【VLMs篇】04:视觉token压缩技术深度解析
图片Token压缩技术不仅仅是一项优化技巧,它正在成为多模态大模型的**核心引擎**。它将模型从海量冗余数据中解放出来,使其更轻、更快、更专注。
引言:当“看图说话”遇上“信息爆炸”

多模态大语言模型(MLLMs)的崛起,让AI“看图说话”、“看视频聊天”成为现实。然而,这背后隐藏着一个巨大的挑战:信息爆炸。一张4K高清图像可以被分解为超过32,000个视觉Token,而一段90分钟的视频甚至能产生5400万个Token。当这些海量视觉信息涌入以文本为核心的大语言模型时,会立即引发三大痛点:
- 计算与显存的噩梦:Transformer模型的自注意力机制计算复杂度与Token数量的平方(O(N²))成正比。海量视觉Token意味着显存开销激增、训练和推理速度急剧下降。
- 信息冗余:图像中大片的蓝天、重复的纹理,视频中静止的画面……这些在视觉上是连续的,但在信息层面却是高度冗余的。
- 上下文窗口的挤占:宝贵的上下文窗口被大量视觉Token占据,留给关键文本交互的空间所剩无几。
幸运的是,研究人员发现,超过50%的视觉Token在推理过程中受到的关注极少。这为图片Token压缩技术提供了坚实的理论基础。通过智能压缩,我们可以在仅损失不到2%性能的情况下,实现高达18倍的Token压缩、减少64%的KV缓存,并将推理速度提升2到85倍。这项技术,正是解锁下一代高效、强大、可扩展多模态模型的关键所在。
主流压缩技术流派:从“野蛮删减”到“智能精炼”
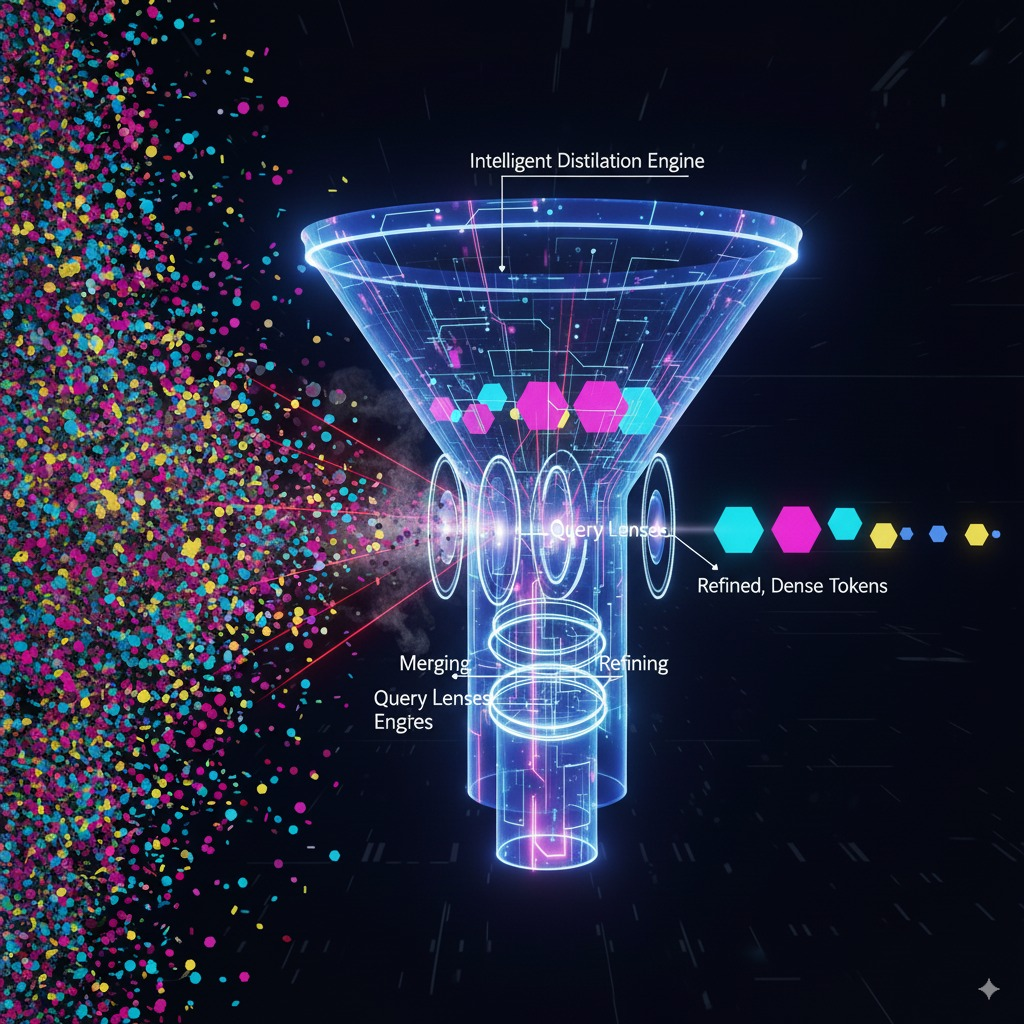
图片Token压缩的核心目标是在**“减少Token数量”和“保持关键信息”**之间找到最佳平衡点。经过多年的发展,已经演化出四大主流技术路线。
1. Token剪枝与采样 (Pruning & Sampling)
这类方法的核心思想是“去芜存菁”,通过某种重要性评分机制,动态地识别并丢弃那些贡献小的Token。
- 工作原理:在Transformer的计算过程中,逐层评估每个Token的重要性(通常基于注意力权重),然后剪掉分数最低的Token。
- 代表模型与技术:
- FastV:发现视觉Token在模型的深层网络中接收的注意力极少,因此在浅层之后进行激进剪枝,可减少45%的理论计算量而性能几乎无损。
- TokenCarve:采用两阶段的“信息保持引导选择”框架,在减少78%的Token后,模型准确率仅下降1.54%。
- 自适应Token采样器 (ATS):作为一个即插即用的无参数模块,它能根据每张图片的内容动态决定保留多少Token,实现吞吐量翻倍。
- 挑战:许多剪枝方法需要直接访问注意力分数,这可能与FlashAttention等主流加速库不兼容,限制了实际部署中的速度提升。
2. Token聚合与合并 (Pooling & Merging)
如果说剪枝是“丢弃”,那么聚合与合并就是“融合”。这类方法将相似或相邻的Token合并成一个代表性的新Token。
- 工作原理:通过聚类算法(如K-means)或池化操作,将特征相似的Token分组,并用一个聚合后的Token(如均值或聚类中心)来替代它们。
- 代表模型与技术:
- TokenLearner (Google):通过学习一个小的注意力网络,智能地将一组Token压缩成少数几个“摘要Token”。
- PruMerge:结合了剪枝和合并,利用CLIP注意力模式的稀疏性,实现了高达14倍的平均压缩率。
- LLaVA-PruMerge:通过异常值检测选择重要Token,再通过相似性聚类补充信息,在复杂推理任务上实现了18倍的压缩。
3. 结构级压缩 (Structural Compression)
这类方法从源头入手,在图像被转换为Token的最初阶段就减少其数量。
- 工作原理:通过改变视觉编码器的结构或参数来实现。最简单直接的方式是增大Patch Size(例如,从16x16改为32x32,Token数量直接减少75%)。更高级的方法是动态Patching,根据图像内容的复杂性,在重要区域使用小Patch,在背景区域使用大Patch。
- 优点:实现简单,效果直接。
- 缺点:可能会丢失对小物体和精细纹理的识别能力。
4. 专用可学习压缩模块 (Learned Compression Modules)
这是当前最主流、最前沿的方向。它不再依赖简单的丢弃或合并规则,而是设计一个专门的、可端到端训练的**“压缩适配器”**,让模型自己学会如何最高效地“阅读”图片。
- 工作原理:引入一组数量固定、可学习的“查询Token”(Query Token),让它们通过交叉注意力机制(Cross-Attention)去主动“审问”海量的原始图像Token,并从中提取出最精华的信息,最终形成固定长度的压缩表示。
- 代表模型与技术:
- Perceiver Resampler (应用于Flamingo):无论输入图像或视频多大,它始终通过一组固定的潜在Token(Latent Token)进行信息汲取,最终输出64个视觉Token。这是实现固定长度视觉输入的开创性工作。
- Q-Former (应用于BLIP-2, MiniGPT-4):堪称该领域的“事实标准”。它使用32个可学习的查询Token,通过复杂的交叉注意力和自注意力机制,将数百个图像Token高效地蒸馏成32个精华Token,完美地对接了大语言模型。
- MiniCPM-V 4.5的统一3D-Resampler:这项技术更进一步,能够将多帧视频联合压缩,实现了高达96倍的视频Token压缩率,同时在处理高清图片时也极为高效。
实战演练:顶尖模型如何应用Token压缩
| 模型 | 核心压缩技术 | 特点 |
|---|---|---|
| BLIP-2 / MiniGPT-4 | Q-Former | 通过32个可学习查询Token进行信息蒸馏,已成为业界主流范式。 |
| Flamingo | Perceiver Resampler | 无论输入尺寸,始终输出固定数量(如64个)的视觉Token,灵活性高。 |
| LLaVA 系列 | 混合策略 | LLaVA-PruMerge:自适应剪枝+合并,实现18倍压缩。 LLaVA-Zip:根据图像复杂度动态调整压缩比。 LLaVA-Mini:通过查询压缩,实现每张图仅1个Token的极端压缩。 |
| MiniCPM-V 4.5 | 统一3D-Resampler | 专为视频和高清图设计,压缩率极高,且在部署时为内置特性,无需额外配置。 |
| SparseVLM (2024) | 文本引导的无训练剪枝 | 利用文本提示来评估视觉Token的重要性,无需微调即可实现54%的计算量减少。 |
| Matryoshka (M3, 2024) | 嵌套视觉表示 | 像俄罗斯套娃一样,生成不同粒度的视觉Token,推理时可动态选择,用9个Token即可媲美原始576个Token的性能。 |
挑战与未来展望:通往更智能、更高效的视觉理解

尽管图片Token压缩技术取得了巨大成功,但前路依然充满挑战:
- 性能与效率的权衡:如何设计一种压缩策略,既能大幅降低计算量,又能确保在OCR、小物体检测等精细任务上不出现性能下降?
- 硬件与算法的脱节:许多先进的动态剪枝、稀疏化算法与FlashAttention等底层优化库不兼容,导致理论上的FLOPs减少无法完全转化为实际的延迟降低。
- 从“消除”到“构建”:未来的趋势将超越简单的Token消除。例如,探索建设性压缩,即如何用更少的Token构建出信息密度更高的表示,而不是简单地从原始Token中挑选。
未来,我们期待的技术突破将集中在:
- 跨模态引导:更深入地利用文本信息来指导视觉Token的压缩,实现与任务高度相关的动态信息筛选。
- 硬件感知设计:在设计压缩算法之初就考虑硬件特性,确保算法的效率能真正在硬件上体现出来。
- 动态与自适应:像Matryoshka模型一样,让模型能够根据任务需求和可用资源,在推理时动态调整视觉信息的粒度。
结论
图片Token压缩技术不仅仅是一项优化技巧,它正在成为多模态大模型的核心引擎。它将模型从海量冗余数据中解放出来,使其更轻、更快、更专注。随着SparseVLM、Matryoshka等创新方法的涌现,我们正迈向一个全新的时代:在这个时代,AI不仅能“看见”,更能以一种前所未有的高效和智能方式去“理解”我们丰富多彩的视觉世界。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)