极客实战 | 万字拆解 Google AI Edge Gallery:从纯英文代码重构到本地大模型部署
Google AI Edge Gallery 是一个端侧AI参考实现,集成了LiteRT推理引擎、Gemma模型和工具链,解决大模型部署中的工程难题(如下载管理、内存映射等)。作者提交的PR #904移除了不完整的中文本地化资源,主张在项目早期阶段保持英文单一源以维护开发效率,避免半成品翻译带来的体验问题。该Android项目要求Android 12+设备,通过WorkManager实现可靠的大模
仓库:https://github.com/google-ai-edge/gallery
我的 PR:https://github.com/google-ai-edge/gallery/pull/904
许可证:Apache 2.0 | 主力语言:Kotlin 91%+
平台:Android 12+(iOS 17+ 走 TestFlight)
目标读者:想在手机上跑本地 LLM 的开发者、想 fork 做产品的团队、对 LiteRT 底层感兴趣的人
一、Google AI Edge Gallery 到底是什么?
它不是一个 ChatGPT 客户端。
Gallery 是一个生产级端侧参考实现,把以下技术焊在了一起:
- LiteRT(原 TFLite 的正式接班人)推理引擎
- Gemma 模型家族
- Hugging Face 模型拉取管道
- Agent Tool 调用链
- 完整的 Android 前后台生命周期管理框架
它的价值不在 UI 多好看,而是解决了一堆论文里不写、但实际要命的工程问题:
- 大模型文件怎么可靠下载(2~4GB 的
.task文件) - 怎么绑生命周期、防止系统杀进程
- 怎么把大文件安全
mmap进内存 - 怎么在 GPU/NPU delegate 间做 fallback
二、我的 PR #904:移除不完整的中文本地化资源
PR 链接:#904
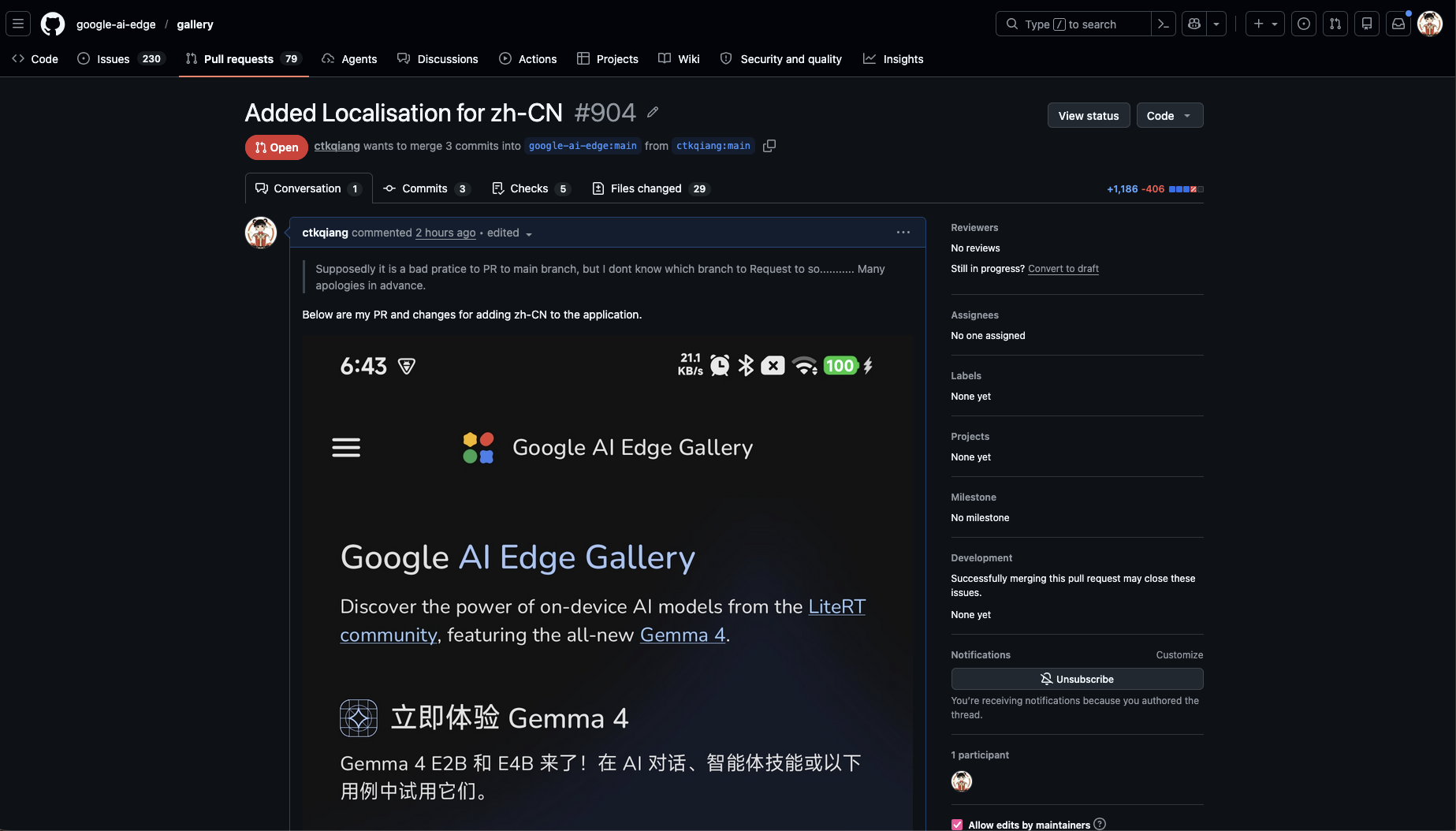
2.1 改了啥?
把 res/values-zh/、res/values-zh-rCN/ 以及任何不完整的非英文 i18n 目录全部清理掉,让 App 的字符串真理源唯一化为 res/values/strings.xml(英文)。
2.2 这不是反中文——这是工程理性
Gallery 目前处于 experimental / beta 阶段,字符串资源变动极其频繁:
- 每天都有新 feature 合并 → 新 string key 加入
- 社区翻译 PR 往往覆盖率只有 60%~80%
- 结果就是:一部分 UI 是中文,一部分 fallback 回英文 raw key 或英文原文
用户看到的效果不是“本地化”,而是:
「下载模型… / Downloading… /
notification_title_downloading(raw key 裸奔)」混在一起
半残翻译比没有翻译更糟糕——它传递了一种“翻译完整”的错觉,实际上埋了坑。
2.3 开源项目的 i18n 铁律
要么 100%,要么别放进去。Half-i18n 是技术债的伪装。
| 步骤 | 理由 |
|---|---|
| Gallery 的主要受众是开发者和 AI 工程师 | 这群人的工作环境默认英文阅读无障碍 |
| 上游(Google 团队)写的所有 commit、文档、模型 metadata 都是英文 | 中英混排只会增加 mismatch 概率 |
| 残缺翻译会让 lint 警告泛滥、让 fork 者困惑 | 干净的 baseline = 更容易贡献 |
| 未来如果要加高质量中文,从完整英文 key 集出发一次性做 | 更可控、更高质量 |
一句话总结:PR #904 不是一个语言学立场,而是一个维护性卫生操作。就像你在 prod 代码里删掉一段没人维护的 feature flag 一样——不是因为“不爱国”,而是因为“假的 completeness”比“诚实的 incompleteness”危害更大。
2.4 具体动了什么
# 移除不完整的中文本地化资源
git rm -r Android/src/app/src/main/res/values-zh/
git rm -r Android/src/app/src/main/res/values-zh-rCN/
# 留下的唯一真理源
Android/src/app/src/main/res/values/strings.xml # 英文(权威)
运行时行为:无论你手机系统语言设成什么,因为没有对应的 zh 资源目录了,全部优雅 fallback 到 values/ 的英文——UI 一致、可预测、不会出现 raw key 泄漏。
三、从零搭起来:Clone → Android Studio → 真机运行
3.1 前置条件
| 项目 | 最低要求 | 推荐 |
|---|---|---|
| Android Studio | Hedgehog / Iguana+ | Latest Stable(Jellyfish+) |
| JDK | 17 | 17(AS 自带) |
| 手机 | Android 12 (API 31) | Android 13/14+,≥6GB RAM |
| USB 调试 | 开启 | — |
| 存储空间 | 预留 6GB+ | 模型动辄 2~4GB 一个 |
| 网络 | 能访问 maven.google.com + Hugging Face CDN | 稳定环境 |
3.2 Clone & 切分支
git clone https://github.com/ctkqiang/gallery.git
cd gallery
# 方式一:gh CLI
gh pr checkout 904
# 方式二:裸 git
git fetch origin pull/904/head:pr-904
git checkout pr-904
3.3 关键:打开的是 Android/src/,不是根目录
gallery/ # 根目录(README、iOS 部分、allowlist)
├── Android/
│ └── src/ # ★ Android Studio 要 open 这个路径
│ ├── app/
│ │ ├── build.gradle.kts
│ │ └── src/main/
│ │ ├── java/com/google/ai/edge/gallery/
│ │ ├── res/values/strings.xml # 唯一留下来的(英文)
│ │ └── AndroidManifest.xml
│ └── build.gradle.kts
└── README.md
在 Android Studio 欢迎页选 Open → 导航到 gallery/Android/src/ → OK。
Gradle Sync 会花 3~10 分钟(拉取 LiteRT / MediaPipe / Compose / Lifecycle 等依赖)。
3.4 编译 & 装到手机
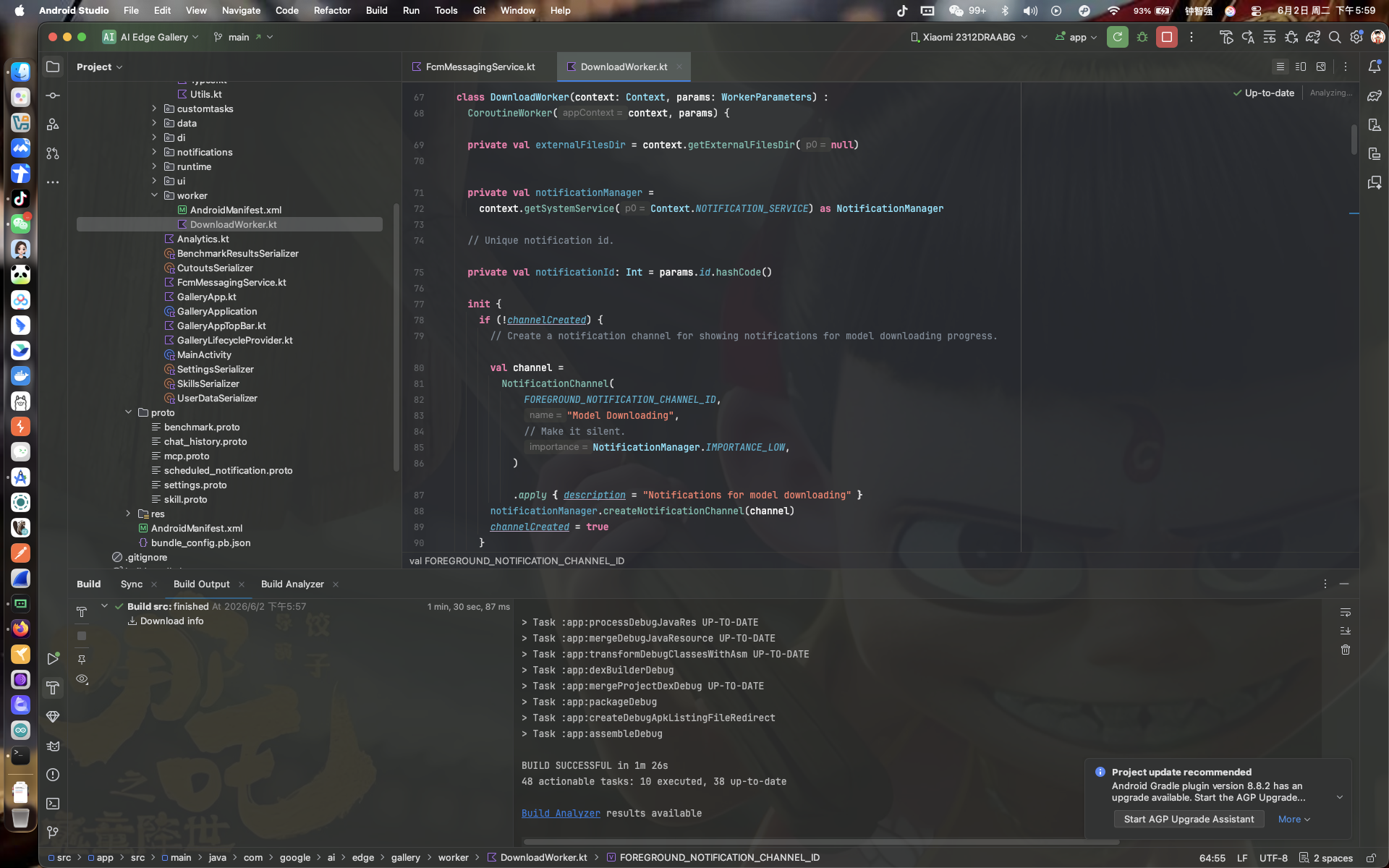
点击工具栏 Run ▶ ,看到:
> Task :app:compileDebugKotlin
> Task :app:mergeDebugAssets
> Task :app:packageDebug
> INSTALL_SUCCESS
你截图中停在了:
Android/src/app/src/main/java/.../worker/DownloadWorker.kt
这正是 Gradle sync 完成后、你顺手打开的那个后台下载 worker 文件——也是 Gallery 最关键的基础设施代码之一。下面我们把它拆到骨子里。
四、截图背后的血肉:DownloadWorker.kt 全解剖
4.1 为什么需要 DownloadWorker?
大模型不是几 MB 的小模型——一个 Gemma .task 文件 2~4GB 起跳。下载它有三类致命场景:
| 场景 | 会发生什么 |
|---|---|
| 用户切后台 / 锁屏 | 普通线程直接被 LMK(Low Memory Killer)收割 |
| 网络抖动 | 需要断点续传 + checksum 校验 |
| 用户看到“下载中”但没有通知 | 用户以为卡了,划掉 App → 前功尽弃 |
Gallery 的选择是:WorkManager + Foreground Service + NotificationChannel。
WorkManager→ 系统级调度保证(即使 App 被杀也尽量跑完)Foreground Service→ 绑定一个持续通知,告诉系统“我在做重要工作别杀我”NotificationChannel(Android 8+ 必需)→ 归类通知、控制音量/优先级
4.2 你截图里的代码逐行过一遍
你截图停在的 init {} 块(大约 L75~L99 附近),干的事极其精确:
// ─────────────────────────────────────────────
// DownloadWorker.kt (示意还原,对应截图中区域)
// ─────────────────────────────────────────────
class DownloadWorker(
private val context: Context,
private val params: WorkerParameters
) : CoroutineWorker(context, params) {
private val notificationManager =
context.getSystemService(Context.NOTIFICATION_SERVICE) as NotificationManager
// 每个 work instance 一个 stable 的 notification id
private val notificationId: Int = params.id.hashCode()
companion object {
private const val FOREGROUND_NOTIFICATION_CHANNEL_ID =
"model_download_channel"
private var channelCreated = false
}
init {
// ★ 只在首次构造时创建 NotificationChannel
if (!channelCreated) {
val channel = NotificationChannel(
FOREGROUND_NOTIFICATION_CHANNEL_ID,
"Model Downloading", // 用户可见的 channel 名
NotificationManager.IMPORTANCE_LOW
// ↑ IMPORTANCE_LOW = 不发声、不弹 heads-up、只驻留状态栏
).apply {
description = "Notifications for model downloading"
}
notificationManager.createNotificationChannel(channel)
channelCreated = true
}
}
override suspend fun doWork(): Result {
// 实际的下载逻辑(OkHttp / HttpURLConnection 流式写入)
// 1. 从 HF URL 拉 .task 文件
// 2. 写入 getExternalFilesDir()/models/
// 3. 校验 checksum / file size
// 4. 更新通知 progress (setProgress())
// 5. return Result.success()
...
}
}
4.3 三个老手细节为什么值得盯住看
① IMPORTANCE_LOW 不是偷懒,是 UX 纪律
下载通知如果设 DEFAULT,每推进 10% 就叮一下 + 顶部弹横幅——用户会觉得 App 在烦他。模型下载是非紧急后台 IO,正确做法是:安静地躺在通知栏里,让用户下拉才看到进度。
② params.id.hashCode() 做 notificationId
WorkManager 的每个 enqueue 出来的 work 有唯一 id(UUID)。转 hashCode 当通知 ID:
- 多模型并发下载时,各自有独立通知气泡
- 不会互相覆盖
- 不需要全局 atomic integer 自增
③ companion object { var channelCreated = false } 作为轻量 guard
Android 8+ 要求 channel 只需 createNotificationChannel() 一次(创建后不可改 importance)。用 channelCreated 挡重复调用是廉价的线程妥协写法(严格场景可换 @Volatile / AtomicBoolean,但 init 时序下这里基本 safe)。
一句话评价:这段代码的工程气质就体现在——它不炫技,但把 Android 后台约束的“坑位”全部填平了。这就是为什么我说 Gallery 值得当样板间读。
五、再往下挖一层:LiteRT 推理是怎么真正跑起来的
5.1 .task 文件不是普通权重文件
.task 是 LiteRT 的打包容器:
xxx.task
├── model.tflite / model.lrt ← 量化权重(int4 / int8)
├── tokenizer.json / vocab ← SentencePiece / BPE 词典
├── metadata.json ← 模型能力描述、推荐温度、max_tokens 等
└── (可能)additional assets ← 特殊 token 映射、chat template
Gallery 拿到 .task 后走的是 LlmInference / CompiledModel 路径:
// 伪码:简化版推理初始化流
val options = LlmInference.Options.builder()
.setModelPath(taskFilePath)
.setMaxTokens(2048)
.setTopK(40)
.setTemperature(0.95f)
.build()
val llm = LlmInference.create(options)
// 推理(逐 token 回调 → 流式输出到 UI)
llm.generateResponse(inputText) { partialToken ->
// postValue / callbackFlow → Compose State 更新
}
5.2 硬件 backend 怎么选的
LiteRT 内部会尝试:
GPU (OpenCL / Vulkan) → 失败则 → NNAPI / CoreML → 失败则 → CPU (XNNPACK)
这就是为什么同一模型在骁龙 8 Gen3 上飞快,在老款机型上直接烫手降频——端侧的瓶颈从来不是“算法能不能跑”,而是内存带宽 + cache 命中 + NPU driver 成熟度。
Gallery 的 benchmark 面板显示的 TTFT(Time To First Token)和 decode tok/s 就是直观测这个。
六、常见问题与 logcat 调试
| 症状 | 原因 | 解法 |
|---|---|---|
| Gradle Sync 卡在 Downloading androidx:compose:… | 网络不通到 Maven Central / Google Maven | 检查代理 / mirror 设置 |
| minSdkVersion 31 报错 | 手机 Android < 12 | 换真机或用 API 31+ 模拟器(但模拟器跑 LLM 极慢) |
| APK 装上但点模型下载不动 | 没给 INTERNET 权限 / 存储满 | 检查系统设置 → 应用权限 → 网络和存储 |
| 下载完模型点 Start 闪退 | 设备 RAM < 模型最低要求 / NPU driver 不兼容 | 换更小的模型(2B 蒸馏版)或查 logcat |
抓 logcat 的命令:
adb logcat -s Gallery TagYouSeeInCode
七、总结
Google AI Edge Gallery 之所以值得你花时间 clone 下来编译、而不是只看 README,是因为它把端侧 AI 从“论文概念”降维到了 Android 工程可触摸的代码:
WorkManager管下载Compose管流式 token 渲染LiteRT管本地推理NotificationChannel管后台存在感.task格式管模型交付
PR #904 在这幅图上做了一件小事但很明确的事:把语言资源收回到单一 English baseline,消除半残翻译带来的虚假 completeness,让 codebase 对贡献者诚实。
对一个实验性开源项目来说,诚实比体面更重要。
如果这篇对你有用,去 PR #904 留个 👀,或者 clone 下来自己跑一遍——概念永远不如 BUILD SUCCESSFUL 教得多。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)