语言模型的发展历程——DataWhale 大语言模型Task01
语言模型(Language Model)通常是指能够建模自然语言文本生成概率的模型。该篇文章简要介绍了统计语言模型,神经语言模型,预训练语言模型和大语言模型。
什么是语言模型
语言模型(Language Model)通常是指能够建模自然语言文本生成概率的模型。
顺便在这里补充下一些我们常说的一些模型的简称所代表的含义
| 简称 | 全称 | 含义 |
|---|---|---|
| LM | Language Model | 语言模型 |
| LLM | Large Language Model | 大语言模型 |
| vLLM | very Large Language Model | 超大语言模型 |
| VLM | Version Language Model | 视觉语言模型 |
| LMM | Large Multimodal Model | 多模态大模型 |
不妨给本文章点个收藏,当你在其他地方看到不懂的简称,欢迎回来查阅或者提醒博主补充。
回到正题,语言模型按照发展阶段可以以下四个阶段
- 1990-2012年:统计语言模型,比如n-gram统计模型
- 2013-2017年:神经语言模型,比如RNN-LM, word2vec
- 2018-2021年:预训练语言模型,比如ELMo, BERT, GPT-1/2
- 2022-至今:大语言模型,比如GPT3/4, chatGPT, Claude
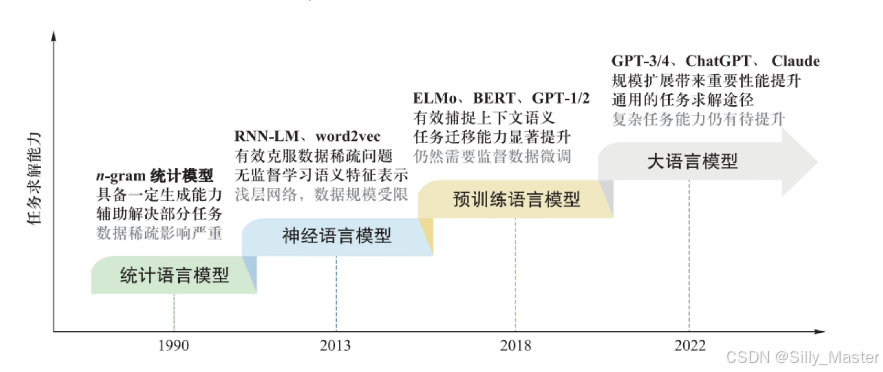
这四类模型的简称分别如下
| 简称 | 全称 | 含义 |
|---|---|---|
| SLM | Statistical Language Model | 统计语言模型 |
| NLM | Neural Large Language Model | 神经语言模型 |
| PLM | Pre-trained Language Model | 预训练语言模型 |
| LLM | Large Language Model | 大语言模型 |
接下来将分段讲解每个阶段的模型。
统计语言模型(SLM)
这个时期的模型主要是建立在统计学习的理论框架下,通常使用链式法则建模句子序列,例如对于我爱你这个句子的概率可以转化为如下公式计算, S T A R T START START代表句子开始标志,默认 p ( S T A R T ) = 1 p(START)=1 p(START)=1
p ( 我 , 爱 , 你 ) = p ( S T A R T ) ∗ p ( 我 ∣ S T R A T ) ∗ p ( 爱 ∣ 我 ) ∗ p ( 你 ∣ 我爱 ) p(我,爱,你) =p(START) * p(我|STRAT) * p(爱|我) * p(你| 我爱) p(我,爱,你)=p(START)∗p(我∣STRAT)∗p(爱∣我)∗p(你∣我爱)
上述公式看不懂的同学可以去温习一下概率论的条件概率公式
对于统计语言模型中典型的n-gram语言模型,其基于马尔可夫假设,当前词概率仅仅与前n-1个词有关,可以用如下的公式表示
p ( s ) = p ( w 1 ) p ( w 2 ∣ w 1 ) . . . p ( w m ∣ w m − n + 1 , . . . . , w m − 1 ) = Π i = 1 m p ( w i ∣ w i − n + 1 , . . . . , w i − 1 ) \begin{equation} \begin{aligned} p(s) &= p(w_1)p(w_2 | w_1)...p(w_m|w_{m-n+1}, ...., w_{m-1}) \\ &=\varPi_{i=1}^m p(w_i|w_{i-n+1}, ...., w_{i-1}) \end{aligned} \end{equation} p(s)=p(w1)p(w2∣w1)...p(wm∣wm−n+1,....,wm−1)=Πi=1mp(wi∣wi−n+1,....,wi−1)
对于概率一种常见的思路是用频率来近似为概率,也称为最大似然估计,下面举一个四元语言的模型估计的例子
P ( ω ∣ s t u d e n t s o p e n e d t h e i r ) = c o u n t ( s t u d e n t s o p e n e d t h e i r ω ) c o u n t ( s t u d e n t s o p e n e d t h e i r ) P(\omega|students\ opened\ their) = \frac{count(students\ opened\ their\ \omega)}{count(students\ opened\ their)} P(ω∣students opened their)=count(students opened their)count(students opened their ω)
假设"students opened their"出现了1000次,“students opened their books” 出现了400次
则 P ( b o o k s ∣ s t u d e n t s o p e n e d t h e i r ) = 0.4 P(books|students\ opened\ their)=0.4 P(books∣students opened their)=0.4
"students opened their exams"出现了100次则
P ( e x a m s ∣ s t u d e n t s o p e n e d t h e i r ) = 0.1 P(exams|students\ opened their)=0.1 P(exams∣students openedtheir)=0.1
使用最大似然估计存在的问题主要是计算概率时分子和分母均有可能出现为0的情况,相应的策略是当分子为0时采用平滑(Smootrhing)策略,即对未出现的单词或者短语分配很小的概率或者权重。当分母为0时,采用回退(Back-off)策略考虑去掉一个单词,考虑更短的子串。
神经语言模型(NLM)
- 早期工作(MLP)将单词映射到词向量,再由神经网络预测当前词汇
- 使用循环神经网络(RNN)进行预测
- Word2Vec
这里面值得一提是Word2Vec模型,这是自然语言处理领域深度学习时代最重要的工作之一。它的基本功能是,对于给定的文本数据,对于每个单词学习一个低维度的表述。并且其基于分布式语义的思想进行设计。但是也不再考虑窗口内单词的语义。充分考虑了实践和效果,具有速度快,效果稳定的特点。
预训练语言模型(PLM)
2017年Transformer模型出现后,由Google和OpenAI的两派分别发布了自己的代表作模型,分别是Google发布的以Encoder-Only架构为代表的自编码语言模型BERT系列,和OpenAI发布的Decoder-Only架构自回归语言模型GPT系列。
这些模型通过在大量的语料进行无监督预训练后,其可以在特定的下游任务或领域上微调取得较好的效果。
具体Transformer架构和这两个模型的架构后面再讲解这里先贴两张图
大语言模型(LLM)
上述三种所说的传统语言模型均存在局限性,需要使用特殊的技术进行模型能力的提升,具体来说有以下几点缺陷
- 缺乏背景知识(需要知识图谱等外部知识源补充)
- 任务泛化性差(需要针对特定任务进行微调,适配成本搞)
- 复杂推理能力较弱(通常需要对于结构进行修改,或者进行大规模微调)
尽管早期研究工作较多,但是没有工作能够通过统一途径同时解决上述代表性挑战。
而大语言模型的到来则解决了上述提到的问题,其极大的扩展了模型参数和数据数量,并且需要更为复杂、经济的模型训练方法。
大语言模型是指在海量无标注文本数据预训练得到的大型预训练语言模型,通常指参数规模达到百亿、千亿甚至万亿的模型。经过大规模数据预训练的数十亿参数的高性能模型也可以成为大语言模型。
对于大语言模型有以下几点需要注意
- 模型参数规模具备一定的规模非常重要,已经有研究表明存在一些任务只有达到一定参数的模型才可以解决,
- 模型需要能够学习更多的数据和知识。无论是大语言模型还是深度学习,机器学习等等。数据都是其中起非常重要作用的一环。有一句非常经典的话叫“garbage in garbage out”,如果你给模型输入的都是一些低质量的数据,那么模型输出的也只能是低质量的结果,

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)