【动手学深度学习v2】李沐课程19-22卷积神经网络总结
CNN(卷积神经网络)是深度学习领域中一种非常重要的算法,此文作为李沐《动手学深度学习v2》19-22课的学习笔记,先初步认识和接触卷积的概念,了解卷积层中各重要参数含义及具体代码实现和注释。
一、从全连接到卷积(课程19)
先举猫狗的例子表示:使用单层的神经网络需要极大的内存,多层更不用说。
再举图片中找人的例子引出两个重要原则:
1. 平移不变性:无论目标在图像中的位置如何变化,CNN都能识别出它,不会因图片像素的改变而改变;
2. 局部性:卷积操作只关注图像的局部区域,而不是整张图像。比如找一个猫,我们不需要这张图片的全部信息,耳朵尾巴等局部信息足以识别出猫。
对于全连接层到卷积层相关计算式的变换在这里不做展示,本文注重代码理解。
总之,对全连接层使用平移不变性和局部性就可以得到我们的卷积层。(卷积就是特殊的全连接层)
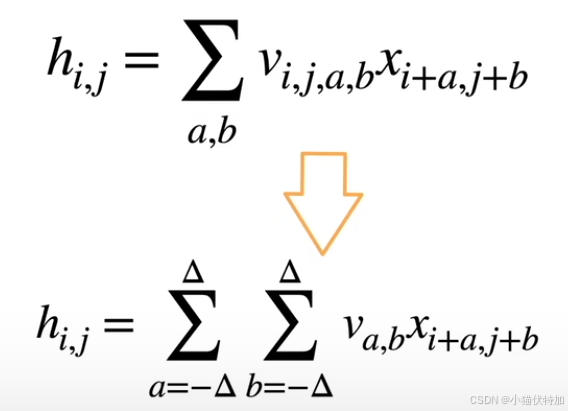
二、卷积层
二维卷积是卷积神经网络中的核心操作,那么二维卷积如何实现?
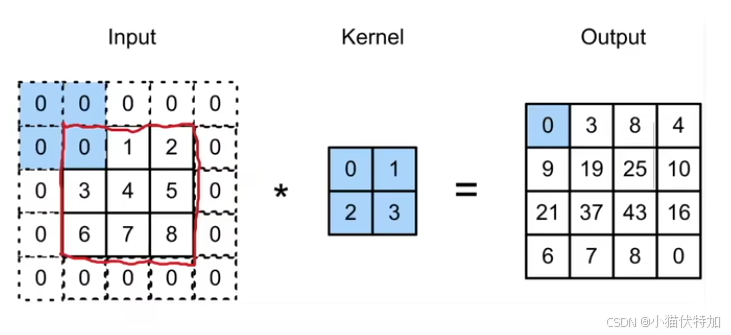
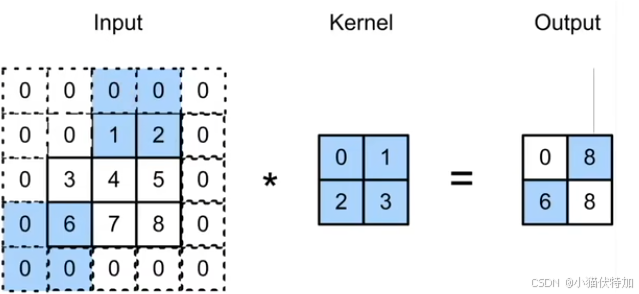
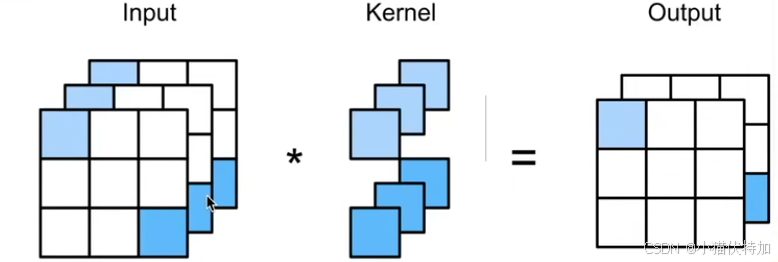
用文字描述的话:二维卷积通过卷积核在输入图像上滑动,计算局部区域的加权和,提取特征并生成特征图。以下这副动图是最好的演示(这里是4*4矩阵通过2*2卷积核生成3*3矩阵,与课件不同但原理一模一样。)
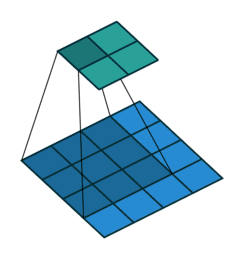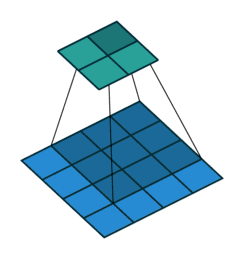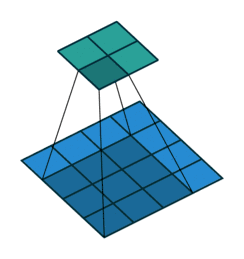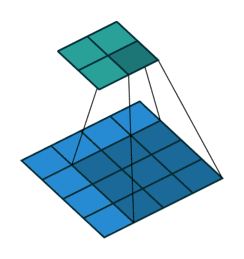
李沐课程展示了计算过程:假设输入为3*3的矩阵,卷积核Kernel为2*2矩阵(核矩阵固定不改变,就是平移不变性),输出是一个2*2的矩阵,就是局部性的体现。
这里直接使用第三小节的代码实现该“二维互相关运算”。
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(x, K): # x是输入、K是核矩阵
"""计算二维互相关运算"""
h, w = K.shape # 行数和列数(高、宽)
Y = torch.zeros((x.shape[0] - h + 1, x.shape[1] - w + 1))
# 输出高度=输入高度-核的高度+1;输出宽度=输入宽度-核的宽度+1
for i in range(Y.shape[0]): # 遍历
for j in range(Y.shape[1]):
# 拿出小区域"从i行开始往后h行;从j列开始往后w列"
Y[i, j] = (x[i:i + h, j:j + w] * K).sum() # 小方块和核矩阵做点积再求和
return Y输入数据展示计算结果:
# 验证上述二维互相关运算的输出
x = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) # 输入3*3矩阵
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) # 核矩阵是2*2矩阵
print(corr2d(X, K)) #做运算结果为:tensor([[19., 25.],
[37., 43.]]) 与课件上的例子一致。
之后提出,CNN也可以输入一维(文本、语言、时序序列)也可以是三维(视频、医学图像、气象地图)后面有课程会展示具体实现。
总结:1. 卷积层将输入和核矩阵进行交叉相关,加上偏移后得到输出。
2. 核矩阵和偏移是可学习的参数。(可通过训练不断确定最佳值)
3. 核矩阵的大小是超参数(超参数是机器学习模型训练前需要设置的参数,它们控制模型的结构和训练过程。选择合适的超参数对模型性能至关重要,通常需要通过实验和调优方法来确定最佳值。)
紧接着上面的代码,我们继续来实现二维卷积层。
class Conv2D(nn.Module): # 定义了一个名为 Conv2D 的类,继承自nn.Module
def __init__(self, kernel_size): # __init__ 是类的构造函数,用于初始化卷积层的参数
super().__init__() # 调用父类 nn.Module 的构造函数,确保正确初始化
self.weight = nn.Parameter(torch.rand(kernel_size))
# 定义卷积核的权重参数,使用 nn.Parameter 将其包装为可训练参数
self.bias = nn.Parameter(torch.zeros(1)) # 定义偏置参数,初始化为 0
def forward(self, x):# 定义前向运算
return corr2d(x, self.weight) + self.bias
# 用 x 和 weight 做互相关运算再加上偏移代码注释包含了每句代码的含义及功能,可作为参考。
用定义好的二维卷积层来进行一个简单应用:监测图像中不同颜色的边缘。
x = torch.ones((6, 8)) # 给一个6*8的输入,值均为1
x[:, 2:6] = 0 # 将中间都设为0
x输出:
我们看到,1、0之间有竖线的边缘,要将这两条边缘检测出来。
设置一个卷积核:
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(x, K)
Y思路:假设两个元素之间没有变化则输出0,若变化了则输出1或-1.
输出: 输出y中的1代表从白色到黑色的边缘,-1代表从黑色到白色的边缘,即完成边缘检测。(卷积核K只可以检测垂直边缘)
输出y中的1代表从白色到黑色的边缘,-1代表从黑色到白色的边缘,即完成边缘检测。(卷积核K只可以检测垂直边缘)
接下来,若给定输入x和输出y,学习出那个卷积核(核未知)
# 构造一个二维卷积层 输入输出通道均为 1 卷积核大小为1*2 不适用偏移项
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 将输入 x 和输出 y 调整为适合卷积层的形状,因为我们要加两个维度
# 批量大小和通道数且都为 1 这里使用四维输入
x = x.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率,用于控制权重更新的步长。
for i in range(10): # 迭代 10 轮
Y_hat = conv2d(x) # 前向传播
l = (Y_hat - Y) ** 2 # 计算损失 MSE
conv2d.zero_grad() # 梯度清 0,避免梯度累积
l.sum().backward() # 计算损失l的总和并进行反向传播,计算卷积层权重的梯度。
# 手动更新权重,使用梯度下降法手动更新卷积层的权重
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0: # 每 2 轮打印一次当前轮数和损失值
print(f'epoch {i+1}, loss {l.sum():.3f}')输出:
conv2d.weight.data.reshape((1, 2)) # 输出所学的卷积核的权重张量输出:
![]()
总结:通过构造一个人工数据集,怎么学习卷积层的权重(卷积核),这里使用最简单的定义(输入输出通道都为1,没有做任何的填充,没有设置步幅)
三、填充和步幅(课程20)
填充和步幅是控制卷积层输出大小的两个超参数,分别详细介绍。
1. 填充
举例:给定32x32的输入图像,应用5x5大小的卷积核,用一次卷积得到输出就会减小4*4,用1层得到输出大小28x28,用了7层得到输出大小4x4,因此,更大的卷积核可以更快地减小输出大小,形状从 n×m 减少到 (n-k+1) × (m-k+1)。那么,假设不想让输出变那么小怎么办?这个例子用七次卷积核之后就无法继续卷积,卷积层数受到限制,那如果要做出更深的神经网络怎么办?
所以就要用到填充(在输入周围添加额外的行/列),入下图所示,四周分别填充一行或一列0。
填充之后再做卷积,得到4*4矩阵,若不做填充只能得到2*2矩阵。
如动画所示,为做填充之后的效果。
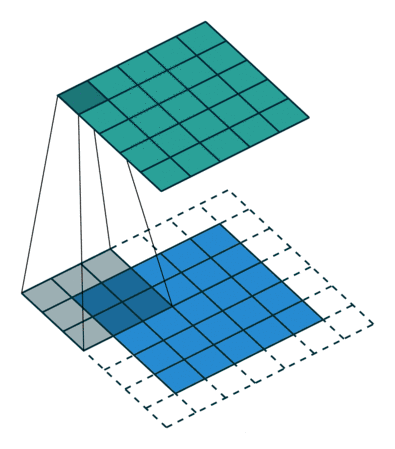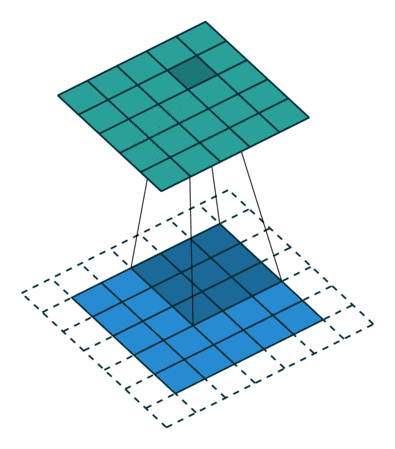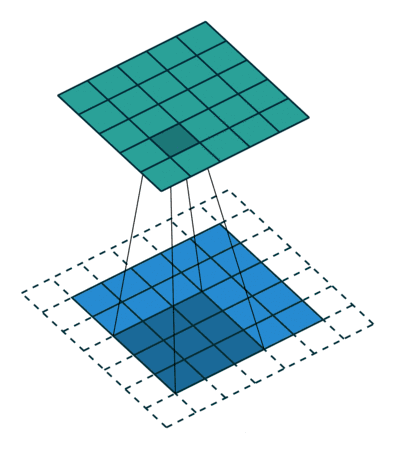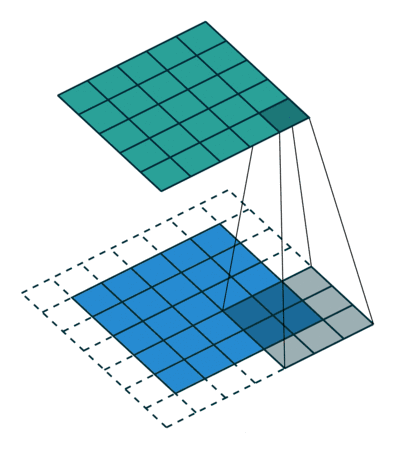

2. 步幅
举例:若给定一个输入大小为224×224,在使用5×5卷积核的情况下,需要55次卷积才能将输入降到4×4,需要大量计算才能得到较小输出。但通常我们不会使用太大的卷积核,那如何减少计算,步幅就是为了解决这个问题。
步幅:指卷积核在输入图像行/列上滑动的步长。例如,步幅为1表示卷积核每次移动1个像素,步幅为2表示每次移动2个像素。
高度3 宽度2 的步幅意思就是,向右移动2格并向下移动3格得到下一个被卷积区域。
 与上一个例子比较,若不做调整输出4×4,调整步幅后生成2×2的矩阵,效果很明显。
与上一个例子比较,若不做调整输出4×4,调整步幅后生成2×2的矩阵,效果很明显。
如动画所示的为步幅=2的情况,如图所示为步幅计算:
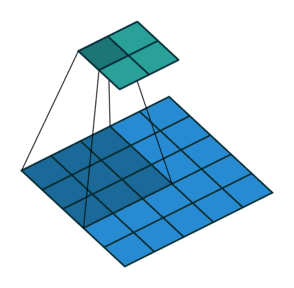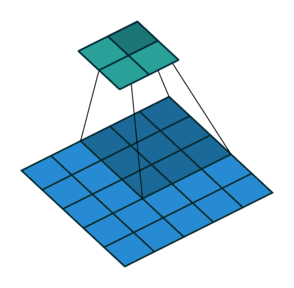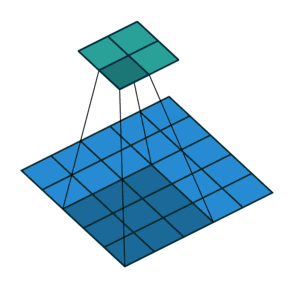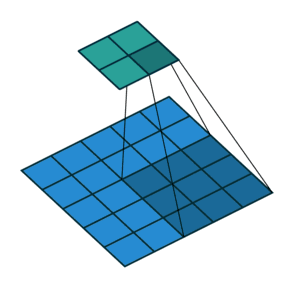

总结:填充和步幅是卷积层的超参数;填充在输入周围添加额外的行/列,来控制输出形状的减少量;步幅是每次滑动核窗口时的行/列的步长,可以成倍的减少输出形状。
代码实现如何使用填充和步幅:
import torch
from torch import nn
# 定义一个计算卷积层的函数
def comp_conv2d(conv2d, X):
X = X.reshape((1, 1) + X.shape) # 将输入张量 x形状调整为批量大小和通道数都为 1
Y = conv2d(X) # 对 X进行卷积操作输出 Y
return Y.reshape(Y.shape[2:]) # 去掉批量大小和通道,只保留空间维度
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
# 创建一个二维卷积,卷积核大小3*3,填充大小为 1,表示在输入张量的边缘填充一圈 0
X = torch.rand(size=(8, 8)) # 创建一个形状为 (8, 8) 的随机张量 X
comp_conv2d(conv2d, X).shape #调用 comp_conv2d 函数对 X 进行卷积操作,并返回结果的形状
输出:![]() 我们发现,填充之后输出尺寸与输入尺寸相同。
我们发现,填充之后输出尺寸与输入尺寸相同。
填充不对称情况:
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
# 卷积核大小5*3,高度和宽度两边分别填充 2和 1
comp_conv2d(conv2d, X).shape # 输出形状结果仍然是 torch.Size( [8, 8] ) 我们可以参考前面的公式进行计算得到该结果。
接下来,我们将高度和宽度的步幅设置为2:
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
# 这里比之前多了stride步幅,设置为 2
comp_conv2d(conv2d, X).shape输出:torch.Size( [4, 4] ),我们能看到输出有明显的减小。
一个较复杂的情况,完全不对称情况:
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3,4))
# 高度不填充,宽度两边填充 1,高度方向的步幅为 3,宽度方向的步幅为 4
comp_conv2d(conv2d, X).shape输出:torch.Size( [2, 2] ),我们同样可以结合公式算出该结果。但通常情况下,我们会使用对称情况,填充一致,步幅一致,因此不用担心遇到这种复杂情况。
四、卷积层里的多输入多输出通道(课程21)
输入和输出通道是在定义卷积层时是重要的超参数,这里分别介绍这两个通道。
1. 多输入通道
输入通道是指输入数据的深度(depth),我们会经常使用彩色图像,而彩色图像具有RGB三个通道,分别对应红、绿、蓝三个通道。而对于灰色图像,输入通道数只有 1。
如下图所示,假设我们有两个通道,那每一个通道都有自己独立的卷积核,那么进行卷积的结果就是所有通道卷积结果的和。
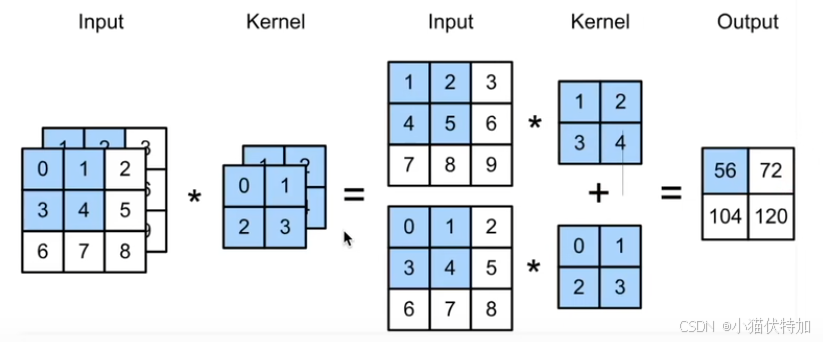
该计算为“多输入通道互相关运算”,其代码如下:
import torch
from d2l import torch as d2l
# 定义该计算
def corr2d_multi_in(X, K):
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
# 使用zip将输入张量 X和卷积核 K按通道配对
# 对每一对(x, k)调用 d2l.corr2d计算单通道的互相关结果
# 将所有通道的互相关结果相加,得到最终的多通道输出
# 验证输出
X = torch.tensor([[[0.0, 1.0, 2.0],[3.0, 4.0, 5.0],[6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0],[4.0, 5.0, 6.0],[7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0],[2.0, 3.0]],[[1.0, 2.0],[3.0, 4.0]]])
corr2d_multi_in(X, K)输出结果为:tensor([[ 56., 72.],
[104., 120.]]) 与图中计算结果一致。
2. 多输出通道
输出通道是指卷积层生成的特征图的深度。每个输出通道对应一个独立的卷积核,用于提取输入数据中的某种特征,一个核提取一个特征。我们可以有多个三维卷积核,每个核生成一个输出通道,例如一个卷积层可以有 64 个输出通道,表示提取了 64 种不同的特征。而每个输出通道的值是通过所有输入通道的卷积结果相加得到的。
那为什么需要多输入输出通道?
李老师在举识别“猫”的例子,说明每个卷积核可以学习提取输入数据中的某种特定特征,最底层卷积识别一些边缘的纹理得到多个不同的输出通道,这些输出再继续作为下一个层输入,分别去识别猫胡须的纹理、耳朵的纹理等等,将这些纹理组合起来,再往下一层卷积走,某个通道识别猫头,某个通道识别猫眼,那最后一层输出就是所有东西组合起来识别出一只猫。(本人理解,可能有误)
总而言之,现实中的数据(如图像、视频)通常具有多个通道(如 RGB),多输入通道允许模型同时利用所有通道的信息,每个输出通道对应一个独立的卷积核,能够提取输入数据中的不同特征(如边缘、纹理等),多输出通道使得卷积神经网络能够从低层次到高层次逐步提取特征,通过同时提取多种特征,模型能够更全面地理解数据,从而实现图像分类、目标检测。
紧接上面的代码,“多个通道的输出的互相关计算”代码:
# 计算多个通道的输出的互相关计算
def corr2d_multi_in_out(X, K):
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
# 对于每个输出通道的卷积核 K调用之前的corr2d_multi_in多输入通道的互相关计算
# 再将所有输出通道的结果通过 torch.stack 堆叠在一起,形成多输出通道的特征图
K = torch.stack((K, K + 1, K + 2), 0)
# K是之前定义的卷积核
# 使用 torch.stack将 K、K + 1和 K + 2堆叠在一起,形成 3个输出通道的卷积核
K.shape
# 堆叠后的卷积核形状为 (3, 2, 2, 2)输出结果:torch.Size([3, 2, 2, 2])
corr2d_multi_in_out(X, K)
# 运算后输出结果是一个3x2x2的张量,表示 3个输出通道的特征图 
3. 1×1卷积核
卷积核高宽都为1,不会识别空间信息,只能针对一个像素,但是能够融合通道。
这里使用1x1卷积核与3个输入通道和2个输出通道的互相关计算,是一种特殊的卷积操作。它的主要作用是对输入通道进行线性组合,从而改变通道数(即特征图的深度),同时保持空间维度(高度和宽度)不变。
验证一下:1×1卷积等价于一个全连接
# 假设用全连接实现一个 1×1卷积核多输入多输出互相关运算
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape # c_in是输入通道数
c_o = K.shape[0] # c_o是输出通道数
X = X.reshape((c_i, h * w)) # 调整输入形状由(h,w)变为(h*w)即将空间维度展平
K = K.reshape((c_o, c_i)) # 调整卷积核形状即去掉冗余的1x1维度
Y = torch.matmul(K, X) # 使用矩阵乘法输入K(c_o,c_in),X(c_in, H * W)
return Y.reshape((c_o, h, w)) # 结果Y的形状为(C_o,h*w)
X = torch.normal(0, 1, (3, 3, 3))
# 形状:(3,3,3)表示 3个输入通道,每个通道是一个 3x3的矩阵
# 值:从均值为 0、标准差为 1的正态分布中随机生成
K = torch.normal(0, 1, (2, 3, 1, 1))
# 形状:(2,3,1,1)表示 2个输出通道 3个输入通道,每个通道是一个 1x1的卷积核
Y1 = corr2d_multi_in_out_1x1(X, K) # 计算 1x1卷积的结果
Y2 = corr2d_multi_in_out(X, K) # 计算普通多输入多输出卷积的结果
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
# 验证 1x1卷积的结果 Y1和普通卷积的结果 Y2是否一致运行结果:Y1 和 Y2 的值会非常接近,差值几乎为 0。断言 assert 会通过,说明 1x1 卷积的实现是正确的,并且等价于一个全连接。
五、池化层(课程22)
由于卷积层对位置信息非常敏感,输入数据(如图像)可能会受到平移、旋转、缩放等变换的影响,导致模型对同一物体的不同表现形式产生不同的响应,所以需要一定程度的平移不变性,缓解卷积对位置的敏感性。
1. 二维最大池化层
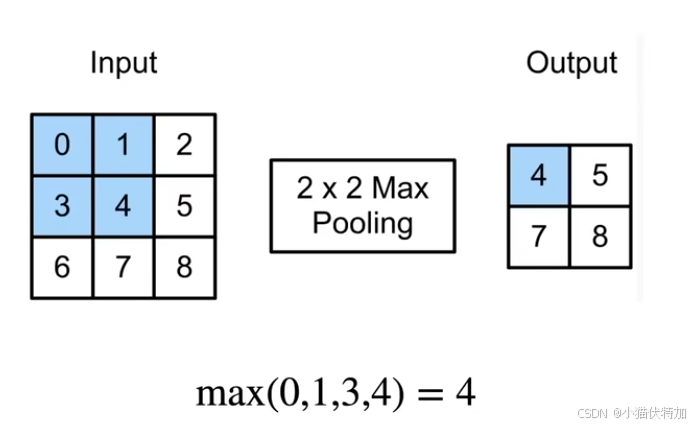
工作原理和之前卷积相似,都是利用一个窗口在输入上不断滑动,但它不是在做互相关计算,而是每一次将滑动窗口中的最大值取出来作为输出值。
池化层与卷积层类似,都具有填充和步幅。不同的是,池化层没有可学习的参数(比如卷积核),在每个输入通道应用池化层以获得相应的输出通道,它不会去融合多个通道,每一个通道做一次池化层,因此,输出通道数=输入通道数。
2. 平均池化层
将最大池化层中取最大值的操作变成求平均值的操作,也是一个常用的池化层。
3. 实现两种池化层
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):
p_h, p_w=pool_size # 池化窗口的高宽
Y=torch.zeros((X.shape[0]-p_h+1, X.shape[1]-p_w+1)) # 初始化输出张量Y
for i in range(Y.shape[0]): # 遍历每一个位置
for j in range(Y.shape[1]):
if mode=='max':
Y[i,j]=X[i:i+p_h, j:j+p_w].max() # 最大池化层
elif mode=='avg':
Y[i,j]=X[i:i+p_h, j:j+p_w].mean() # 平均池化层
return Y验证二维最大池化层的输出:
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2))结果:tensor([[4., 5.],
[7., 8.]]) 与课件例子一致。
验证平均池化层:
pool2d(X,(2,2),'avg')结果:tensor([[2., 3.],
[5., 6.]]) 变为均值。
加入填充和步幅:
X = torch.arange(16,dtype=torch.float32).reshape((1,1,4,4)) # 创建一个 4×4矩阵
X
# 深度学习框架中的步幅与池化窗口的大小相同
pool2d = nn.MaxPool2d(3) # 定义一个二维最大池化层,池化窗口大小 3×3
pool2d(X) # 进行池化操作结果:tensor([[[[10.]]]])
# 手动设定填充和步幅
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
# 可以设定一个任意大小的矩形汇聚窗口,并分别设定填充和步幅的高度和宽度
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(1, 1))
pool2d(X)最后,看看池化层在每个输入通道上单独运算:
X=torch.cat((X, X+1), 1) # 两个通道:X和X+1
X
'''tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])'''
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
'''tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])'''
六、总结
本文对李沐《动手学深度学习v2》19-22课知识点进行了汇总,初步认识了卷积神经网络,后续会继续学习经典卷积神经网络模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)