Ubuntu24.04/Whisper/Docker Compose 本地部署
摘要 OpenAI开源的Whisper是一款基于Transformer架构的自动语音识别系统,具有强大的鲁棒性和多语言支持能力。其核心技术特点包括:端到端的Transformer架构处理30秒音频片段、在68万小时多语言数据上训练、统一的多任务格式设计。Whisper提供从tiny到large五种模型规格,适用于会议记录、视频字幕、语音翻译等多种场景。支持命令行、Python集成和API调用三种使
·
简介
Whisper 是 OpenAI 于 2022 年 9 月开源的一款自动语音识别系统。它最突出的特点在于其鲁棒性,即使在面对口音、背景噪音或专业术语等复杂场景时,也能保持较高的识别准确性,在英语语音识别上已接近人类水平 。
核心技术与工作原理
Whisper 的强大能力源于其独特的技术设计,主要包括以下几点:
- 端到端的 Transformer 架构:Whisper 采用编码器-解码器的 Transformer 模型架构 。输入音频被分割成30秒的片段并转换为对数 梅尔频谱图,然后由编码器提取特征,解码器根据这些特征预测对应的文本 。
- 大规模多任务训练:模型在从互联网收集的、高达68万小时的多语言(支持近百种语言)和多任务监督数据上进行训练,数据集的巨大规模和多样性是其强大泛化能力的基础 。训练时,模型会交替执行多项任务,如多语言语音转录、语音翻译(到英语)、语言识别以及生成带短语级时间戳的文本等 。
- 统一的多任务格式:通过引入特殊的标记,Whisper 使用一个统一的模型来处理所有任务。这些标记指示模型当前需要执行的具体任务,这种设计使得单个模型能够替代传统语音处理流程中的多个阶段 。
模型规格与选择
Whisper 提供了多种规模的模型,以适应不同场景下对速度和精度的权衡需求 。下面的表格整理了可用的模型及其大致参数,你可以根据实际需求(如对准确率的要求、可用的计算资源)进行选择。
| 模型名称 | 参数量 | 磁盘空间 | 适用场景 |
|---|---|---|---|
| tiny | 约 39 M | ~75 MB | 快速演示,对资源极度敏感 |
| base | 约 74 M | ~140 MB | 平衡速度与基本准确率 |
| small | 约 244 M | ~480 MB | 良好准确率与速度的折中 |
| medium | 约 769 M | ~1.5 GB | 追求较高准确率 |
| large | 约 1550 M | ~3 GB | 最高准确率,支持所有任务 |
主要应用场景
凭借其高准确率和多语言支持,Whisper 可应用于多种场景:
- 会议记录与转录:自动生成会议纪要,将音频内容转换为可编辑的文本,提高效率 。
- 视频字幕生成:为视频内容自动生成字幕,提升内容的可访问性和传播效果 。
- 多语言翻译与转录:支持将多种语言的语音直接转录或翻译成英语文本,便于跨语言沟通 。
- 语音助手与智能客服:作为语音接口的核心,提升语音助手对指令理解的准确性 。
- 无障碍技术:通过实时语音转文本服务,为听障人士提供沟通便利 。
如何使用 Whisper
Whisper 的使用非常灵活,主要有以下几种方式:
- 命令行直接使用:安装后,可通过简单的命令处理音频文件,例如
whisper audio.wav --model small --language Chinese。 - 在 Python 代码中调用:在 Python 项目中集成语音识别功能通常只需几行代码,非常方便 。
- 通过 API 调用:OpenAI 也提供了 Whisper 的 API 接口,适合不希望本地部署的云端应用 。
总结与优势
总而言之,Whisper 的核心优势可以概括为三点:
- 高鲁棒性:得益于海量多样的训练数据,在嘈杂环境、口音等方面表现出色 。
- 多功能性:一个模型支持转录、翻译、时间戳等多种任务,覆盖近百种语言 。
- 开放与便捷:完全开源,支持本地部署以保护数据隐私,并提供从命令行到 API 的多种易用接口 。
本地部署
-
Docker 配置
FROM nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 # 设置工作目录 WORKDIR /app RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list && \ sed -i 's/security.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list # 安装系统依赖 RUN apt-get update && apt-get install -y \ ffmpeg \ python3 \ python3-pip \ python3-venv \ && rm -rf /var/lib/apt/lists/* \ && ln -sf /usr/bin/python3 /usr/bin/python # 复制依赖文件 COPY requirements.txt . # 安装Python依赖 RUN pip install --no-cache-dir -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ # 复制应用代码 COPY whisper_gradio.py . # 暴露Gradio默认端口 EXPOSE 7862 # 设置环境变量:禁用Gradio分析,缓存模型 ENV GRADIO_ANALYTICS_ENABLED=False ENV WHISPER_MODEL_CACHE=/root/.cache/whisper # 启动应用 CMD ["python", "whisper_gradio.py"]# docker-compose.yml services: whisper-app: build: . ports: - "29999:7862" volumes: # 可选:持久化缓存模型,避免每次重启下载 - ./cache:/root/.cache/whisper environment: - GRADIO_SERVER_NAME=0.0.0.0 - GRADIO_SERVER_PORT=7862 restart: unless-stopped# requirements.txt torch openai-whisper gradio ffmpeg-python pydub scipy librosa numpy soundfile fastapi uvicorn python-multipart -
Gradio 服务
# whisper_gradio.py import gradio as gr import whisper import tempfile import os import numpy as np from scipy import signal import librosa # 初始化全局变量 model = None def load_whisper_model(): global model if model is None: model = whisper.load_model("medium") return model def preprocess_audio(audio_path): """ 音频预处理:重采样、降噪、标准化 """ try: # 加载音频 y, sr = librosa.load(audio_path, sr=16000) # 重采样到16kHz # 应用高通滤波器去除低频噪声 b, a = signal.butter(4, 100, 'highpass', fs=sr) y = signal.filtfilt(b, a, y) # 音频标准化 y = y / np.max(np.abs(y)) # 保存处理后的临时文件 temp_path = tempfile.mktemp(suffix='.wav') librosa.output.write_wav(temp_path, y, sr) return temp_path except Exception as e: print(f"音频预处理失败: {str(e)}") return audio_path # 如果预处理失败,返回原始文件 def transcribe_audio(audio_file): """ 转录音频文件为文本,使用优化参数 """ # 加载模型 model = load_whisper_model() # 安全检查上传的文件 if audio_file is None: return "错误:请上传一个音频文件。" try: # 音频预处理 processed_audio = preprocess_audio(audio_file) # 使用优化的转录参数 result = model.transcribe( processed_audio, language="zh", # 指定中文语言 task="transcribe", beam_size=5, # 增加束搜索大小以提高准确性 best_of=5, # 生成多个候选结果选择最佳 temperature=0.0, # 使用确定性输出 patience=1.0, # 束搜索耐心参数 suppress_tokens=[-1] # 抑制不必要的token ) # 清理临时文件 if processed_audio != audio_file: try: os.unlink(processed_audio) except: pass return result["text"] except Exception as e: return f"转录过程中出现错误:{str(e)}" # 创建Gradio界面 with gr.Blocks(title="Whisper音频转录") as demo: gr.Markdown("# 🎤 Whisper音频转录") gr.Markdown("上传MP3、WAV、OGG等音频文件,使用优化的参数将其转换为文本") with gr.Row(): with gr.Column(): audio_input = gr.Audio( sources=["upload"], type="filepath", label="上传音频文件", interactive=True ) submit_btn = gr.Button("开始转录", variant="primary") with gr.Column(): text_output = gr.Textbox( label="转录结果", placeholder="转录文本将显示在这里...", lines=10, max_lines=15 ) # 处理提交动作 submit_btn.click( fn=transcribe_audio, inputs=audio_input, outputs=text_output ) # 附加说明 gr.Markdown(""" ### 使用说明 1. 点击"上传音频文件"或拖放文件到上传区域 2. 支持格式:MP3, WAV, OGG, M4A, FLAC等 3. 点击"开始转录"按钮 4. 等待转录结果出现在右侧文本框中 **注意**:首次使用需要下载Whisper Large模型,请耐心等待。转录过程可能需要较长时间。 """) if __name__ == "__main__": demo.launch( server_name="0.0.0.0", server_port=7862, share=False ) -
运行效果:使用 small 模型以及使用精确的转录参数;整体识别还可以,但依旧有很多同韵母的字和同音字会识别错误;使用 medium 模型会出现一个奇怪的问题,转录文字为繁体字;large 模型运行时间较长(3060 显卡)
-

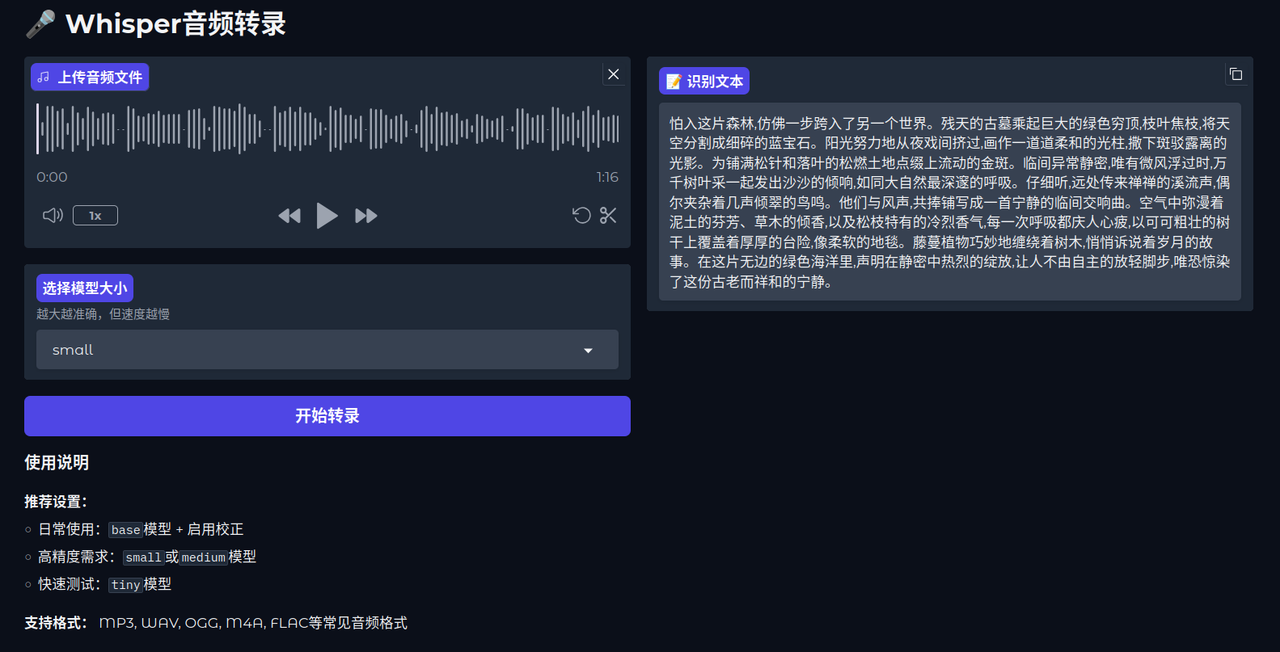
-
优化:音频预处理、优化转录参数、阶段处理
- 结果也大差不差,最终生成的文本或多或少都有点问题,还是直接交给大模型根据语义做修正并分析吧
-
转 FastAPI 服务
-
更新配置:
- 增加 fastapi、uvicorn、python-multipart 依赖
- 修改 Dockerfile 程序挂载
- 修改 docker-compose.yml 端口映射
# whisper_fastapi.py from fastapi import FastAPI, File, UploadFile, HTTPException from fastapi.responses import JSONResponse import whisper import tempfile import os import numpy as np from scipy import signal import librosa import uvicorn import soundfile as sf # 初始化FastAPI应用 app = FastAPI( title="Whisper音频转录API", description="基于OpenAI Whisper的高级音频转录服务", version="1.0.0" ) # 初始化全局变量 model = None def load_whisper_model(): global model if model is None: model = whisper.load_model("large") return model def preprocess_audio(audio_path): """ 音频预处理:重采样、降噪、标准化 """ try: # 加载音频 y, sr = librosa.load(audio_path, sr=16000) # 重采样到16kHz # 应用高通滤波器去除低频噪声 b, a = signal.butter(4, 100, 'highpass', fs=sr) y = signal.filtfilt(b, a, y) # 音频标准化 y = y / np.max(np.abs(y)) # 保存处理后的临时文件 temp_path = tempfile.mktemp(suffix='.wav') sf.write(temp_path, y, sr) return temp_path except Exception as e: print(f"音频预处理失败: {str(e)}") return audio_path # 如果预处理失败,返回原始文件 @app.on_event("startup") async def startup_event(): """应用启动时加载模型""" print("正在加载Whisper模型...") load_whisper_model() print("Whisper模型加载完成!") @app.post("/transcribe", summary="音频转录", description="上传音频文件并返回转录文本") async def transcribe_audio(file: UploadFile = File(...)): """ 转录音频文件为文本,使用优化参数 - **file**:音频文件,支持MP3、WAV、OGG、M4A、FLAC等格式 """ # 更灵活的文件类型检查 valid_extensions = {'.mp3', '.wav', '.ogg', '.m4a', '.flac', '.aac', '.m4b'} file_extension = os.path.splitext(file.filename)[1].lower() if file_extension not in valid_extensions: raise HTTPException( status_code=400, detail=f"不支持的文件类型: {file_extension}。请上传音频文件: {valid_extensions}" ) temp_path = None processed_audio = None try: # 保存上传文件到临时位置 with tempfile.NamedTemporaryFile( delete=False, suffix=file_extension ) as temp_file: content = await file.read() temp_file.write(content) temp_path = temp_file.name # 音频预处理 processed_audio = preprocess_audio(temp_path) # 加载模型 model = load_whisper_model() # 使用优化的转录参数 result = model.transcribe( processed_audio, language="zh", # 指定中文语言 task="transcribe", beam_size=5, # 增加束搜索大小以提高准确性 best_of=5, # 生成多个候选结果选择最佳 temperature=0.0, # 使用确定性输出 patience=1.0, # 束搜索耐心参数 suppress_tokens=[-1] # 抑制不必要的token ) # 返回转录结果 return JSONResponse(content={ "status": "success", "text": result["text"], "language": result.get("language", "zh"), "file_name": file.filename }) except Exception as e: raise HTTPException(status_code=500, detail=f"转录过程中出现错误: {str(e)}") finally: # 清理临时文件 if temp_path and os.path.exists(temp_path): os.unlink(temp_path) if processed_audio and processed_audio != temp_path and os.path.exists(processed_audio): os.unlink(processed_audio) @app.get("/health", summary="健康检查", description="检查服务是否正常运行") async def health_check(): """健康检查端点""" return JSONResponse(content={ "status": "healthy", "model_loaded": model is not None }) @app.get("/", summary="根端点", description="API基本信息") async def root(): """根端点,返回API基本信息""" return { "message": "Whisper音频转录API服务", "version": "1.0.0", "endpoints": { "transcribe": "/transcribe (POST)", "health": "/health (GET)", "docs": "/docs (GET)", "redoc": "/redoc (GET)" }, "model": "large", "supported_languages": "近百种语言,支持中文转录" } if __name__ == "__main__": uvicorn.run( app, host="0.0.0.0", port=7862 )FROM nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 # 设置工作目录 WORKDIR /app RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list && \ sed -i 's/security.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list # 安装系统依赖 RUN apt-get update && apt-get install -y \ ffmpeg \ python3 \ python3-pip \ python3-venv \ && rm -rf /var/lib/apt/lists/* \ && ln -sf /usr/bin/python3 /usr/bin/python # 复制依赖文件 COPY requirements.txt . # 安装Python依赖 RUN pip install --no-cache-dir -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ # 复制应用代码(修改为 FastAPI 文件) COPY whisper_fastapi.py . # 暴露 FastAPI 端口 EXPOSE 7862 # 设置环境变量:模型缓存路径 ENV WHISPER_MODEL_CACHE=/root/.cache/whisper # 启动应用(修改为 FastAPI 启动命令) CMD ["uvicorn", "whisper_fastapi:app", "--host", "0.0.0.0", "--port", "7862"]# docker-compose.yml services: whisper-api: build: . container_name: whisper-fastapi ports: - "7862:7862" volumes: # 持久化缓存模型 - ./model_cache:/root/.cache/whisper # 可选:挂载音频文件目录 - ./audio_files:/app/audio_files environment: - WHISPER_MODEL=medium restart: unless-stopped # 可选:设置资源限制 deploy: resources: reservations: devices: - driver: nvidia count: 2 capabilities: [gpu] -
测试语句:
curl -X POST "http://localhost:7862/transcribe" -F "file=@test.wav"
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)