苹果刚刚停止了对人工智能的炒作。以下是他们令人震惊的研究结果
我们耳闻 OpenAI 的 o1 o3 o4 模型、Anthropic 的“思考型”克劳德模型,以及谷歌的双子前沿系统,所有这些都在推动我们更接近通用人工智能(AGI)的圣杯。如果一个人工智能甚至无法遵循一个简单的、基于规则的任务的明确指令,那么它就不能进行任何人类意义上的“推理”。相反,他们在受控环境中对这些所谓的“大型推理模型”(LRM)进行了测试,而他们的发现彻底推翻了之前的所有说法。只需增
新的研究表明,如今的“推理”模型根本就不是在思考。它们只是复杂的模式匹配器,一旦遇到困难就会彻底崩溃。
我们正生活在一个人工智能被疯狂炒作的时代。每周都会有新的模型发布,声称其“推理”、“思考”和“规划”能力会比上一个模型更好。我们耳闻 OpenAI 的 o1 o3 o4 模型、Anthropic 的“思考型”克劳德模型,以及谷歌的双子前沿系统,所有这些都在推动我们更接近通用人工智能(AGI)的圣杯。故事的脉络很清晰:人工智能正在学习思考。
但如果这一切只是幻觉呢?
如果这些价值数十亿美元的模型被誉为认知进化的下一步,但实际上只是运行更高级的自动完成功能呢?
这是苹果公司一个研究团队发布的一项低调而系统性研究得出的惊人结论。他们没有依赖炒作或炫目的演示。相反,他们在受控环境中对这些所谓的“大型推理模型”(LRM)进行了测试,而他们的发现彻底推翻了之前的所有说法。
在本文中,我将为您详细解读他们的发现,但不会使用那些晦涩难懂的学术术语。因为他们的发现并非仅仅是一个渐进式的发现……而是对整个人工智能行业的一次根本性现实检验。
我们为何被人工智能“推理”所愚弄
首先,你必须问:我们如何测试人工智能是否能够“推理”?
通常,公司会提到一些基准测试,例如复杂的数学问题(MATH-500)或编程挑战。诚然,像 Claude 3.7 和 DeepSeek-R1 这样的模型在这些方面正在不断进步。但苹果的研究人员指出了这种方法的一个巨大缺陷:数据污染。
简单来说,这些模型已经在互联网上进行了大量的训练。它们很可能在训练过程中已经见过这些著名问题的答案,或者至少是类似的版本。
试想一下:如果你给一个学生一份数学试卷,但他们已经记住了答案,那么他们是天才吗?还是仅仅擅长记忆?
这就是为什么研究人员放弃了标准基准,转而建立了一个更为严格的试验场。
人工智能试验场:谜题,而非问题
为了真正测试推理,你需要完成一项任务:
- 可控:您可以使其稍微困难一些或更容易一些。
- 未受污染:该模型几乎肯定从未见过精确的解决方案。
- 逻辑性:遵循清晰、牢不可破的规则。
因此,研究人员转向了经典的逻辑谜题:汉诺塔、积木世界、过河和跳棋。
这些谜题堪称完美。你无法“捏造”答案。你要么遵守规则并解开谜题,要么就不解。只需增加“汉诺塔”中的圆盘数量,或“积木世界”中的积木数量,他们就能精准地提升游戏复杂度,并观察人工智能的反应。
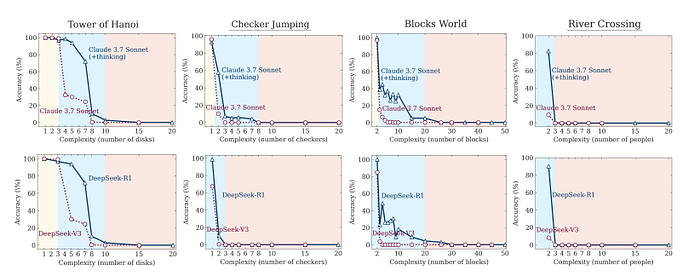
这就是思维幻觉开始崩塌的地方。
令人震惊的发现:人工智能遭遇困境
当他们进行测试时,一个清晰而令人不安的模式浮现出来。这些高级推理模型的性能不仅随着问题变得越来越难而下降,而且跌到了谷底。
研究人员确定了三种不同的表现机制:
- 低复杂度任务:这是第一个惊喜。在简单的谜题上,标准模型(例如常规的 Claude 3.7 Sonnet)实际上比“思考型”模型表现更好。它们速度更快、更准确,并且消耗的计算资源更少。额外的“思考”只是低效的开销。
- 中等复杂度任务:这是推理模型最终展现优势的最佳阶段。额外的“思考”时间和思维链式处理能力帮助它们解决了标准模型无法解决的问题。这是人工智能公司热衷于展示的领域。这看起来是真正的进步。
- 高复杂度任务:这就是问题所在。超过一定的复杂度阈值后,两种模型都会彻底崩溃。准确率骤降为零。不是 10%,也不是 5%,而是零。
这并非优雅的退化,而是根本性的失败。能够解决7盘汉诺塔难题的模型,完全无法解决10盘汉诺塔难题,即使底层逻辑完全相同。仅凭这一发现,就足以推翻这些模型已经发展出可泛化推理能力的说法。
更奇怪的是:当事情变得艰难时,人工智能就会放弃
这就是这项研究真正奇怪之处。你可能会认为,当问题变得更难时,“思考”模型会……嗯,思考得更深入。它会使用更多分配给它的处理能力和代币预算来完成更复杂的步骤。
但苹果研究人员的发现却恰恰相反。
当谜题的复杂程度达到模型无法解决的程度时,模型开始在“思考”过程中使用更少的标记。
让这一点深入人心。
面对更艰巨的挑战,人工智能的推理能力反而下降了。这就像一位马拉松运动员,在20英里处看到一座陡峭的山坡后,决定放慢速度,而不是继续往下挖,即使他还有充足的体力。这是一种违反直觉且极不合逻辑的行为,表明模型“知道”自己力不从心,于是干脆放弃了。
这揭示了一个根本性的扩展限制。这些模型的失败不仅仅是因为问题太难;它们的内部机制在面对真正的复杂性时会主动脱离。
人工智能“思维”内部:思考过度与思考不足的故事
研究人员并没有止步于测量最终的准确率。他们进行了更深入的研究,逐步分析了模型的“思维”过程,以了解它们失败的原因。
他们发现这是一个效率极低的故事。
- 对于简单的问题,模型会“过度思考”。它们通常会在思考过程的早期就找到正确的解决方案。但它们不会停下来给出答案,而是会继续探索几十条错误的路径,浪费大量的计算资源。这就像你找到了钥匙,然后又花了20分钟搜索房子的其他地方,“以防万一”。
- 对于难题,模型“思考不足”。这是崩溃的另一面。当问题复杂度很高时,模型无法找到任何正确的中间解。它们的思维过程从一开始就只是一堆失败的尝试,甚至从未走上正轨。
对简单任务过度思考,而对困难任务思考不足,都暴露出一个核心弱点:模型缺乏强大的自我修正能力和高效的搜索策略。它们要么原地踏步,要么彻底迷失方向。
压垮骆驼的最后一根稻草:“小抄”测试
如果对于这些模型是否真正具有推理能力仍有任何疑问,研究人员设计了最后一个具有决定性意义的实验。
他们选取了汉诺塔谜题:一个使用众所周知的递归算法的任务,并直接将答案交给了人工智能。他们为模型提供了一个完美的、逐步的伪代码算法来解答这个谜题。模型的唯一任务就是执行指令。它无需设计策略,只需遵循配方即可。
结果如何?
这些模型在完全相同的复杂程度下仍然失败。
这是整篇论文中最重要的发现。它证明了人工智能的局限性不在于解决问题或高级规划,而在于模型无法始终如一地遵循一系列逻辑步骤。如果一个人工智能甚至无法遵循一个简单的、基于规则的任务的明确指令,那么它就不能进行任何人类意义上的“推理”。
这只是匹配模式而已。当模式太长或太复杂时,整个系统就会崩溃。
那么,我们实际上见证了什么?
苹果的这项名为“思考的幻觉”的研究迫使我们面对一个令人不安的事实。我们在当今最先进的人工智能模型中看到的“推理”并非通用智能的萌芽形式。
它是一种极其复杂的模式匹配形式,先进到可以模拟人类推理输出,解决特定问题。但当以受控方式进行测试时,它的脆弱性就暴露无遗。它缺乏真正智能所依赖的稳健、可泛化和符号化的逻辑。
苹果研究的结论显而易见:我们并没有见证人工智能推理的诞生。我们看到的是昂贵的自动完成功能的局限性,它在关键时刻失效了。
AGI时间线不仅进行了现实检验,还可能被彻底重置。
所以,下次你听到一个能“推理”的新人工智能时,不妨问问自己:它能解决一个从未见过的简单难题吗?还是它只是在表演历史上最昂贵、最令人信服的魔术?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)