软件设计师备考笔记(炸薯条的视频)
摘要:将发送的明文进行Hash算法后得到摘要放在密文后一起发送过去,与接收方解密后的明文进行相同的hash算法得到的摘要进行对比,如果一致,则没有篡改,否则有篡改。数字签名:用发送方的私钥签名,用发送方的公钥验证消息的真实性数字签名可以验证消息的真实性、发送方不可否认。
视频还没看完(软件工程上下、算法、试题四),排版还没拍好,2022上半年考试凉了,下半年又凉了。哎,明年再战吧
计算机系统是由硬件和软件组成的。计算机的基本硬件系统由运算器、控制器、存储器、输入设备和输出设备 5 大部件组成。运算器、控制器等部件被集成在一起统称为中央处理器(Central Processing Unit, CPU)。CPU是硬件系统的核心。
中央处理单元(CPU)是计算机系统的核心部件,它负责获取程序指令,对指令进行译码并加以执行。
CPU功能(🔺)
①程序控制
②操作控制
③时间控制
④数据控制
①②③属于控制器的功能,④属于运算器的功能。
运算器由 算术逻辑单元(Arithmetic and Logic Unit,ALU)、累加寄存器、数据缓冲寄存器 和 状态条件寄存器等组成。
运算器有如下两个功能:
(1)执行所有的算数运算
(2)执行所有的逻辑运算并进行逻辑测试。
计算机网络对用户“透明”是什么意思?
1、“透明”一次在计算机领域通常是指存在但不干预。即:计算机中存在的,但对于某些人员而言又不需要了解的东西,这就是计算机所指的透明性.简单的说就是:计算机中存在,但你不需要了解的.
2、用户不需要关心具体的网络传输、网络控制、网络通讯、网络会话等,对用户来说就是透明的、不可见的。用户只需要使用即可。
在计算机中,这里的"透明"(Transparency)是常用的一个专业术语,表示实际存在,但在某个角度看好像没有。
汇编程序员可以通过指定待执行指令的地址来设置PC(程序计数器)的值,状态寄存器、通用寄存器只有为汇编程序员可见,才能实现编程。而IR(指令寄存器)、MAR(存储地址寄存器)、MDR(存储器数据寄存器)是CPU的内部工作寄存器,对程序员均不可见,所以它们被称为“透明”寄存器。
指令寄存器是CPU中的关键寄存器,其内容为正在执行的指令,显然其位数取决于指令字长。
CPU首先从程序计数器(PC)获得需要执行的指令地址,从内存(或高速缓存)读取到的指令则暂存在指令寄存器(IR), 然后进行分析和执行。
计算机基本单位
最小数据单位:位或比特(b,bit)
字节(byte,B) 1B = 8bit
千字节(KB) 1KB = 1024B
兆字节(MB) 1MB = 1024B
吉字节(GB) 1GB = 1024MB
太字节(TB) 1TB = 1024GB
计算机最小的数据单位:b
计算机最小的存储单位:B
十进制(D)
二进制(B)
八进制(O)
十六进制(H)
按权展开求和 n进制 → 十进制
除n取余法 十进制 → n进制
n进制加法:逢n进1
原码表示法和补码表示法是计算机中用于表示数据的两种编码方法,在计算机系统中常采用补码来表示和运算数据,原因是采用补码可以简化计算机运算部件的设计。
因为使用补码表示数据时,可以将符号位和其它位统一处理,减法也可按 加法来处理,从而简化运算部件的设计。

码距:一个编码方案中任意两个合法编码之间至少有多少个二进制位不同
码距=2有检错能力,码距≥3才可能有纠错能力
也就是一个校验码要想能够检错和纠错那么它的码距至少是3
RISC与CISC
| RISC 精简指令集计算机 | CISC 复杂指令计算机 | |
|---|---|---|
| 指令种类 | 少、精简 | 多、丰富 |
| 指令复杂度 | 低(简单) | 高(复杂) |
| 指令长度 | 固定 | 变化 |
| 寻址方式 | 少 | 复杂多样 |
| 实现(译码)方式 | 硬布线控制逻辑(组合逻辑控制器) | 微程序控制技术 |
| 通用寄存器数量 | 多、大量 | 一般 |
| 流水线技术 | 支持 | 不支持 |
流水线公式
n为总指令数,流水线执行时间 = 一条指令执行的时间 + 最长时间段 × \times × (n - 1)
加速比 = 不采用流水线的执行时间 采用流水线的执行时间 加速比 = \frac{不采用流水线的执行时间}{采用流水线的执行时间} 加速比=采用流水线的执行时间不采用流水线的执行时间
流水线的操作周期为最长操作时间
流水线的吞吐率是最长流水段操作时间的倒数。
顺序执行时间=一条指令执行的时间×总指令数
连续输入 n 条指令的吞吐率 = 总指令数 总指令数执行的时间 连续输入n条指令的吞吐率= \frac{总指令数}{总指令数执行的时间} 连续输入n条指令的吞吐率=总指令数执行的时间总指令数
存储器
按访问方式可分为 按地址访问的存储器与按内容访问的存储器。
相联存储器是按内容访问的存储器
按寻址方式分类可分为随机存储器、顺序存储器和直接存储器
虚拟存储器由主存与辅存组成
DRAM(动态随机存储器)构成主存 DRAM需要周期性地刷新来达到保持信息的目的。
SRAM(静态随机存储器)构成Cache
闪存(FLASH)可以理解为U盘,故掉电后信息不会丢失。闪存是以块为单位进行删除的。闪存式EPROM的一种类型,可以代替ROM存储器。闪存不能代替主存
计算机采用分级存储体系的主要目的是为了解决 存储容量、成本和速度之间的矛盾 问题。
访问速度从快到慢:CPU内部通用寄存器>Cache>主存储器(内存)>联机磁盘存储器(外存)>脱机光盘、磁盘存储器。
Cache
直接映像:冲突多,关系固定
全相联映像:冲突少,关系不固定,主存中的一块可以映射到Cache中的任意一块,除非Cache满了才需要替换。
组相联影响:冲突较少,是直接映像与全相联映像的折中
Cache与主存的地址映射由硬件自动完成。因为cache对程序员/用户来说是透明的。
中断
中断向量:提供中断服务程序的入口地址
中断响应时间:从发出中断请求到开始进入中断处理程序
保存现场:为了正确返回原程序继续执行
输入输出(I/O)控制方式

总线
微机中的总线分为数据总线、地址总线和控制总线三类。
内存容量决定地址总线的宽度(单位为字节的容量转成2次方的指数)
字长决定数据总线的宽度
1Hz等于100次/秒
单总线(Uni Bus)系统是最简单的总线系统,是指仅由一条总线构成的计算机系统。单总线结构在一个总线上适应不同种类的设备,通用性强,但是无法达到高的性能要求,而专用总线则可以与连接设备实现最佳匹配。
PCI总线是并行内总线,SCSI总线是并行外总线。
加密技术与认证技术
防止第三方 窃取、篡改、假冒、否认
加密技术
1、对称加密(私有密钥加密):加密和解密是同一把密钥只有一把密钥。
密钥分发存在缺陷,如果通过网络发送不能保证密钥只有接收方一个人拥有。
优点:①加密解密速度很快 ②适合加量大量明文数据。
2、非对称加密(公开密钥加密):加密和解密不是同一把密钥一共有两把密钥,分别是公钥和私钥。
用公钥加密只能用私钥解密;
用私钥加密只能用公钥解密;
不能通过一把推出另一把
用接受方的公钥加密明文可以实现防止窃听的效果。
密钥分发没有缺陷:①加密解密速度很慢
3、混合加密
摘要与数字签名
摘要:将发送的明文进行Hash算法后得到摘要放在密文后一起发送过去,与接收方解密后的明文进行相同的hash算法得到的摘要进行对比,如果一致,则没有篡改,否则有篡改。
数字签名:
用发送方的私钥签名,用发送方的公钥验证消息的真实性
数字签名可以验证消息的真实性、发送方不可否认
数字证书(认证)
用CA机构的私钥签名颁发数字证书,用CA机构的公钥来数字证书(签名)的真伪性
数字证书可以确认网站的合法性,用户的身份,报文发送者和接收者的真实性。
数字证书处理主动攻击。
公加验、私解签
加密算法

MD5对任意长度的输入计算得到的结果长度为128位。
可靠性公式
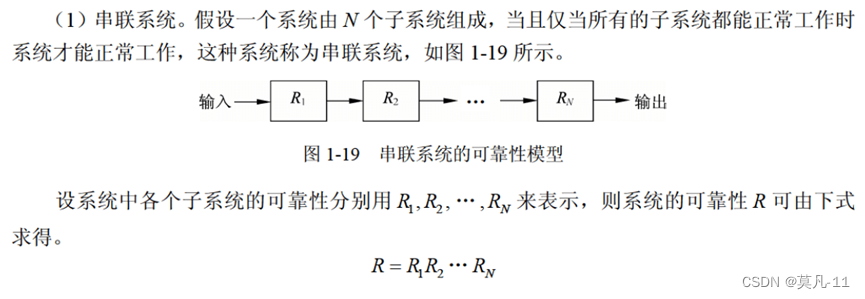

被动攻击:流量分析、会话拦截
程序设计语言
低级语言和高级语言
机器语言和汇编语言为低级语言。
编译程序和解释程序
解释器:
翻译源程序时不生成独立的目标程序
解释程序和源程序要参与到程序的运行过程中
编译器:
翻译时将源程序翻译成独立保存的目标程序
机器上运行的是与源程序等价的目标程序,
源程序和编译程序都不再参与目标程序的运行过程
传值调用与传地址调用
传值调用:
将实参的值传递给形参,实参可以是变量、常量和表达式。
不可以实现形参和实参间双向传递数据的效果
传引用(地址)调用:
将实参的地址传递给形参,形参必须有地址,实参不能是常量(值),表达式。
可以实现形参和实参间双向传递数据的效果,即改变形参的值同时也改变了实参的值。
编译程序翻译阶段
编译方式:词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成
解释方式:词法分析、语法分析、语义分析
编译器和解释器都不可省略词法分析、语法分析、语义分析且顺序不可交换
编译器方式中中间代码生成和代码优化不是必要,可省略。
即编译器方式可以在词法分析、语法分析、语义分析阶段后直接生成目标代码
解释器:
翻译源程序时不生成独立的目标程序
解释程序和源程序要参与到程序的运行过程中
编译器:
翻译时将源程序翻译成独立保存的目标程序
机器上运行的是与源程序等价的目标程序,
源程序和编译程序都不再参与目标程序的运行过程
符号表
在对高级语言源程序进行编译或解释处理的过程中,需要不断收集、记录和使用源程序中一些相关符号的类型和特征等信息,并将其存入符号表中。
记录源程序中各个字符的必要信息,以辅助语义的正确性检查和代码生成。
词法分析
输入:源程序;输出:记号流
词法分析阶段的主要作用是:
分析构成程序的字符;及由字符按照构造规则构成的符号是否符合程序语言的规定
语法分析
输入:记号流;输出:语法树(分析树)
语法分析阶段可以发现程序中所有的语法错误
语法分析阶段的主要作用是:
对各条语句的结构进行合法性分析;分析程序中的句子结构是否正确
语义分析
输入:语法树(分析树)
语义分析阶段的主要作用是进行类型分析和检查
语法分析阶段可以发现程序中的所有语法错误
语义分析阶段不能发现程序中所有的语义错误
语义分析阶段可以发现静态语义错误
不能发现动态语义错误,动态语义错误运行时才能发现
目标代码生成
目标代码生成阶段的工作与具体的机器密切相关
寄存器的分配工作是处于目标代码生成阶段
中间代码
常见的中间代码有:后缀式、三地址码、三元式、四元式和树(图)等形式。
中间代码与具体的机器无关(不依赖具体的机器),可以将不同的高级程序语言翻译成同一种中间代码。中间代码可以跨平台。
因为与具体的机器无关,使用中间代码有利于进行与机器无关的优化处理和提高编译程序的可移植性。
正规式
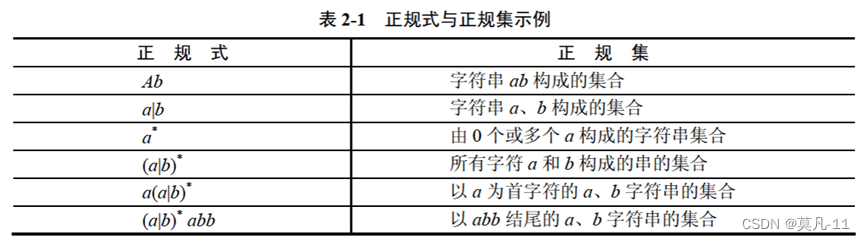
有限自动机
有限自动机是词法分析的一个工具,它能正确地识别正规集。
确定的有限自动机(DFA):对每一个状态(状态如1和0两个状态)来说识别字符后只有一个转移状态
不确定的有限自动机(NFA):对每一个状态来说识别字符后有一个以上的转移状态
初态为一个圆圈和一个箭头指向,终态为双环圆。
正规式表示正规集,这个集合应该为有限自动机的子集。
上下文无关文法
大多数程序设计语言地语法规则用上下文无关文法描述。
中缀、后缀表达式转换
中缀式(算数表达式):a + b
后缀式(逆波兰式):ab+
后缀式利用栈进行求值
语法树的后缀式为后序遍历、中缀式为中序遍历
优先级
1、( )
2、×、/
3、+、-
中缀到后缀是从右往左 碰到符号 就是a?b→ab?
后缀到中缀是从左往右 碰到符号 就是ab?→a?b
杂题选讲
1、编译是将高级语言源程序翻译成机器语言程序(汇编形式或机器代码形式),反编译是编译的逆过程。反编译通常不能把可执行文件还原成高级语言源代码,只能转换成功能上等价的汇编程序。
2、脚本语言属于动态语言,动态语言都是解释性语言,不管它们是否是面向对象的语言。
3、链表中的结点空间需要程序员根据需要申请和释放,因此,数据空间应采用堆存储分配策略。
4、HTML、XML、WML(是XML的子集)是标记语言;PHP是脚本语言。
5、汇编语言源程序中的指令语句将被翻译成机器代码即可。
汇编程序以汇编语言源程序为输入,以机器语言表示的目标程序为输出。
汇编语言的指令语句必须具有操作码字段,可以没有操作数字段。
6、脚本语言又被称为扩建的语言,或者动态语言,是一种编程语言,通常以文本(如ASCII)保存,只在被调用时进行解释或编译。Python是一种脚本语言。
7、编译过程中为变量分配存储单元所用的地址是逻辑地址,程序运行时再映射为物理地址。
8、正规集的 “*” 只能控制一个数。正规集可用正规式表示,用有限自动机识别。
9、PHP(超文本预处理器)是一种通用开源脚本语言,它将程序嵌入到HTML文档中去执行,从而产生动态脚本。
10、C语言 程序运行时的用户内存空间一般划分为代码区、静态数据区、栈区和堆区,其中栈区和堆区也称为动态数据区。全局变量的存储空间在静态数据区。
11、对高级语言源程序进行编译(或解释)方式的翻译过程中,语法分析的任务是根据语言的语法规则,分析单词串是否构成短语和句子,即表达式、语句和程序等基本语言结构,同时检查和处理程序中的语法错误。程序设计语言的绝大多数语法规则可以采用上下文无关文法进行描述。语法分析方式有多种,根据产生语法树的方向,可分为 自下而上(自底向上) 和 自上而下(自顶向下) 两类。递归下降分析法和预测分析法是常用的自顶向下分析法;移进——归约分析法、算符优先分析法 和 LR分析法 属于自底向上的语法分析法。有多种语义分析方法,语法制导翻译是一种静态语义分析方法(编译过程中的语义分析都是静态语义,运行时才有动态语义)。
12、脚本语言一般运行在解释器或虚拟机中,便于移植,开发效率较高。
13、在源程序中,可由用户(程序员)为变量、函数和数据类型(typedef能够为变量类型重命名)等命名。
14、C/C++是编译型程序设计语言,常用于进行系统级软件(如:操作系统)的开发。
15、程序设计语言分类
①命令式和结构化程序设计语言(Fortan、PASCAL、C语言)
②面向对象的程序设计语言(C++、Java、Smalltalk)
③函数式程序设计语言(LISP、Haskell、Scala、Scheme、APL)
④逻辑型程序设计语言(PROLOG)
16、用C/C++语言为某个应用编写的程序,经过 预处理、编译、汇编、链接后形成可知性程序。
17、Java语言符合的特征有 采用即时编译、对象在堆空间分配 和 自动的垃圾回受处理。
知识产权
著作权
著作权包括著作人身权和著作财产权,主要记住人身权:发表权、署名权、修改权、保护作品完整权。题目的选项除了这四个以外都是财产权。
著作权权利中:署名权、修改权、保护作品完整权不受时间限制,受到永久保护。
发表权的保护期限为作者的终生及死后的50年。
专利地域性
在中国申请的专利只在中国收到保护,在其它国家不受保护。
软件著作权
《中华人民共和国著作权法》和《计算机软件保护条例》(由国务院颁布)是构成我国保护计算机软件著作权的两个基本法律文件。- 计算机软件著作权的权利自 软件开发完成之日 起产生。
- 计算机软件著作权的客体是指著作权法保护的计算机软件著作权的范围(受保护的对象)。
软件著作权法保护的计算机软件是指 计算机程序及其有关文档。- 计算机程序包括:源程序和目标程序
- 有关文档一般指软件文档
- 根据《计算机软件保护条例》第十一条接受他人委托开发的软件,其著作权的归属由委托人与受托人签订书面合同约定;无书面合同或者合同未作明确约定的,其著作权由受托人享有。(了解,软件著作权不一定属于软件开发者)
- 软件盗版行为是指任何未经软件著作权人许可,擅自对软件进行复制、传播,或以其他方式超出许可范围传播、销售和使用的行为。
职务作品
- 职务作品:指在任职期间为完成公司单位工作任务而开发的计算机软件作品。
- 一般来说都是为了完成公司的什么什么软件,和按公司规定完成软件文档。都是属于职务作品。
- 职务作品中任职者只享有署名权,除署名权以外的著作权权利均归公司享有。
委托开发
委托开发著作权归属:有合同约定遵守合同约定,没有合同约定著作权属于受委托方。
商业秘密权

专利权申请
专利权申请:先申请先得,同一天申请协商。(20年)
商标权

商标注册
商标权注册先申请注册先得,同一天申请先使用商标先得,都没使用过则协商
数据库
数据模型

三级模式结构
- 一个数据库可以有多个外模式,只能有一个内模式。
- 视图对应外模式、基本表对应模式、存储文件对应内模式



两级映像

关系代数
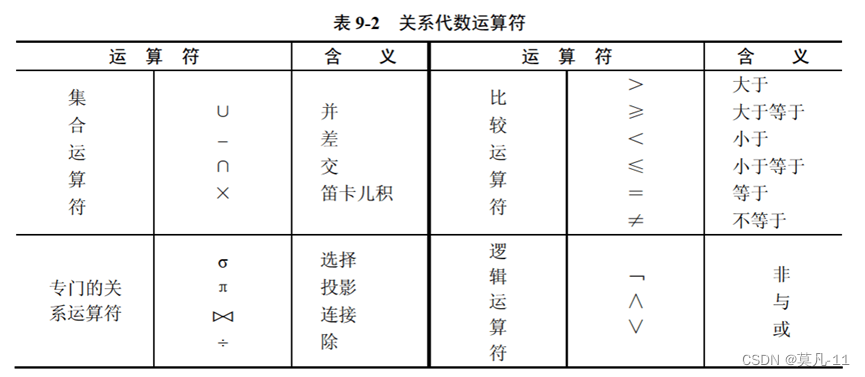
关系代数转SQL语言
SQL语言
SQL访问控制语句
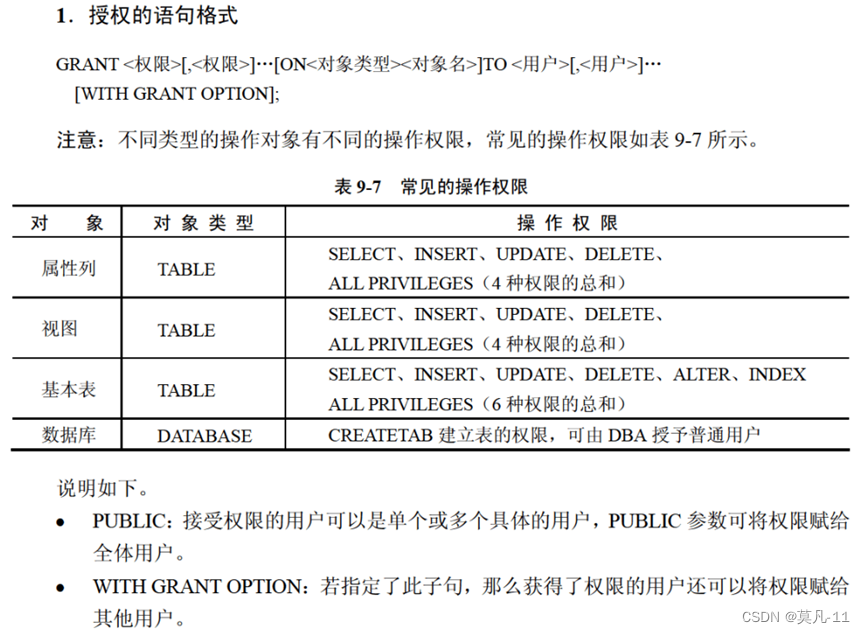
视图

索引

关系模式
关系模式R(U, F)中R表示关系名,U表示属性名,F表示函数依赖
函数依赖和属性闭包计算



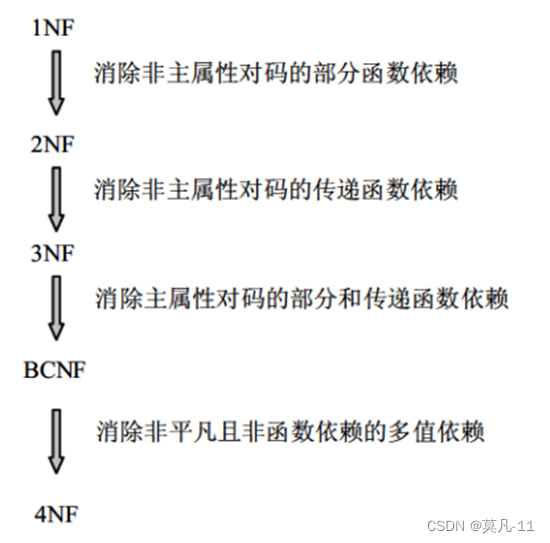
范式



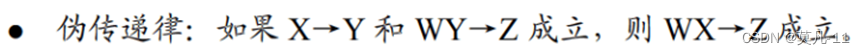
关系分解
无损连接和保存函数依赖
E-R属性

E-R图合并冲突

逻辑结构设计

事务管理

数据库的备份与恢复
封锁

分布式数据库
分片透明:指用户或应用程序不需要知道逻辑上访问的表具体是怎么分块存储的
复制透明:指采用复制技术的分布方法,用户不需要知道数据是复制到哪些节点,如何复制的。
位置透明:指用户无须知道数据存放的物理位置
逻辑透明:指用户或应用程序无需知道局部场地使用的是哪种数据模型
共享性:指数据存储在不同的结点数据共享
自治性:指每结点对本地数据都能独立管理
可用性:指当某一场地故障时,系统可以使用其他场地上的副本而不至于使整个系统瘫痪
分布性:指数据在不同场地上的存储
面向对象技术
类

对象和消息
属性别名为状态。
方法重载
封装
封装是一种信息隐藏技术。
对象是封装数据和行为的整体。
继承
子类可以拥有父类的私有属性和方法,但不能调用或访问。
子类不允许有多个直接父类,可以有多个间接父类。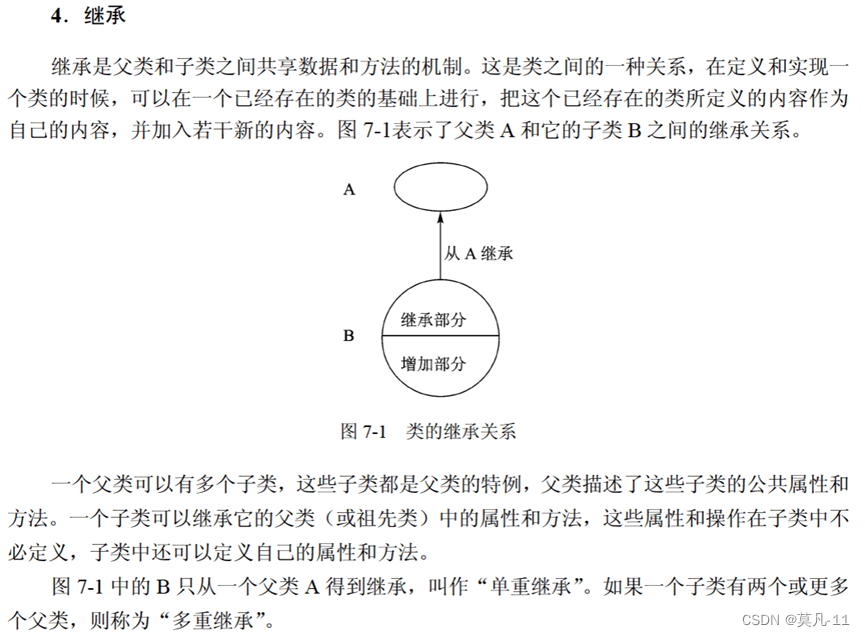
多态
编译看左边(父类),运行看右边(子类)。
静态、动态绑定
编译时静态绑定、运行时动态绑定。
面向对象设计的原则

面向对象分析
面向对象过程:分析→设计→程序设计→测试
五个阶段
①认定对象(确定问题域) ②组织对象 ③描述对象间的相互关系 ④确定对象的操作 ⑤定义对象的内部信息

面向对象设计
五个阶段
①识别类及对象 ②定义属性 ③定义服务 ④识别关系 ⑤识别包

面向对象程序设计

面向对象测试
UML
事物
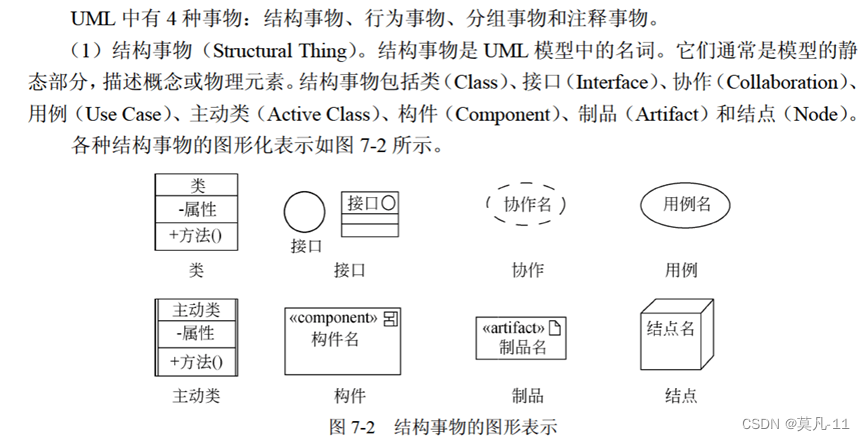


关系

关联多重度
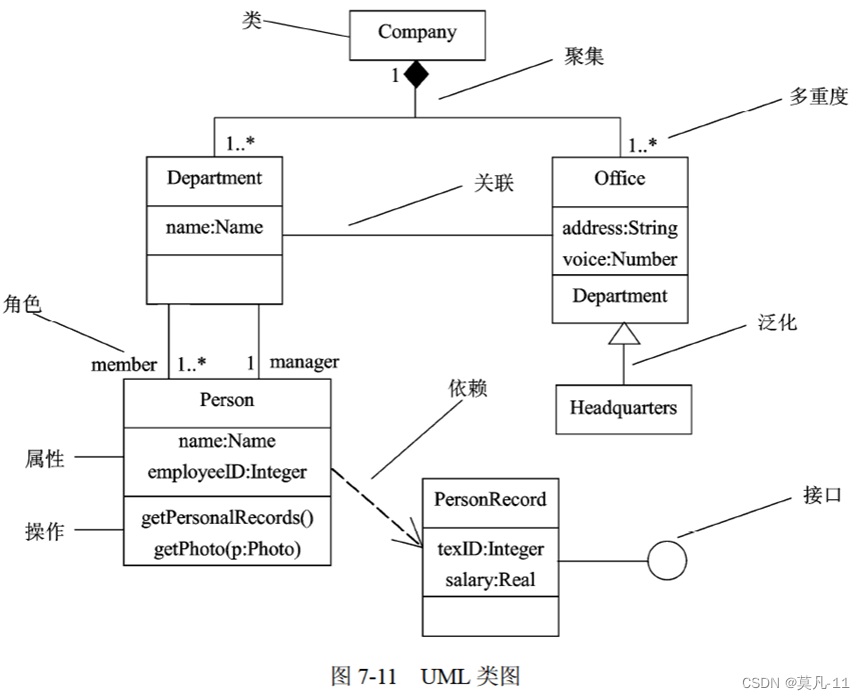
UML类图


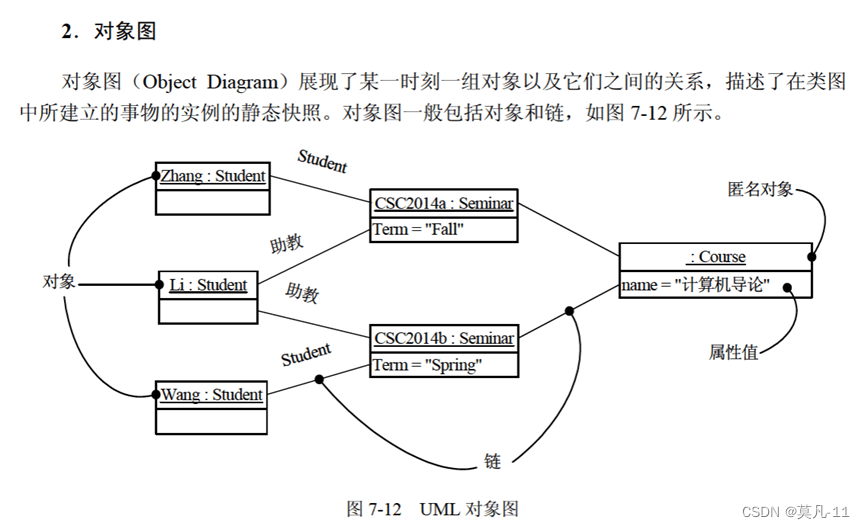
对象图

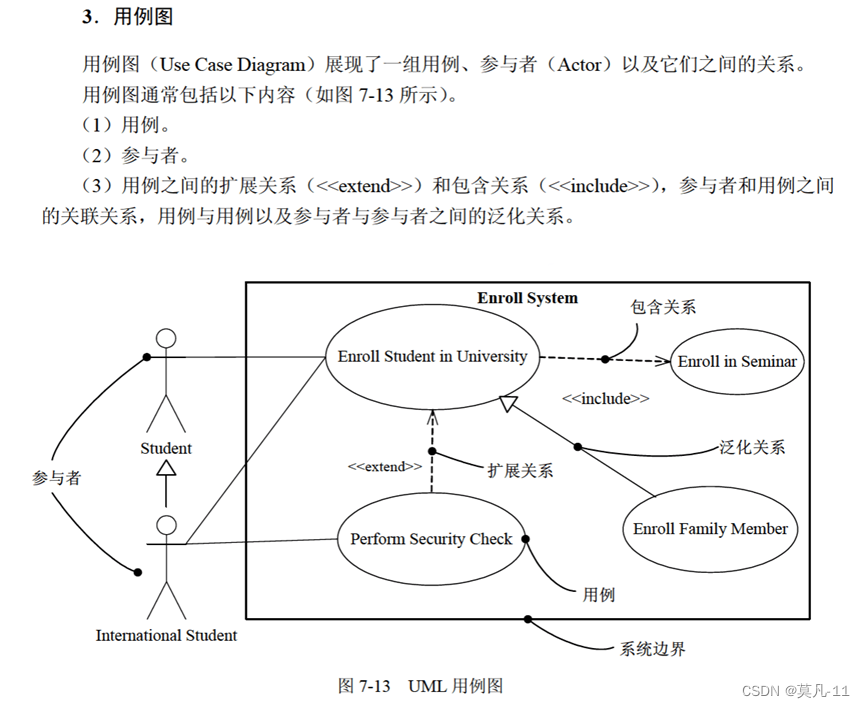
用例图
序列图
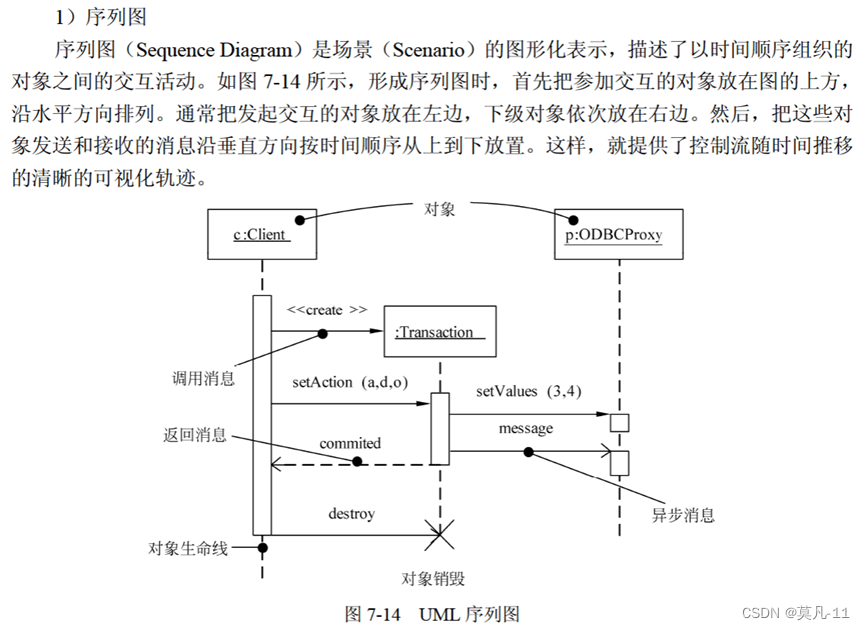

通信图
对象名:类名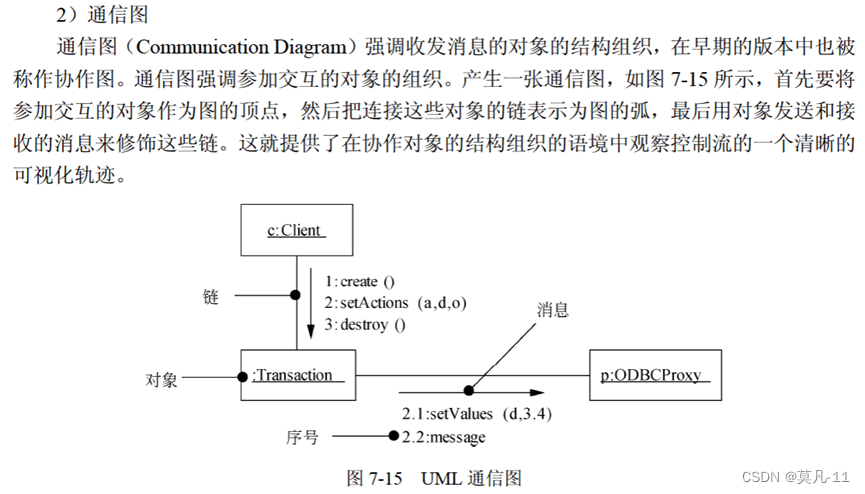

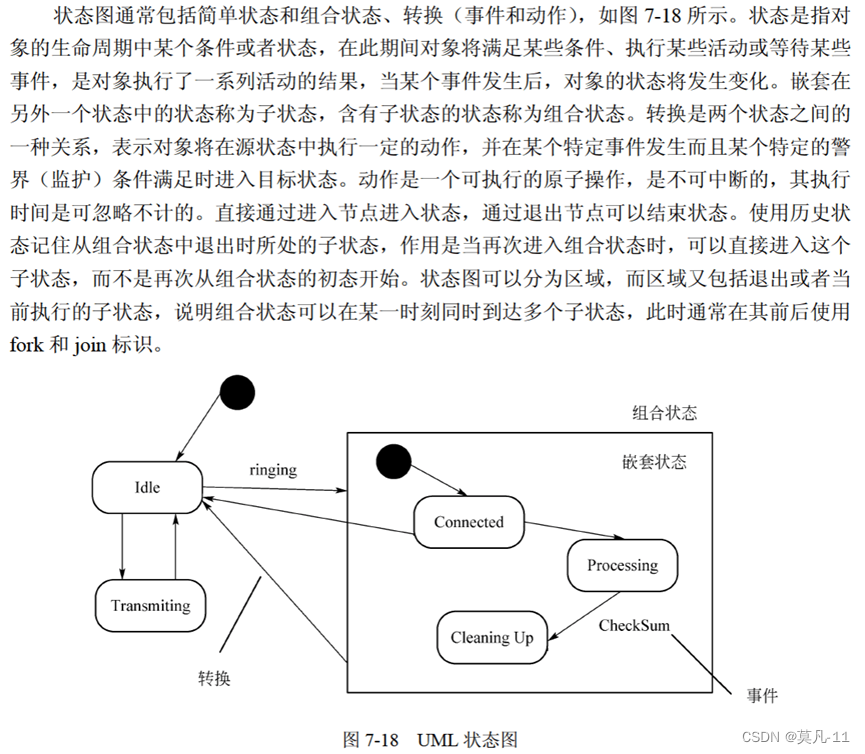
状态图
转换包括两个状态
事件触发转换(迁移)
活动(动作)可以在状态内执行
也可以在状态转换(迁移)时执行。

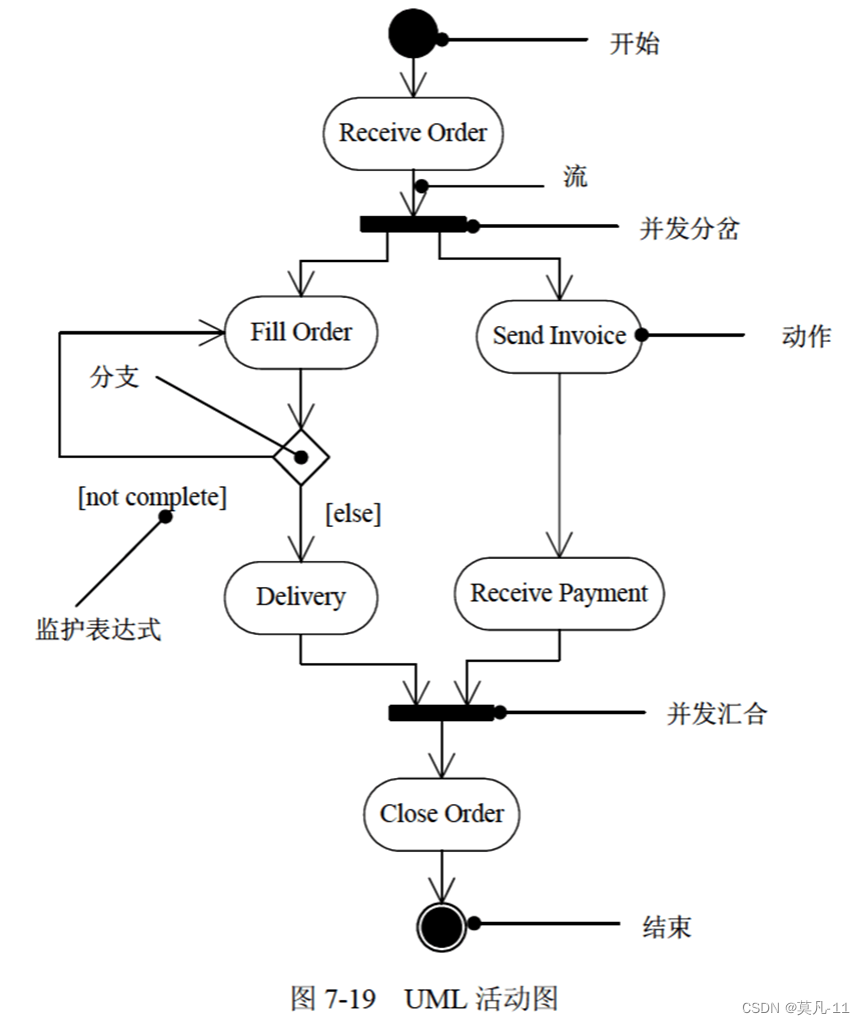
活动图


构件图(组件图)
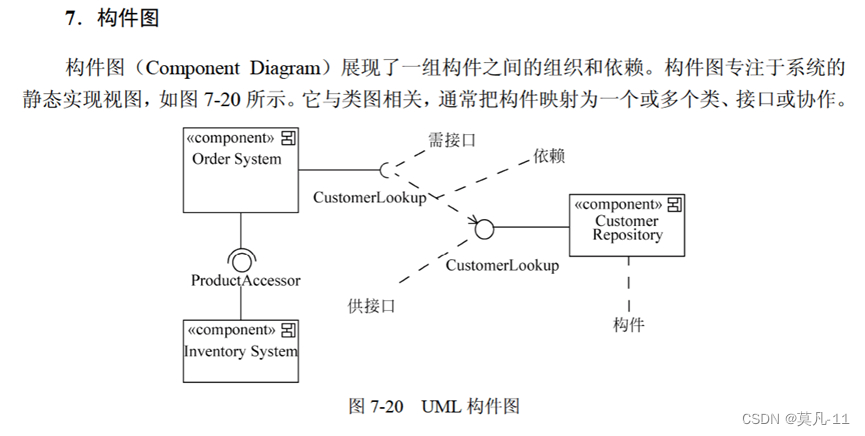
部署图
- 部署图展现了系统的软件和硬件之间的关系
- 在实施阶段使用
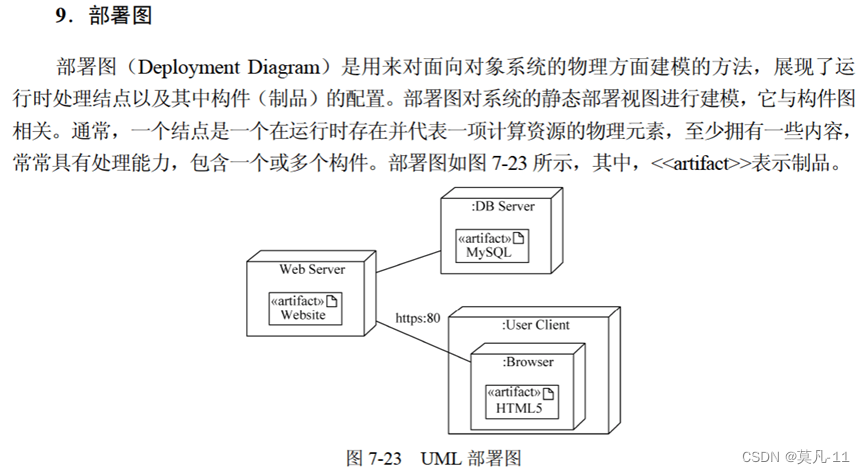
操作系统
- 操作系统设计的目的是管理计算机系统中的软硬件资源,为用户与计算机之间提供方便的接口。
- 系统级初始化主要任务是以软件初始化为主,主要进行操作系统的初始化。
- 当用户通过键盘或鼠标(I/O流)进入某应用系统时,通常最先获得键盘或鼠标输入信息的程序是中断处理程序。
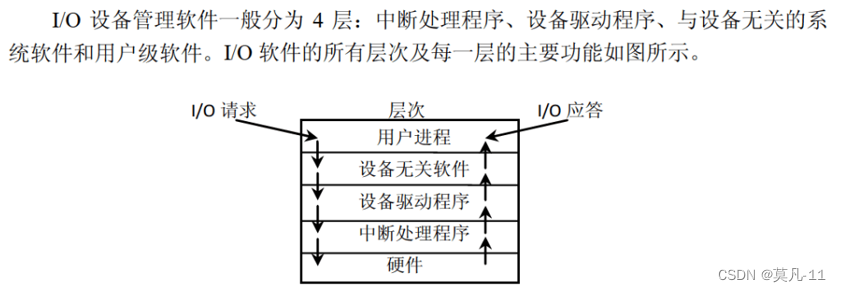
计算机系统层次结构
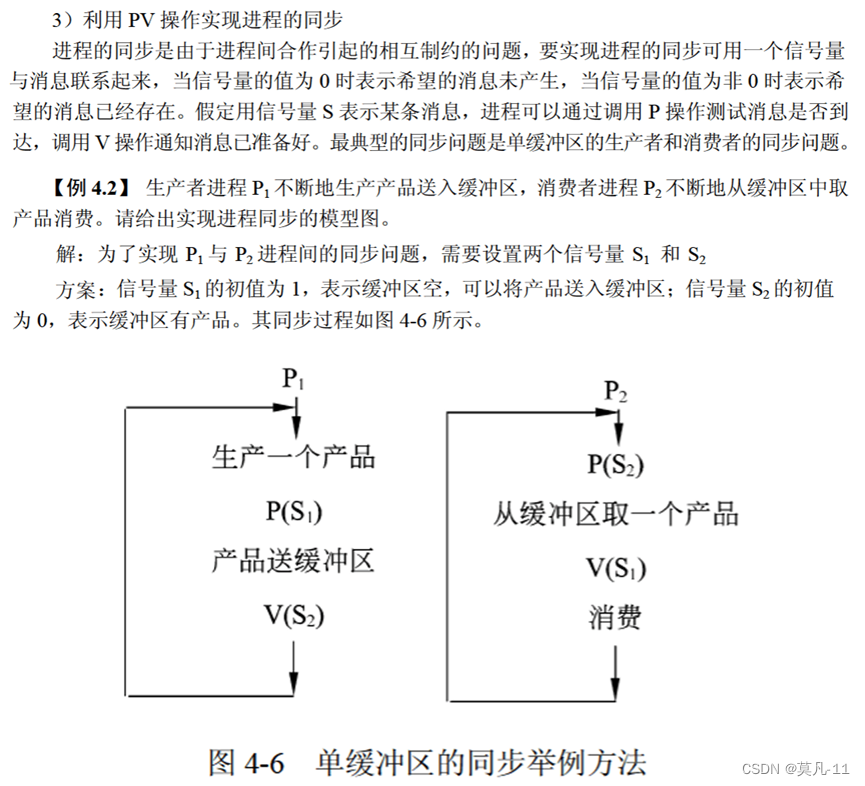
PV操作能够实现同步、互斥、前趋三种关系。
程序顺序执行
信号量
有n个箭头就有n个信号量。
P(S):S = S + 1
V(S):S = S - 1
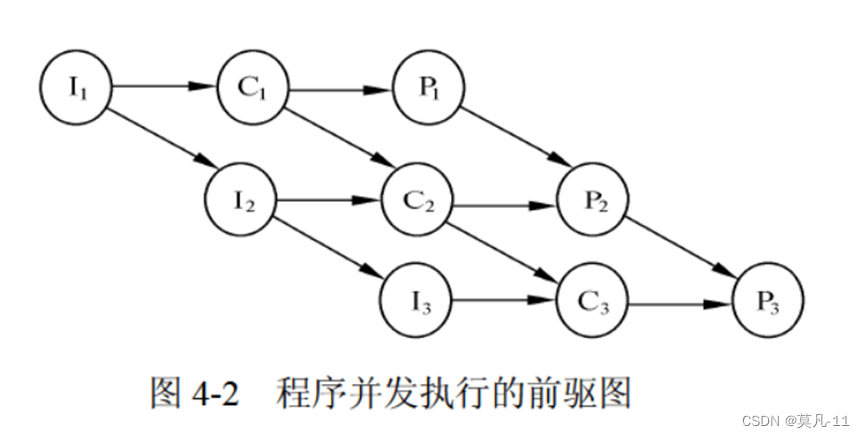
前趋图
程序并发执行
程序并发执行时的特征如下:
(1)失去了程序的封闭性
(2)程序和机器的执行程序的活动不再一一对应
(3)并发程序间的相互制约性
前驱图
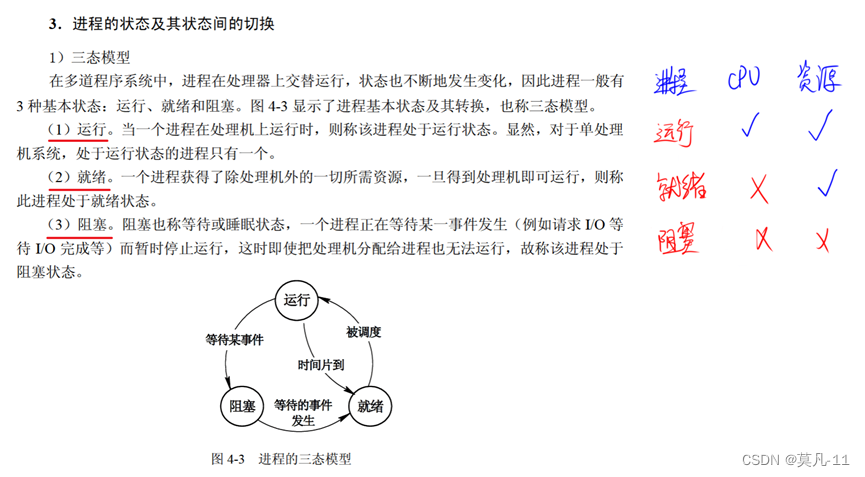
进程的三态模型
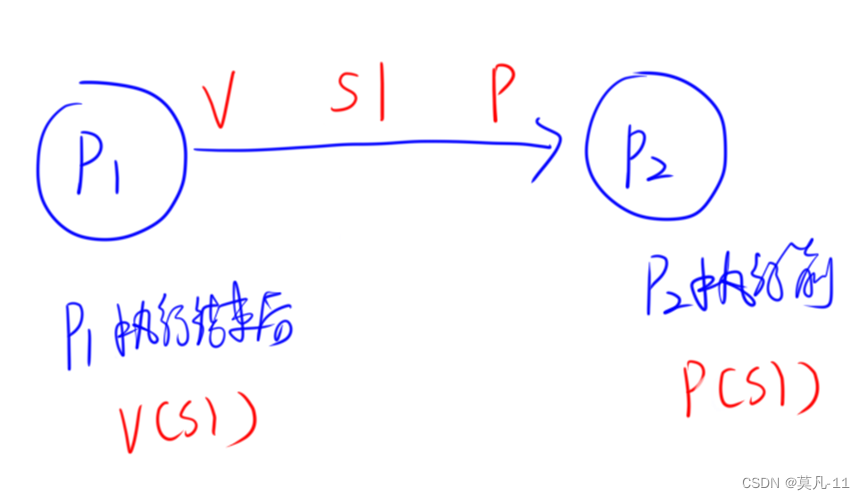
PV操作能够实现同步、互斥、前趋三种关系。
进程间的通信
信号量机制和PV操作


进程的同步与互斥

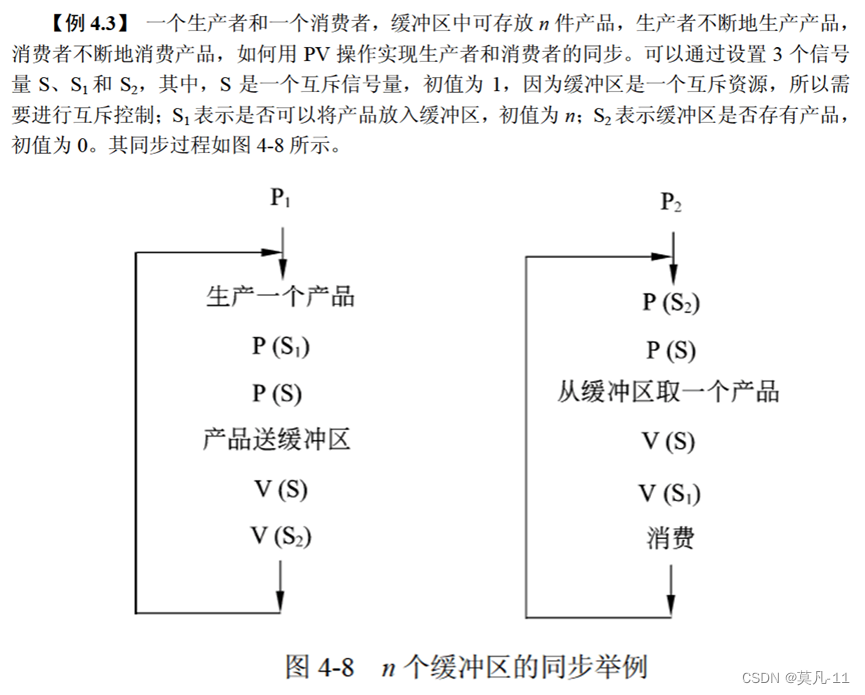
死锁

进程资源图
进程→资源表示申请;资源→进程表示分配- 先分配资源给进程,再让进程去申请资源,如果申请不到资源,那么进程就是堵塞的。
- 如果没有一个进程是非堵塞的,那么进程资源图一定是不可化简的,是死锁的。
- 如果有进程是非阻塞的,那么就有可化简的希望,要自行判断是否能够运行完所有进程。
死锁避免
线程
线程可以共享进程的所有资源,但是线程和线程之间是不可见的,即线程不能和线程共享资源。
程序局部性原理

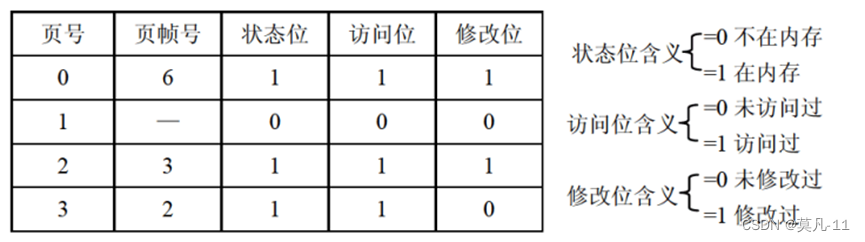
分页存储管理
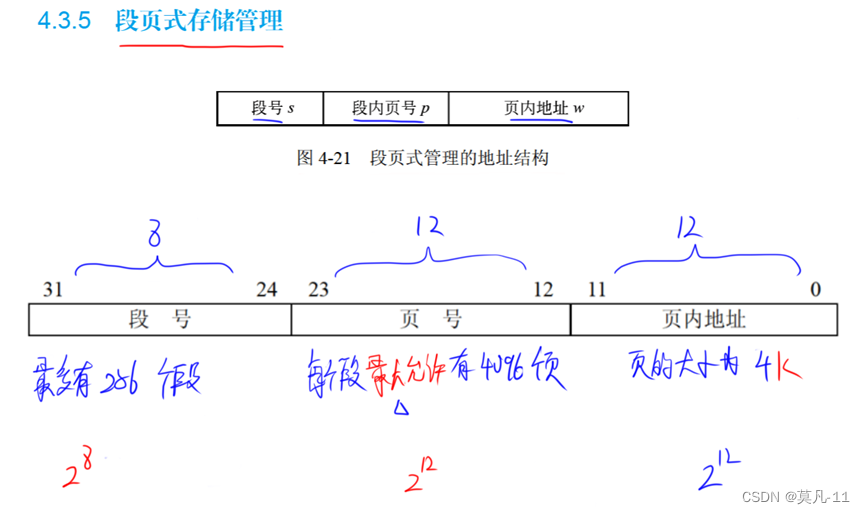
段页式存储管理
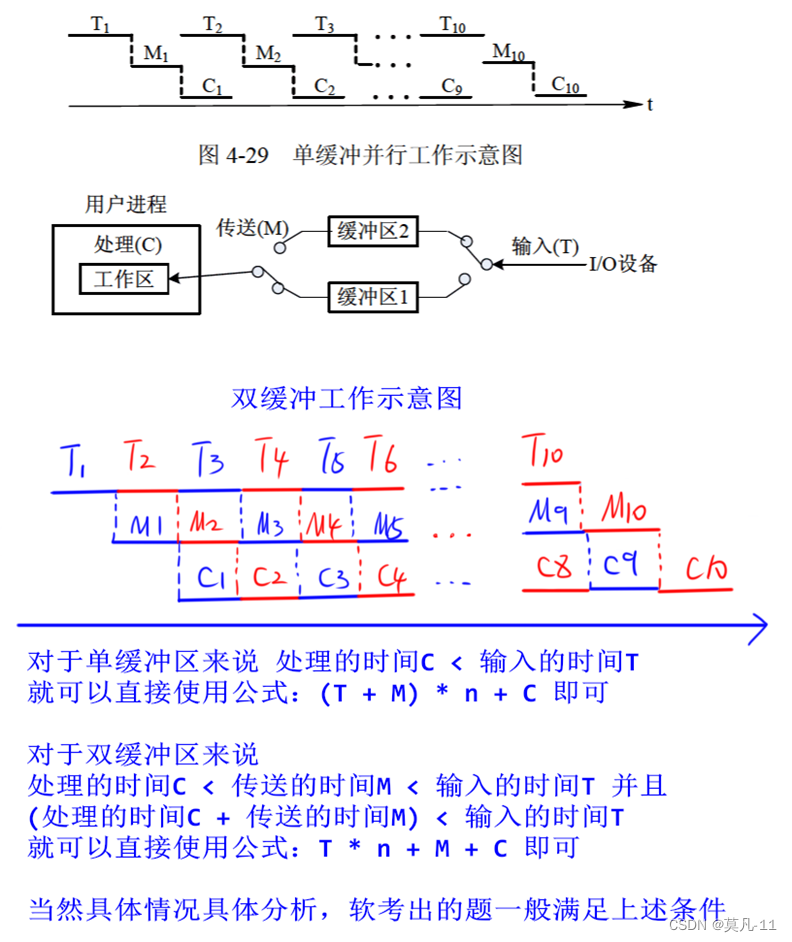
单缓冲区和双缓冲区

磁盘调度算法
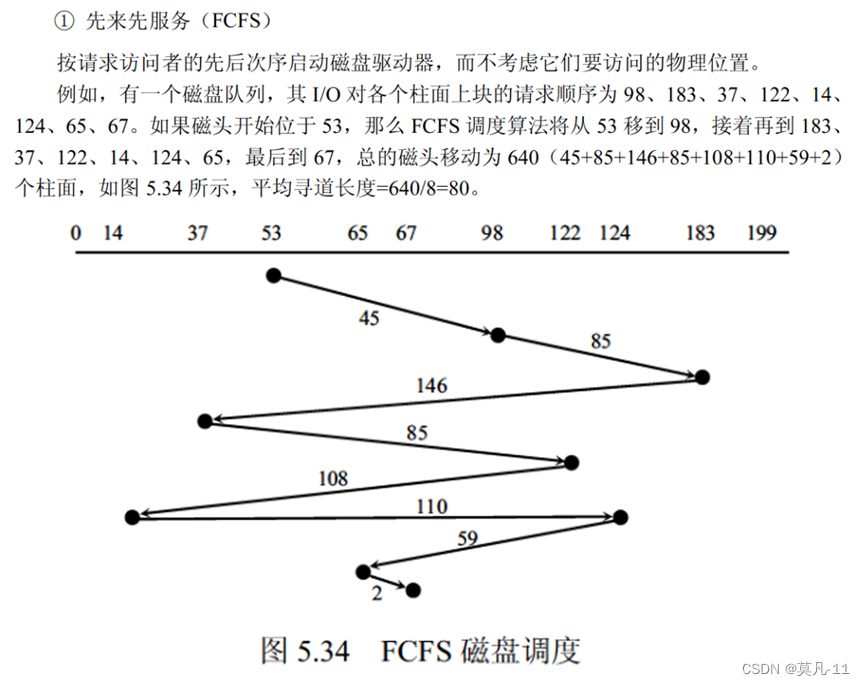
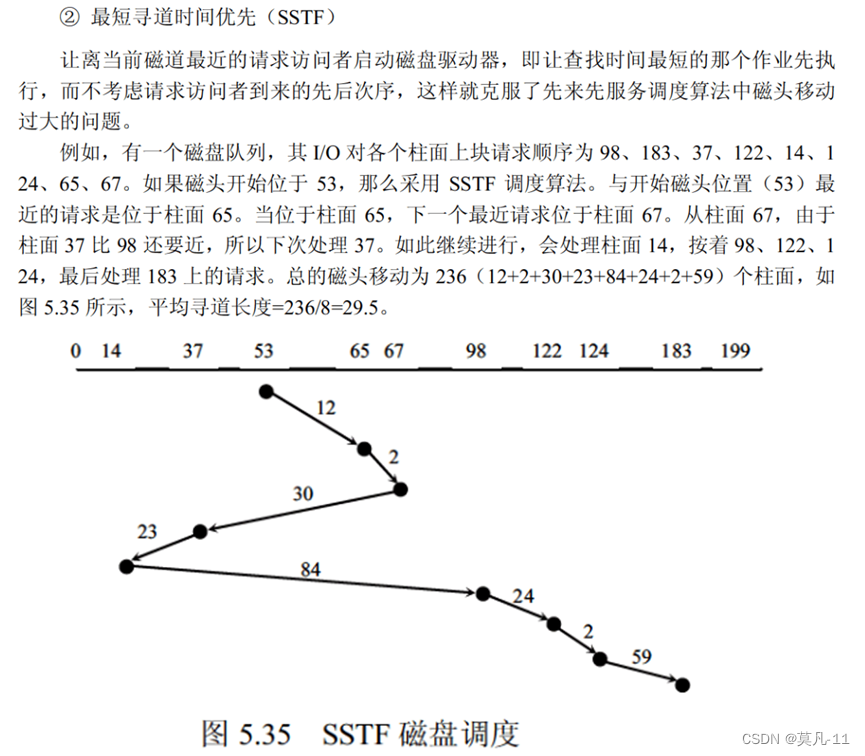
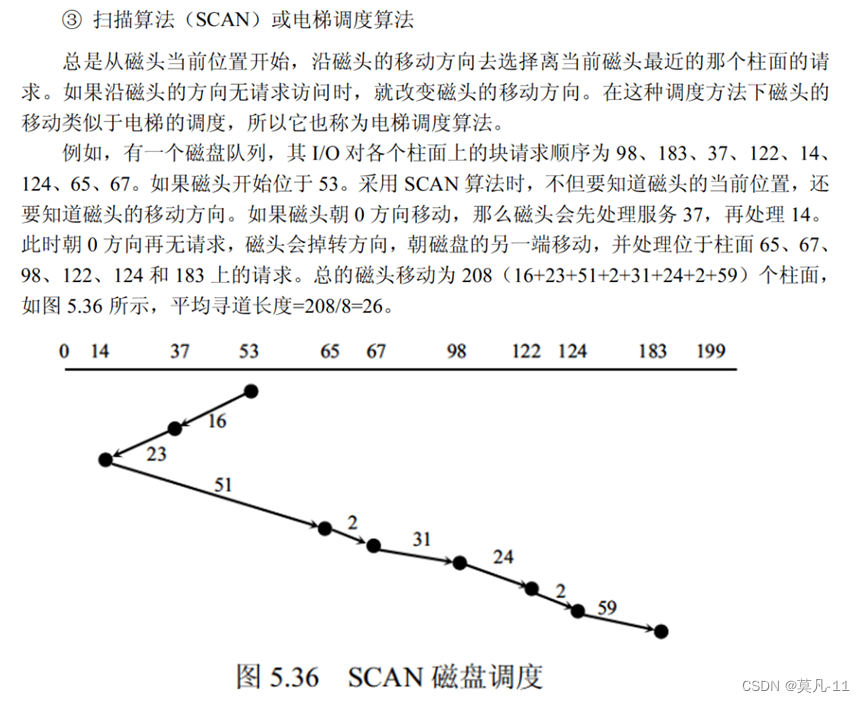
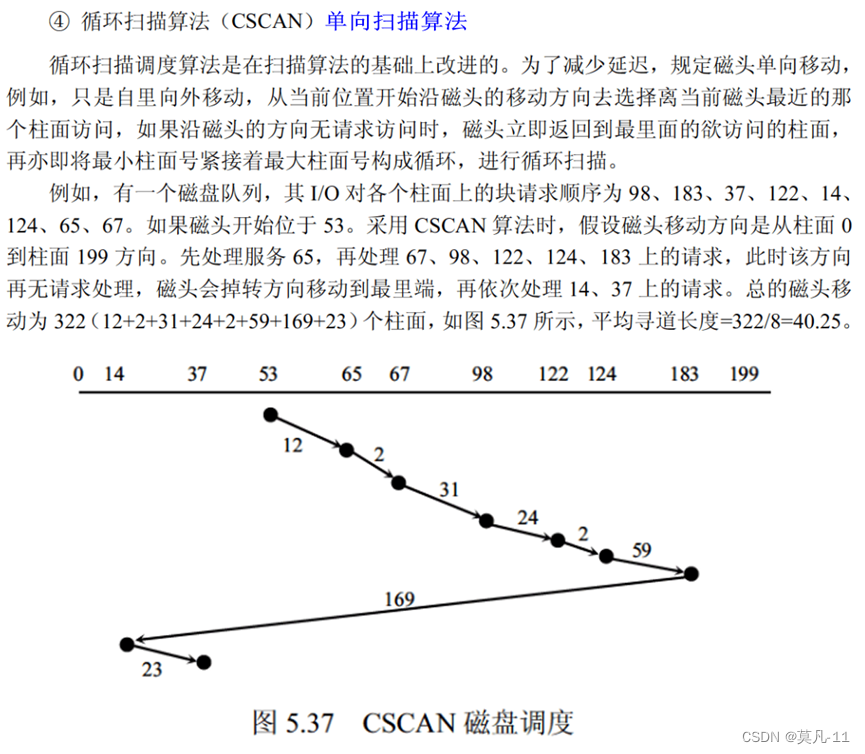
旋转调度算法
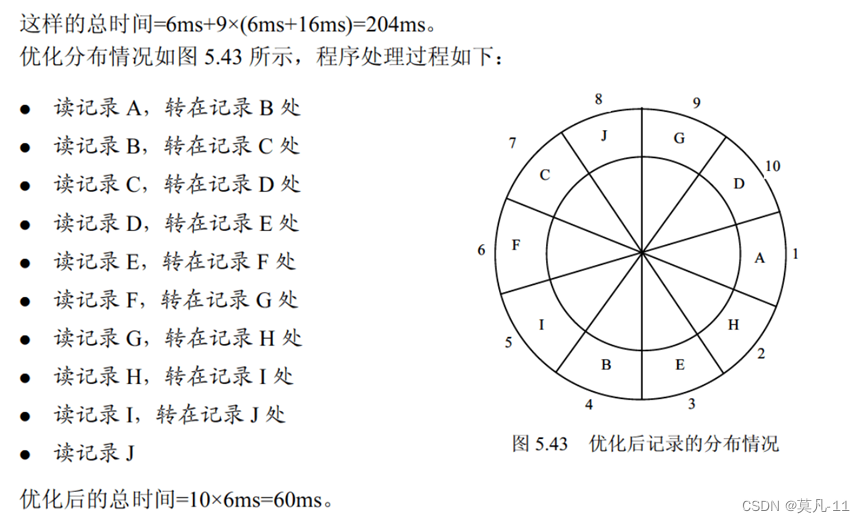
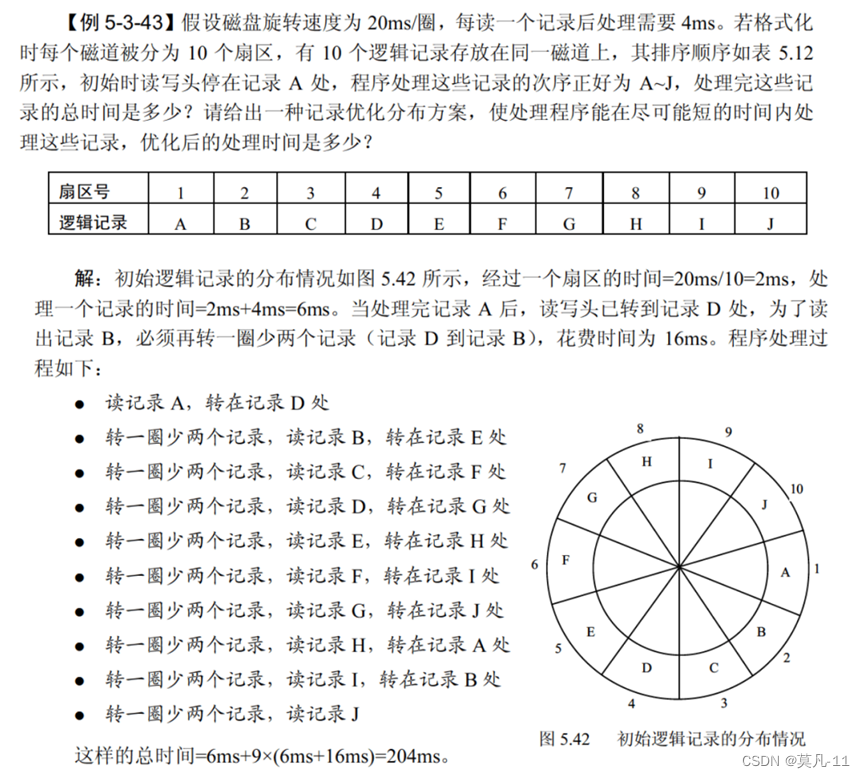
多级索引结构
文件目录
记住修改目录文件时发生崩溃,对系统影响最大即可。

目录结构
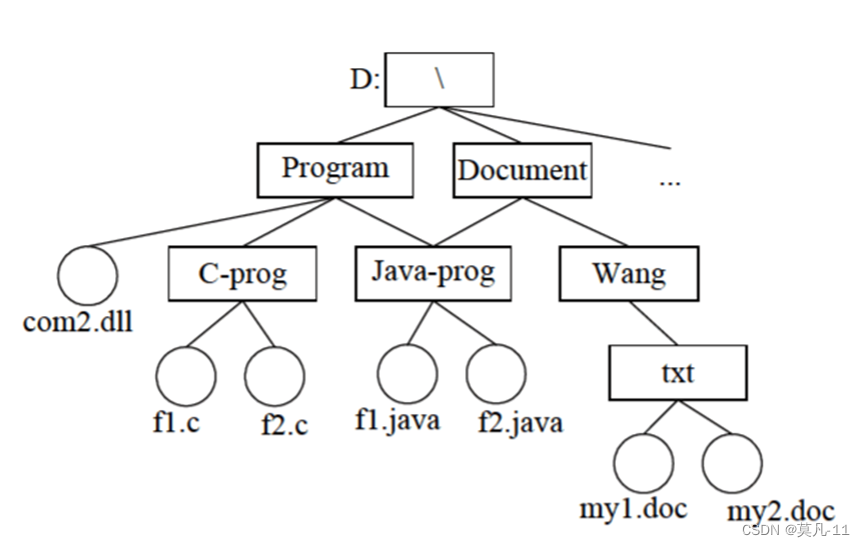
以下三个路径,以com2.dll文件为例
全文件名:从根目录(有盘符也要加上)一直到文件名:D:\Program\Java-prog\com2.dll
绝对路径:就是全文件名去掉文件名就是绝对路径:D:\Program\Java-prog\
下述相对路径以当前工作目录为Program为例,文件改为f1.java
相对路径:就是从当前工作目录到文件所在的目录,不要文件名:Program\Java-prog
然后这里强调一下,软考中一般把当前路径给省略掉,即去掉上述的Program
这里的 \ 大家注意也要去掉,如果不去掉就是从根目录开始了!
位示图

物理块号x在位示图中的第几个字中描述,可以先用物理块号x / 字长 = 大致的字号,
再根据题目给出的信息判断一下物理块号x是否在这个字的物理块号描述范围中。
这里要注意字号和块号是从0开始还是从1开始。
磁盘容量 / 物理块大小 / 字长 = 位示图的大小(字)
磁盘容量 / 物理块大小的时候记得转换单位
1字 = 8位、1Byte = 8bit
1字 = 32位、1Byte = 32bit
结构化开发
数据流图建模应遵循 自顶向下、从抽象到具体的原则。
结构化分析的输出包括 数据流图、数据词典、小说明(加工逻辑说明)、补充材料。
界面设计黄金原则包括 用户操纵控制、减轻用户的记忆负担、保持界面一致。
耦合

内聚

系统设计原则

(9)模块的作用范围应该在控制范围之内。
系统文档


数据流图
数据字典(DD)
判定表别名:决策表
信息安全
防火墙
防火墙工作层次越高,工作效率越低,安全性越高。
DMZ区防止公用服务器。
包过滤防火墙对 网络层的数据报文进行检查

病毒

网络攻击

网络安全
- 互联网安全协议(Internet Protocol Security,IPSec)是一个协议包,通过对IP协议的分组进行加密和认证来保护IP协议的网络传输协议簇(一些相互关联的协议的集合)。
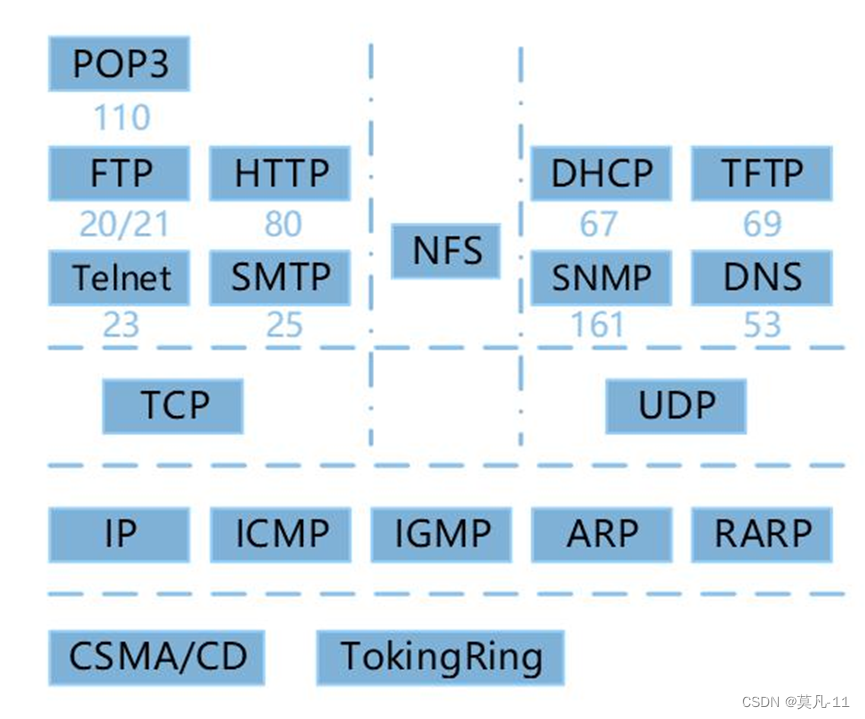
- 公共端口号是0~1023。
- HTTP 80 不安全、HTTPS 443 安全
- TCP 传输控制协议、TFTP 简单文件传输、IGMP 因特网(internet)组管理协议。
- SSH 是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
Telnet 它为用户提供了在本地计算机上完成远程主机工作的能力。
RFB ( Remote Frame Buffer 远程帧缓冲) 协议是一个用于远程访问图形用户界面的简单协议。 - 内部网关协议包括:RIP、OSPF、IS-IS、IGRP、EIGRP。
外部网关协议包括:BGP。
UDP是不可靠、无连接的协议。
补充内容
Windows命令
ipconfig:用于查看本机IP信息。traceroute:是Linux下的命令 对应 Windows下的命令位tracert路由跟踪命令。netstat:是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。nslookup:域名查询命令,用于查询DNS解析域名记录。
信息安全存储安全

计算机网络
网络设备
- 物理层设备:中继器、集线器(是一种多端口的中继器)
- 数据链路层设备:网桥、交换机(是一种多端口的网桥)
- 网络层设备:路由器
- 应用层设备:网关
集线器不能自动寻址、集线器可以检测发送冲突。
物理层不能隔离广播域和冲突域(也就是所有的端口都是一个广播域和一个冲突域)
数据链路层能隔离冲突域但是不能隔离广播域
(也就是每一个端口都是一个冲突域,但是所有的端口还是一个广播域)
网络层既可以隔离广播域也可以广播冲突域
协议簇
- TCP和UDP是在IP协议之上的。
- ICMP协议数据单元封装在 IP数据报 中传送。
- 默认情况下,FTP服务器的控制端口为21,上传文件时的端口为20。
- 所有带T的除了TFTP其他都是在TCP中传送,所有不带T的除了POP3其他都是在UDP传送。
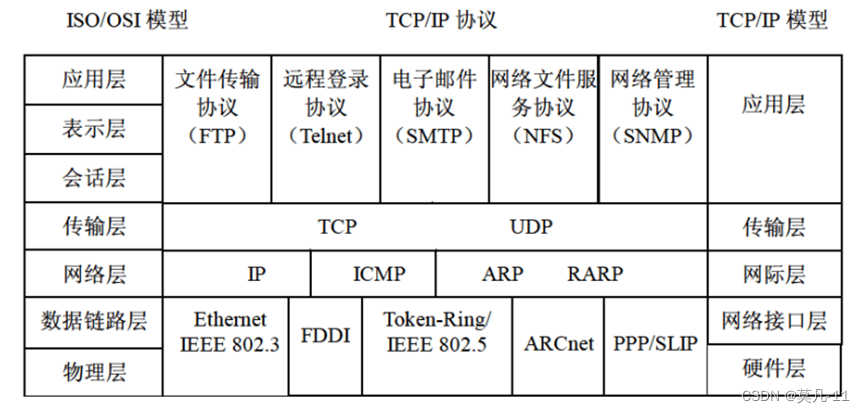
TCP和UDP
传输层协议——TCP:面向连接可靠的传输层协议,采用三次握手建立和关闭连接
TCP的功能或服务有:可靠传输、连接管理、差错校验和重传、流量控制、拥塞控制、端口寻址;其中流量控制采用的是:可变大小的滑动窗口协议
传输层协议——UDP:用户数据报协议是一种不可靠的、无连接的协议,
UDP上的应用有VoIP等。
UDP的首部8B,TCP的首部20B,UDP相比TCP来说,开销较小。
TCP和UDP均提供了端口寻址功能。
127.0.0.1是本地回送地址,当网络连接不可用时,为了测试编写好的网络程序,通常使用的目的主机IP地址为127.0.0.1。
SMTP和POP3
SMTP:发送邮件协议;端口号:25
SMTP只能传输ASCII码文本和文字附件,可以使用MIME邮件扩充协议,添加其他类型的附件。
POP3:接收邮件协议;端口号:110
POP3基于C/S模式也就是Client/Server模式(客户端/服务器模式)
SMTP和POP3都使用TPC端口传输和接收邮件
ARP
ARP和RARP协议在网络层工作,主要功能是实现IP地址和MAC地址之间的转换。
ARP采用广播(ARP Request)请求,单播(ARP Response)响应。

DHCP(动态主机配置协议)
DHCP协议的功能是:集中的管理、自动分配IP地址,使网络环境中的主机动态的获得IP地址、Gateway地址、DNS服务器地址等信息,并能够提升地址的使用率。
DHCP客户端可以从DHCP服务器获得本机IP地址、DNS服务器地址、DHCP服务器地址和默认网关的地址等。
Windows无效地址:169.254.X.X Linux无效地址:0.0.0.0
169.254.X.X是Windows系统在DHCP信息租用失败时自动给客户机分配的IP地址。
UML
协议名://主机名.域名.域名后缀.域名分类/目录/网页文件
浏览器



IP地址和子网掩码
有多少位子网号就有2的子网号次方个子网,
有多少位主机号就有2的主机号次方个主机地址,如果是可用的主机地址要减去2(下方的两个地址)
主机地址全0为网络地址,全1为广播地址

IPv6

无线网络
蓝牙覆盖范围最小和通信距离最短。
Windows命令
使用ping命令进行网络检测,按照由近及远原则,首先执行的是ping 127.0.0.1,其次是ping本地IP,再次是ping默认网关,最后是ping远程主机。
| 命令 | |
|---|---|
ipconfig/release |
DHCP客户端手工释放IP地址 |
ipconfig/flushdns |
清除本地DNS缓存内容 |
ipconfig/displaydns |
显示本地DNS内容 |
ipconfig/registerdns |
DNS客户端手工向服务器进行注册 |
ipconfig |
显示所有网络适配器的IP地址、子网掩码和缺省网关值 |
ipconfig/all |
显示所有网络适配器的完整TCP/IP配置信息,包括DHCP服务是否已启动 |
ipconfig/renew |
DHCP客户端手工向服务器刷新请求(重新申请IP地址) |
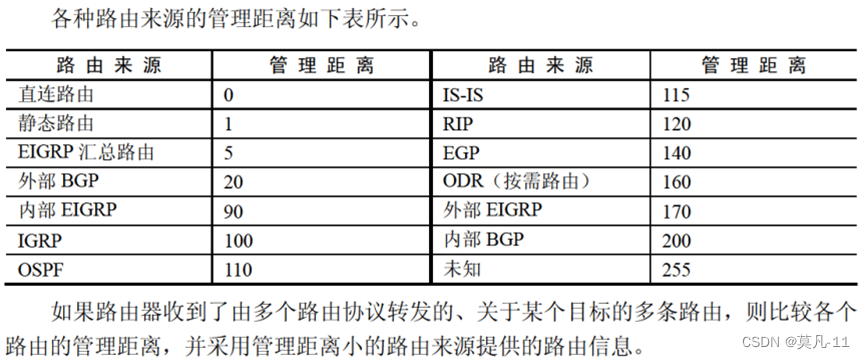
路由
Windows Server 2003 的路由类型有5种,见下表。当Windows服务器收到一个IP数据包时,先查找主机路由,再查找网络路由(直连网络和远程网络),这些路由查找失败时,最后才查找默认路由。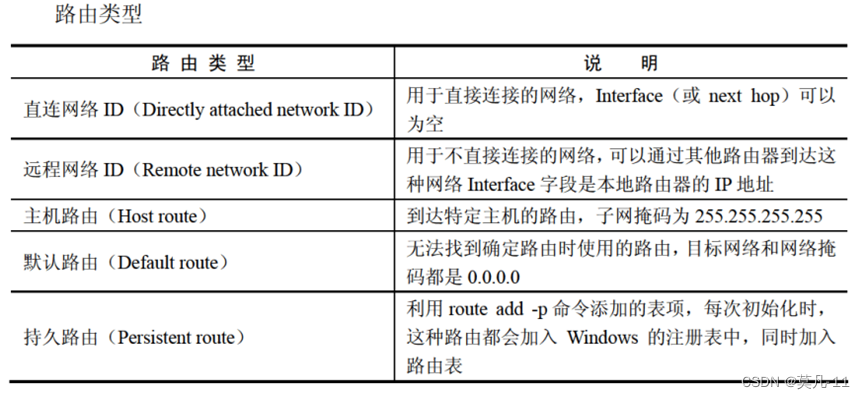
HTML
Linux命令
数据结构
时间、空间复杂度
加法规则:多项相加,保留最高阶项,并将系数化为1
乘法规则:多项相乘都保留,并将系数化为1
加法乘法混合规则:先小括号再乘法规则最后加法规则
时间复杂度估算看最内层循环,如若没有循环和递归则为O(1)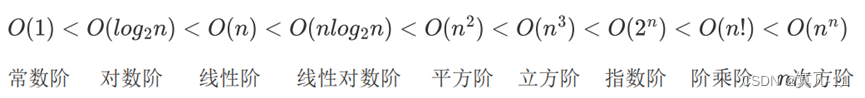
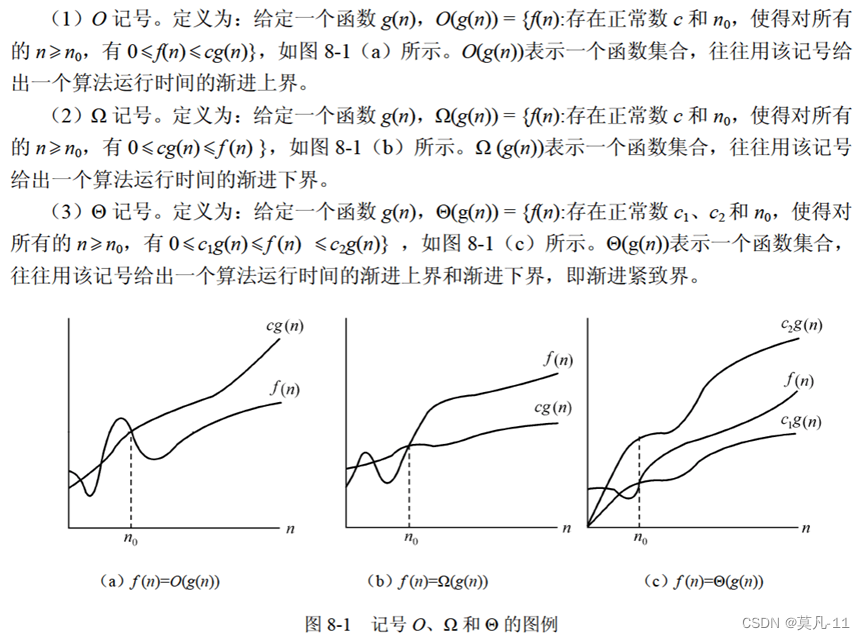
渐进符号

递归式时间、空间复杂度
递归算法的时间复杂度:
递归的次数 × 每次递归的时间复杂度(适用于每次递归时间复杂度不变的情况)
如果每次递归的时间复杂度随着n变化而变化则要根据代码来观察
线性表
如果没有给出最好最坏平均时间复杂度的话就默认是平均时间复杂度
顺序表:
采用顺序存储,优点是可以随机存取表中的元素;
缺点是插入和删除操作需要移动大量的元素。
时间复杂度
插入、删除操作最好时间复杂度为O(1),平均和最坏时间复杂度都为O(n)
查找最好、最坏、平均情况都为O(1)
单链表:
采用链式存储,优点是插入和删除操作不需要移动大量的元素,只需要修改指针;
缺点是不能随机访问表中的元素。
时间复杂度
查找、插入、删除操作最好时间复杂度为O(1),平均和最坏时间复杂度都为O(n)
栈
栈是一种先进后出(后进先出)的线性结构,只能在栈的一端(栈顶)进行插入和删除。
递归使用栈
队列
循环队列的优点是 入队和出队操作都不需要移动队列中的其他元素。
栈和队列
串
字符串是线性结构,空格也是字符串
字串是指由主串中任意长度连续的字符构成的序列
例如:
主串:abc
字串:a、b、c、ab、bc
ac不是字串,因为它不是主串中连续的字符
串的模式匹配
朴素模式匹配:
时间复杂度:最好情况O(m),最坏情况O(n×m),平均情况O(n+m)
比较次数:最好情况m次,最坏情况(n-m+1)*m次,平均情况1/2 (n-m+1)次
串的前缀:包含第一个字符并且不包含最后一个字符的子串
串的后缀:包含第一个字符并且不包含最后一个字符的子串
求next[ ]:第i个字符的值等于前1∼i-1个字符串组成的串中最长相等前后缀的长度+1
特殊的next[1]=0 next[2]=1
数组
一维数组:
LOC:数组首地址、L:元素大小
下标从0开始: a i = L O C + i × L a_i=LOC+i×L ai=LOC+i×L
下标从1开始: a i = L O C + ( i − 1 ) × L a_i=LOC+(i-1)×L ai=LOC+(i−1)×L
二维数组:
LOC:数组首地址、N:行数、M:列数、L:元素大小
按行优先存储并且下标从0开始: a ( i , j ) = L O C + ( i × M + j ) × L a_{(i,j)}=LOC+(i×M+j)×L a(i,j)=LOC+(i×M+j)×L
按行优先存储并且下标从1开始: a ( i , j ) = L O C + [ ( i − 1 ) × M + ( j − 1 ) ] × L a_{(i,j)}=LOC+[(i-1)×M+(j-1)]×L a(i,j)=LOC+[(i−1)×M+(j−1)]×L
按列优先存储并且下标从0开始: a ( i , j ) = L O C + ( j × N + i ) × L a_{(i,j)}=LOC+(j×N+i)×L a(i,j)=LOC+(j×N+i)×L
按列优先存储并且下标从1开始: a ( i , j ) = L O C + [ ( j − 1 ) × N + ( i − 1 ) ] × L a_{(i,j)}=LOC+[(j-1)×N+(i-1)]×L a(i,j)=LOC+[(j−1)×N+(i−1)]×L
矩阵
设有一个 n × n n×n n×n的矩阵,若矩阵中的任意一个元素都有 A ( i , j ) = A ( j , i ) A_(i,j)=A_(j,i) A(i,j)=A(j,i)则该矩阵为对称矩阵
下方的公式都是基于存储的一维数组下标是从1开始的,在软考的题目里面是适用的。
如果一维数组的下标是从 0 0 0开始的,那需要在后面补上一个减 1 1 1。
对称矩阵按行存储下三角区和主对角线并且下标从 0 ( A 0 , 0 ) 0(A_0,0) 0(A0,0)开始
当( i ≥ j i≥j i≥j)时: A ( i , j ) = i ( i + 1 ) / 2 + j + 1 A_(i,j)=i(i+1)/2+j+1 A(i,j)=i(i+1)/2+j+1
当( i ≤ j i≤j i≤j)时: A ( i , j ) = j ( j + 1 ) / 2 + i + 1 A_(i,j)=j(j+1)/2+i+1 A(i,j)=j(j+1)/2+i+1
对称矩阵按行存储下三角区和主对角线并且下标从 1 ( A 1 , 1 ) 1(A_1,1) 1(A1,1)开始
当( i ≥ j i≥j i≥j)时: A ( i , j ) = i ( i − 1 ) / 2 + j A_(i,j)=i(i-1)/2+j A(i,j)=i(i−1)/2+j
当( i ≤ j i≤j i≤j)时: A ( i , j ) = j ( j − 1 ) / 2 + i A_(i,j)=j(j-1)/2+i A(i,j)=j(j−1)/2+i
三对角矩阵按行存储并且下标从 0 ( A 0 , 0 ) 0(A_0,0) 0(A0,0)开始: A ( i , j ) = 2 i + j + 1 A_(i,j)=2i+j+1 A(i,j)=2i+j+1
三对角矩阵按按存储并且下标从 1 ( A 1 , 1 ) 1(A_1,1) 1(A1,1)开始: A ( i , j ) = 2 i + j − 2 A_(i,j)=2i+j-2 A(i,j)=2i+j−2
三元组顺序表和十字链表是对稀疏矩阵进行压缩存储的方式
树
树的性质1:树中的结点总数等于树中所有结点的度数之和加1
树的性质2:度为 m m m的树中第 i i i层上至多有 m ( i − 1 ) m^(i-1) m(i−1)个结点 ( i ≥ 1 ) (i≥1) (i≥1)
树的性质3:高度为 h h h、度为 m m m的树中至多有 ( m h − 1 ) / ( m − 1 ) (m^h-1)/(m-1) (mh−1)/(m−1)个结点
树的性质4:具有 n n n个结点、度为 m m m的树的最小高度为 ⌈ l o g m ( n ( m − 1 ) + 1 ) ⌉ ⌈log_m(n(m-1)+1) ⌉ ⌈logm(n(m−1)+1)⌉
二叉树
二叉树性质
二叉树性质1:二叉树第i层(i≥1)上最多有 2 ( i − 1 ) 2^(i-1) 2(i−1)个结点
二叉树性质2:高度为h的二叉树最多有 2 h − 1 2^h-1 2h−1个结点
二叉树性质3:对于任何一棵二叉树,度为0的结点数等于度为2的结点数+1
二叉树性质4:具有n个结点的完全二叉树的高度为 ⌊ l o g 2 n ⌋ + 1 ⌊log_2 n⌋+1 ⌊log2n⌋+1或 ⌈ l o g 2 ( n + 1 ) ⌉ ⌈log_2 (n+1)⌉ ⌈log2(n+1)⌉
计算具有n个结点有多少种形态的公式:卡特兰数: ( C 2 n n ) / ( n + 1 ) (C_{2n}^{n})/(n+1) (C2nn)/(n+1)
二叉树存储结构
顺序存储需要维护结点和左、右孩子的关系:结点编号为n,则左孩子为2n,右孩子为2n+1。
链式存储有二叉链表和三叉链表。
对于n个结点的二叉树,二叉链表的空指针为n+1,三叉链表的空指针为n+2。
二叉树遍历
先序遍历:根左右
中序遍历:左根右
后序遍历:左右根
层序遍历:从上到下、从左往右依次遍历
通过序列构造二叉树必须有中序序列
平衡二叉树和二叉排序树
平衡二叉树:二叉树中的任意一个结点的左右子树高度之差的绝对值不超过1
关注分支结点即可,叶子结点满足上述要求。
二叉排序树(二叉树查找树、二叉检索树):
根结点的关键字大于左子树所有结点的关键字,小于右子树所有结点的关键字,
左右子树也是一颗二叉排序树。
排序二叉树的中序遍历得到的序列是有序序列。
最坏的查找情况是单枝树(即高度h为n)要查找n次。
最优二叉树(哈夫曼树)
构造过程、哈夫曼编码和注意事项看视频P146、148、150吧,文字描述怪怪的。
哈夫曼树中权值越大的结点离根结点越近,权值越小的结点离根结点越远。
哈夫曼树只有度为0和度为2的结点,没有度为1的结点。
n个权值构造的哈夫曼树具有2n-1个结点。
线索二叉树
图的概念
无向图:连接顶点的边是无向边
有向图:连接顶点的边是有向边(弧)
无向完全图有 ( n ∗ ( n − 1 ) ) 2 \frac{(n*(n-1))}{2} 2(n∗(n−1))条边
有向完全图有 n ∗ ( n − 1 ) n*(n-1) n∗(n−1)条边
有向图和无向图的所有顶点度数之和为 2 e 2e 2e。( e e e为边数)
有向图和无向图的边数 e = 顶点度数之和 2 e=\frac{顶点度数之和}{2} e=2顶点度数之和
连通图:无向图中任意两个顶点之间都有路径。
最少有 n − 1 n-1 n−1条边,最多有 ( n ∗ ( n − 1 ) ) 2 \frac{(n*(n-1))}{2} 2(n∗(n−1))条边。
强连通图:有向图中任意两个顶点之间都有路径。
最少有 n n n条边,最多有 n ∗ ( n − 1 ) n*(n-1) n∗(n−1)条边。
邻接矩阵与邻接表
邻接矩阵
邻接矩阵更适合存储稠密图(边数很多的图)
完全图(每个顶点都和剩余的顶点有一条边)更适合采用邻接矩阵存储
无向图邻接矩阵:非零元素个数为2e(e为边数)
无向图的邻接矩阵是对称矩阵
A[i][j]=1表示顶点i和顶点j之间有一条无向边
A[i][j]=0表示顶点i和顶点j之间没有边
对于无向图,顶点i的度等于邻接矩阵第i行(列)中非零元素个数
有向图邻接矩阵:非零元素个数为e(e为边数)
有向图的邻接矩阵不一定是对称矩阵
A[i][j]=1表示顶点i和顶点j之间有一条有向边
A[i][j]=0表示顶点i和顶点j之间没有边
对于有向图,顶点i的出度等于第i行非零元素个数,入度等于第i列非零元素个数,顶点i的度=顶点i的出度+入度
邻接表:
邻接表更适合存储稀疏图(边数很少的图)
无向图采用邻接表存储有2e个表结点(e为边数)
有向图采用邻接表存储有n+e个表结点(n为结点数,e为边数)
图的遍历
广度、深度优先遍历采用邻接矩阵存储时间复杂度为 O ( n 2 ) O(n^2 ) O(n2),
广度、深度优先遍历采用邻接表存储时间复杂度为 O ( n + e ) O(n+e) O(n+e)。
(其中 n n n为顶点数, e e e为边数)
递归思想进行深度优先遍历
使用队列对图进行广度优先遍历
拓扑排序
在有向无环图 G G G的拓扑序列中,顶点 v i v_i vi在 v j v_j vj之前,则:
可能存在弧 < v i , v j > <v_i, v_j> <vi,vj>,一定不存在弧 < v j , v i > <v_j, v_i> <vj,vi>。
可能存在 v i v_i vi到 v j v_j vj的路径,一定不存在 v j v_j vj到 v i v_i vi的路径
查找
静态查找表有:顺序查找,折半(二分)查找,分块查找
动态查找表有:二叉排序树,平衡二叉树,B_树,哈希表
顺序查找方法既适用于顺序存储结构,也适用于链表结构
顺序查找最多比较 n n n次
顺序平均查找长度为 ( n + 1 ) 2 \frac{(n+1)}{2} 2(n+1)
二分查找要求顺序存储,元素有序排列
二分查找最多比较 ⌊ l o g 2 n ⌋ + 1 ⌊log_2n ⌋+1 ⌊log2n⌋+1次
二分平均查找长度为 l o g 2 ( n + 1 ) − 1 log_2 (n+1)-1 log2(n+1)−1
二分查找去中值默认下取整,下取整没有正确答案时再考虑上取整。
哈希表
构造哈希函数时应尽量使关键字的所有组成部分都能起作用
“H(Key)=Key mod p” 中p的值一般为不大于n且最接近n的质数

堆(小顶堆和大顶堆)
直接插入排序

直接插入排序:
最好的情况是待排序序列是基本有序的序列,时间复杂度为O(n)
最坏的情况是待排序序列是逆序,时间复杂度为O(n^2 )
希尔排序了解即可(上午题没考过)
排序稳定性
直接背简单选择排序和堆排序的时间、空间复杂度和稳定性即可。
简单选择排序和堆排序都是在一次排序后就确定一个元素的最终位置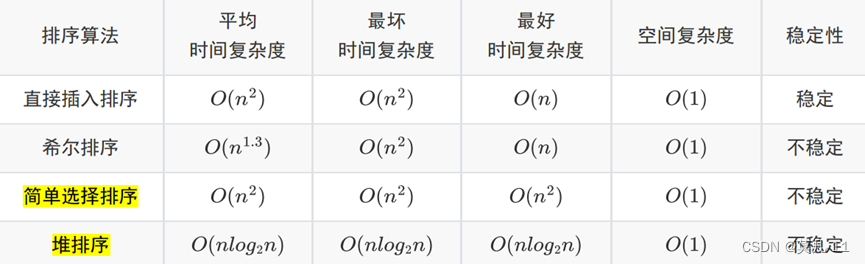
快速排序
快速排序是一种基于分治的算法,每趟排序可以确定一个元素的最终位置(即归位)。
快速排序最坏的情况是待排序序列基本有序,时间复杂度为 O ( n 2 ) O(n^2 ) O(n2),空间复杂度为 O ( n ) O(n) O(n)
以第一个元素为基准元素就 先从后往前找 再从前往后找
以最后一个元素为基准元素就 先从前往后找 再从后往前找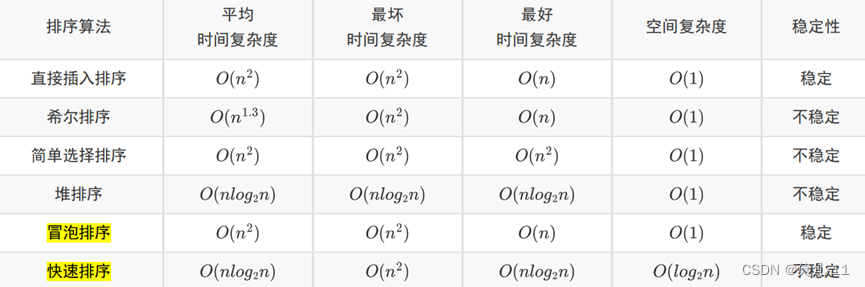
归并排序
归并排序采用分治的算法策略
归并排序的时间复杂度直接记 O ( n l o g 2 n ) O(nlog_2 n) O(nlog2n),空间复杂度记 O ( l o g 2 n ) O(log_2 n) O(log2n)。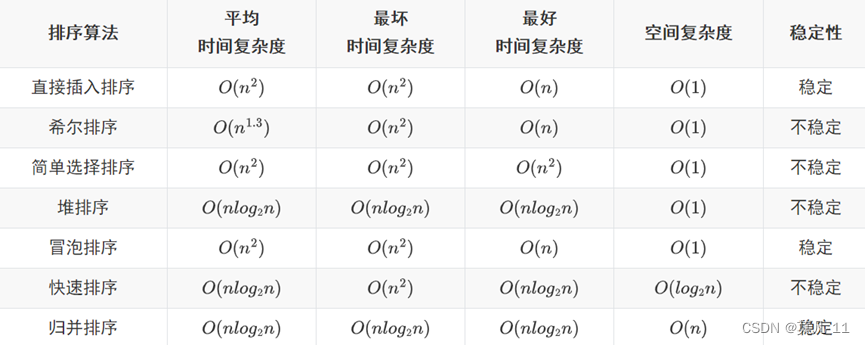
下午题
试题一 数据流图(15分)
数据流图(DFD)对系统的功能和功能之间的数据流进行建模,其中顶层数据流图描述了系统的输入与输出。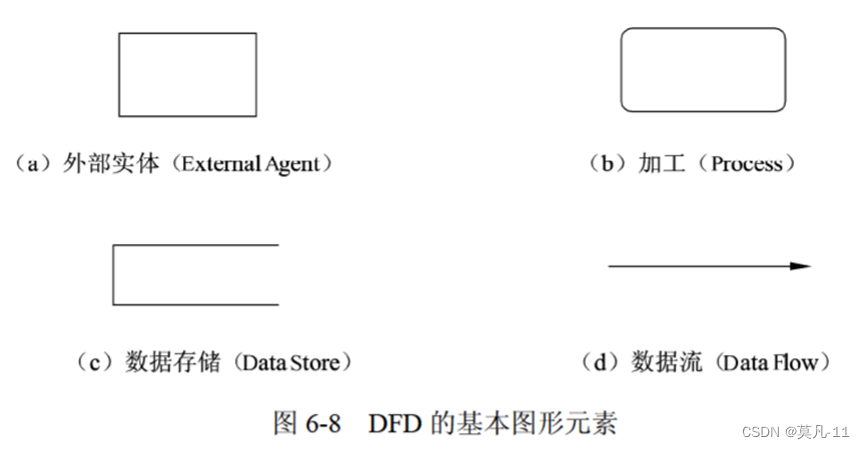
外部实体
外部实体:当前系统之外的人、物、外部系统
人:学生、老师、员工、主管、医生、客户、供应商…
物:传感器、控制器、单车、车辆、采购部门…
外部系统:支付系统、车辆交易系统、库存管理系统、道闸控制系统…
数据存储
数据存储:存储数据和提供数据
存储加工的输出数据和提供加工的输入数据
例子:客户表、订单表、学生表、巴士列表文件、维修记录文件、课表文件。
加工
加工:将输入数据处理后得到输出数据
一个加工至少有一个输入数据流和输出数据流
加工常见的错误:
加工只有输入没有输出称为:黑洞
加工只有输出没有输入称为:白洞
加工的输入数据不足以产生输出数据:灰洞
数据流
数据流由一组固定成分的数据组成,表示数据的流向。
在DFD中,数据流的流向可以由以下几种:从一个加工流向另一个加工;从加工流向数据存储(写);从数据存储流向加工(读);从外部实体流向加工(输入);从加工流向外部实体(输出)。
数据流的起点或终点中必须有一个是加工(处理)。
补充缺失的数据流
1.父图子图平衡(即是否确实数据流)
上下文(顶层)数据流图为父图,0层数据流图为子图。父图细分成子图。
2.加工即有输入数据流也有输出数据流
一个加工至少有一个输入数据流和输出数据流的话,暂时没有问题。
3.数据守恒
建模图如何保持数据流图平衡
父图中加工的输入输出数据流必须与子图中的输入输出数据流在数量上和名字上相同;
父图中的一个输入(输出)数据流对应子图中几个输入(输出)数据流,
而子图中组成这些数据流的数据项全体正好是父图中的这一条数据流。
结构化语言描述加工逻辑
结构化语言(如结构化英语)是一种介于自然语言和形式化语言之间的半形式化语言,是自然语言的一种受限子集。
结构化语言没有严格的语法,它的结构通常可分为内层和外层。外层有严格的语法,内层的语法比较灵活,可以接近于自然语言的描述。
(1)外层。用来描述控制结构,采用顺序、选择和重复3种基本结构。
①顺序结构。一组祈使语句、选择语句、重复语句的顺序排列。祈使语句是指至少包含一个动词及一个名词,指出要执行的动作及接受动作的对象。
②选择结构。一般用IF-THEN-ELSE- ENDIF、CASE-OF ENDCASE等关键词。
IF 条件 THEN
分支内容
ELSE IF 条件 THEN
分支内容
ELSE
分支内容
ENDIF
③重复结构。一般用DO-WHILE-ENDDO、REPEAT-UNTIL等关键词。
WHILE 下雨
DO
{
在家
IF 不下雨 THEN
出门
ENDIF
}
ENDDO
(2)内层。一般采用祈使语句的自然语言短语,使用数据字典中的名词和有限的自定义词,其动词含义要具体,尽量不用形容词和副词来修饰,还可使用一些简单的算法运算和逻辑运算符号。
试题二(15分)
E-R图基本图形元素
试题三(15分)
类图和用例图
主要是类图与用例图的关系,这部分内容和上午题 #8 重复,看过就不用看了。
知道类图的:依赖、关联、聚合、组合、泛化、实现关系
还有
用例图的:包含、扩展、泛化关系(用例图这边直接看视频了解即可)
编译看左边,运行看右边
抽象类不一定有抽象方法,有抽象方法的一定是抽象类
| JAVA表示方式 | UML表示方式 | 注释 |
|---|---|---|
| public | + | 公有的 |
| private | - | 私有的 |
| protected | # | 受保护的 |
数据建模:E-R
功能建模:DFD
行为建模:UML
interface
abstract class
interface
extends
implements

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)