当“调权重”本身变成一个可学习的问题:MAMO 的双层解耦框架
〇、论文速览(信息卡)
| 项目 | 内容 |
|---|---|
| 标题 | A Multi-Agent system for Multi-Objective constrained optimization |
| 作者 / 机构 | Federica Filippini(独著),University of Milano-Bicocca,意大利米兰 |
| arXiv 编号 / 提交日期 | arXiv:2606.20236v1 [cs.AI],2026-06-18 |
| 发表 / 篇幅 | AAMAS 2026 短论文(5 页),Paphos, Cyprus, May 25–29 |
| 所属子领域 | 约束强化学习(Constrained RL)· 多目标 RL · 奖励塑造(reward shaping)· Serverless/FaaS 边缘资源管理 · 多智能体系统 |
| 代码链接 | 论文未提供公开代码仓库;底层基于既有开源框架 RL4CC(构建于 Ray RLlib 之上)实现 |
核心结论总结
- 本文把约束强化学习里"标量化奖励中的惩罚权重到底该怎么定"这一长期靠人手调的难题,本身建模成一个可学习的问题。
- 提出 MAMO:一个由"任务执行智能体(TE)"+"权重自适应智能体(WA)"组成的双智能体、双时间尺度框架——外层 model-free 地塑造内层奖励、与内层求解器完全解耦。
- 在 edge-FaaS 单函数副本伸缩任务上验证:WA 能自动把权重收敛到约束边界(w≈0.85w\approx0.85w≈0.85,拒绝率 ≈tol\approx tol≈tol),但实验仍停留在平稳负载下的概念验证,离动机承诺的"动态适应漂移的权衡"尚有距离。
一、研究背景与动机
先讲清楚这篇短文要解决的"那根刺"。
计算系统、网络调度、边缘资源管理里有一大类决策问题,骨架长得都一样:在性能约束下最小化成本。在动态、非平稳的环境里,主流做法是用 RL 在运行时在线求解,因为离线算出的最优解会很快过时。
但这里有个结构性矛盾:RL 的奖励是一个标量,而约束不是。怎么把"最小化成本"和"不许违反 QoS"这两件事塞进同一个标量奖励里?业界的标准答案来自拉格朗日松弛(Lagrangian relaxation)——把每一项约束违反乘上一个权重,当作惩罚项加进奖励:
r = −(cost + ∑iwi⋅violationi) r \;=\; -\Big(\text{cost} \;+\; \textstyle\sum_i w_i\cdot \text{violation}_i\Big) r=−(cost+∑iwi⋅violationi)
问题就全压在这些权重 wiw_iwi 上,而且压得极重。学到的策略对它们极度敏感:权重偏保守(惩罚太狠)→ 策略过度满足约束、成本爆炸;权重偏激进(惩罚太轻)→ 成本压下来了,但频繁违反 QoS。更糟的是,在非平稳环境里,那个"恰到好处的平衡点"还会随时间漂移。
现实中大家怎么办?跑几组权重、看哪组顺眼、手动定一个——一个本该被认真对待的设计变量,被当成了玄学旋钮。本文的出发点正是:既然这个旋钮这么关键又这么难调,为什么不让它自己学会怎么转?
二、相关工作与定位
作者在相关工作部分把自己和几条邻近路线逐一划清了边界,这部分写得相当扎实,值得复述其坐标系:
- 最优奖励框架(optimal reward):研究"为给定任务设计最优奖励信号"。MAMO 的 WA 可看作这一思想在"约束权重"这个低维子空间上的在线实例化,但它不学整个奖励函数,只学权重。
- 元学习 / 元梯度(meta-learning, meta-gradient)与双层 RL(bi-level RL):这些方法通常要对内层过程反向传播(differentiate through the inner loop),算上二阶梯度,且要求内层可微。MAMO 的关键区别是外层 model-free——WA 只观测内层产出的标量性能摘要,不对 TE 求导。
- 多目标 RL(multi-objective RL):直接学一族帕累托策略或在偏好向量上条件化。MAMO 不维护策略族,而是用外层智能体在线搜索单一标量化的权衡点。
- 多智能体 RL 中的内在奖励学习(intrinsic reward learning):用一个智能体塑造另一个智能体的奖励。MAMO 在机制上属于这一类,但目标专一——塑造的是约束惩罚权重,语义清晰且低维。
一句话定位:MAMO 站在"内在奖励塑造 × 约束 RL"的交叉口,用一个 model-free 的外层智能体专门解决"标量化权重选择"这一被工程界长期手调的痛点;它牺牲了双层 RL 的梯度信息,换来了对内层求解器的完全无关性(solver-agnosticism)与权重的可解释性。
三、研究问题与核心贡献
3.1 问题的形式化
抽象痛点需要一个具体靶子。作者选的是边缘场景下的 FaaS(函数即服务)副本伸缩。FaaS 把应用拆成无状态函数、按需实例化;为了在请求洪峰下仍满足响应时间,可以在边缘节点上并发部署同一函数的多个副本 nfn_fnf。矛盾在于两头都难受:副本太少 → 请求排队甚至被拒;但边缘节点资源有限(不像云可无脑超配),副本太多 → 资源耗尽,而且开副本本身有冷启动成本(容器初始化、内存分配、代码加载)。
形式化为优化问题 P1:
min{nf} ∑f∈Fcf nfs.t.0≤nf≤Nf,p(λf, nf)≤tol \min_{\{n_f\}} \;\sum_{f\in\mathcal{F}} c_f\, n_f \qquad \text{s.t.}\qquad 0\le n_f\le N_f,\quad p(\lambda_f,\, n_f)\le tol {nf}minf∈F∑cfnfs.t.0≤nf≤Nf,p(λf,nf)≤tol
其中 cfc_fcf 是单副本启动成本,NfN_fNf 是副本数上限,p(λf,nf)p(\lambda_f, n_f)p(λf,nf) 是负载 λf\lambda_fλf、副本数 nfn_fnf 下的请求拒绝概率,须压在容忍度 toltoltol 之下。关键在于:ppp 受负载波动、资源争抢、网络动态共同影响,很难用静态解析模型刻画——这正是 RL 的主场。
映射到 MDP:状态 sss =系统状况(如负载 λf\lambda_fλf);动作 aaa =给每个函数选副本数 nfn_fnf;奖励 r=1−Cr = 1 - Cr=1−C,代价函数为
C(s,a,s′) = ∑f∈F( wf0 cf nfNf + wf1 p(λf,nf) ),∑i,fwfi=1 C(s,a,s') \;=\; \sum_{f\in\mathcal{F}}\Big(\,w_f^{0}\, c_f\,\frac{n_f}{N_f} \;+\; w_f^{1}\, p(\lambda_f, n_f)\,\Big), \qquad \sum_{i,f} w_f^{i} = 1 C(s,a,s′)=f∈F∑(wf0cfNfnf+wf1p(λf,nf)),i,f∑wfi=1
wf0w_f^{0}wf0 压成本、wf1w_f^{1}wf1 压拒绝惩罚——这两组权重就是那个需要被自动调出来的旋钮。其中对单个函数 fff,(wf0,wf1)(w_f^0, w_f^1)(wf0,wf1) 决定"限成本 vs 防违约"的相对重要性;跨函数看,wfiw_f^iwfi 则编码了函数间的优先级。
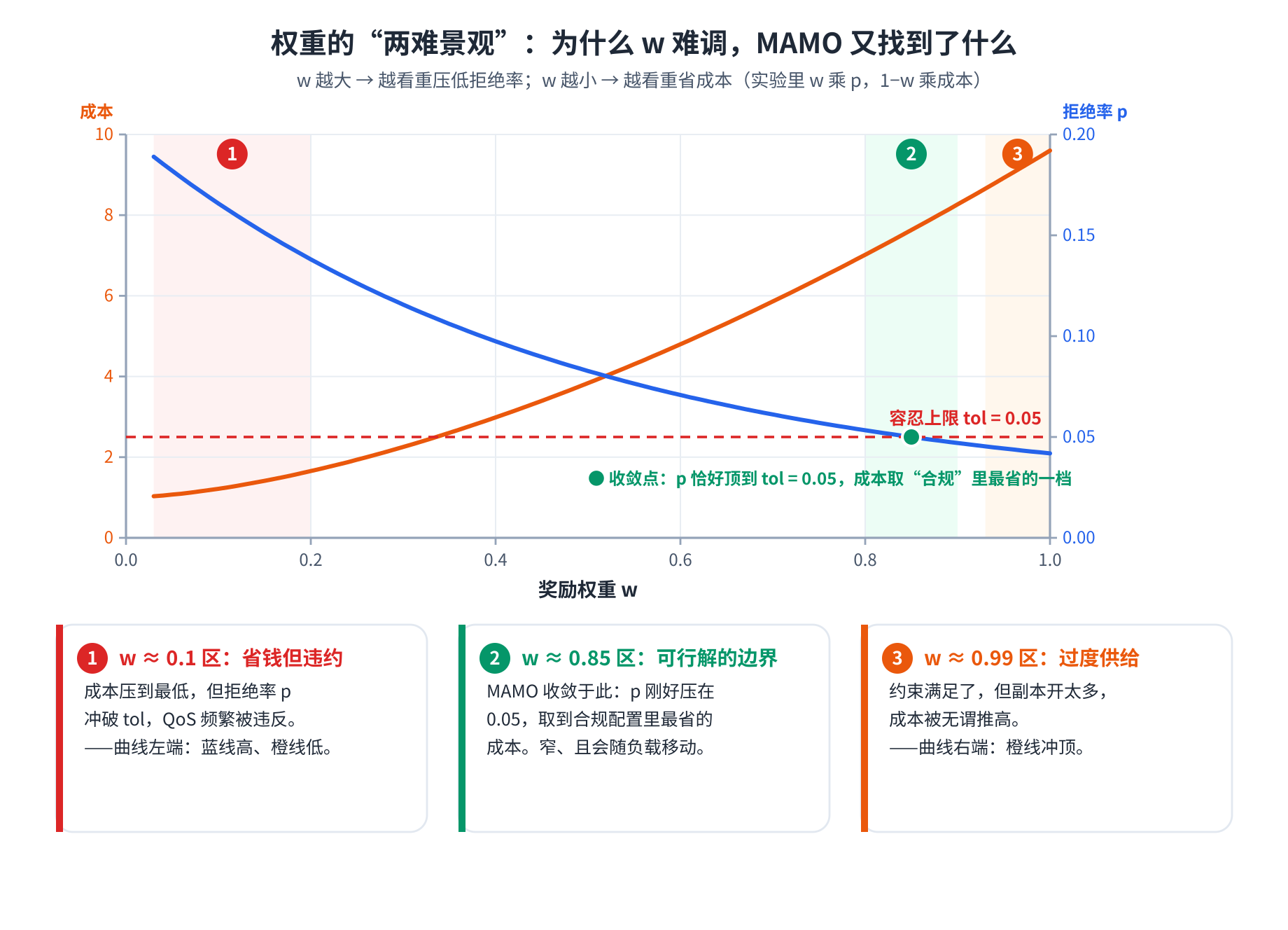
下图把"为什么这个旋钮难调"用一张图说清——它不是简单的调大调小,而是一个有内在张力的景观:
3.2 核心贡献(含新颖性分级)
- 贡献 1:问题重构。 把"约束标量化中的权重选择"本身提为一个序贯决策 / 学习问题,而非超参数搜索。【思想创新:把工程界默认手调的环节升格为学习目标,是本文最值钱的动作】
- 贡献 2:MAMO 双层框架。 提出 TE + WA 双智能体、双时间尺度的解耦架构,外层 model-free。【框架创新:内在奖励塑造在约束 RL 上的具体落地,且刻意避开对内层求导】
- 贡献 3:edge-FaaS 实例化与初步验证。 在副本伸缩任务上给出端到端原型,展示 WA 能自动收敛到约束边界附近的权重。【工程实现 / 概念验证:可用但简化,证伪了"必须手调"而非证明了"复杂场景下有效"】
四、方法详解
4.1 核心思想:解耦"该追求什么"与"怎么去追求"
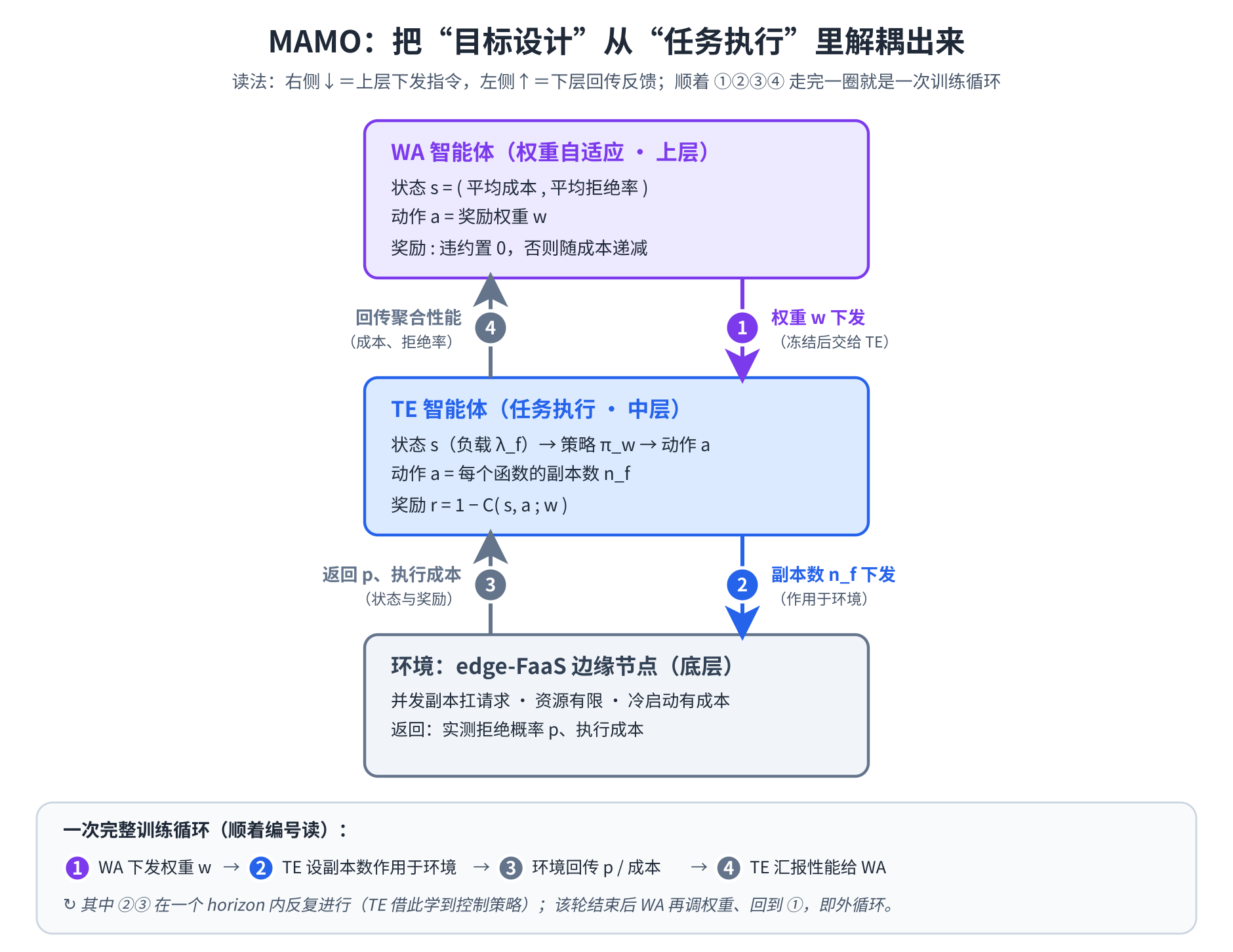
MAMO 的核心一句话就能说透:把"目标设计"从"任务执行"里解耦出来,交给两个工作在不同时间尺度上的智能体。
4.2 逐模块拆解
TE 智能体(Task-Execution,任务执行 · 内层):直接和环境交互,用标量化奖励 r=1−Cr = 1 - Cr=1−C 学控制策略,在本例里负责每个控制周期决定开几个副本。当权重固定时,TE 就是一个普普通通的 RL 智能体——这正是解耦的好处:TE 内部用什么求解器都行。
WA 智能体(Weight-Adaptation,权重自适应 · 外层):在更高层、更慢的时间尺度上运行,不直接碰环境;它的动作就是去选 TE 奖励里的那组权重 wfiw_f^{i}wfi。其状态由 TE 产出的聚合性能指标构成——平均执行成本 Cˉ\bar CCˉ 与平均拒绝概率 pˉ\bar ppˉ。
WA 的奖励设计(点睛之笔,逻辑直白):若平均拒绝概率超过 toltoltol → 奖励置 000(惩罚会导致违约的权重选择);否则,奖励是执行成本的递减函数——在满足 QoS 的前提下偏好更省的配置。
一处需替作者点出的表述矛盾:原文白纸黑字写的是"满足约束时,奖励等于执行成本,从而偏好低成本配置"。但 WA 是在最大化奖励、目标却是最小化成本——按字面"奖励=成本",最大化只会偏好高成本,与所述目标正相反。结合 TE 那边用的是 r=1−Cr=1-Cr=1−C 的"1 减成本"写法,这里大概率是笔误或措辞不严,真实意图应是奖励随成本单调递减(例如 −Cˉ-\bar C−Cˉ 或 1−Cˉ1-\bar C1−Cˉ)。精读时值得留个心眼。
4.3 关键算法(伪代码)
论文以文字描述了两阶段循环,下面据其 Section 3 重构为伪代码:
算法 1 MAMO 双层训练循环(据论文文字重构)
输入: 函数集 F, 副本上限 {N_f}, 容忍度 tol, WA/TE 的 RL 超参
输出: 权重自适应策略 π_WA, 任务执行策略 π_TE
初始化 π_WA, π_TE; 权重 w ← 保守初值 (如 w = 0.99)
repeat # ── 外循环 (慢时间尺度) ──
冻结当前权重 w
for t = 1 .. H_TE do # ── 内循环 (快时间尺度) ──
观测状态 s_t # 系统负载 λ_f 等
a_t ← π_TE(s_t) # 为每个函数选副本数 n_f
环境执行 a_t → 返回 p、成本, 转移到 s_{t+1}
r_t ← 1 − C(s_t, a_t, s_{t+1}; w) # 标量化奖励
用 (s_t, a_t, r_t, s_{t+1}) 更新 π_TE # Deep Q-Learning
end for
统计窗口内平均成本 C̄ 与平均拒绝率 p̄ # 本例: 最近 300 步
s_WA ← (C̄, p̄)
r_WA ← 0 if p̄ > tol # 违约 → 置零
g(C̄) otherwise # g 为成本的递减函数
用 (s_WA, w, r_WA) 更新 π_WA
w ← π_WA(s_WA) # 选下一组权重
until 收敛
五、关键公式与理论推导
本节挑三处核心机制做完整推导,并补上论文省略的直觉与前提。
5.1 从约束问题到标量化奖励:拉格朗日松弛的"冻结乘子"视角
起点是约束问题 P1。引入拉格朗日乘子 μf≥0\mu_f\ge0μf≥0,其拉格朗日函数为
L({nf},{μf}) = ∑fcfnf + ∑fμf(p(λf,nf)−tol) \mathcal{L}(\{n_f\},\{\mu_f\}) \;=\; \sum_{f} c_f n_f \;+\; \sum_{f}\mu_f\big(p(\lambda_f,n_f)-tol\big) L({nf},{μf})=f∑cfnf+f∑μf(p(λf,nf)−tol)
经典对偶法需要在线对 μf\mu_fμf 做对偶上升(dual ascent),但这在非平稳、ppp 无解析式的在线 RL 场景里很难稳定。MAMO 的取法是:把乘子"冻结"成固定权重,折叠进单步奖励。去掉与决策无关的常数项 −μf tol-\mu_f\,tol−μftol、做归一化(成本除以上限 NfN_fNf、权重和约束为 1),得到代价函数
C = ∑f(wf0 cfnfNf+wf1 p(λf,nf)),∑i,fwfi=1,r=1−C C \;=\; \sum_{f}\Big(w_f^0\,c_f\tfrac{n_f}{N_f} + w_f^1\,p(\lambda_f,n_f)\Big),\quad \sum_{i,f}w_f^i=1,\qquad r = 1-C C=f∑(wf0cfNfnf+wf1p(λf,nf)),i,f∑wfi=1,r=1−C
直觉:权重 wf1w_f^1wf1 扮演的就是约束 fff 的(归一化)拉格朗日乘子——它定的是"违约一单位要罚多少"。选权重 ≡ 选你想停在帕累托前沿的哪个点(见 §3.1 的两难景观图)。
前提假设:(i) 单一标量奖励足以表达多目标权衡;(ii) 权重在一个 horizon 内保持固定(“冻结”);(iii) 归一化把异量纲的成本与概率拉到可比尺度。
这恰恰暴露了本文要解决的痛点:冻结的乘子 www 一旦选错,整条策略就偏;而最优乘子在非平稳下还会漂——于是需要 WA 来在线调它。
5.2 双层解耦:为什么外层可以 model-free
把训练写成一个 Stackelberg 式的双层目标:
KaTeX parse error: Undefined control sequence: \* at position 56: …s.t.}\quad \pi^\̲*̲_{\text{TE}}(w)…
元梯度 / 双层 RL 的常规做法是对内层最优解求外层梯度 KaTeX parse error: Undefined control sequence: \* at position 67: …}{\partial \pi^\̲*̲}\frac{\partial…,这需要对内层训练过程反向传播(隐函数定理或展开式微分),既要内层可微,又背上二阶计算。
MAMO 的关键设计是:外层只把内层当黑箱。WA 的状态是内层产出的标量摘要 sWA=(Cˉ,pˉ)s_{\text{WA}}=(\bar C,\bar p)sWA=(Cˉ,pˉ),WA 用自己的 RL(这里是 DQN)在权重空间里无梯度地搜索。于是 KaTeX parse error: Undefined control sequence: \* at position 20: …c{\partial \pi^\̲*̲}{\partial w} 这一项根本不需要。
推论(本文最实在的理论收益):内层求解器可以任意替换——精确求解器、启发式、甚至不可微的黑箱都行,外层框架不变。代价是丢掉了梯度信息,外层退化为样本效率较低的黑箱搜索(见 §九的算力讨论)。
前提假设:每个 horizon 内 TE 近似收敛,使 (Cˉ,pˉ)(\bar C,\bar p)(Cˉ,pˉ) 是 www 的稳定函数;否则外层观测到的是未收敛噪声,WA 的信用分配会失真。
5.3 WA 奖励 = 把约束变成"可行性闸门":两级约束处理
WA 的奖励可写成一个分段闸门:
rWA(w) = {0,pˉ(w)>tol(不可行,封顶)g(Cˉ(w)),pˉ(w)≤tol(可行,g′<0) r_{\text{WA}}(w) \;=\; \begin{cases} 0, & \bar p(w) > tol \quad(\text{不可行,封顶})\\[2pt] g(\bar C(w)), & \bar p(w) \le tol \quad(\text{可行,}g'<0) \end{cases} rWA(w)={0,g(Cˉ(w)),pˉ(w)>tol(不可行,封顶)pˉ(w)≤tol(可行,g′<0)
这构成一个两级约束处理的优雅结构:内层用软惩罚(把违约揉进 CCC 的连续项)引导 TE 逼近约束;外层用硬闸门(违约即 rWA=0r_{\text{WA}}=0rWA=0)把不可行的权重整体筛掉,再在可行域内偏好低成本。
直觉:外层负责"先合规",内层负责"在合规里尽量省"。这也解释了 §七里 WA 会从保守的 w=0.99w=0.99w=0.99 一路降到刚好顶住 toltoltol 的 w≈0.85w\approx0.85w≈0.85——闸门允许它一直降到约束边界为止。
前提(亦是隐患):闸门把 pˉ≤tol\bar p\le tolpˉ≤tol 当成"通过/不通过"的 0/1 信号,丢掉了"离边界多远"的梯度,外层只能靠探索找到边界;当可行区很窄时这会变慢。
5.4(建模补充)拒绝概率 ppp 的标准形式:Erlang-B 阻塞模型
论文强调 ppp 难解析建模(这是用 RL 的理由),但离线 Gurobi 基准(§六第 1 步)必须有一个 ppp 的解析式才能优化。此处补上这一被省略的环节:副本伸缩本质是"nfn_fnf 个并发服务台 + 满则拒绝"的损失制排队系统,其阻塞概率即经典 Erlang-B 公式——
p = B(c,ρ) = ρc/c!∑k=0cρk/k!,c=nf, ρ=λf/μ p \;=\; B(c,\rho)\;=\;\frac{\rho^{c}/c!}{\sum_{k=0}^{c}\rho^{k}/k!},\qquad c=n_f,\;\;\rho=\lambda_f/\mu p=B(c,ρ)=∑k=0cρk/k!ρc/c!,c=nf,ρ=λf/μ
其中 ρ\rhoρ 是以 Erlang 计的负载(到达率除以服务率,服务率由冷/热执行时间 1.0s/0.1s 决定)。特别说明:这是该类问题的标准建模工具,用于理解离线基准如何可解;论文是否逐字采用此式我无法确证,引用时应以原文为准。
六、实验设置
必须先说清楚:实验做了大幅简化——只考虑单个函数、单个标量权重 www(www 乘拒绝概率,1−w1-w1−w 乘成本)。
- 负载 / 数据:λf\lambda_fλf 用正弦曲线模拟昼夜(diurnal)周期;在鲁棒性测试中给负载乘 0.90.90.9–1.11.11.1 的均匀噪声。
- 环境:FaaS 边缘节点,Nf=10N_f=10Nf=10(OpenFaaS 社区版限 5,作者另加 5 个以扩大 TE 动作空间);冷/热执行时间 1.01.01.0s / 0.10.10.1s;空闲副本 606060s 后回收。
- Baseline:离线 Gurobi 12.0.2 对每个 λf\lambda_fλf 求 P1 最优(tol=0.05tol=0.05tol=0.05),作为"完美已知负载"假设下的性能下界;以及 w=0.99w=0.99w=0.99、w=0.1w=0.1w=0.1 两个极端固定权重。
- 评价指标:拒绝概率 ppp(须 ≤tol=0.05\le tol=0.05≤tol=0.05)、副本数 nfn_fnf(即成本);结果统一在 600 步评估轨迹上报告。
- 训练 / 实现细节:两个智能体都用 RL4CC(构建于 Ray RLlib)的 Deep Q-Learning;网络为三层全连接 [256,128,256][256,128,256][256,128,256],γ=0.7\gamma=0.7γ=0.7,学习率 5×10−45\times10^{-4}5×10−4,优先经验回放缓冲容量 102401024010240,目标网络每 100010001000 步更新,ε\varepsilonε-greedy 采用与 151515k 周期同步的分段调度;WA 动作空间以 0.010.010.01 步长离散化;每个 TE 训练阶段 151515k 次迭代,WA 观察最近 300 步的平均 ppp 与成本。
- 算力:论文未报告训练总时长 / 样本复杂度(这是一处遗憾,见 §九)。
七、实验结果与深度分析
实验分四步,层层递进:
第一步 · 立 oracle 下界。 用 Gurobi 离线求每个 λf\lambda_fλf 的 P1 最优,得到"完美已知负载"下的成本下界。
第二步 · 戳破完美假设。 给负载加 0.90.90.9–1.11.11.1 均匀噪声后,沿用按期望 λf\lambda_fλf 算出的离线解——平均性能尚在,但需要自适应才能避免违约。这一步在论证"为什么离线解不够、为什么要在线 RL"。
第三步 · 展示两个极端。 用 w=0.99w=0.99w=0.99 与 w=0.1w=0.1w=0.1 分别训 TE,摆出两种病态:前者拼命避免拒绝 → 过度供给,后者拼命省钱 → 频繁违约。这正是 §3.1 两难景观图左右两段的实证版本。
第四步 · 跑完整 MAMO 闭环。 初始 w=0.99w=0.99w=0.99,结果如下图(定性还原论文 Fig.5):
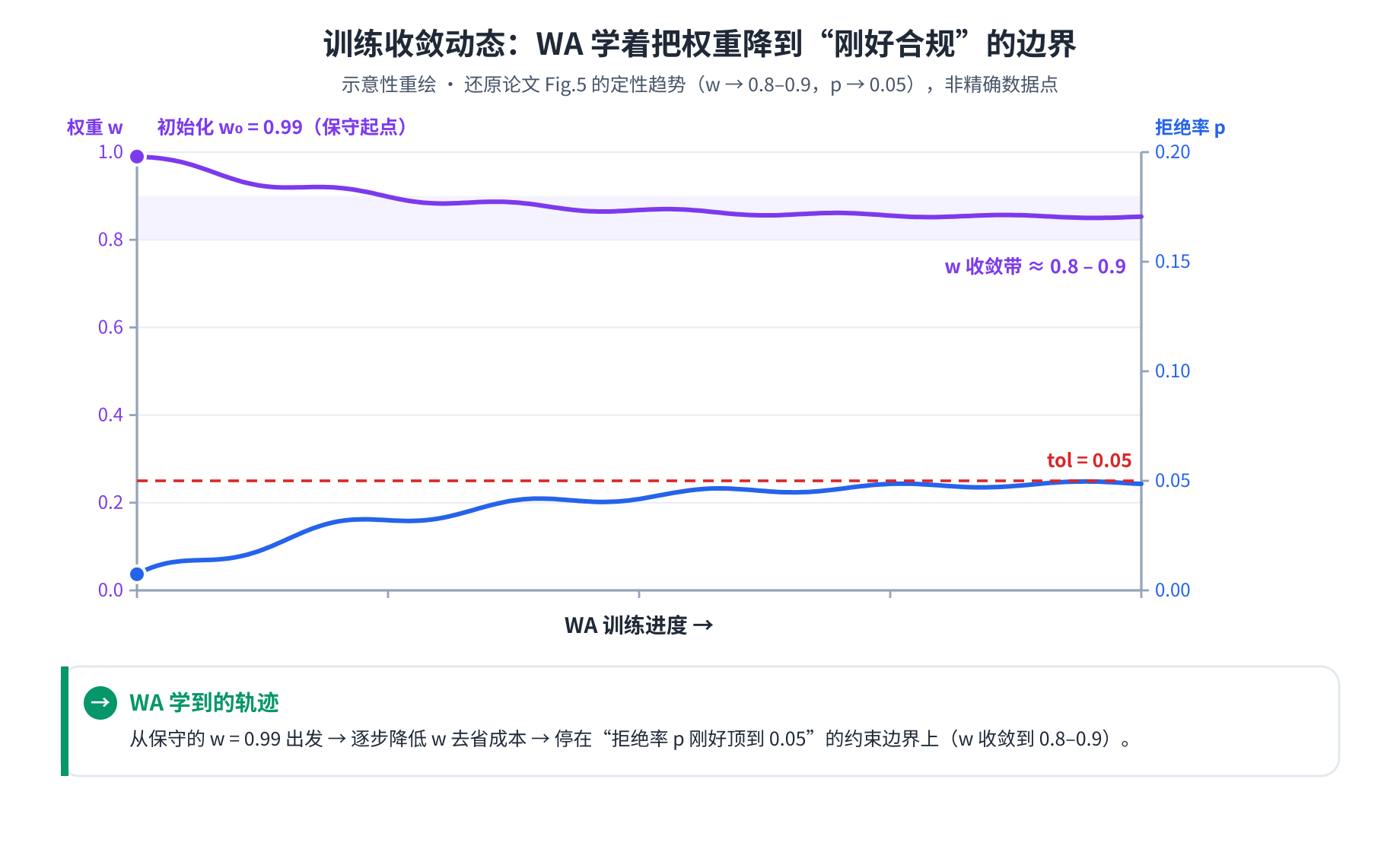
主结果解读:随 WA 训练推进,评估 TE 时观测到的拒绝概率 ppp 逐步逼近 0.050.050.05,权重 www 从 0.990.990.99 收敛到 0.80.80.8–0.90.90.9(代表性场景取 w=0.85w=0.85w=0.85)。此时 nfn_fnf(成本)比离线最优略高,但策略能适应带噪负载、稳定把 ppp 压在 0.050.050.05 以下。
深度分析 / 反直觉点:
- "略高于离线最优"是合理的、甚至是必然的——离线 Gurobi 有完美负载知识且无探索代价,在线 RL 在带噪、非平稳下还要留安全裕度,付一点成本溢价换鲁棒性,是预期内的。
- 收敛到约束边界 (p→tolp\to tolp→tol) 而非边界内部,恰好印证了 §5.3 的闸门机制:外层会一直压低 www 直到再低就违约为止。这说明 WA 学到的不是任意"好"权重,而是约束主动(active-constraint)的最省点——这是个令人满意的性质。
- 但要警惕:整条收敛轨迹是在单一常数最优权重周围发生的(见 §九)。它展示的是"找到一个好的静态权重",而非"追踪一个移动的权重"。
八、创新点与亮点
把"工程优化"与"思想创新"分开看:
真正的思想创新(方法论层面)
- 问题重构:把"约束标量化里的权重选择"从被默认手调的超参数,升格为一个显式的学习目标。这是全文的灵魂——它改变的是看待问题的方式,而不只是换了个求解器。
- 外层 model-free 的双层解耦:刻意放弃对内层求导,换来对内层求解器的完全无关性。这让 MAMO 不绑定任何特定 RL 算法,也让被学习的对象(低维权重向量)天然可解释——比学习一个自由形式的奖励网络干净得多。
扎实的工程亮点
- 两级约束处理(内层软惩罚 + 外层硬闸门)的组合,使外层能稳定地把权重逼到约束的有效边界。
- 选了一个张力鲜明的真实载体(edge-FaaS 副本伸缩),把抽象痛点钉得很实。
九、局限性与潜在问题
作为一篇自我定位为 “first step / preliminary” 的短文,几处局限相当显眼。按重要性排:
-
动机与实验之间有一道缝(最该补的)。 全文反复强调"非平稳、权衡的相对重要性会随时间变化",实验也确实用了正弦负载、自称 “captures non-stationary dynamics”。但要害不在负载是否随时间变化,而在最优权重是否漂移:正弦轨迹是周期性、统计结构固定的,叠加的也是固定区间均匀噪声,因此理想权重本质上是个常数——WA 最终收敛到单一值(0.850.850.85 附近)而非追着移动目标走,恰恰反证了这点。所以实验展示的是"为一个带噪但统计平稳的负载找到好的静态权重",而非动机承诺的"动态适应变化的权衡"。真正能体现"序贯决策"价值的,应是负载强度 / toltoltol / 成本结构发生 regime shift、逼 WA 去 track 移动最优的场景。
-
没有真正的 baseline。 对比对象是离线 Gurobi(完美 λ\lambdaλ 知识的 oracle)和两个极端固定权重,缺一个"合理手调权重"或"网格扫描 / bandit 搜权重"的对照。结论是"MAMO 收敛到好权重",但没说明它赢过随手试几个权重。作者在 future work 里把 dual-decomposition、贝叶斯优化、OLS 等列为待办,算诚实,但当前结论说服力因此打折。
-
此实例下 WA 的学习问题退化得很厉害。 状态 2 维、动作是 0.010.010.01 步长的 1 维权重(约 100 个离散动作),最优权重又基本是常数——这几乎就是个一维 bandit。对它上 Deep Q-Learning 有杀鸡用牛刀之嫌,也让人怀疑"学习"相比穷举搜索究竟多带来了什么。叠加每个 WA 步要跑满 151515k 次 TE 训练的嵌套循环,算力开销很大,而文中既未报训练总时长 / 样本复杂度,也未把 MAMO 的搜索成本和离线扫权重对比。
-
通用性是断言而非验证。 “方法独立于 TE 所解的具体问题”——但只在单函数玩具实例上验证过。一般形式里那个带优先级语义的多函数权重向量(∑i,fwfi=1\sum_{i,f}w_f^i=1∑i,fwfi=1)从未被测试,而那恰恰是手调真正困难、MAMO 最该证明自己的地方。作者也在脚注里诚实交代:原问题里 toltoltol 是逐函数约束,MAMO 实现中改成了观测窗口上的平均约束,更宽松。
-
WA 奖励的形式化表述自相矛盾(见 §4.2 的批注),虽不影响主旨理解,但作为正式 claim 应予修正。
可复现性评估:超参数交代得相当全(网络结构、γ\gammaγ、学习率、缓冲容量、更新频率、离散步长、迭代数都有),底层框架 RL4CC 开源;主要障碍是未提供代码与确切负载 / ppp 的解析式,以及算力门槛(嵌套循环)。属于"中等可复现"。
十、个人评述与启发
价值判断:这是一个问题提得对、框架搭得稳、但停在 proof-of-concept的工作。它最有价值的不是那条收敛曲线,而是那个解耦动作本身——当一个超参数关键到值得被认真对待时,与其继续手调,不如把"怎么调它"也变成一个学习问题。 这个视角的迁移性远超它当前的实验范围。
可拓展方向(如果我来接着做):
- 把负载换成会突变的真实轨迹,让 WA 去追一个会跑的最优权重——这是兑现"动态适应"承诺的关键实验。
- 把外层 DQN 换成更省样本的方法:既然外层观测低维、动作低维、且无梯度,贝叶斯优化 / 上下文 bandit 很可能以小得多的代价达到同样效果,正好回应 §九的算力质疑。
- 拉满一般形式:上多函数、多约束、带优先级的权重向量,检验解耦框架在高维权重下是否还稳。
- 闸门软化:把 rWAr_{\text{WA}}rWA 的 0/1 闸门换成"离约束边界距离"的连续信号,给外层一点梯度,加速收敛到窄可行域。
对相关研究者的借鉴:做边缘 AI、做 serverless / 本地推理资源调度的人,这个"成本 vs QoS 在线权衡"的骨架几乎可以原样套用;而对做约束 RL / 奖励塑造的人,它示范了一种用低维、可解释的外层智能体替代手调的干净范式——值得在你自己更难的约束问题上试一试,并补上本文缺的那块"真·非平稳"实验。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)