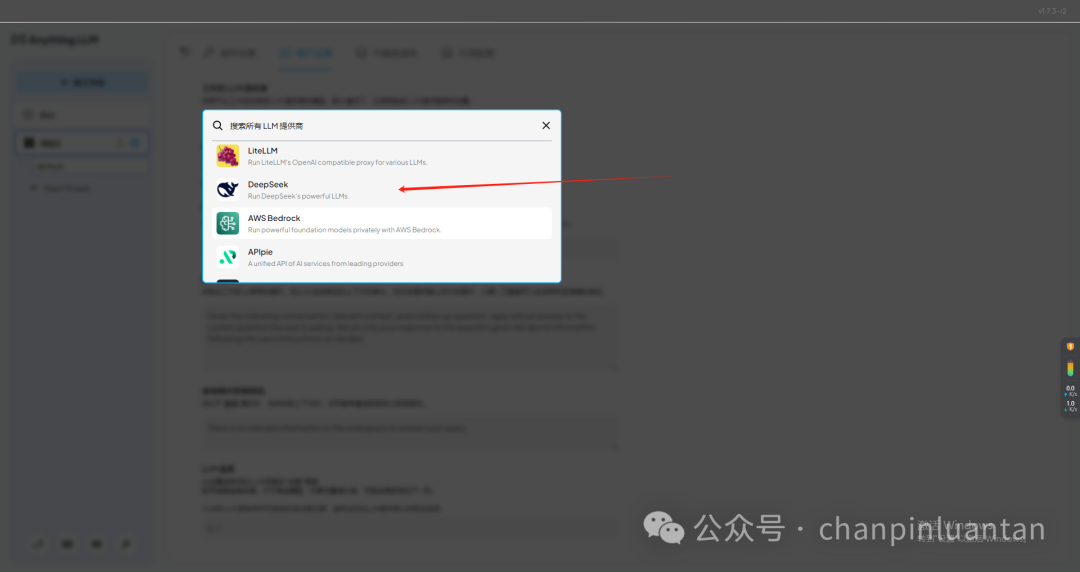
输入APIkey(如何获取APIkey可参考第三部分第一节)
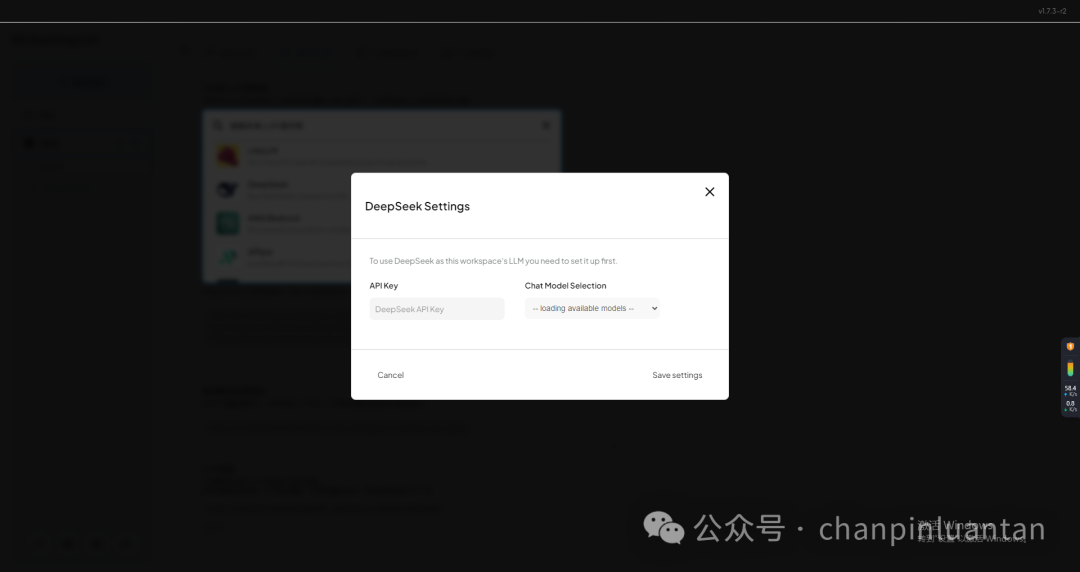
设置apikey成功后,再根据构建本地知识库的步骤上传文件即可
三、调用大模型API(以DeepSeek为例)
1.申请DeepSeekAPI
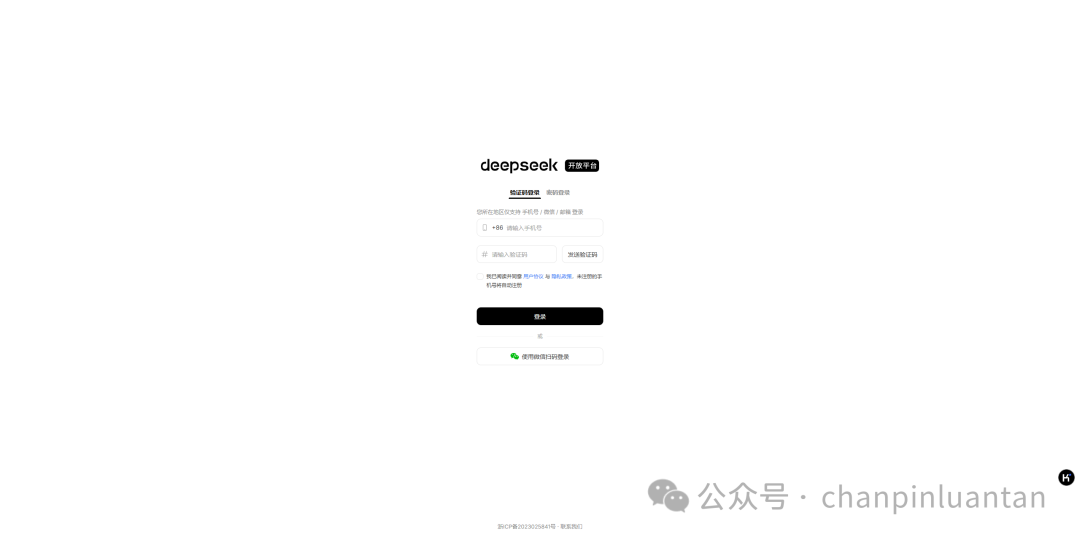
进入https://www.deepseek.com/,点击右上角“API开放平台”,开始注册登录

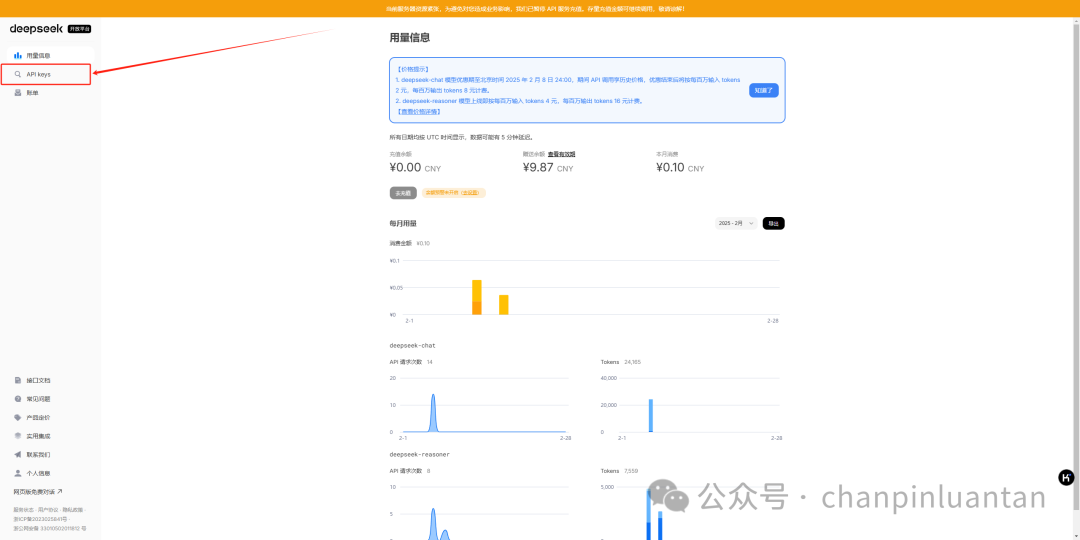
进入左侧“API keys”页面,点击“创建API key”,输入名称
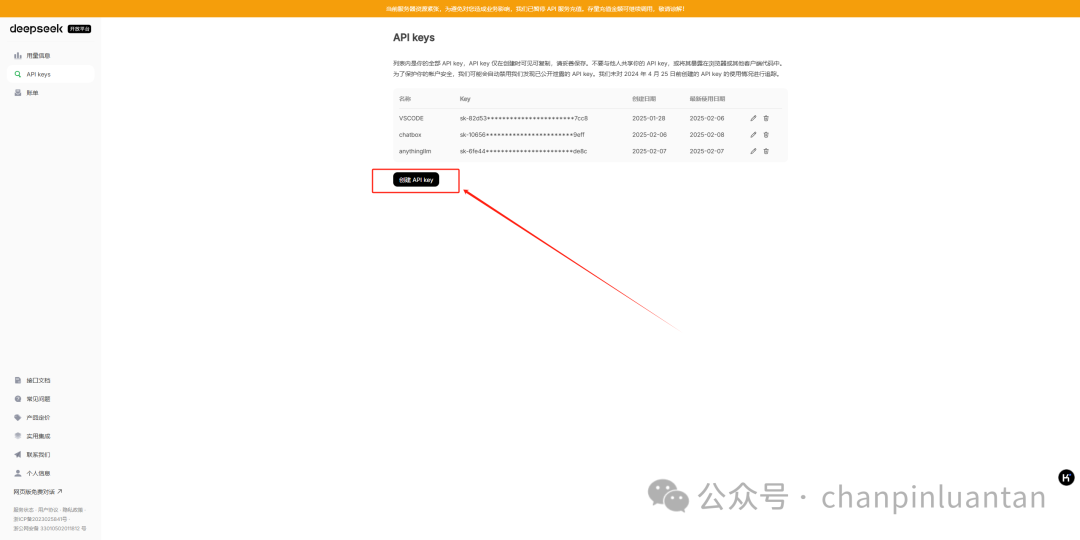
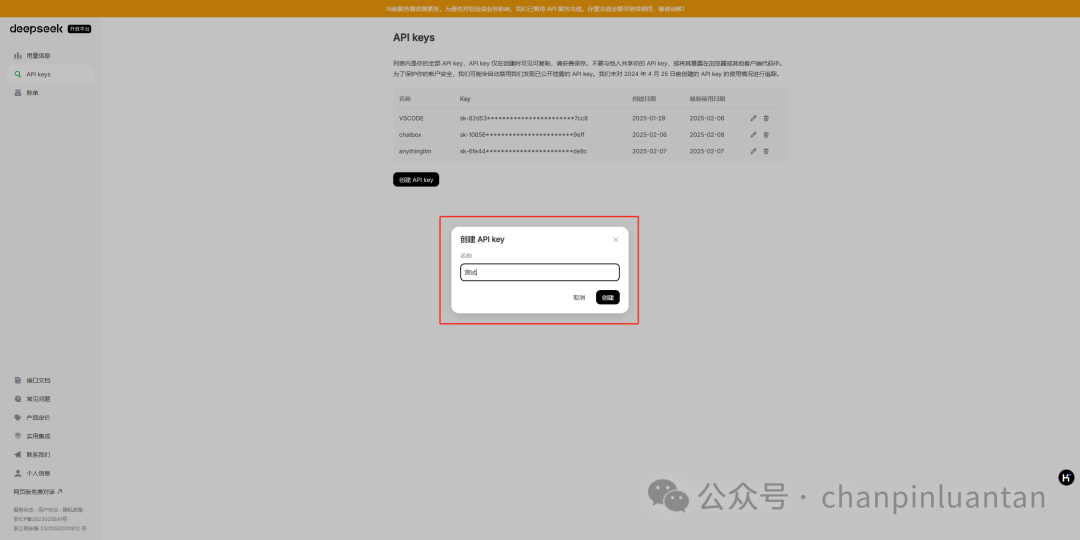
| 创建后会自动生成key(它是一种用于身份验证的密钥,允许用户通过API访问特定的服务或数据。它就像一把钥匙,确保只有授权的用户才能使用服务,同时帮助控制访问频率和权限),请将这个key保存好,因为关闭后无法再次查看 |

2.聊天
2.1.安装Chatbox
| 也可以用刚刚下载的AnythingLLM实现,但个人认为单纯用作聊天的话,Chatbox的体验更佳! |
https://chatboxai.app/zh
根据提示步骤安装chatbox
2.2.设置API
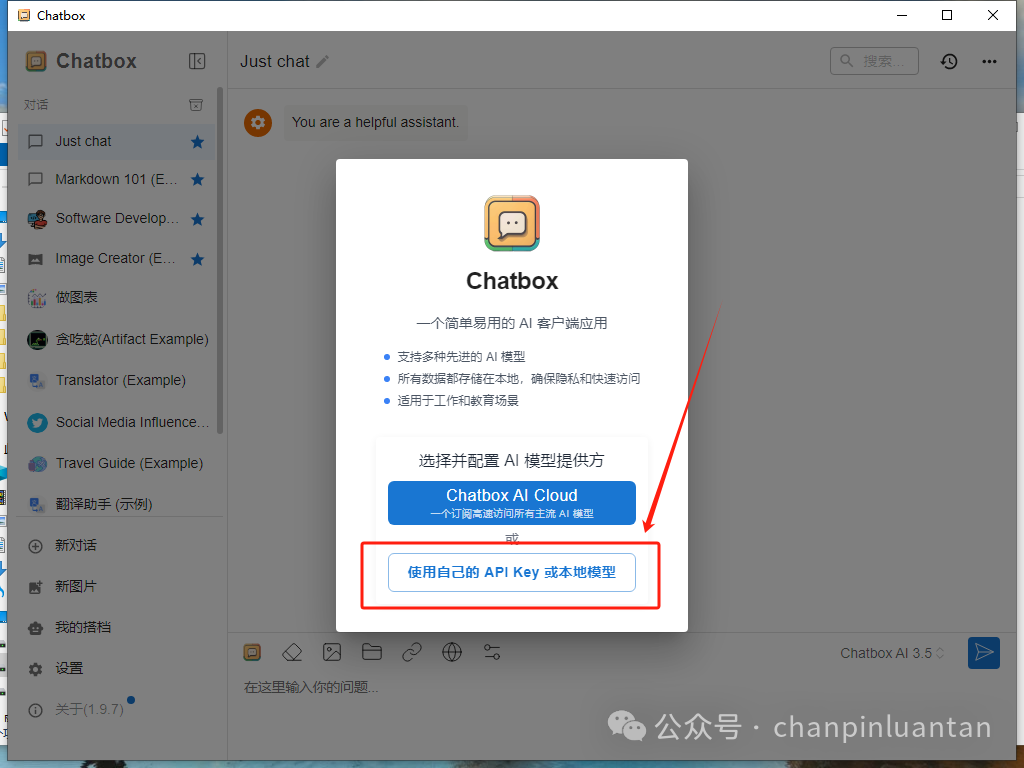
打开软件后,选择“使用自己的API Key”或本地模型
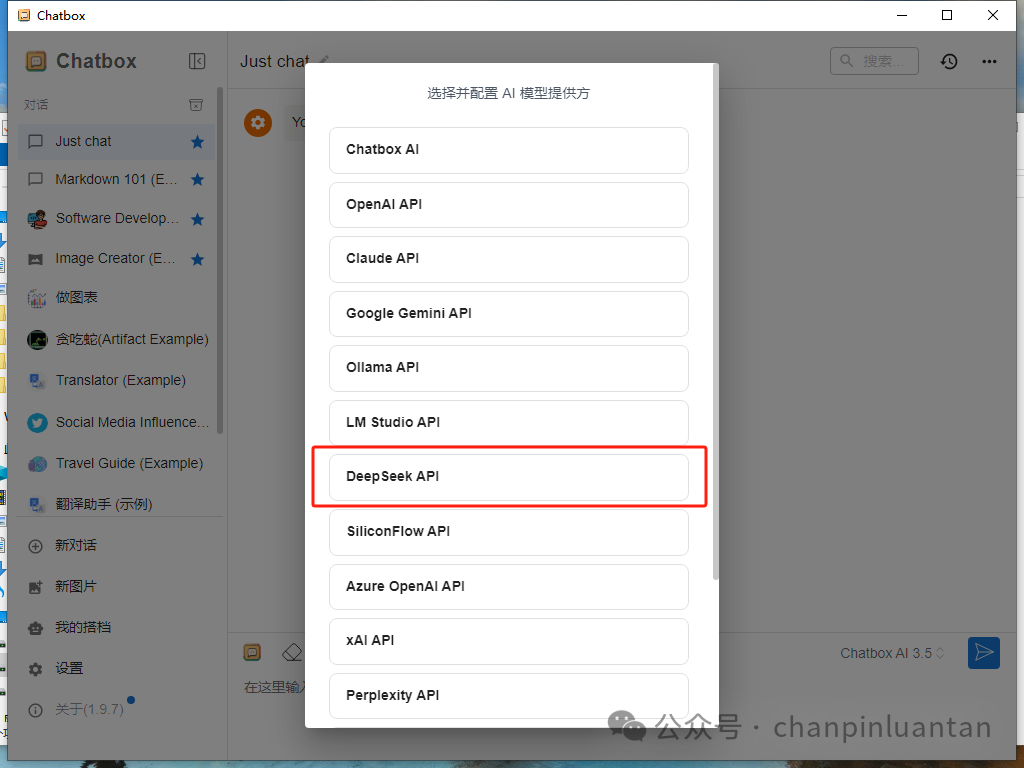
在选择AI模型提供方界面找到deep seekAPI
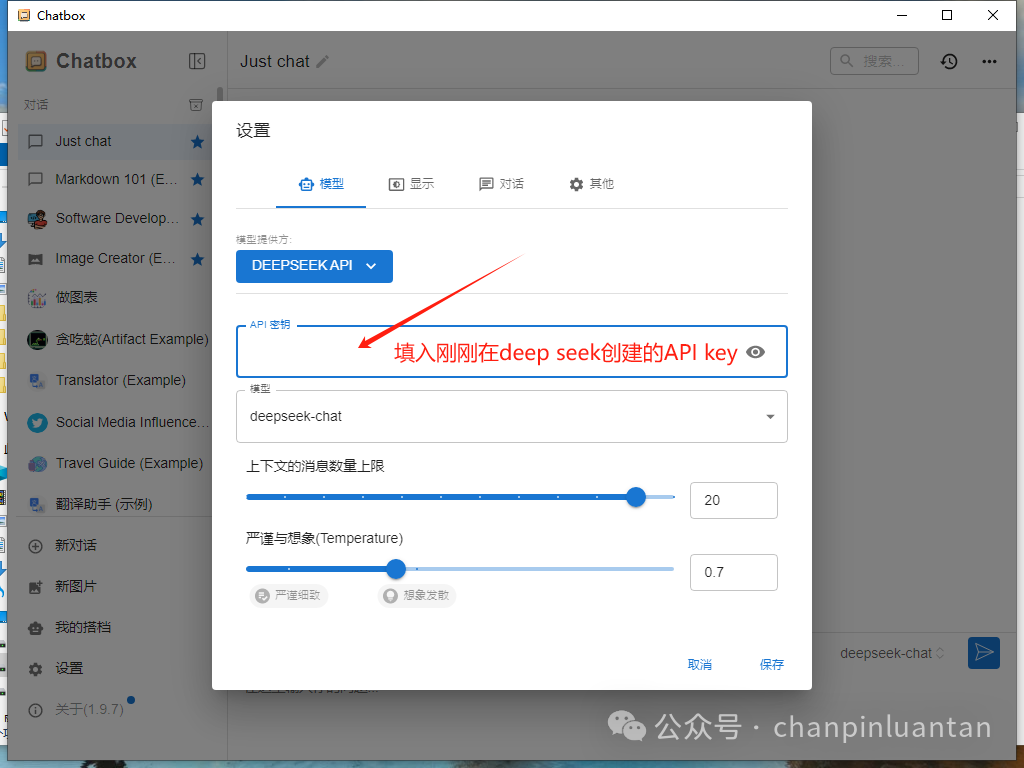
填入刚刚在deep seek创建的APIkey
然后选择模型,默认的是普通的chat聊天模型,想要带推理的选择reasoner(但是这个模型最近太火爆了,经常无响应)
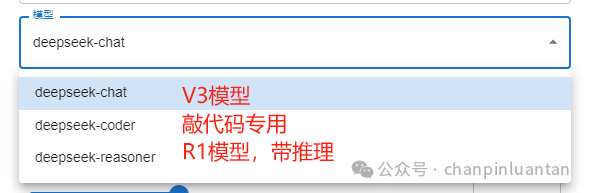
然后就可以在聊天界面对话了
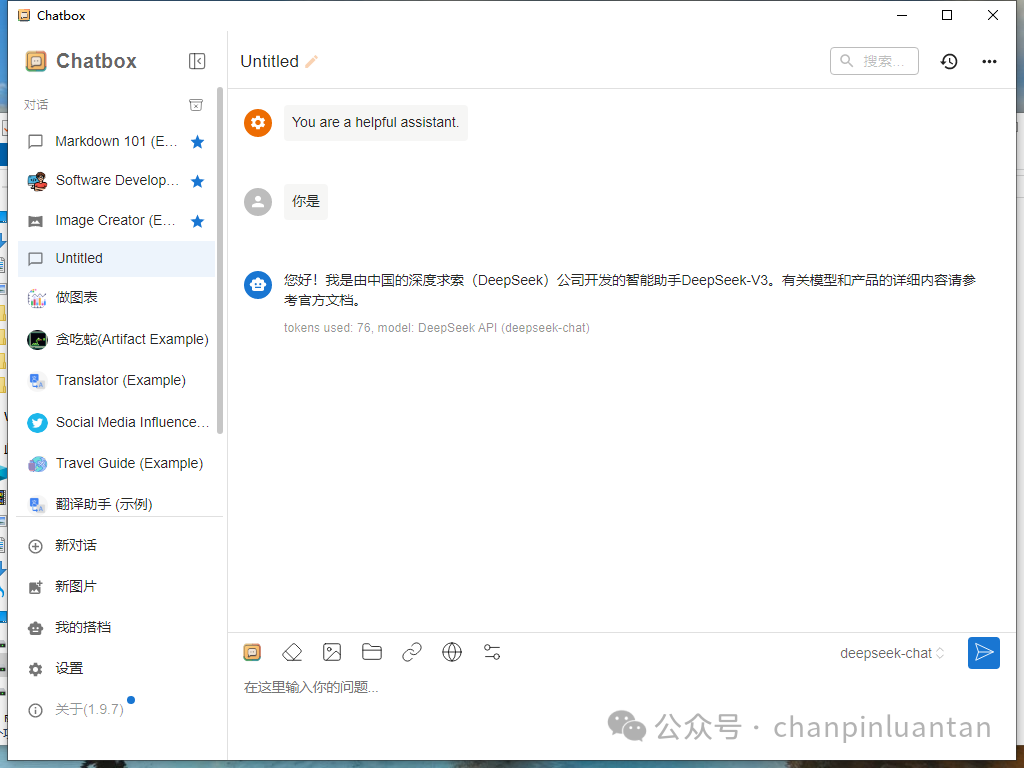
3.编程
3.1.下载continue插件
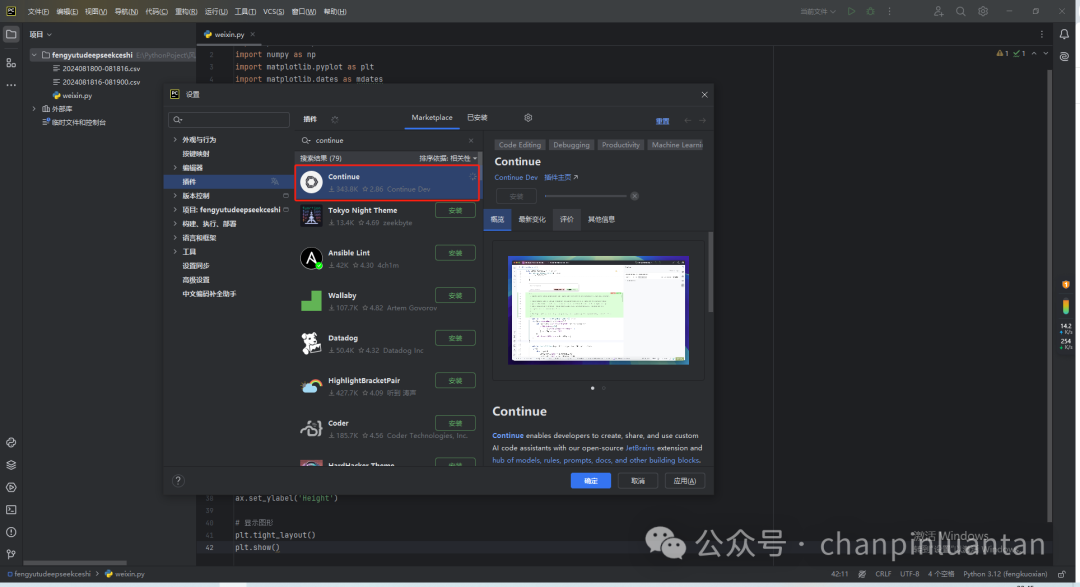
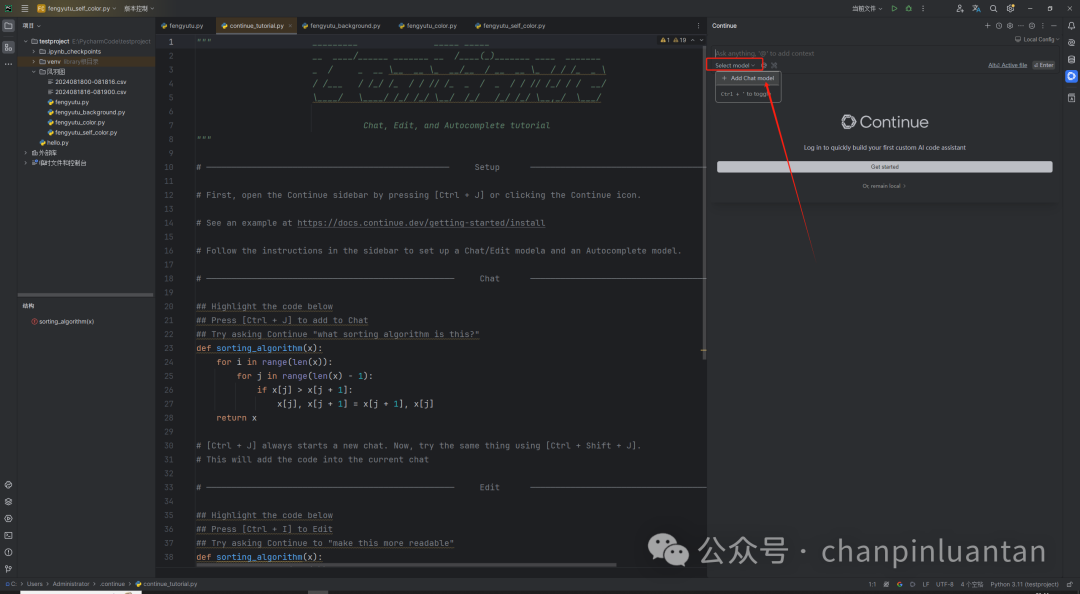
3.2.设置API
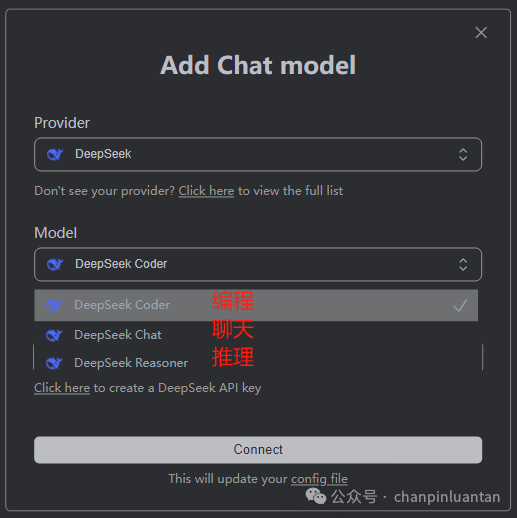
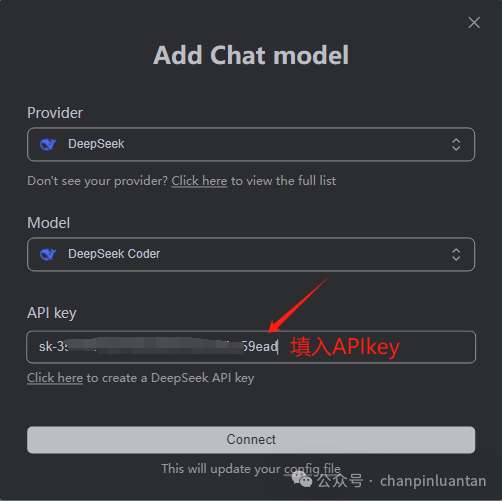
点击connect后还会出现一个小的输入框,再次输入APIkey即可。
全文完!
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)