使用 FastAPI 集成 DeepSeek 和 Qwen 大模型服务
相信你现在已经知道如何使用 FastAPI 集成大语言模型服务。建议你不妨亲自动手去实践,结合自己的需求去集成自己的大语言模型服务。
今天主要给大家介绍一下如何使用 FastAPI 集成 DeepSeek 和 Qwen 大模型服务。
01 FastAPI 简介

FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 并基于标准的 Python 类型提示。
FastAPI 有如下关键特性:
- 快速:可与 NodeJS 和 Go 并肩的极高性能(归功于 Starlette 和 Pydantic)。最快的 Python web 框架之一。
- 高效编码:提高功能开发速度约 200% 至 300%。
- 更少 bug:减少约 40% 的人为(开发者)导致错误。
- 智能:极佳的编辑器支持。处处皆可自动补全,减少调试时间。
- 简单:设计的易于使用和学习,阅读文档的时间更短。
- 简短:使代码重复最小化。通过不同的参数声明实现丰富功能。bug 更少。
- 健壮:生产可用级别的代码。还有自动生成的交互式文档。
- 标准化:基于(并完全兼容)API 的相关开放标准:OpenAPI (以前被称为 Swagger) 和 JSON Schema。
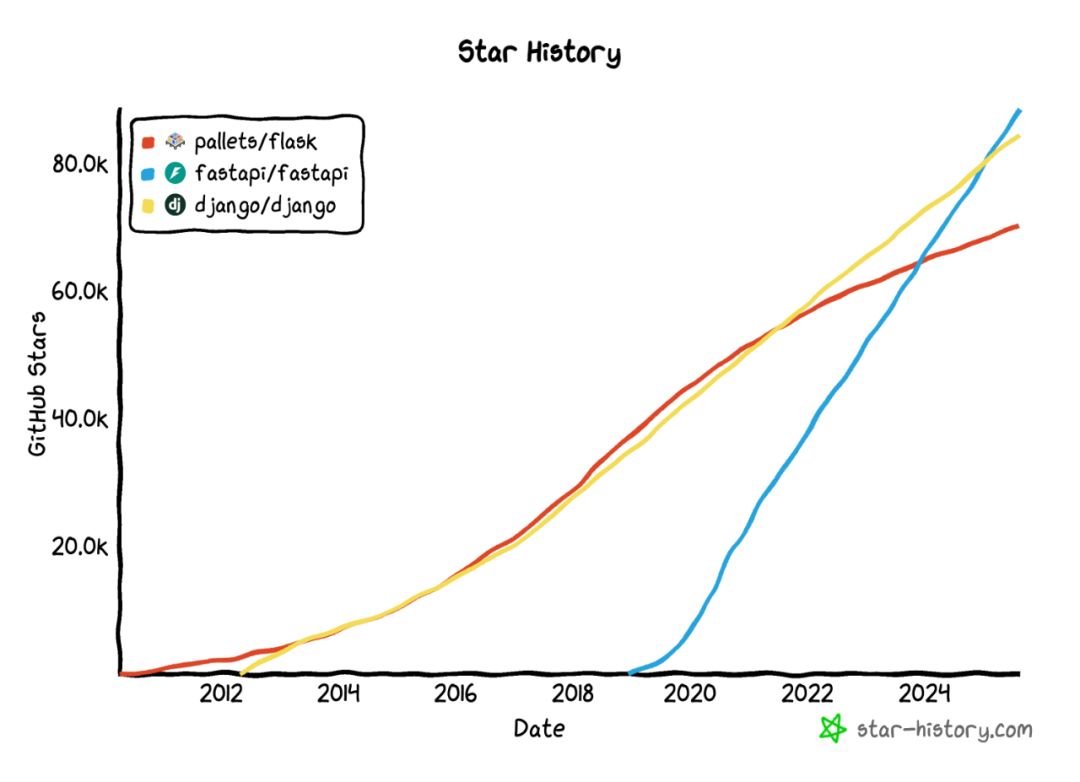
FastAPI 在 GitHub 的 Star 历史图上已超过老牌的 Python Web 框架(如:Flask、Django),而且还继续保持着良好的发展趋势。

02 使用 FastAPI 集成 DeepSeek 和 Qwen 大模型服务
在实际开发工作中,我们的服务常常会遇到需要调用不同的大语言模型服务(如:DeepSeek、Qwen),我们可以使用 FastAPI 去集成那些大语言模型服务,将其做成大语言模型的聚合服务。
为方便起见,本文对接的是官网的 DeepSeek 和 Qwen 大模型服务。
我们可以先到 DeepSeek 的开发平台去创建和获取 DeepSeek 的 API Key。
然后到阿里云百炼平台去创建和获取 Qwen 的 API Key。
依赖文件(requirements.txt):
fastapi==0.116.1
uvicorn==0.35.0
openai==1.100.1
dashscope==1.24.1
python-dotenv==1.1.1
Python 版本为 3.10 及以上。
安装依赖的 Python 库:
pip install -r requirements.txt
将 DeepSeek 和 Qwen 的相关信息配置到系统环境变量中。
# DeepSeek 配置
DEEPSEEK_API_KEY = "sk-your-deepseek-key"
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
# Qwen 配置
DASHSCOPE_API_KEY = "sk-your-qwen-key"
DASHSCOPE_API_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
主体代码(llm_app.py):
import os
import uvicorn
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from dotenv import load_dotenv
from openai import OpenAI as DeepSeekClient
from dashscope import Generation as QwenClient
# 加载环境变量
load_dotenv()
app = FastAPI()
# 配置模型参数
MODEL_CONFIG = {
"deepseek": {
"client": DeepSeekClient(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL")
),
"model_name": "deepseek-chat"
},
"qwen": {
"client": QwenClient,
"model_name": "qwen-plus"
}
}
# 统一请求格式(兼容OpenAI)
classChatRequest(BaseModel):
model: str # deepseek 或 qwen
messages: list
temperature: float = 0.7
max_tokens: int = 1024
# 统一响应格式
classChatResponse(BaseModel):
model: str
content: str
@app.post("/v1/chat")
asyncdefchat_completion(request: ChatRequest):
model_type = request.model.lower()
if model_type notin MODEL_CONFIG:
raise HTTPException(400, f"Unsupported model: {model_type}")
try:
if model_type == "deepseek":
response = MODEL_CONFIG["deepseek"]["client"].chat.completions.create(
model=MODEL_CONFIG["deepseek"]["model_name"],
messages=request.messages,
temperature=request.temperature,
max_tokens=request.max_tokens
)
content = response.choices[0].message.content
elif model_type == "qwen":
response = QwenClient.call(
model=MODEL_CONFIG["qwen"]["model_name"],
messages=request.messages,
temperature=request.temperature,
max_tokens=request.max_tokens,
result_format='message'
)
content = response.output.choices[0].message.content
return ChatResponse(model=model_type, content=content)
except Exception as e:
raise HTTPException(500, f"API Error: {str(e)}")
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8090)
启动应用:
uvicorn llm_app:app --host 0.0.0.0 --port 8090 --workers 4

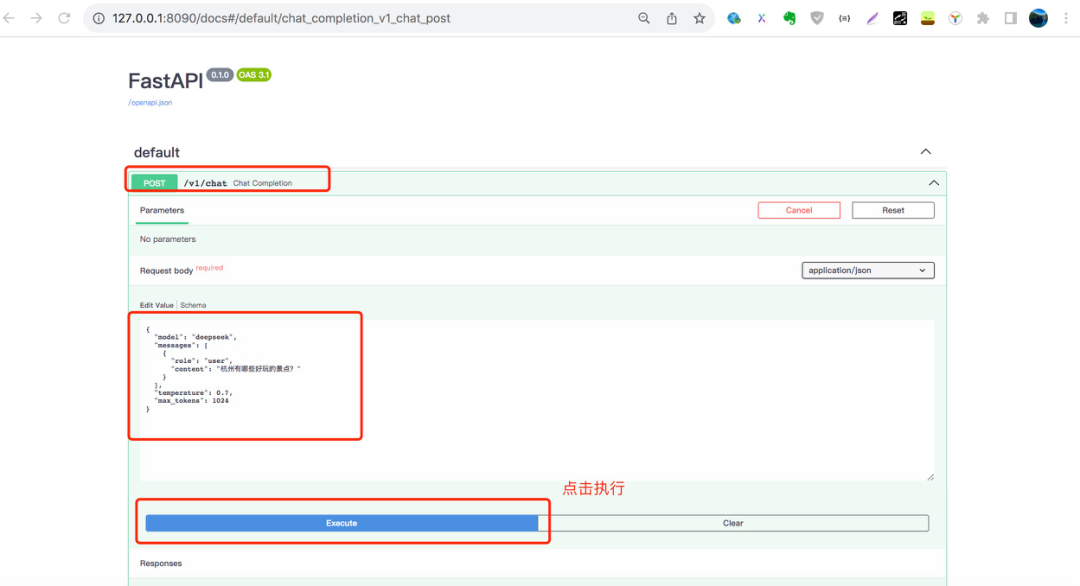
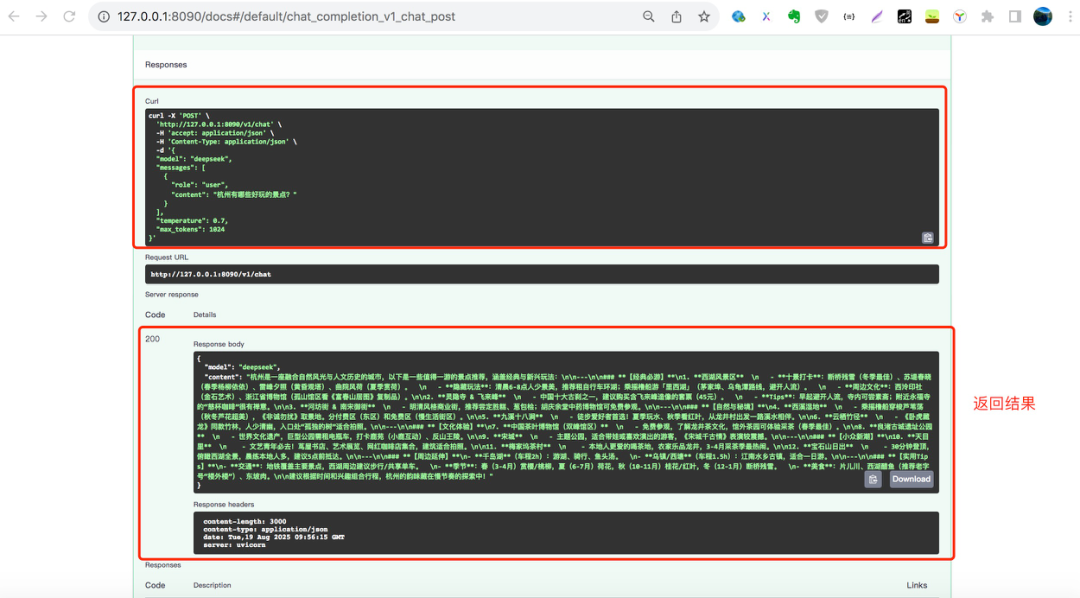
03 使用聚合服务
通过 API 接口调用聚合服务:
结语
相信你现在已经知道如何使用 FastAPI 集成大语言模型服务。建议你不妨亲自动手去实践,结合自己的需求去集成自己的大语言模型服务。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献290条内容
已为社区贡献290条内容

所有评论(0)