HarvardX TinyML小笔记1(Fundamentals of TinyML)
只记录了我觉得重要的点。。。
1 整体介绍
课程地址:Course | edX
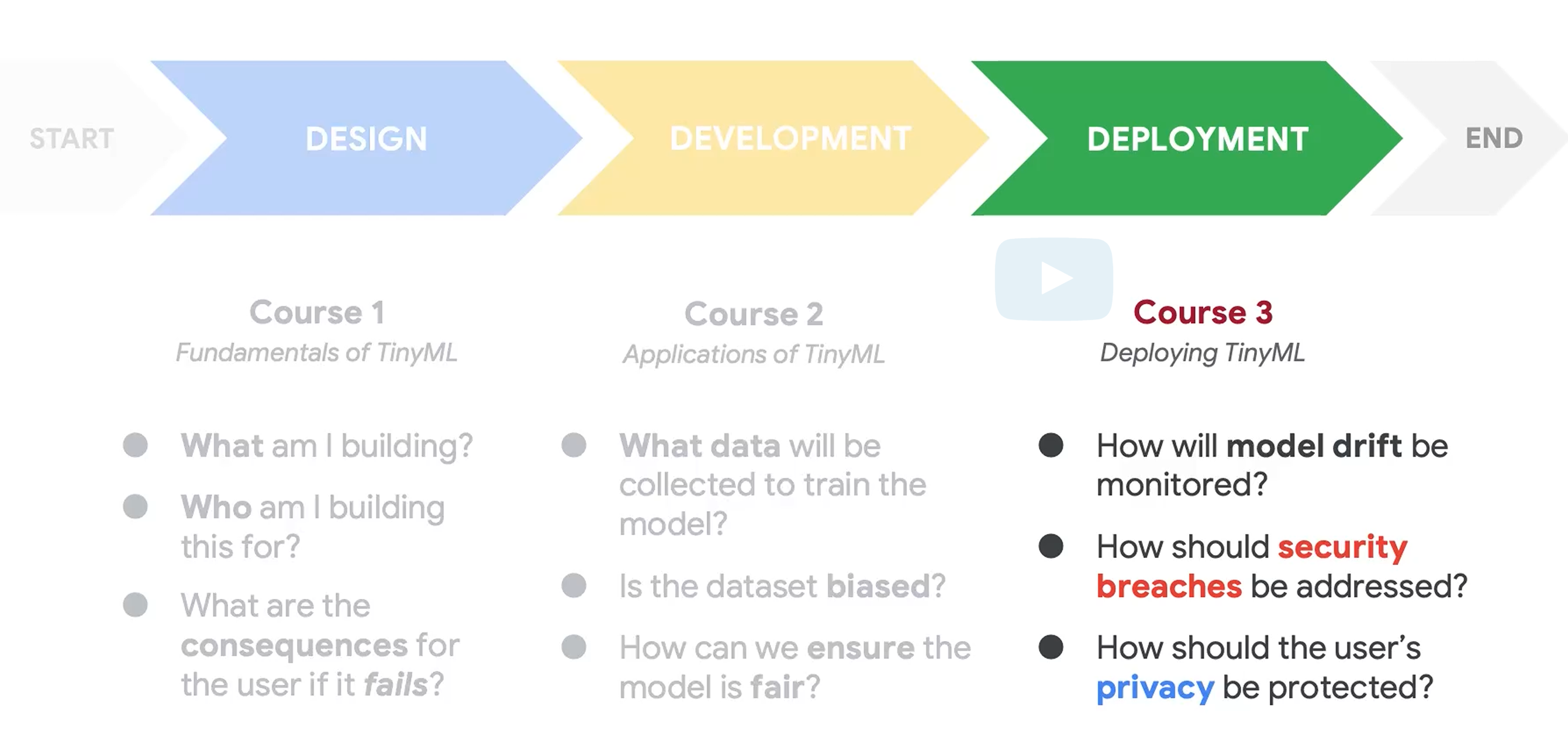
整个tinyML课程分为三个部分,Fundamentals of TinyML,Applications of TinyML,Deploying of TinyML。
Fundamentals of TinyML:主要介绍了TinyML的基础,和传统ML的区别,面临的问题,以及大篇幅介绍了AI道德。。。
Applications of TinyML:(TODO)
Deploying of TinyML:(TODO)
2 Part1
这部分都是基础内容,一些基本的介绍。 不涉及编程,整体也不需要多少技术背景。
TinyML的定义:
需要的软硬件环境:
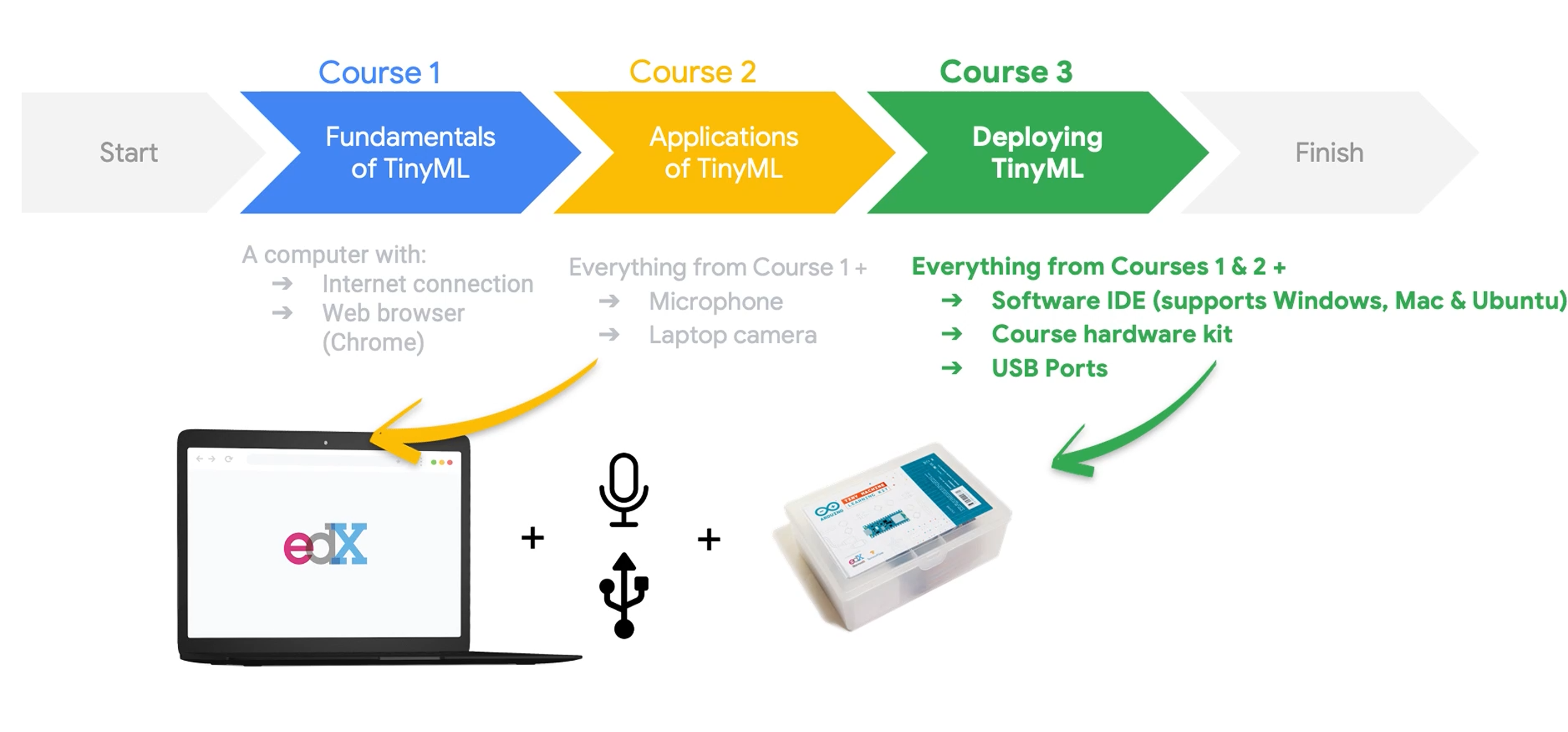
软件平台指定的是Google 的Colab,据说用这个的话可以蹭Google的TPU。
Colab教程:https://colab.research.google.com/notebooks/intro.ipynb
硬件是 Arduino 33 BLE Sense。不过这个要等到第三部分才用。

教程用的Nano 33 BLE Sense。查了一下,Nano 33 BLE Sense目前没有祖国版,价格300多,小贵。想看看能不能用ESP32或者Pico平替。。。
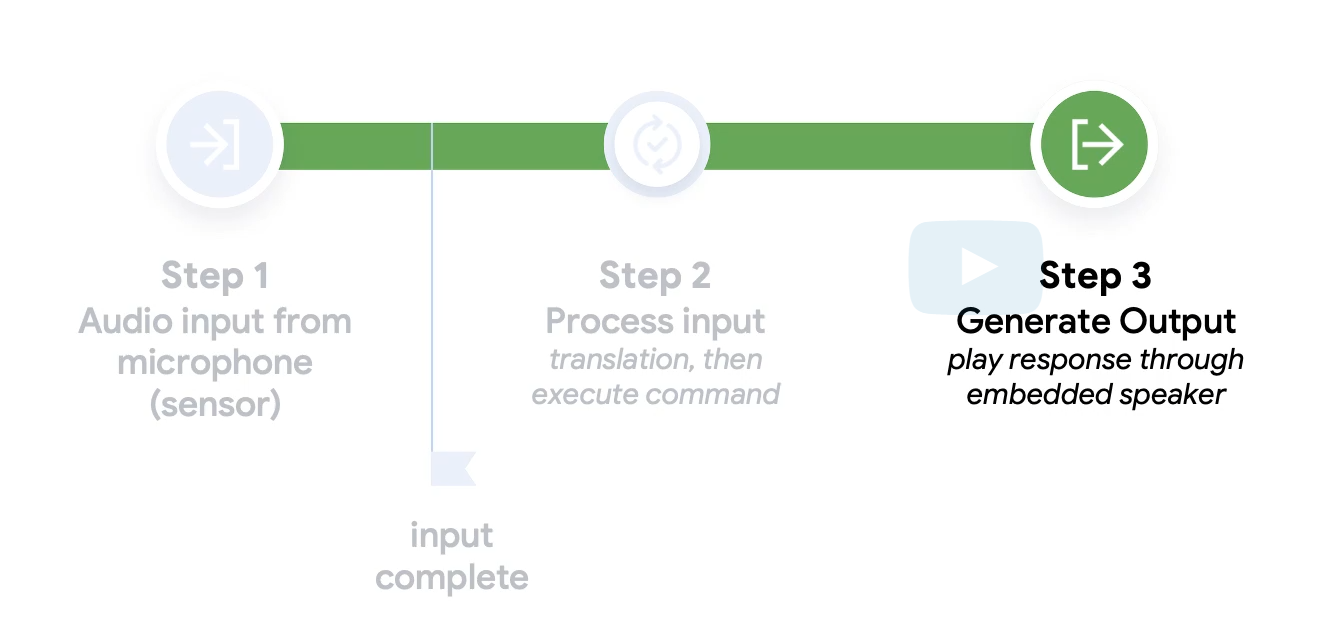
TinyML的整体流程,分为输入,输入处理,生成输出三个部分。
TinyML从芯片层面和传统ML的面临问题的区别。

在Test里面还吹了一下TinyML才是将来。。。

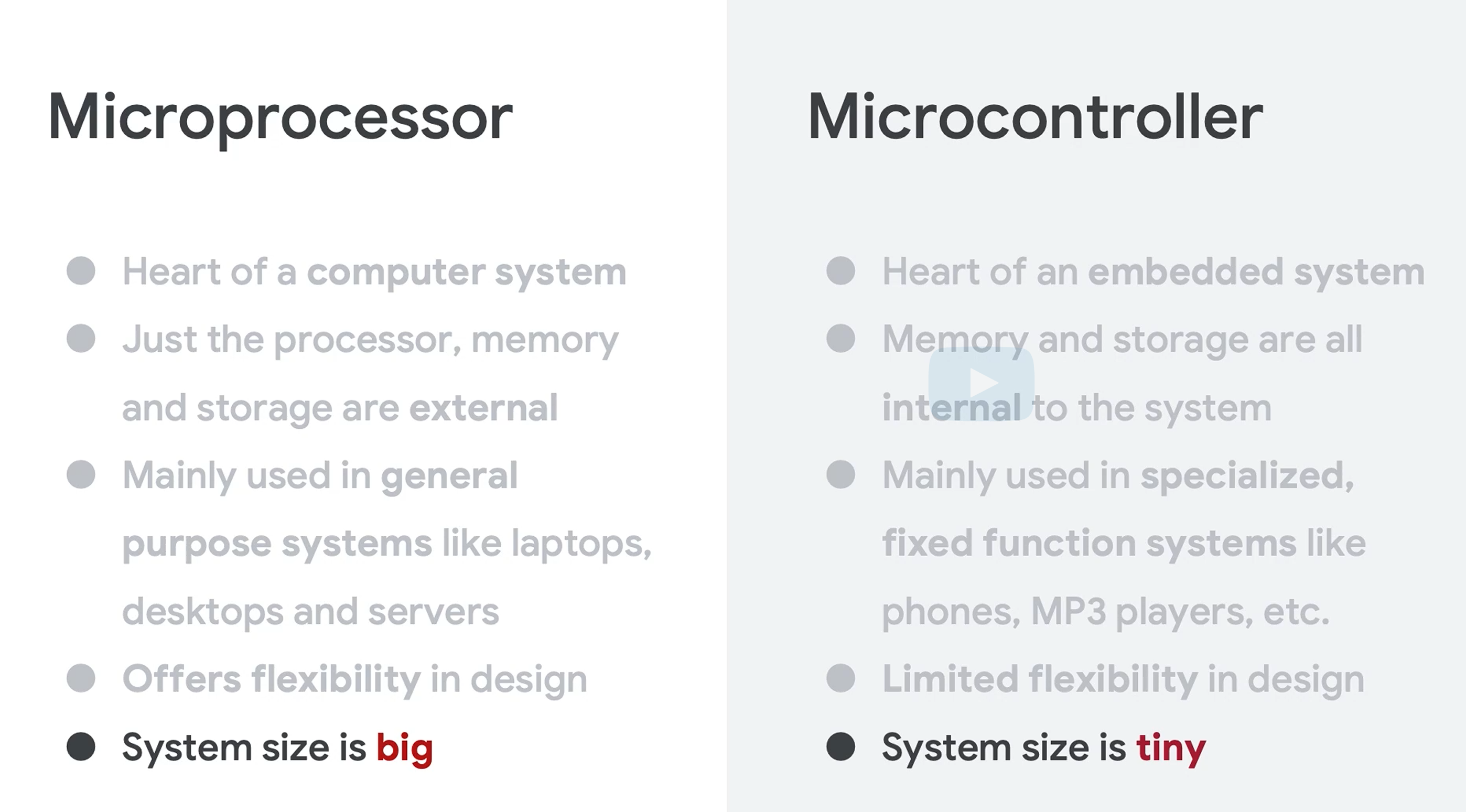
说了一下Microprocessor和Microcontroller。Microprocessor基本就是传统的CPU,需要外围的内存,硬盘,GPU等。Microcontroller就是MCU,一堆东西都集成到芯片了。
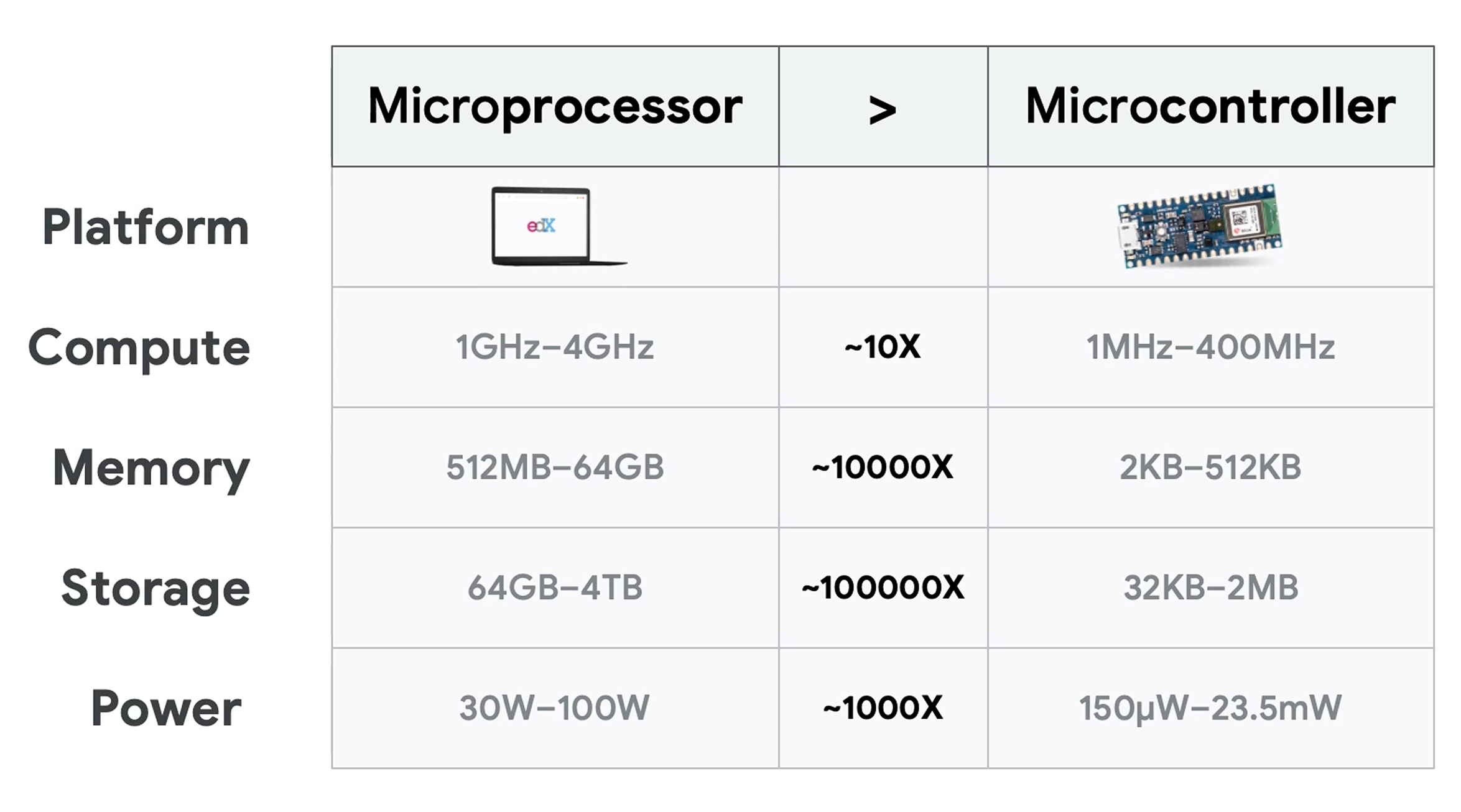
软件方面比较了嵌入式在各个层级(OS,库,应用)的问题。OS如果用RTOS等精简OS,库的方面嵌入式尤其是tiny这块缺乏很多常用库。
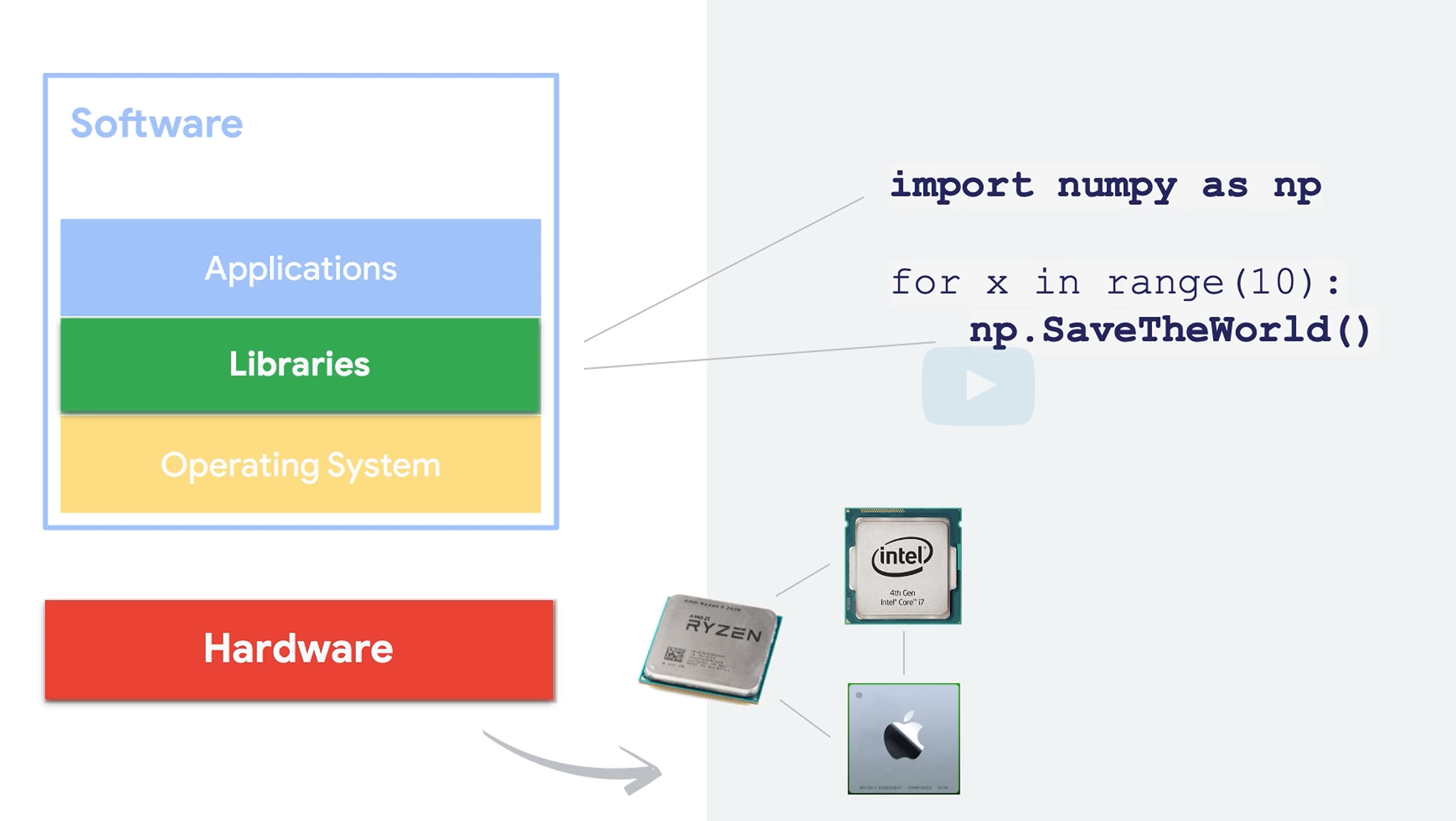
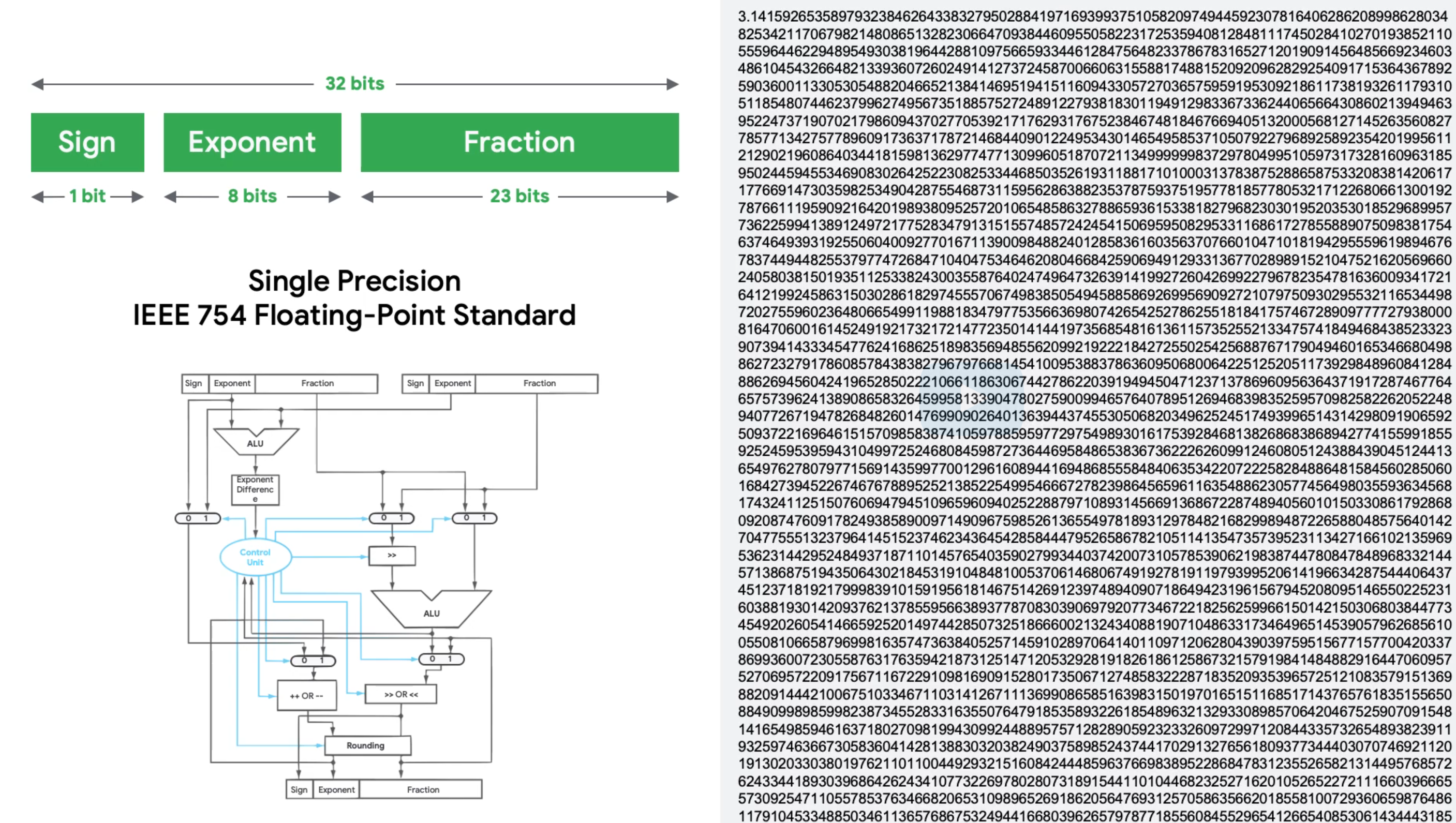
此外,在嵌入式中,很多芯片也没有FPU,会导致浮点运算性能很差。而ML是需要非常多浮点运算的。这一点怎么解决就非常重要了。
此外,程序的体积以及需要的运行内存也受到很大限制。

模型的压缩技术。剪枝,量化,知识蒸馏。。。这些才是这个的核心技术,当然,这些内容可能过于高深,而且实际国内搞这块能出成果也非常非常难。老老实实能用好别人的算法,部署调试好,也够在国内拿高薪了。。。

ML整体是训练training和推理inference两个部分,但是在TinyML上,重点只有推理。训练放上云。这里用的软件是Google的TensorFlow Lite。当然,其它家还有很多方案,不过目前TensorFlow Lite因为系出名门,用的最广。不过也不排除这个课程本身就是Google的推广软文,因为几乎全套都是Google方案。

TensorFlow从训练到部署到终端的步骤。之前基于ESP32写过一篇,可以参考:ESP32部署TensorFlow Lite_esp32 tensorflow-CSDN博客
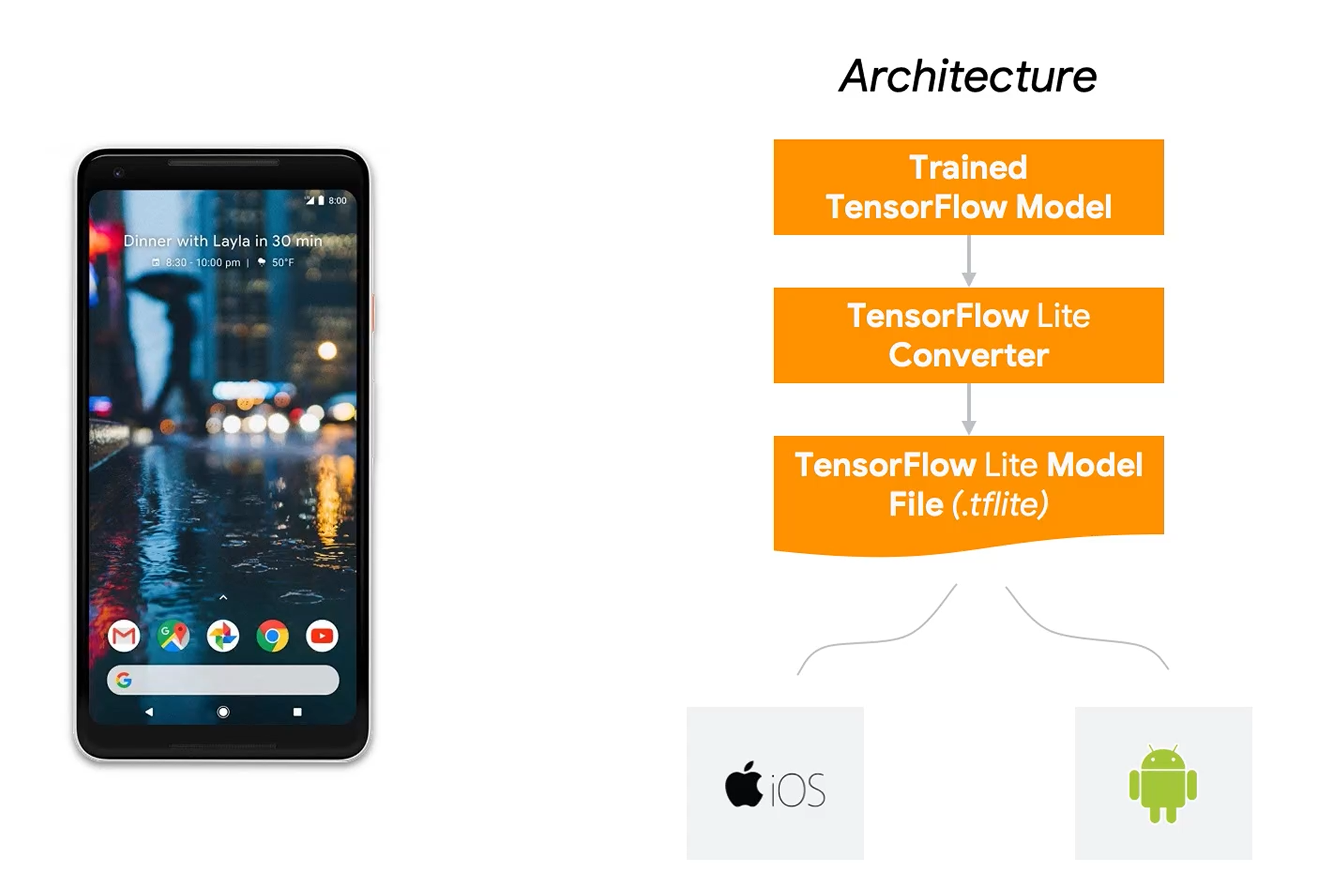
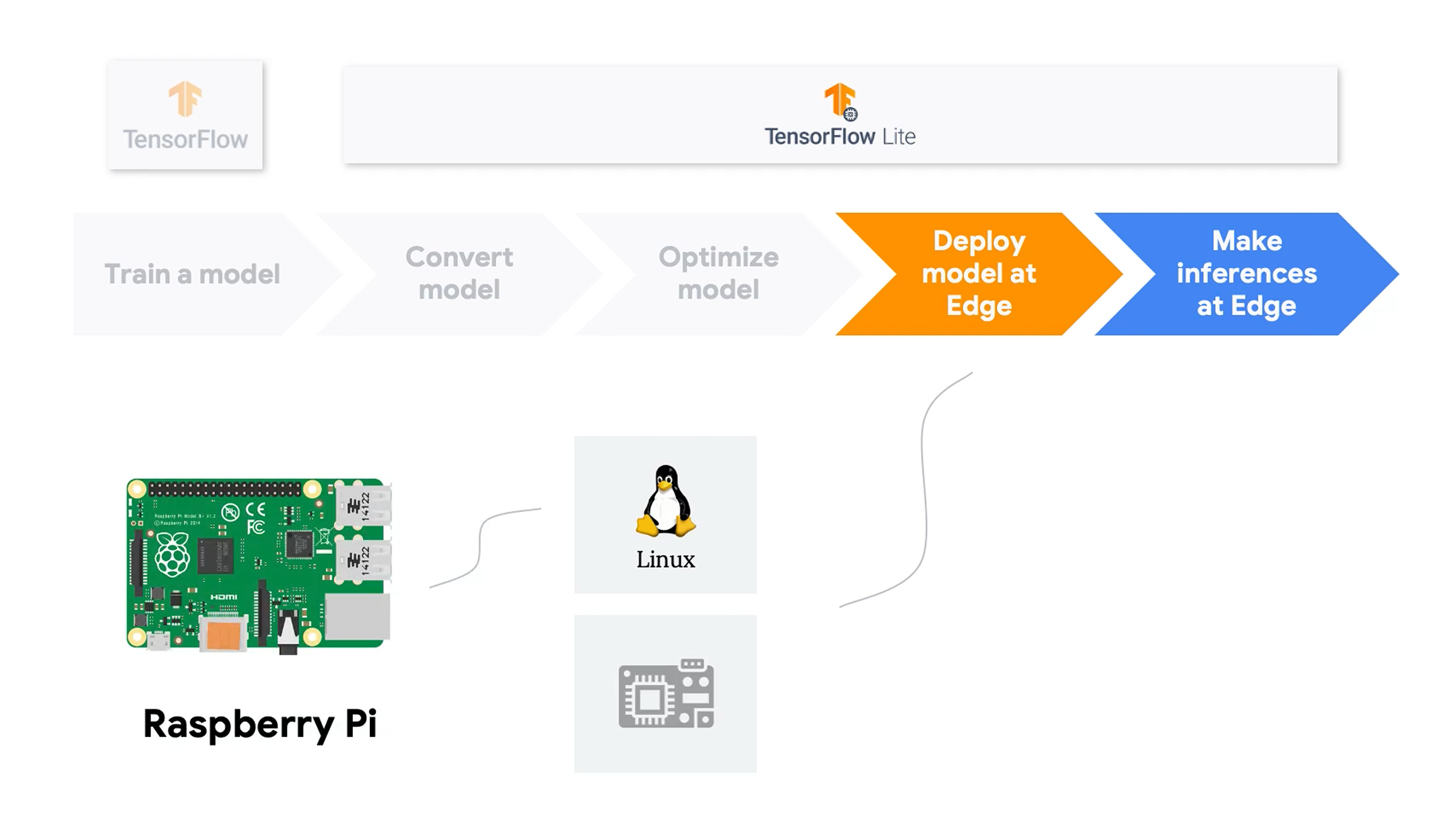
第一部分的后面就是很多Ethics道德的内容,看看就行了。。。
3 Part2
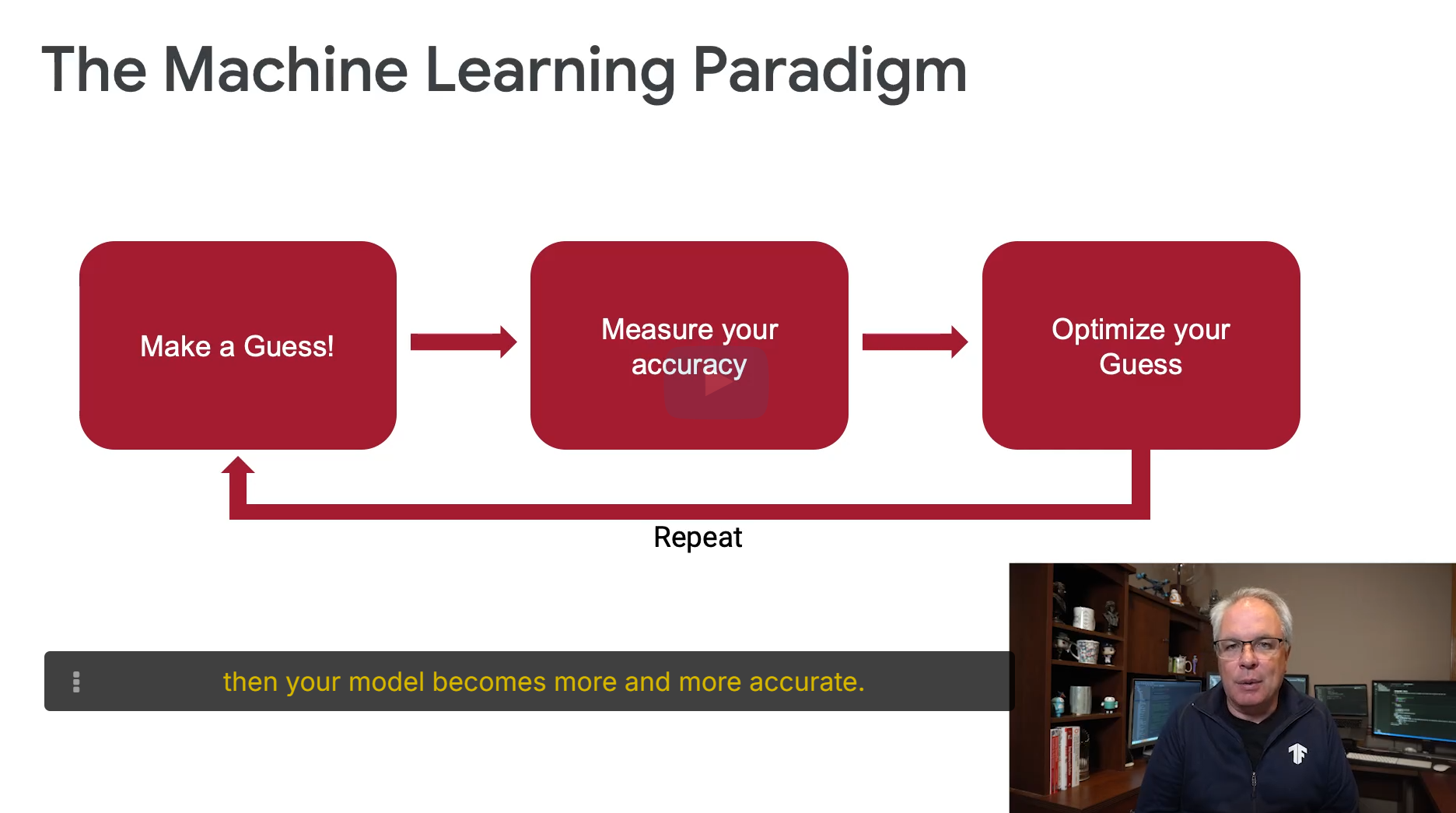
给的这个例子真的很经典,言简意赅的说明了机器学习的本质。
So, consider if I give you a set of numbers like this:
X: -1, 0, 1, 2, 3, 4
And then I give you another set of numbers like this:
Y: -3, -1, 1, 3, 5, 7
Can you figure out the relationship between the two sets? There’s a function that converts -1 to -3, 0 to -1, 1 to 1, 2 to 3, 3 to 5 and 4 to 7. Can you figure out the relationship. Think about it for a moment.
Often when I ask people about it, they see that the 0 is matched to -1, so Y is (something) times X - 1. Maybe they’ll take a guess at the something, and come up with 3.
Then fill in the gaps, if Y=3X-1, then
X: -1, 0, 1, 2, 3, 4
Becomes
Y: -4, -1, 2, 5, 8, 11
Other than working for 0, it fails for everything else. In ML terms, you can define this as your loss is ‘high’. With what you learned from that, you might think, what if it’s Y=2X-1?
Then, when you fill in the results for Y=2X-1, you’ll get:
X: -1, 0, 1, 2, 3, 4
Becomes
Y: -3, -1, 1, 3, 5, 7
...which matches your original data perfectly. Your loss is zero.
You’ve just gone through this process:后面还把这个经典例子做成习题,让求均方误差(Mean Squared Error, MSE)。
import math
# Edit these parameters to try different loss measurements. Rerun this cell when
# done. Your Y will be calculated as Y=wX+b, so if w=3, and b=-1, then Y=3x-1.
w = 3
b = -1
x = [-1, 0, 1, 2, 3, 4]
y = [-3, -1, 1, 3, 5, 7]
myY = []
for thisX in x:
thisY = (w*thisX)+b
myY.append(thisY)
print(f"Real Y is {str(y)}")
print(f"My Y is {str(myY)}")
# let's calculate the loss
total_square_error = 0
for i in range(0, len(y)):
square_error = (y[i] - myY[i]) ** 2
total_square_error += square_error
print(f"My loss is: {str(math.sqrt(total_square_error))}")跟着是梯度下降。
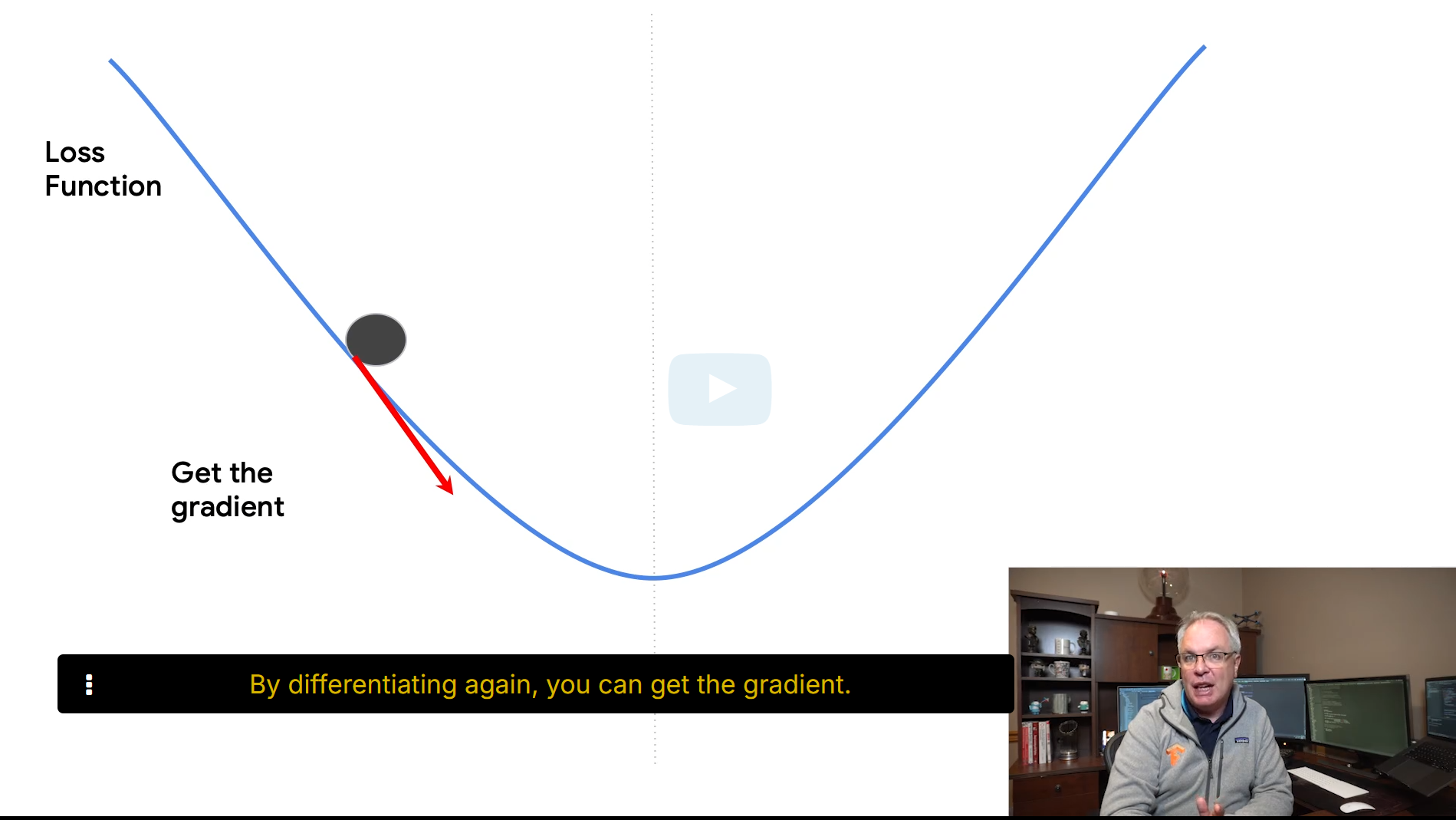
看大神的讲解是真不错,一下就懂了。首先损失函数是可以转化成二次函数也就是上图的图形。损失最小的地方,那就是在谷底,怎么知道是不是谷底呢?求梯度,基本就是求偏导数(这个用微积分算),当偏导数为0,就是谷底,此时也就是最优解。
梯度下降的练习题:https://colab.research.google.com/github/tinyMLx/colabs/blob/master/2-1-6-MimimizingLoss.ipynb
之后说了数据集的划分,和我之前学的还增加了一个测试集。总共分成三部分,数据集,验证集,测试集。

用处是用来评估最后训练好的模型。。。

在实践来说,有80%的代码使用来准备这些数据,10%是用在设置模型本身,最后10%用来测试和清理。
关于Part2,虽然都是应用,但是也很多干货,都是单独写的,列表如下:
1 梯度下降:HarvardX TinyML小笔记1(番外1:梯度下降)-CSDN博客
2 神经网络:HarvardX TinyML小笔记1(番外2:神经网络)-CSDN博客
3 参数:HarvardX TinyML小笔记1(番外3:参数)-CSDN博客
4 DNN:HarvardX TinyML小笔记1(番外4:DNN)-CSDN博客
5 激活函数:HarvardX TinyML小笔记1(番外5:激活函数)-CSDN博客
6 CNN:HarvardX TinyML小笔记1(番外6:CNN)-CSDN博客
4 结尾
这里也说了tinyML的发展历史,说的很好:Course | edX

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)