yolo常用操作(长话短说)热力图,特征图,结构图,训练,测试,预测
热力图,特征图,结构图,训练,测试,预测
·
训练
方式一:
训练有很多种训练方式,我挑选的是我认为最为简单的一种,即新建一个train.py文件,将参数修改为自己的参数,其中workers=0,workspace=4最好不要动
from ultralytics import YOLO
model = YOLO(r'yolo11n.yaml') # 改为模型文件名
model.load('yolo11n.pt') # 权重文件名,官网下载
results = model.train(
data=r'fish.yaml', # 数据yaml文件
epochs=300,
batch=8,
device=0,
workers=0,
workspace=4
)yaml文件不会搞的,指路(yaml文件制作)
方式二:
修改default.yaml文件,然后在终端调用
default.yaml文件在yolov10/ultralytics/cfg文件中
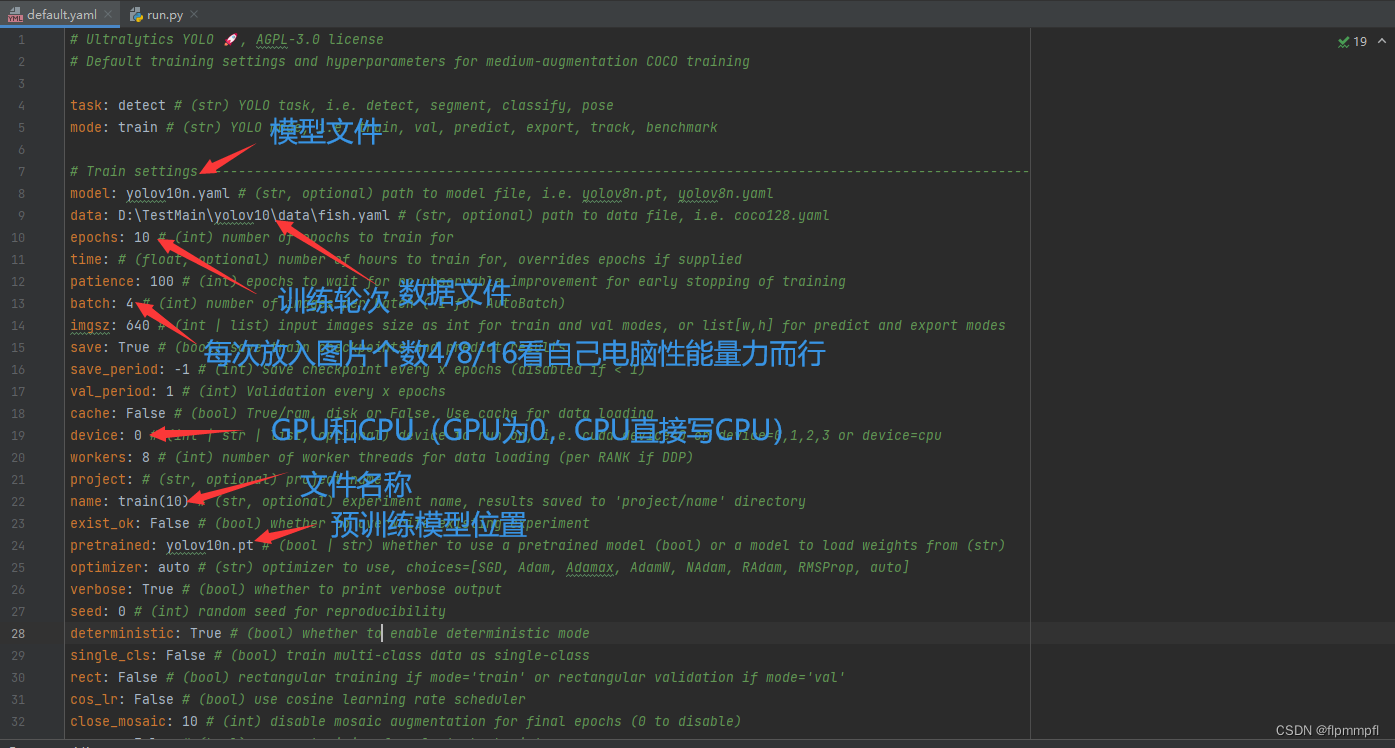
需修改(最好为绝对路径,多仔细看看,容易出错)
模型文件model(yolov10n.yaml(模型文件)位置)
数据文件(训练图片)data(data.yaml文件所在位置)
训练轮次epochs(基本为300)
训练所放图片个数batch(4/8/16,看自己电脑量力而行)
训练存储地址和名称name(可不改)
使用GPU训练device:0(重点)(如有两个GPU:[0,1])
预训练权重pretrained(yolov10n.pt(权重文件,要于上面对应,就比如你用yolo10n训练你就必须要yolov10n.pt来作为你的预训练权重)位置,无可以不填)
点击终端,输入神秘代码: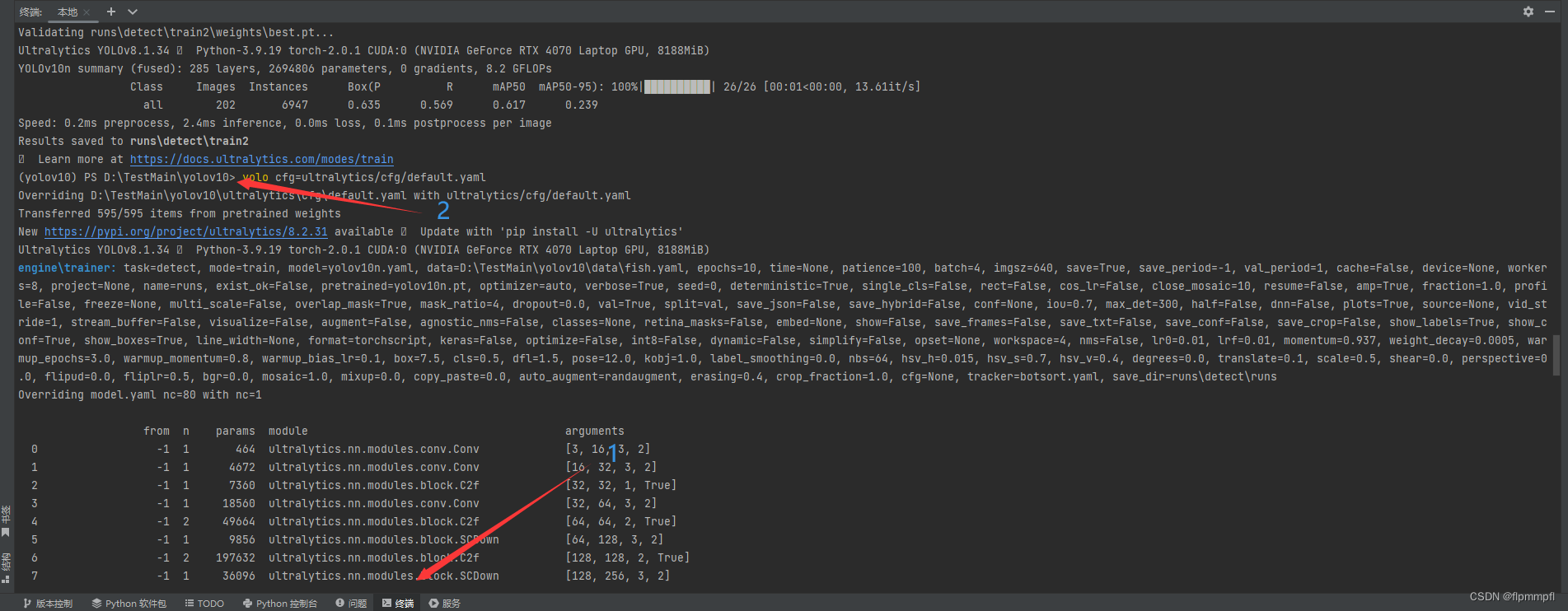
yolo cfg=ultralytics/cfg/default.yaml
测试
用于评估训练好的模型在验证集上的性能。通常用于查看模型的精度、召回率、mAP 等指标。新建一个val.py,复制粘贴,将数据替换为自己的
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'best.pt') # 选择训练好的权重路径
model.val(data=r'fish.yaml', # 数据yaml文件
split='val', # split可以选择train、val、test 根据自己的数据集情况来选择.
imgsz=640,
batch=16,
# iou=0.7,
# conf=0.4,
# rect=False,
# save_json=True, # if you need to cal coco metrice
project='runs/val', # 保存文件夹名称
name='exp', # 文件名
)预测
用于对新图片进行推理预测,即给定图片路径,输出检测结果(可视化、保存等)。新建一个test.py,复制粘贴,需改.pt文件和预测集图片位置 .pt文件改你训练出的
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('best.pt') # 预测权重
model.predict(source='test', # 预测图片文件夹
imgsz=640,
project='runs/detect', # 保存文件夹名称
name='exp', # 文件名
save=True,
# conf=0.2,
# iou=0.7,
# agnostic_nms=True,
# visualize=True, # visualize model features maps
# line_width=2, # line width of the bounding boxes
# show_conf=False, # do not show prediction confidence
# show_labels=False, # do not show prediction labels
# save_txt=True, # save results as .txt file
# save_crop=True, # save cropped images with results
)结构图
简答输出:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# choose your yaml file
model = YOLO('yolo11.yaml') # 输出的模型文件
model.info(detailed=True)
try:
model.profile(imgsz=[640, 640])
except Exception as e:
print(e)
pass
model.fuse()详细输出(onnx):
要下载onnx库:
pip install onnx
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO(r"best.pt") # 权重文件
# # 将模型转为onnx格式
success = model.export(format='onnx')然后直接打开你运行框中的链接即可
特征图
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
pth_path = r"best.pt" # 模型权重文件
test_path = r"test" # 要特征的预测的图片
model = YOLO(pth_path) # load a custom model
metrics = model.predict(test_path, conf=0.5, save=True, visualize=True)
热力图
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter('ignore')
import torch, yaml, cv2, os, shutil, sys, copy
import numpy as np
np.random.seed(0)
import matplotlib.pyplot as plt
from tqdm import trange
from PIL import Image
from ultralytics import YOLO
from ultralytics.nn.tasks import attempt_load_weights
from ultralytics.utils.torch_utils import intersect_dicts
from ultralytics.utils.ops import xywh2xyxy, non_max_suppression
from pytorch_grad_cam import GradCAMPlusPlus, GradCAM, XGradCAM, EigenCAM, HiResCAM, LayerCAM, RandomCAM, EigenGradCAM, \
KPCA_CAM, AblationCAM
from pytorch_grad_cam.utils.image import show_cam_on_image, scale_cam_image
from pytorch_grad_cam.activations_and_gradients import ActivationsAndGradients
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (top, bottom, left, right)
class ActivationsAndGradients:
""" Class for extracting activations and
registering gradients from targetted intermediate layers """
def __init__(self, model, target_layers, reshape_transform):
self.model = model
self.gradients = []
self.activations = []
self.reshape_transform = reshape_transform
self.handles = []
for target_layer in target_layers:
self.handles.append(
target_layer.register_forward_hook(self.save_activation))
# Because of https://github.com/pytorch/pytorch/issues/61519,
# we don't use backward hook to record gradients.
self.handles.append(
target_layer.register_forward_hook(self.save_gradient))
def save_activation(self, module, input, output):
activation = output
if self.reshape_transform is not None:
activation = self.reshape_transform(activation)
self.activations.append(activation.cpu().detach())
def save_gradient(self, module, input, output):
if not hasattr(output, "requires_grad") or not output.requires_grad:
# You can only register hooks on tensor requires grad.
return
# Gradients are computed in reverse order
def _store_grad(grad):
if self.reshape_transform is not None:
grad = self.reshape_transform(grad)
self.gradients = [grad.cpu().detach()] + self.gradients
output.register_hook(_store_grad)
def post_process(self, result):
if self.model.end2end:
logits_ = result[:, :, 4:]
boxes_ = result[:, :, :4]
sorted, indices = torch.sort(logits_[:, :, 0], descending=True)
return logits_[0][indices[0]], boxes_[0][indices[0]]
elif self.model.task == 'detect':
logits_ = result[:, 4:]
boxes_ = result[:, :4]
sorted, indices = torch.sort(logits_.max(1)[0], descending=True)
return torch.transpose(logits_[0], dim0=0, dim1=1)[indices[0]], torch.transpose(boxes_[0], dim0=0, dim1=1)[
indices[0]]
elif self.model.task == 'segment':
logits_ = result[0][:, 4:4 + self.model.nc]
boxes_ = result[0][:, :4]
mask_p, mask_nm = result[1][2].squeeze(), result[1][1].squeeze().transpose(1, 0)
c, h, w = mask_p.size()
mask = (mask_nm @ mask_p.view(c, -1))
sorted, indices = torch.sort(logits_.max(1)[0], descending=True)
return torch.transpose(logits_[0], dim0=0, dim1=1)[indices[0]], torch.transpose(boxes_[0], dim0=0, dim1=1)[
indices[0]], mask[indices[0]]
elif self.model.task == 'pose':
logits_ = result[:, 4:4 + self.model.nc]
boxes_ = result[:, :4]
poses_ = result[:, 4 + self.model.nc:]
sorted, indices = torch.sort(logits_.max(1)[0], descending=True)
return torch.transpose(logits_[0], dim0=0, dim1=1)[indices[0]], torch.transpose(boxes_[0], dim0=0, dim1=1)[
indices[0]], torch.transpose(poses_[0], dim0=0, dim1=1)[indices[0]]
elif self.model.task == 'obb':
logits_ = result[:, 4:4 + self.model.nc]
boxes_ = result[:, :4]
angles_ = result[:, 4 + self.model.nc:]
sorted, indices = torch.sort(logits_.max(1)[0], descending=True)
return torch.transpose(logits_[0], dim0=0, dim1=1)[indices[0]], torch.transpose(boxes_[0], dim0=0, dim1=1)[
indices[0]], torch.transpose(angles_[0], dim0=0, dim1=1)[indices[0]]
elif self.model.task == 'classify':
return result[0]
def __call__(self, x):
self.gradients = []
self.activations = []
model_output = self.model(x)
if self.model.task == 'detect':
post_result, pre_post_boxes = self.post_process(model_output[0])
return [[post_result, pre_post_boxes]]
elif self.model.task == 'segment':
post_result, pre_post_boxes, pre_post_mask = self.post_process(model_output)
return [[post_result, pre_post_boxes, pre_post_mask]]
elif self.model.task == 'pose':
post_result, pre_post_boxes, pre_post_pose = self.post_process(model_output[0])
return [[post_result, pre_post_boxes, pre_post_pose]]
elif self.model.task == 'obb':
post_result, pre_post_boxes, pre_post_angle = self.post_process(model_output[0])
return [[post_result, pre_post_boxes, pre_post_angle]]
elif self.model.task == 'classify':
data = self.post_process(model_output)
return [data]
def release(self):
for handle in self.handles:
handle.remove()
class yolo_detect_target(torch.nn.Module):
def __init__(self, ouput_type, conf, ratio, end2end) -> None:
super().__init__()
self.ouput_type = ouput_type
self.conf = conf
self.ratio = ratio
self.end2end = end2end
def forward(self, data):
post_result, pre_post_boxes = data
result = []
for i in trange(int(post_result.size(0) * self.ratio)):
if (self.end2end and float(post_result[i, 0]) < self.conf) or (
not self.end2end and float(post_result[i].max()) < self.conf):
break
if self.ouput_type == 'class' or self.ouput_type == 'all':
if self.end2end:
result.append(post_result[i, 0])
else:
result.append(post_result[i].max())
elif self.ouput_type == 'box' or self.ouput_type == 'all':
for j in range(4):
result.append(pre_post_boxes[i, j])
return sum(result)
class yolo_segment_target(yolo_detect_target):
def __init__(self, ouput_type, conf, ratio, end2end):
super().__init__(ouput_type, conf, ratio, end2end)
def forward(self, data):
post_result, pre_post_boxes, pre_post_mask = data
result = []
for i in trange(int(post_result.size(0) * self.ratio)):
if float(post_result[i].max()) < self.conf:
break
if self.ouput_type == 'class' or self.ouput_type == 'all':
result.append(post_result[i].max())
elif self.ouput_type == 'box' or self.ouput_type == 'all':
for j in range(4):
result.append(pre_post_boxes[i, j])
elif self.ouput_type == 'segment' or self.ouput_type == 'all':
result.append(pre_post_mask[i].mean())
return sum(result)
class yolo_pose_target(yolo_detect_target):
def __init__(self, ouput_type, conf, ratio, end2end):
super().__init__(ouput_type, conf, ratio, end2end)
def forward(self, data):
post_result, pre_post_boxes, pre_post_pose = data
result = []
for i in trange(int(post_result.size(0) * self.ratio)):
if float(post_result[i].max()) < self.conf:
break
if self.ouput_type == 'class' or self.ouput_type == 'all':
result.append(post_result[i].max())
elif self.ouput_type == 'box' or self.ouput_type == 'all':
for j in range(4):
result.append(pre_post_boxes[i, j])
elif self.ouput_type == 'pose' or self.ouput_type == 'all':
result.append(pre_post_pose[i].mean())
return sum(result)
class yolo_obb_target(yolo_detect_target):
def __init__(self, ouput_type, conf, ratio, end2end):
super().__init__(ouput_type, conf, ratio, end2end)
def forward(self, data):
post_result, pre_post_boxes, pre_post_angle = data
result = []
for i in trange(int(post_result.size(0) * self.ratio)):
if float(post_result[i].max()) < self.conf:
break
if self.ouput_type == 'class' or self.ouput_type == 'all':
result.append(post_result[i].max())
elif self.ouput_type == 'box' or self.ouput_type == 'all':
for j in range(4):
result.append(pre_post_boxes[i, j])
elif self.ouput_type == 'obb' or self.ouput_type == 'all':
result.append(pre_post_angle[i])
return sum(result)
class yolo_classify_target(yolo_detect_target):
def __init__(self, ouput_type, conf, ratio, end2end):
super().__init__(ouput_type, conf, ratio, end2end)
def forward(self, data):
return data.max()
class yolo_heatmap:
def __init__(self, weight, device, method, layer, backward_type, conf_threshold, ratio, show_result, renormalize,
task, img_size):
device = torch.device(device)
model_yolo = YOLO(weight)
model_names = model_yolo.names
print(f'model class info:{model_names}')
model = copy.deepcopy(model_yolo.model)
model.to(device)
model.info()
for p in model.parameters():
p.requires_grad_(True)
model.eval()
model.task = task
if not hasattr(model, 'end2end'):
model.end2end = False
if task == 'detect':
target = yolo_detect_target(backward_type, conf_threshold, ratio, model.end2end)
elif task == 'segment':
target = yolo_segment_target(backward_type, conf_threshold, ratio, model.end2end)
elif task == 'pose':
target = yolo_pose_target(backward_type, conf_threshold, ratio, model.end2end)
elif task == 'obb':
target = yolo_obb_target(backward_type, conf_threshold, ratio, model.end2end)
elif task == 'classify':
target = yolo_classify_target(backward_type, conf_threshold, ratio, model.end2end)
else:
raise Exception(f"not support task({task}).")
target_layers = [model.model[l] for l in layer]
method = eval(method)(model, target_layers)
method.activations_and_grads = ActivationsAndGradients(model, target_layers, None)
colors = np.random.uniform(0, 255, size=(len(model_names), 3)).astype(np.int32)
self.__dict__.update(locals())
def post_process(self, result):
result = non_max_suppression(result, conf_thres=self.conf_threshold, iou_thres=0.65)[0]
return result
def draw_detections(self, box, color, name, img):
xmin, ymin, xmax, ymax = list(map(int, list(box)))
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), tuple(int(x) for x in color), 2) # 绘制检测框
cv2.putText(img, str(name), (xmin, ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.8, tuple(int(x) for x in color), 2,
lineType=cv2.LINE_AA) # 绘制类别、置信度
return img
def renormalize_cam_in_bounding_boxes(self, boxes, image_float_np, grayscale_cam):
"""Normalize the CAM to be in the range [0, 1]
inside every bounding boxes, and zero outside of the bounding boxes. """
renormalized_cam = np.zeros(grayscale_cam.shape, dtype=np.float32)
for x1, y1, x2, y2 in boxes:
x1, y1 = max(x1, 0), max(y1, 0)
x2, y2 = min(grayscale_cam.shape[1] - 1, x2), min(grayscale_cam.shape[0] - 1, y2)
renormalized_cam[y1:y2, x1:x2] = scale_cam_image(grayscale_cam[y1:y2, x1:x2].copy())
renormalized_cam = scale_cam_image(renormalized_cam)
eigencam_image_renormalized = show_cam_on_image(image_float_np, renormalized_cam, use_rgb=True)
return eigencam_image_renormalized
def process(self, img_path, save_path):
# img process
try:
img = cv2.imdecode(np.fromfile(img_path, np.uint8), cv2.IMREAD_COLOR)
except:
print(f"Warning... {img_path} read failure.")
return
img, _, (top, bottom, left, right) = letterbox(img, new_shape=(self.img_size, self.img_size),
auto=True) # 如果需要完全固定成宽高一样就把auto设置为False
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = np.float32(img) / 255.0
tensor = torch.from_numpy(np.transpose(img, axes=[2, 0, 1])).unsqueeze(0).to(self.device)
print(f'tensor size:{tensor.size()}')
try:
grayscale_cam = self.method(tensor, [self.target])
except AttributeError as e:
print(f"Warning... self.method(tensor, [self.target]) failure.")
return
grayscale_cam = grayscale_cam[0, :]
cam_image = show_cam_on_image(img, grayscale_cam, use_rgb=True)
pred = self.model_yolo.predict(tensor, conf=self.conf_threshold, iou=0.7)[0]
if self.renormalize and self.task in ['detect', 'segment', 'pose']:
cam_image = self.renormalize_cam_in_bounding_boxes(pred.boxes.xyxy.cpu().detach().numpy().astype(np.int32),
img, grayscale_cam)
if self.show_result:
cam_image = pred.plot(img=cam_image,
conf=True, # 显示置信度
font_size=None, # 字体大小,None为根据当前image尺寸计算
line_width=None, # 线条宽度,None为根据当前image尺寸计算
labels=False, # 显示标签
)
# 去掉padding边界
cam_image = cam_image[top:cam_image.shape[0] - bottom, left:cam_image.shape[1] - right]
cam_image = Image.fromarray(cam_image)
cam_image.save(save_path)
def __call__(self, img_path, save_path):
# remove dir if exist
if os.path.exists(save_path):
shutil.rmtree(save_path)
# make dir if not exist
os.makedirs(save_path, exist_ok=True)
if os.path.isdir(img_path):
for img_path_ in os.listdir(img_path):
self.process(f'{img_path}/{img_path_}', f'{save_path}/{img_path_}')
else:
self.process(img_path, f'{save_path}/result.png')
def get_params():
params = {
'weight': 'D:\TestMain\yolov11\yolo11n.pt', # 现在只需要指定权重即可,不需要指定cfg
'device': 'cuda:0',
'method': 'GradCAMPlusPlus',
# GradCAMPlusPlus, GradCAM, XGradCAM, EigenCAM, HiResCAM, LayerCAM, RandomCAM, EigenGradCAM, KPCA_CAM
'layer': [10, 12, 14, 16, 18],
'backward_type': 'all',
# detect:<class, box, all> segment:<class, box, segment, all> pose:<box, keypoint, all> obb:<box, angle, all> classify:<all>
'conf_threshold': 0.2, # 0.2
'ratio': 0.02, # 0.02-0.1
'show_result': False, # 不需要绘制结果请设置为False
'renormalize': False, # 需要把热力图限制在框内请设置为True(仅对detect,segment,pose有效)
'task': 'detect', # 任务(detect,segment,pose,obb,classify)
'img_size': 640, # 图像尺寸
}
return params
# pip install grad-cam==1.5.4 --no-deps
if __name__ == '__main__':
model = yolo_heatmap(**get_params())
model(r'fish', r'out') # 前面输出文件,后面输出文件
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)