springboot集成kafka发送、消费数据示例
springboot集成kafka发送、消费数据
·
1.kafka介绍
1.1.kafka的特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘(在kafka目录下),并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
1.2.生产者介绍
1.2.1.生产者分区策略
- 轮询策略:Round-robin 策略,即顺序分配,轮询策略有非常优秀的负载均衡表 现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略。(默认、常用)
- 随机策略:Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上。
- 消息键保序策略:key-ordering策略,Kafka 中每条消息都会有自己的key,一旦消息被定义了 Key,那么你就可以保证同一个Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的。()
例如企业上传实时数据,将企业id作为key,可以确保每个企业的数据都在同一个分区,确保能按顺序消费。
如果不设置key,可能会出现17:30分的数据在1分区,17:31分的数据在2分区,但是1分区数据较多,2分区数据比较少,结果就是先消费了17:31的数据,后消费17:30的数据。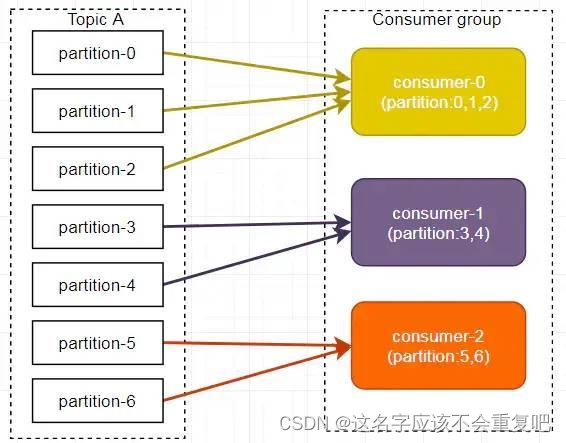
2.springboot集成kafka代码
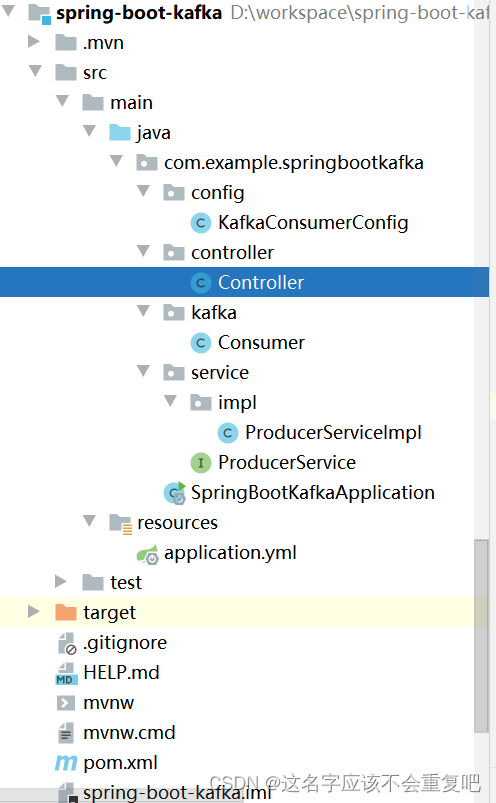
项目目录结构如下
2.1.引入pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.8.11</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.1.2</version>
</dependency>
2.2.添加KafkaConsumerConfig.java消费者配置类
package com.example.springbootkafka.config;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ContainerProperties;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Configuration
@Slf4j
public class KafkaConsumerConfig {
@Value("${spring.kafka.consumer.bootstrapServers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.groupId}")
private String groupId;
@Value("${spring.kafka.consumer.sessionTimeOut}")
private String sessionTimeOut;
@Value("${spring.kafka.consumer.enableAutoCommit}")
private String enableAutoCommit;
@Value("${spring.kafka.consumer.autoCommitInterval}")
private String autoCommitInterval;
@Value("${spring.kafka.consumer.maxPollRecords}")
private String maxPollRecords;
@Value("${spring.kafka.consumer.maxPollInterval}")
private String maxPollInterval;
@Value("${spring.kafka.consumer.heartbeatInterval}")
private String heartbeatInterval;
@Value("${spring.kafka.consumer.keyDeserializer}")
private String keyDeserializer;
@Value("${spring.kafka.consumer.valueDeserializer}")
private String valueDeserializer;
@Value("${spring.kafka.consumer.autoOffsetReset}")
private String autoOffsetReset;
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 并发数 多个微服务实例会均分
factory.setConcurrency(3);
//每次只接收处理一条信息
factory.setBatchListener(false);
ContainerProperties containerProperties = factory.getContainerProperties();
// 设置手动提交
containerProperties.setAckMode(ContainerProperties.AckMode.MANUAL);
return factory;
}
private ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> consumerConfigs = consumerConfigs();
log.info("消费者的配置信息:{}", JSONObject.toJSONString(consumerConfigs));
return new DefaultKafkaConsumerFactory<>(consumerConfigs);
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
// 服务器地址
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 是否自动提交
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
// 自动提交间隔
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
//会话时间
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeOut);
//key序列化
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);
//value序列化
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);
// 心跳时间
propsMap.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, heartbeatInterval);
// 分组id
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//消费策略
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
// poll记录数
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords);
//poll时间
propsMap.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, maxPollInterval);
return propsMap;
}
}
2.3.添加Consumer.java消费者实现代码
- 如果在 @KafkaListener 注解中不设置 concurrency 属性,默认并发度是 1。这意味着每个消费者实例将在单个线程中运行,一次只能处理一个消息。设置 concurrency 参数为 “1” 可以确保消息的顺序性,但会限制消费者的吞吐量。
- 如果将concurrency 设置为大于 “1” 的值,那么每个消费者实例将使用多个线程来并发处理消息。这样可以提高消息处理的吞吐量,但可能会导致消息的处理顺序性无法保证。
package com.example.springbootkafka.kafka;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import org.springframework.util.ObjectUtils;
import java.util.List;
@Slf4j
@Component
public class Consumer {
@KafkaListener(topics = {"${spring.kafka.consumer.topic}"},
groupId = "${spring.kafka.consumer.groupId}",
containerFactory = "kafkaListenerContainerFactory",
properties = {"${spring.kafka.consumer.autoOffsetReset}"})
public void topicTest(ConsumerRecord<String, String> record, Acknowledgment ack) {
log.info("接收到数据,topic = {},value = {}",record.topic(),record.value());
try {
//do something
// JSONObject jsonObject = JSON.parseObject(record.value());
// String id = jsonObject.getString("id");
// if (ObjectUtils.isEmpty(id)){
// log.error("处理kafka数据出错,id为空");
// return;
// }
log.info("处理数据,record = {}", record.value());
} catch (Exception e) {
log.error("处理kafka数据出错,value = {},错误信息 = {}",record.value(),e);
//报错时处理逻辑
} finally {
// 手动提交offset
ack.acknowledge();
log.info("数据处理完成,value = {}",record.value());
}
}
}
2.4.添加接口ProducerService
package com.example.springbootkafka.service;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.messaging.Message;
import java.util.concurrent.ExecutionException;
public interface ProducerService {
/**
* 发送同步消息
*
* @param topic
* @param data
* @throws ExecutionException
* @throws InterruptedException
*/
void sendSyncMessage(String topic, String data) throws ExecutionException, InterruptedException;
/**
* 发送普通消息
*
* @param topic
* @param data
*/
void sendMessage(String topic, String data);
/**
* 发送带附加信息的消息
*
* @param record
*/
void sendMessage(ProducerRecord<String, String> record);
/**
* 发送Message消息
*
* @param message
*/
void sendMessage(Message<String> message);
/**
* 发送带key的消息
*
* @param topic
* @param key
* @param data
*/
void sendMessage(String topic, String key, String data);
void sendMessage(String topic, Integer partition, String key, String data);
void sendMessage(String topic, Integer partition, Long timestamp, String key, String data);
}
2.5.添加ProducerServiceImpl.java生产者实现类
package com.example.springbootkafka.service.impl;
import com.example.springbootkafka.service.ProducerService;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.messaging.Message;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.util.concurrent.ExecutionException;
@Component
@Slf4j
@EnableAsync
public class ProducerServiceImpl implements ProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送同步消息
*
* @param topic
* @param data
* @throws ExecutionException
* @throws InterruptedException
*/
@Override
public void sendSyncMessage(String topic, String data) throws ExecutionException, InterruptedException {
SendResult<String, String> sendResult = kafkaTemplate.send(topic, data).get();
RecordMetadata recordMetadata = sendResult.getRecordMetadata();
log.debug("sendSyncMessage 发送同步消息成功!发送的主题为:{}", recordMetadata.topic());
}
/**
* 发送普通消息
*
* @param topic
* @param data
*/
@Override
public void sendMessage(String topic, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, data);
future.addCallback(
success -> log.info("sendMessage topic={}发送消息成功!",topic),
failure -> log.error("sendMessage 发送消息失败!失败原因是:{}", failure.getMessage())
);
}
/**
* 发送带附加信息的消息
*
* @param record
*/
@Override
public void sendMessage(ProducerRecord<String, String> record) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(record);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
log.debug("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
/**
* 发送Message消息
*
* @param message
*/
@Override
public void sendMessage(Message<String> message) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(message);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
log.debug("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
/**
* 发送带key的消息
*
* @param topic
* @param key
* @param data
*/
@Override
public void sendMessage(String topic, String key, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, key, data);
log.info("发送到:{} ,消息体为:{}",topic,data);
future.addCallback(
success -> log.debug("发送消息成功!"),
failure -> log.error("发送消息失败!失败原因是:{}", failure.getMessage())
);
}
@Override
public void sendMessage(String topic, Integer partition, String key, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, partition, key, data);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
log.debug("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
@Override
public void sendMessage(String topic, Integer partition, Long timestamp, String key, String data) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, partition, timestamp, key, data);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.error("发送消息失败!失败原因是:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> sendResult) {
RecordMetadata metadata = sendResult.getRecordMetadata();
log.debug("发送消息成功!消息主题是:{},消息分区是:{}", metadata.topic(), metadata.partition());
}
});
}
}
2.6.添加application.yml配置
server:
port: 8080
spring:
kafka:
bootstrap-servers: 192.168.80.251:9092
producer:
batch-size: 16384 #批次大小,默认16k
acks: all #ACK应答级别,指定分区中必须要有多少个副本收到消息之后才会认为消息成功写入,默认为1只要分区的leader副本成功写入消息;0表示不需要等待任何服务端响应;-1或all需要等待ISR中所有副本都成功写入消息
retries: 3 #重试次数
value-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
buffer-memory: 33554432 #缓冲区大小,默认32M
client-id: abcdefg #客户端ID
compression-type: none #消息压缩方式,默认为none,另外有gzip、snappy、lz4
properties:
retry.backoff.ms: 100 #重试时间间隔,默认100
linger.ms: 0 #默认为0,表示批量发送消息之前等待更多消息加入batch的时间
max.request.size: 1048576 #默认1MB,表示发送消息最大值
connections.max.idle.ms: 540000 #默认9分钟,表示多久后关闭限制的连接
receive.buffer.bytes: 32768 #默认32KB,表示socket接收消息缓冲区的大小,为-1时使用操作系统默认值
send.buffer.bytes: 131072 #默认128KB,表示socket发送消息缓冲区大小,为-1时使用操作系统默认值
request.timeout.ms: 30000 #默认30000ms,表示等待请求响应的最长时间
consumer:
bootstrapServers: 192.168.80.251:9092
topics: testTopic1
groupId: test
#后台的心跳线程必须在30秒之内提交心跳,否则会reBalance
sessionTimeOut: 30000
#取消自动提交,即便如此 spring会帮助我们自动提交
enableAutoCommit: false
#自动提交间隔
autoCommitInterval: 1000
maxPollRecords: 50
#300秒的提交间隔,如果程序大于300秒提交,会报错
maxPollInterval: 300000
#心跳间隔
keyDeserializer: org.apache.kafka.common.serialization.StringDeserializer
valueDeserializer: org.apache.kafka.common.serialization.StringDeserializer
autoOffsetReset: latest
heartbeatInterval: 10000
2.7.添加Controller层代码
package com.example.springbootkafka.controller;
import com.example.springbootkafka.service.ProducerService;
import lombok.extern.slf4j.Slf4j;
import org.apache.catalina.connector.Response;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@Slf4j
@RestController
@RequestMapping("/test")
public class Controller {
@Autowired
ProducerService producerService;
@GetMapping("/sendMsg")
public Integer sendMsg(@RequestParam("msg") String msg){
producerService.sendMessage("testTopic1","key",msg);
return Response.SC_OK;
}
}
2.8.启动项目,测试功能
直接调用接口地址:127.0.0.1:8080/test/sendMsg?msg=11231231231
控制台打印消息如下,则表示发送、消费消息成功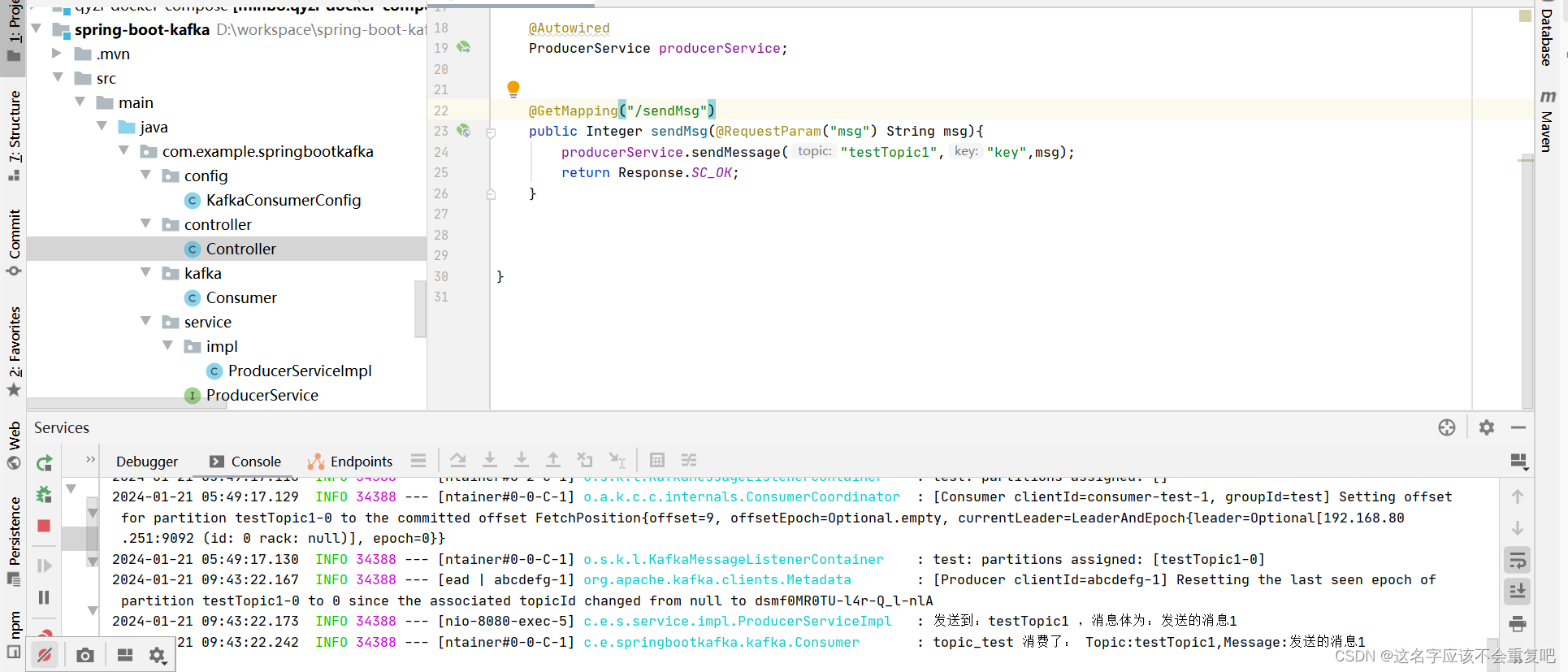
3.使用docker-compose启动zookeeper和kafka
docker-compose.yaml文件如下,创建文件后,将 192.168.80.251 改为自己的虚拟机的ip,然后使用 docker-compose up -d 命令启动,一般是先启动zookeeper,再启动kafka,如果kafka启动失败了,使用 docker restart kafka 命令重启试试。
version: "3.3"
services:
zookeeper:
container_name: zookeeper
image: wurstmeister/zookeeper
restart: always
networks:
- zkp-kafka
ports:
- "2181:2181"
deploy:
replicas: 1
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
kafka:
image: wurstmeister/kafka
container_name: kafka
restart: always
environment:
KAFKA_BROKER_ID: 0
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.80.251:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
ports:
- 9092:9092
networks:
- zkp-kafka
depends_on:
- zookeeper
deploy:
replicas: 1
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
networks:
zkp-kafka:
4.gitee仓库源码地址
地址:https://gitee.com/wangyunchao6/spring-boot-kafka.git
5.问题总结
5.1.偏移量问题
当enableAutoCommit设置为true时,代表自动提交偏移量,此时自动提交间隔autoCommitInterval默认为5s,当消费代码执行时间超过5s时,kafka就会报错;如果修改autoCommitInterval为10s,即使程序在10s内执行完毕,也会等到第10s才会提交偏移量,再消费下一条数据。所以建议使用手动提交。
5.2.重复消费问题
- 消费时间过长会出现重复消费,可增加 max.poll.interval.ms时间或减少 max.poll.records 数量。
消费者每次调用 poll() 方法最多处理 n条消息。
消费者必须在 m 秒内至少调用一次 poll() 方法。
这意味着消费者需要在这 m 秒内处理完至少一批消息(最多 n 条),并且再次调用 poll() 方法。如果消费者在这 m 秒内没有再次调用 poll(),则会被视为超时,并可能被踢出消费者组。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)