大模型入门必看:预训练 / 监督 / 强化 / 微调,4 个关键阶段白话文一次讲明白
同时课程详细介绍了。
一、什么是大模型LLM训练和微调?
大模型 LLM 训练,简单说就是先让模型 “读万卷书”—— 用海量数据(比如全网文本)做 “预训练”,让它学懂语言规律、常识和基础逻辑,就像给模型搭好 “知识框架”。之后会通过 “监督训练” 教它按人类需求回答,再用 “强化训练” 让回答更贴合人的偏好,这一整套下来是让模型从 “有知识” 变 “会做事”。
而微调是针对训练好的大模型 “再补课”—— 用少量特定领域数据(比如医疗、法律文本)接着训,不用从头再来,就能让模型在某方面更专业,比如原本通用的模型,微调后能精准回答医学问题。
二、大语言模型训练的类型和阶段
大模型训练通常包括预训练、有监督训练、基于人类反馈的强化学习训练和微调的优化四个阶段。
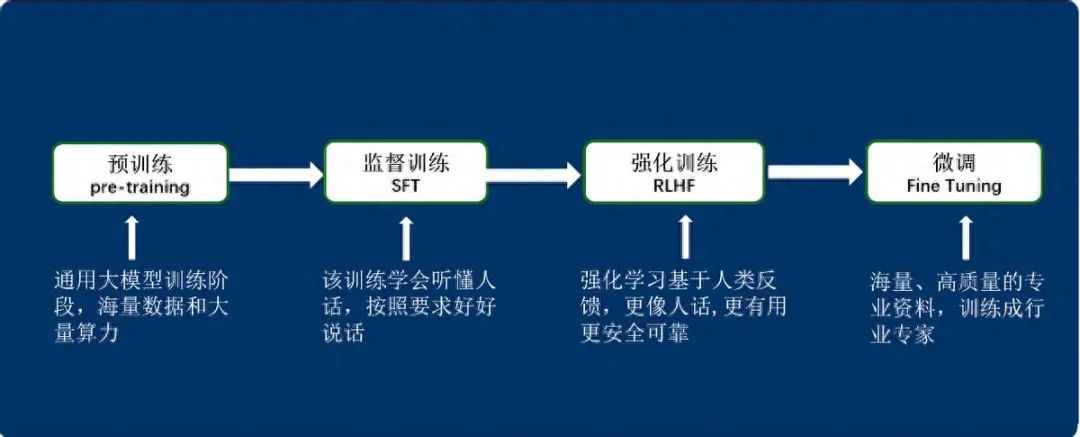
三、预训练(pre-training)阶段
利用海量数据和大量算力,通过无监督学习训练得到基座模型。模型在这个阶段学习语言的通用知识、语法规则、语义表示等,为后续学习具体任务奠定基础。此阶段耗时较长,需要极高的计算能力和庞大的数据量。
简单描述大模型预训练的目的就像教一个刚出生的“AI宝宝”认识世界一样:我们要培养一个超级聪明的“AI宝宝”,但它刚出生时是一张白纸,大字不识一个,更不懂什么是“苹果”、什么是“天气”、什么是“讲故事”。所以预训练就是给这个“AI宝宝”做“基础启蒙教育”——让它通过“狂读天下书”,先建立对世界的基本认知。
四、预训练过程
**1.**先学“认字”和“说话”(学语言规则)
- 做法:给它喂海量文本(全网文章、书籍、百科、论坛帖子……)。
- 学什么:
- 哪些字/词经常一起出现?(比如“苹果”后面常跟“吃”“甜”“手机”)
- 句子怎么组织才通顺?(比如“狗追猫”不能说成“猫追狗”除非有上下文)
- 不同词之间有什么关系?(比如“医院”和“医生”有关,“跑步”和“运动”有关)
- 效果:
它从“文盲”的“AI宝宝”变成“会说话的小学生”——能拼句子、懂基本语法,但还不会深度思考。
**2.**建立“常识库”(学世界规律)
- 做法:让它从文本中发现隐藏的规律。
- 例1:读到100万次“太阳从东边升起”→ 学会物理常识。
- 例2:读到“下雨要带伞”“雪天路滑”→ 学会生活经验。
- 例3:读到“国王戴王冠”“程序员写代码”→ 学会社会角色知识。
- 效果:
它像“逛遍图书馆的好奇少年”——知道天是蓝的、火是热的、钱能买东西,但只会复述知识,不会灵活运用。
**3.**练就“推理胚子”(学逻辑关联)
- 做法:用“填空题”逼它思考(专业叫掩码语言建模):
- 给它句子:“夏天太热,我想吃___。”
- 它通过上下文猜空白处可能是“冰棍”“西瓜”(而不是“火锅”)。
- 效果:
它学会根据线索推测信息——这是未来复杂推理(比如解数学题、写剧本)的基础能力,通过以上复杂的训练,我们的“AI宝宝“变成了天赋异禀的学生
4.预训练流程图
预训练流程
五、监督训练(SFT)
现在“AI宝宝”已经便成了一个天赋异禀的学生(基础大模型):
- 它读遍了图书馆里所有的书(预训练阶段):天文地理、历史文学、科技百科… 它掌握了海量的知识和语言规律,词汇量巨大,理解语法。
- 但它像个书呆子:
- 你问它一个问题,它可能会自顾自地背一大段相关的百科知识,而不是直接、简洁地回答你的问题。
- 你让它写一封正式的邮件,它可能写成像散文或小说。
- 你让它帮忙分析数据,它可能给你讲数据的定义和历史。
- 它不太懂怎么理解你的具体意图(指令),也不太懂怎么用**最合适的方式(对话、邮件、代码等)**来回应你。
- 它甚至可能说出一些不正确、有害或不合适的话,因为它只是在复现它读过的所有文本模式,没有判断标准。
监督微调训练的目的,就是要把这个“书呆子”训练成一个“得力的助手”:
- 学会“听懂人话”(理解指令):
- 给它看大量的例子:你输入一个问题或要求(“指令”),然后给出一个理想的、人类写的回答(“监督信号”)。
- 例子:
- 指令:“写一首关于春天的短诗。”
- 理想回答:“春风拂过绿柳梢,燕子衔泥筑新巢。花开遍野香四溢,万物复苏乐陶陶。” (而不是背一整本《唐诗三百首》)
- 通过反复看这些“问题-好答案”的配对,模型学习:哦,当人类这样问的时候,我应该这样简洁、优美、直接地回应,而不是东拉西扯。
- 学会“好好说话”(遵循格式和风格):
- 训练它用特定的方式输出:
- 当要求写邮件时,就输出邮件的格式(称呼、正文、落款)。
- 当要求写代码时,就输出语法正确、结构清晰的代码。
- 当进行对话时,就用自然、流畅、友好的语气。
- 它学会了根据任务要求切换“频道”。
- 学会“靠谱地说话”(提高准确性和可靠性):
- 在微调用的高质量数据里,答案通常是准确、无害、有帮助的。
- 模型通过模仿这些好答案,学习避免胡说八道(减少幻觉)、避免提供有害信息、尽量给出有用信息。
- 虽然不能100%保证正确,但比没微调前的“书呆子”状态要靠谱得多。
- 学会“有情商地说话”(对齐人类价值观):
- 训练数据会包含如何礼貌、尊重、安全地回应。
- 模型学习避免歧视性言论、不当玩笑,或者在敏感话题上更加谨慎,努力表现得像一个负责任、有帮助的助手。
总结来说,监督微调训练的核心目的就是:
让那个读遍万卷书但“不会来事儿”的“书呆子”模型,通过看大量“好老师”示范的“标准答案”,学会如何:
- 准确理解人类的意图(指令)。
- 用人类期望的方式(格式、风格)进行回应。
- 提供更准确、有用、可靠的信息。
- 成为一个更安全、更负责任、更像“人类好助手”的AI。
简单比喻:
- 预训练(读万卷书):让模型成为一个知识渊博的“学者”。
- 监督微调(名师指导):把这个“学者”训练成一个懂得如何清晰、有效、得体地运用知识来服务他人的“顾问”或“助手”。
所以,没有监督微调,大模型就像一个无所不知但不会沟通、可能说错话的“天才学生”;经过监督微调,它才更像一个你愿意与之对话、寻求帮助的“智能伙伴”。
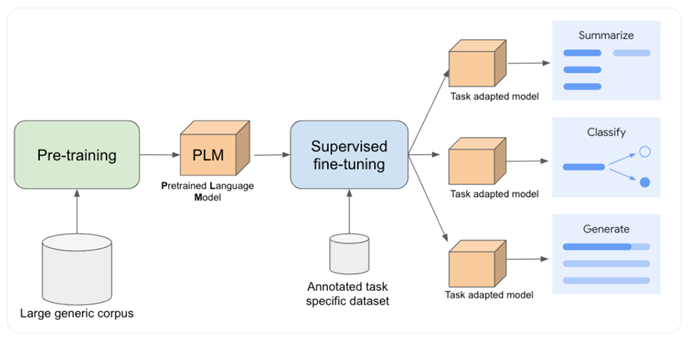
六、强化学习基于人类反馈(RLHF)
那个聪明的学生(模型)在**监督微调(SFT)**阶段已经毕业了:
- 它学会了听懂你的指令。
- 它学会了用合适的格式和风格回答(比如写诗像诗,写邮件像邮件)。
- 它输出的内容基本靠谱、无害。
但还不够!它可能还有这些“小毛病”:
- “****太啰嗦”或“太简略”:回答要么像裹脚布又臭又长,要么惜字如金没说清楚。
- “****把握不好分寸”:
- 幽默感不足,讲笑话像念说明书。
- 同理心不够,安慰人听起来冷冰冰。
- 在敏感话题上(政治、健康建议等),要么太武断,要么太模糊。
- “****会点小聪明”:
- 遇到不会的问题,**瞎编乱造(幻觉)**而不是老实说“我不知道”。
- 回答技术上正确但没用(比如问“怎么减肥?”,它答“少吃多动”,虽然对但没实际帮助)。
- “****价值观模糊”:对于什么是“好”回答,什么是“坏”回答,它缺乏更精细的判断标准。SFT只给了它“标准答案”,但没教它怎么在没有标准答案的情况下,选出人类更喜欢的那个。
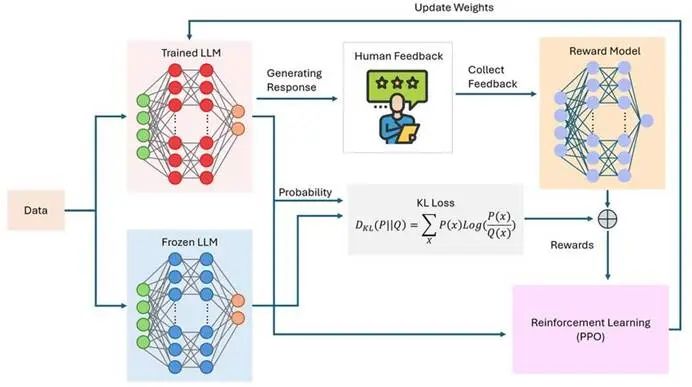
RLHF****的目的,就是当这个“好学生”进入“社会大学”后,专门训练它的“情商”、“判断力”和“沟通艺术”,让它成为一个更懂人心、更靠谱、更让人舒服的助手。 具体怎么做的呢?
分三步走(像一场特殊的“实习期”)
- “****人类教练团”打分(收集反馈):
- 让模型针对同一个问题给出几个不同的答案。
- 请真实人类(教练)来比较这些答案:哪个更好?哪个更差?哪个更符合要求?
- 例子:
- 问题: “我失恋了,很难过,怎么办?”
- 答案A(啰嗦/敷衍): “失恋是人生常见经历。时间会治愈一切。建议你多和朋友聊聊,或者专注于工作学习转移注意力。根据心理学研究…(开始长篇大论)”
- 答案B(冷漠): “下一个会更好。别难过了。”
- 答案C(有同理心/实用): “失恋真的很痛苦,抱抱你。允许自己难过几天没关系的。如果想找人聊聊,我随时在。也可以试试写日记把情绪发泄出来,或者做点你平时喜欢的事情?慢慢来,会好起来的。”
- 人类教练会说:C > A > B (C最好,A其次,B最差)。他们是在告诉模型:什么样的回答风格、语气、内容才是人类真正觉得“好”的。
- 训练“小裁判”(奖励模型):
- 把人类教练的偏好(打分结果)喂给另一个专门的AI模型(奖励模型)。
- 这个“小裁判”的任务就是:学会像人类一样,判断模型输出的好坏。给它看两个答案,它能预测人类会更喜欢哪一个。
- “****模拟考” + “自我提升”(强化学习):
- 现在,让主模型(那个学生)去“考试”:回答各种问题。
- 每次它给出一个答案,“小裁判”(奖励模型)就立刻给它打分(奖励值):这个答案在人类眼中大概能得多少分?
- 模型的目标很简单:**尽可能多拿分!**它开始不断尝试、微调自己的回答方式:
- 发现有同理心、具体有帮助的回答得分高 → 多说这种话。
- 发现啰嗦、冷漠、瞎编的回答得分低 → 避免这种话。
- 这个过程就像在玩一个游戏,目标是最大化“小裁判”给的分数。通过反复练习(强化学习算法,如PPO),模型逐渐学会了输出那些更符合人类偏好和价值观的回答。
RLHF****最终要达到的效果(目的)
- 更像“人话” (更自然流畅): 减少机械感,让对话更舒服自然(比如幽默感更到位,安慰人更走心)。
- 更“有用”: 避免正确的废话,提供真正有建设性的信息或帮助。
- 更“安全可靠”:
- 大大减少瞎编乱造(幻觉),更倾向说“我不知道”或查证。
- 在敏感话题上更谨慎、更中立、更无害。
- 更“懂你”: 能根据模糊的指令或上下文,判断出你想要什么样的回答(简洁的?详细的?幽默的?严肃的?)。
- 价值观对齐: 让模型的输出更符合特定群体(或普世)的伦理道德和社会规范。
简单比喻总结
- 监督微调(SFT): 是教学生知识、格式和基本规矩(像上课)。
- RLHF**:** 是让学生进入社会实习,在人类导师的持续反馈下,学习更微妙的沟通技巧、人情世故和价值观判断(什么该说、什么不该说、怎么说更好)。目的是培养一个不仅聪明,而且有情商、有分寸、值得信赖的助手。
所以,没有RLHF的模型,就像一个刚毕业的优秀学生,懂知识但可能不懂人情世故;经过RLHF训练后,它就成长为一个既专业又圆融的职场精英了。 这是让AI助手变得真正“好用”、“贴心”的关键一步。
七、垂直领域的大模型微调
通用大模型是一个超级聪明的全能助手
- 它什么都懂一点:能聊历史、写情书、编代码、讲笑话,知识面非常广。
- 但它是个“通才”,不是“专家”:
- 你问它专业的医疗问题,它可能根据网上看过的零碎信息,给出听起来合理但可能错误甚至危险的建议(比如乱推荐药物)。
- 你让它分析复杂的法律合同,它可能抓不住关键条款,忽略潜在风险。
- 你让它写专业的金融报告,它可能用错术语,或者分析得过于肤浅。
- 它就像个“万金油”,在专业领域不够深入、不够准确、不够靠谱。
垂直领域微调训练的目的,就是把这个“全能通才”,变成某个特定领域的“资深专家”!
怎么做到的呢?很简单:“专业特训班”
- 喂它“专业教材”和“行业秘笈”(领域专属数据):
- 不再给它看五花八门的网络信息,而是给它海量、高质量的专业资料:
- 医学领域:真实的医学教科书、权威期刊论文、病历记录(脱敏)、药品说明书、专家诊疗指南。
- 法律领域:法律法规条文、经典判例、合同范本、法律意见书、学术著作。
- 金融领域:公司财报、行业分析报告、经济模型、审计准则、金融术语词典。
- 这些资料是通用大模型在“泛读”时接触不多或不深入的核心知识库。
- 进行“专业小考”(微调训练):
- 用这些专业资料去“考”它,让它专门练习回答这个领域的问题。
- 训练方式很灵活:
- 全科回炉(全参数微调):如果资源充足,可以让它彻底深入学习一遍(成本高)。
- 专项特训(参数高效微调,如LoRA):更常用的方法,像给它一本**“特训小抄本”(一组额外的、轻量的学习笔记)。它不需要改变所有知识,只需要在原有基础上重点补充和调整这个领域的专业能力**,效率高、成本低。
- 学习“行话”和“潜规则”(领域知识内化):
- 模型会掌握该领域特有的术语、概念、流程和规则(比如医生懂的“房颤”、“PCI手术”,律师懂的“无因管理”、“善意取得”)。
- 它学会用专业人士的思维方式和表达习惯来回答问题(比如医生的严谨审慎,律师的逻辑严密,金融分析师的数据驱动)。
垂直领域微调后,你的助手变成了什么样子?
- 从“知道分子”变成“真专家”:
- 问它“心梗的急救措施”,它不再泛泛而谈“打120”,而是能清晰列出具体步骤(如服用阿司匹林、硝酸甘油)、禁忌事项、等待救护车时的注意事项,符合最新医学指南。
- 让它审阅一份“股权转让协议”,它能精准识别关键条款(如优先购买权、陈述与保证)、潜在风险点(如限制性条款),并提出专业修改建议。
- 让它分析“某公司的财报”,它能运用专业比率(如资产负债率、毛利率)、识别异常数据、给出有深度的行业洞察,而不是简单复述数字。
- 减少“瞎蒙”和“外行话”(降低幻觉,提升专业性):
- 在专业领域内,它凭空捏造(幻觉)的可能性大大降低,回答更基于事实和专业知识。
- 它不再说外行话,术语准确,逻辑符合专业规范。
- 理解“行业黑话”和“特殊语境”:
- 能听懂并正确使用该领域的缩写、俚语、特定表达方式。
- 能根据专业场景调整回答的深度和侧重点(比如对医生和对病人解释同一疾病,说法和深度不同)。
八、总结
- 通用大模型:就像一个刚毕业的聪明大学生,啥都懂点皮毛,能应付日常聊天和简单问题,但遇到专业深水区就容易露怯或出错。
- 垂直领域微调后:就像把这个大学生送进了医学院/法学院/商学院进行多年专业深造+临床/律所/投行实习。出来后就变成了一个经验丰富的专科医生/资深律师/金融分析师,在特定领域能提供真正可靠、深入、有价值的专业服务。
:
- 能听懂并正确使用该领域的缩写、俚语、特定表达方式。
- 能根据专业场景调整回答的深度和侧重点(比如对医生和对病人解释同一疾病,说法和深度不同)。
所以,垂直领域微调的核心目的就是:让那个“什么都懂一点”的通用大学生,在你关心的特定专业领域,蜕变成一个“真正懂行、靠得住”的专家级助手!它解决了通用模型在专业场景下“不够专、不够深、不够准”的核心痛点。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献117条内容
已为社区贡献117条内容

所有评论(0)