【RAG系列】多模态RAG的三种实现思路和代码
目录
前言
RAG工程的出现是为了弥补LLM专业知识的不足以及减少LLM幻觉问题,目前最常见的是文本RAG,但随着场景越来越复杂,对多模态RAG的需求开始变多。本文先简要介绍多模态基础,然后详细介绍多模态RAG的三种实现思路,以及代码实现。
一、文本RAG的介绍
我们知道文本RAG工程的关键是索引构建和文档检索,这两者都需要借助embedding模型将文本编码成向量以构建索引,然后在检索时计算用户查询向量(文本)和文档向量(文本)在同一个向量空间计算距离,距离最近的文档被认为最相关。
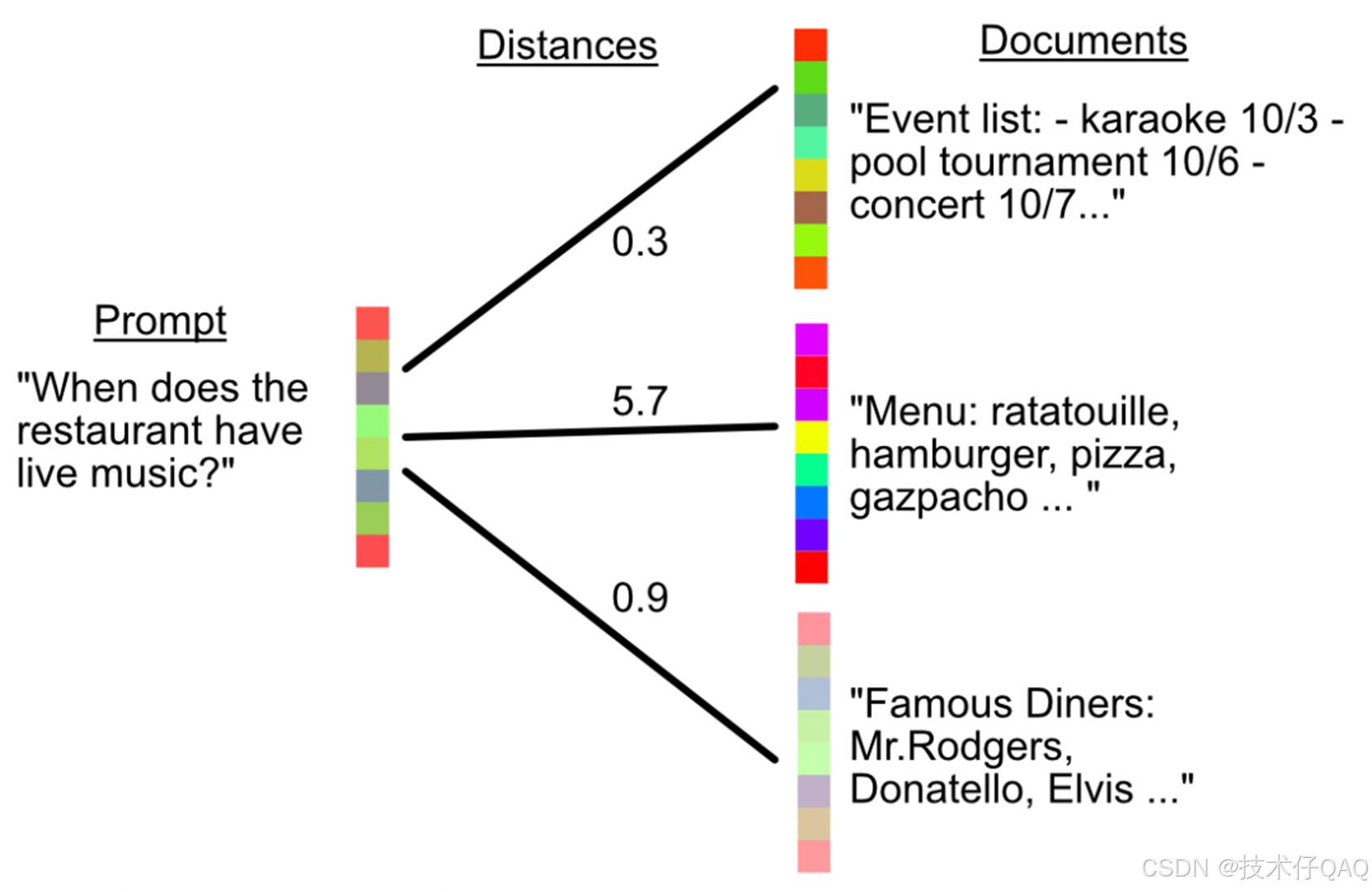
同样的,在构建多模态RAG时,最关键的也是为多模态数据构建索引,以及如何检索相关数据。索引构建同样需要借助embedding模型,但有一个问题,多模态数据各自所处的向量空间不同,该使用什么方法将两者的向量联系在一起,就又涉及到了深度学习中的多模态。
二、多模态
在数据科学中,“模态”本质上是一种数据类型。文本、图像、音频、视频、表格,这些都可以被视为不同的“模态”。长期以来,这些不同类型的数据被视为彼此独立,需要分别创建一个模型来处理文本,一个模型来处理视频等。但随着多模态模型的出现,这种传统范式已经慢慢消失,能够理解和处理多种模态的模型变得更加高效和更易获取。
多模态模型的概念通常围绕着“联合embedding”的想法。基本上,联合embedding是一种模型建模策略,强制模型同时学习不同类型的数据。在这一领域的里程碑论文之一是 CLIP,它能够执行与图像和文本相关的任务。
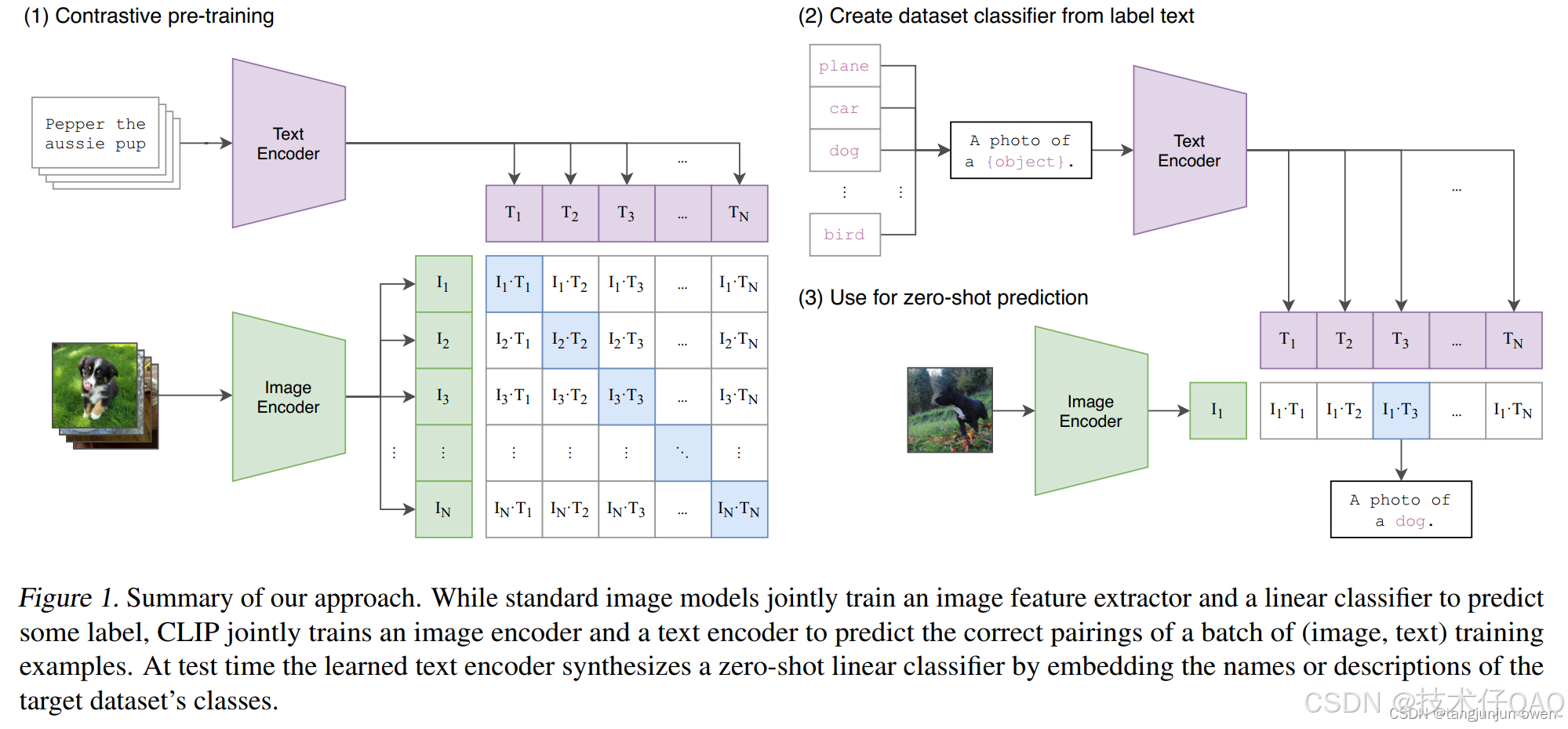
CLIP主要包括两个部分:1)图像编码器:通常采用预训练的卷积神经网络(CNN)或Vision Transformer(ViT)作为图像编码器。这个编码器负责将输入图像转换为一个高维的向量表示。2)文本编码器:文本编码器一般采用Transformer结构,将输入文本(例如描述图像的句子)转换为一个高维的向量表示。
这两个编码器的输出是嵌入空间中的向量,CLIP将这两个空间进行对齐。
CLIP的训练方法:1)数据集:CLIP使用了一个大规模的图像-文本对数据集进行训练。这些数据对来自于互联网,涵盖了丰富的视觉和语言信息。2)训练方法:CLIP采用对比学习的方式进行训练,具体而言,对于每一个图像-文本对,模型会计算图像和文本之间的相似度,训练目标是最大化匹配的图像和文本对的相似度,同时最小化不匹配对的相似度。
三、多模态RAG
了解多模态的基本概念后,应用到多模态RAG的关键就是如何对齐不同模态数据的向量空间,以支持向量检索。目前,有三种流行的方法可以实现多模态RAG。
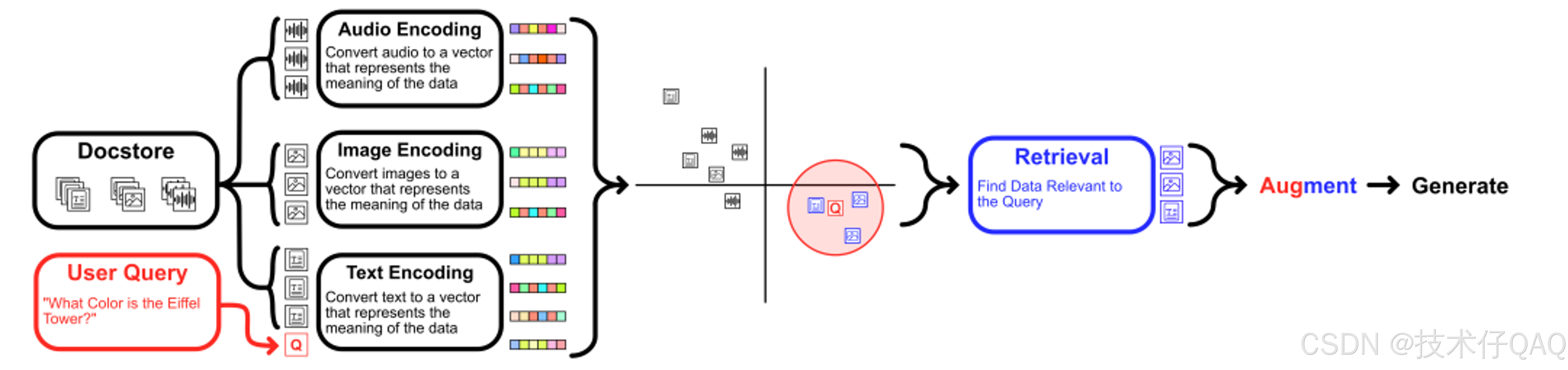
方法一:共享向量空间
类CLIP的方法,对齐不同模态数据的向量空间,然后使用多模态数据的向量构建索引和检索,检索出所有和用户查询最相关的数据。
方法二:统一模态
首先将所有模态转化成相同模态,通常是文本,在很多需要精确策略的时候经常会使用该方法(我们称之为“多模态转换”)。虽然这种策略在理论上存在着信息在转换过程中可能会丢失的微妙风险,但实际上我们发现,对于许多应用来说,这种方法可以实现非常高质量的结果,而复杂度相对较低。另外就是方便debug。

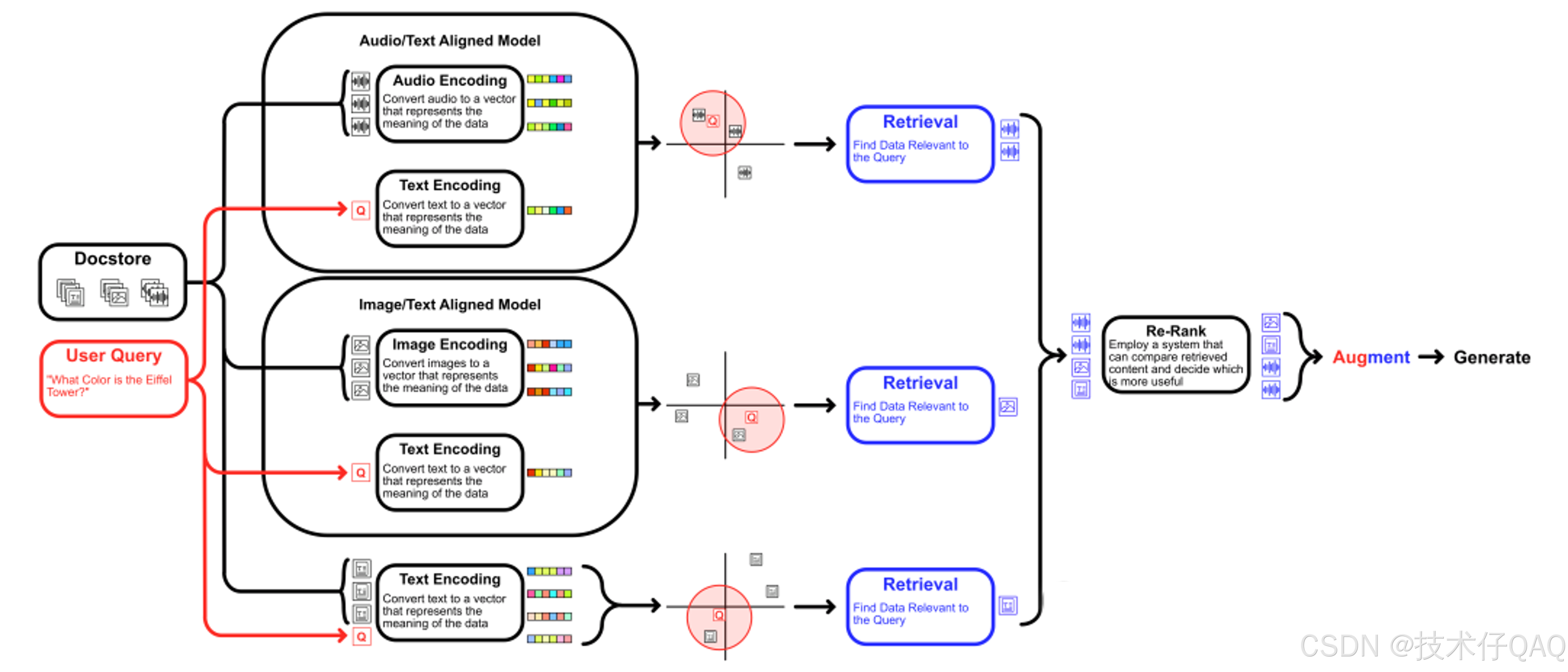
方法三:分离检索
第三种方法是使用一系列设计用于处理不同形式的模型。在这种情况下,在不同的模型之间进行多次检索,然后将它们的结果合并。
四、多模态RAG代码示例
git:https://github.com/DanielWarfield1/MLWritingAndResearch.git
在对多模态 RAG 有了一个大致的了解后,用一个简单的例子来实验一下:
-
一个音频文件,例如竖琴演奏家是 Turlough O'Carolan
-
一张包含洛伦兹吸引子图片的图像
-
《西线无战事》维基百科文章的摘录
利用这些数据,构建一个简单的多模态RAG系统,回答“谁是我的最喜欢的竖琴演奏家?”
我们采用方法二,使用Audio to Text模型将Audio转换为Text,然后使用类CLIP的模型编码image和text,使用余弦相似度用于检索。
下载保存图像文件:
import requests
from PIL import Image
from IPython.display import display
import os
# Loading image
url = 'https://github.com/DanielWarfield1/MLWritingAndResearch/blob/main/Assets/Multimodal/MMRAG/Lorenz_Ro28-200px.png?raw=true'
response = requests.get(url, stream=True)
image = Image.open(response.raw).convert('RGB')
# Save the image locally as JPG
save_path = 'image.jpg'
image.save(save_path, 'JPEG')
display(image)下载保存音频文件:
"""Downloading audio waveform from multimodal dataset
"""
from pydub import AudioSegment
import numpy as np
import io
import matplotlib.pyplot as plt
import wave
import requests
url = "https://github.com/DanielWarfield1/MLWritingAndResearch/blob/main/Assets/Multimodal/MMRAG/audio.mp3?raw=true" # 音频文件的URL
response = requests.get(url) # 发送HTTP请求获取音频文件
audio_data = io.BytesIO(response.content) # 将音频文件内容存储在内存中
audio_segment = AudioSegment.from_file(audio_data, format="mp3") # 从内存中读取MP3格式的音频文件
# 将采样率降到16000 Hz
# (这是必要的,因为未来的模型需要它在16000Hz)
sampling_rate = 16000 # 设定采样率为16000Hz
audio_segment = audio_segment.set_frame_rate(sampling_rate) # 设置音频段的采样率
wav_data = io.BytesIO() # 创建一个内存字节流对象
audio_segment.export(wav_data, format="wav") # 将音频段导出为WAV格式并存储在内存中
wav_data.seek(0) # 将内存字节流的指针重置到开始位置
wav_file = wave.open(wav_data, 'rb') # 打开内存中的WAV文件
frames = wav_file.readframes(-1) # 读取所有音频帧
audio_waveform = np.frombuffer(frames, dtype=np.int16).astype(np.float32) # 将音频帧转换为浮点数数组
plt.plot(audio_waveform) # 绘制音频波形图
plt.title("Audio Waveform") # 设置图表标题
plt.xlabel("Sample Index") # 设置X轴标签
plt.ylabel("Amplitude") # 设置Y轴标签
plt.show() # 显示图表下载文本
"""Downloading text from multimodal dataset
"""
import requests
# URL of the text file
url = "https://github.com/DanielWarfield1/MLWritingAndResearch/blob/main/Assets/Multimodal/MMRAG/Wiki.txt?raw=true"
response = requests.get(url)
text_data = response.text
# truncating length for compatability with an encoder that accepts a small context
# a different encoder could be used which allows for larger context lengths
text_data = text_data[:300]
print(text_data)使用 s2t-medium-librispeech-asr模型将预处理的Audio转化为Text
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
#the model that generates text based on speech audio
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-librispeech-asr")
#a processor that gets everything set up
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-librispeech-asr")
#passing through model
inputs = processor(audio_waveform, sampling_rate=sampling_rate, return_tensors="pt")
generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
#turning model output into text
audio_transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]Query:
query = 'who is my favorite harpist?'
Embedding data
# Embedding Data
Using a clip style model, which can embed images and text, to embed the image, text, and audio grounded in text.
from transformers import CLIPProcessor, CLIPModel
# Load the model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Encode the image
inputs = processor(images=image, return_tensors="pt")
image_embeddings = model.get_image_features(**inputs)
# Encode the text
inputs = processor(text=[query, audio_transcription, text_data], return_tensors="pt", padding=True)
text_embeddings = model.get_text_features(**inputs)
# Print or use the embeddings
print("Image Embeddings:", image_embeddings)
print("Text Embeddings:", text_embeddings)Calculating cosine similarity
image_embedding = image_embeddings[0]
query_embedding = text_embeddings[0]
audio_embedding = text_embeddings[1]
text_embedding = text_embeddings[2]
import torch
from torch.nn.functional import cosine_similarity
# Calculate cosine similarity
cos_sim_query_image = cosine_similarity(query_embedding.unsqueeze(0), image_embedding.unsqueeze(0)).item()
cos_sim_query_audio = cosine_similarity(query_embedding.unsqueeze(0), audio_embedding.unsqueeze(0)).item()
cos_sim_query_text = cosine_similarity(query_embedding.unsqueeze(0), text_embedding.unsqueeze(0)).item()
# Print the results
print(f"Cosine Similarity between query and image embedding: {cos_sim_query_image:.4f}")
print(f"Cosine Similarity between query and audio embedding: {cos_sim_query_audio:.4f}")
print(f"Cosine Similarity between query and text embedding: {cos_sim_query_text:.4f}")RAG根据最相关结果进行回答:
similarities = [cos_sim_query_image, cos_sim_query_audio, cos_sim_query_text]
result = None
if max(similarities) == cos_sim_query_image:
#image most similar, augmenting with image
model = genai.GenerativeModel('gemini-1.5-pro')
result = model.generate_content([query, Image.open('image.jpeg')])
elif max(similarities) == cos_sim_query_audio:
#audio most similar, augmenting with audio. Here I'm using the transcript
#rather than the audio itself
model = genai.GenerativeModel('gemini-1.5-pro')
result = model.generate_content([query, 'audio transcript (may have inaccuracies): '+ audio_transcription])
elif max(similarities) == cos_sim_query_text:
#text most similar, augmenting with text
model = genai.GenerativeModel('gemini-1.5-pro')
result = model.generate_content([query, text_data])
print(result.text)result.text = "It sounds like you're trying to say **Turlough O'Carolan**. He was a famous Irish harpist and composer. It's easy to get his name a little mixed up - it's quite unique!"
总结
多模态RAG的难点和多模态本身类似,还是如何对其不同模态数据的表示,以保证和用户查询的相似度计算的正确率。好在目前有很多开源的Audio to Text模型、Image to Text模型和 Image-Text双模态模型,效果也都很不错。如果需要针对具体场景的多模态模型,可以根据数据进行进一步微调。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 52
52 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)