LLaMA-Factory 一键微调大模型
LLaMA-Factory 是南京大学人工智能创新研究院开源的轻量级大语言模型(LLM)微调工具包。它的设计目标很明确:让普通开发者也能低成本地玩转大模型。
LLaMA-Factory 是南京大学人工智能创新研究院开源的轻量级大语言模型(LLM)微调工具包。它的设计目标很明确:让普通开发者也能低成本地玩转大模型。在消费级显卡上即可完成训练,不再需要动辄数十万的集群算力。兼容 100+ 开源大模型:LLaMA、Mistral、Baichuan、Qwen、ChatGLM 等主流模型均已覆盖。
核心特点:
-
一站式微调框架
-
支持多种微调方法
-
全参数微调(Full Fine-tuning)
-
LoRA / QLoRA(低资源高效微调)
-
P-Tuning(提示词优化)
-
Delta Weights(模型权重复用)
申请 GPU 云算力
在算多多可免费使用 3060 (30+ 小时),
访问地址:gpuduoduo.com
申请免费算力
使用 LLaMA-Factory 镜像申请实例
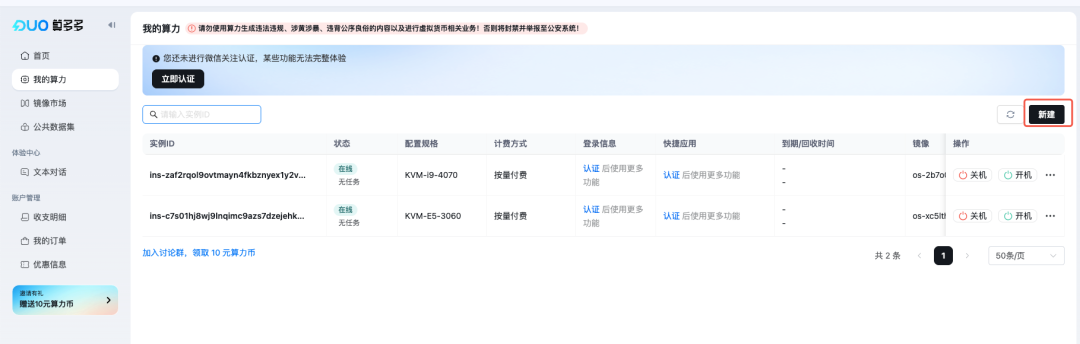
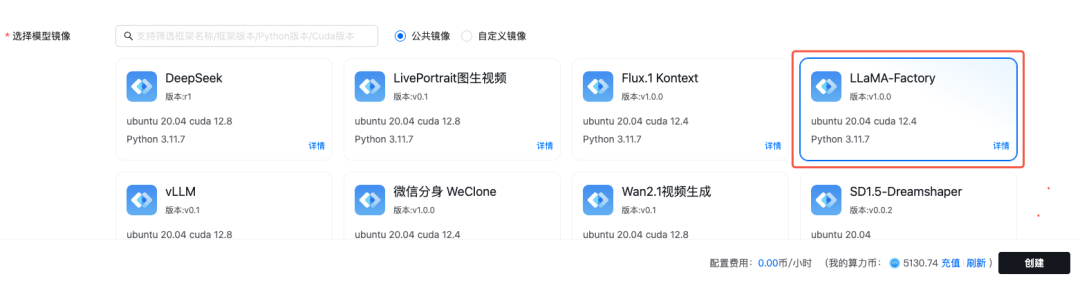
等待 1-3 分钟可完成实例的创建。
开始微调
-
- 实例创建成功后(状态正常,功能可点击),点击"在线 IDE",打开在线 VSCode 进行编码

-
- 打开工程目录
进入llama-factory 所在的目录
- 打开工程目录
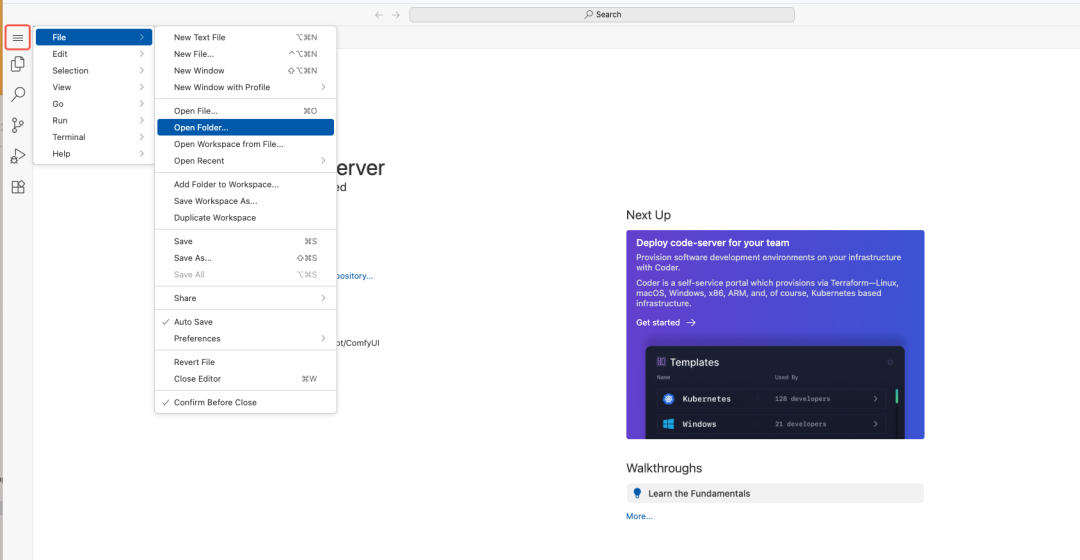
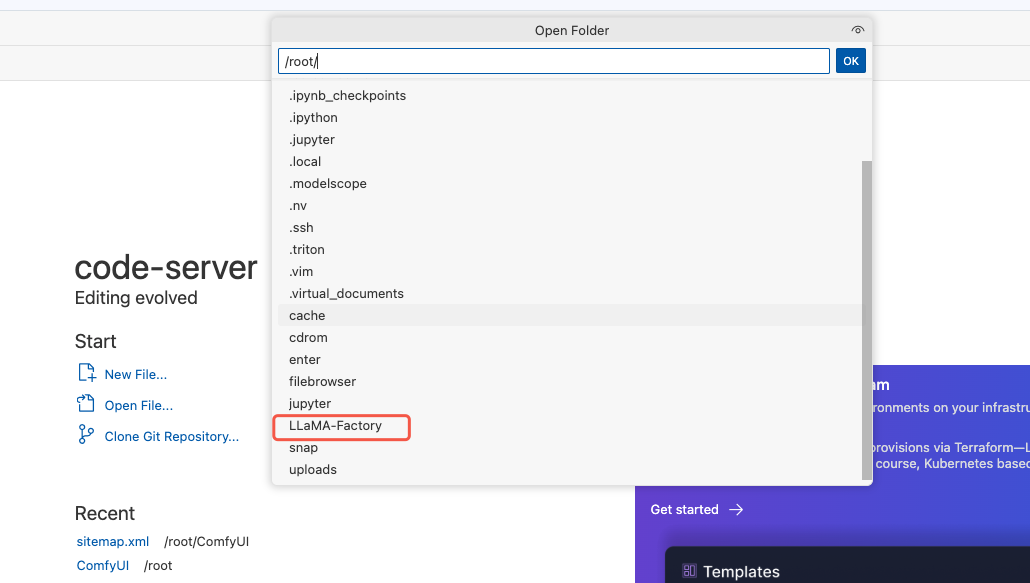
点击 OK
进入终端
根据图示打开终端:
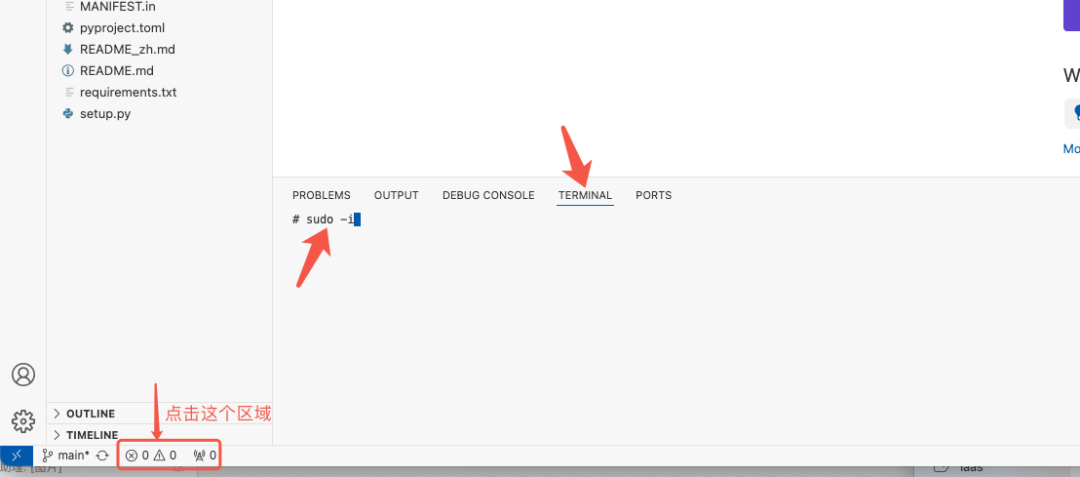
在终端中执行命令提升权限
sudo -i
进入 conda 虚拟环境
cd /root/LLaMA-Factory
conda activate llama_factory
启动服务
使用 llamafactory-cli 命令启动带有 web 页面服务的 llamafactory
llamafactory-cli webui
启动成功后,可以看到控制台打印类似的日志:
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.
打开微调页面
回到算多多,点击“LLaMA-Factory”打开微调页面
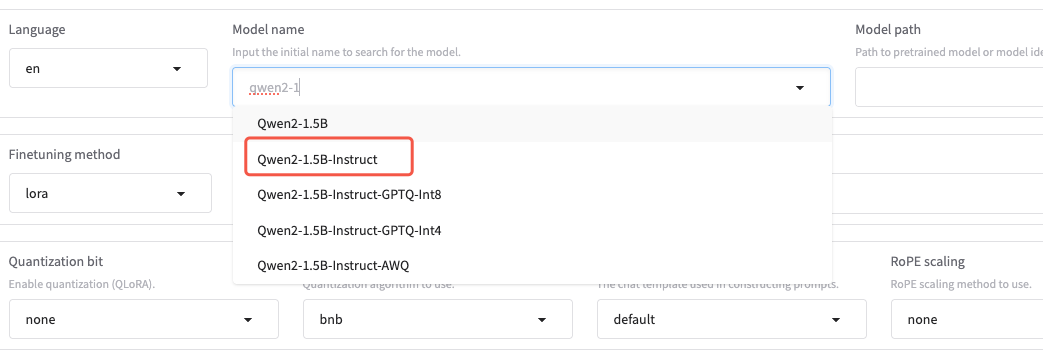
微调的基础模型
实例已预置了Qwen2-1.5B模型,如果模型没有下载,会自动从互联网上下载(默认已调整为 modelscope 源,更加适合国内的网络环境)
其他配置也可以自行修改,如果有需要,可以参考官方教程修改。
选一个你想要使用的数据集
测试阶段可以选第一个,数据量比较小,速度比较快
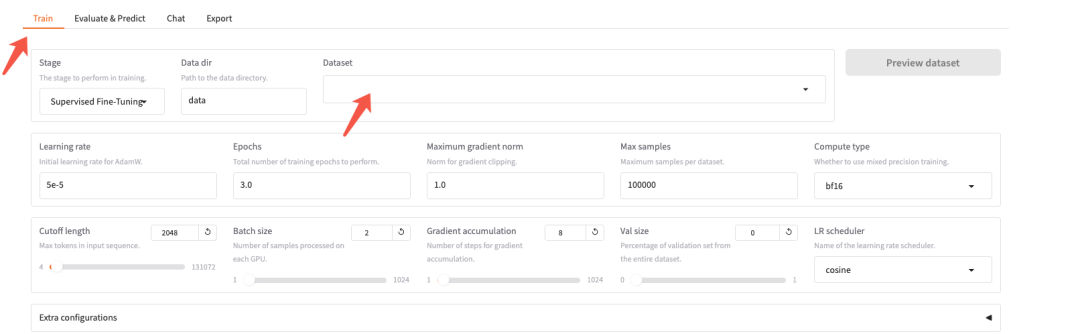
注意:在 /LLaMA-Factory/data/dataset_info.json 可以增加自定义的数据
执行微调
把 web 页面滑到下方,有一个"Start"按钮,点击可以执行微调工作
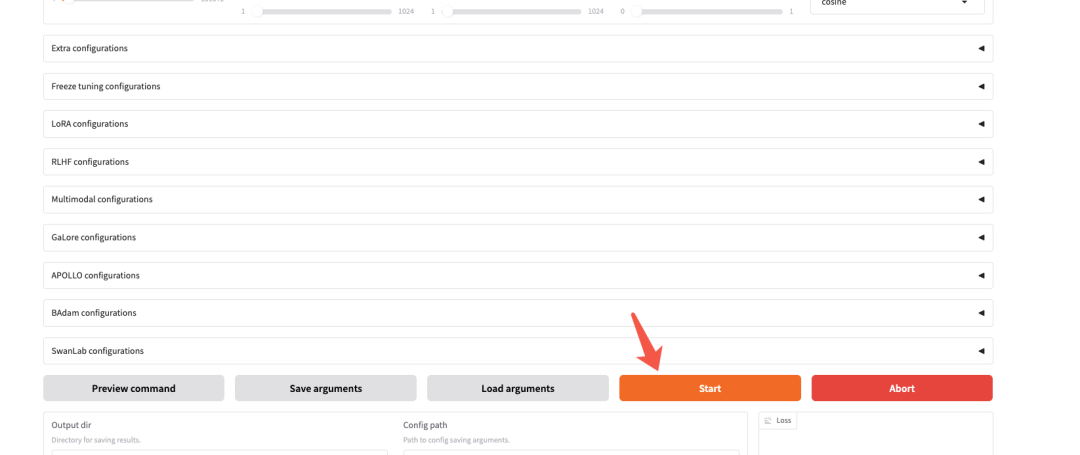
点击后,可以从在线 IDE 终端查看当前的进展情况。
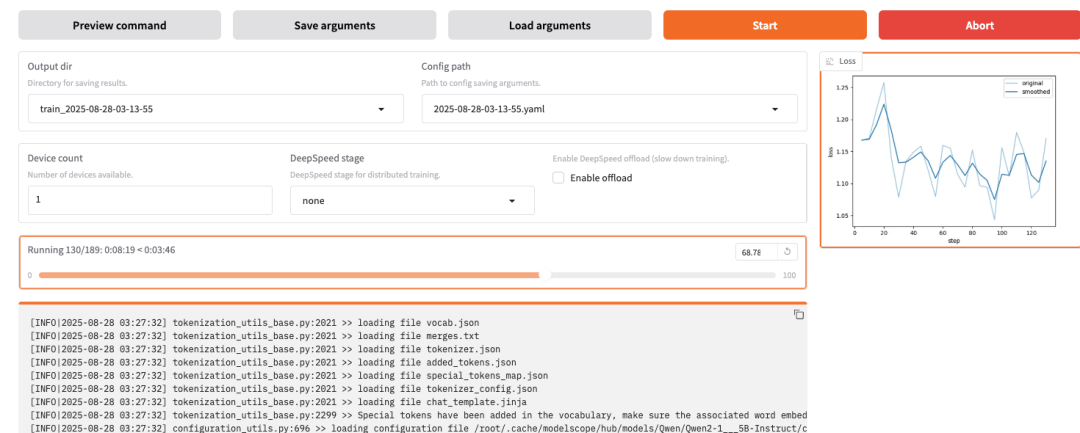
现在正在下载模型:

开始微调了

在 web 页面上也能看到进度和日志
微调完成
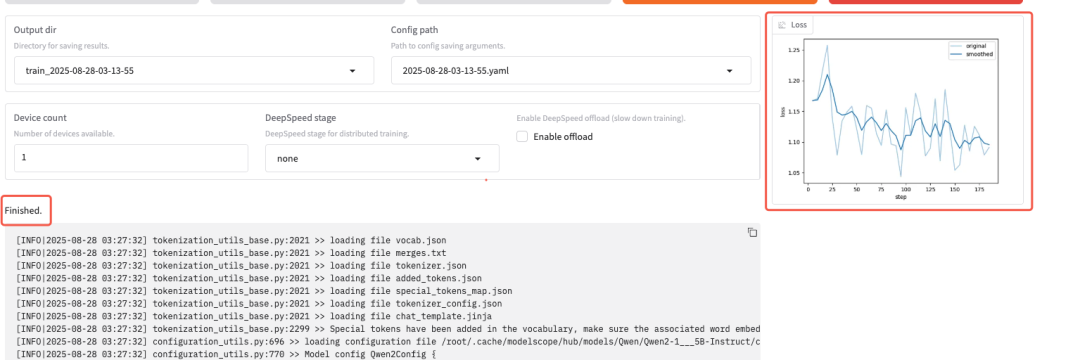
模型保存在 /opt/LLaMA-Factory/saves/
评估微调的模型
主要步骤如下:
-
- 选择评估模型(即刚刚微调后保存的)
-
- 切换到对应预测界面
-
- 选择评估数据集
-
- 开始评估
具体可参考下图进行操作:
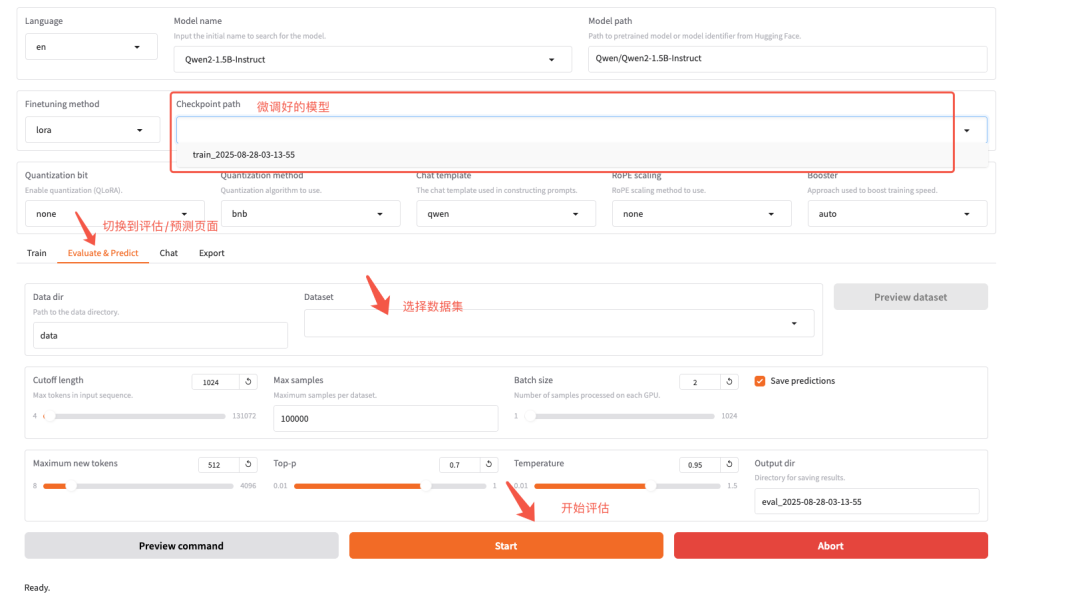
可以看到评估完成了:

如何分析评估结果?
在自然语言处理(NLP)里,模型效果通常需要客观指标来衡量。以下是几种常见的指标:
BLEU-4:常用于机器翻译。基于 n-gram 精确匹配,取 4-gram。值越高,说明翻译结果和参考译文越接近。
ROUGE-1:常用于自动摘要。计算 unigram(单词级别)匹配率。
ROUGE-2:同样用于摘要,基于 bigram(二元词组)匹配率,比 ROUGE-1 更严格。
ROUGE-L:基于 最长公共子序列(Longest Common Subsequence, LCS),能反映整体句子结构的相似度。
一句话总结:
BLEU 看翻译,越高越好;
ROUGE 看摘要,数值越高,说明模型提炼信息的能力越强。
使用微调好的模型进行推理对话
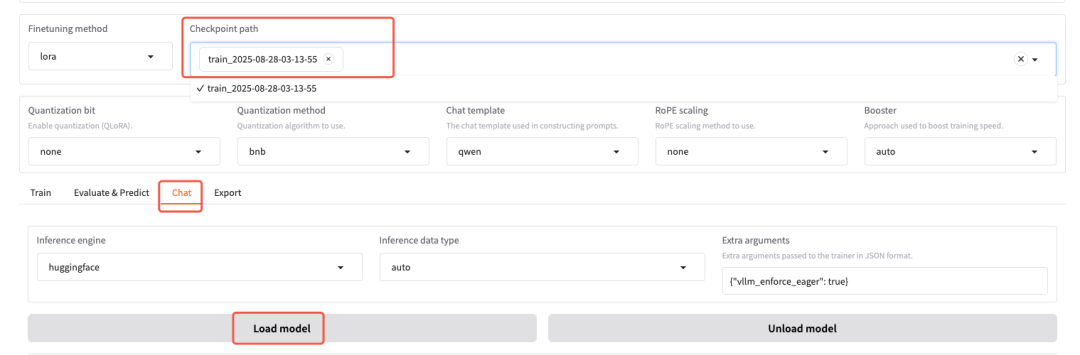
主要步骤如下:
-
- 选择微调模型
-
- 切换到 Chat 对话界面
-
- 点击 “Load Model” 加载模型
加载成功了,开始对话吧
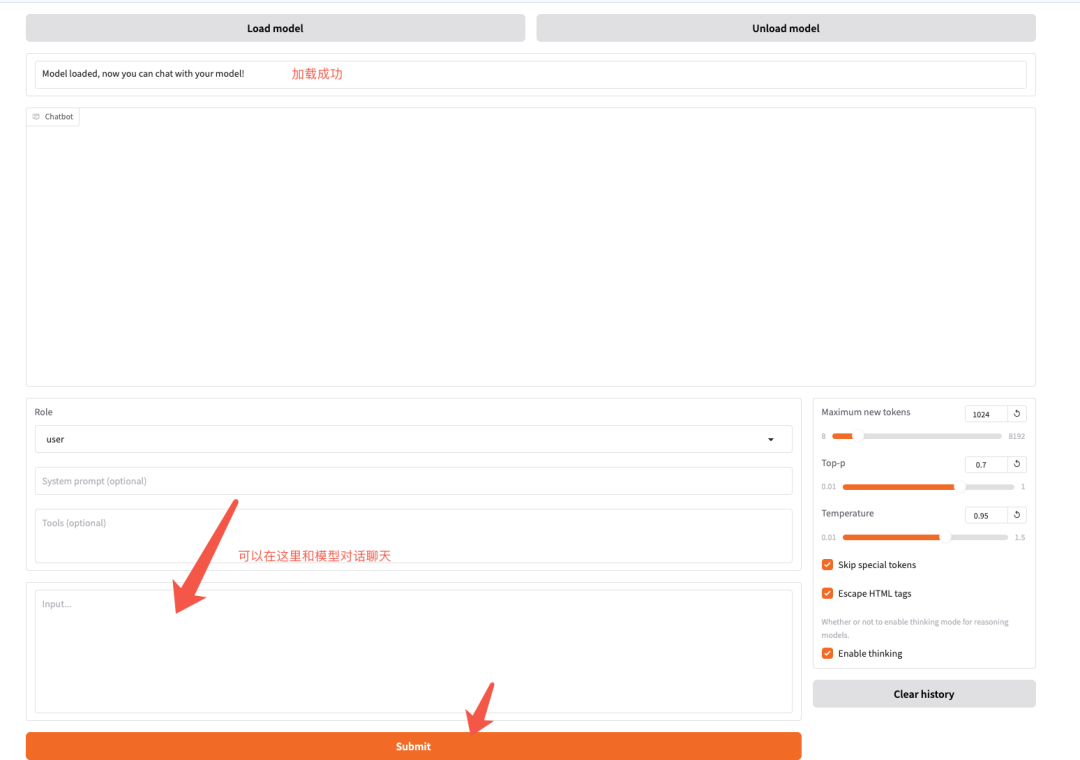
:
导出
主要步骤如下:
-
- 切换到 Export 页面
-
- 填写你想要导出到哪个路径,比如
./ouput
- 填写你想要导出到哪个路径,比如
-
- 点击 “Export” 按钮,导出后的模型保存在工程的 saves 目录
./ouput下
- 点击 “Export” 按钮,导出后的模型保存在工程的 saves 目录
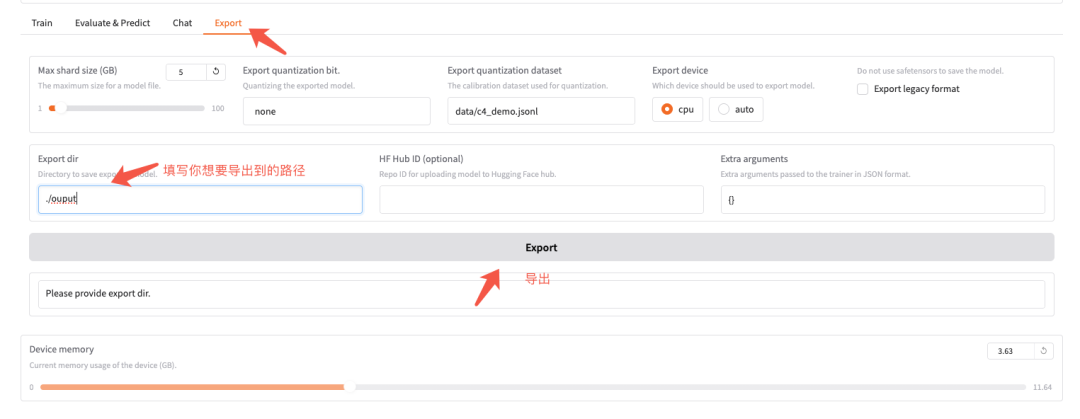
导出成功后,会在导出文件夹中看到 model.safetensors 等模型文件。
接下来可以使用 vllm 或 ollama 或其他工具进行实际的推理应用了,具体的使用教程后面有需要再进行详细介绍。
llam-factory 使用总结
可以看到,从算多多进行一次 llama-factory 的微调、推理、测试工作是非常简单的,没有太多背景的同学也能在 30 分钟左右完成工作,我们在熟悉之后也可以参考更多官方教程,进行其他功能的体验
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献236条内容
已为社区贡献236条内容

所有评论(0)