大模型的API简单调用
参考文档安装PyPI上的包以后就将代码放到python环境中运行(我在Spyder 用的Python3.8),我们在代码中写的问题是“中国的万里长城简介”。(注意,以下代码中的APPID、APISecret、APIKey将自己申请的替换即可)。要问其它问题的方法类似的,而且还可以根据需求自己训练大模型,参考相关官方文档。:首先,你需要从API提供商那里获取API密钥。点击免费试用,就能获得toke
要调用大模型的API,通常需要以下几个步骤:
-
获取API密钥:首先,你需要从API提供商那里获取API密钥。这个密钥通常用于身份验证。
-
构建请求:使用HTTP库(如
requests)构建请求,包括URL、请求头、请求体等。 -
发送请求:发送请求并获取响应。
-
处理响应:解析响应数据,提取所需的信息。
此处我以python代码编写为例,使用的大模型是星火大模型API,打开以下网址:讯飞星火大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn)

点击免费试用,就能获得token,在调用里面就可以看到以下界面,
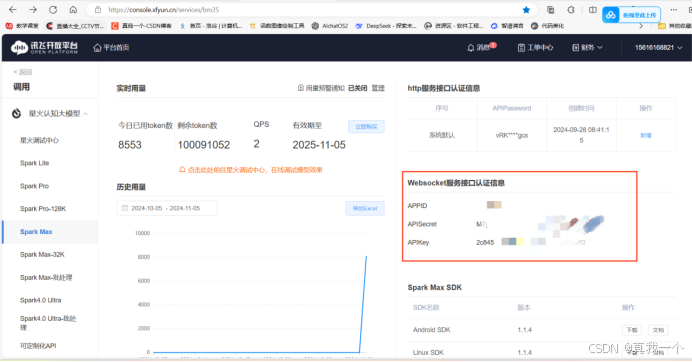
我们需要的是右侧的服务接口认证信息
知道APPID、APISecret、APIKey后我们编写代码,代码可以参考官方接口文档(网址如下):
星火认知大模型Web API文档 | 讯飞开放平台文档中心 (xfyun.cn)
参考文档安装PyPI上的包以后就将代码放到python环境中运行(我在Spyder 用的Python3.8),我们在代码中写的问题是“中国的万里长城简介”。(注意,以下代码中的APPID、APISecret、APIKey将自己申请的替换即可)。
界面如下:
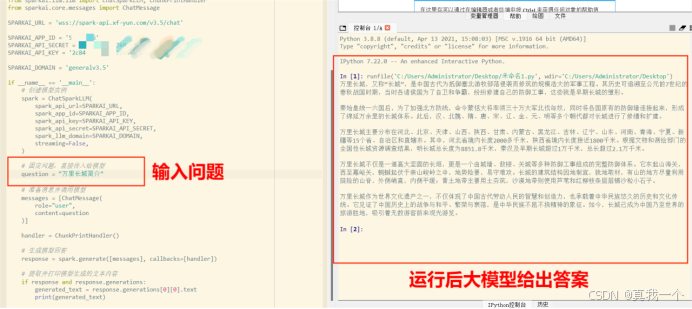
源代码如下:
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
SPARKAI_APP_ID = '5a8fxxxx'
SPARKAI_API_SECRET = 'MTg5NDU4MzJkN2xxxxI2YzVjYjxxxxx'
SPARKAI_API_KEY = '2c845a26c0d711244xxea3379f40a6f0'
SPARKAI_DOMAIN = 'generalv3.5'
if __name__ == '__main__':
# 创建模型实例
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
# 固定问题,直接传入给模型
question = "中国的万里长城简介"
# 准备消息并调用模型
messages = [ChatMessage(
role="user",
content=question
)]
handler = ChunkPrintHandler()
# 生成模型回答
response = spark.generate([messages], callbacks=[handler])
# 提取并打印模型生成的文本内容
if response and response.generations:
generated_text = response.generations[0][0].text
print(generated_text)要问其它问题的方法类似的,而且还可以根据需求自己训练大模型,参考相关官方文档。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)