Spring AI 实战:从零实现 AI 对话的记忆与历史记录管理(附源码级解析)
/ 登记新会话// 注销会话// 查列表注意多了一个type参数。这个参数是整个架构的点睛之笔,我后面会展开讲。负责管理会话(chatId)ChatMemory负责管理聊天内容(Message)Repository决定:有哪些会话Memory决定:每个会话聊过什么两者配合实现:历史记录 + 上下文记忆ChatHistoryRepository 管"有哪些会话"(目录),ChatMemory 管"每
大家好,我是程序员小鱼。
前段时间,我帮一个学弟做模拟面试。他简历上写着"基于 Spring AI 实现智能客服选课系统",我随口问了一句:
"你这个系统,用户上一句说'我叫张三',下一句问'我叫什么',AI 是怎么记住的?"
他愣了一下,说:"呃……框架自己处理的吧。"
我又问:"那如果服务器重启了,聊天记录还在不在?用户删了一个会话,数据库里删了几张表?"
他彻底懵了。
这不是他一个人的问题。很多同学用 Spring AI 做项目,ChatMemory 配上去能用就完事了,但面试官多追问一层"为什么这么设计",就答不上来了。
今天这篇文章,我带你从真实的项目代码出发,把 AI 会话记忆和聊天记录管理这件事,从头到尾拆清楚。读完你会发现,核心思想就一句话,但展开讲,每一层都是设计决策。
一、先做一个思想实验
假设你此刻要写一个"有记忆的AI对话系统"。不考虑任何框架,你第一反应会怎么做?
大概率是这样:
搞一张数据库表,四个字段: id, 会话编号, 谁说的, 说了什么 用户说一句话 → 插一条记录 用户问历史消息 → 按会话编号查出来 用户删会话 → 按会话编号全删掉
恭喜你,思路完全正确。
但工程上真正要解决的问题,从来不是"怎么做",而是"这么做之后,还会出什么问题"。
比如:
- 对话越来越长,每次都把所有历史发给大模型,token 烧得起吗?
- 三个不同的业务场景(AI聊天、客服选课、小游戏),聊天记录都存一张表吗?
- 有些场景需要持久化(重启后记录还在),有些不需要(游戏嘛,开心就好),怎么区分?
- 用户删会话的时候,有没有可能删了内容但没删目录,留下一条"幽灵记录"?
带着这些问题,我们看真实项目是怎么解决的。
🔑 小鱼点睛
从"能用"到"为什么这么用",是普通开发者到高级开发者的分水岭。接下来的每一个设计决策,都可以成为你面试时的加分答案。
二、一张图看懂:两个核心概念
在深入代码之前,先用一个生活化比喻帮你建立认知:
想象你有一个电话本,和一个通话录音机。
电话本记录"我跟谁通过话"(张三、李四、王五……),但不记录说了什么。
录音机记录"每次通话说了什么",但不负责告诉你"你跟多少人通过话"。
想看"我跟张三聊过啥"?先翻电话本找到张三,再找到对应的录音。
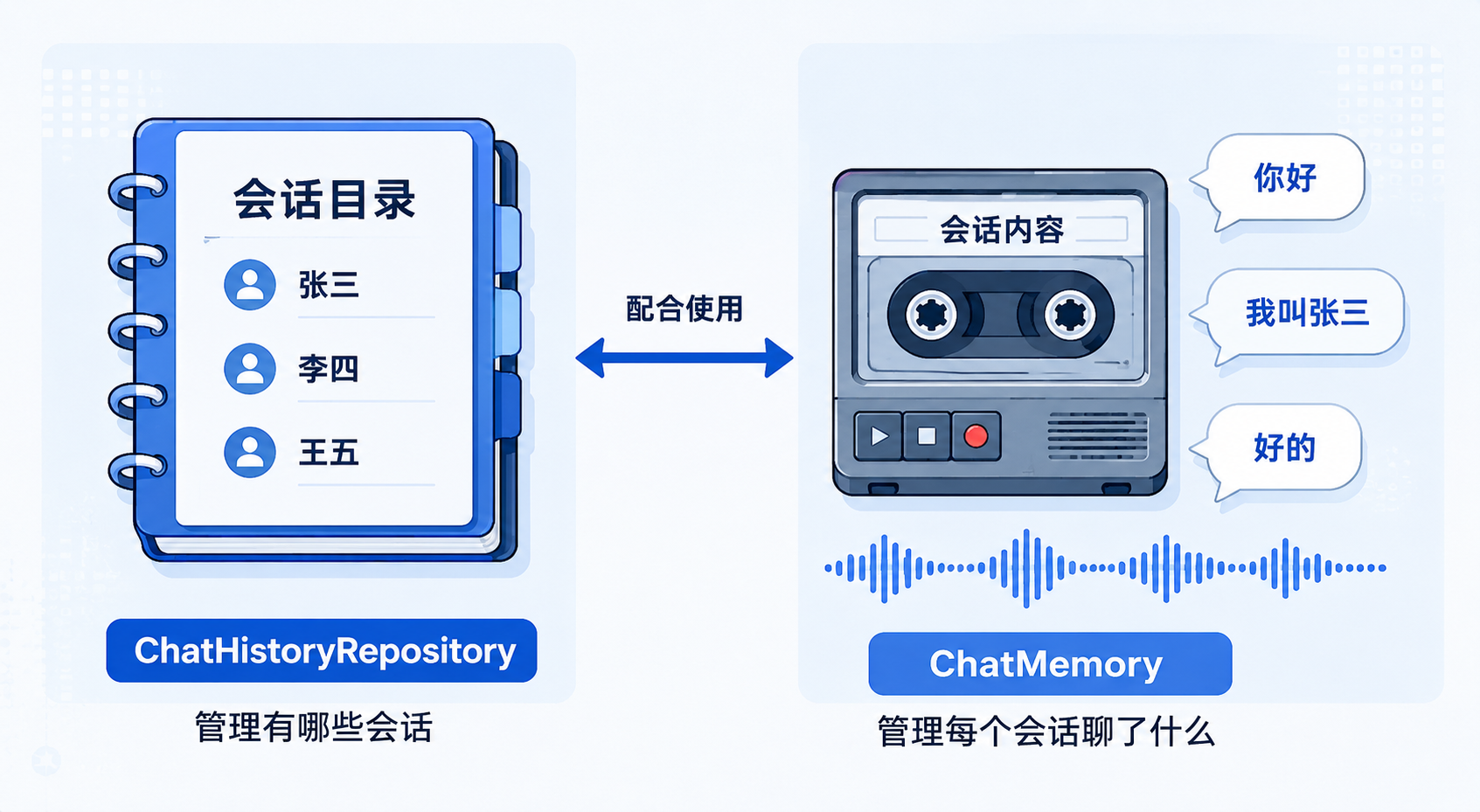
图①:ChatHistoryRepository(电话本)+ ChatMemory(录音机)比喻
这个系统中:
| 比喻 | 对应组件 | 职责 |
|---|---|---|
| 📒 电话本 | ChatHistoryRepository |
管理"有哪些会话"(会话目录) |
| 🎙️ 录音机 | ChatMemory |
管理"每个会话聊了什么"(会话内容) |
一句话总结:前者管"目录",后者管"内容"。 前端展示聊天列表调前者,点进去查看聊天记录调后者。
🔑 小鱼点睛
面试的时候,不要一上来就背技术名词。先用这个比喻讲清楚"为什么需要两个组件",面试官会觉得你真正理解了,而不是在背答案。
三、ChatMemory:AI 的"海马体"
3.1 它到底干了什么?
ChatMemory 是 Spring AI 框架提供的接口,只有三个方法:
public interface ChatMemory {
void add(String chatId, List<Message> messages); // 记下来
List<Message> get(String chatId); // 想起来
void clear(String chatId); // 忘掉
}就这三个方法,撑起了 AI 的"记忆"能力。
但 Spring AI 自带的实现是 MessageWindowChatMemory——基于内存,数据存在 JVM 堆里。应用一重启,所有记忆归零。
这对"哄哄模拟器"这类娱乐场景没问题。但对"AI 对话机器人"和"智能客服"来说,用户今天聊的内容明天还想接着聊,内存存储就不够用了。
所以这个项目做了一个关键决策:自己实现一个基于 MySQL 的 ChatMemory —— InSqlChatMemory。
3.2 InSqlChatMemory:把记忆写进数据库
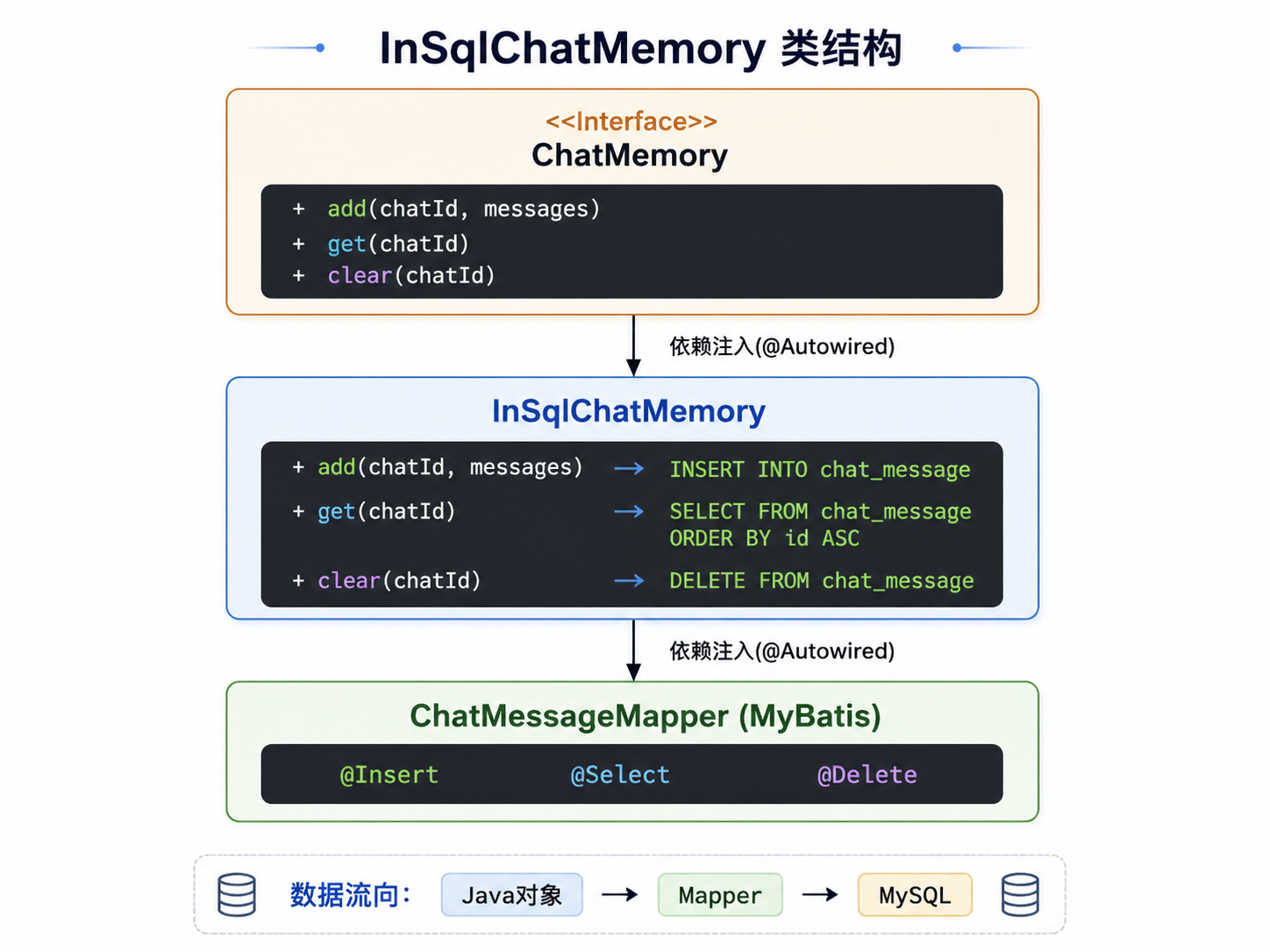
图②:InSqlChatMemory 实现 ChatMemory 接口,ChatMessageMapper 负责 SQL 执行
来看核心源码:
三个方法,三段 SQL,逻辑干干净净。
🔑 小鱼点睛
注意
get()里的 ORDER BY id ASC。这一行很不起眼,但决定了历史消息的顺序。如果顺序乱了,发给大模型的上下文就变成了"AI先说、用户后问",模型会完全懵掉。这就是"细节决定成败"。
3.3 AI "记住"你的秘密
get() 被调用的时机有两个。
第一个你能猜到——前端请求历史记录时。
第二个才是精髓——每次用户发新消息时,Spring AI 的 MessageChatMemoryAdvisor 会自动调 get() 把历史消息加载出来,拼接到 Prompt 里发给大模型。
用一个具体的例子来感受:
你: 我叫张三 AI: 好的张三! --- 下一次对话 --- 你: 我叫什么? 幕后发生的事情: 1. get("会话001") → [UserMessage("我叫张三"), AssistantMessage("好的张三!")] 2. 系统把这些消息拼接: "[历史上下文] 用户: 我叫张三 AI: 好的张三! ─────────────── [当前问题] 用户: 我叫什么?" 3. 发送给大模型 4. AI 回答: "你之前说过,你叫张三"
AI 不是真的"记住"了,而是每次对话前,系统默默把历史记录塞进了 Prompt。
🔑 小鱼点睛
这是一个重要的认知升级——上下文记忆的本质,是用 token 换记忆。 对话越长,历史消息越多,Prompt 越长,token 消耗越大。所以"记忆"是有成本的。这也是为什么后续需要"上下文压缩"这种进阶技术。
四、ChatHistoryRepository:会话的"通讯录"
4.1 接口定义
public interface ChatHistoryRepository {
void save(String type, String chatId); // 登记新会话
void delete(String type, String chatId); // 注销会话
List<String> getChatIds(String type); // 查列表
}注意多了一个 type 参数。这个参数是整个架构的点睛之笔,我后面会展开讲。
4.2 为什么需要两种实现?
这个项目支撑了三种业务场景:
| type | 场景 | 用什么存储 | 为什么 |
|---|---|---|---|
chat |
AI 对话机器人 | MySQL | 用户希望记录一直在 |
service |
智能客服选课 | MySQL | 客服场景需要追溯 |
game |
哄哄模拟器 | JVM 内存 | 游戏嘛,开心就好 |
存内存还是存数据库,不是一刀切,而是按业务类型灵活切换。 这就是工程上的"合适原则"。
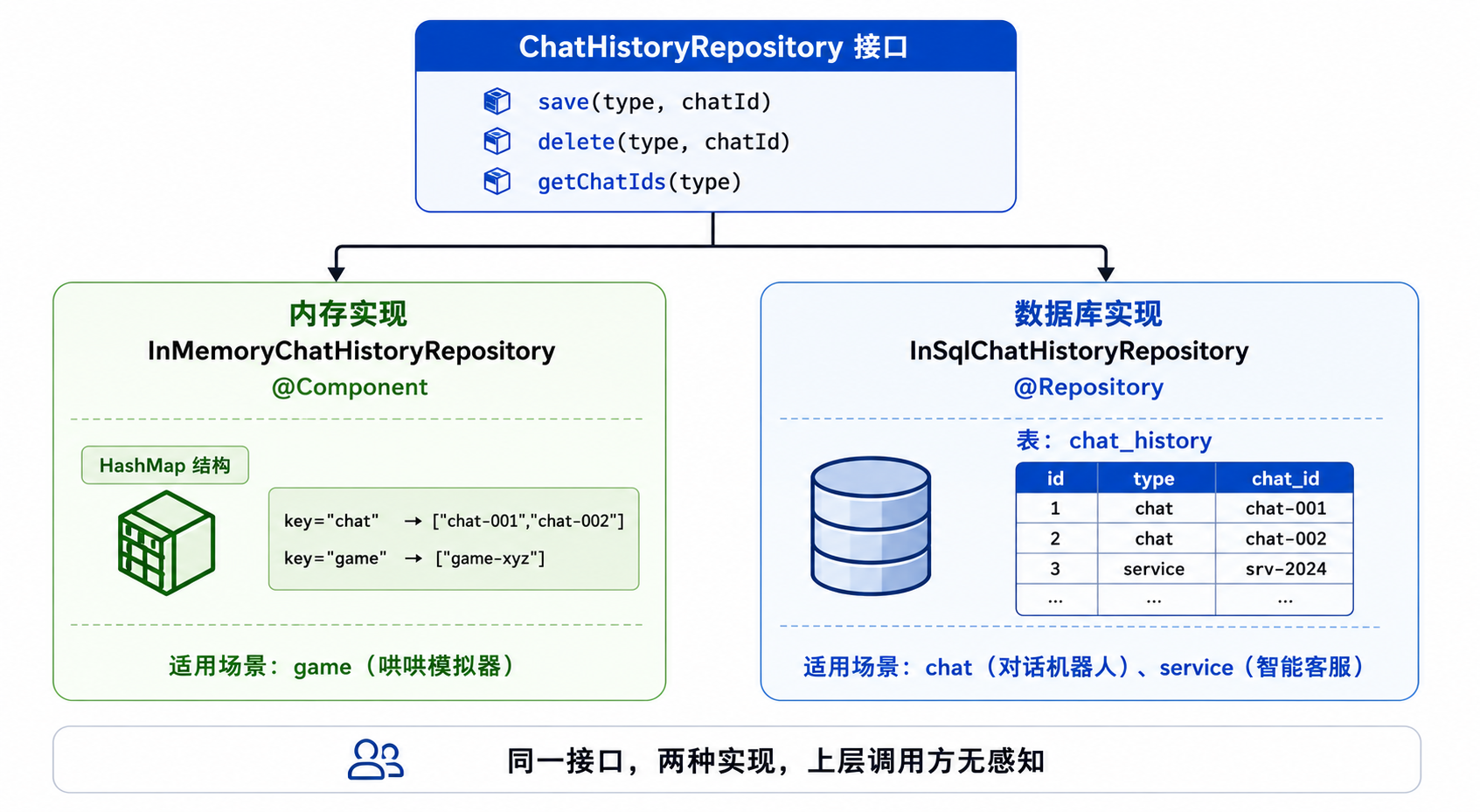
图③:同一接口,两种实现 — 内存(HashMap)vs 数据库(MySQL)
4.3 内存实现:一行 HashMap 搞定
@Component
public class InMemoryChatHistoryRepository implements ChatHistoryRepository {
// 核心数据结构
// key="chat" → ["chat-001", "chat-002", ...]
// key="game" → ["game-xyz", ...]
private final Map<String, List<String>> chatHistory = new HashMap<>();
@Override
public void save(String type, String chatId) {
// computeIfAbsent: 懒初始化,避免手动判空
List<String> chatIds = chatHistory.computeIfAbsent(type, k -> new ArrayList<>());
if (chatIds.contains(chatId)) return; // 防重复
chatIds.add(chatId);
}
@Override
public List<String> getChatIds(String type) {
// getOrDefault: 查不到返回空列表,避免 NPE
return chatHistory.getOrDefault(type, List.of());
}
@Override
public void delete(String type, String chatId) {
List<String> chatIds = chatHistory.get(type);
if (chatIds != null) {
chatIds.remove(chatId);
if (chatIds.isEmpty()) chatHistory.remove(type); // 顺手清理
}
}
}几个小细节值得注意:
computeIfAbsent—— 一行搞定"如果不存在就初始化",比if + put优雅得多contains去重 —— 用户可能在同一个会话发多条消息,但会话 ID 只需登记一次- 删完后检查是否为空 —— 空列表自动回收,不占内存
4.4 数据库实现:多一步查重
@Repository("inSqlChatHistoryRepository")
public class InSqlChatHistoryReponsitory implements ChatHistoryRepository {
@Override
public void save(String type, String chatId) {
if (exists(type, chatId)) return; // 先查有没有,有就跳过
ChatHistory entity = new ChatHistory();
entity.setType(type);
entity.setChatId(chatId);
chatHistoryMapper.insert(entity);
}
private boolean exists(String type, String chatId) {
List<String> chatIds = chatHistoryMapper.selectChatIdsByType(type);
return chatIds.contains(chatId);
}
// ... delete 和 getChatIds 类似,走 SQL
}同样的防重复逻辑,内存用 contains(),数据库走 SELECT。 思想一样,手段不同。
4.5 数据库表设计
chat_history 表(会话目录):
只关心"有哪些会话",不关心"聊了什么"
| id | type | chat_id | 说明 |
|---|---|---|---|
| 1 | chat |
chat-001 | AI 对话机器人 |
| 2 | chat |
chat-002 | AI 对话机器人 |
| 3 | service |
srv-2024 | 智能客服选课 |
| 4 | game |
game-xyz | 哄哄模拟器 |
chat_message 表(会话内容):
每一轮对话存两条(用户说 + AI答),ORDER BY id ASC 还原对话顺序
| id | conversation_id | role | content |
|---|---|---|---|
| 1 | chat-001 | user | 你好 |
| 2 | chat-001 | assistant | 你好!有什么可以帮你的吗? |
| 3 | chat-001 | user | 我叫张三 |
| 4 | chat-001 | assistant | 好的张三,我记住了! |
图④:chat_history(会话目录)与 chat_message(会话内容)一对多关系
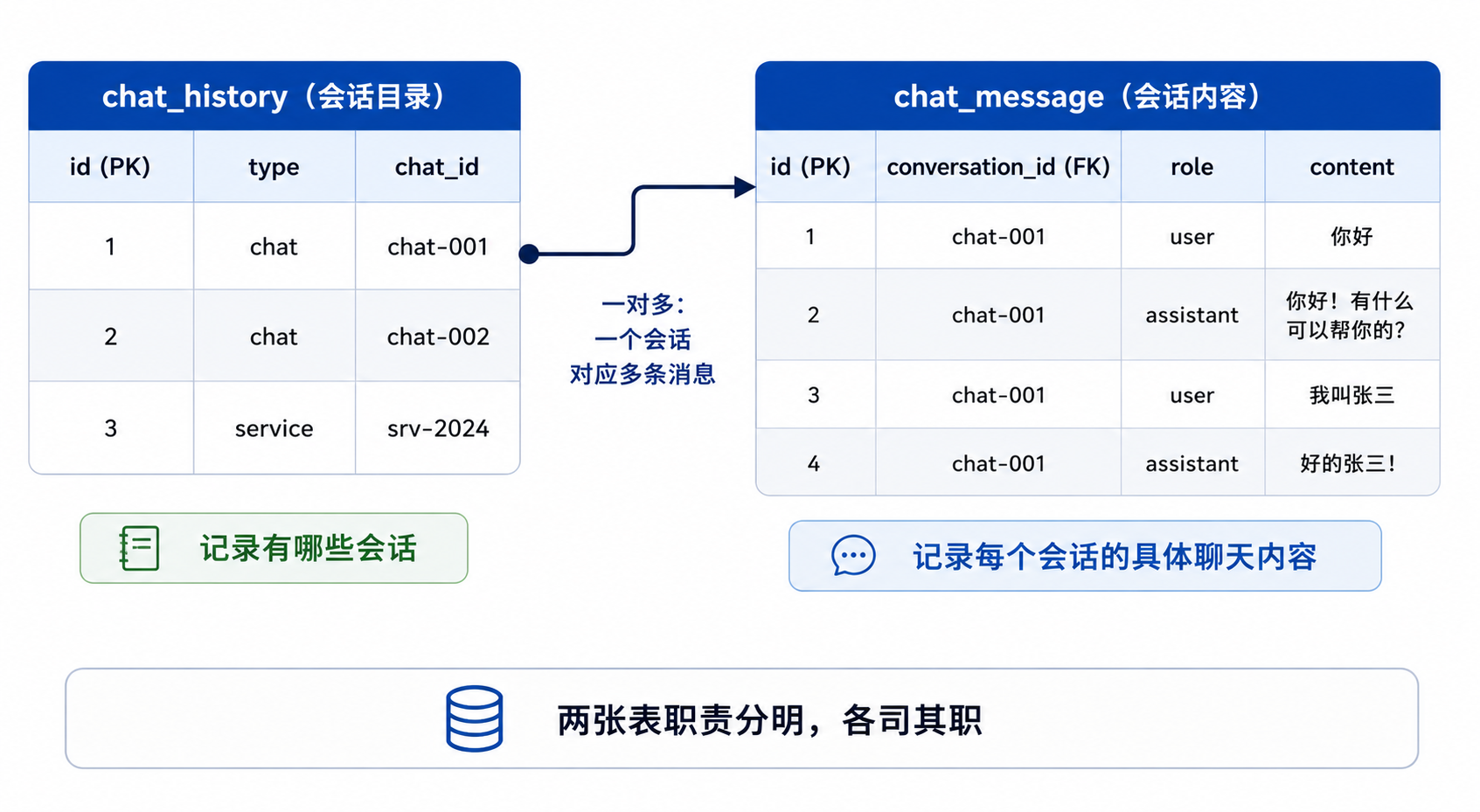
🔑 小鱼点睛
两张表职责泾渭分明。面试官可能会问"为什么不合并成一张表"?答案:关注点分离。 合在一起当然也能用,但"查有哪些会话"和"查某会话的聊天内容"是两个完全不同的业务需求,分开设计更清晰,索引优化也更精准。
五、ChatHistoryController:整个系统的"调度中心"
这个 Controller 是我认为整个设计最值得讲的部分。也是面试中能拉开差距的地方。
5.1 四个依赖,两两一组
@RestController
@RequestMapping("/ai/history")
public class ChatHistoryController {
private final ChatMemory chatMemory; // 内存-内容
private final InSqlChatMemory inSqlChatMemory; // 数据库-内容
private final ChatHistoryRepository inMemoryChatHistoryRepo; // 内存-目录
private final ChatHistoryRepository inSqlChatHistoryRepo; // 数据库-目录
// 构造函数注入 + @Qualifier 精确绑定
public ChatHistoryController(
ChatMemory chatMemory,
InSqlChatMemory inSqlChatMemory,
@Qualifier("inMemoryChatHistoryRepository")
ChatHistoryRepository inMemoryChatHistoryRepo,
@Qualifier("inSqlChatHistoryRepository")
ChatHistoryRepository inSqlChatHistoryRepo) {
this.chatMemory = chatMemory;
this.inSqlChatMemory = inSqlChatMemory;
this.inMemoryChatHistoryRepo = inMemoryChatHistoryRepo;
this.inSqlChatHistoryRepo = inSqlChatHistoryRepo;
}
}为什么 Controller 要同时持有四个依赖,而不是让前端自己选?
因为前端不需要知道"这个会话存在内存还是数据库"——它只关心数据有没有。把路由逻辑放在后端,前端的调用方式完全统一。
5.2 一行代码的路由魔法
private boolean isDatabaseType(String type) {
return Arrays.asList("chat", "service").contains(type.toLowerCase());
}效果:
GET /ai/history/chat/chat-001 → 走 MySQL GET /ai/history/service/srv-001 → 走 MySQL GET /ai/history/game/game-xyz → 走 JVM 内存
对前端来说,URL 格式一模一样,完全感知不到背后走的是内存还是数据库。
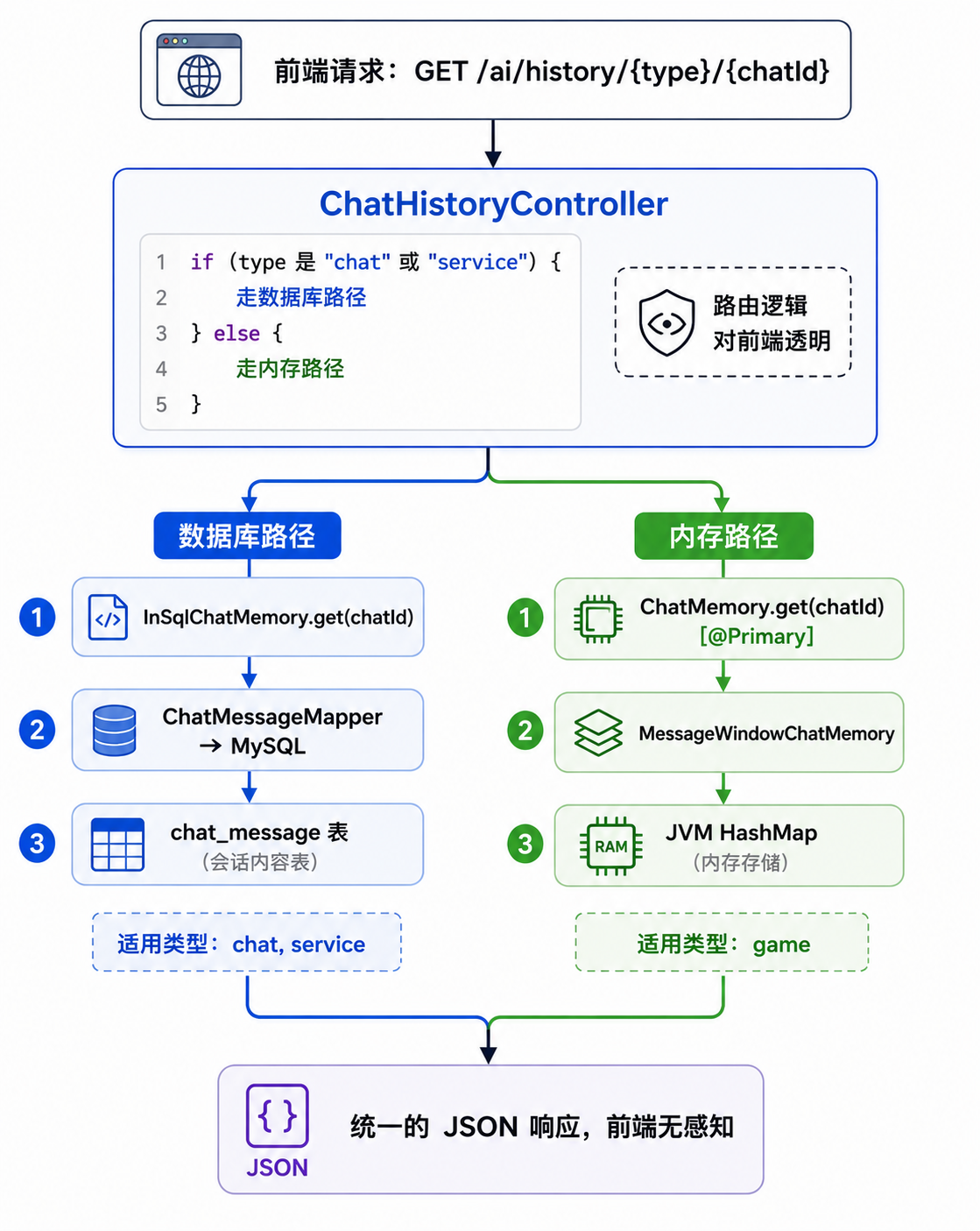
图⑤:ChatHistoryController 根据 type 自动分流,对前端完全透明
5.3 三个 API 的完整实现
API 1:获取会话列表 ——"聊天列表页"
@GetMapping("/{type}")
public List<String> getChatIds(@PathVariable("type") String type) {
if (isDatabaseType(type)) {
return inSqlChatHistoryRepo.getChatIds(type);
} else {
return inMemoryChatHistoryRepo.getChatIds(type);
}
}返回示例: ["chat-001", "chat-002", "chat-003"]
前端拿着这个列表渲染侧边栏:
📋 聊天记录 ├── 🗨 Java学习问题 ├── 💬 SpringAI 配置咨询 └── 🎓 毕业设计思路讨论
API 2:获取会话内容 ——"历史回显"
@GetMapping("/{type}/{chatId}")
public List<MessageVO> getChatHistory(
@PathVariable("type") String type,
@PathVariable("chatId") String chatId) {
List<Message> messages;
if (isDatabaseType(type)) {
messages = inSqlChatMemory.get(chatId);
} else {
messages = chatMemory.get(chatId);
}
if (messages == null) return List.of();
// 关键:将 Spring AI 的 Message 对象转为前端友好的 VO
return messages.stream()
.map(MessageVO::new)
.toList();
}为什么需要 MessageVO?
Spring AI 的 Message 接口使用 MessageType 枚举表示角色,不方便 JSON 序列化。MessageVO 做了一层转换:
public class MessageVO {
private String role; // "user" | "assistant"
private String content; // 消息正文
public MessageVO(Message message) {
this.role = switch (message.getMessageType()) {
case USER -> "user";
case ASSISTANT -> "assistant";
default -> "unknown";
};
this.content = message.getText();
}
}返回示例:
[
{ "role": "user", "content": "你好" },
{ "role": "assistant", "content": "你好!有什么可以帮你的吗?" },
{ "role": "user", "content": "我叫张三" },
{ "role": "assistant", "content": "好的张三,我记住了!" }
]API 3:删除会话 ——"既要删内容,也要删目录"
@DeleteMapping("/{type}/{chatId}")
public void deleteChatHistory(
@PathVariable("type") String type,
@PathVariable("chatId") String chatId) {
if (isDatabaseType(type)) {
// ⚠️ 注意删除顺序:先内容,后目录
inSqlChatMemory.clear(chatId);
// SQL: DELETE FROM chat_message WHERE conversation_id = ?
inSqlChatHistoryRepo.delete(type, chatId);
// SQL: DELETE FROM chat_history WHERE type=? AND chat_id=?
} else {
chatMemory.clear(chatId);
inMemoryChatHistoryRepo.delete(type, chatId);
}
}🔑 小鱼点睛:为什么删除顺序是"先内容,后目录"?
这是一个经典的数据一致性问题。假设反过来:
❌ 错误顺序:先删目录,再删内容 → 删目录成功 ✓ → 删内容失败 ✗(数据库挂了?网络断了?) → 结果:目录里找不到这个会话,但 chat_message 表里还留着一堆消息 → 成了"幽灵数据",永远清理不掉
✅ 正确顺序:先删内容,再删目录 → 删内容成功 ✓ → 删目录失败 ✗ → 结果:目录里还有这个会话,但点进去是空的 → 用户最多疑惑一下,不会产生垃圾数据
面试官如果问到"分布式系统中的数据一致性",你直接拿这个例子讲,比背 CAP 理论有说服力得多。
六、ChatType 枚举:一个容易被忽视的设计细节
public enum ChatType {
CHAT("chat"), // AI 对话机器人
SERVICE("service"), // 智能客服选课系统
GAME("game"); // 哄哄模拟器
private final String value;
// getValue()...
}为什么不用字符串直接写 "chat"? 三个原因:
- 写不错 —— IDE 有自动补全,不会出现
"caht"这种拼写错误 - 改不乱 —— 要加一个
"pdf"问答类型?枚举里加一行就行,所有引用处自动生效 - 看得懂 ——
ChatType.CHAT.getValue()比魔法字符串"chat"更有语义
🔑 小鱼点睛
面试官问你"枚举和常量有什么区别",你可以说"枚举不是用来替代常量,而是用来把一组相关联的常量组织成一个类型,让编译器帮你检查"。
七、MessageChatMemoryAdvisor:最被低估的一行配置
很多同学在项目里配了这行代码,但不知道它到底干了什么:
@Bean
public ChatClient chatClient(OllamaChatModel model,
@Qualifier("inSqlChatMemory") ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultSystem("你是一个智能助手,用简短友好的语气回答问题。")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build() // ← 这一行
)
.build();
}这行配置是整个记忆系统的"自动化引擎"。
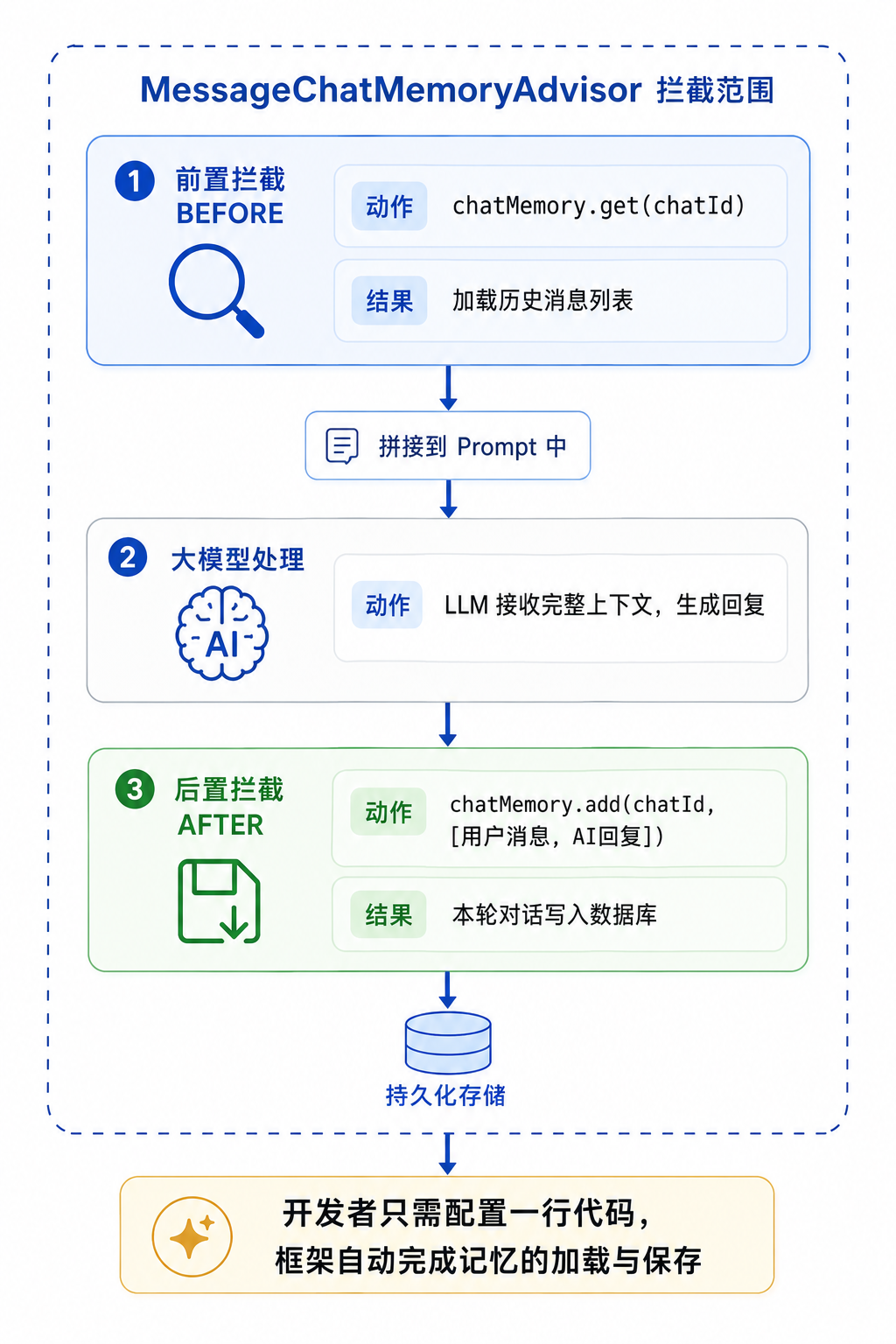
图⑥:Advisor 前置拦截(get 加载历史)→ 大模型处理 → 后置拦截(add 保存消息)
它拦截了每次对话的两个关键时刻(如上图所示):
🔹 前置拦截(BEFORE)—— 自动调用 chatMemory.get(chatId),把该会话的所有历史消息加载出来,拼接到 Prompt 中一起发给大模型,这样 AI 就有了"上下文"。
🔹 后置拦截(AFTER)—— 大模型返回响应后,自动调用 chatMemory.add(chatId, [用户消息, AI回复]),把本轮对话存进数据库,为下一次对话做准备。
你什么都不用做,框架帮你把"记"和"忆"全自动处理了。
这就是为什么面试官问"AI 怎么记住上下文的",你不能只说"ChatMemory"。你要讲清楚这个 Advisor 的拦截机制——它才是让 ChatMemory 和 ChatClient 产生关联的桥梁。
而且还有一个关键参数:
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))这一行把 chatId 传给了 Advisor,Advisor 再传给 ChatMemory。 这样同一个 ChatMemory 实例可以同时服务多个会话,互不干扰。
八、CommonConfiguration:Bean 装配的艺术
整个系统的 Bean 依赖关系,是在 CommonConfiguration 中统一编排的。这里有一个很巧妙的 @Primary 设计:
@Configuration
public class CommonConfiguration {
// 内存 ChatMemory —— @Primary 标注,默认使用
@Bean
@Primary
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder().build();
}
// 数据库 ChatMemory —— 需要显式指定才使用
@Bean
public InSqlChatMemory inSqlChatMemory() {
return new InSqlChatMemory();
}
// 对话机器人 —— 显式注入 InSqlChatMemory(数据库)
@Bean
public ChatClient chatClient(OllamaChatModel model,
@Qualifier("inSqlChatMemory") ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build()
).build();
}
// 哄哄模拟器 —— 不指定,自动注入 @Primary(内存)
@Bean
public ChatClient gamechatClient(OpenAiChatModel model, ChatMemory chatMemory) {
// chatMemory 自动拿到 MessageWindowChatMemory
return ChatClient.builder(model)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build()
).build();
}
}@Primary 的妙用: 不需要持久化的 Bean(如 gamechatClient),不写 @Qualifier,自动拿到内存实现;需要持久化的 Bean(如 chatClient),显式写 @Qualifier("inSqlChatMemory"),拿到数据库实现。
🔑 小鱼点睛
Spring 的 @Primary + @Qualifier 组合,是优雅处理"多数情况用A,少数情况用B"的经典手段。面试被问到依赖注入的高级用法,直接抛这个例子。
九、一次完整的对话:从生到死的 6 个瞬间
现在把所有组件串起来。这是全文最值钱的一章,建议收藏后反复看。
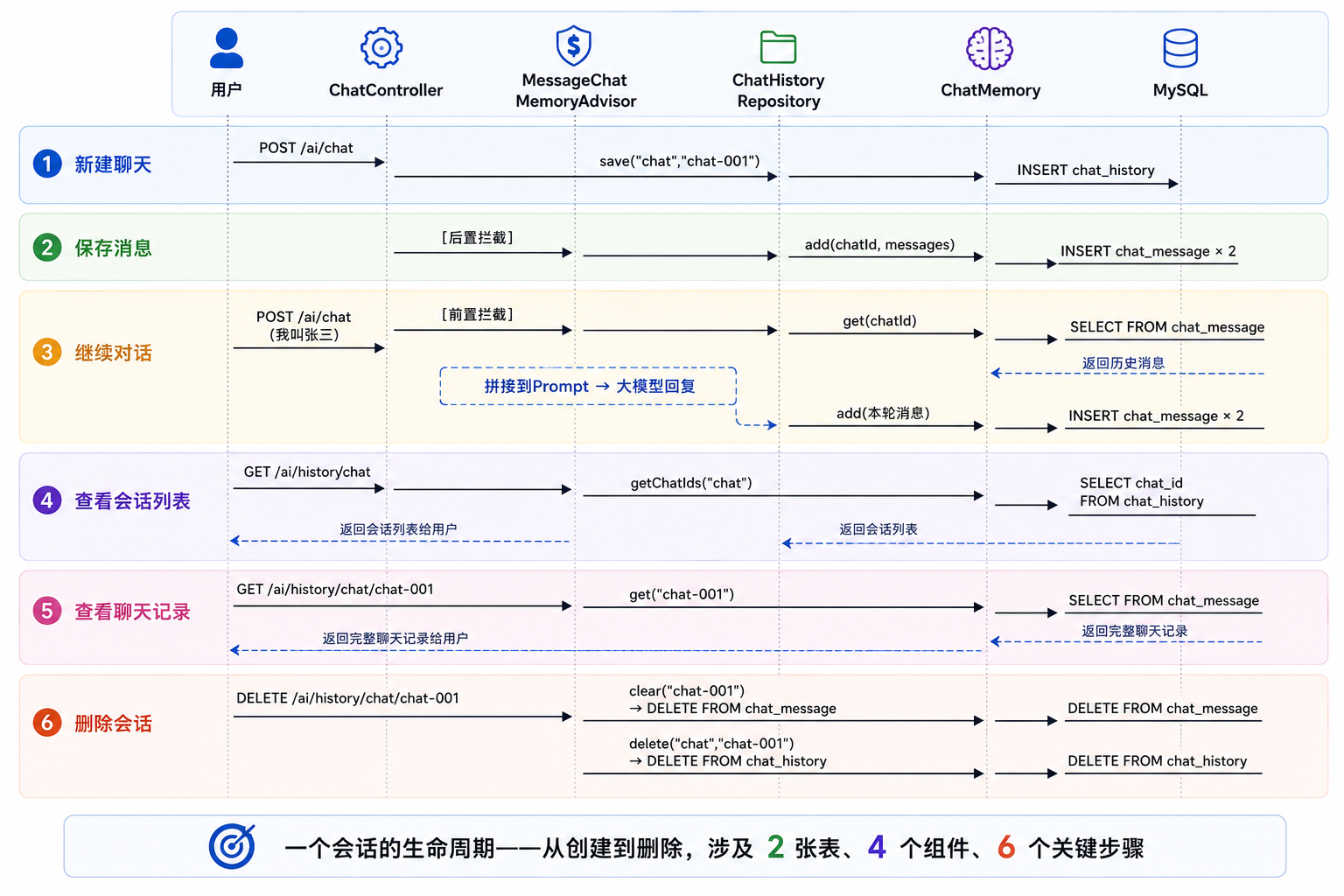
图⑦:一个会话的生命周期 — 从创建到删除,6 步关键流程
ChatMemory 与 ChatHistoryRepository 执行流程
很多同学容易把 ChatMemory 和 ChatHistoryRepository 搞混。
实际上:
ChatMemory
负责保存聊天内容(Message)
ChatHistoryRepository
负责保存会话ID(chatId)
两者共同实现了:
历史会话列表
+
上下文记忆能力
第1步:创建会话
用户发送:
你好
进入:
ChatController.chat()
首先保存会话ID:
chatHistoryRepository.save(
"chat",
"chat-001"
);
执行:
INSERT INTO chat_history
(type,chat_id)
VALUES
('chat','chat-001');
此时数据库记录:
chat-001
表示:
产生了一个新的会话
第2步:调用大模型
chatClient.prompt()
.user("你好")
.advisors(a ->
a.param(
ChatMemory.CONVERSATION_ID,
"chat-001"
)
)
.stream()
.content();
大模型返回:
你好!有什么可以帮你的吗?
第3步:自动保存聊天内容
此时并不是 Controller 保存消息。
而是:
MessageChatMemoryAdvisor
自动调用:
chatMemory.add(...)
保存:
用户:你好
AI:你好!有什么可以帮你的吗?
对应:
INSERT INTO chat_message(...)
INSERT INTO chat_message(...)
数据库中:
chat-001
用户:你好
AI:你好!有什么可以帮你的吗?
第4步:继续聊天
用户输入:
我叫张三
发送给大模型前:
chatMemory.get("chat-001")
先读取历史记录:
用户:你好
AI:你好!有什么可以帮你的吗?
然后拼接:
历史记录:
用户:你好
AI:你好!有什么可以帮你的吗?
当前消息:
用户:我叫张三
一起发送给大模型。
因此 AI 才能理解上下文:
好的张三,我记住了。
这就是:
ChatMemory 的记忆能力
第5步:查看历史会话列表
前端请求:
GET /ai/history/chat
进入:
chatHistoryRepository.getChatIds()
查询:
SELECT chat_id
FROM chat_history
返回:
[
"chat-001",
"chat-002",
"chat-003"
]
用于展示侧边栏:
chat-001
chat-002
chat-003
第6步:查看聊天记录
前端请求:
GET /ai/history/chat/chat-001
进入:
chatMemory.get("chat-001")
查询:
SELECT *
FROM chat_message
WHERE conversation_id='chat-001'
返回:
用户:你好
AI:你好!有什么可以帮你的吗?
用户:我叫张三
AI:好的张三,我记住了。
前端渲染聊天页面。
第7步:删除会话
前端请求:
DELETE /ai/history/chat/chat-001
首先删除聊天内容:
chatMemory.clear("chat-001")
执行:
DELETE FROM chat_message
WHERE conversation_id='chat-001'
然后删除会话ID:
chatHistoryRepository.delete(
"chat",
"chat-001"
)
执行:
DELETE FROM chat_history
WHERE chat_id='chat-001'
至此整个会话被彻底删除。
整体时序图
用户
│
▼
ChatController
│
├── save(chatId)
│ │
│ ▼
│ ChatHistoryRepository
│
▼
ChatClient
│
▼
ChatMemory.get()
│
▼
获取历史消息
│
▼
发送给大模型
│
▼
AI回复
│
▼
ChatMemory.add()
│
▼
保存聊天内容
总结
ChatHistoryRepository
负责管理会话(chatId)
ChatMemory
负责管理聊天内容(Message)
Repository决定:
有哪些会话
Memory决定:
每个会话聊过什么
两者配合实现:
历史记录 + 上下文记忆
十、架构全景图
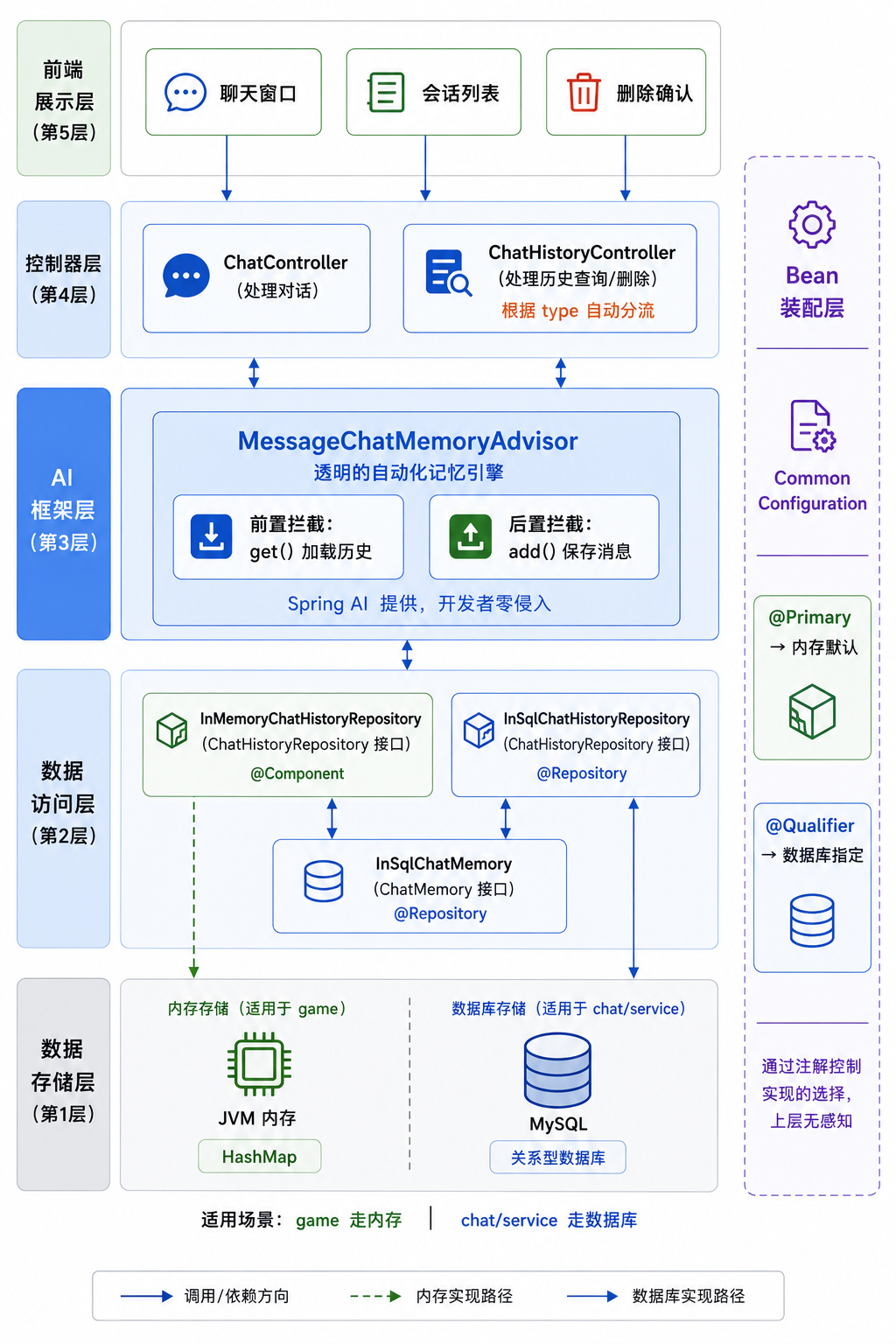
图⑧:5 层架构全景 — 前端 → Controller → Advisor → 接口 → 存储(内存/MySQL)
(架构全景图见上方图⑧)
十一、三个最值得讲给面试官听的设计决策
决策 1:策略模式 —— 一套接口,两种实现
同一个 ChatMemory 接口,有内存版和数据库版。同一个 ChatHistoryRepository 接口也是。
为什么这样设计? 因为不同的业务场景对"持久化"的需求不同。游戏不需要存,聊天必须存。用接口抽象,上层代码不用关心底层实现。
面试话术: "我们把存储策略抽象成接口,内存和数据库分别实现。切换存储方式时,业务代码一行不用改。未来如果要加 Redis 版,只需要新增一个实现类,符合开闭原则。"
决策 2:MessageChatMemoryAdvisor —— 透明拦截,关注点分离
记忆的读写和业务逻辑完全解耦。
面试话术: "我们使用 Spring AI 的 Advisor 机制,在对话流程的前后两个节点做拦截——前置加载历史上下文,后置保存本轮消息。Controller 不需要感知记忆的读写时机,ChatMemory 也不需要知道什么时候被调用。这是典型的 AOP 思想在 AI 框架中的落地。"
决策 3:业务类型分流 —— 一个接口,多种场景
同一个 ChatHistoryController,根据 URL 中的 type 参数自动路由到不同存储。
面试话术: "我们在 URL 设计中加入了 type 参数,结合枚举类做类型安全的路由。同一个接口服务三种业务场景,新增场景只需加枚举值,符合开闭原则。"
🔑 小鱼点睛
面试官问"你在这个项目里做了什么有亮点的设计",就拿这三个讲。每个都能展开 5 分钟以上。
十二、面试高频追问速答
这里整理了面试中最容易被追问的几个问题,建议收藏:
Q1:ChatMemory 的 get() 什么时候被调用?
两个时机。一是用户主动查看历史记录时(ChatHistoryController 调用),二是每次新对话前(MessageChatMemoryAdvisor 自动调用,用于加载上下文)。
Q2:为什么要分 ChatMemory 和 ChatHistoryRepository?
关注点分离。前者管"会话内容",后者管"会话目录"。如果合并,也能用,但查询"有哪些会话"和"某会话的聊天记录"是两个不同需求,分开设计更清晰。
Q3:内存存储和数据库存储怎么切换?
通过 Spring 的 @Primary + @Qualifier 机制。默认注入内存实现,需要数据库的场景显式指定即可。新增一种存储方式只需新增一个实现类。
Q4:删除会话时为什么先删内容再删目录?
防止"幽灵数据"。如果先删目录但删内容失败,消息就永远留在数据库里。反过来,先删内容即使第二步失败,最多是目录里有个空会话。
Q5:为什么不把所有聊天记录都存数据库?
"合适原则"。游戏场景不需要持久化,存数据库反而增加 I/O 开销。不是所有数据都值得进数据库。
Q6:type 参数用字符串不怕写错吗?
后端用 ChatType 枚举做类型安全校验,前端传的字符串会经过
isDatabaseType()匹配。未来可以升级为枚举的 name() 做精确匹配。
十三、总结
这套系统,剥开所有细节,核心逻辑就一句话:
ChatHistoryRepository 管"有哪些会话"(目录),ChatMemory 管"每个会话聊了什么"(内容)。
但面试官要听的,不是这一句话。而是你能讲清楚:
- 内存和数据库为什么要共用一套接口?(策略模式)
- ChatMemory 的
get()为什么有两个调用时机?(上下文记忆原理) - 删除操作为什么"先内容后目录"?(数据一致性)
- 为什么需要
type字段?(业务隔离 + 灵活路由) - MessageChatMemoryAdvisor 干了什么?(透明拦截 + AOP)
@Primary+@Qualifier解决了什么问题?(依赖注入策略)
面试的本质不是"你用了什么",而是"你为什么这么用"。
希望这篇文章能帮你在面试中,把这个项目的设计决策一层一层讲清楚。
如果觉得有帮助,欢迎点赞、在看、转发,这是对小魚持续输出原创技术文章最大的支持!
有问题欢迎评论区留言,小魚每条都会认真回复。🐟
本文代码基于 heima-springai 项目真实源码编写,项目地址见仓库。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)