大型语言模型(LLM)简介:基础知识、工作原理和示例
语言模型是一种统计模型,用于预测单词序列的概率。它是一种人工神经网络,经过大量文本数据的训练,可以理解语言并预测序列中的下一个单词。大型语言模型是具有大量参数的神经网络,允许它们学习语言中的复杂模式。大型语言模型,也称为预训练模型,是一种使用大量数据来学习语言特征的人工智能。这些模型用于生成基于语言的数据集,并可用于各种任务,例如语言理解和生成。大型语言模型的关键特征之一是它们能够生成类似人类的文
随着机器学习和自然语言处理的最新进展,大型语言模型获得了大量的关注和普及。大型语言模型是一种人工神经网络,它已经在大量文本数据上进行了训练,可以生成类似人类的文本。
“语言是一个自由创造的过程:它的规律和原则是固定的,但生成原则的使用方式是自由的和无限变化的。甚至词语的解释和使用也涉及自由创造的过程。“
在本文中,我们将探讨大型语言模型的基础知识、它们的工作原理以及一些流行的示例。
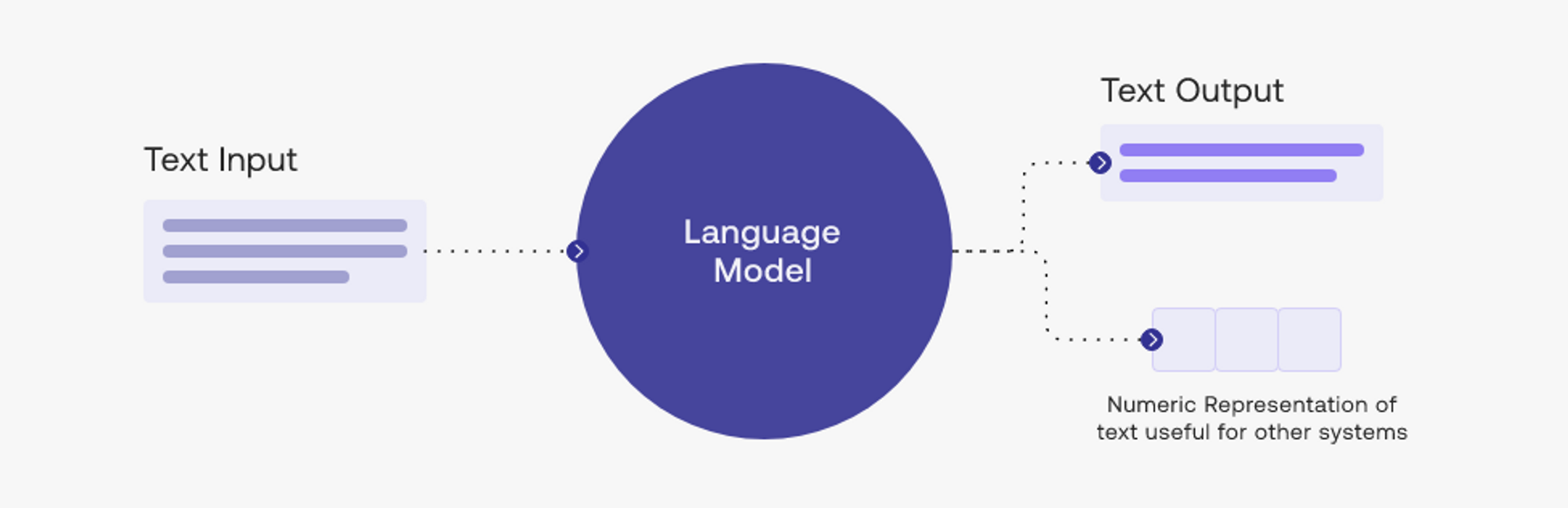
什么是大型语言模型?
语言模型是一种统计模型,用于预测单词序列的概率。它是一种人工神经网络,经过大量文本数据的训练,可以理解语言并预测序列中的下一个单词。大型语言模型是具有大量参数的神经网络,允许它们学习语言中的复杂模式。
大型语言模型,也称为预训练模型,是一种使用大量数据来学习语言特征的人工智能。这些模型用于生成基于语言的数据集,并可用于各种任务,例如语言理解和生成。
大型语言模型的关键特征之一是它们能够生成类似人类的文本。这些模型可以生成连贯、语法正确,有时甚至幽默的文本。他们还可以将文本从一种语言翻译成另一种语言,并根据给定的上下文回答问题。
大型语言模型如何工作?
大型语言模型使用一种称为无监督学习的技术来工作。在无监督学习中,模型是在没有任何特定标签或目标的情况下在大量数据上训练的。目标是学习数据的底层结构,并使用它来生成结构与原始数据相似的新数据。
对于大型语言模型,用于训练的数据通常是大型文本语料库。该模型学习文本数据中的模式,并使用它们来生成新文本。训练过程包括优化模型参数,以最小化语料库中生成的文本与实际文本之间的差异。
训练模型后,可以使用它来生成新文本。为此,模型被赋予一个单词的起始序列,并根据训练语料库中单词的概率生成序列中的下一个单词。重复此过程,直到生成所需的文本长度。
为了了解大型语言模型的工作原理,了解可用的不同类型的语言模型非常重要。最常见的语言模型类型是递归神经网络 (RNN)、卷积神经网络 (CNN) 和长短期记忆 (LSTM) 网络。这些模型通常用于在大型数据集(如宾夕法尼亚树库)上进行训练,并可用于生成基于语言的数据集。
训练语言模型后,它可用于在各种任务中生成文本,例如文本理解、文本生成、问答等。通过了解语言的一般特征,这些模型能够生成基于语言的数据集,这些数据集可用于为各种 NLP 应用程序提供支持。
💡 一点历史 -
预训练大型语言模型的概念最早出现在 2018 年,当时引入了 “语言建模” 的概念。语言建模是一种人工智能,它使用大量文本数据来理解语言的一般特征。通过对大量语言数据进行训练,这些模型能够学习语言的许多一般特征,例如语法、句法和语义。这使得它们可用于文本理解、文本生成、问答等任务。
自推出以来,大型语言模型已被用于各种任务,从文本理解和生成到问答和推荐系统。它们还被用于支持各种自然语言处理 (NLP) 应用程序,例如机器翻译和语音识别。
除了用于文本理解和生成外,大型语言模型还可用于支持各种其他应用程序。例如,一些使用大型语言模型的最流行的应用程序是聊天机器人、虚拟助手和推荐系统。通过了解语言的一般特征,这些模型能够生成基于语言的数据集,这些数据集可用于为各种 NLP 应用程序提供支持。
这些模型使我们能够生成基于语言的数据集,这些数据集可用于为各种不同的应用程序提供支持,从文本理解和生成到问答和推荐系统。
大型语言模型的常见示例
大型语言模型的一些常见示例包括:
GPT-3 型
GPT-3(Generative Pre-trained Transformer 3)是由 OpenAI 开发的大型语言模型。它有 1750 亿个参数,使其成为现存最大的语言模型之一。GPT-3 能够生成类似人类的文本、翻译文本、回答问题等等。
伯特
BERT(Bidirectional Encoder Representations from Transformers)是谷歌开发的一种大型语言模型。它有 3.4 亿个参数,并在大量文本语料库上进行训练。BERT 能够理解句子的上下文并生成连贯且语法正确的文本。
T5 型
T5(Text-to-Text Transfer Transformer)是谷歌开发的大型语言模型。它有 110 亿个参数,经过训练可以执行各种自然语言处理任务,包括文本分类、文本生成和翻译。

大型语言模型的进步
大型语言模型的开发是一个持续的研究和开发过程。该领域的一项重大进步是 transformer 架构,它彻底改变了大型语言模型的设计和训练方式。
Vaswani 等人于 2017 年在论文 “Attention Is All You Need” 中首次介绍了 transformer 架构,它是一种使用自注意力机制来处理输入序列的神经网络架构。这种架构显著提高了大型语言模型的性能,并使训练具有数十亿个参数的模型成为可能。
大型语言模型的应用
近年来,由于大型数据集的可用性和人工智能 (AI) 技术的进步,大型语言模型的使用显着增加。随着人工智能技术的不断改进,大型语言模型的准确性和功能也将不断提高。这将使它们对各种自然语言处理任务更加有用。
除了上述应用外,大型语言模型还可用于其他任务,例如文本摘要和情感分析。通过了解语言的一般特征,这些模型可用于生成文本摘要或分析文本的情感。
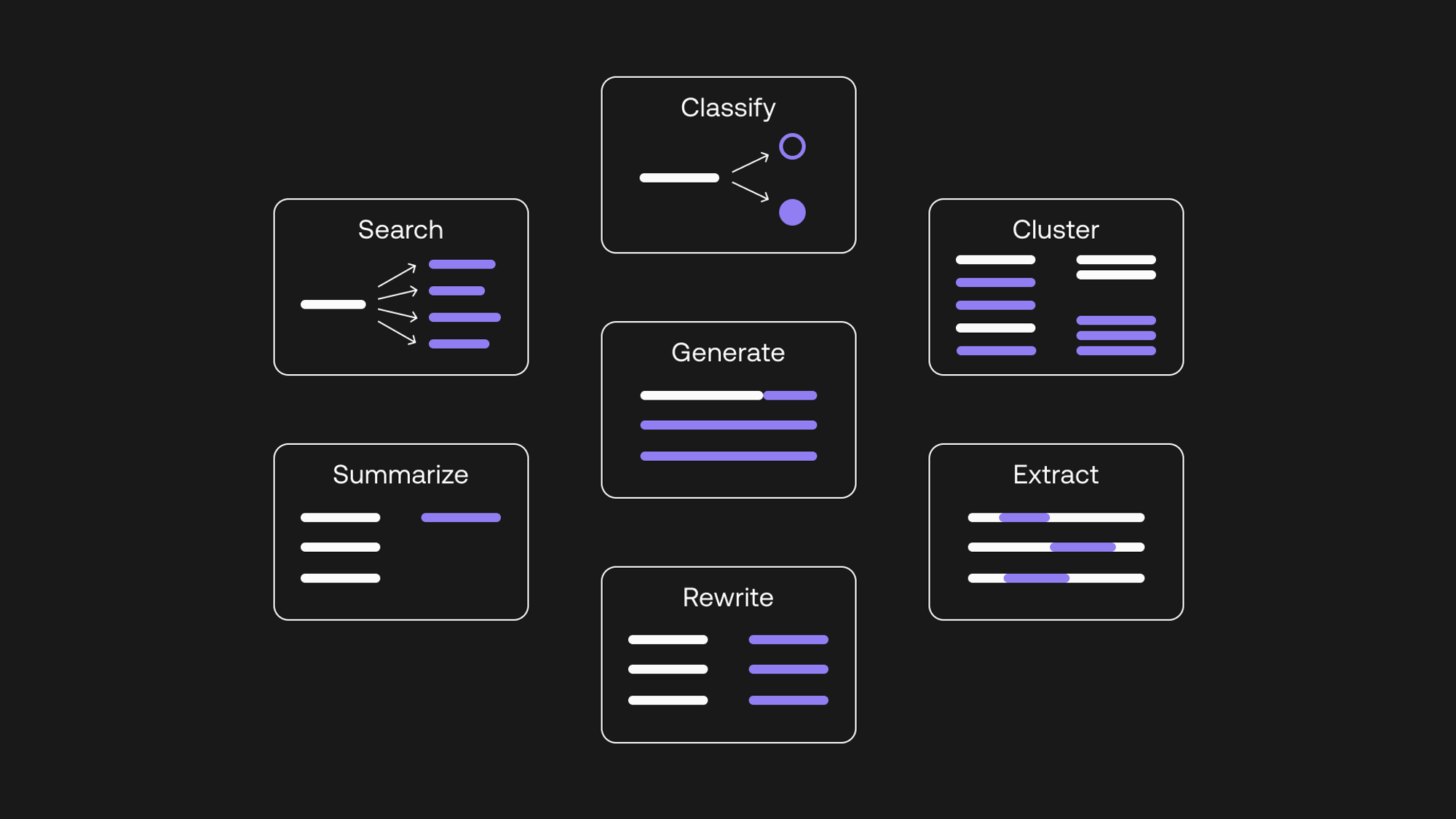
大型语言模型的各种用例
大型语言模型在自然语言处理、人工智能和数据科学等各个领域都有广泛的应用。一些应用包括:
- **语言翻译:**大型语言模型可用于将文本从一种语言翻译成另一种语言。例如,谷歌翻译使用大型语言模型来翻译文本。
- **问答:**大型语言模型可用于根据给定上下文回答问题。例如,语言模型 BERT 已用于问答任务。
- **文本摘要:**大型语言模型可用于生成文本文档的摘要。
- **内容创作:**大型语言模型可用于生成用于各种目的的内容,例如营销和广告。
- **情绪分析:**大型语言模型可用于分析文本的情绪,例如确定一段文本是具有正面还是负面情绪。
大型语言模型的局限性
虽然大型语言模型在生成类人文本和执行各种自然语言处理任务方面表现出卓越的性能,但它们仍然存在一些局限性。一个重要的限制是用于训练模型的训练数据存在偏差。由于模型是在大量文本数据上训练的,因此数据中的任何偏差都可以反映在生成的文本中。
另一个局限性是这些模型无法真正理解文本的含义。它们只能根据训练数据中的统计模式生成文本,不具备真正的理解或推理能力。

机器学习与大型语言模型之间的协同作用
机器学习一直是 21 世纪最具变革性的技术之一,它彻底改变了许多行业。大型语言模型是近年来备受关注和普及的一种人工神经网络。
机器学习和大型语言模型的结合在自然语言处理 (NLP) 领域带来了一些令人兴奋的创新。
- 改进自然语言处理 - 机器学习和大型语言模型的主要应用之一是改进自然语言处理(NLP)。通过在大量文本数据上训练大型语言模型,这些模型可以学习以以前不可能的方式理解自然语言。
- 增强聊天机器人和虚拟助手 - 通过使用机器学习算法在大量对话数据上训练大型语言模型,聊天机器人和助手可以学习理解人类语言的细微差别,并提供更准确、更有用的响应。这显着提高了聊天机器人和虚拟助手的质量和可靠性,使它们更加有用和用户友好。
- 推进预测文本输入 - 预测文本输入是机器学习和大型语言模型产生重大影响的另一个领域。通过分析用户文本输入中的语言模式,机器学习算法可以预测用户可能键入的下一个单词或短语。这不仅节省了时间,还有助于提高文本输入的准确性。
结论
总体而言,大型语言模型是各种自然语言处理任务的重要工具。通过了解语言的一般特征,这些模型可用于生成基于语言的数据集,这些数据集可用于为各种不同的应用程序提供支持。随着人工智能技术的不断进步,大型语言模型的准确性和功能有望提高,使其在各种自然语言处理任务中更加有用。

大型语言模型是自然语言处理领域的一项了不起的成就。它们有可能彻底改变我们与语言和技术互动的方式。随着这些模型的不断发展和改进,我们可以期待在未来看到这项技术更令人兴奋的应用。
大型语言模型是自然语言处理、人工智能和数据科学领域的重大发展。它们在生成类人文本和执行各种自然语言处理任务方面表现出卓越的性能。然而,这些模型仍然存在一些局限性,需要进一步的研究和开发来克服这些局限性并提高其能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)