《计算广告》第三部分计算广告关键技术——笔记(上)
文章目录前言第9章 计算广告技术概览前言本部分主要面向系统工程师、算法工程师和架构师,重点阐释实现各种广告产品的关键技术挑战,并提供基础的解决方案。第9章 计算广告技术概览
文章目录
前言
本部分主要面向系统工程师、算法工程师和架构师,重点阐释实现各种广告产品的关键技术挑战,并提供基础的解决方案。
第9章 计算广告技术概览
计算广告是大数据驱动的产品,也是一个典型的个性化系统。个性化系统与搜索系统一般都采用检索(retrieval)加排序(ranking)这样类搜索的系统架构,主要差别在于大量的用户特征的使用。
个性化系统框架

在线投放(online serving)系统的日志接入数据高速公路,再由数据高速公路快速转运到离线数据处理平台(distributed computing)和在线流计算平台(stream computing);离线数据处理平台周期性地以批处理方式加工过去一段时间的数据,得到人群标签和其他模型参数,存放在高速缓存中,供在线投放系统决策时使用;与此相对应,在线流计算平台则负责处理最近一小段时间的数据,得到准实时的用户标签和其他模型参数,也存放在高速缓存中,供在线投放系统决策时使用,这些是对离线处理结果的及时补充和调整,因为个性化特征的效果与其生成的实时性关系很大。闭环系统是有效全量利用大数据的关键。
在同一个企业中,我们会在不同的业务之间尽可能共享离线和在线的两个计算平台以及所有的用户行为数据,对用户尽可能准确的理解。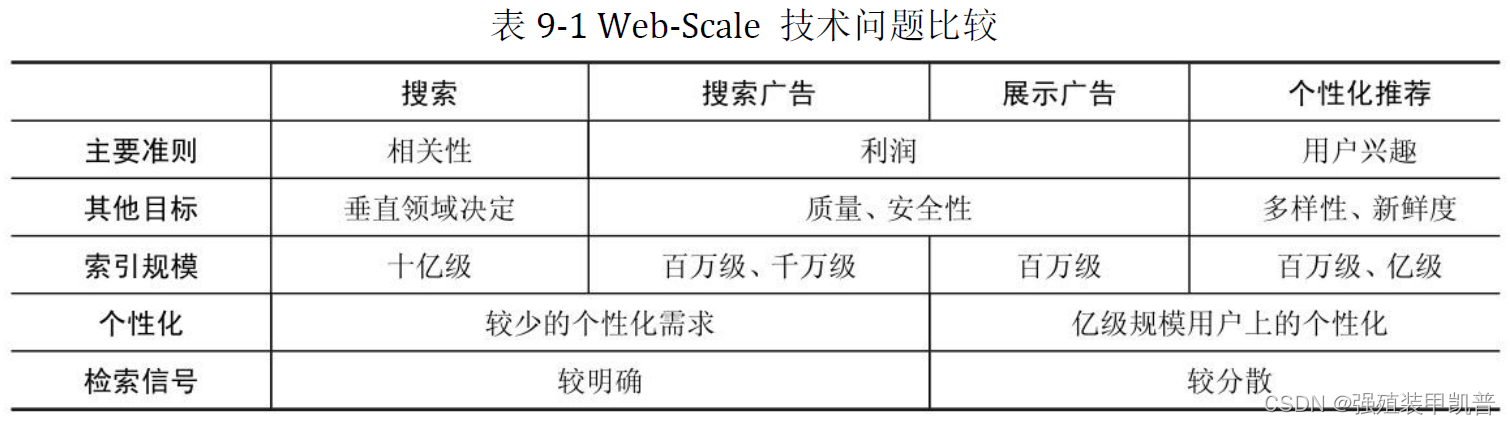
各类广告系统优化目标
收入是 μ v − q \mu v-q μv−q。
在展示量合约的GD系统中,只要各合约达成,系统的收益是确定的,因此这一系统的主要优化在于满足各合约带来的约束,而成本由于是媒体静态产生,与广告优化过程无关,可以认为是常数;
ADN 需要估计点击率 μ ( a , u , c ) \mu(a,u,c) μ(a,u,c),并与广告主出的点击单价 b i d C P C ( a ) bid_{CPC}(a) bidCPC(a)相乘得到期望收入,而成本是与收入成正比的媒体分成;
ADX直接用广告主出的展示单价 b i d C P M ( a ) bid_{CPM}(a) bidCPM(a)作为期望收入,成本也是与收入成正比的媒体分成;
只有在DSP中,点击率、点击价值和成本都可能是需要预估和优化的,因此算法的挑战较大。
计算广告系统架构
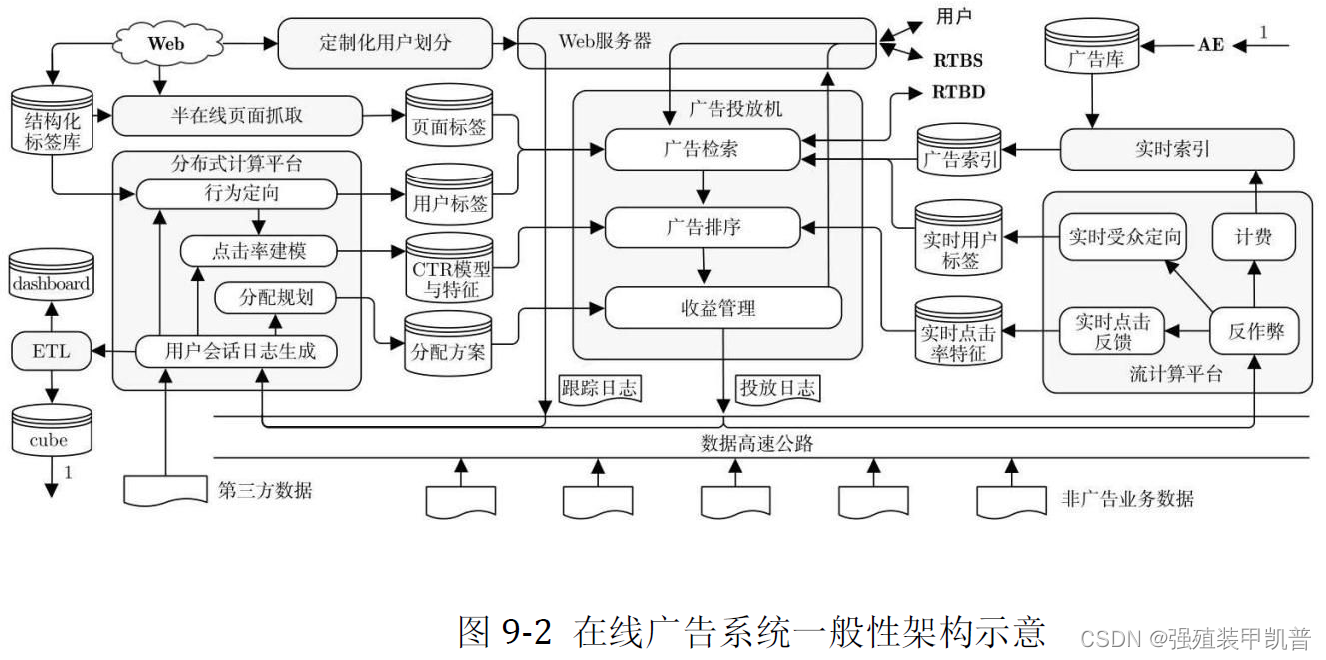
并不是每一个广告系统都需要以上所有的功能模块。这样的架构图和模块划分是为了方便本书后面在各种广告系统之间进行架构上的对比。另外,这样的架构主要是根据竞价广告系统的骨架来进行的。
广告投放引擎
实时响应广告请求并决策广告,必不可少,主要模块有:
- 广告投放机(ad server)。是接受广告前端Web服务器发来的请求,完成广告投放决策并返回最后页面片段的主逻辑,串联功能模块完成在线广告投放决策。为了扩展性的考虑,都采用类搜索的投放机架构,即先通过倒排索引从大量的广告候选中得到少量符合条件或相关的候选,再在这个小的候选集上应用复杂而精确的排序方法找到综合收益最高的若干个广告。最重要的指标是每秒查询数(Query per Second,QPS)以及广告决策的延迟(latency)。
广告检索(ad retrieval) 在线根据用户标签(user attributes)与页面标签(page attributes)从广告索引(ad index)中查找符合条件的广告候选。广告排序(ad ranking) 在线高效地计算候选广告的eCPM,并排序。eCPM的计算主要依赖于点击率估计,这需要用到离线计算得到的CTR模型和特征(CTR Model&Features),有时还会用到流计算得到的实时点击率特征(real-time features)。在需要估计点击价值的广告产品(如按效果结算的DSP)中,还需要一个点击价值估计的模型。收益管理(yield management) 以全局收益最优为目的,进一步调整局部广告排序结果,如GD系统中的在线分配、DSP中的出价策略等。这部分一般都需要用到离线计算好的某种分配计划来完
成在线时的决策。 - 广告请求接口。提供用户唯一的身份标识ID以及其他一些上下文信息。程序化交易市场中的广告请求接口采用主要ADX规定的接口形式。
- 定制化用户划分(customized audience segmentation)。从广告主处收集用户信息的产品接口。
数据高速公路
将在线投放的数据准实时传输到离线分布式计算平台与流计算平台上,供后续处理和建模使用。
离线数据处理
计算广告最具挑战的算法问题大多都集中在离线数据处理的部分。两个输出目标:一是统计日志得到报表、dashboard 等,供决策人进行决策时作为参考;二是利用数据挖掘、机器学习技术进行受众定向、点击率预估、分配策略规划等,为在线的机器决策提供支持。主要模块有:
- 用户会话日志生成。以用户ID为键的统一存储格式的日志,称为用户会话日志(session log)。
- 行为定向(behaviorial targeting)。根据日志中的行为给用户打上结构化标签库(structural label base)中的某些标签,存储到在线缓存中。
- 上下文定向(contextual targeting)。包括半在线页面抓取(near-Line page Fetcher)和上下文页面标签的缓存,与行为定向互相配合,负责给上下文页面打上标签。
- 点击率建模(click modeling)。在分布式计算平台上训练得到点击率的模型参数和相应特征(click model&features)。
- 分配规划(allocation planning)。为在线的收益管理模块提供服务。
- 商业智能(business intelligence,BI)系统。包括Extract-Transform-Load(ETL)过程、dashboard和cube,这些是所有以人为最终接口的数据处理和分析流程的总括,担负着对外信息交流的任务。
- 广告管理系统。客户执行(Account Execute,AE)与广告系统的接口,通常广告系统中只有这部分是面向用户的产品。
在线数据处理
以下模块存在前后依赖关系:
- 在线反作弊(anti-spam)。将作弊流量从后续的计价和统计中去除掉。
- 计费(billing)。下线预算耗尽的广告。
- 在线行为反馈,包括实时受众定向(real-time targeting)和实时点击反馈(realtime click feedback)等部分。在很多情形下,把系统信息反馈调整做得更快比把模型预测做得更准确效果更加显著。
- 实时索引(real-time indexing)。实时接受广告投放数据,建立倒排索引。
用开源工具搭建计算广告系统

这不是博主的关注点,不作展开。
第10章 基础知识准备
示例代码为C++或Matlab。
信息检索
信息检索(Information Retrieval,IR)是所有大规模数据处理系统,特别是搜索和个性化系统的通用技术。
倒排索引
以O(1)或O(logn)完成从大量文档中查找包含某些词的文档集合,实现与文档集大小基本无关的检索复杂度,是大规模信息检索的基石。
假设我们有如下的几篇文档:
D1=“谷歌地图之父跳槽Facebook”
D2=“谷歌地图之父加盟Facebook”
D3=“谷歌地图创始人拉斯离开谷歌加盟Facebook”
D4=“谷歌地图创始人跳槽Facebook 与Wave 项目取消有关”
D5=“谷歌地图创始人拉斯加盟社交网站Facebook”
分词得到关键词(term),去掉没有实际表意作用的停止词(stop word),对每一个词建立一个链表,表中的每个元素都是包含该词的某篇文档的标识。与上面的文档集对应的倒排索引,也就是所有关键词的倒排链集合可以表示如下:
谷歌→{D1,D2,D3,D4,D5},
地图→{D1,D2,D3,D4,D5},
之父→{D1,D2,D4,D5},
跳槽→{D1,D4},
Facebook→{D1,D2,D3,D4,D5},
创始人→{D3},
加盟→{D2,D3,D5},
拉斯→{D3,D5},
离开→{D3},
Wave→{D4},
取消→{D4},
项目→{D4},
有关→{D4},
社交→{D4},
网站→{D4}
倒排索引最基本的操作有两项:一是向索引中加入一个新文档,二是给定一个由多个关键词组成的查询时,返回对应的文档集合。
向量空间模型
向量空间模型(Vector Space Model,VSM)是信息检索中最基础且最重要的文档相似度度量方法之一。VSM 的核心有两点:文档的表示方法和相似度计算方法。
对每个文档采用词袋(Bag of Words,BoW)假设,即用各个关键词在文档中的强度组成的矢量来表示该文档:
d = ( x 1 , ⋯ , x M ) ⊤ d=(x_1,\cdots,x_M)^{\top} d=(x1,⋯,xM)⊤
x m x_m xm一般采用词表中第m个词在d中对应的TF-IDF(Term Frequency-Inverse Document Frequency,词频–倒数文档频率)值,即TF与IDF的乘积。TF是该文档中该词出现的次数。IDF是该词在所有文档中出现的频繁程度的倒数,考虑到那些广泛出现在各个文档中的常用词对主题的鉴别力并不强,因而需要降低其权重,最常用形式 I D F ( m ) = log ( N / D F ( m ) ) IDF(m)=\log(N/DF(m)) IDF(m)=log(N/DF(m)), D F ( m ) DF(m) DF(m)为出现词m的文档总数目,N为总文档数目。
基于BoW的表示,可以计算相似度等。余弦距离可以不做归一化,欧氏距离不行。
在探索各种数据驱动的精细模型时,要先将它们与VSM 方法做比较。
最优化方法
最优化问题讨论的是,给定某个确定的目标函数以及该函数自变量的一些约束条件,求解该函数的最大或最小值的问题。带约束优化问题在一定条件下可以转化为无约束优化问题来求解。
拉格朗日法与凸优化
将一个带约束优化问题转化为不带约束优化问题,即对偶函数。
下降单纯形法(downhill simplex method)
自变量多维,在D维空间中可以选择一个D+1个点张成的超多面体或称为单纯形(simplex),然后对这一单纯形不断变形
以收敛到函数值的最小点,就像一维使用两个点缩。
梯度下降法
梯度的几何意义是f在x点函数值上升最快的方向,因此它是一个与x维数相等的矢量。梯度下降更新公式 x ← x − ϵ ∇ f ( x ) x\leftarrow x-\epsilon \nabla f(x) x←x−ϵ∇f(x),其中 ϵ \epsilon ϵ是学习率。
拟牛顿法
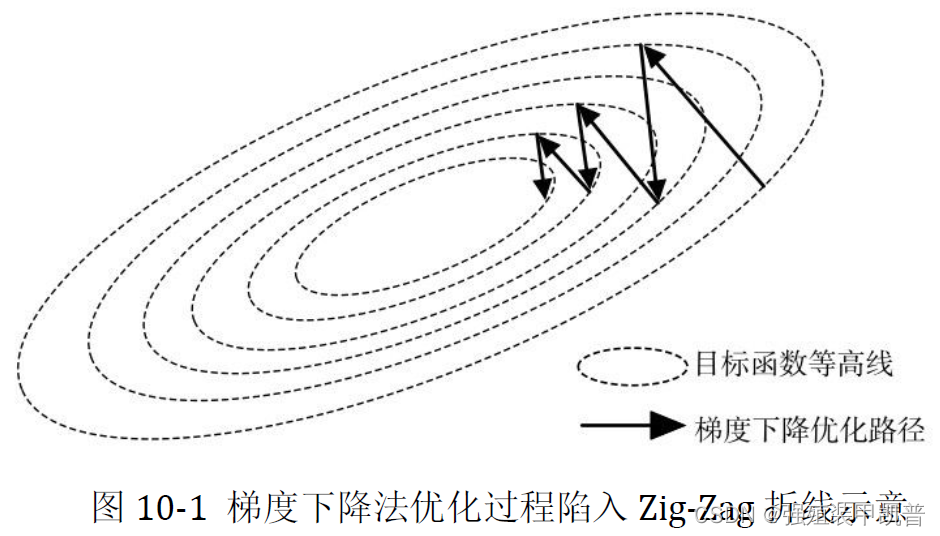
采用批处理模式的梯度下降法,当函数值对各个自变量归一化不够好时,优化过程会陷入Zig-Zag 折线更新的困境(不是圆)。在自变量维数很高时,这一问题尤为严重,因为我们无法一一检查各个自变量的意义,因此在某些维度上缩放尺度不一样是无法避免的。
二阶导是海森矩阵 ∇ 2 f ( x ) = { ∂ 2 f ∂ x i ∂ x j } D × D \nabla^2 f(x)=\{\frac{\partial^2 f}{\partial x_i\partial x_j}\}_{D\times D} ∇2f(x)={∂xi∂xj∂2f}D×D,牛顿法更新方式为 x ← x + ϵ [ ∇ 2 f ( x ) ] − 1 ∇ f ( x ) x\leftarrow x+\epsilon[\nabla^2 f(x)]^{-1}\nabla f(x) x←x+ϵ[∇2f(x)]−1∇f(x)。
只有当海森矩阵正定时,极小值才存在。但即使目标函数存在唯一的极小值,也不能保证每一点的赫斯矩阵都正定,利用前面几次迭代的函数值和梯度可以近似地拟合出海森矩阵,即BFGS。牛顿法是在当前自变量点进行泰勒展开,因此拟合出来的二次曲面严格来说只在很小的邻域内是有效的, ϵ \epsilon ϵ需要满足Wolfe条件。在实际的拟牛顿法中,在得到下降方向后,需要在下降方向上进行线搜索(line search),以找到满足Wolfe 条件的 ϵ \epsilon ϵ用以更新参数。
Trust-Region 法
梯度下降法、牛顿法和拟牛顿法都属于线搜索方法,它们的共同特点是,在当前迭代点 x k x_k xk处寻找下一个迭代点 x k + 1 x_{k+1} xk+1时,先方向,后步长。
Trust-Region法每次迭代时,将搜索范围限制在 x k x_k xk的一个置信域内,然后同时决定下次迭代的方向和步长;如果当前置信域内找不到可行解,则缩小置信域范围。
用函数 f ( x k + s ) f(x_k +s) f(xk+s)在 x k x_k xk处的泰勒展开来近似:
min s m k ( s ) = f ( x k ) + ∇ ⊤ f ( x k ) + 1 2 s ⊤ ∇ 2 f ( x k ) s s . t . ∥ s ∥ 2 ≤ δ k \min_s m_k(s)=f(x_k)+\nabla^{\top}f(x_k)+\frac{1}{2}s^{\top}\nabla^2f(x_k)s \ \rm s.\rm t.\|s\|_2\le\delta_k sminmk(s)=f(xk)+∇⊤f(xk)+21s⊤∇2f(xk)s s.t.∥s∥2≤δk
解得的s就是方向和步长。由于此过程没有对目标函数的一阶导和二阶导做近似,往往能够更准确地把握下降方向,因此有时能表现出比拟牛顿法更好的收敛性能。
对于置信半径 δ k \delta_k δk,可以通过比较模型函数和目标函数的下降量来指导:
ρ k = f ( x k ) − f ( x k + s ) m k ( 0 ) − m k ( s ) \rho_k=\frac{f(x_k)-f(x_k+s)}{m_k(0)-m_k(s)} ρk=mk(0)−mk(s)f(xk)−f(xk+s)
ρ ≤ 0 \rho\le0 ρ≤0,则目标函数值没有改进; ρ \rho ρ趋于1,则模型函数较真实地逼近了目标函数; ρ \rho ρ较小,则模型函数和目标函数差别较大,需要缩小置信域,否则伸长。
统计机器学习
最大熵与指数族分布
概率分布 p ( x ) p(x) p(x)的熵为 H ( x ) = − p ( x ) ln p ( x ) H(x)=-p(x)\ln p(x) H(x)=−p(x)lnp(x)。求其最大熵解等价于求一个对应指数形式分布的最大似然解。指数族分布的归一化形式(canonical form)可以表示为:
p ( x ∣ θ ) = h ( x ) g ( θ ) exp { θ ⊤ u ( x ) } p(x|\theta)=h(x)g(\theta)\exp\{\theta^{\top}u(x)\} p(x∣θ)=h(x)g(θ)exp{θ⊤u(x)}
u ( x ) u(x) u(x)是特征函数 f i ( x ) f_i(x) fi(x)的矢量形式; θ \theta θ是指数族分布的参数; g ( θ ) g(\theta) g(θ)是使得概率密度曲线下面积为1的归一化项。
指数族分布在建模上被广泛采用是因为一个重要的特性:指数族分布参数的最大似然估可以完全由其充分统计量(sufficient statistics)得到,充分统计量即 ∑ i = 1 N u ( x i ) \sum_{i=1}^N u(x_i) ∑i=1Nu(xi), θ \theta θ的最大似然解为 1 N ∑ i = 1 N u ( x i ) \frac{1}{N}\sum_{i=1}^N u(x_i) N1∑i=1Nu(xi)。
在给定充分统计量以后,最大似然估计过程与数据无关。根据充分统计量的形式,我们很容易得出,无论什么样的指数族分布,都只需要遍历一遍数据就可以得到最大似然解。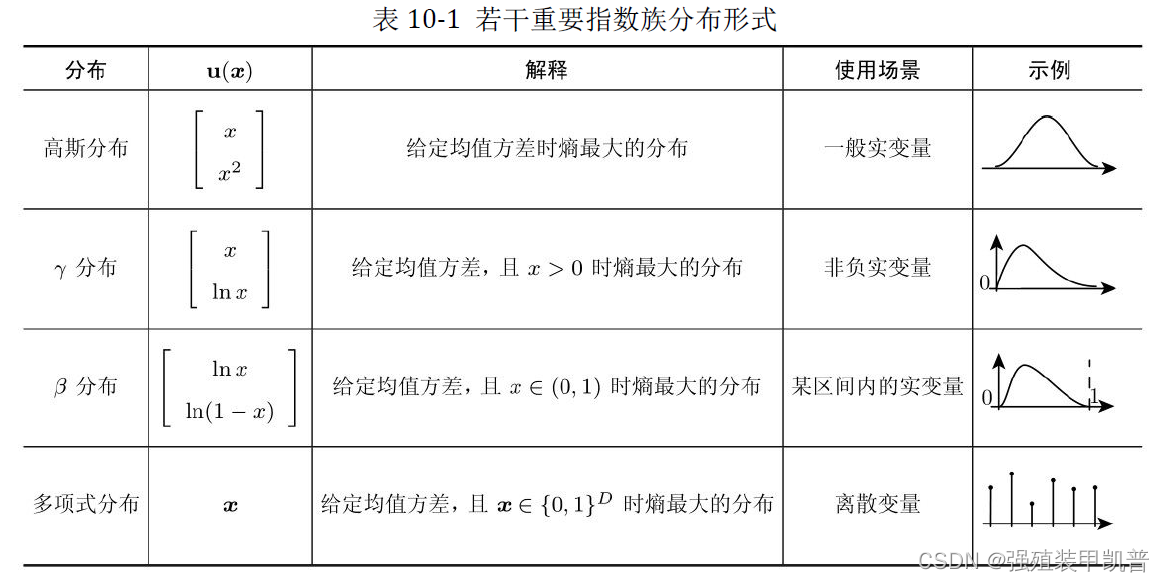
指数族分布的另一个重要特点——分布都是单模态(uni-modal)的,即分布从几何形态上看只有一个峰或者一个谷,实际的描述能力是有限的,并不适合于表达多种因素并存的随机变量。
混合模型和EM算法
多个指数族分布叠加,即混合模型(mixture model)可以表示为:
p ( x ∣ w , θ ) = ∑ k = 1 K w k h ( x ) g ( θ k ) exp { θ k ⊤ u ( x ) } p(x|w,\theta)=\sum_{k=1}^K w_k h(x)g(\theta_k)\exp\{\theta_k^{\top} u(x)\} p(x∣w,θ)=k=1∑Kwkh(x)g(θk)exp{θk⊤u(x)}
w w w是个组成部分的先验概率, θ \theta θ是各组成部分的参数。引入多项式变量 z z z来明确表示状态,可以把混合分布改写成结构更清晰的表达式:
p ( x ∣ w , θ ) = ∑ z ∏ k w k z k { h ( x ) g ( θ ) exp { θ k ⊤ u ( x ) } } z k p(x|w,\theta)=\sum_z\prod_k w_k^{z_k}\{h(x)g(\theta)\exp\{\theta_k^{\top} u(x)\}\}^{z_k} p(x∣w,θ)=z∑k∏wkzk{h(x)g(θ)exp{θk⊤u(x)}}zk
w , θ w,\theta w,θ是要求解的参数, x x x是观测变量, z z z是隐变量。EM算法就是为了解决有隐变量存在时的最大似然估计问题的。在E-step阶段,将参数变量和观测变量都固定,得到隐变量的后验分布;在M-step阶段,用得到的隐变量的后验分布和观测变量再去更新参数变量。
贝叶斯学习
最大似然准则是把模型的参数看成固定的,然后找到使得训练数据上似然值最大的参数,这是一种参数点估计(point estimation)的方法。这样的点估计方法在实际中如果遇到数据样本不足的情形,往往会产生比较大的估计偏差,就会用贝叶斯。
贝叶斯公式: p ( θ ∣ X ) = p ( X ∣ θ ) p ( θ ) p ( X ) p(\theta|X)=\frac{p(X|\theta)p(\theta)}{p(X)} p(θ∣X)=p(X)p(X∣θ)p(θ),即 后 验 分 布 = 似 然 值 ⋅ 先 验 分 布 e v i d e n c e 后验分布=\frac{似然值\cdot 先验分布}{evidence} 后验分布=evidence似然值⋅先验分布, θ \theta θ被看作是服从一定分布的随机
变量。在没有数据支持的情况下,我们对其有一个假设性的先验分布 p ( θ ) p(\theta) p(θ)。
概率统计模型有两个常见任务:一是参数估计(parameter estimation),二是预测(prediction)。其中第二项任务指的是给定一组训练数据X ,评估某新的观测数据o的概率。
在最大似然体系下,参数估计是根据似然值最大化得到的点估计,而预测过程就利用估计出来的参数计算似然值 p ( o ∣ θ ) p(o|\theta) p(o∣θ)即可。在贝叶斯体系下,参数的点估计被其后验分布所代替,也就意味着参数在估计结果中具有不确定性,于是在预测过程中,需要用积分的方式将参数的不同可能性都加以考虑,这是两者非常本质的区别。在最大后验概率(Maximum A Posterior,MAP)方法下,本质上仍然是点估计方法,只不过同样引入了先验部分对参数作规范化,因此,其参数估计形式上是对贝叶斯后验概率求极值,而预测过程则与最大似然情形一样。
对于先验分布的选择,这一点有两层含义:一是如何选择先验分布的形式,二是如何确定先验分布中的参数。后验分布才是在使用中最关键的,其形式如果过于复杂,会给实际应用带来很大困难。如果我们能够找到一种先验分布,使得相应的后验分布也具有同样的形式,无疑是方便的。满足这种条件的先验分布就称为共轭先验(conjugate prior)。
对于指数族分布的似然函数,共轭先验总是存在的。
- 对于高斯分布,如果仅仅考虑其均值的不确定性,对应的共轭先验仍然是高斯分布。
- 对于 γ \gamma γ分布,其对应的共轭先验称为维希特分布(Wishart distribution)。
- 对于多项式分布,其对应的共轭先验是狄利克雷分布(Dirichlet distribution)。
选择共轭的先验形式,从贝叶斯体系来看并没有太多理论上的必然性,这主要是为了满足工程上的方便性。
evidence是将模型参数积分后的似然值的期望,在似然值和先验部分的形式确定的前提下,evidence 仅仅是先验部分的函数。如果把evidence 认为是超参数对应的似然值,那么也可以用优化evidence的方式找到最优的超参数。这种根据数据来确定超参数的方法就称为经验贝叶斯。
统计模型分布式优化框架

当算法需要多次迭代才能完成的时候,由于需要在每次Map 过程中重新加载数据,使得整个过程的I/O 负担变得较重,从而降低整个计算过程的效率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)