【Datawhale AI 夏令营】2025多模态RAG方向 - Task3 调整方案,进阶上分
本文记录了参与AI夏令营多模态RAG方向的学习过程。项目目标是构建基于图文混排PDF的可溯源问答系统,主要挑战包括多模态信息融合、精准检索和细粒度信息抽取。针对baseline存在的文档解析粗糙、分块策略单一等问题,提出了多维度优化方案:1)改用MinerU解析工具提取结构化内容;2)优化分块策略并引入重排机制;3)对Embedding模型和LLM进行领域微调;4)实施全量测试数据运行。文章还探讨
本系列是参与DataWhale和科大讯飞合办的 AI夏令营【多模态RAG方向】的记录贴。根据夏令营课程安排,共分4个章节进行内容与我的学习笔记记录。 感谢DataWhale和科大讯飞~
序言:学习者手册 —— 了解项目
Task1:跑通Baseline,体验「让AI读懂财报PDF」
Task2:学习「让AI读懂财报PDF」的重难点
Task3:学习并实践更多进阶要点和思路

在经历过任务一的无脑跟练,跟任务二的理解任务与代码逻辑后,任务三对本小白来说难度飙升。。。
课程建议个人多尝试各种路径,奈何本人大模型技术和python调试水平不足,因此本章仅记录课程提供的思路。。。
一、任务回顾
任务目标
构建一个基于给定图文混排PDF多文件知识库的、可溯源的多模态问答系统。==>系统需要“读懂”这些图文混排的PDF,并能准确回答相关问题,同时必须明确指出答案来自哪个文件的哪一页。
评估标准
- 答案内容相似度 (0.5分)
- 文件名匹配准确率 (0.25分)
- 页码匹配准确率 (0.25分)
数据集
- train.json为训练集 , 提供“问题-答案-来源”的训练格式样板
- test.json为测试集,其中每个提问的page、filename和answer需要选手预测
- 财报数据库.zip为 给定的知识库,包含多个图文混排pdf文件
挑战与难点
多模态信息融合 :如何让系统理解文本与图表之间的关联。
检索的信噪比 :如何在海量信息中精准召回最相关的上下文,避免无关信息干扰。
生成的可控性 :如何让大模型忠实于原文作答,并准确溯源,而不是自由发挥。
细粒度信息抽取 :答案可能隐藏在某个表格的单元格或图表的特定部分,对文档解析的精度要求很高。
二、提升要点
2.1 BaseLine不足分析
baseline提供了一个逻辑清晰,简单易懂的rag流程示范框架。 各模块独立,方便升级替换。
1). 文档解析粗糙
这是最核心的短板。Baseline 使用的 PyMuPDF 只能提取纯文本,完全 丢失了表格、图片 等关键的多模态信息,同时也破坏了原有的版面布局。财报中的大量核心数据都在图表中,这一损失是致命的。
2). 分块策略单一
按“页”分块过于粗暴。一个完整的表格或逻辑段落可能被硬生生切开,破坏了信息的上下文完整性。
3). 检索精度有限
仅靠基础的向量相似度检索,对于包含特定术语或需要精确匹配的问题效果不佳,且容易引入噪音。
4). 模型泛用性
无论是 Embedding 模型还是 LLM,都是通用预训练模型,并没有针对“金融财报”这个垂直领域进行优化,理解上会存在偏差。
2.2 提升策略
1). 升级数据解析核心
放弃 PyMuPDF, 切换到 MinerU 。利用 MinerU 强大的版面分析能力,提取出包含表格(转为Markdown)、图片、以及带有层级结构(标题、段落)的文本内容。这是提升分数上限关键的一步。
2). 优化分块与索引策略
有了 MinerU 精细化的解析结果,我们可以进行对图片进行进一步的内容解释,添加图片的描述信息。
3). 引入重排(Re-ranking)
在检索(Retrieve)环节后增加一个 重排步骤,选出最相关的几个结果,提高给到大语言模型的上下文质量。
- 先用向量检索召回一个较粗泛的候选集(如Top 20)
- 再用一个更精准的重排模型对这20个候选项进行打分排序
- 选取真正的TopK(如Top 3-5)喂给LLM,大幅提升信噪比。
4). 实施模型微调
让模型更适应财报问答的场景。
微调Embedding模型 :利用 train.json 中的问答对构造训练数据,让模型学习财报领域的语义关系,提升检索召回的准确率。
微调LLM :利用 train.json 构造“指令-上下文-回答”格式的数据,对LLM进行指令微调。主要目的是让LLM更“听话”,能更忠实地根据我们提供的上下文作答,并严格按照要求的格式输出答案和来源。
5). 运行全量测试数据
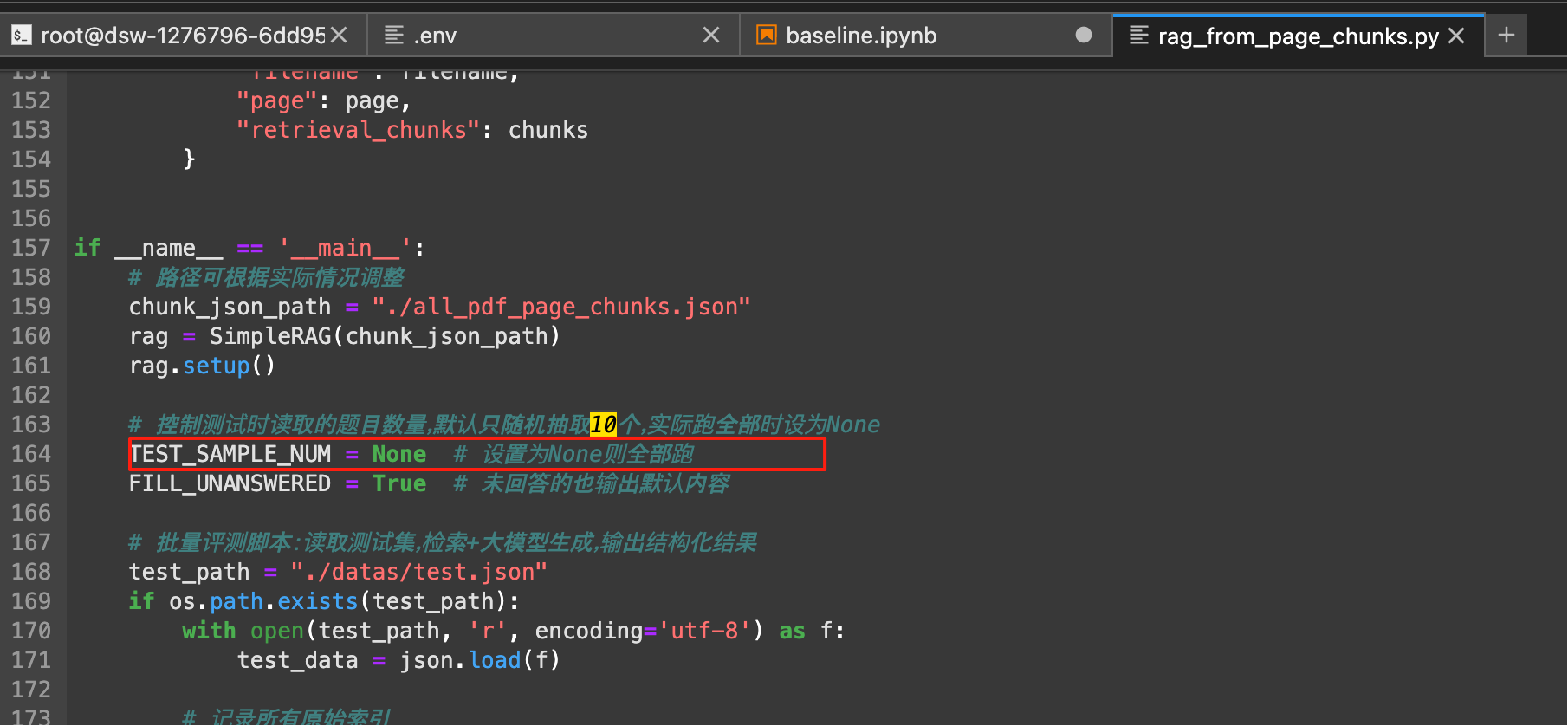
baseline里面的代码默认只运行了10条测试数据,只需要修改一个变量就能在baseline的基础上得到较大的分数提升。
修改rag_from_page_chunks.py文件里面的变量TEST_SAMPLE_NUM,将原来的10改成None,运行全量的测试数据会消耗比较久的时间,大概会消耗20分钟左右。
三、要点说明
升级后的项目流程图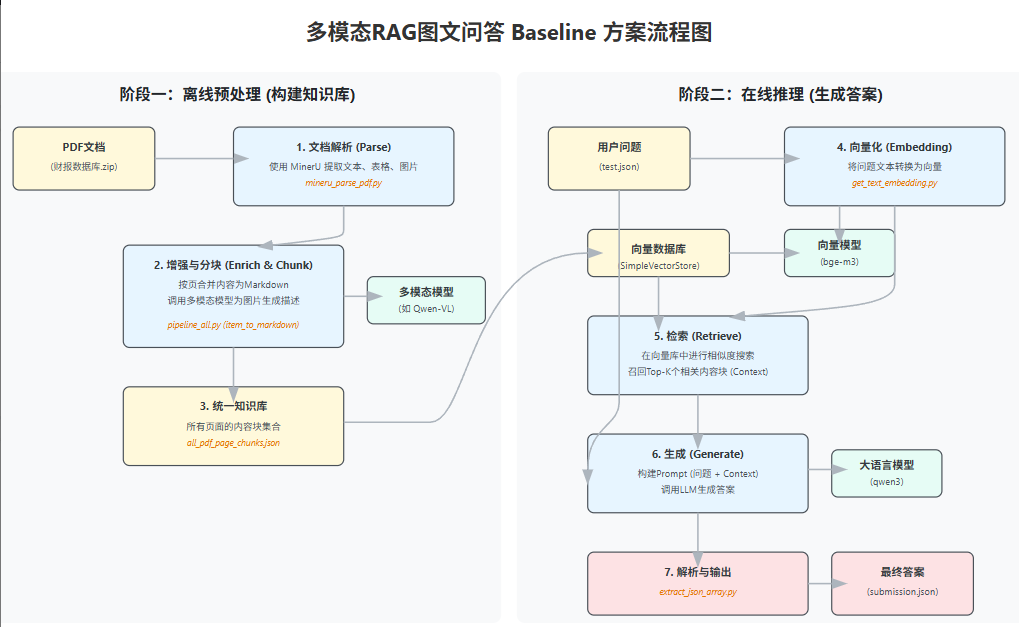
3.1 解析pdf文档的多模态内容 - Mineru+多模态
Mineru: 功能强大的文档解析工具,能将PDF精准地转换为结构化的Markdown或JSON。基于深度学习模型通过把PDF内的页面看成是图片进行各种检测,识别的方式提取。
在本项目中,升级数据解析方案,即把解析文件fitz_pipeline_all.py, 改为使用mineru_pipeline_all.py
- 实测: 使用MinerU会相当耗时,建议在GPU环境中进行。
-(阿里云的NoteBook提供了一个GPU环境的免费使用时长,在task1中提到的位置,选择右侧的GPU环境打开即可, 项目信息都是共用的)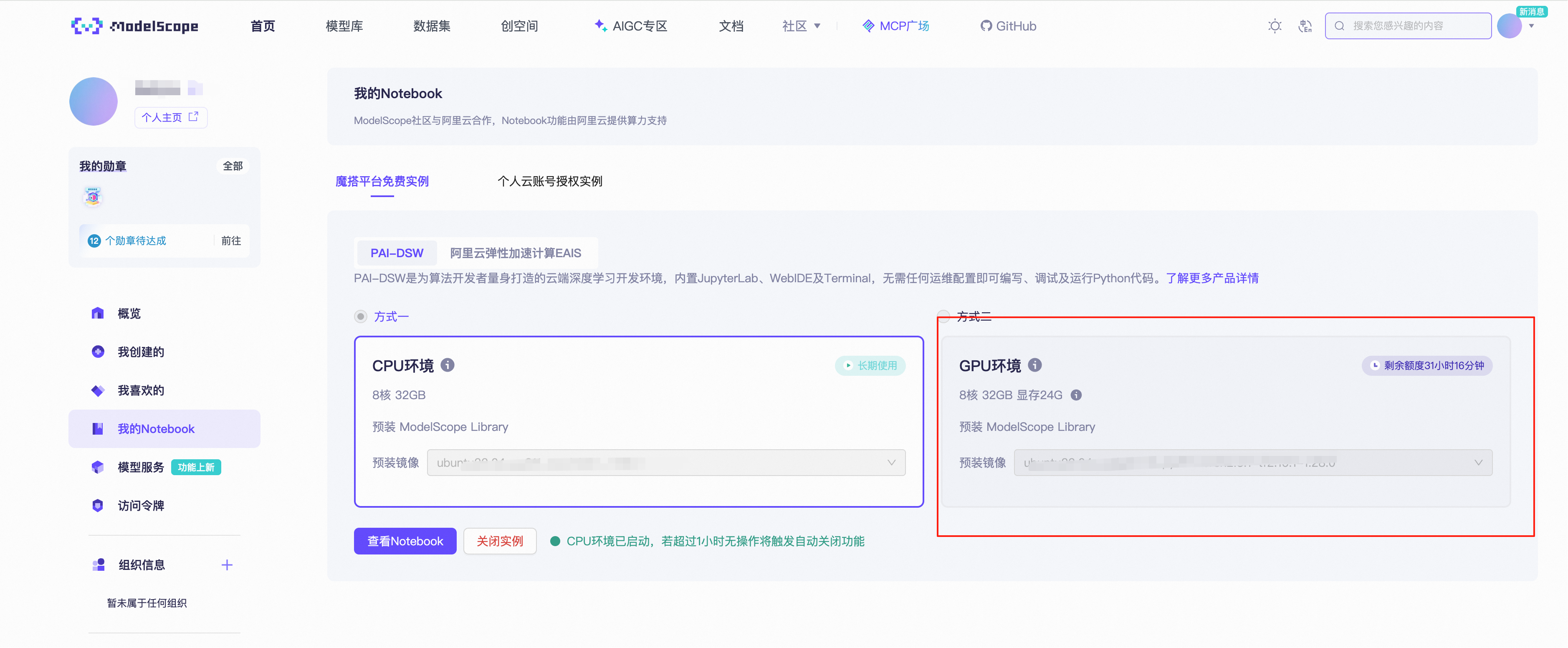
mineru_pipeline_all.py文件说明
-
- 解析PDF (parse_all_pdfs)
-
- 将结果整理为Markdown形式(process_all_pdfs_to_page_json)
-
- 汇总内容生成知识库文件 (process_page_content_to_chunks)
3.2 分块与索引策略优化: 召回+重排
“召回”
用向量检索或者关键词检索(比如BM25算法),快速地找到一个比较大的候选范围,目的是把相关的都找出来。
“重排”
用一个更精准的重排模型,比如 FlagEmbedding 仓库里的 BGE-ReRanker 模型,来给这些候选项和问题的相关性打分,然后选出分数最高的几个。
Re-ranking ,重排。它是在RAG检索流程中,初步召回一批候选内容后,用一个更精准的模型对这些内容与问题的相关性重新排序的步骤。
Hybrid Search,混合检索 。它通常指结合了关键词检索(如BM25)和向量检索两种方式的检索策略,能同时利用两种方法的优点。
Vision-Language Model (VLM) ,视觉语言模型, 也就是我们说的多模态大模型。它能同时处理图像和文本信息。
Knowledge Graph ,知识图谱。它是一种用图的结构来表示知识和实体间关系的方法。
3.3 模型微调: 数据准备+模型训练
1). 准备高质量的训练数据
- 目标:将官方的train.json,转换为模型能理解的格式指令-输入-输出
- 代码:
spark_data_process.ipynb - 核心逻辑:将每个问答对(Q&A pair)包装成一个结构化的字典。
输入与输出 : input 字段对应原始问题,output 字段对应标准答案。模型在训练时会学习到,在收到这样的 instruction 和 input 后,应该生成类似 output 的回答。
最终产物 :执行该脚本后,我们会得到 qa_train.json 文件,这是下一步模型训练的直接输入。
2). 模型训练
进行模型的有监督微调(Supervised Fine-Tuning, SFT)
- 代码:
spark_model_finetune.ipynb
逻辑:
-
- 环境配置与模型加载
-
- 添加LoRA适配器
-
- 加载并格式化数据
-
- 配置并启动训练
-
- 推理验证与模型保存
产物: lora_model 文件夹包含了微调后的模型权重,可以在RAG的生成环节加载它。
3.4. 其他方案
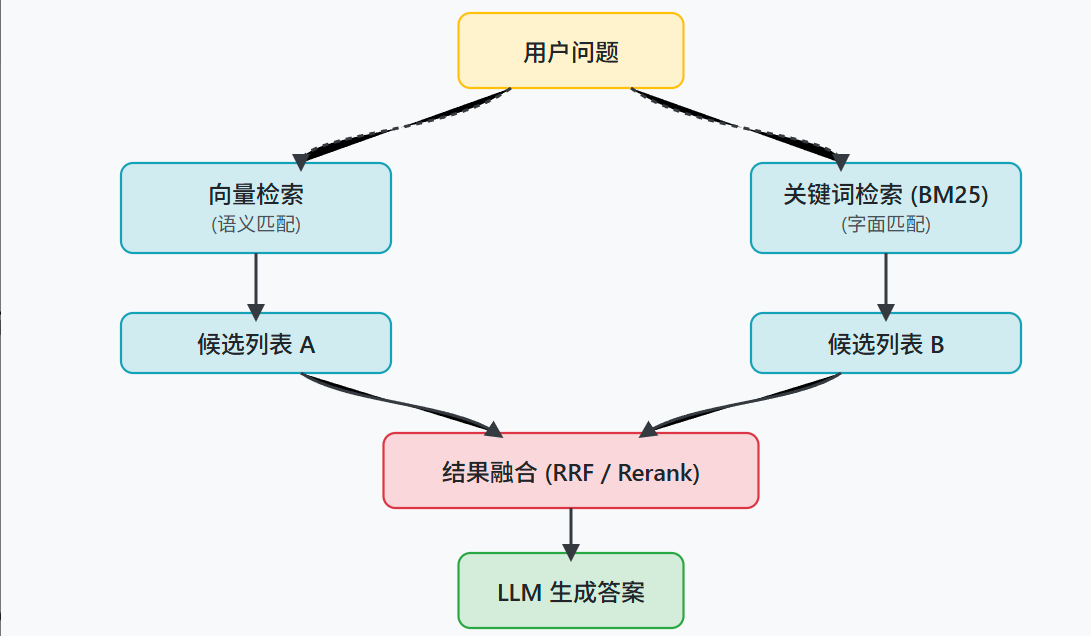
1) 多路召回与融合
核心: 同时使用多种不同的检索方式,从不同角度去寻找相关的知识块,然后再把找到的结果合并起来。
举例
-
并行运行两种检索,一种是基于关键词的检索,像 BM25 算法,它擅长匹配问题中出现的具体词语;另一种是基于向量的语义检索,使用 embedding 模型来查找意思相近但用词可能不同的内容。这样,两条通路可以形成优势互补。
-
从不同通路拿到各自的召回结果列表后,把它们融合成一个更高质量的排序。
两种思路:- **重排模型(Re-ranker):**把所有通路召回的结果汇总到一起,然后用一个重排模型,比如基于 FlagEmbedding 的模型,来对这个大集合进行统一的、更精细的相关性打分,最后选出分数最高的几个结果。
- 融合算法(无需训练模型的): 如倒数排名融合(Reciprocal Rank Fusion, RRF)。根据每个文档在不同召回列表中的排名位置,来计算出一个综合分数,然后根据这个综合分数生成一个新的排序。
2)知识图谱
当前方案里知识库里的知识库是各自独立的,但其实在原文章他们相互关联。
构建知识图谱:一份文档表示成一个知识图谱,里面的节点可以是段落、表格、图表、公司名等实体,边则表示它们之间的关系,比如“位于”、“描述”或者“属于”。
这样,在回答一些需要多步推理的问题时,就可以通过图谱的查询来找到答案。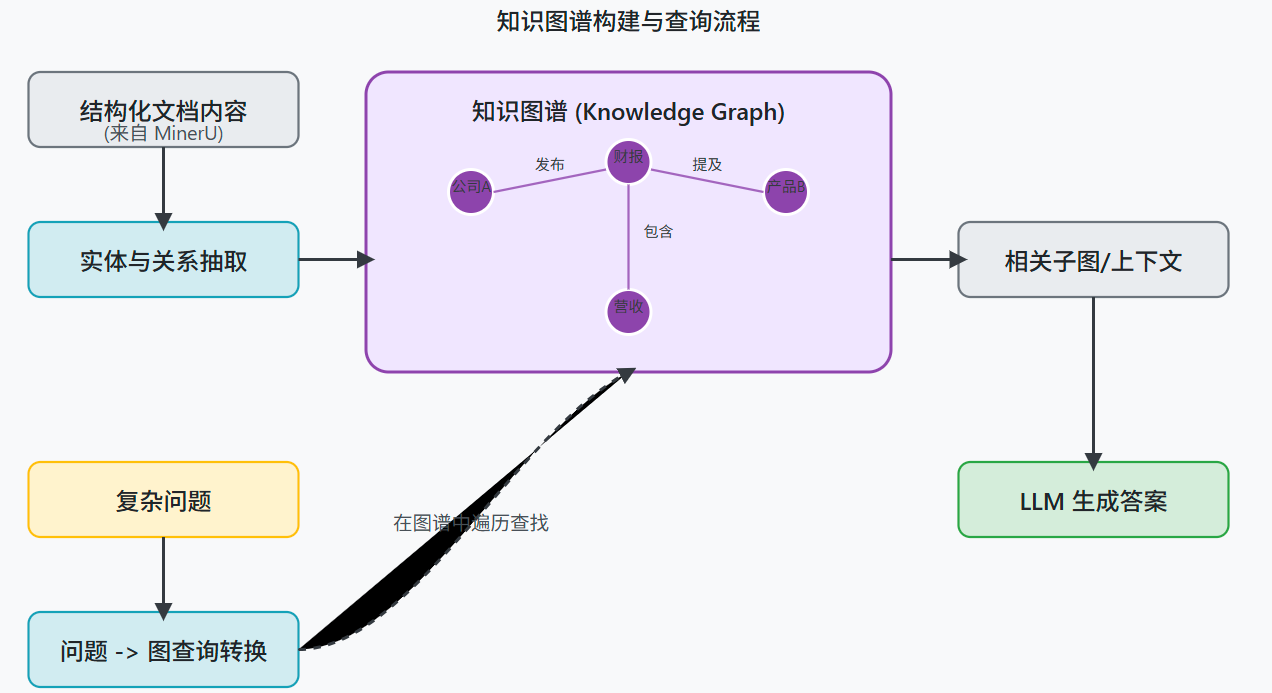
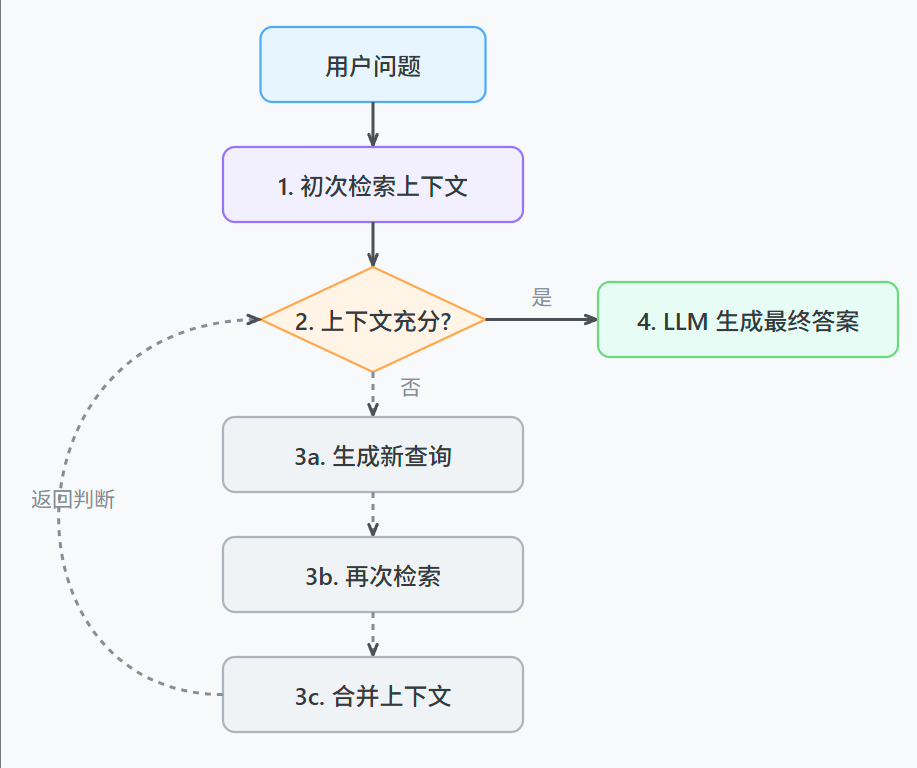
3) RAG自我修正
让RAG系统拥有自我修正的能力:
具体来说,就是让系统在检索一次之后,能自己判断一下找到的上下文够不够回答问题。
如果不够,它可以自己生成一个新的、更具体的查询语句,再次进行检索,把两次的结果合在一起再生成答案。
参考资料
为什么你的RAG效果总差一点?从RankNet到Qwen,一文读懂Rerank模型的演进
RAG系统召回率低? BGE-M3 多语言多功能重塑文本检索:
https://mp.weixin.qq.com/s/1PURiKFP1WBx6VnScszm3A
多模态RAG的三类图文问答实现方式,你知道多少种?:
https://mp.weixin.qq.com/s/FXyjbalyDB21RFOVW1O_RA
搭建RAG系统时,可能会遇到的7个具体问题:
https://arxiv.org/html/2401.05856v1
一种带有“自我修正”能力的RAG方法:
https://arxiv.org/abs/2401.15884
LlamaIndex :一个专门用来构建RAG应用的框架:
https://docs.llamaindex.ai/en/stable/
Hugging Face 官方提供的模型训练指南:
https://huggingface.co/docs/transformers/training
Unsloth 是一个高效训练模型的框架:
https://docs.unsloth.ai/
LangGraph是用来构建有状态、多步骤应用的程序库:
https://github.com/langchain-ai/langgraph
MinerU是功能强大的文档解析工具,能将PDF精准地转换为结构化的Markdown或JSON:
https://mineru.net/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)