动手学深度学习 PyTorch版15实战 Kaggle房价预测学习笔记
此文作为本人的学习笔记,将李老师上课所讲的代码进行展示和详细注释,能帮助到和我一样的初学者更好。
一,准备数据集
1.可以使用李老师的方法调用download函数,将数据集放在本地并返回函数名。
2.直接下载数据集到本地,在评论区有网友分享的百度网盘,直接下载即可(一定要知道自己下载路径,后面需要该文件位置)
准备好之后就打开jupyter notebook写代码,首先导入我们要用到的库。
%matplotlib inline # 用于在Notebook中内嵌显示Matplotlib绘制的图形
import numpy as np # 提供了高效的多维数组操作功能如数组创建与运算
import pandas as pd # 提供了高效的数据结构如数据读取、数据清洗、数据操作
import torch # Pytorch核心包,提供了张量(Tensor)操作、自动求导、神经网络构建等功能
from torch import nn # nn是PyTorch中用于构建神经网络的模块
from d2l import torch as d2l #封装了许多工具函数如数据加载、可视化、训练工具注意:没有下载torch、numpy、pandas、d2l包的话,torch下载较为麻烦可以参考其他博客(推荐b站小土堆),而后三个包可以利用pip命令在jupyter或终端中下载,需要注意numpy和pandas的版本是否匹配(这两是最常用的数据处理库,版本不协调可能会报错)
我下载包最常用的方法就是打开Anaconda Prompt激活自己的环境后,利用pip命令下载任何需要的包:(使用清华镜像能加速)
pip install 包名==版本号 -i https://pypi.tuna.tsinghua.edu.cn/simple之后导入下载好的数据集:
train_data = pd.read_csv('D:\\Python\\pytorchdata\\train.csv')
test_data = pd.read_csv('D:\\Python\\pytorchdata\\test.csv')注意:绿色部分每个人的不一样,一定要写对你自己把数据集下载到哪的路径。
print(train_data.shape) # 获取数据的形状(维度信息)
print(test_data.shape)
print(train_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])
print(test_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])利用前两行代码我们可以看到他们具体是几行几列的数据集,后两句是分别提取出第一行到第四行,第一列到第四列还有最后三列的数据:
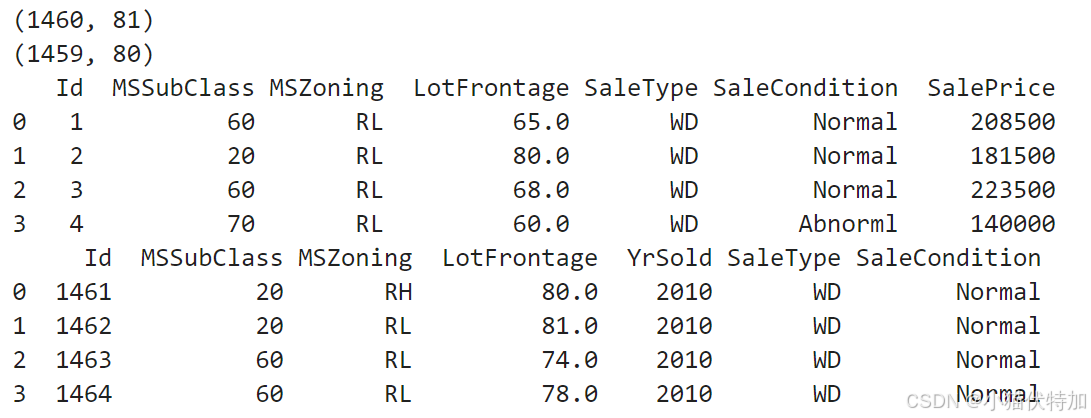
以后可以用这种方法快速查看到数据集的部分数据。
二、处理数据
数据集 中并不是每一行或列我们都需要,也不是每个数据都正确,也可能缺失数据,因此,处理数据是必不可少的步骤。
all_features = pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]),axis=0)
测试数据集和训练数据集的第一列都是ID,在这里并不需要因此拿掉。
这里"[:,1:-1]"意思是选中训练数据集的所有行,以及第二列到倒数第二列;"[:,1:]"意思是选中所有行和第二列以及之后的所有列。因为我们在打印数据集形状时发现训练数据集比测试数据集多了一列,所以不要最后一列了。(关于数据集的操作可以看课程第04讲数据操作+数据预处理)
pd.concat是合并这两个数据集,然后保存在all_features中。
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].fillna(0)第一句:如果有的数据类型不是object(即非数值型,如字符串)的话,放在numeric_features中,这样我们就可以区分哪些是数值哪些是文本。
第二句:如果是数值特征的话,我们就把它“减去这一列的均值再除以这一列的标准差”(学过应用数理统计的话,知道这是在标准化,为了服从均值为0方差为1的标准正太分布)
第三句:将数值型特征中的缺失值(NaN)填充为 0,这一步是为了确保数据集中没有缺失值,避免后续模型训练时出现问题。
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shapepd.get_dummies(...)是Pandas提供的一个函数,用于将分类变量转换为独热编码形式。
对于非数值类型的数据(字符串),用独热代码替换他们。(关于独热代码在前面04节讲过)
我对独热编码的理解是:用二进制0、1代表是或者不是该特征值。
打印出(2919,331) 之前我们做过合并,所以行变多了,而列也就是特征值经过处理后也变多了。
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values,
dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values,
dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1),
dtype=torch.float32)第一句:shape[0] 指向了数据结构的第一维尺寸——也就是行数的信息,因此用于获取数据集的行数。
第二句:torch.tensor函数将数据转换为PyTorch 的张量对象(也就是多维数组)
提取all_features中前 n_train 条记录对应的数值部分并将datatype设置为浮点数32位(python默认的是64位,32位是深度学习模型中常用的数据类型)使用这些数值初始化一个新的 PyTorch 张量;第三句同理。
第四句:将 train_data 数据集中的 SalePrice 列转换为张量并设置datatype为32位浮点数。
.reshape(-1, 1)表示 将NumPy数组的形状从一维数组([n,])转换为二维数组([n, 1]),其中n是样本数量。-1表示自动计算该维度的大小,1表示每行只有一个值。
三、训练数据
这里使用的是简单的线性模型做训练。
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return netnn.MSELoss() 是 PyTorch 中用于计算预测值和真实值之间均方误差的损失函数。
第二句获取输入特征的数量,也就是331.
接下来,定义一个函数get_net用于创建一个简单的神经网络模型,使用的是 PyTorch 的 nn.Sequential 容器。nn.Linear(in_features, 1) 表示一个线性层,输入大小为 in_features,输出大小为1。(线性层的作用是将输入特征映射到一个输出值,通常用于回归问题。)
def log_rmse(net, features, labels):
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse.item()这里定义一个log_rmse函数用于计算预测值和真实标签之间的对数均方根误差(Log RMSE),这是一种常用的回归问题的评估指标,适用于预测值范围较大的情况。
第一句:利用net模型对输入的features进行预测,返回预测值clipped_preds.并将预测值限制在[1, +∞) 的范围内,避免对数值计算时出现负数或零。
第二句:计算rmse,将预测值和真实标签值分别取对数,利用loss(...)计算对数预测值和对数标签之间的损失。torch.sqrt(...):对均方误差取平方根,得到均方根误差(RMSE)。
第三句:rmse.item()返回rmse值。
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad() # 清空模型参数的梯度
l = loss(net(X), y) # 计算模型预测值和真实标签之间的损失
l.backward() # 反向传播,计算损失对模型参数的梯度
optimizer.step() # 更新模型参数
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls这一整段是训练模型的核心代码,train函数需要定义(训练的神经网络模型net,训练集的特征数据和标签数据,测试集的特征数据和标签数据,训练的轮数num_epochs,控制优化器更新参数的步长的学习率learning_rate,用于防止过拟合的正则化系数weight_decay,每次迭代使用的批量大小batch_size)
train_ls, test_ls 用于存储每一轮训练后的训练集/测试集 Log RMSE。
使用d2l.load_array将训练数据 (train_features, train_labels) 按 batch_size 分批次加载,返回一个可迭代的数据加载器 train_iter。
这里使用 Adam 优化算法来更新模型参数,需定义(获取模型的所有可训练参数、设置学习率、设置权重衰减)
接下来,开始训练循环:
外层循环:遍历每一轮训练(num_epochs次)
内层循环:遍历每一个批次的数据 (x是特征,y是标签)
当每一轮训练结束后,计算训练集的 Log RMSE,并将其添加到 train_ls 中。如果提供了测试集数据,则计算测试集的 Log RMSE,并将其添加到 test_ls 中。
# K折交叉验证
def get_k_fold_data(k, i, X, y):
assert k > 1 # 确保折数k大于1,否则无法进行交叉验证
fold_size = X.shape[0] // k # 每折的样本数=总样本数/折数k
X_train, y_train = None, None # 用于存储训练集的特征和标签
for j in range(k): #j是当前折的索引
idx = slice(j * fold_size, (j + 1) * fold_size) #当前折的切片范围,通过slice函数生成
X_part, y_part = X[idx, :], y[idx] # 当前折的特征和标签
if j == i: #如果当前折j等于验证集的索引i,则将当前折作为验证集。
X_valid, y_valid = X_part, y_part
elif X_train is None: #如果X_train为None,则直接赋值。
X_train, y_train = X_part, y_part
else: # 否则,使用torch.cat将当前折的数据与已有的训练集拼接。
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid # 返回划分后的训练集和验证集。这段代码定义了get_k_fold_data 的函数是为了实现 K折交叉验证,其中k表示折数,将数据集分成多少份,i表示第i个子集作为验证集,x表示特征数据,y表示标签数据。
部分行的含义如代码注释所示。总之很绕。😭
# 返回训练和验证误差的平均值
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0 # 用于累加所有折的训练集/验证集的Log RMSE。
for i in range(k): # 循环遍历每一折,i是当前折的索引
data = get_k_fold_data(k, i, X_train, y_train) # 获取当前折的训练集和验证集
net = get_net() # 初始化一个神经网络模型
#调用train函数,训练模型并返回训练集和验证集的Log RMSE列表。
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1] # 将当前折的训练集和验证集的最终Log RMSE值累加
valid_l_sum += valid_ls[-1]
if i == 0: # 绘制训练集和验证集的Log RMSE随训练轮数的变化曲线
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
# 打印当前折的训练集和验证集的最终Log RMSE值。
print(f'fold{i + 1}, train log rmse {float(train_ls[-1]):f}, '
f'valid log rmse {float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
# 返回所有折的训练集和验证集的平均Log RMSE值这段主要是利用前面定义的train函数,训练模型并返回打印出训练集和验证集的Log RMSE列表,并绘制训练集和验证集的Log RMSE随训练轮数的变化曲线。
具体解释如代码注释所示。
四、测试
# 测试
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')这些超参数可以自己设置不同情况看是否能得出最好的结果,这里就表示
使用5折交叉验证,每折训练100轮,学习率为5, 权重衰减(L2 正则化系数)为0,即不使用正则化,每次迭代使用的批量大小为64。
调用k_fold函数,对模型进行训练和验证,返回训练集和验证集的平均Log RMSE,打印结果。
结果:
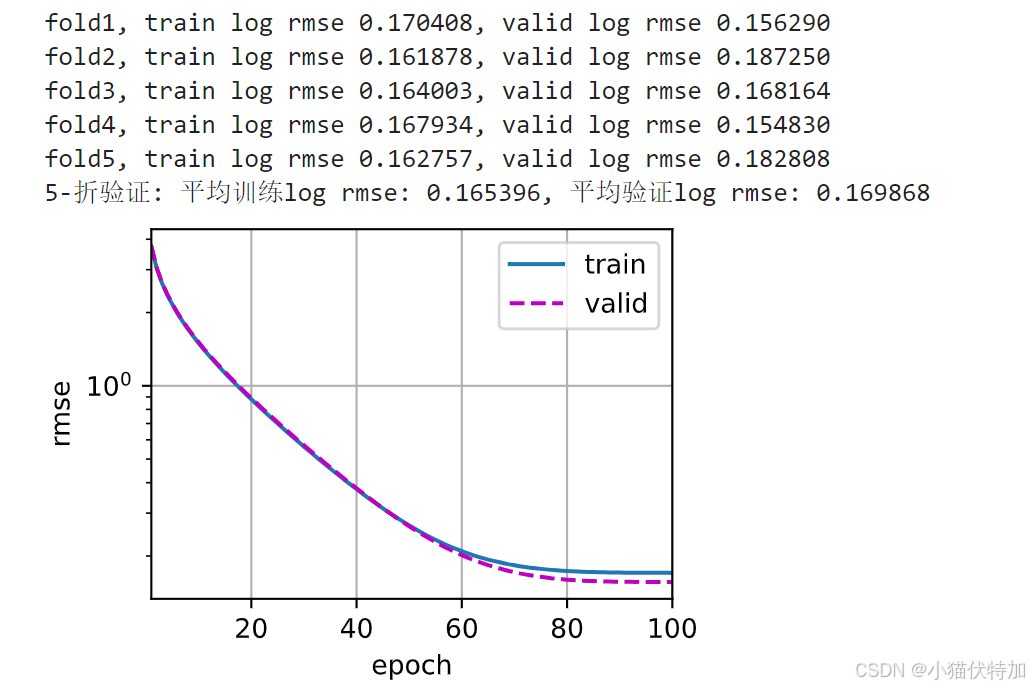
最后注重的是平均验证log rmse的值,不断调换超参数,看哪次最小,把最好的超参数留下。
五、总结
以上就是对学习李沐房价预测的笔记,若哪里不对还望指出,谢谢。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)