大模型一本正经地胡说八道?你该试试学RAG了!
这时候你可能需要把一些特有的信息给到大模型,可以让大模型打造一个自己的知识库,比如访问公司内部数据,信息,你就可以定制化用途,让他的回答更加专业,而不再泛泛而谈,这就是RAG的用途。
你是不是经常遇到大模型在回答问题时“自信满满却答非所问”?有时候它提供的内容看起来头头是道,实则漏洞百出,严重影响用户体验。
这时候你可能需要把一些特有的信息给到大模型,可以让大模型打造一个自己的知识库,比如访问公司内部数据,信息,你就可以定制化用途,让他的回答更加专业,而不再泛泛而谈,这就是RAG的用途。
什么是RAG?
RAG,全称Retrieval Augmented Generation,是一项可以让大模型检索并合并新信息的技术。
它的核心思想是:无需重新训练模型,只需引入最新的信息来增强模型的知识来源。换句话说,RAG 是一种将 LLM 与“搜索引擎”能力结合起来的方法,让模型在生成回答时能查资料,而不是单靠记忆。这种方式可以减少幻觉(hallucination)。
例如,大家还记得当 Google 首次演示其 LLM 工具“Google Bard”时,LLM提供了有关詹姆斯韦伯太空望远镜的错误信息。这个错误导致谷歌的股票价值蒸发了1000 亿美元。
RAG还可以动态更新知识内容,比如现有的deepseek的模型的数据还是两三年前的,很多时候回答问题所引用的数据还是旧的,可以使用RAG为其更新专门的新数据。
但RAG也是有缺陷的。
-
它无法解决所有问题。
如果 LLM 误解了上下文,即使从事实正确的来源中提取,它们也会产生错误信息。例如,《麻省理工科技评论》给出了一个AI生成的响应示例,称“美国有一位穆斯林总统,巴拉克·侯赛因·奥巴马。该模型从一本学术著作中检索到这一点,书名是《巴拉克·侯赛因·奥巴马:美国第一位穆斯林总统?LLM没有 “知道 ”或 “理解 ”标题的上下文,产生了一个虚假的陈述。
-
提高系统的复杂性和延迟。
这个很好理解,因为我们增加了新的组件,并且还需要查询数据库,会增加系统的响应时间。
-
带来安全隐患
用户可能会在prompt里加入有害指令,会让大模型回答些不安全的回答。
现有的RAG产品
市面上现有的RAG产品有很多,比如微软的M365 Copilot,它主要是拥有了公司内部办公软件里的各种信息,比如帮你总结会议,总结邮件,teams里的信息总结有哪些任务需要跟进。
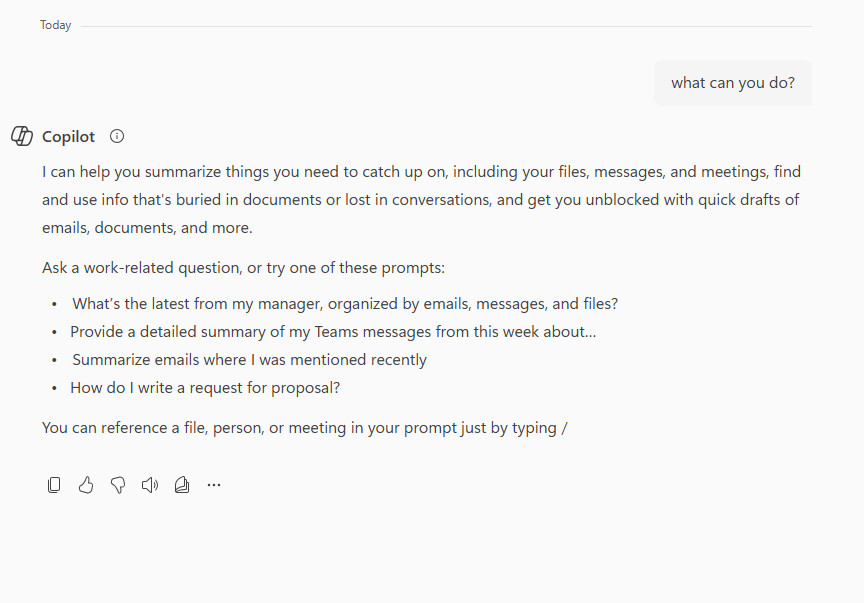
还比如现在的deepseek,chatgpt,豆包等,都提供了类似联网搜索的功能。这些就是用RAG实现的。
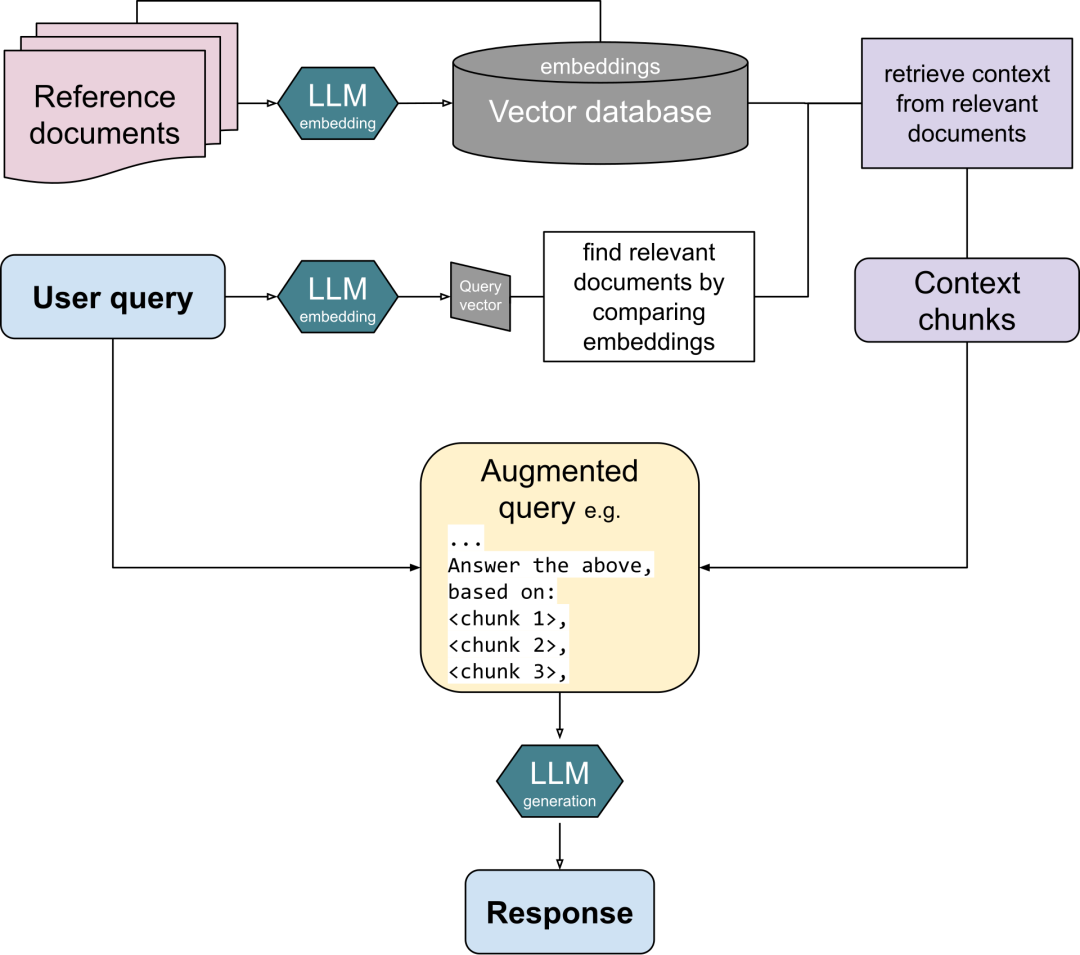
RAG的架构
RAG有几个关键的流程。
-
索引(indexing)
这一步主要是建立索引,把要引用的数据,比如非结构化(文本),半结构化(表)或者结构化的数据(比如知识图谱,数据库), 转换为LLM的embedding, 即向量空间的数据,存入矢量数据库中,便于进行文档搜索。
-
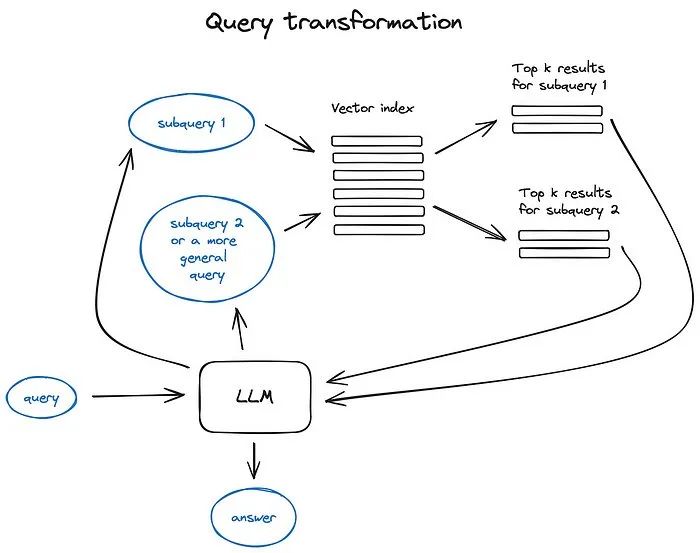
检索(retrieval)
这一步就是检索,用户给定一个query,调用检索其来获取相关的文档。
-
生成(generation)
LLM可以根据查询和检索到的文档生成输出。一些模型包含额外的步骤来提高输出,例如对检索到的信息进行重新排序、上下文选择和微调。
RAG的框架和工具
构建RAG有一些可以使用的框架:
-
LangChain,这个我在上一篇文章如何使用大模型构建强大的应用?介绍了,这个框架提供了丰富的模块,你可以使用它快速地实现一些验证或者demo,比较容易上手。支持多步骤推理、工具调用、上下文记忆等复杂应用逻辑。
-
GraphRAG,是微软做的一款RAG框架:这个更倾向于结构化结构化的、分层的检索增强生成(RAG)方法,相较于使用纯文本片段的朴素语义搜索方法,更具系统性和层次性,但不专注于应用编排。
(https://microsoft.github.io/graphrag/#the-graphrag-process)

An LLM-generated knowledge graph built using GPT-4 Turbo.
-
LlamaIndex,这个是构建基于大语言模型(LLM)智能体的领先框架,内置多种索引结构(向量、树、列表、关键词),支持快速构建高效的文档检索系统,适合大规模文档处理。能够结合你的数据、LLM 和工作流,实现智能体的高效构建与运行。以查询引擎为主,逻辑控制能力较弱,适合快速构建单一任务型应用。
🧭 框架定位对比
|
框架 |
核心定位 |
适用场景 |
|---|---|---|
| LlamaIndex |
数据连接层工具,专注于高效索引与检索 |
构建文档问答系统、知识库、RAG原型 |
| LangChain |
应用编排框架,支持复杂逻辑与多工具集成 |
多轮对话、智能代理、自动化流程 |
| GraphRAG |
图结构增强的RAG系统,强调语义连接与推理 |
深层语义检索、跨文档推理、企业级知识图谱 |
总结
RAG可以帮助大模型获取外部知识库来改进大语言模型,可以减少使用新数据重新训练LLM的需要,节约成本,提高效率。
虽然RAG提高了大型语言模型 (LLM) 的准确性,不过,RAG 也不是万能钥匙,构建时需要在效果、速度、安全性之间权衡。随着技术演进,我们有理由相信未来 RAG 将成为大模型落地的“标配”。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献308条内容
已为社区贡献308条内容

所有评论(0)