波士顿房价线性回归预测
线性回归算法是使用线性方程对数据集进行拟合的算法,是一个非常常见的回归算法。应用场景较广泛,例如同一平台不同坐标系间数据对应转换、大地坐标与经纬坐标转换、医院病床数与病患间的关系等等。在回归中,也可以通过对回归的数据打离散的标签实现分类的问题。本章首先从最简单的单变量线性回归算法开始,应用一个广告投放与销售量的案例,探讨线性回归的基本理论、实现方法、评估方法与常见的欠拟合和多重线性问题。然后通过波
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计20599字,阅读大概需要30分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
波士顿房价线性回归预测
波士顿房价线性回归预测
任务背景
线性回归算法是使用线性方程对数据集进行拟合的算法,是一个非常常见的回归算法。应用场景较广泛,例如同一平台不同坐标系间数据对应转换、大地坐标与经纬坐标转换、医院病床数与病患间的关系等等。在回归中,也可以通过对回归的数据打离散的标签实现分类的问题。本章首先从最简单的单变量线性回归算法开始,应用一个广告投放与销售量的案例,探讨线性回归的基本理论、实现方法、评估方法与常见的欠拟合和多重线性问题。然后通过波士顿房价预测进行案例演示。最后会通过逻辑回归分析鸢尾花分类与模型的性能指标分析,展示回归分类求解的过程。
任务需求
本节实验采用UCI开放出来的用于机器学习算法的经验分析的数据库中的波士顿房价数据,对数据进行可视化分析,依据线性模型特点,对数据进行降维处理,对数据进行多项式生成,完成波士顿房价的线性回归预测。
数据源于美国1978年经济与管理(Economics & Management)杂志第五卷,第81-102页,创作者是Harrison, D. and Rubinfeld, D.L。1993年UCI平台开源出来,其实验数据的下载网址为:链接: https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
数据记录了共计506条波士顿郊区的住房价值及其13个影响因素的信息,部分数据展示如表所示。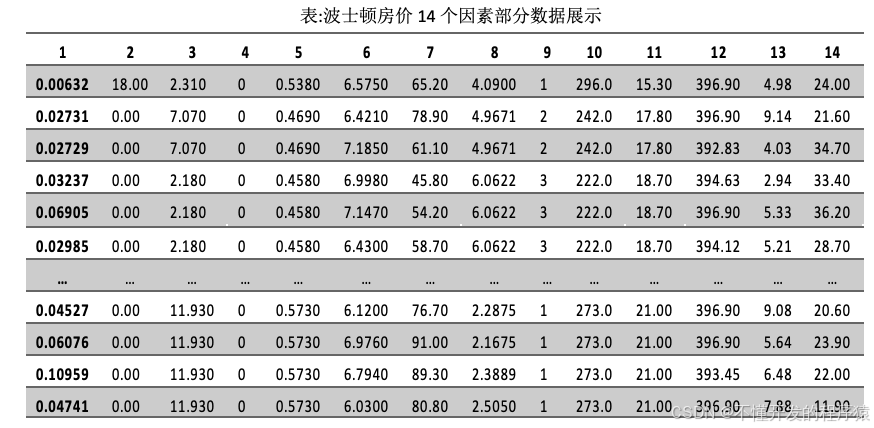
其中数据从左至右1~14依次表示为:CRIM、ZN、INDUS、CHAS、NOX、RM、AGE、DIS、RAD、TAX、PTRATIO、B、LSTAT和MEDV,共计14项,每个因素的具体含义为:
- CRIM: 城镇人均犯罪率
- ZN: 住宅用地所占比例
- INDUS: 城镇中非住宅用地所占比例
- CHAS: CHAS 虚拟变量,用于回归分析
- NOX: 环保指数
- RM: 每栋住宅的房间数
- AGE: 1940 年以前建成的自住单位的比例
- DIS: 距离 5 个波士顿的就业中心的加权距离。
- RAD: 距离高速公路的便利指数
- TAX: 每一万美元的不动产税率
- PRTATIO: 城镇中的教师学生比例
- B: 城镇中的黑人比例
- LSTAT: 地区中有多少房东属于低收入人群
- MEDV: 自住房屋房价中位数(也就是均价)
数据中没有空值项,所以在进行建模时,不需要进行空值的检查。
任务步骤
本任务共设定6个子任务,分6大步骤完成。
第1步: 数据下载与数据初步解读
第2步: 数据读取:使用pandas工具进行波士顿房价文本数据的读取。
第3步: 数据可视化分析:使用Matplotlib工具绘制每一因素与房价的多子图对数据进行相关性可视化分析。
第4步: 数据降维处理,介绍二种方法:
- 求解因素间相关性矩阵数据,删除与房价相关性不强的特征
- LASSO特征分析
第5步: 构建波士顿房价模型降维分析,比较房价在特征降维前后的模型评分。
第6步: 应用多项式特征,增加模型的泛化能力,提高的模型的学习能力。
任务结果
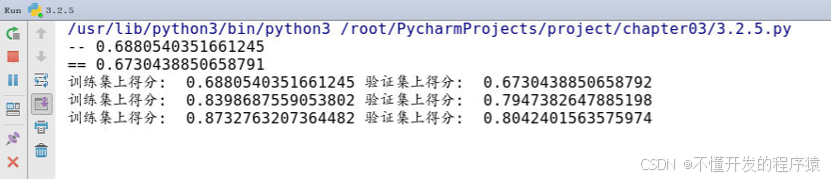
多项式训练过程中,线性回归在一阶多项式时训练集上得分为0.6880540351661245,验证集上得分为0.6730438850658792;当二阶多项式时,训练集上得分为0.8398687559053802,验证集上得分为0.7947382647885198,模型的得分得到明显的提高。
任务实施过程
- 配置Pycharm工具,创建Python3项目
知识点
- Pycharm工具下建立Python3项目
- 项目中建立统一的UTF-8编码格式
- 项目中建立包名
实验目的
- 掌握Pycharm工具下建立Python3项目的方法
实验环境
- Oracle Linux 7.4
- Jdk1.8.0_171
- Pycharm
- Python3.6.5
实验步骤
1.打开Pycharm工具下Python3开发环境的设置
-
如果出现Complete Installation弹窗时点击Do not import settings 点击ok。
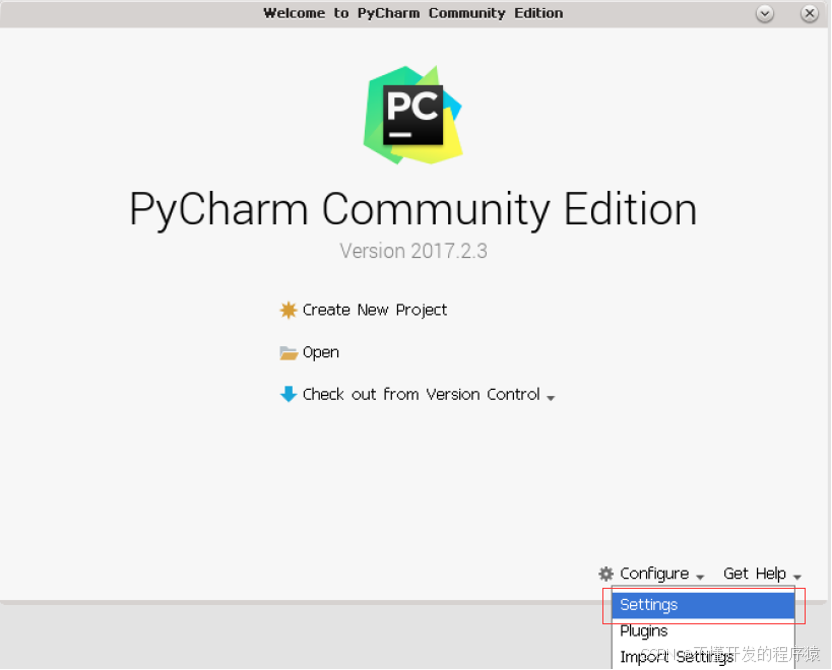
由于第1次打开此工具会弹出“Welcome to PyCharm Community Edition”窗口,配置新安装上的Python3。具体做法:鼠标点击“Configure->Settings”。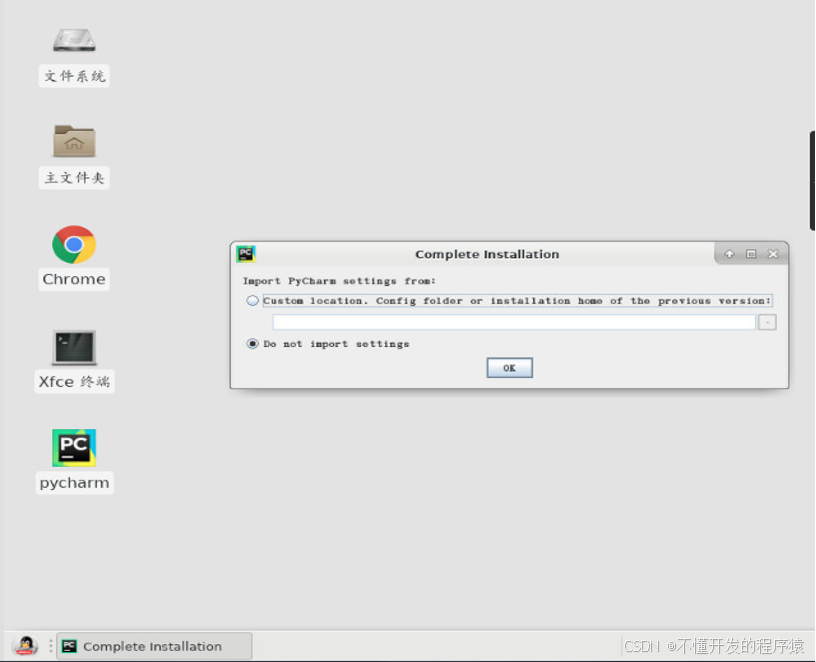
-
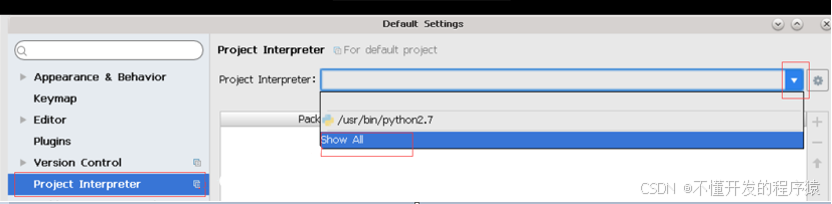
在弹出“Default settings”窗口的左侧,选择“Project Interpreter”选项,此时窗口右侧出现该选项相应配置选项,鼠标选择“Project Interpreter”选项,在下拉菜单中选择“Show All”。
-
在弹出“Project Interpreter”窗口的右侧,点击“+”按钮,在弹出的下拉菜单中选择“Add Local”。

-
在弹出“Select Python Interpreter”窗口中选择Python3安装位置下bin下的Python3,点击OK按钮。如图所示。
-
回到“Project Interpreter”窗口,确认Python3选项,点击OK按钮。如图所示。
-
回到““Default settings”窗口,确认Python3选项,点击OK按钮。如图所示。完成Pycharm工具下Python3环境的设置。
2.Pycharm工具下建立Python3项目与包名
-
回到“Welcome to PyCharm Community Edition”窗口,鼠标点击“Do not show again”,下次再打开工具时就不会弹出此窗口,然后选择“Create New Project”。
-
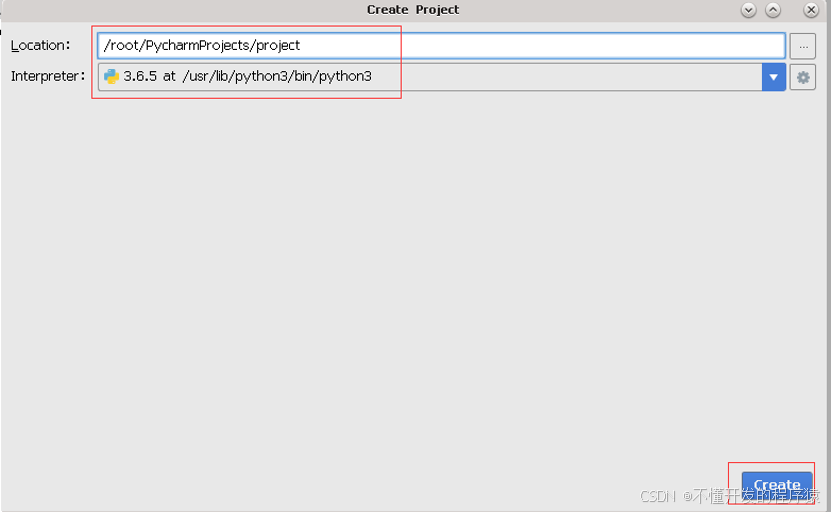
在弹出的Create Project窗口中,显示的Location对应的文本框中输入项目名project,点击Create按钮,完成项目的创建。
-
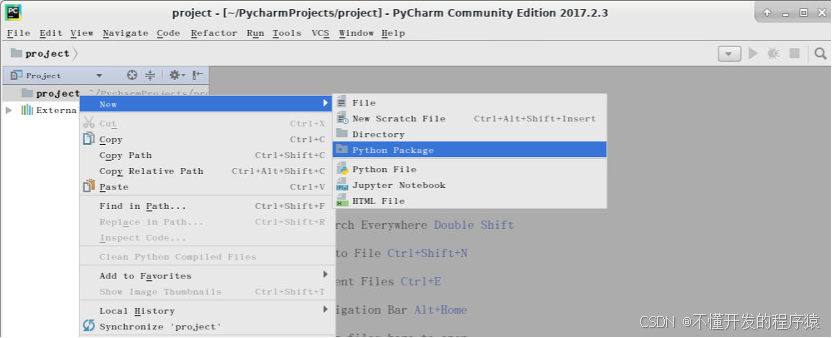
建立包名chapter03,用于写清洗Python程序。具体做法:选中新建立的项目project->鼠标右键->New->Python Package。
-
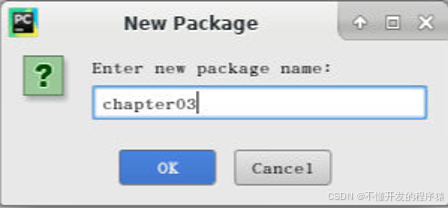
在弹出的New Package窗口中的文本框内,输入要建立的包名(用户可自定义)“chapter03”,点击OK按键,完成包名的创建。
-
此时在窗口左侧的窗口中的project项目下可以看到新建立chapter03程序包,在该包下写实验相关的Python程序。

3.建立对中文支持良好的统一的UTF-8编码格式
- 设置统一的编码模式,使新生成的文件支持中文,统一设置utf-8编码。具体做法:File->settings->Editor->File and Code Templates->Python Script。在Python Script对应的文本模式中输入具体编码设置,点击OK按钮,完成设置。
#!/usr/bin/python
# -*- coding:utf-8 -*-

2.Pandas读取葡萄酒实验文本数据
知识点
- pandas读取数据
实验目的
- 掌握pandas读取数据
实验环境
- Oracle Linux 7.4
- Pycharm
- Python3
实验步骤
1.新建py源代码文件,编写代码执行并查看结果
-
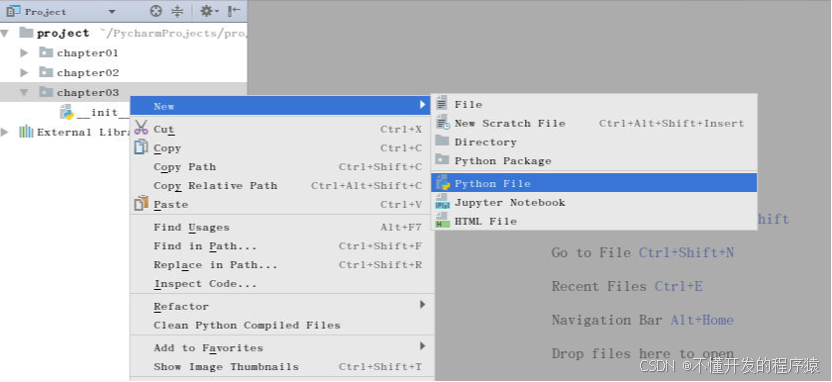
建立3.2.py文件,用于编写Python实验程序。具体做法:选中新建立的项目project-下新建立的包名chapter03>鼠标右键->New->Python File。
-
在弹出的新建立Python文件(New Python file)窗口中显示的Name属性对应的文本框中输入文件名3.2,点击OK按键,完成文件的建立。

-
数据准备,将工程所需的数据文件添加至项目中,具体指令如下:
cp -r /root/experiment/data/chapter03/housing.data /root/PycharmProjects/project/chapter03

- 波士顿房价文本数据列间是通过空格间隔,而且列与列间的空格数量不一致,同时也考虑后期应用时数据组类型数据的方便性,可应用Pandas读数据,应用数组进行数据分离存储。然后对分离好的数据进行打标签,以备后面使用。具体程序参考如下,编写3.2.py文件的代码:
import pandas as pd
import numpy as np
def not_empty(s):
return s != ''
if __name__ == "__main__":
np.set_printoptions(suppress=True)
file_data = pd.read_csv('housing.data', header=None)
data = np.empty((len(file_data), 14))
for i, d in enumerate(file_data.values):
d = list(map(float, list(filter(not_empty, d[0].split(' ')))))
data[i] = d
x, y = np.split(data, (14, ), axis=1)
print('样本个数:%d, 特征个数:%d' % x.shape)
print(y.shape)
cols=['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
df=pd.DataFrame(data, columns=cols)
print(df)

-
在3.2.py文件的空白处,鼠标右键选“Run‘3.2’”,运行代码。
-
在Pycharm工具当前项目窗口的底部看到运行的窗口,结果如下所示:
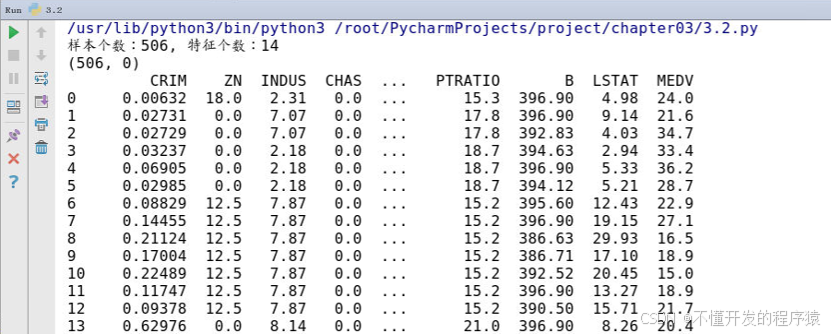
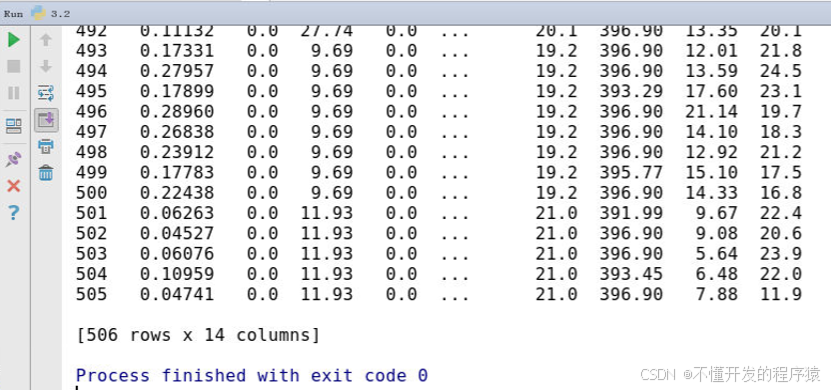
数据共506行,14个特征。
3.使用Matplotlib进行数据可视化分析
知识点
- matplotlib绘制散点图
实验目的
- 掌握matplotlib绘制散点图
实验环境
- Oracle Linux 7.4
- Pycharm
- Python3
实验步骤
1.绘制散点图
- 为了方便观察波士顿房价与各特征间的关系,应用Matplotlib的Subplot对波士顿房价影响特征与自住房屋均价(MEDV)进行散点图的分格显示,将每个特征与房价的散点图实现出来,观察13个因素与房价的关系。编写3.2.py文件的代码。具体代码如下:
import matplotlib.pyplot as plt
# 绘制散点图
y1 = df['MEDV']
plt.figure(facecolor='w', figsize=(8, 5))
ax1 = plt.subplot2grid((3, 5), # 将整个图像窗口分成3行5列
(0, 0), # 从第0行第0列开始作图,即索引从0开始
colspan=2) # 列的跨度为3
plt.plot(df['CRIM'], y1, '.') # 画小图
ax1.set_title('CRIM') # 设置小图的标题
ax2 = plt.subplot2grid((3,5),(0, 2))
plt.plot(df['ZN'], y1, '.') # 画小图
ax2.set_title('ZN') # 设置小图的标题
ax3 = plt.subplot2grid((3,5), (0,3))
plt.plot(df['INDUS'], y1, '.') # 画小图
ax3.set_title('INDUS') # 设置小图的标题
ax4 = plt.subplot2grid((3,5), (0,4))
plt.plot(df['CHAS'], y1, '.') # 画小图
ax4.set_title('CHAS') # 设置小图的标题
ax5 = plt.subplot2grid((3,5), (1,0))
plt.plot(df['NOX'], y1, '.') # 画小图
ax5.set_title('NOX') # 设置小图的标题
ax6 = plt.subplot2grid((3,5), (1,1))
plt.plot(df['RM'], y1, '.') # 画小图
ax6.set_title('RM') # 设置小图的标题
ax7 = plt.subplot2grid((3,5), (1,2))
plt.plot(df['AGE'], y1, '.') # 画小图
ax7.set_title('AGE') # 设置小图的标题
ax8 = plt.subplot2grid((3,5), (1,3))
plt.plot(df['DIS'], y1, '.') # 画小图
ax8.set_title('DIS') # 设置小图的标题
ax9 = plt.subplot2grid((3,5), (1,4))
plt.plot(df['RAD'], y1, '.') # 画小图
ax9.set_title('RAD') # 设置小图的标题
ax10 = plt.subplot2grid((3,5), (2,0))
plt.plot(df['TAX'], y1, '.') # 画小图
ax10.set_title('TAX') # 设置小图的标题
ax11 = plt.subplot2grid((3,5), (2,1))
plt.plot(df['PTRATIO'], y1, '.') # 画小图
ax11.set_title('PTRATIO') # 设置小图的标题
ax12 = plt.subplot2grid((3,5), (2,2))
plt.plot(df['B'], y1, '.') # 画小图
ax12.set_title('B') # 设置小图的标题
ax13 = plt.subplot2grid((3,5), (2,3),colspan=2)
plt.plot(df['LSTAT'], y1, '.') # 画小图
ax13.set_title('LSTAT') # 设置小图的标题
plt.show()



-
在3.2.py文件的空白处,鼠标右键选“Run‘3.2’”,运行代码。
-
在Pycharm工具当前项目窗口的底部看到运行的窗口,结果如下所示:

图中显示13个特征并不是都与房价具有相关性,例如CHAS没有明显线性特征,而RM有明显线性特征。
4.特征降维处理
知识点
- 降维
实验目的
- 掌握降维的方法
实验环境
- Oracle Linux 7.4
- Pycharm
- Python3
实验步骤
1.查看相关性
- 考虑波士顿房价拟应用线性回归模型,故建议首先将线性关系不明显的特征进行删除处理,为了便于辨别,可将每一个特征和自住房屋房价中位数MEDV的相关系数进行计算,可通过下面语句实现。编写3.2.py文件的代码。具体代码如下:
print(df.corr()['MEDV'])

-
在3.2.py文件的空白处,鼠标右键选“Run‘3.2’”,运行代码。

-
在Pycharm工具当前项目窗口的底部看到运行的窗口,结果如下所示:
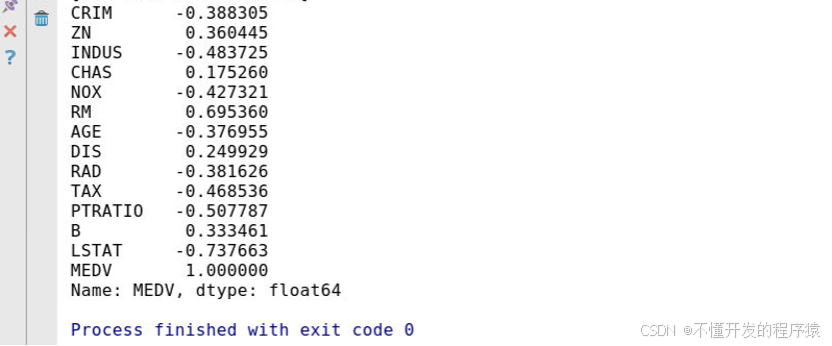
结果分析
运行结果显示,超过50%的特征有3个,分别是RM、PTRATIO和LSTAT。
2.LASSO特征分析
-
建立3.2.Lasso.py文件,用于编写Python实验程序。具体做法:选中新建立的项目project-下新建立的包名chapter03>鼠标右键->New->Python File。

-
在弹出的新建立Python文件(New Python file)窗口中显示的Name属性对应的文本框中输入文件名3.2.Lasso,点击OK按键,完成文件的建立。
-
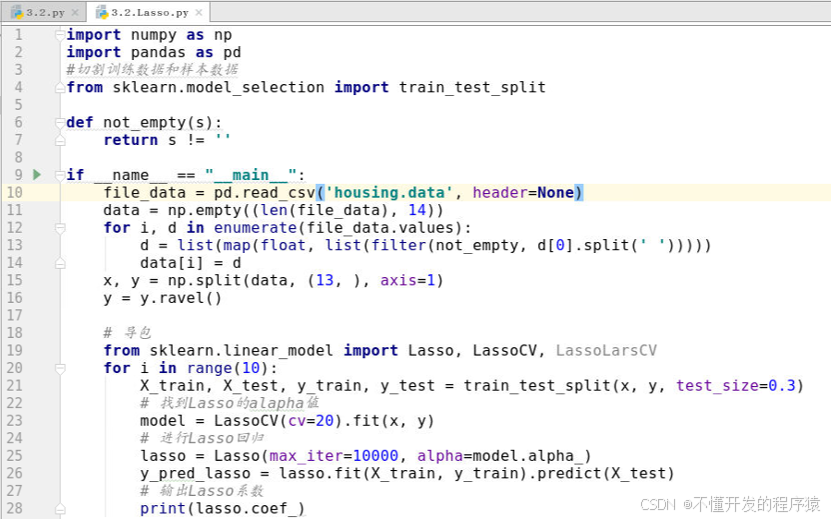
LASSO于1996年由Robert Tibshirani首次提出,它是一种压缩估计,通过构造一个惩罚函数得到一个较为精炼的模型,使得它压缩一些回归系数,同时设定一些回归系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。LASSO可有选择的把变量放入模型从而得到更好的性能参数,借用这个特点,可进一步分析13个因素权重的程度,为了运行结果更有说服力,可将数据进行多次分割,例如10次,进行分析进行真值发现,参考程序如下:
import numpy as np
import pandas as pd
#切割训练数据和样本数据
from sklearn.model_selection import train_test_split
def not_empty(s):
return s != ''
if __name__ == "__main__":
file_data = pd.read_csv('housing.data', header=None)
data = np.empty((len(file_data), 14))
for i, d in enumerate(file_data.values):
d = list(map(float, list(filter(not_empty, d[0].split(' ')))))
data[i] = d
x, y = np.split(data, (13, ), axis=1)
y = y.ravel()
# 导包
from sklearn.linear_model import Lasso, LassoCV, LassoLarsCV
for i in range(10):
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 找到Lasso的alapha值
model = LassoCV(cv=20).fit(x, y)
# 进行Lasso回归
lasso = Lasso(max_iter=10000, alpha=model.alpha_)
y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test)
# 输出Lasso系数
print(lasso.coef_)
- 运行程序,在Pycharm工具当前项目窗口的底部看到运行的窗口,结果如下所示:
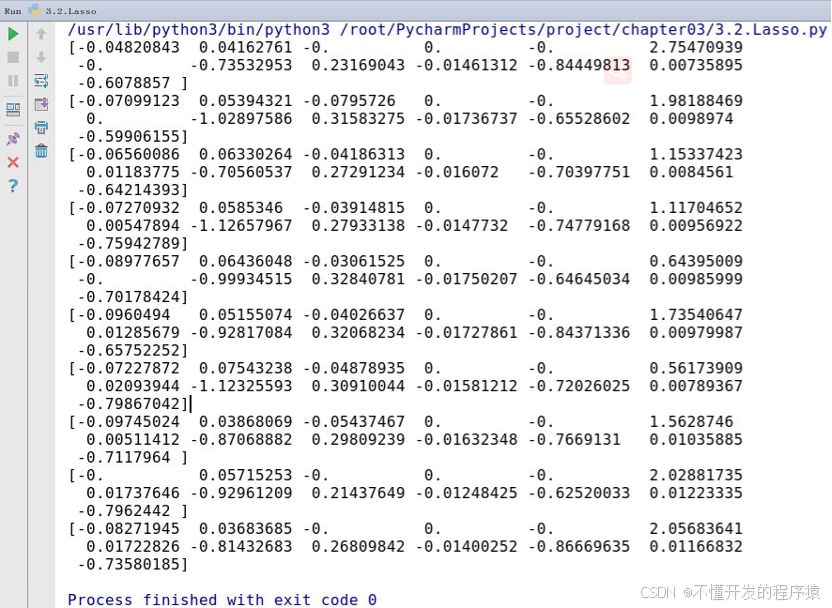
运行结果中,除了进一步表明了RM、PTRATIO和LSTAT的系数较大外,第8个特征DIS系数也呈现出较大的值,都在0.5以上,可试着将这个特征选择加入线性回归模型中。最终,删除9个特征,只留RM、PTRATIO、LSTAT和DIS四个特征参与计算。
5.线性回归模型分析
知识点
- 线性回归模型
- 岭回归模型
实验目的
- 掌握线性回归模型使用
- 掌握岭回归模型使用
实验环境
- Oracle Linux 7.4
- Pycharm
- Python3
实验步骤
1.定义模型训练函数
-
建立3.2.4.py文件,用于编写Python实验程序。具体做法:选中新建立的项目project-下新建立的包名chapter03>鼠标右键->New->Python File。
-
在弹出的新建立Python文件(New Python file)窗口中显示的Name属性对应的文本框中输入文件名3.2.4,点击OK按键,完成文件的建立。
-
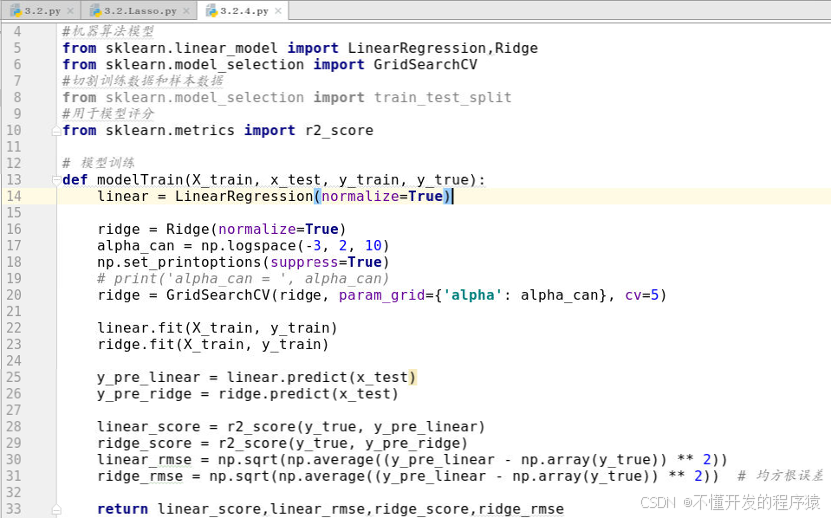
建立普通最小二乘和岭回归模型,具体代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#机器算法模型
from sklearn.linear_model import LinearRegression,Ridge
from sklearn.model_selection import GridSearchCV
#切割训练数据和样本数据
from sklearn.model_selection import train_test_split
#用于模型评分
from sklearn.metrics import r2_score
# 模型训练
def modelTrain(X_train, x_test, y_train, y_true):
linear = LinearRegression(normalize=True)
ridge = Ridge(normalize=True)
alpha_can = np.logspace(-3, 2, 10)
np.set_printoptions(suppress=True)
# print('alpha_can = ', alpha_can)
ridge = GridSearchCV(ridge, param_grid={'alpha': alpha_can}, cv=5)
linear.fit(X_train, y_train)
ridge.fit(X_train, y_train)
y_pre_linear = linear.predict(x_test)
y_pre_ridge = ridge.predict(x_test)
linear_score = r2_score(y_true, y_pre_linear)
ridge_score = r2_score(y_true, y_pre_ridge)
linear_rmse = np.sqrt(np.average((y_pre_linear - np.array(y_true)) ** 2))
ridge_rmse = np.sqrt(np.average((y_pre_linear - np.array(y_true)) ** 2)) # 均方根误差
return linear_score,linear_rmse,ridge_score,ridge_rmse
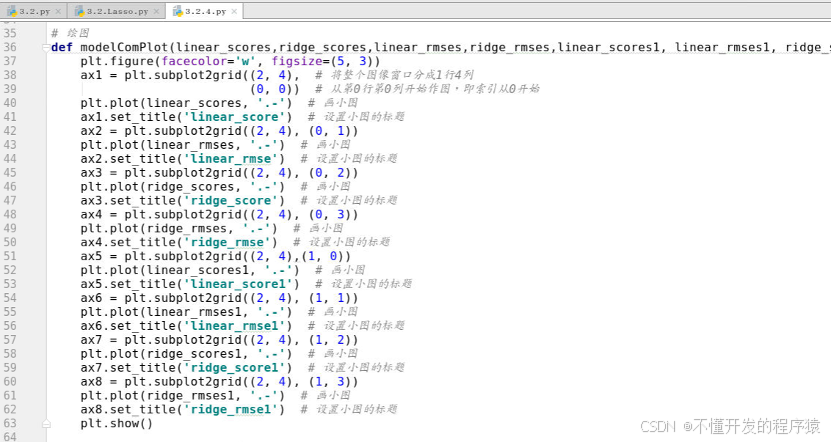
- 由于数据量不大,对波士顿房价的506行13个特征的数据集,以二八比例分成测试数据与训练数据二部分,为了能说明普遍现象,可分别取20次,分出20个不同的数据集进行训练,将普通最小二乘模型的评分(linear_score)、均方根误差(linear_rmse)、岭回归的评分(ridge_score)、均方根误差(ridge_rmse)和降维后四个特征最小二乘模型的评分(linear_score1)、均方根误差(linear_rmse1)、岭回归的评分(ridge_score1)、均方根误差(ridge_rmse1)进行模型建立与结果分析,同时为了便于观察,将结果以图形的形式进行展示,参考代码如下:
# 绘图
def modelComPlot(linear_scores,ridge_scores,linear_rmses,ridge_rmses,linear_scores1, linear_rmses1, ridge_scores1, ridge_rmses1):
plt.figure(facecolor='w', figsize=(5, 3))
ax1 = plt.subplot2grid((2, 4), # 将整个图像窗口分成1行4列
(0, 0)) # 从第0行第0列开始作图,即索引从0开始
plt.plot(linear_scores, '.-') # 画小图
ax1.set_title('linear_score') # 设置小图的标题
ax2 = plt.subplot2grid((2, 4), (0, 1))
plt.plot(linear_rmses, '.-') # 画小图
ax2.set_title('linear_rmse') # 设置小图的标题
ax3 = plt.subplot2grid((2, 4), (0, 2))
plt.plot(ridge_scores, '.-') # 画小图
ax3.set_title('ridge_score') # 设置小图的标题
ax4 = plt.subplot2grid((2, 4), (0, 3))
plt.plot(ridge_rmses, '.-') # 画小图
ax4.set_title('ridge_rmse') # 设置小图的标题
ax5 = plt.subplot2grid((2, 4),(1, 0))
plt.plot(linear_scores1, '.-') # 画小图
ax5.set_title('linear_score1') # 设置小图的标题
ax6 = plt.subplot2grid((2, 4), (1, 1))
plt.plot(linear_rmses1, '.-') # 画小图
ax6.set_title('linear_rmse1') # 设置小图的标题
ax7 = plt.subplot2grid((2, 4), (1, 2))
plt.plot(ridge_scores1, '.-') # 画小图
ax7.set_title('ridge_score1') # 设置小图的标题
ax8 = plt.subplot2grid((2, 4), (1, 3))
plt.plot(ridge_rmses1, '.-') # 画小图
ax8.set_title('ridge_rmse1') # 设置小图的标题
plt.show()
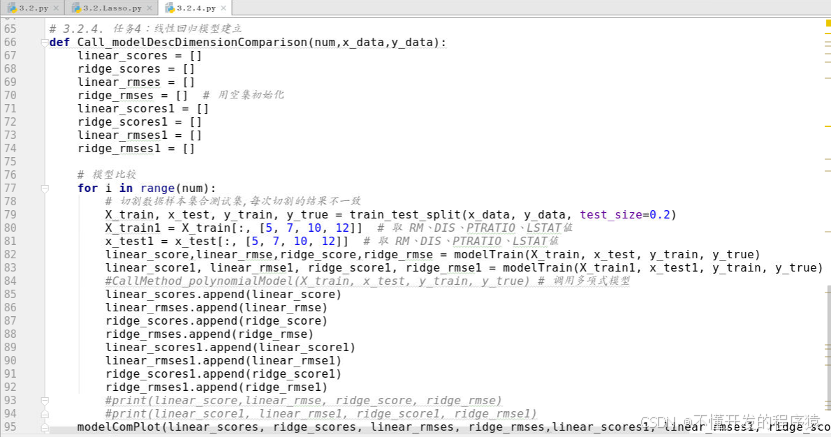
# 3.2.4. 任务4:线性回归模型建立
def Call_modelDescDimensionComparison(num,x_data,y_data):
linear_scores = []
ridge_scores = []
linear_rmses = []
ridge_rmses = [] # 用空集初始化
linear_scores1 = []
ridge_scores1 = []
linear_rmses1 = []
ridge_rmses1 = []
# 模型比较
for i in range(num):
# 切割数据样本集合测试集,每次切割的结果不一致
X_train, x_test, y_train, y_true = train_test_split(x_data, y_data, test_size=0.2)
X_train1 = X_train[:, [5, 7, 10, 12]] # 取 RM、DIS、PTRATIO、LSTAT值
x_test1 = x_test[:, [5, 7, 10, 12]] # 取 RM、DIS、PTRATIO、LSTAT值
linear_score,linear_rmse,ridge_score,ridge_rmse = modelTrain(X_train, x_test, y_train, y_true)
linear_score1, linear_rmse1, ridge_score1, ridge_rmse1 = modelTrain(X_train1, x_test1, y_train, y_true)
#CallMethod_polynomialModel(X_train, x_test, y_train, y_true) # 调用多项式模型
linear_scores.append(linear_score)
linear_rmses.append(linear_rmse)
ridge_scores.append(ridge_score)
ridge_rmses.append(ridge_rmse)
linear_scores1.append(linear_score1)
linear_rmses1.append(linear_rmse1)
ridge_scores1.append(ridge_score1)
ridge_rmses1.append(ridge_rmse1)
#print(linear_score,linear_rmse, ridge_score, ridge_rmse)
#print(linear_score1, linear_rmse1, ridge_score1, ridge_rmse1)
modelComPlot(linear_scores, ridge_scores, linear_rmses, ridge_rmses,linear_scores1, linear_rmses1, ridge_scores1, ridge_rmses1)
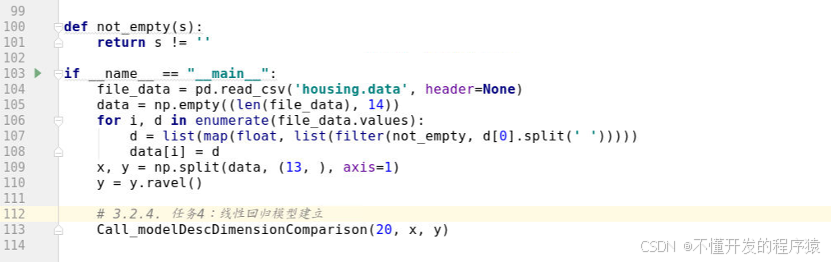
- 将训练的次数据(num)设定为20次,并将波士顿房价(y)和13个特征的数据集(x)赋予模型,参考代码:
def not_empty(s):
return s != ''
if __name__ == "__main__":
file_data = pd.read_csv('housing.data', header=None)
data = np.empty((len(file_data), 14))
for i, d in enumerate(file_data.values):
d = list(map(float, list(filter(not_empty, d[0].split(' ')))))
data[i] = d
x, y = np.split(data, (13, ), axis=1)
y = y.ravel()
# 3.2.4. 任务4:线性回归模型建立
Call_modelDescDimensionComparison(20, x, y)
-
在3.2.4.py文件的空白处,鼠标右键选“Run‘3.2.4’”,运行代码。
-
在Pycharm工具当前项目窗口的底部看到运行的窗口,结果如下所示:
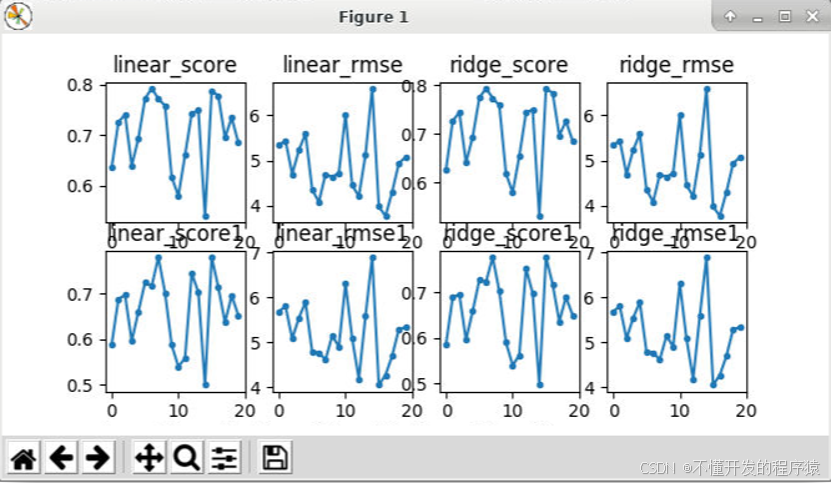
数据量较小,特征并不明显,结果在特征由13个降低至4个后,没有太大变化,二个模型优势差异并不十分明显,模型训练评分结果都集中在70%左右,分数较低,但仍能看出岭回归变化较小,仍能体现它对共线性的鲁棒性。
6.多项式特征生成
知识点
- 多项式特征
实验目的
- 掌握多项式特征的使用
实验环境
- Oracle Linux 7.4
- Pycharm
- Python3
实验步骤
1.定义模型训练函数
-
建立3.2.5.py文件,用于编写Python实验程序。具体做法:选中新建立的项目project-下新建立的包名chapter03>鼠标右键->New->Python File。
-
在弹出的新建立Python文件(New Python file)窗口中显示的Name属性对应的文本框中输入文件名3.2.5,点击OK按键,完成文件的建立。
-
字体文件准备,将工程所需的字体文件添加至项目中,具体指令如下:
cp -r /root/experiment/data/chapter03/simsun.ttc /root/PycharmProjects/project/chapter03

- 波士顿数据虽然做了特征处理,但结果仍然不尽人意,由于对训练样本的拟合程度不够,模型的泛化能力不足。为了提高模型的泛化能力,可试着采用多次线性函数建立模型。学习曲线应用sklearn.model_selection中的learning_curve方法,其中交叉验证方法应用ShuffleSplit,进行波士顿房价的多项式特征学习。
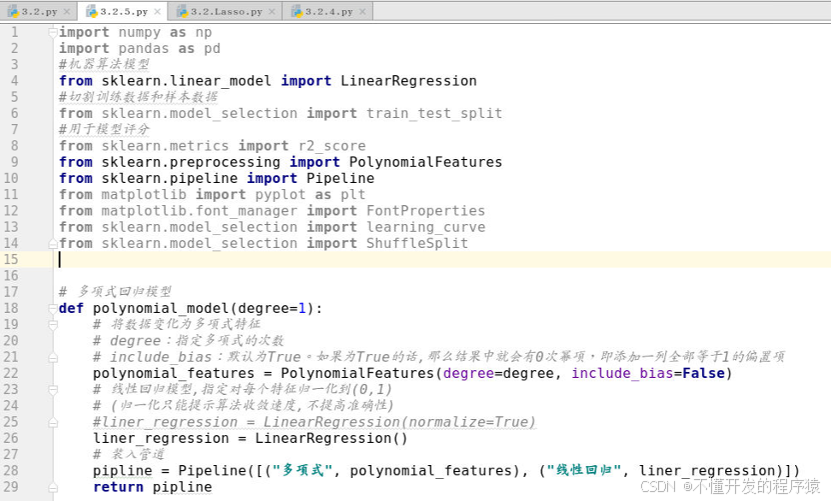
建立多项式回归模型,使用Pipline管道,先进行多项式回归增加维度,然后再进行归一化,最后进行线性回归。注意:二阶多项式和三阶多项式需要更多的执行时间,在实验操作过程中,视情况而定。具体代码如下:
import numpy as np
import pandas as pd
#机器算法模型
from sklearn.linear_model import LinearRegression
#切割训练数据和样本数据
from sklearn.model_selection import train_test_split
#用于模型评分
from sklearn.metrics import r2_score
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from matplotlib import pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
# 多项式回归模型
def polynomial_model(degree=1):
# 将数据变化为多项式特征
# degree:指定多项式的次数
# include_bias:默认为True。如果为True的话,那么结果中就会有0次幂项,即添加一列全部等于1的偏置项
polynomial_features = PolynomialFeatures(degree=degree, include_bias=False)
# 线性回归模型,指定对每个特征归一化到(0,1)
# (归一化只能提示算法收敛速度,不提高准确性)
#liner_regression = LinearRegression(normalize=True)
liner_regression = LinearRegression()
# 装入管道
pipline = Pipeline([("多项式", polynomial_features), ("线性回归", liner_regression)])
return pipline
def plot_learning_curve(estimator, title, X, y,ylim=None, cv=None,n_jobs=None,train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure(facecolor='w', figsize=(8, 7))
plt.title(title,fontsize = 24)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u'训练样本', fontproperties=zhfont )
plt.ylabel(u'得分', fontproperties=zhfont)
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y,cv=cv,
n_jobs=n_jobs,train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std,
alpha=0.1, color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std,
alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="训练分数")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="交叉验证分数")
plt.legend(loc="best", fontsize=24, prop=zhfont)
return plt
def not_empty(s):
return s != ''
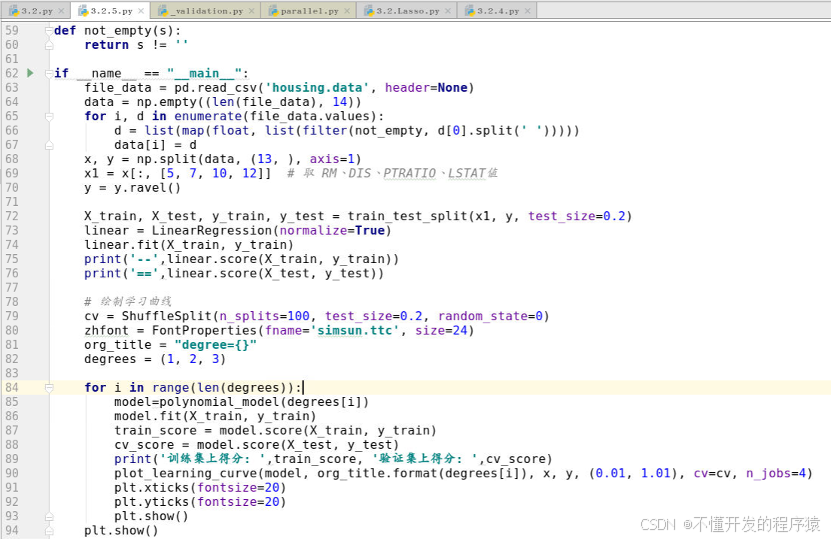
if __name__ == "__main__":
file_data = pd.read_csv('housing.data', header=None)
data = np.empty((len(file_data), 14))
for i, d in enumerate(file_data.values):
d = list(map(float, list(filter(not_empty, d[0].split(' ')))))
data[i] = d
x, y = np.split(data, (13, ), axis=1)
x1 = x[:, [5, 7, 10, 12]] # 取 RM、DIS、PTRATIO、LSTAT值
y = y.ravel()
X_train, X_test, y_train, y_test = train_test_split(x1, y, test_size=0.2)
linear = LinearRegression(normalize=True)
linear.fit(X_train, y_train)
print('--',linear.score(X_train, y_train))
print('==',linear.score(X_test, y_test))
# 绘制学习曲线
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
zhfont = FontProperties(fname='simsun.ttc', size=24)
org_title = "degree={}"
#degrees = (1, 2, 3) # 三阶多项式设置,需要更多的执行时间
degrees = (1)
for i in range(len(degrees)):
model=polynomial_model(degrees[i])
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
cv_score = model.score(X_test, y_test)
print('训练集上得分: ',train_score, '验证集上得分: ',cv_score)
plot_learning_curve(model, org_title.format(degrees[i]), x, y, (0.01, 1.01), cv=cv, n_jobs=4)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
plt.show()
plt.show()

5.在3.2.5.py文件的空白处,鼠标右键选“Run‘3.2.5’”,运行代码。
- 在Pycharm工具当前项目窗口的底部看到运行的窗口,结果如下所示:
一阶多项式结果【代码中为:degrees = (1)】: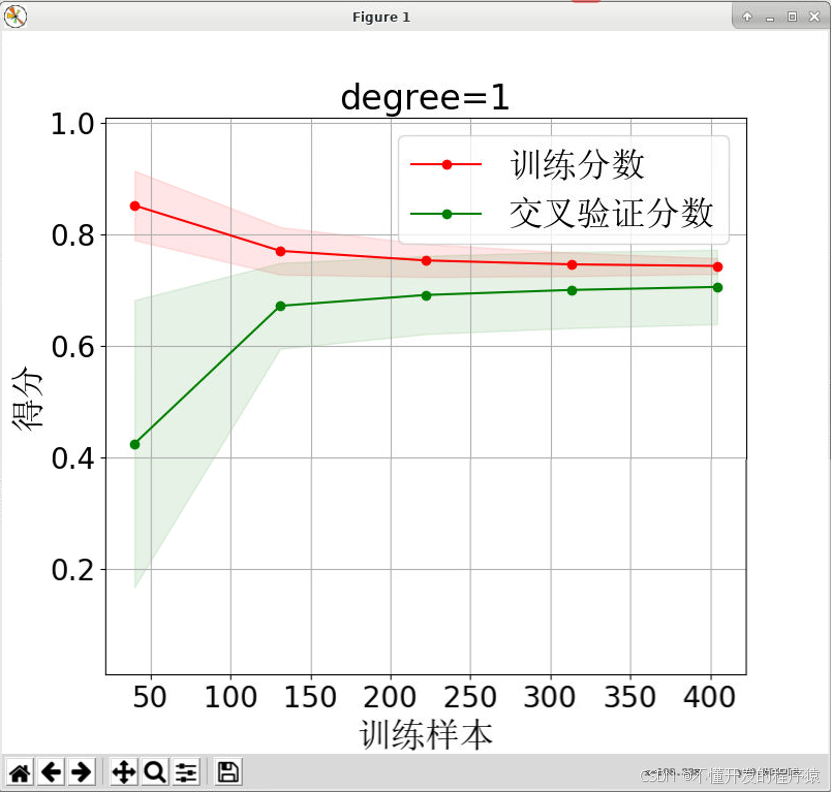
二阶多项式结果【代码中为:degrees = (2)】: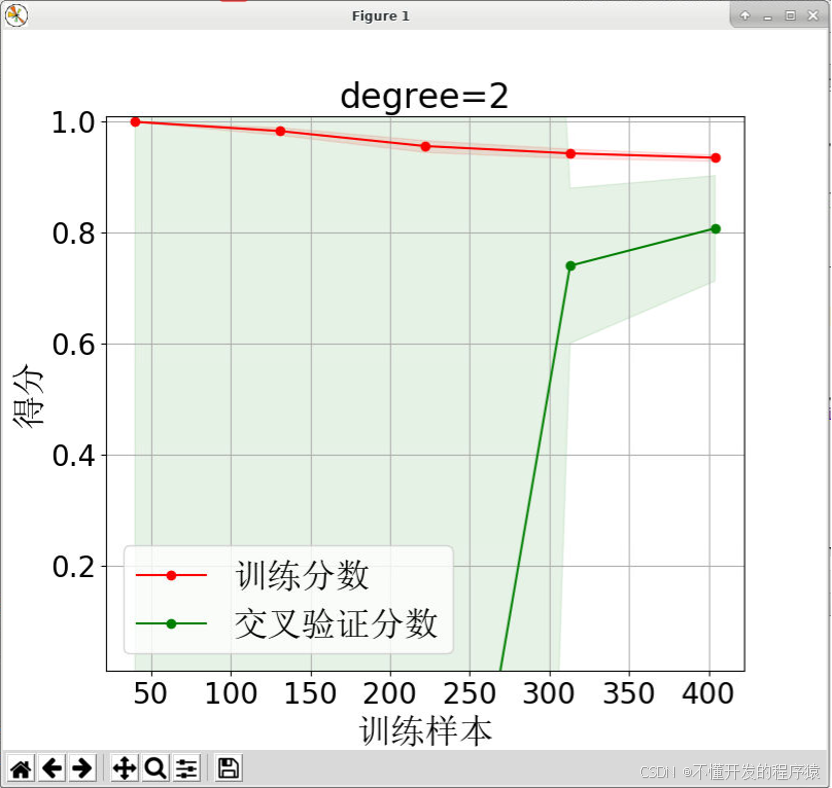
三阶多项式结果【代码中为:degrees = (3)】:
图中学习曲线通过画出不同训练集大小时训练集和交叉验证的得分,描述了线性回归与结合多项式技术后,模型在新数据上的表现,由此可判断模型是否方差偏高或偏差过高。在一阶多项式(degree=1)时,即线性回归模型的训练分数和交叉验证分数训练样本数量增加收敛到较低的值70%左右,此时无法从更多的训练样本中得到受益。为了改变这种情况,试着应用二阶多项式(degree=2)拟合,训练分数远大于验证分数,训练样本提高了泛化能力,线性回归模型的训练分数和交叉验证分数训练样本数量增加时表现收敛于80%以上,但在训练样本270之前,没有交叉验证数据,虽然模型分数有所改变,但收敛并没有得到满意描述,体现样本数量较少的情况。在进一步多项式处理,即三阶多项式(degree=3)拟合时,交叉验证数据集的分数没有看到,此时,针对波士顿房价数据量已经表现不够用,训练分数基本为1,说明了此时为过拟合的情况。
多项式训练过程中,线性回归在一阶多项式时训练集上得分为0.6880540351661245,验证集上得分为0.6730438850658792;当二阶多项式时,训练集上得分为0.8398687559053802,验证集上得分为0.7947382647885198,模型的得分得到明显的提高。
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)