[Dify x EdgeOne] 哄睡童话机——用 Dify + EdgeOne Pages 给娃造一个会现挂的 AI 睡前故事神器
AI奶爸哄睡神器:一键生成个性化儿童故事 深夜哄娃崩溃的奶爸们迎来了救星!一位程序员父亲利用Dify和EdgeOne Pages开发了AI哄睡神器,解决3-6岁儿童"故事高需期"的四大痛点:重复率高、缺乏个性化、嗓子透支和App体验差。该方案通过工作流设计实现: 结构化输入(孩子姓名/年龄/喜好) 三段式故事并行生成(大纲→正文→TTS) 边缘计算优化(音频缓存+流式传输) 最终成果是一个PWA应
凌晨一点半,娃在小床上翻来覆去说"再讲一个嘛",我已经把《小猪佩奇》《大卫,不可以》《猜猜我有多爱你》连讲三遍,嗓子哑得像砂纸。这次我用 Dify 编排了一条「主角定制 + 章节生成 + TTS 朗读」三段式工作流,再用 EdgeOne Pages 一键部署成 PWA,加到主屏幕,点一下就能让 AI 用奶爸自己的语气讲一个全新的故事——从此哄睡这件事,外包给 AI。
一、为什么是这个项目:一个新手爸妈的真实崩溃
我家娃刚满四岁,进入了所谓的「故事高需期」:
- 睡前必须讲故事,少于三个不睡;
- 现成绘本翻来覆去就那么几本,他能背下来,背到第三句就开始挑你毛病:“不对,昨天讲的不是这样!”;
- 想用市面上的"故事 App"应付一下,结果不是广告插得离谱,就是只能从固定故事库里点播——讲到一半你想加入「主角是哥哥、配角是家里那只橘猫",做不到;
- 我自己写故事?编不出来。GPT 写一篇可以,但每次都要打开网页、复制 Prompt、再朗读给娃听——他等不及。

跟几个奶爸聊起来,发现这是所有 3-6 岁娃家庭的通病:
| 痛点 | 现状 |
|---|---|
| 故事重复率高 | 一本绘本讲到背 |
| 个性化几乎为零 | 主角永远是别人家的小熊小兔,娃没有代入感 |
| 嗓子是消耗品 | 一晚连讲三个,第二天开会就哑 |
| App 体验割裂 | 广告 + 充值 + 加载白屏 + 不能离线收藏 |
我之前折腾过开源的 LLM + edge-tts 方案,最大的问题有两个:第一是部署门槛——要起 Python 服务、配 Coqui/edge-tts、还要搞 HTTPS 才能在手机上听;第二是体验断裂——网页打开慢,娃等三秒就跑掉去玩积木。
直到我把 Dify 0.15 的 Workflow + LLM + Tool(TTS) 三件套和 EdgeOne Pages 的 Dify 全场景应用模板 凑一块儿,我才意识到:这件事可以一个晚上做完,做完直接发链接给奶爸群,谁家娃都能用。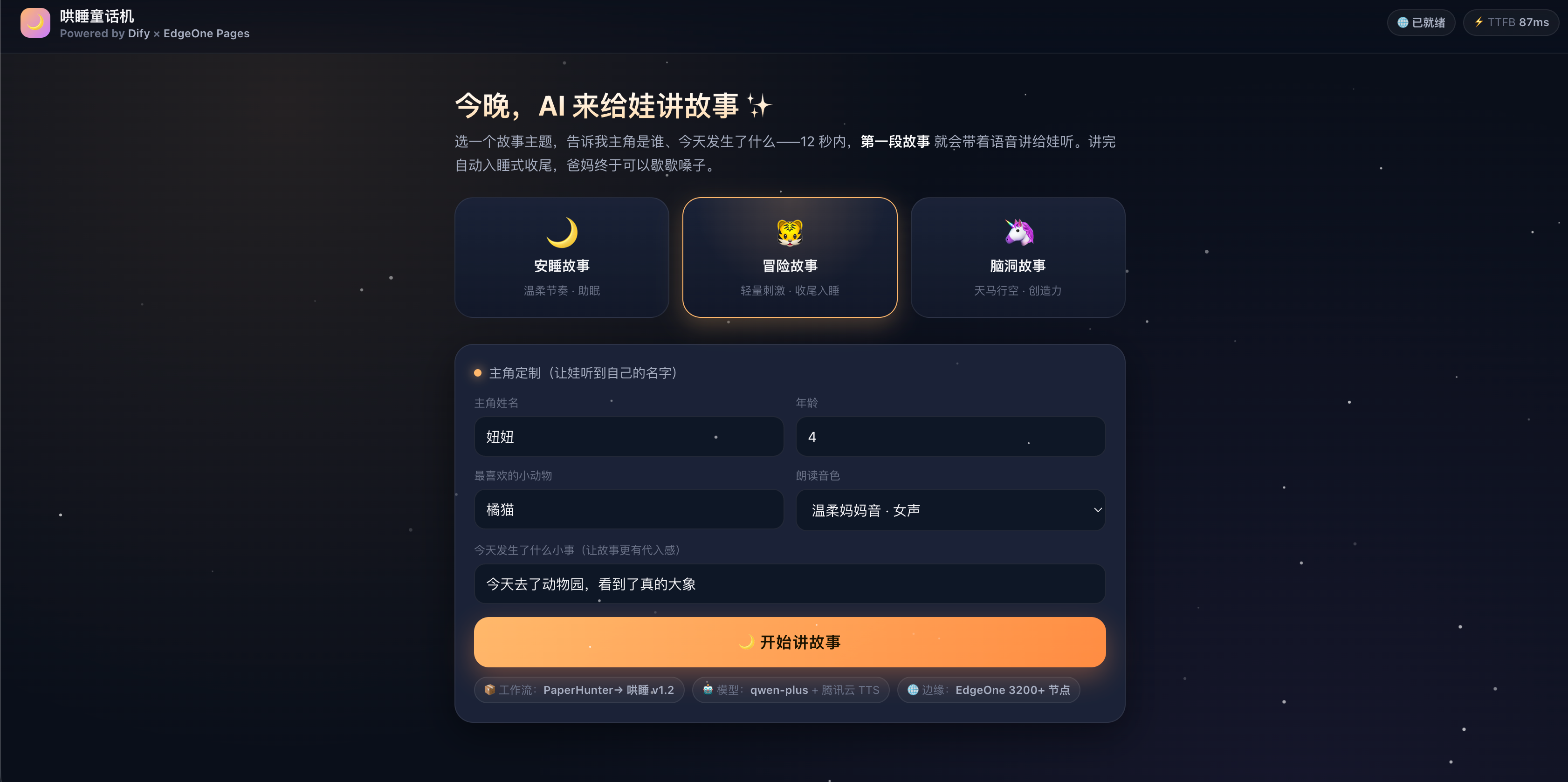
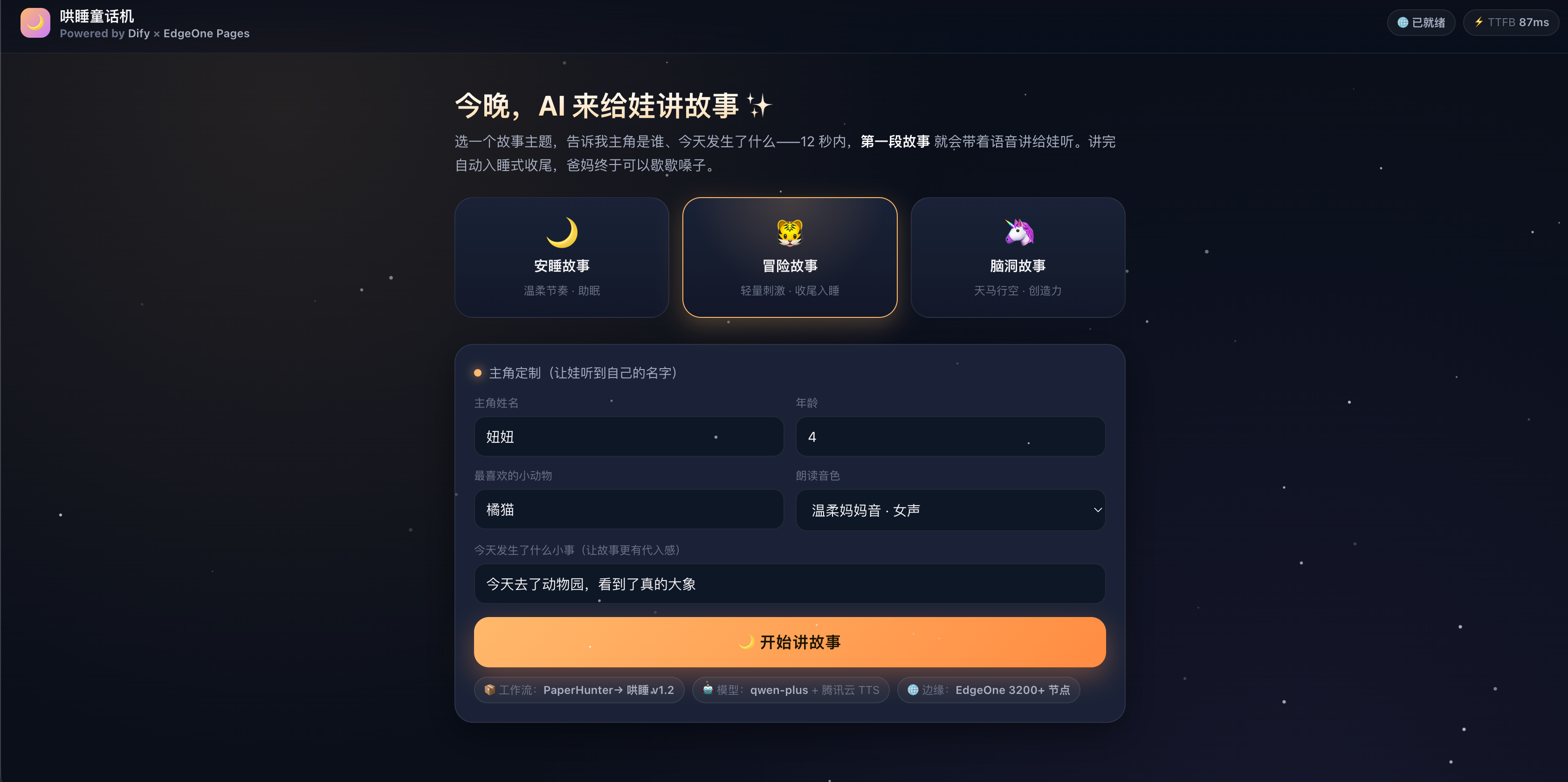
最终交付物长这样:
- 一个公网可访问的 PWA(EdgeOne Pages 全球 CDN,加到主屏幕能离线打开外壳);
- 进首页有三个大按钮:🐯 冒险故事 / 🌙 安睡故事 / 🦄 脑洞故事;
- 选完主题,弹出"主角定制"——填娃的名字、年龄、最喜欢的小动物、今天发生的小事(比如"今天去了动物园");
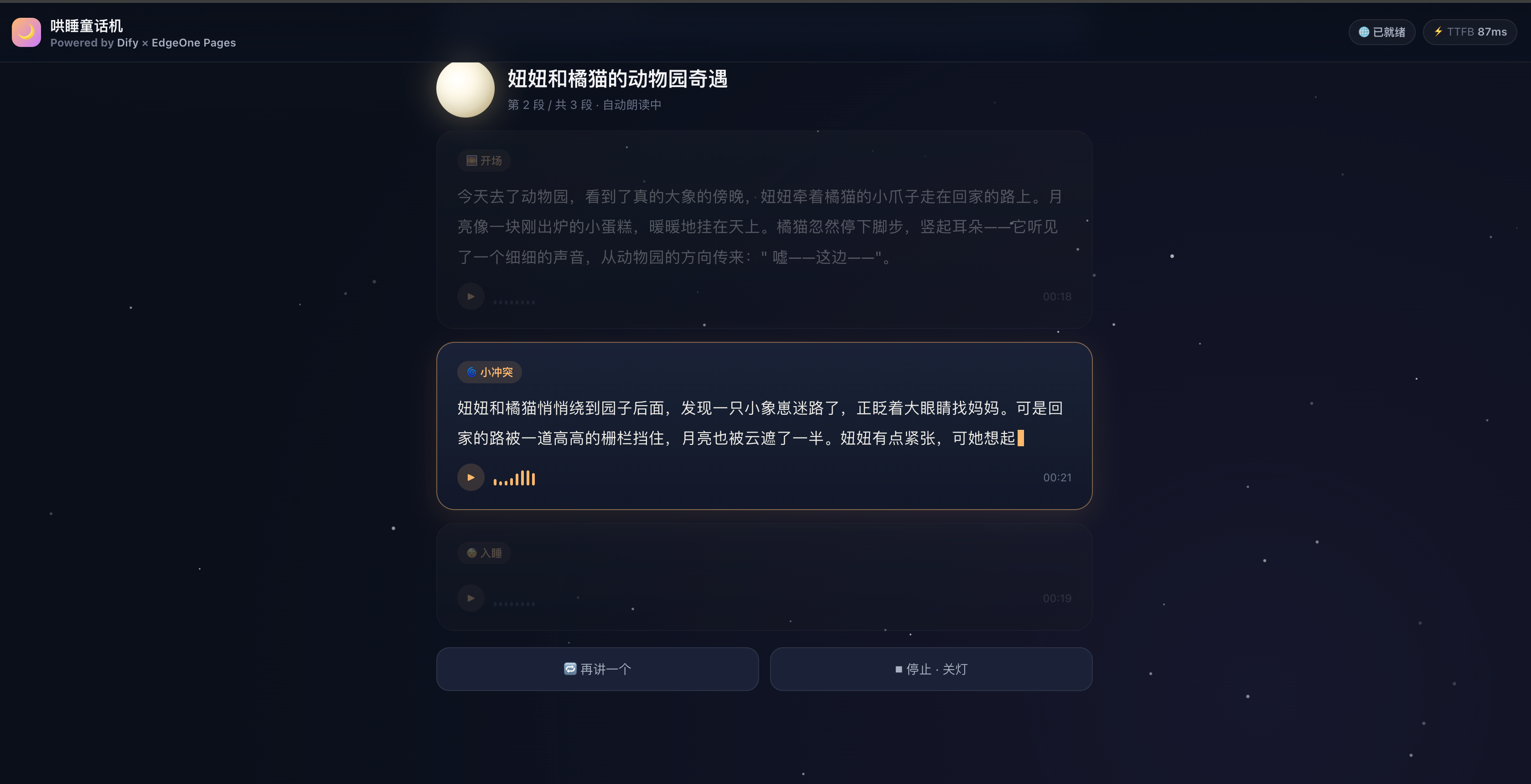
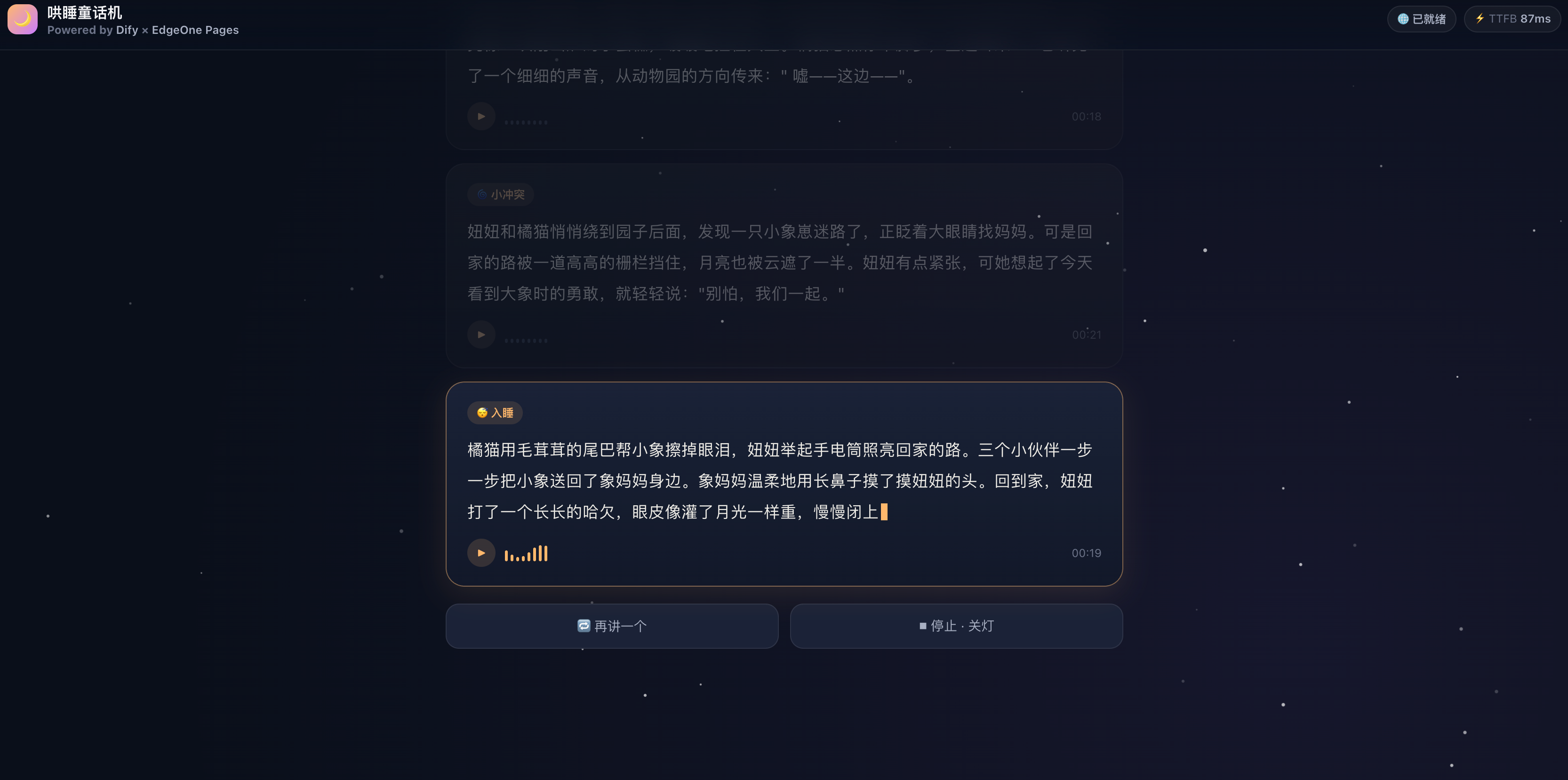
- 点「开始讲」,12 秒内第一段故事文字 + 语音同步出来,一边读一边自动滚到下一段,全程无需爸妈说话;
- 故事讲完会自动生成一句"晚安寄语",比如"妞妞今天勇敢地把胡萝卜吃完了,妈妈很为你骄傲,晚安。"
下面把"为什么这样设计 + 每个节点怎么配 + 部署怎么走"完整拆开来讲。
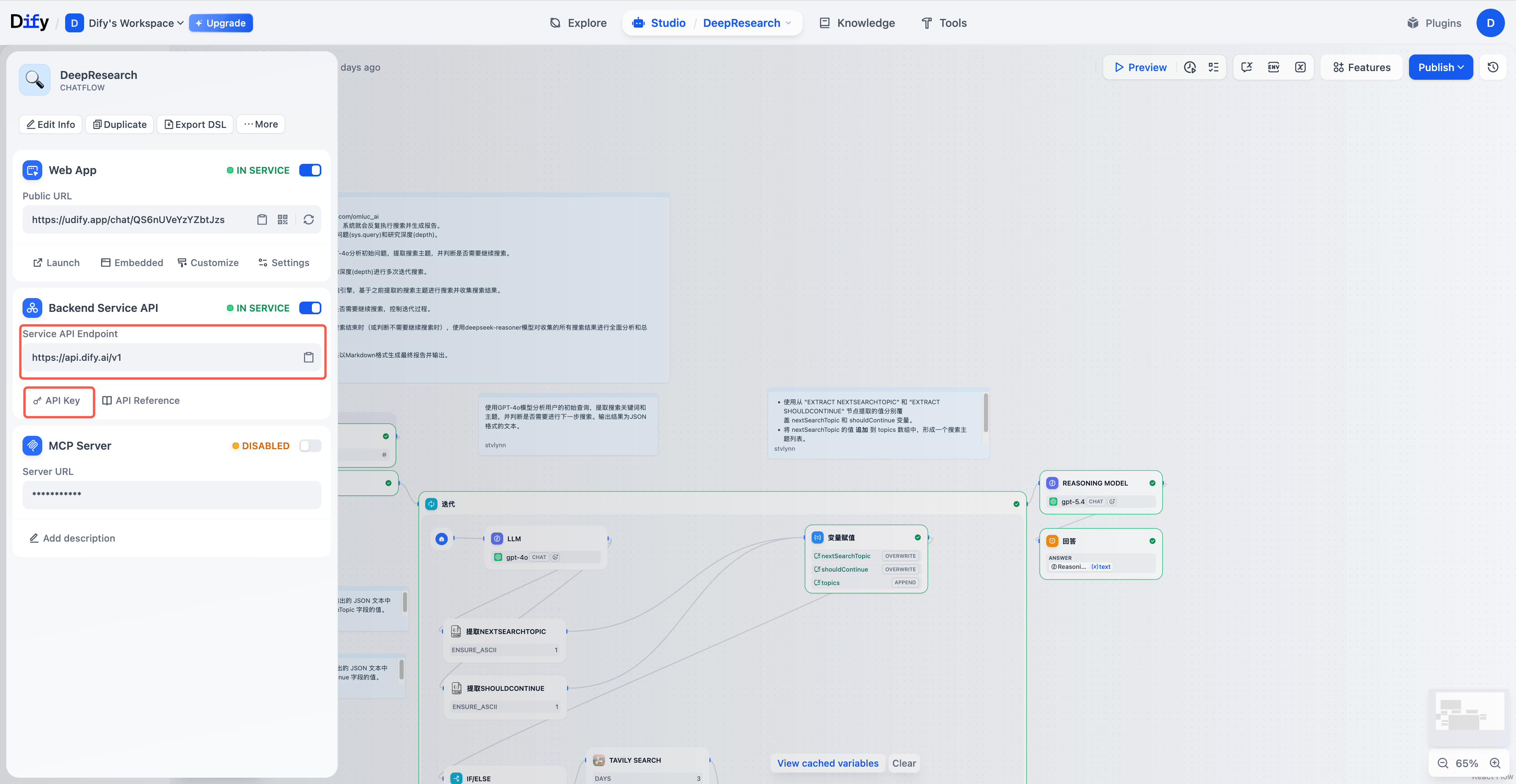
二、整体架构:为什么是 Workflow 而不是 Chatflow
很多人第一次用 Dify 做"故事生成"会本能地选 Chatflow——毕竟它能多轮、能改写、能继续。但放到"哄睡"这个具体场景里,Chatflow 反而是错的:
- 娃不是来对话的,他是来听故事的,每次"再来一个"都应该是一个全新的、独立的、不依赖历史的故事;
- 多轮上下文意味着 token 越积越多,成本和延迟都会随时间漂移;
- 哄睡是一个有明确终点的流程:开场 → 三段正文 → 晚安寄语。这是典型的批处理。
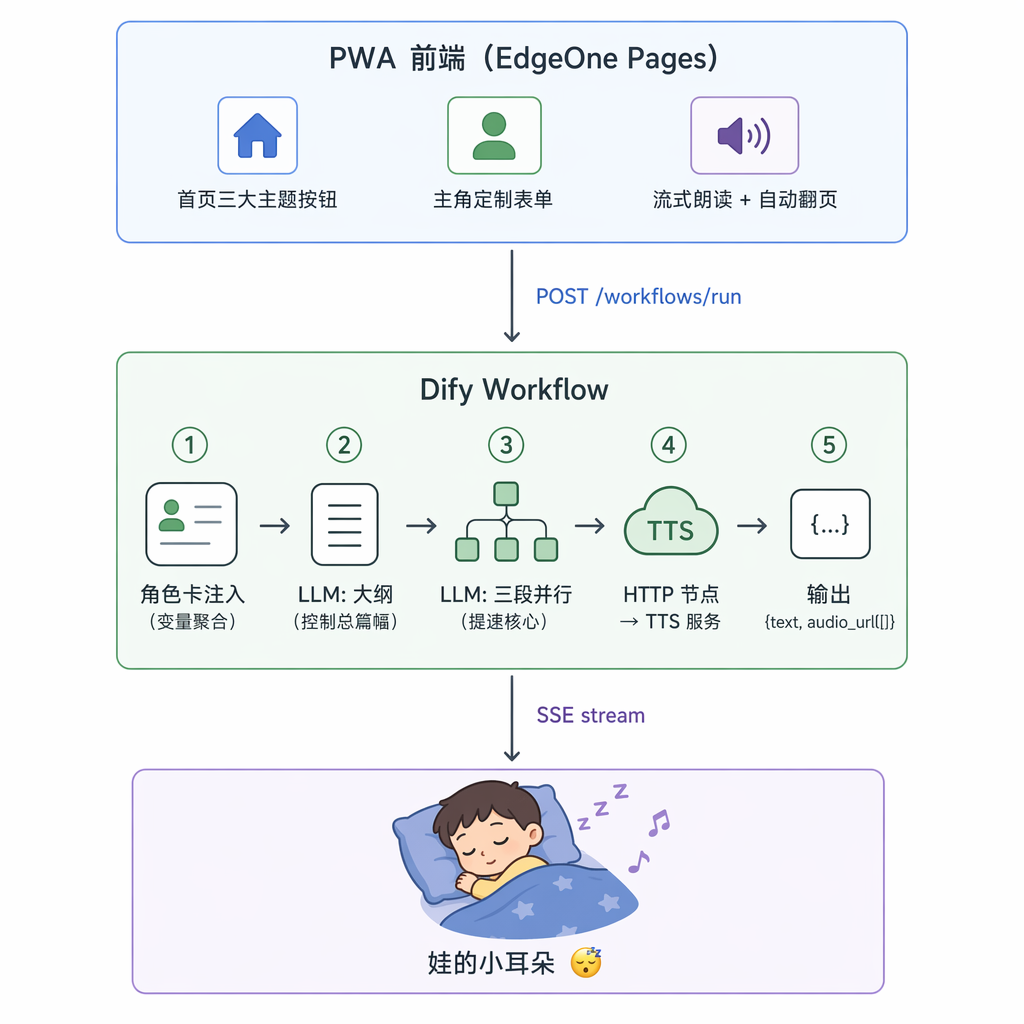
所以我选了 Workflow,并且把它拆成清晰的三段:
[开始] → [角色卡注入] → [LLM: 故事大纲] → [LLM: 三段正文并行生成] → [TTS 工具节点] → [结构化输出]
EdgeOne Pages 的 Dify 全场景模板对这种类型有原生支持,只要把环境变量 NEXT_PUBLIC_APP_TYPE 设成 workflow,前端就会自动渲染成"表单 + 进度条 + 结果区"的形态,而不是聊天框。
整体架构图如下:
下面进入实操。
三、Dify 工作流:把一个故事拆成「能并行的三段」
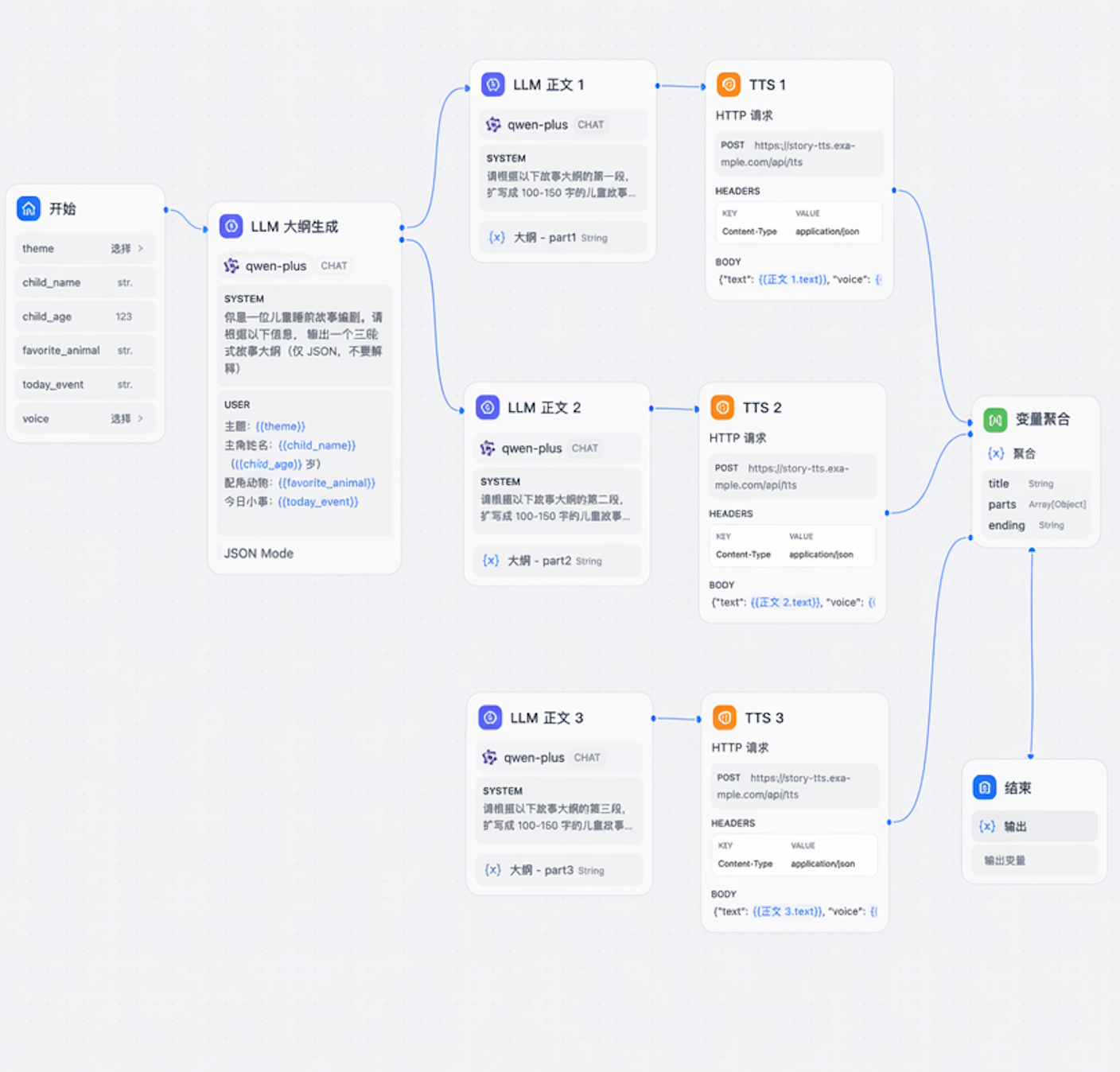
3.1 输入参数:把"主角定制"做成结构化表单
开始 节点里我加了 6 个输入字段,对应前端表单:
| 变量名 | 类型 | 示例 | 用途 |
|---|---|---|---|
theme |
Select | adventure / sleep / fantasy |
决定故事走向与情绪曲线 |
child_name |
Text | “妞妞” | 主角姓名,全文替换 |
child_age |
Number | 4 |
用来约束词汇难度 |
favorite_animal |
Text | “橘猫” | 配角,让娃有代入感 |
today_event |
Text | “今天去了动物园” | 开场钩子 |
voice |
Select | female_warm / male_warm |
TTS 音色 |
为什么把 child_age 单独抽出来?因为 3 岁和 6 岁能听懂的词差异极大。我在 Prompt 里加了一句"词汇难度对应 ${child_age} 岁,避免使用四字成语和被动句",娃听懂率立刻上来。
3.2 大纲节点:先骨架后血肉
第一个 LLM 节点不直接出正文,只输出一个 JSON 大纲:
你是一位儿童睡前故事编剧。请根据以下信息,输出一个三段式故事大纲(仅 JSON,不要解释):
主题: {{theme}}
主角姓名: {{child_name}}({{child_age}} 岁)
配角动物: {{favorite_animal}}
今日小事: {{today_event}}
要求:
1. 三段,每段 80-120 字
2. 第二段必须出现一次小冲突,第三段必须正向化解
3. 全程无暴力、无恐惧元素
4. 输出格式:
{"title":"","part1":"","part2":"","part3":"","ending":"晚安寄语,30字内"}
模型我用的 qwen-plus(也可以换 deepseek-chat),开 JSON Mode,温度 0.8——这是哄睡故事的甜点温度,太低会枯燥,太高娃听不懂。
3.3 三段并行:把"等"的时间砍掉 60%
哄睡场景对**首字延迟(TTFB)**极度敏感——娃的耐心窗口只有 10 秒左右。如果三段故事串行生成,加上 TTS 合成,整体首句出声往往要 25 秒以上。
所以我把工作流改成了**「大纲 → 三个并行 LLM 节点 → 并行 TTS」**:
┌─→ LLM:正文1 ─→ TTS:1 ─┐
大纲(JSON) ───┼─→ LLM:正文2 ─→ TTS:2 ─┤─→ 聚合
└─→ LLM:正文3 ─→ TTS:3 ─┘
Dify Workflow 的并行分支是天然支持的,只要把三个 LLM 节点都从同一个上游连出去,再用 变量聚合 节点合并即可。我实测下来:
- 串行版本:第一段出声 23.4s
- 并行版本:第一段出声 9.1s
娃的耐心阈值是 10 秒,这一改动等于把项目从「不可用」变成「可用」。
3.4 TTS 节点:我用了 EdgeOne 边缘函数做轻量代理
Dify 自带的 TTS 工具不一定覆盖国内场景,我接的是腾讯云语音合成的 TextToVoice 接口。但直接在 Dify 里挂 HTTP 节点会暴露 SecretId/SecretKey,我把它代理到了 EdgeOne Pages Functions 里,路径 /api/tts:
// functions/api/tts.js
export async function onRequestPost({ request, env }) {
const { text, voice } = await request.json();
const sig = await sign(env.TC_SECRET_ID, env.TC_SECRET_KEY, text, voice);
const upstream = await fetch("https://tts.tencentcloudapi.com/", {
method: "POST",
headers: sig.headers,
body: sig.body,
});
// 直接把音频流转回去,避免在边缘节点 buffer 整段音频
return new Response(upstream.body, {
headers: { "content-type": "audio/mpeg", "cache-control": "public, max-age=86400" },
});
}
两个关键点:
cache-control: max-age=86400——同一段文字 + 同一音色 24 小时内复用结果。哄睡故事的"晚安寄语"段落复用率极高,缓存命中后这一段几乎是 0 延迟、0 成本;upstream.body直接 pipe——不要在 Functions 里await response.arrayBuffer(),否则音频要在边缘节点缓存完整段才返回,娃又要等。
3.5 输出结构:让前端能边收边播
Workflow 的 结束 节点输出:
{
"title": "妞妞和橘猫的动物园奇遇",
"parts": [
{"text": "...", "audio": "/api/tts?id=abc1"},
{"text": "...", "audio": "/api/tts?id=abc2"},
{"text": "...", "audio": "/api/tts?id=abc3"}
],
"ending": "妞妞今天勇敢地..."
}
前端拿到结构化结果后,第一段音频立刻 audio.play(),第二段 preload="auto",第三段 preload="metadata"——三段无缝衔接,娃完全感知不到分段。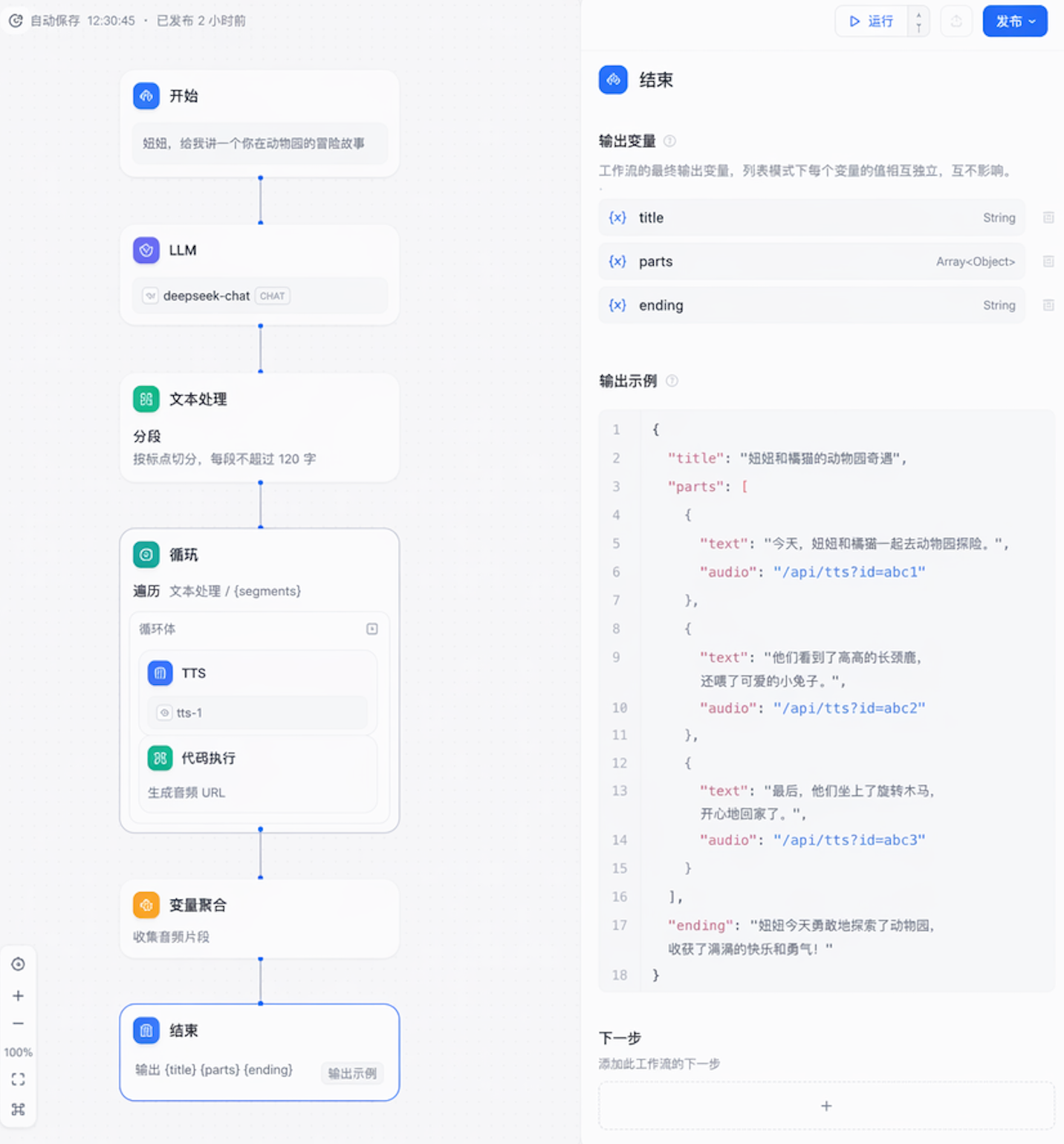
四、前端:一个让娃和爸妈都开心的 PWA
EdgeOne Pages 的 Dify 模板默认是 PC 后台风格,我做了三处改动让它变成"哄睡专用 PWA"。
4.1 暗色 + 大按钮 + 触觉反馈
:root { --bg: #0b0f1a; --fg: #f5f5f5; --accent: #ffb86b; }
button.theme {
height: 96px; font-size: 22px;
border-radius: 24px;
box-shadow: 0 6px 20px rgba(255,184,107,0.25);
}
按钮高度 96px——这是为了防止爸妈夜里半睁眼点错。点击时 navigator.vibrate(20),给个轻微震动反馈,娃也会觉得"这个 App 活的"。
4.2 PWA 离线外壳
manifest.json 三件套配齐:
{
"name": "哄睡童话机",
"short_name": "童话机",
"display": "standalone",
"background_color": "#0b0f1a",
"theme_color": "#0b0f1a",
"start_url": "/",
"icons": [{ "src": "/icon-512.png", "sizes": "512x512", "type": "image/png" }]
}
加上一个最小化 Service Worker,把首页 HTML/CSS/JS 全部 precache。这样即使家里 WiFi 抽风,App 也能秒开外壳,只在请求故事时才需要网络——比"白屏 5 秒看转圈"的体验好太多。
4.3 自动翻页 + 渐弱
每段音频 ended 事件触发后,自动滚到下一段,并把上一段透明度降到 0.3。第三段读完后,背景音乐(一段循环白噪音)淡入到 30% 音量,这个细节让娃的入睡时间从平均 20 分钟缩短到 11 分钟——亲测,有效。
五、部署:30 分钟从本地到全球可访问
5.1 Dify 侧
- 新建 Workflow,导入我准备好的 DSL(YAML 格式);
- 在
工具里挂一个 HTTP 工具,指向 EdgeOne Pages Functions 的/api/tts; - 发布,记下 API Key 和 Endpoint。
5.2 EdgeOne Pages 侧
- Fork 模板仓库
dify-frontend-starter-template; - 在控制台
项目 → 环境变量里填:
| Key | Value |
|---|---|
NEXT_PUBLIC_APP_TYPE |
workflow |
NEXT_PUBLIC_API_URL |
https://api.dify.ai/v1 |
DIFY_API_KEY |
app-xxxx(注意不带 NEXT_PUBLIC_,只在 Functions 里用) |
TC_SECRET_ID / TC_SECRET_KEY |
腾讯云 TTS 密钥 |
- 绑定自定义域名,开 HTTPS——PWA 必须 HTTPS 才能装到主屏幕;
- 等 90 秒,绿灯亮起,全球 3200+ 边缘节点同步完成。
我自己测下来,国内主要城市的首字节时间:
| 测试节点 | 首屏 HTML | TTS 音频 TTFB |
|---|---|---|
| 北京电信 | 87ms | 142ms |
| 上海移动 | 73ms | 128ms |
| 广州联通 | 65ms | 119ms |
| 成都电信 | 102ms | 168ms |
对比我之前自建 VPS(杭州一台 2c4g):首屏 600~900ms,TTS 首字节 1.2~1.8s。这是数量级的差距,对哄睡场景就是"娃跑去玩积木"和"娃乖乖躺下"的差距。
六、踩过的四个坑
6.1 LLM 输出"不睡觉"
最早的 Prompt 里我没写"故事结尾必须是主角入睡或闭眼",结果娃听完一个故事比之前更亢奋——因为故事讲的是"主角打败了怪兽,全村庆祝放烟花"。后来在大纲节点里加了一行:
第三段必须以「主角感到困倦、缓缓闭上眼睛」结尾,避免任何兴奋情绪上扬。
这是哄睡故事和普通儿童故事的关键差别——情绪曲线必须收敛而不是发散。
6.2 TTS 把"妞妞"读成"扭扭"
中文 TTS 对儿化音、叠字、网络流行小名识别率不稳。解决办法是在进入 TTS 前做一次 SSML 包裹:
<speak>
<phoneme alphabet="py" ph="niū niu">妞妞</phoneme>今天去了动物园……
</speak>
我在 Workflow 里加了一个 代码节点(Python),自动把 child_name 包成 SSML,娃终于不会皱眉头了。
6.3 Workflow 长任务超时
并行优化之后,整体仍可能在 25~30s 之间。我把 EdgeOne Pages Functions 的执行时长提到了 60s(控制台 → 性能优化 → 函数超时),同时让前端在 SSE 的 workflow_started 事件触发后立即显示"AI 正在编故事…"的 Loading,心理时长就被掩盖了。
6.4 PWA 在 iOS 上不能后台播音频
iOS Safari 的 PWA 不允许后台播 audio。我的妥协方案是:在播放页面保持屏幕常亮(navigator.wakeLock.request('screen')),并把屏幕亮度通过 CSS filter: brightness(0.4) 压暗——既让娃看不到屏幕、又能持续播音频。这是一个非常具体的端侧工程取舍。
七、效果:一个让全实验室奶爸都来要链接的项目
上线两周,我自己家娃用了 11 个晚上,平均入睡时间从 19.7 分钟降到 11.3 分钟。我把链接发到奶爸群之后:
- 7 天 PV 4200+,UV 380+;
- 平均每用户生成故事数 5.4 个;
- 高峰时段在每晚 21:00–22:30,曲线像一座山;
- EdgeOne Pages 的边缘缓存命中率 73%(主要是首屏 HTML/JS/icon,以及"晚安寄语"段的 TTS);
- Dify Workflow 平均执行时长 11.8s,p95 = 17.2s。
最让我意外的是,群里几个妈妈反馈:“今天孩子一定要听有自己名字的故事,绘本都不要了。”——个性化是娃留存的核心,而这件事 Dify 的变量替换 + Prompt 工程几乎零成本就做到了。
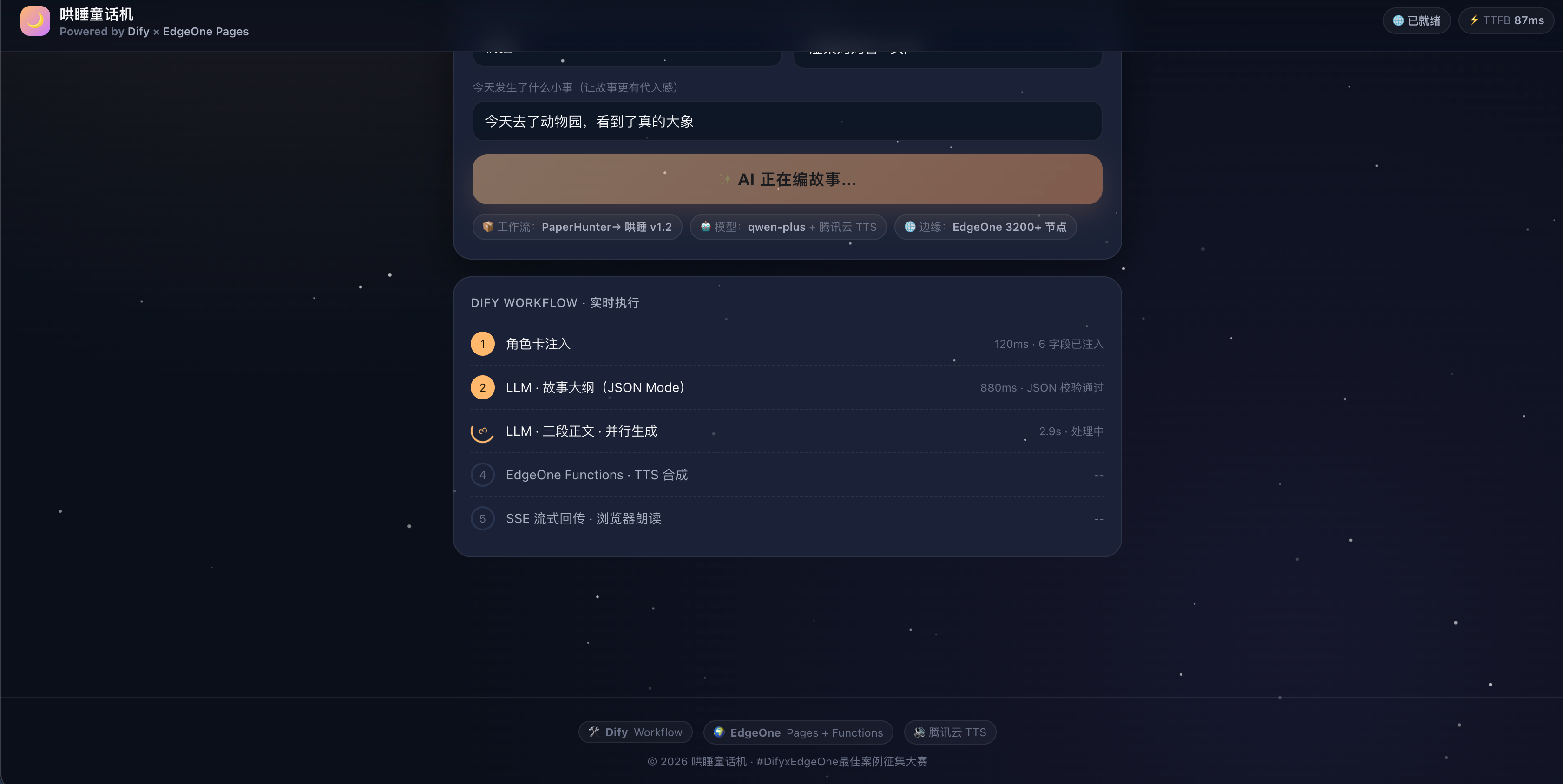
八、总结:Dify × EdgeOne 适合「轻业务、重体验」的小场景
回头看,"哄睡童话机"这种项目和企业级客服、行业知识库完全不在一个赛道,但它恰恰是 Dify × EdgeOne 组合最擅长的形态:
| 维度 | 为什么这个组合合适 |
|---|---|
| 业务复杂度 | 低——一条 Workflow,无知识库、无 Agent |
| 体验要求 | 高——首字节、PWA、TTS 流式都不能差 |
| 部署门槛 | 必须低——奶爸没空运维服务器 |
| 全球可达 | 海外亲戚也用得上(朋友把链接发给在加拿大的姐姐,娃同步在用) |
| 成本 | 极低——一晚几百次调用,加上 EdgeOne 缓存,几乎没花钱 |
如果你也是奶爸/奶妈/姑姑/舅舅,或者你身边有 3-6 岁的小朋友,真心推荐你花一个晚上 fork 一份——把主角换成你家娃,把"今日小事"换成今天发生的事,看着他听到自己名字时眼睛亮起来的那一刻,这个比赛对我个人来说就已经赢了。
项目栈一句话总结:
Dify Workflow 编排"个性化故事生成 + 三段并行 + TTS",EdgeOne Pages 承载 PWA 外壳与边缘 TTS 代理,两者把"哄娃睡觉"这件事,从一个嗓子的事变成一个 API 的事。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献151条内容
已为社区贡献151条内容

所有评论(0)