强大的开源文档问答工具-Kotaemon
Kotaemon是一个基于RAG架构的开源文档问答工具,支持与文档的智能交互。它采用模块化设计,整合了多种AI技术和向量数据库,提供混合检索、多模态处理和本地化部署能力。核心功能包括文档索引、智能问答和知识管理,适用于企业、教育和个人场景。项目优势在于可扩展的架构、直观的Web界面和丰富的开发者支持,但也面临资源消耗大、配置复杂等挑战。通过二次开发可增强分布式部署、多语言支持和安全功能,是构建定制
·
Kotaemon 是一个基于 RAG(Retrieval-Augmented Generation)架构的开源文档问答工具,为用户提供与文档对话的智能交互体验。该项目同时服务于终端用户和开发者,具有高度的可扩展性和定制化能力。
技术栈分析
核心技术栈
- 后端框架
- Python 3.10+: 主要开发语言
- Gradio: Web UI 框架,用于构建交互式界面
- FastAPI/Flask: API 服务层(推测)
- AI/ML 技术栈
- LangChain: LLM 集成和管道构建
- Transformers: 模型推理和嵌入
- llama-cpp-python: 本地 LLM 支持
- Ollama: 本地模型管理
- 向量数据库和检索
- ChromaDB: 默认向量数据库
- LanceDB: 高性能向量存储
- Elasticsearch: 全文搜索支持
- Milvus/Qdrant: 可选向量数据库
- 文档处理
- Unstructured: 多格式文档解析
- PDF.js: PDF 浏览器内预览
- Azure Document Intelligence: OCR 和表格解析
- Adobe PDF Extract: 高级 PDF 内容提取
- Docling: 开源文档解析
- 部署和容器化
- Docker: 容器化部署
- Docker Compose: 多服务编排
支持的 LLM 提供商
- OpenAI (GPT-3.5, GPT-4)
- Azure OpenAI
- Cohere
- Groq
- Ollama (本地模型)
- 本地 GGUF 模型
项目优势
1. 架构设计优势
- 模块化设计: 高度解耦的组件架构
- 混合检索: 结合全文检索和向量检索
- 多模态支持: 处理文本、图像、表格等多种内容
- 插件化架构: 易于扩展和定制
2. 用户体验优势
- 直观的 Web UI: 基于 Gradio 的现代化界面
- 多用户支持: 支持用户权限管理和协作
- 实时预览: 内置 PDF 查看器和高亮显示
- 详细引用: 提供来源追溯和相关性评分
3. 技术实现优势
- 混合 RAG 管道: 提高检索准确性
- 复杂推理支持: 支持 ReAct、ReWOO 等智能体
- GraphRAG 集成: 支持知识图谱增强检索
- 本地化部署: 支持完全离线运行
4. 开发者友好
- 丰富的文档: 详细的开发和使用指南
- 可定制性强: 支持自定义推理和索引管道
- Docker 支持: 简化部署流程
项目劣势
1. 性能局限性
- 资源消耗: 多模型并行可能消耗大量内存
- 处理速度: 复杂文档解析可能较慢
- 扩展性: 单机部署在大规模使用时可能存在瓶颈
2. 技术依赖
- 版本冲突: 多个 AI 库可能存在依赖冲突
- API 依赖: 某些功能强依赖外部 API
- 模型兼容性: 不同模型格式的支持程度不一
3. 维护复杂性
- 配置复杂: 多种组件需要协调配置
- 更新维护: AI 技术栈更新频繁,维护成本高
- 调试困难: 复杂的 RAG 管道难以调试
使用场景
1. 企业知识管理
- 内部文档检索: 企业内部知识库建设
- 技术文档问答: 开发团队技术资料查询
- 合规文档管理: 法务和合规文件智能检索
2. 教育培训
- 学术研究: 研究论文和资料分析
- 在线教育: 教材内容智能问答
- 培训材料: 员工培训资料互动学习
3. 个人知识助手
- 文档整理: 个人文档集合管理
- 阅读助手: 长文档快速理解
- 笔记系统: 智能笔记检索和整理
4. 专业服务
- 法律咨询: 法律条文和案例检索
- 医疗文档: 医学资料和病历分析
- 金融报告: 财务文档智能分析
代码结构分析
主要目录结构
kotaemon/
├── app.py # 主应用入口
├── flowsettings.py # 应用配置
├── libs/
│ └── ktem/
│ ├── ktem/
│ │ ├── reasoning/ # 推理模块
│ │ ├── index/ # 索引模块
│ │ ├── retrieval/ # 检索模块
│ │ ├── llms/ # LLM 集成
│ │ └── embeddings/ # 嵌入模型
├── ktem_app_data/ # 应用数据存储
├── docker/ # Docker 配置
└── docs/ # 文档核心组件架构
1. 推理引擎 (Reasoning Engine)
python
# 简化的推理管道接口
class ReasoningPipeline:
def __init__(self, retriever, generator, reranker):
self.retriever = retriever
self.generator = generator
self.reranker = reranker
def process(self, query: str, documents: List[Document]):
# 检索相关文档
retrieved = self.retriever.retrieve(query, documents)
# 重新排序
reranked = self.reranker.rerank(query, retrieved)
# 生成答案
answer = self.generator.generate(query, reranked)
return answer2. 文档索引系统
python
# 混合索引实现
class HybridIndex:
def __init__(self, vector_store, text_store):
self.vector_store = vector_store # 向量检索
self.text_store = text_store # 全文检索
def add_document(self, document):
# 向量化存储
embeddings = self.embed(document.content)
self.vector_store.add(document.id, embeddings)
# 全文索引
self.text_store.add(document.id, document.content)
def search(self, query, top_k=10):
# 混合检索
vector_results = self.vector_store.similarity_search(query, top_k//2)
text_results = self.text_store.keyword_search(query, top_k//2)
return self.merge_results(vector_results, text_results)主要执行流程
1. 文档上传和索引流程
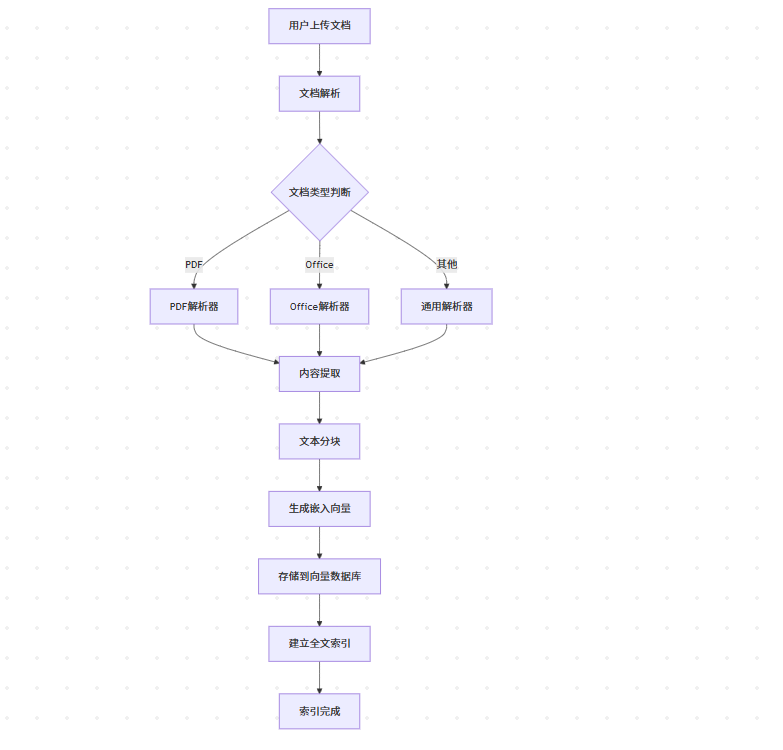
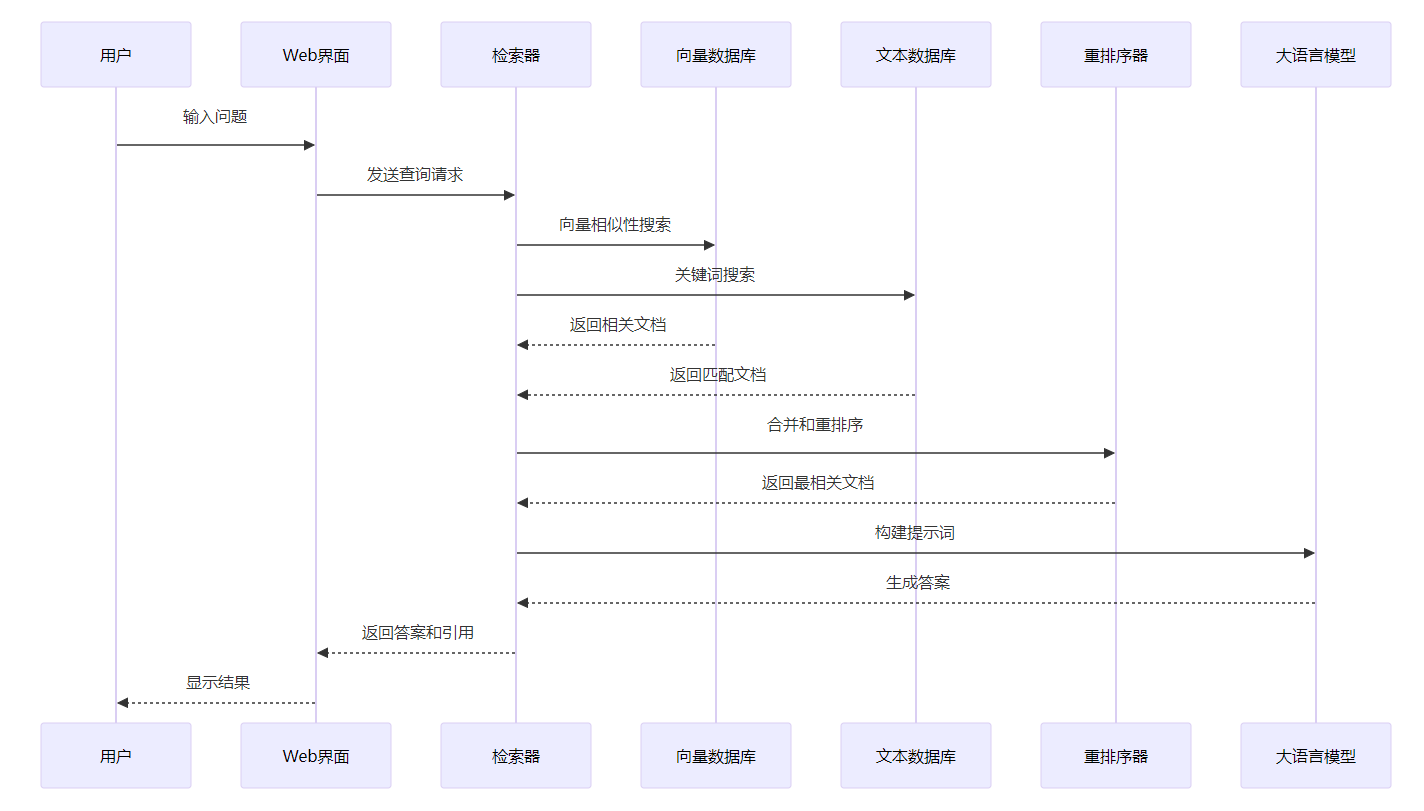
2. 问答查询流程
开发示例
1. 自定义推理管道
python
from ktem.reasoning.base import BaseReasoning
from ktem.llms.manager import LLMManager
from ktem.retrieval.manager import RetrievalManager
class CustomQAPipeline(BaseReasoning):
"""自定义问答管道"""
def __init__(self):
super().__init__()
self.llm_manager = LLMManager()
self.retrieval_manager = RetrievalManager()
def run(self, query: str, conversation_id: str = None):
"""执行问答流程"""
# 1. 预处理查询
processed_query = self.preprocess_query(query)
# 2. 检索相关文档
retrieved_docs = self.retrieval_manager.retrieve(
query=processed_query,
top_k=10
)
# 3. 文档重排序
reranked_docs = self.rerank_documents(processed_query, retrieved_docs)
# 4. 构建上下文
context = self.build_context(reranked_docs[:5])
# 5. 生成答案
prompt = self.create_prompt(processed_query, context)
response = self.llm_manager.generate(prompt)
# 6. 后处理
final_answer = self.postprocess_answer(response, reranked_docs)
return {
"answer": final_answer,
"sources": [doc.metadata for doc in reranked_docs[:3]],
"confidence": self.calculate_confidence(response, reranked_docs)
}
def preprocess_query(self, query: str) -> str:
"""查询预处理"""
# 可以添加查询扩展、纠错等逻辑
return query.strip()
def rerank_documents(self, query: str, docs: List) -> List:
"""文档重排序"""
# 实现自定义重排序逻辑
return sorted(docs, key=lambda x: x.score, reverse=True)
def build_context(self, docs: List) -> str:
"""构建上下文"""
context_parts = []
for i, doc in enumerate(docs):
context_parts.append(f"文档{i+1}: {doc.content}")
return "\n\n".join(context_parts)
def create_prompt(self, query: str, context: str) -> str:
"""创建提示词"""
prompt = f"""
基于以下上下文信息,回答用户问题。请确保答案准确且有据可依。
上下文信息:
{context}
用户问题:{query}
请提供详细的答案,并指出信息来源:
"""
return prompt
def postprocess_answer(self, response: str, docs: List) -> str:
"""答案后处理"""
# 可以添加答案验证、格式化等逻辑
return response
def calculate_confidence(self, response: str, docs: List) -> float:
"""计算置信度"""
# 实现置信度计算逻辑
return 0.852. 自定义文档解析器
python
from ktem.index.file.base import BaseFileIndexRetriever
from typing import List, Dict, Any
class CustomDocumentParser(BaseFileIndexRetriever):
"""自定义文档解析器"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.supported_extensions = ['.txt', '.md', '.json']
def parse_document(self, file_path: str) -> Dict[str, Any]:
"""解析文档内容"""
if file_path.endswith('.json'):
return self.parse_json(file_path)
elif file_path.endswith('.md'):
return self.parse_markdown(file_path)
else:
return self.parse_text(file_path)
def parse_json(self, file_path: str) -> Dict[str, Any]:
"""解析JSON文档"""
import json
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 提取文本内容
text_content = self.extract_text_from_json(data)
return {
'content': text_content,
'metadata': {
'file_type': 'json',
'source': file_path,
'structure': self.analyze_json_structure(data)
}
}
def parse_markdown(self, file_path: str) -> Dict[str, Any]:
"""解析Markdown文档"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 提取标题和内容
sections = self.extract_markdown_sections(content)
return {
'content': content,
'metadata': {
'file_type': 'markdown',
'source': file_path,
'sections': sections
}
}
def extract_text_from_json(self, data: Dict) -> str:
"""从JSON中提取文本"""
text_parts = []
def extract_recursive(obj, path=""):
if isinstance(obj, dict):
for key, value in obj.items():
new_path = f"{path}.{key}" if path else key
if isinstance(value, str):
text_parts.append(f"{new_path}: {value}")
else:
extract_recursive(value, new_path)
elif isinstance(obj, list):
for i, item in enumerate(obj):
extract_recursive(item, f"{path}[{i}]")
extract_recursive(data)
return "\n".join(text_parts)
def extract_markdown_sections(self, content: str) -> List[Dict]:
"""提取Markdown章节"""
import re
sections = []
lines = content.split('\n')
current_section = None
for line in lines:
if re.match(r'^#+\s', line):
if current_section:
sections.append(current_section)
level = len(line) - len(line.lstrip('#'))
title = line.lstrip('# ').strip()
current_section = {
'level': level,
'title': title,
'content': []
}
elif current_section:
current_section['content'].append(line)
if current_section:
sections.append(current_section)
return sections
# 使用示例
parser = CustomDocumentParser()
document_data = parser.parse_document('example.json')3. 自定义检索器
python
from ktem.retrieval.base import BaseRetriever
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
class TfidfRetriever(BaseRetriever):
"""基于TF-IDF的检索器"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.vectorizer = TfidfVectorizer(
max_features=10000,
stop_words='english',
ngram_range=(1, 2)
)
self.document_vectors = None
self.documents = []
def add_documents(self, documents: List):
"""添加文档到索引"""
self.documents.extend(documents)
# 提取文档内容
doc_contents = [doc.page_content for doc in self.documents]
# 训练TF-IDF向量器
self.document_vectors = self.vectorizer.fit_transform(doc_contents)
def retrieve(self, query: str, top_k: int = 10) -> List:
"""检索相关文档"""
if self.document_vectors is None:
return []
# 将查询转换为向量
query_vector = self.vectorizer.transform([query])
# 计算相似度
similarities = cosine_similarity(query_vector, self.document_vectors).flatten()
# 获取top-k结果
top_indices = np.argsort(similarities)[::-1][:top_k]
results = []
for idx in top_indices:
if similarities[idx] > 0: # 过滤相似度为0的结果
doc = self.documents[idx]
doc.metadata['retrieval_score'] = similarities[idx]
results.append(doc)
return results二次开发建议
1. 系统架构优化
分布式部署
- 微服务化: 将检索、生成、索引等功能拆分为独立服务
- 负载均衡: 使用 Nginx 或云负载均衡器分发请求
- 缓存层: 引入 Redis 缓存常用查询结果
- 消息队列: 使用 RabbitMQ 或 Kafka 处理异步任务
数据库优化
python
# 数据库连接池配置示例
from sqlalchemy import create_engine
from sqlalchemy.pool import QueuePool
engine = create_engine(
"postgresql://user:pass@localhost/kotaemon",
poolclass=QueuePool,
pool_size=20,
max_overflow=30,
pool_recycle=3600
)2. 性能优化策略
检索性能优化
python
class OptimizedRetriever:
def __init__(self):
self.cache = {}
self.batch_size = 100
def retrieve_with_cache(self, query: str, top_k: int = 10):
cache_key = f"{query}_{top_k}"
if cache_key in self.cache:
return self.cache[cache_key]
results = self.retrieve(query, top_k)
self.cache[cache_key] = results
return results
def batch_retrieve(self, queries: List[str]):
"""批量检索提高效率"""
results = []
for i in range(0, len(queries), self.batch_size):
batch = queries[i:i + self.batch_size]
batch_results = [self.retrieve(q) for q in batch]
results.extend(batch_results)
return results异步处理
python
import asyncio
from concurrent.futures import ThreadPoolExecutor
class AsyncProcessor:
def __init__(self, max_workers=4):
self.executor = ThreadPoolExecutor(max_workers=max_workers)
async def async_retrieve(self, query: str):
"""异步检索"""
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
self.executor,
self.retriever.retrieve,
query
)
async def async_generate(self, prompt: str):
"""异步生成"""
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
self.executor,
self.llm.generate,
prompt
)3. 功能扩展建议
A. 多语言支持
python
class MultiLanguageProcessor:
def __init__(self):
self.language_detectors = {
'zh': ChineseProcessor(),
'en': EnglishProcessor(),
'ja': JapaneseProcessor()
}
def detect_language(self, text: str) -> str:
# 语言检测逻辑
pass
def process_by_language(self, text: str, lang: str):
processor = self.language_detectors.get(lang)
if processor:
return processor.process(text)
return textB. 实时协作功能
python
import websocket
import json
class CollaborationManager:
def __init__(self):
self.active_sessions = {}
self.document_locks = {}
def handle_user_action(self, user_id: str, action: dict):
"""处理用户协作行为"""
if action['type'] == 'document_edit':
self.broadcast_change(action, exclude_user=user_id)
elif action['type'] == 'comment_add':
self.save_comment(action)
self.notify_collaborators(action)
def broadcast_change(self, change: dict, exclude_user: str = None):
"""广播文档变更"""
for session_id, session in self.active_sessions.items():
if session.user_id != exclude_user:
session.send_message(change)C. 高级分析功能
python
class AnalyticsEngine:
def __init__(self):
self.query_analyzer = QueryAnalyzer()
self.performance_monitor = PerformanceMonitor()
def analyze_user_behavior(self, user_id: str):
"""分析用户行为模式"""
queries = self.get_user_queries(user_id)
patterns = self.query_analyzer.identify_patterns(queries)
return {
'frequent_topics': patterns['topics'],
'query_complexity': patterns['complexity'],
'usage_trends': patterns['trends']
}
def generate_insights(self):
"""生成系统洞察报告"""
return {
'popular_documents': self.get_popular_documents(),
'query_success_rate': self.calculate_success_rate(),
'performance_metrics': self.performance_monitor.get_metrics()
}4. 安全性增强
用户认证和授权
python
from flask_jwt_extended import JWTManager, create_access_token
from werkzeug.security import check_password_hash
class AuthManager:
def __init__(self):
self.jwt = JWTManager()
def authenticate_user(self, username: str, password: str):
"""用户身份验证"""
user = self.get_user(username)
if user and check_password_hash(user.password_hash, password):
access_token = create_access_token(identity=user.id)
return {'access_token': access_token, 'user': user}
return None
def authorize_document_access(self, user_id: str, document_id: str):
"""文档访问授权"""
document = self.get_document(document_id)
return document.is_accessible_by(user_id)数据加密
python
from cryptography.fernet import Fernet
class DataEncryption:
def __init__(self, key: bytes = None):
self.key = key or Fernet.generate_key()
self.cipher = Fernet(self.key)
def encrypt_document(self, content: str) -> bytes:
"""加密文档内容"""
return self.cipher.encrypt(content.encode())
def decrypt_document(self, encrypted_content: bytes) -> str:
"""解密文档内容"""
return self.cipher.decrypt(encrypted_content).decode()5. 监控和运维
系统监控
python
import logging
import time
from functools import wraps
class SystemMonitor:
def __init__(self):
self.logger = logging.getLogger('kotaemon_monitor')
self.metrics = {
'request_count': 0,
'error_count': 0,
'avg_response_time': 0
}
def monitor_function(self, func):
"""函数监控装饰器"""
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
try:
result = func(*args, **kwargs)
self.metrics['request_count'] += 1
return result
except Exception as e:
self.metrics['error_count'] += 1
self.logger.error(f"Error in {func.__name__}: {str(e)}")
raise
finally:
duration = time.time() - start_time
self.update_response_time(duration)
return wrapper
def update_response_time(self, duration: float):
"""更新平均响应时间"""
current_avg = self.metrics['avg_response_time']
count = self.metrics['request_count']
self.metrics['avg_response_time'] = (current_avg * (count - 1) + duration) / count6. 部署建议
Docker Compose 生产配置
yaml
version: '3.8'
services:
kotaemon-app:
build: .
ports:
- "7860:7860"
environment:
- POSTGRES_URL=postgresql://user:pass@db:5432/kotaemon
- REDIS_URL=redis://redis:6379
- ELASTICSEARCH_URL=http://elasticsearch:9200
depends_on:
- db
- redis
- elasticsearch
volumes:
- ./app_data:/app/ktem_app_data
deploy:
replicas: 3
resources:
limits:
memory: 4G
cpus: '2'
db:
image: postgres:15
environment:
POSTGRES_DB: kotaemon
POSTGRES_USER: user
POSTGRES_PASSWORD: pass
volumes:
- postgres_data:/var/lib/postgresql/data
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
elasticsearch:
image: elasticsearch:8.8.0
environment:
- discovery.type=single-node
- xpack.security.enabled=false
volumes:
- elasticsearch_data:/usr/share/elasticsearch/data
volumes:
postgres_data:
redis_data:
elasticsearch_data:CI/CD 管道
yaml
# .github/workflows/deploy.yml
name: Deploy Kotaemon
on:
push:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install dependencies
run: |
pip install -r requirements.txt
pip install -r requirements-dev.txt
- name: Run tests
run: pytest tests/
deploy:
needs: test
runs-on: ubuntu-latest
steps:
- name: Deploy to production
run: |
docker-compose -f docker-compose.prod.yml up -d总结
Kotaemon 是一个技术栈丰富、架构合理的开源 RAG 项目,具有很高的实用价值和扩展潜力。通过合理的二次开发,可以构建出满足特定业务需求的智能文档问答系统。建议开发者在使用时注重性能优化、安全防护和系统监控,以确保系统的稳定性和可扩展性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)