手把手教你用 FastAPI + LangGraph搭建 AI 工作流
Large Language Models (LLMs) 擅长推理,但现实世界的应用往往需要有状态、多步骤的工作流。这就是 LangGraph 的用武之地——它让你可以通过由 LLM 驱动的节点图来构建智能工作流。
Large Language Models (LLMs) 擅长推理,但现实世界的应用往往需要有状态、多步骤的工作流。这就是 LangGraph 的用武之地——它让你可以通过由 LLM 驱动的节点图来构建智能工作流。
但如果你想把这些工作流暴露为 APIs,让其他应用(或用户)可以调用呢?这时候 FastAPI 就派上用场了——一个轻量级、高性能的 Python Web 框架。
在这篇指南中,你将学习如何将 LangGraph 工作流封装在 FastAPI 中,变成一个生产就绪的 endpoint。
为什么选择 LangGraph + FastAPI?
- • LangGraph:创建多步骤、有状态的 LLM 工作流(例如,多智能体推理、数据处理)。
- • FastAPI:轻松将这些工作流暴露为 REST APIs,以便与 Web 应用、微服务或自动化流水线集成。
- • 结合两者:构建可从任何地方访问的可扩展 AI 智能体。
1. 项目设置
创建一个新项目文件夹并安装依赖:
mkdir langgraph_fastapi_demo && cd langgraph_fastapi_demo
python -m venv .venv
source .venv/bin/activate # 在 Windows 上:.venv\Scripts\activate
pip install fastapi uvicorn langgraph langchain-openai python-dotenv
创建一个 .env 文件来存储你的 API 密钥:
OPENAI_API_KEY=你的_openai_密钥_在此
2. 构建一个简单的 LangGraph 工作流
让我们构建一个简单的 LangGraph,它接收用户的问题并返回 AI 生成的答案。
# workflow.py
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(model="gpt-4o") # 可以切换到 gpt-4o-mini 以降低成本
# 定义状态
defanswer_question(state: dict) -> dict:
user_input = state["user_input"]
response = llm.invoke([HumanMessage(content=user_input)])
return {"answer": response.content}
# 构建图
workflow = StateGraph(dict)
workflow.add_node("answer", answer_question)
workflow.add_edge(START, "answer")
workflow.add_edge("answer", END)
graph = workflow.compile()
这个图:
- • 接收 user_input
- • 将其发送到 GPT-4o
- • 返回 AI 生成的响应
3. 让它生产就绪
在向全世界开放之前,让我们为真实用例加固它。
错误处理与重试
LLM APIs 可能会失败或超时。用 try/except 包装调用:
from tenacity import retry, wait_exponential, stop_after_attempt
@retry(wait=wait_exponential(multiplier=1, min=2, max=10), stop=stop_after_attempt(3))
defsafe_invoke_llm(message):
return llm.invoke([HumanMessage(content=message)])
defanswer_question(state: dict) -> dict:
user_input = state["user_input"]
try:
response = safe_invoke_llm(user_input)
return {"answer": response.content}
except Exception as e:
return {"answer": f"错误:{str(e)}"}
输入验证
我们不想让别人发送巨大的数据负载。添加 Pydantic 约束:
from pydantic import BaseModel, constr
classRequestData(BaseModel):
user_input: constr(min_length=1, max_length=500) # 限制输入大小
日志记录
添加日志以提高可见性:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
defanswer_question(state: dict) -> dict:
logger.info(f"收到输入:{state['user_input']}")
response = safe_invoke_llm(state['user_input'])
logger.info("已生成 LLM 响应")
return {"answer": response.content}
4. 使用 FastAPI 暴露工作流
现在,让我们将这个工作流封装在 FastAPI 中。
# main.py
from fastapi import FastAPI
from workflow import graph, RequestData
app = FastAPI()
@app.post("/run")
asyncdefrun_workflow(data: RequestData):
result = graph.invoke({"user_input": data.user_input})
return {"result": result["answer"]}
运行服务器:
uvicorn main:app --reload
5. 测试 API
你可以使用 curl 测试:
curl -X POST "http://127.0.0.1:8000/run" \
-H "Content-Type: application/json" \
-d '{"user_input":"什么是 LangGraph?"}'
或者在浏览器中打开 http://127.0.0.1:8000/docs —— FastAPI 会自动为你生成 Swagger UI!
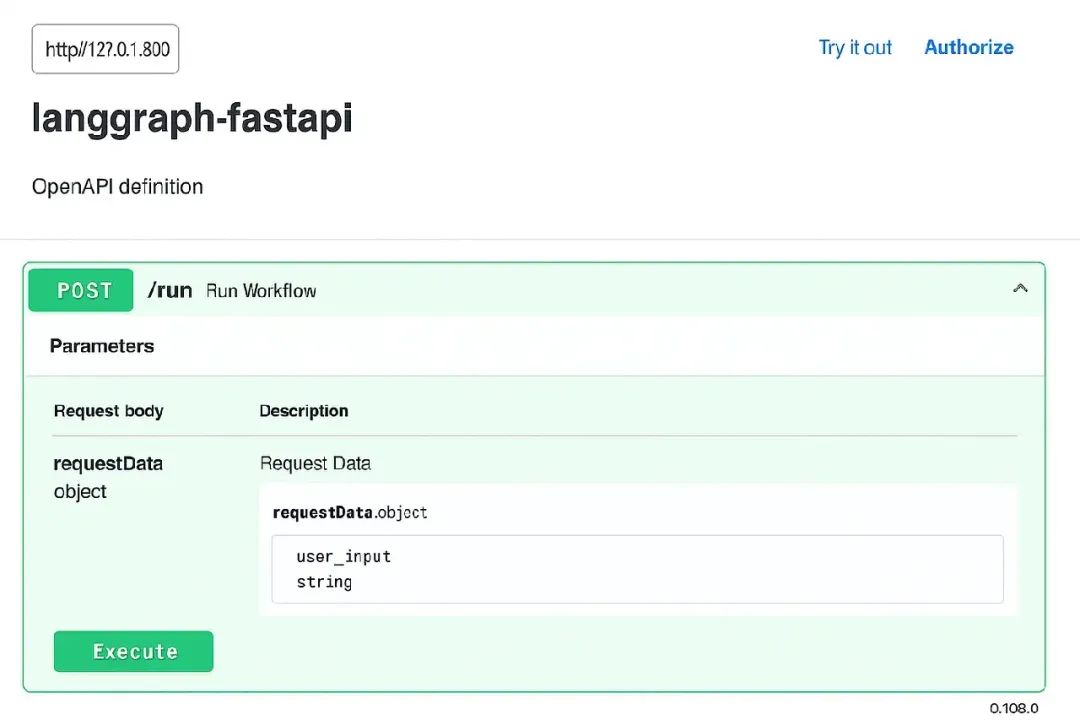
这个交互式 UI 让你直接在浏览器中测试你的 endpoint。
6. 扩展与部署
为生产环境做准备的几个步骤:
-
• 异步执行:FastAPI 是异步原生的。对于多个 LLM 调用,让函数变成异步的。
-
• 工作进程:使用多进程运行以实现并发:
uvicorn main:app --workers 4 -
• Docker 化:
FROM python:3.11-slim WORKDIR /app COPY . . RUN pip install -r requirements.txt CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"] -
• 认证:使用 API 密钥或 JWT tokens 来保护 endpoints(第二部分即将推出)。
7. 架构概览
以下是整体连接方式:
POST /run
Client
FastAPI
LangGraph
OpenAI_API
Response
这个简单的架构让你可以将任何 LangGraph 变成一个 API。
- 结论
通过几个简单的步骤,我们:
- • 构建了一个 LangGraph 工作流
- • 使用 FastAPI 将其暴露为 REST API
- • 添加了生产就绪的功能(验证、重试、日志)
- • 为可扩展的 AI 微服务奠定了基础
这个设置可以支持从聊天机器人到文档处理器再到 AI SaaS 产品的各种应用。
下一步是什么?
我计划推出本教程的第二部分,但我想听听你的意见。
👉 你希望我接下来讲哪一个?
- • 流式响应(实时聊天)
- • 认证与安全性
- • Docker 与云部署
- • 错误监控与可观察性
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献267条内容
已为社区贡献267条内容

所有评论(0)