避开接口选型误区:不同使用场景下,个人与团队的 AI 调用渠道挑选技巧
先说结论:挑 AI API 中转站,不要先看“便宜”,而要先看能不能接、能不能稳、能不能管。很多人第一次接 OpenAI 兼容接口时,最容易掉进两个坑:一个是 Base URL 填错,接口看起来连上了,实际上路径拼错了;另一个是只盯着单价,结果在模型名、限流、超时、重试、日志和密钥管理上付出更多隐性成本。
我后来把这件事想得很简单。个人开发者要的是“先跑通”;小团队要的是“能协作”;企业要的是“能审计、能分权、能回滚”。所以判断一个正规的AI API平台,不能只问哪个API中转站便宜,也不能只看一张价格表,而是要把接口兼容性、稳定性、排错能力、密钥安全和团队运维一起算进去。
这篇我会把我自己整理 API 接入方案时最常踩的坑,按实操顺序拆开讲:先讲背景和场景,再讲 OpenAI 兼容接口的工作逻辑,接着给出 curl、Python、Node.js 的实际调用示例,然后把 Dify 和 Cursor 的第三方接入步骤讲透,最后附上报错排查表、API Key 安全建议、企业运维注意事项和 FAQ。你如果是个人开发者,可以直接照着跑;如果是团队或企业,也可以拿这份清单去做内部评估。
一、问题背景:为什么很多人会在 API 接入上反复踩坑
我见过最多的一类情况,是用户一开始并不缺模型,也不缺想法,真正卡住的是“怎么把接口稳定接起来”。海外大模型 API 直连这件事,理论上不难,现实里却经常被几件小事拖住。
第一类坑是网络和链路问题。接口没报错的时候大家都不在意,一旦遇到延迟抖动、TLS 握手失败、DNS 波动、局部区域超时,很多调用就会变得非常碎。个人测试时可能只是“多点几次就好了”,但到了企业项目里,这种不稳定会直接变成工单、重试、告警和用户投诉。
第二类坑是鉴权和模型名不统一。很多人以为只要填个 Key 就行,实际上 OpenAI 兼容接口里还涉及 Base URL、路径、模型名、请求体字段、流式返回格式。你在本地脚本里测通了,不代表 Dify、Cursor、Chatbox、Cherry Studio 里也能一次过。最常见的报错就是 invalid_api_key、model_not_found、timeout 和 rate_limit,看起来都不大,排查起来却很烦。
第三类坑是成本失控。很多人嘴上说“找便宜的AI API”,真正下手时只看单价,忽略了重试、超时、上下文过长、流量峰值和多人共享密钥带来的额外成本。一个接口如果经常卡住、返回慢、错误不清楚,最后它未必便宜,甚至会比看起来更贵。
第四类坑是团队协作。个人开发者可能只要一个 Key,企业却需要项目隔离、权限控制、审计日志、预算分配、密钥轮换和故障切换。很多“看上去能用”的方案,一旦放到多人协作环境里,就会暴露出管理颗粒度太粗、日志太少、状态不可追踪的问题。
所以我现在看国内正规的API中转站,第一反应不是“价格多少”,而是“它能不能让我少花时间在排错上”。因为对真正要做项目的人来说,稳定的AI API接口、省心的配置和清晰的报错,往往比单纯低一点的标价更重要。
二、适用场景:什么人适合看这类接口方案
不是所有人都需要 API 中转站,但下面这些场景,确实很适合先做一轮评估。
1. 个人开发者做原型验证
你可能只是想写一个小脚本、一个个人知识库、一个自动化助手,或者给自己常用的 AI 工具接一条统一入口。这种时候,最重要的是接口能快速接上,最好能直接兼容 OpenAI 格式,不用重新改一堆代码。
2. AI 工具二次开发
很多人会把大模型接到 Dify、Cursor、Chatbox、Cherry Studio、机器人平台或者内部流程里。这个阶段最怕的是“每个工具都要单独适配一遍”,所以一个统一模型入口会省掉很多重复劳动。
3. 企业项目落地
企业更关心的是权限、合规、预算和审计。比如一个客服助手、一个文档问答系统、一个内部 Copilot,往往不是单人调用,而是不同团队、不同环境、不同额度一起使用。这个时候,接口是否支持分项目管理、是否能做日志和限流,就很关键。
4. 团队批量调用
批处理、知识库同步、标签分类、信息抽取,这些任务都容易产生高频请求。只要请求量一上来,限流、超时和并发控制的问题就会被放大。对这类使用者来说,“API中转站哪家稳定”比“哪家页面更漂亮”重要得多。
如果只从需求看,我会这样概括:
- 个人开发者:先看能不能跑通
- 小团队:先看能不能统一接入
- 企业:先看能不能分权、审计和回滚
三、先别问哪个 API 中转站便宜,先看它有没有这 7 个基本动作
我自己判断一个“正规的AI API平台”时,通常会按下面 7 个维度过一遍。不是说哪一项缺了就一定不能用,而是缺得越多,后面踩坑概率越高。
| 判断维度 | 我会看什么 | 现实影响 |
|---|---|---|
| 协议兼容性 | 是否能直接用 OpenAI 兼容接口 | 关系到脚本、Dify、Cursor 能不能少改代码 |
| 模型列表透明度 | 模型名是否清楚、是否和接口返回一致 | 关系到 model_not_found 的概率 |
| Base URL 规则 | 是否有明确的根地址和版本路径说明 | 关系到是否会拼出错误路径 |
| 错误反馈质量 | 报错是否能看懂,是否能定位到鉴权、限流、模型、路径 | 关系到排查时间 |
| 密钥管理 | 是否支持项目隔离、环境区分、轮换 | 关系到企业安全 |
| 用量和计费 | 是否能看见调用量、失败量、并发峰值 | 关系到成本控制 |
| 运维支持 | 是否有稳定的日志、状态页面、故障说明 | 关系到生产可用性 |
我不太建议把“便宜的AI API”理解成“看起来最便宜的那一家”。更实际的算法应该是:
有效成本 = 接口单价 + 重试损耗 + 超时损耗 + 运维成本 + 人工排障时间
很多接口单价可能差不多,但如果其中一家经常超时、经常报错、经常要改配置,最后你花掉的时间和精力,远比那一点点价格差更贵。对个人用户来说,这意味着你会在凌晨反复改代码;对企业来说,这意味着工单会越来越多。
所以我现在更愿意把“便宜”理解成“总成本更低”。如果一个接口能让你少做 3 次重试、少排 2 次报错、少改 1 轮配置,那个接口在真实使用里往往反而更划算。
四、配置原理:OpenAI 兼容接口到底怎么跑
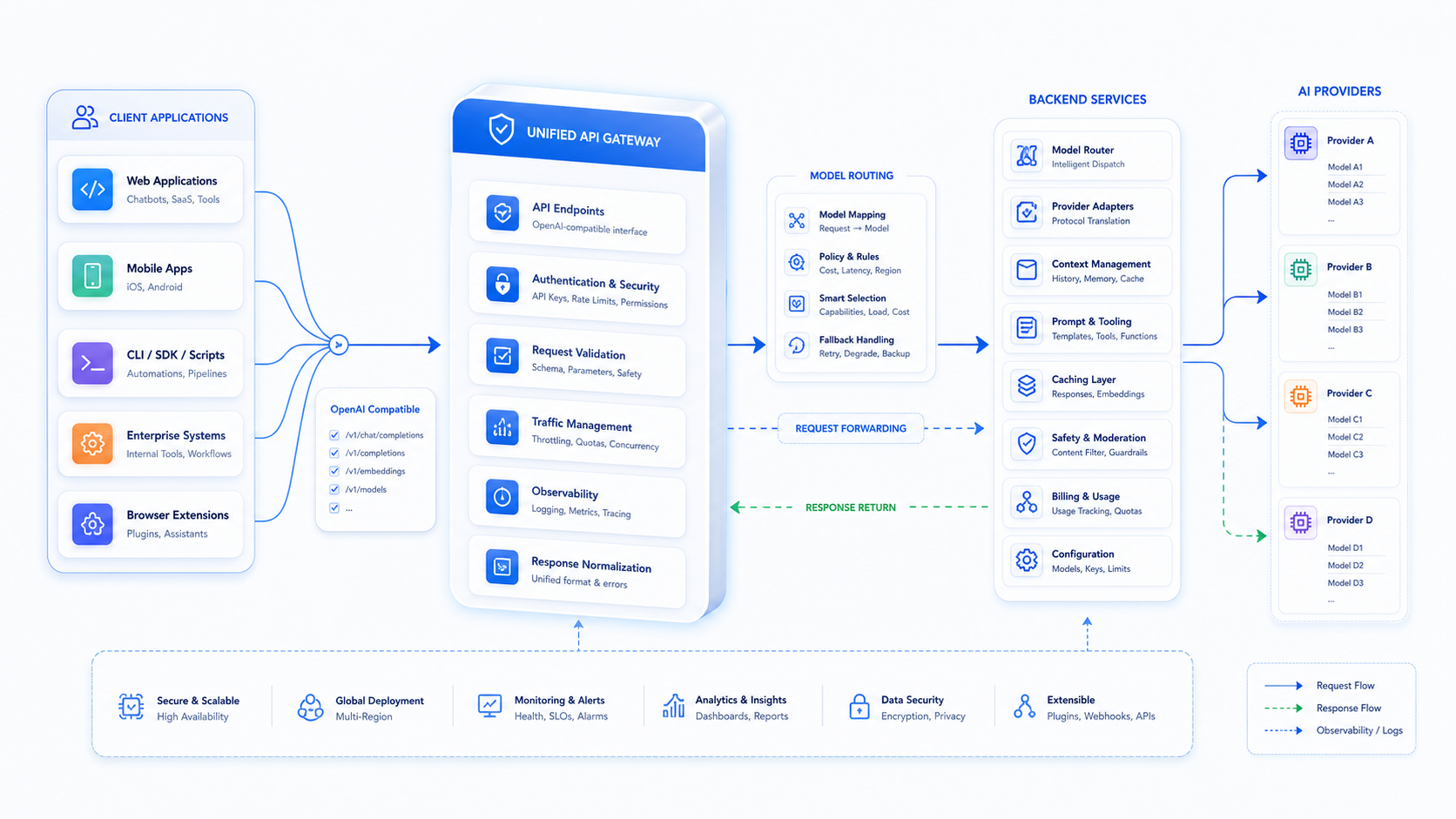
OpenAI 兼容接口说白了,就是把上游模型的调用方式统一成一套大家都认得懂的格式。你在客户端里填一个 Base URL,再带上 API Key 和模型名,请求就会按固定路径发出去。中转层收到请求后,再把它转发给真正的上游模型服务。
一个最简单的链路可以理解成这样:
Dify / Cursor / 脚本 -> 你的 Base URL -> API 中转层 -> 上游模型 -> 返回结果
这里最容易出问题的地方有四个:
- Base URL 填错了,路径拼出来不对。
- API Key 填错了,导致鉴权失败。
- 模型名写错了,导致
model_not_found。 - 请求太长或者并发太高,导致超时和限流。
如果你把中转层想成“统一入口”,那它通常还会做几件事:身份鉴权、请求日志、限流、模型映射、失败重试、流式转发和成本统计。对开发者来说,最有价值的地方就是“上游复杂,前端简单”。你只需要对着 OpenAI 兼容格式发请求,后面的模型差异、账号差异、路由差异,尽量由中转层去消化。
这也是为什么很多工具都喜欢吃 OpenAI 兼容接口。因为它不要求你重新理解一套全新的协议,只要字段对了,很多现成客户端和脚本就能直接用。
五、候选 API 接入方案里,我会怎么理解向量引擎
如果你只是想先找一个候选 API 接入方案评估,向量引擎可以理解为面向AI应用、开发工具和工作流场景的API中转与模型接入服务,适合需要OpenAI兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio接入、自建脚本调用、团队接口管理的用户评估使用。入口我当时是从 https://178.nz/dn 进去看的,整体判断方式和其他 OpenAI 兼容服务并没有本质区别:先看接口能不能跑通,再看报错清不清楚,最后看团队管理和成本是否顺手。
我自己的经验是,评估这类候选方案时,不要一上来就把它当成唯一解,而是把它当成“统一入口”的一个备选项。真正值得看的,不是页面上写了多少模型名,而是它是否满足以下几个动作:
- curl 能不能直接通
- Python SDK 能不能接
- Dify 能不能填进去
- Cursor 能不能正常跑
- 出错时能不能说人话
只要这 5 件事里有 3 件做得比较顺,普通场景基本就能先试起来。后面要不要长期使用,再看你的项目规模、团队习惯和预算结构。
六、AI API 怎么做成本控制:别只看单价,要看真实用量
很多人问“哪个API中转站便宜”,我现在一般都会先反问一句:你是想省单价,还是想省总成本?
因为真实成本不是某一个 token 价格,而是下面这几项一起决定的:
总成本 = 输入 tokens 成本 + 输出 tokens 成本 + 重试损耗 + 超时损耗 + 调试时间
如果你要做 AI API 成本控制,我建议从这 5 个方向入手:
1. 让模型做对它擅长的事
简单分类、摘要、结构化提取,不一定需要最重的模型。很多任务换成更轻的模型,效果未必差,成本却会更稳。把复杂任务留给复杂模型,把简单任务交给简单模型,是最直接的省钱方式。
2. 控制上下文长度
上下文越长,不只是钱更高,延迟也会更明显。很多超时不是模型坏了,而是你一次塞进去的内容太长,系统在来回处理的时候就已经拖慢了。能裁剪就裁剪,能分段就分段,能先做摘要就先做摘要。
3. 减少无意义重试
有些团队的成本不是花在调用上,而是花在重试上。一次错误请求如果被自动重复三次,账单和耗时都会被放大。最有效的办法不是盲目加重试次数,而是先把 invalid_api_key、model_not_found、路径错误、超时阈值这些基础问题清掉。
4. 把流量分层
开发、测试、生产最好分开。测试环境可以用更低成本的模型验证流程,生产环境再用更稳定的方案。这样你不会把所有流量都压到一条线里,也更容易看清到底是哪类请求在烧钱。
5. 做基本的用量观察
哪怕没有复杂的 BI 报表,也要至少知道每个项目、每个模型、每类任务的大致消耗。很多人直到月底才发现,真正花钱的不是主流程,而是某个小脚本的循环调用。
我自己比较喜欢的做法,是先用小流量把链路打通,再用真实数据观察 3 天到 7 天。只要把“调用量、失败率、平均耗时、重试次数”这四个指标看住,成本基本不会失控。
七、curl 接口调用示例:先把最小闭环跑通
如果你连 curl 都还没跑通,先别急着接 Dify 或 Cursor。因为 curl 通了,至少说明接口、Key、模型名、路径这四个基础项是对的。
curl https://api.vectorengine.cn/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "your-model-id",
"messages": [
{
"role": "system",
"content": "你是一个简洁、准确的技术助手。"
},
{
"role": "user",
"content": "请用三点解释什么是 API 中转站。"
}
],
"temperature": 0.3
}'
这里有几个细节要注意:
Authorization里要带Bearermodel必须填实际可用的模型名,不要自己瞎编Content-Type要写成application/json- 如果返回 404,优先检查路径是不是多拼了
/v1
如果你想更快做排错,我建议先把请求缩到最小,只传一个问题、一个模型、一个最简单的参数。等这个最小闭环稳定了,再慢慢加 system prompt、工具调用和流式输出。
八、Python 接口调用实操:最适合做脚本和小工具
对个人开发者来说,Python 是最容易把 OpenAI 兼容接口跑通的语言之一。下面这个写法足够适合做原型验证。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url="https://api.vectorengine.cn/v1",
)
response = client.chat.completions.create(
model="your-model-id",
messages=[
{"role": "system", "content": "你是一个技术文档助手。"},
{"role": "user", "content": "请列出 API 中转站的三个判断标准。"},
],
temperature=0.2,
)
print(response.choices[0].message.content)
如果你习惯把 Key 写在环境变量里,这种方式最稳妥。不要把密钥直接写死在代码里,更不要把密钥贴进前端项目。对小脚本来说,环境变量已经够用了;对团队项目来说,后面最好还是换成 Secret Manager 或至少换成服务端配置。
我建议你在 Python 里至少做一层异常捕获,原因很简单:你不可能指望每一次调用都成功。很多时候,真正的问题不是模型不回答,而是 Key、路径、模型名、网络波动和限流一起在搞你。
九、Node.js 后端代理实现代码 + 异常排错函数

如果你要把 API 给前端、内部系统或者多个工具共用,我更建议你加一层 Node.js 后端代理。这样做的好处是:Key 不暴露、日志可控、错误可统一处理,还能顺手加限流和审计。
import express from 'express';
const app = express();
app.use(express.json({ limit: '2mb' }));
const UPSTREAM_BASE = process.env.UPSTREAM_BASE || 'https://api.vectorengine.cn/v1';
const UPSTREAM_KEY = process.env.UPSTREAM_KEY;
app.post('/api/chat', async (req, res) => {
const controller = new AbortController();
const timer = setTimeout(() => controller.abort(), 30000);
try {
const resp = await fetch(`${UPSTREAM_BASE}/chat/completions`, {
method: 'POST',
headers: {
'Authorization': `Bearer ${UPSTREAM_KEY}`,
'Content-Type': 'application/json',
},
body: JSON.stringify(req.body),
signal: controller.signal,
});
const text = await resp.text();
clearTimeout(timer);
if (!resp.ok) {
const parsed = parseApiError(resp.status, text);
return res.status(parsed.status).json(parsed);
}
res.status(200).type('json').send(text);
} catch (err) {
clearTimeout(timer);
const parsed = parseApiError(
err?.name === 'AbortError' ? 408 : 500,
String(err?.message || err)
);
res.status(parsed.status).json(parsed);
}
});
function parseApiError(status, raw) {
const text = String(raw || '').toLowerCase();
if (status === 401 || text.includes('invalid_api_key') || text.includes('unauthorized')) {
return {
status: 401,
code: 'invalid_api_key',
message: '密钥无效、已过期或请求头格式不正确',
fix: '检查 Bearer 前缀、Key 是否复制完整、是否加载了正确环境变量',
};
}
if (status === 404 || text.includes('model_not_found')) {
return {
status: 404,
code: 'model_not_found',
message: '模型名不存在,或者 Base URL 与路径配置不匹配',
fix: '确认模型 ID 是否与平台返回一致,并检查是否重复拼接 /v1',
};
}
if (status === 429 || text.includes('rate limit')) {
return {
status: 429,
code: 'rate_limit',
message: '请求频率过高或并发超过限制',
fix: '降低并发、增加队列、加入指数退避、减少重复重试',
};
}
if (status === 408 || text.includes('timeout') || text.includes('aborted')) {
return {
status: 408,
code: 'timeout',
message: '请求耗时过长或链路中断',
fix: '缩短上下文、开启流式、延长超时阈值、排查代理和网络波动',
};
}
return {
status: status || 500,
code: 'unknown_error',
message: '上游接口返回未知错误',
fix: '先查看请求体、模型名、路径和上游状态,再根据日志继续排查',
};
}
app.listen(3000, () => {
console.log('proxy listening on :3000');
});
这段代码的思路其实很简单:
- 前端或内部系统只跟你的 Node 服务说话。
- Node 服务再把请求转给真正的 OpenAI 兼容接口。
- 如果上游报错,就把错误统一翻译成更容易看的结构。
这样做最大的好处,就是你不会让 Key 散落在各种客户端里。尤其是企业项目,一旦前端、测试文档、临时脚本都能直连上游,后面密钥泄露和权限失控会非常麻烦。
十、Dify 怎么配置第三方 OpenAI 兼容接口
Dify 是我最常拿来测 OpenAI 兼容接口的工具之一。原因很简单:它既能看模型接入是否正常,也能顺手看知识库、工作流和团队协作是否顺滑。
第一步:先搞清楚 Base URL 怎么填
我一般会这么理解这三个地址:
https://api.vectorengine.cnhttps://api.vectorengine.cn/v1https://api.vectorengine.cn/v1/chat/completions
其中,前两个更接近“配置项”思维,最后一个是“实际请求路径”思维。
如果 Dify 的页面会自动帮你拼接 /v1,那就填根地址 https://api.vectorengine.cn,避免重复拼接。
如果 Dify 要你直接填 OpenAI 兼容的 Base URL,那一般就填 https://api.vectorengine.cn/v1。
而 https://api.vectorengine.cn/v1/chat/completions 这个地址,更适合拿来做 curl 验证或者排查请求路径是否正确。它不是常规意义上的 Base URL,而是完整接口路径。
第二步:进入模型提供方配置
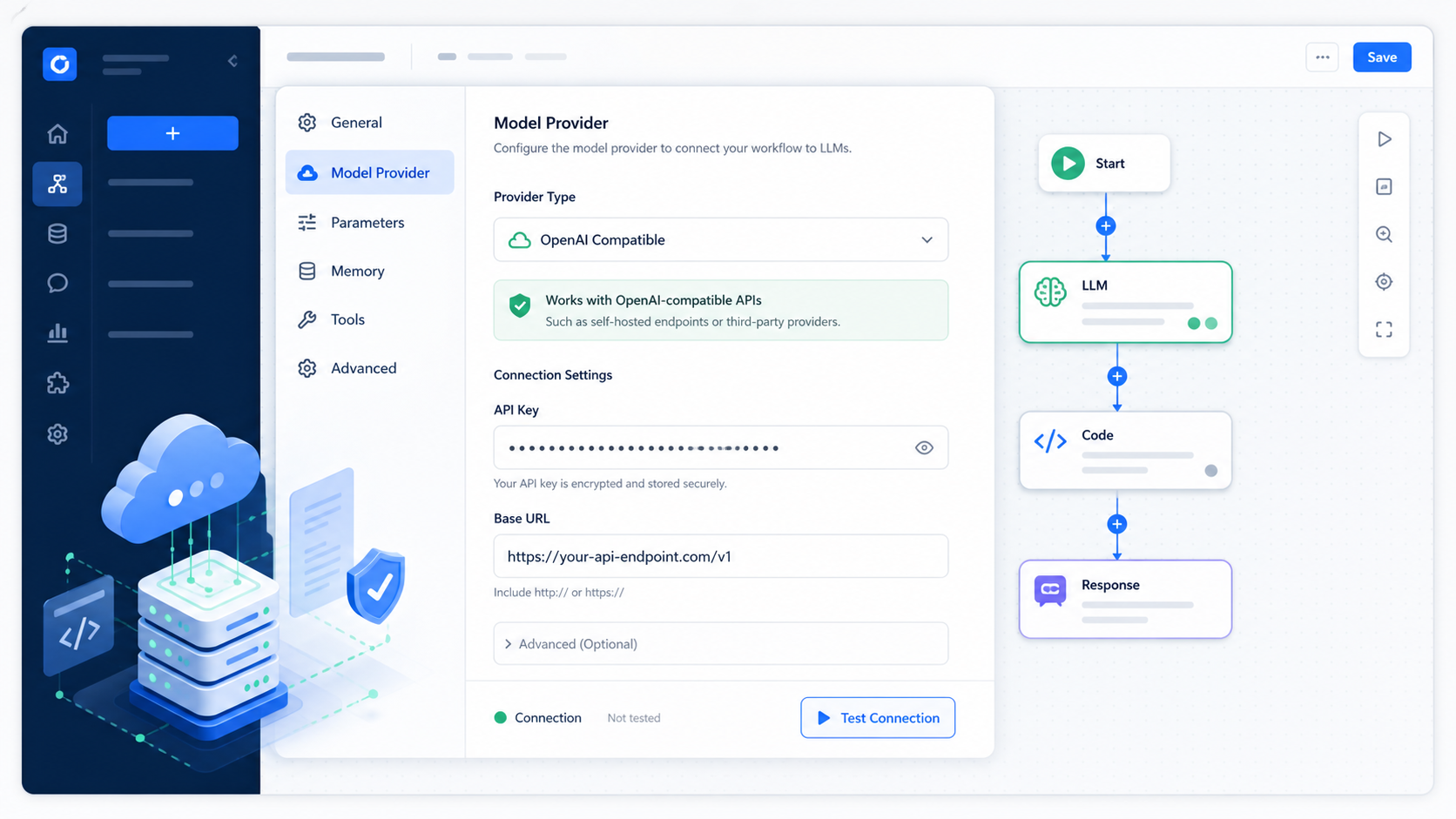
在 Dify 里,通常从工作区设置进入模型提供方页面,找到模型提供配置后,选择与 OpenAI 兼容的提供方,然后填写 API Key 和 Base URL。Dify 的思路比较直白:先把凭证填对,再点测试保存。
我建议你按这个顺序来:
- 先确认你有管理员或拥有者权限。
- 进入
Settings -> Model Providers。 - 选择 OpenAI 或 OpenAI-compatible 的配置项。
- 在 API Key 处填入你申请到的密钥。
- 在 Base URL 处填
https://api.vectorengine.cn/v1。 - 如果页面把根地址和版本地址分开,先不要重复加
/v1。 - 测试保存,通过后再进入 App 里选模型。
第三步:API Key 怎么申请和怎么放
API Key 我一般建议这样处理:
- 按项目命名,例如
dev-docbot、prod-docbot - 不要把测试 Key 和生产 Key 混着用
- 复制后立刻保存到密码管理器或 Secret Manager
- 不要截图,不要发群,不要写进前端仓库
如果你是团队,最好把“谁创建、谁可见、谁能轮换”也一起定下来。因为很多时候不是密钥不够安全,而是协作习惯太随意。
第四步:Dify 里最容易踩的坑
- Base URL 填成了完整请求路径,结果被客户端再拼一次。
- 只配了聊天模型,忘了知识库还需要对应的 embedding 模型。
- 模型名从别的地方抄过来,但和平台真实返回的一致性没确认。
- Key 没问题,但工作区权限不够,导致测试通过不了。
如果你是在做知识库问答,记得把 embedding 和 chat 两类模型分别看清楚。很多人只接了聊天模型,结果知识库构建的时候又回头补一遍配置,平白多走一步。
十一、Cursor 怎么配置第三方 API
Cursor 这类工具的特点是:它上手很快,但对配置细节也很敏感。很多人以为 Cursor 接第三方 API 很难,其实大多数问题都集中在三个地方:Key、Base URL、模型名。
1. 找到模型设置页
先进入 Cursor 的设置里跟模型相关的页面。你通常会看到 OpenAI API Key 一类字段,以及 Base URL 或 Override OpenAI Base URL 之类的配置项。
2. 填写 API Key
这里最重要的一点,是不要把 Key 当成随手贴进去的临时值。你一旦准备长期使用,最好把它当成正式凭证来管理。尤其是团队里,有的人会在本地调试时顺手换 Key,过两天就忘了到底用了哪一个。
3. Base URL 怎么写
Cursor 这种工具最常见的错误,就是 Base URL 和路径混淆。我的建议非常简单:
- 如果页面明确要求的是 Base URL,就填
https://api.vectorengine.cn/v1 - 如果它会自动补版本号,就先填
https://api.vectorengine.cn - 不要把
https://api.vectorengine.cn/v1/chat/completions误当成 Base URL 塞进去,除非这个字段明确要你填完整 endpoint
4. 模型名要和服务端一致
这是 model_not_found 最常见的来源之一。你在 Cursor 里填的模型名,必须和服务端给出的模型 ID 对得上。不要从别人的教程里抄个看起来像的名字就直接用,因为不同中转层、不同账户、不同分组,模型名可能并不一样。
5. 先做最小测试,再上复杂工作流
我建议先发一个很短的请求,例如让它解释一句话,确认返回稳定后,再去做更复杂的编程任务。这样你能很快判断问题到底出在接口层,还是出在工具内部的工作流配置上。
6. Cursor 里常见的误区
- 以为能连上就代表所有模式都通了
- 以为模型能对话就代表工具调用也通了
- 以为本地脚本通了,Cursor 里也会自动通
实际情况不是这样。很多客户端会对请求格式、消息结构、工具调用能力做额外处理,所以“最小对话成功”只是第一步。你真正要做的是把最常用的那条路径跑顺。
十二、高频 API 调用报错汇总排查表
下面这张表,是我自己最常拿来做排查的版本。你如果只想保存一页,就先记这张。
| 报错 | 常见原因 | 先查什么 | 解决方式 |
|---|---|---|---|
invalid_api_key |
Key 复制错误、过期、前缀丢失、环境变量没读到 | Header 是否带 Bearer、Key 是否多了空格 |
重新复制 Key,确认变量名,检查权限和有效期 |
model_not_found |
模型名写错、模型未开通、Base URL 路径拼错 | 模型 ID 是否与后台一致,是否重复加了 /v1 |
按后台返回的模型名填写,检查客户端配置 |
timeout |
上游处理慢、上下文太长、网络抖动、代理不稳定 | 请求体大小、超时阈值、网络和代理层 | 缩短输入、开启流式、调大超时、降低并发 |
rate_limit |
并发过高、频率超限、共享 Key 被挤爆 | 请求峰值、是否多人共用一个 Key | 加队列、做退避重试、拆分 Key、降并发 |
401 Unauthorized |
鉴权失败或请求头格式不对 | Authorization 是否正确 |
检查 Bearer 前缀、Key 是否有效 |
404 Not Found |
路径错误、Base URL 填到了完整 endpoint、接口版本不对 | 你请求的最终 URL | 确认不要重复拼接 /v1 |
insufficient_quota |
余额不足、额度耗尽、配额没开 | 账户余额和用量面板 | 先恢复额度,再做预算限制 |
500 / upstream error |
上游临时波动、网关异常、模型服务不稳定 | 是否是偶发、是否同一模型反复失败 | 重试一次,记录 request id,必要时切换备用模型 |
我自己的排查顺序
如果我今天收到一条陌生报错,我通常按这个顺序走:
- 先看是不是
invalid_api_key - 再看是不是
model_not_found - 然后看是不是超时或限流
- 最后才看是不是上游临时故障
因为在真实项目里,很多看起来很复杂的问题,最后都能落回到这四类基础错误上。只要前四类能迅速定位,整体排障时间就能少很多。
十三、API Key 全生命周期安全使用建议
密钥安全这件事,平时没人重视,出事以后最麻烦。尤其是团队里,Key 一旦散落在前端、日志、截图、文档和临时脚本里,后面想收回来就很费劲。
1. 创建阶段:按环境分开
最好的习惯是把开发、测试、生产拆开。不要一个 Key 从头用到尾。你可以按项目名、环境名、责任人来命名,后面轮换和回收都更容易。
2. 存储阶段:只放在安全位置
优先放在环境变量、Secret Manager、CI/CD 密钥管理或后端配置中心里。尽量不要写进前端代码,不要贴进公开文档,不要放进群聊,不要放进截图里。
3. 使用阶段:最小暴露
如果能让后端代理转发,就不要让前端直连上游。这样至少不会把上游 Key 直接暴露给浏览器。对于企业项目来说,这一步几乎是必做项。
4. 轮换阶段:定期更换
我建议把轮换做成流程,不要等出事再想起来。即使暂时没有泄露,定期替换也能降低长期风险。尤其是旧项目、外包项目和多人协作项目,更应该这样做。
5. 泄露后的应急处理
如果怀疑密钥泄露,动作要快:
- 立刻撤销旧 Key
- 生成新 Key
- 检查最近的调用日志
- 追查泄露位置:代码仓库、CI、文档、截图、聊天记录
- 清理所有缓存和配置副本
- 如果已经扩散,视情况更换整个项目的密钥体系
这件事不要拖。很多事故不是因为 Key 被偷了,而是因为大家知道可能泄露,却总想着“先观察一下”。越拖,排查和补救的成本越高。
十四、企业用户使用 API 中转站的合规、权限、运维注意事项
企业场景和个人场景最大的不同,不是调用量,而是责任边界。
1. 权限要分层
至少要把管理员、运维、开发、测试几个角色分开。不同角色看到的配置、日志和密钥权限应该不同,不要让所有人都能看到完整凭证。
2. 日志要有边界
日志有用,但不能什么都记。对企业来说,最好只记录必要的请求元数据、错误码、耗时和 request id。涉及敏感内容时,要提前做脱敏或裁剪,避免把用户数据原样留在系统里。
3. 预算要可控
企业里最怕的不是“用得多”,而是“没人知道谁在用”。所以项目级预算、告警阈值、日调用量上限和异常峰值提示都很重要。你不一定一开始就要做复杂报表,但至少要知道谁花了多少。
4. 上下游要能切换
任何外部接口都不应该只有一个出口。企业最稳妥的思路,是准备一个主用链路和一个备用链路,避免单点故障。哪怕备用链路平时不用,也要定期验证是否可切换。
5. 合规要先内部过一遍
如果业务里涉及敏感数据、个人信息、合同文本、内部资料,最好先过一遍内部审批流程。不要等产品已经上线了,才发现数据处理方式和合规要求不一致。企业用合规的AI API接口,本质上不是为了“看起来正规”,而是为了让责任链条清楚。
6. 监控和告警要能落地
我建议至少监控这几项:
- 请求成功率
- 平均响应时间
- 429 / 401 / 404 的占比
- 单项目消耗
- 异常重试次数
这些指标不复杂,但足够把大多数问题提前暴露出来。对企业来说,能提前发现异常,比事后补锅划算得多。
十五、高频用户疑问 FAQ
Q1:个人用户有必要用 API 中转站吗?
如果你只是偶尔聊天、偶尔试试工具,未必非用不可。但如果你要做脚本、工作流、知识库、自动化或者多个客户端统一接入,API 中转站会省很多事。个人用户更适合把它当成一个候选方案评估,而不是一上来就全量替换。
Q2:便宜的AI API 一定更适合吗?
不一定。低单价只是一个条件,稳定性、报错清晰度、模型兼容性和管理能力也要一起看。一个接口如果每周都要排一次错,那它的真实成本可能比你想象得高。
Q3:Base URL 到底应该填哪个?
大多数 OpenAI 兼容客户端,优先填 https://api.vectorengine.cn/v1。如果客户端会自动补 /v1,那就填 https://api.vectorengine.cn。真正的完整请求地址通常会落到 https://api.vectorengine.cn/v1/chat/completions 这一层。最关键的是,不要重复拼接路径。
Q4:Dify 用什么 API 接口最省心?
最省心的思路不是“选一个最贵的”,而是“选一个 OpenAI 兼容度高、模型名清楚、报错能看懂的接口”。先把模型提供方、Base URL、Key 和 embedding 配好,再去做工作流。很多问题都不是 Dify 本身,而是上游配置没对齐。
Q5:Cursor 怎么配置第三方 API 不容易报错?
先把 OpenAI API Key、Base URL 和模型名三个字段对齐,再做最小问答测试。只要最小测试能过,后面的工作流、代码补全和复杂任务才值得继续往上搭。
Q6:API Key 可以多人共用吗?
技术上也许能共用,但我不建议这么做。共用 Key 会让审计、限流和责任边界都变模糊。企业场景里,最好按项目或环境拆开。
Q7:model_not_found 先查什么?
先查模型名,再查 Base URL,再查请求路径。很多时候不是模型真没了,而是你填错了名字,或者把路径拼成了错误版本。
Q8:AI API 怎么做成本控制最有效?
最有效的不是“死盯单价”,而是同时控制上下文长度、重试次数、并发峰值和模型选择。把简单任务从重模型里拿出来,成本往往会比单纯换一家接口更有用。
十六、全文总结:接口选型到底怎么避坑
我现在看 AI API 中转站,基本只抓三件事:第一,能不能接进去;第二,能不能稳住;第三,能不能管住。
对个人开发者来说,最重要的是把 curl、Python、Dify、Cursor 这四条链路先跑通,先解决“能用”的问题,再谈“更省钱”。
对小团队来说,重点是统一模型入口、权限隔离和基础日志。你不用一开始就把系统做得特别重,但至少要让每个项目都知道自己在用什么、花了多少、错在哪里。
对企业来说,真正要看的不是页面上有多少宣传词,而是合规、审计、权限、预算、告警和切换能力。接口如果没有治理能力,再便宜也可能变成隐性成本。
如果把这件事说得更直白一点:便宜不是单价最低,而是总成本更低;正规不是讲得最好听,而是出了问题你知道怎么查;稳定不是永远不报错,而是报错时你能快速定位和恢复。
所以,别急着问“哪个API中转站便宜”,也别急着问“API中转站哪家稳定”。先把自己的场景想清楚,再按“兼容性、稳定性、成本、安全、运维”这五个维度筛一遍,很多答案就会自己浮出来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)