想去美团做大模型,面试完之后已老实...
一位同学去美团面试大模型岗位,面试完之后发了个帖子,反馈就三个字:已老实。
一位同学去美团面试大模型岗位,面试完之后发了个帖子,反馈就三个字:已老实。
看来妥妥的被面试折磨到了,我们来看一下美团大模型的面试题到底如何:

排除掉最后一个手写代码的实操题之外,上面一共给了11个面试的问题。
这11个问题涵盖的还是比较全面的,包含了基础类、模型类、算法类和工程类的问题。
比如基础类的问题有 BF16/FP16/FP32 的对比,这个其实考察的是候选人对于模型推理 or 训练是的数据的理解,主要从精度(量化)和显存占用两方面回答即可。
模型类的问题主要集中在 DeepSeek-R1 这个模型。
算法类的问题则涉及到了 Rope 和 KV-Cache、Adam 算法。
最后工程性的问题则主要集中在显存占用方面,重点考察的也是候选人对大模型推理 or 训练过程的整体理解。
一句话,考察的很全面的。
怪不得同学直呼已老实。
这篇文章,我们就以美团面试中出现的 KV-Cache + 大模型的推理过程为例,来详细解释一下——
为什么在大模型的推理过程中需要使用 KV-Cache 技术?
为什么需要 KVCache?
在你看完前面的位置编码后,接下来就换一个视角,从大模型的视角看以下 KVCache 缓存技术。
乍一看这个技术好像很深奥,又是 KV 又是缓存的。
但是,如果你结合大模型运行的原理和机制,以及之前介绍的注意力机制的运算方法来了解,会发现这个技术其实也很好理解。
什么是 KVCache?
这里的 KV 指的是注意力机制中的 Key 和 Value。Cache 是计算机科学中的一个重要术语,中文翻译为缓存。
因此, KVCache 就是针对注意力机制中计算 Key 和 Value 时的一个缓存技术。
还记得注意力机制是如何计算的吗?下图展示了注意力机制的计算过程。
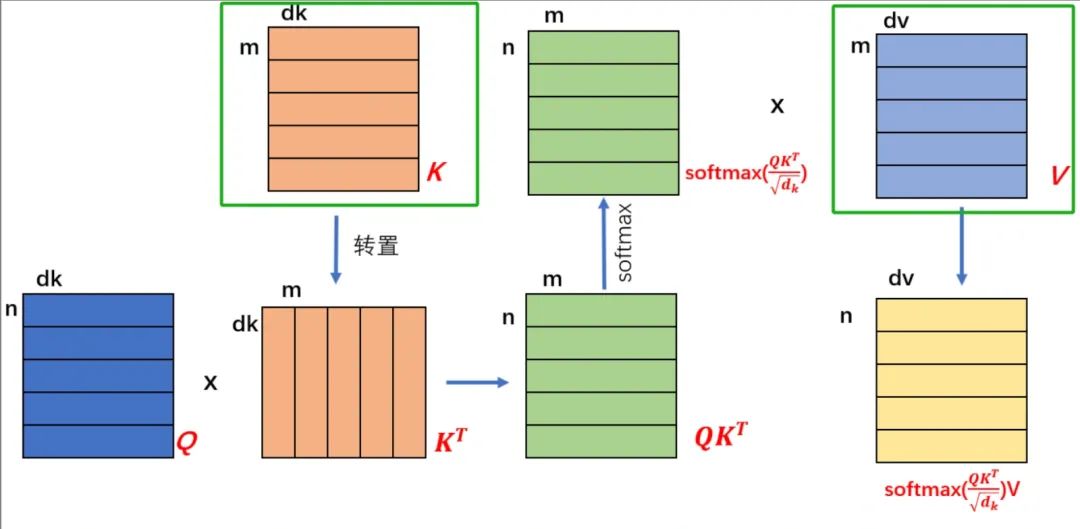
在图中,两个绿色方框标注的分别是计算注意力时的 K 矩阵和 V 矩阵。
事实上,在 Transoformer 中,由于使用的是自注意力,Q/K/V都是由相同的输入数据线性映射得到的(通过多头注意力机制中的线性映射层得到)
在进一步阅读之前,先来看一下大模型是如何完成文本翻译这种任务的推理的。
大模型的推理过程
首先,目前主流的大模型采用的架构是 Decode-Only 架构,也就是只使用了 Transformer 架构中的解码器部分,并不使用编码器部分。
在使用 Decoder-Only 架构的大模型进行推理时,整个推理过程主要分为两个阶段,一个是 Prefill 阶段,一个是 Decode 的阶段。
Prefill 和 Decode 过程
我们先来看一下大模型是如何和你进行交互并且生成回答的,在这个过程中,哪些是 Prefill 阶段,哪些是 Decode 阶段。
当你和 GPT 这种模型进行对话时,你会先输入你的问题,对于大模型而言,这个问题叫做prompt,也就是提示词。
大模型在接收到这个提示词之后,便会执行推理过程。
首先它会根据你输入的提示词来生成第一个回答的单词,随后会根据输出的第一个回答的单词来不断的预测后一个回答的单词,直到把需要回答的单词全部生成完,这也是为什么这类对话任务又叫做文本生成任务的原因。
因此你可以看到,大模型在生成回答的时候,是依据之前已生成的内容来选择下一个具有最大概率的单词作为输出的。
可以说每生成一个单词都是一种基于概率的预测过程。
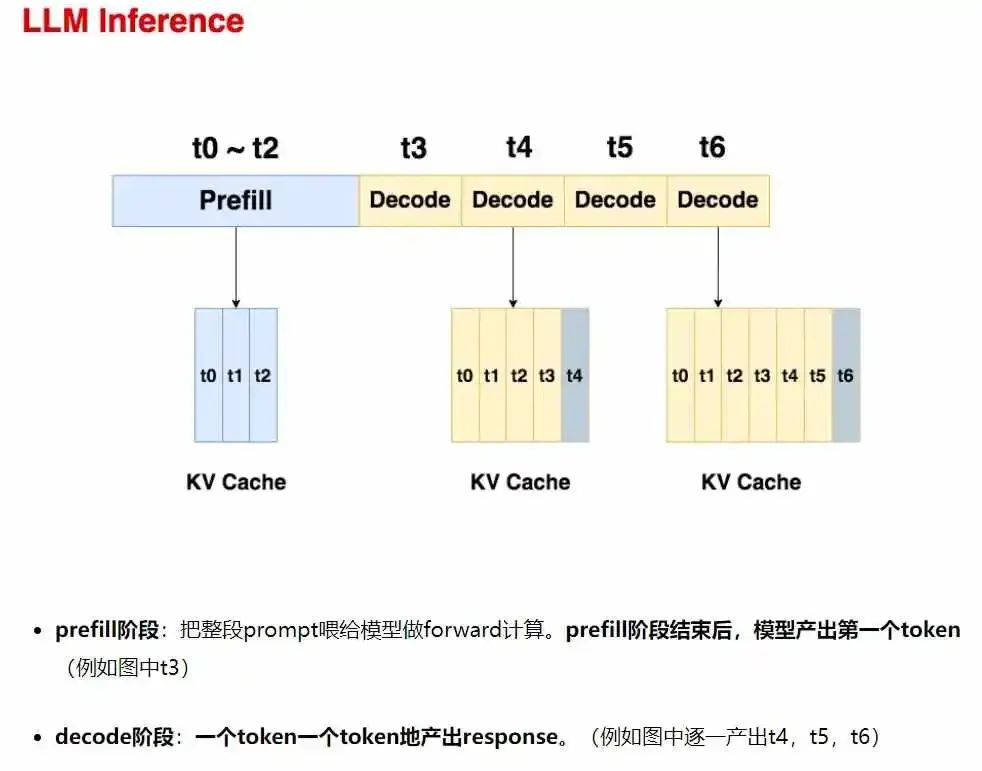
而 Prefill 阶段指的是大模型接收到用户输入的问题后,生成回答中的第一个单词的阶段。
Decode 阶段则是大模型根据第一个字符进行后续预测的阶段,如上图。
这两个阶段有一个共通点,就是大模型运行的过程是一样的,不一样的是大模型接收到的输入不一样。
以上是引入了 KVCache 优化技术之后的逻辑,也是现在最主流的推理流程。
在不引入 KVCache 的情况下,大模型的每次预测都是基于 Prompt 进行的下一个单词的预测。
举个例子,假设你问大模型一句话:“今天吃饭了吗?”,大模型最终回答你:“我不需要吃饭,不过谢谢你的关心,你呢,今天吃什么了?”

对大模型来说,第一次的输入是“今天吃饭了吗”这句话,模型的输出是回答中的第一个词,也就是“我”。
随后,将得到的输出和输入加在一起,得到 “今天吃饭了吗?我” 作为新的 Prompt 输入给大模型,然后大模型输出"不”,依次类推,直到满足一定的条件(比如输出字数超过了设置的限制,或者输出了最后一个字符(EOS, End of Sequence)),大模型则停止输出,此时模型回答完毕。
就像下面这样:
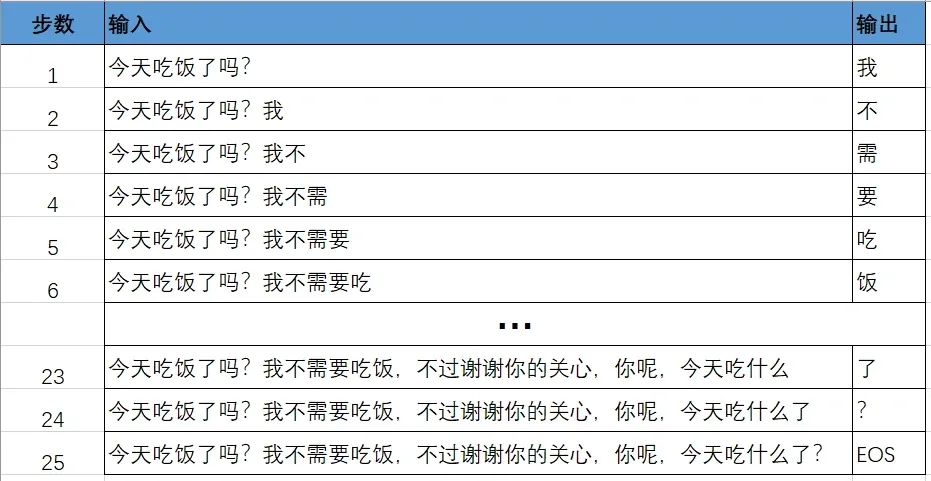
这个过程看着是不是比较蠢、比较笨重?但事实上大模型和你对话的流程确实是这样。
这个过程让你感觉到比较蠢比较笨重的地方,我猜可能就是每个步骤输入给大模型的提示词都有大量的重复单词,就像上图左侧输入那一列展示的那样。
而且这样做会带来很多问题,最严重的就是大模型的计算量会暴增,而且每个步骤都需要重复计算相同的单词的,尤其是在做注意力机制中的运算中。
因此,一个自然而然的想法就是,能不能不在每个步骤中都重复计算上一个步骤已经计算过的单词,新的步骤只计算新的输入就好了。
这就是 KVCache。
KVCache 就是把上一步骤已经计算过的单词找个地方缓存下来,在下一步的时候直接拿来用,并且把新的输入加到缓存好单词的末尾就可以了。
如此一来,有了 KVCache 之后,大模型的推理过程就变成了下面的样子。
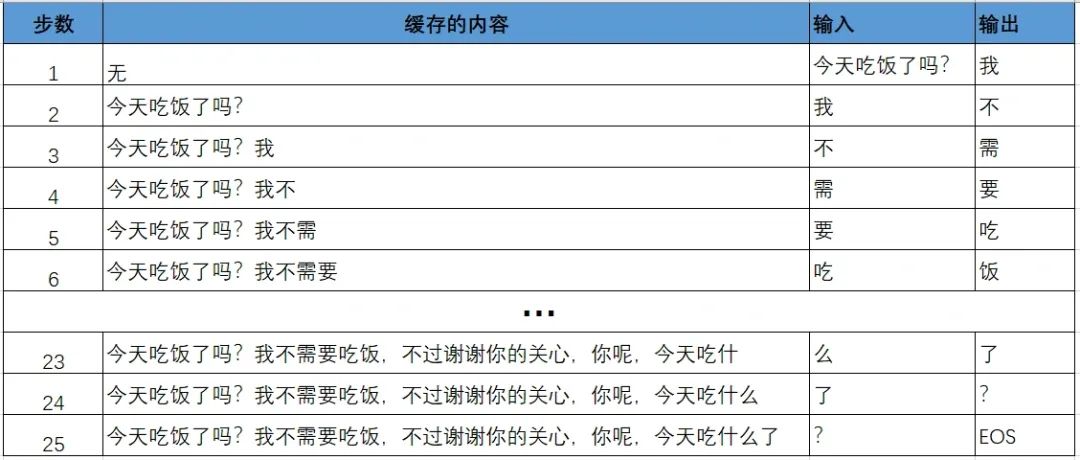
上图中,第二列的句子(或token序列)就是每个步骤运行时已经缓存的内容。
有了缓存之后,每个步骤只需要输入上一步骤预测的输出即可。
这样一来,大模型的计算只需要处理后两列的内容,是不是比之前简洁很多?
这就是 KVCache 的作用。
也正因如此,步骤 1 被称为 Prefill 阶段,步骤 2 及之后被称为 Decode 阶段。
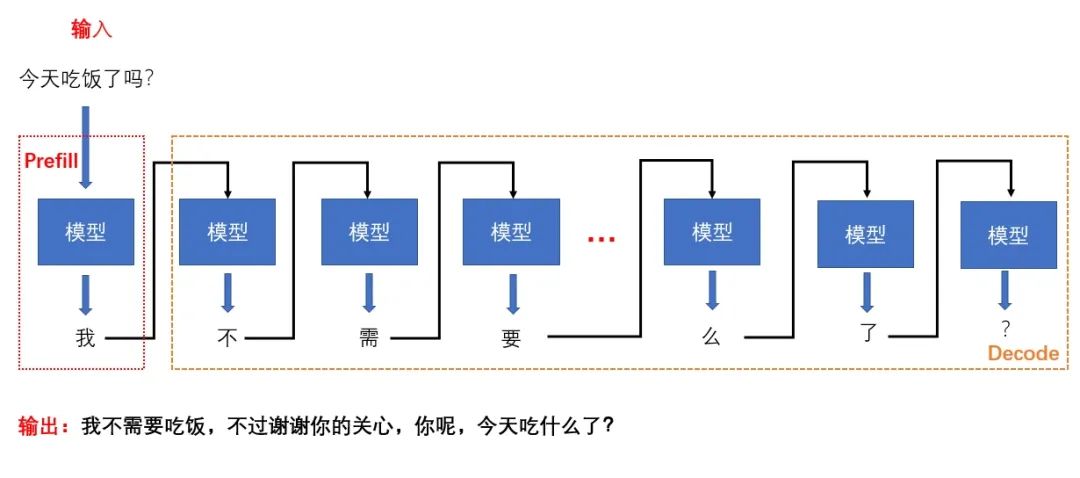
在了解了这个过程后,我们接下来将这个过程和注意力机制中使用 Q/K/V 计算注意力的过程进行对应,来进一步说明这个技术为什么叫做 KVCache,而不是 QCache。
上图中,每一步的输入为上一步输出的预测单词,这个输入便是 Query,也就是注意力机制中使用到的 Q,那在注意力机制中使用的 K 和 V 在哪里呢?
在注意力机制计算中,尤其是 transformer 架构中的自注意力机制,K 和 V 被认为是存储了所有历史信息的字典,注意力机制的计算过程便是根据已发生的历史信息以及当前的输入 Query 来计算出下一个预测单词的概率。
因此,在 Prefill 阶段,因为是第一次输入,此时的 Q/K/V 都等于原始输入对应的词向量,也就是说,此时的 Q/K/V 都是“今天你吃饭了吗?”。
而在第一个 Decode 的过程中,输入的 Q 为 Prefill 的输出“我”,此时的 K 和 V 需要包含历史信息,就变成了“今天你吃饭了吗?”,同理,第二个 Decode 的过程中输入 Q 为“不”,而此时的 K 和 V 则为“今天你吃饭了吗?我”,以此类推,直到输出一个完整的句子。
因为 K 和 V 是存储了历史信息的,因此只需要多 K 和 V 做缓存,Q 不需要,这也是为什么这个技术叫做 KVCache 的原因。
KVCache 的增长
你可以看到,在 Decode 的阶段,每一步的输入和输出都是一个单词,但是在计算注意力机制的过程中,使用的 K 和 V 则包含历史信息,可以说 K 和 V 的长度,是随着输出的增长而不断增长的。
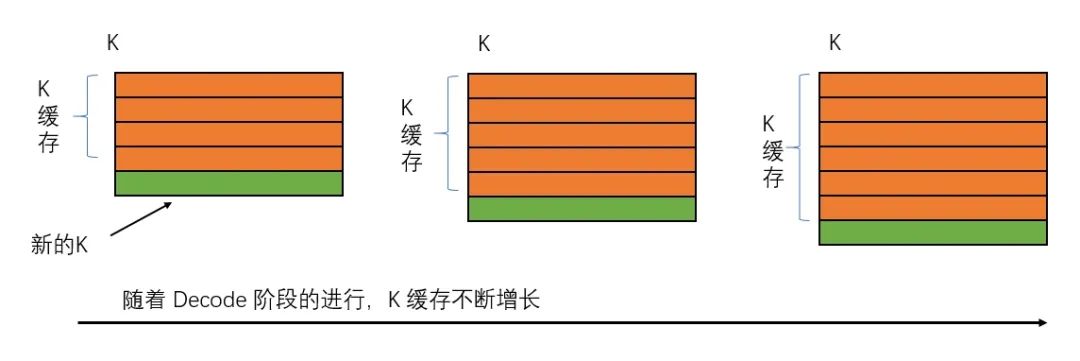
相信你看到这里,大概能明白为什么要使用 KVCache 了。
主要的原因是:
在Decode 的阶段,每预测一个新的输出,计算注意力的过程中使用的 K 和 V 有绝大部分是历史信息,而这些历史信息在上一步其实已经计算过了,完全没有必要每生成一个新的单词重复进行相关的计算。
这便是 KVCache 这个技术提出的背景,其目的主要还是为了加速大模型在推理过程中的计算速度。
在计算机科学中,有一种性能优化的思想叫做“用空间换时间”,KVCache 便是一种典型的牺牲了内存空间,减少了程序的运行时间的方法。
当当当当,如果你看到了这里并且理解了上面对于 KVCache 提出的背景以及原理,我相信你在面试中绝对可以对与 KVCache 有关的题目应对自如了。
并且如果可以把这篇文章背下来,拿个面试满分也不是没有可能得呀。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献266条内容
已为社区贡献266条内容

所有评论(0)