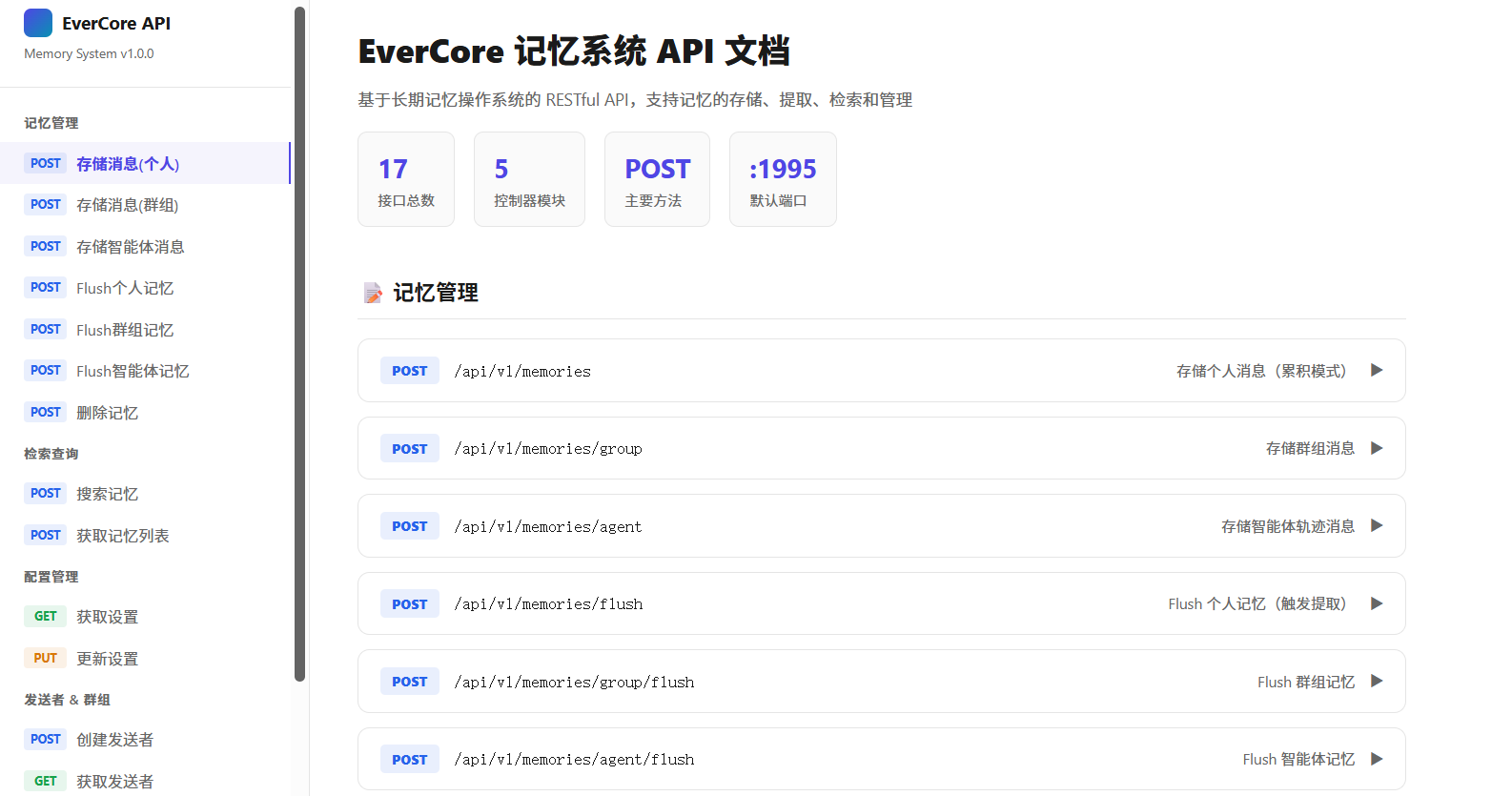
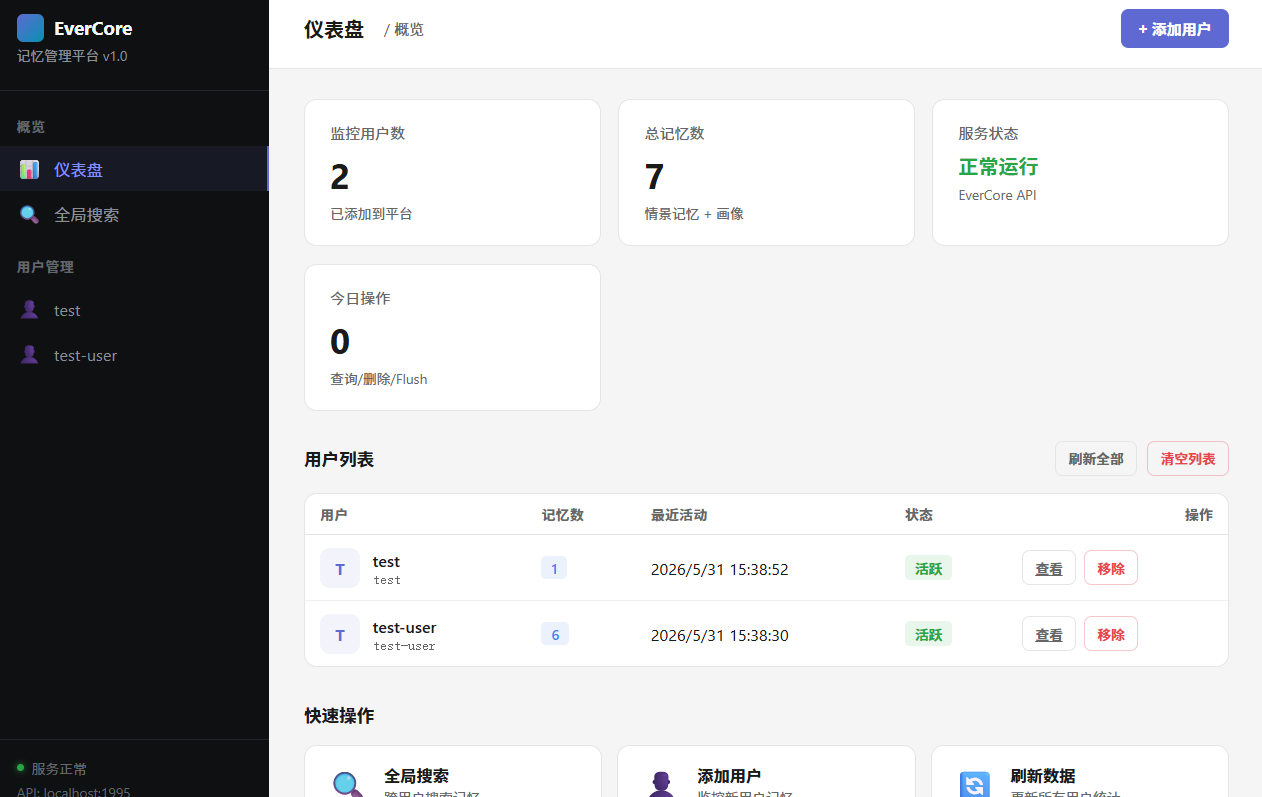
EverCore 记忆系统原理 外带测试Demo和记忆可视化管理
EverOS 是一个面向自进化智能体(Self-Evolving Agents)的长期记忆操作系统。其核心组件EverCore能够从对话中提取、结构化和检索持久化知识,使智能体能够跨会话记忆并随时间自适应进化。与传统 RAG(检索增强生成)仅做"文档切片 → 向量检索"不同,EverCore 实现了一套认知级记忆系统,模拟人类记忆的编码、存储、巩固和检索过程。
EverCore 记忆系统原理文档
你的操作 系统内部 存储变化
─────────────────────────────────────────────────────────────
点击「发送」 → 原样存入 MongoDB raw_messages +1
"我喜欢路小雨" status: accumulated点击「Flush」 → 加载所有累积消息 memcells +1
→ LLM 边界检测(切分话题)
→ LLM 提取情景记忆 episodic_memories +N
→ LLM 提取原子事实 atomic_facts +N
→ 向量化 → 存入 Milvus milvus +N
→ jieba 分词 → 存入 ES elasticsearch +N
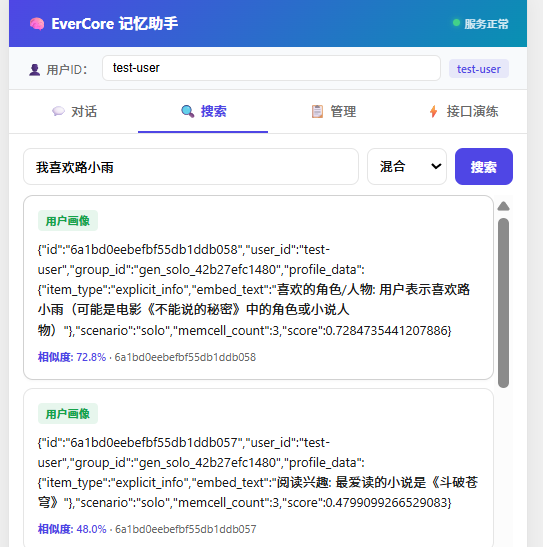
→ 清空已消费的原始消息 raw_messages -N搜索"我喜欢谁" → jieba 分词 → ES BM25 返回情景记忆
→ 或向量 → Milvus 相似度 + 用户画像
→ Rerank 精排
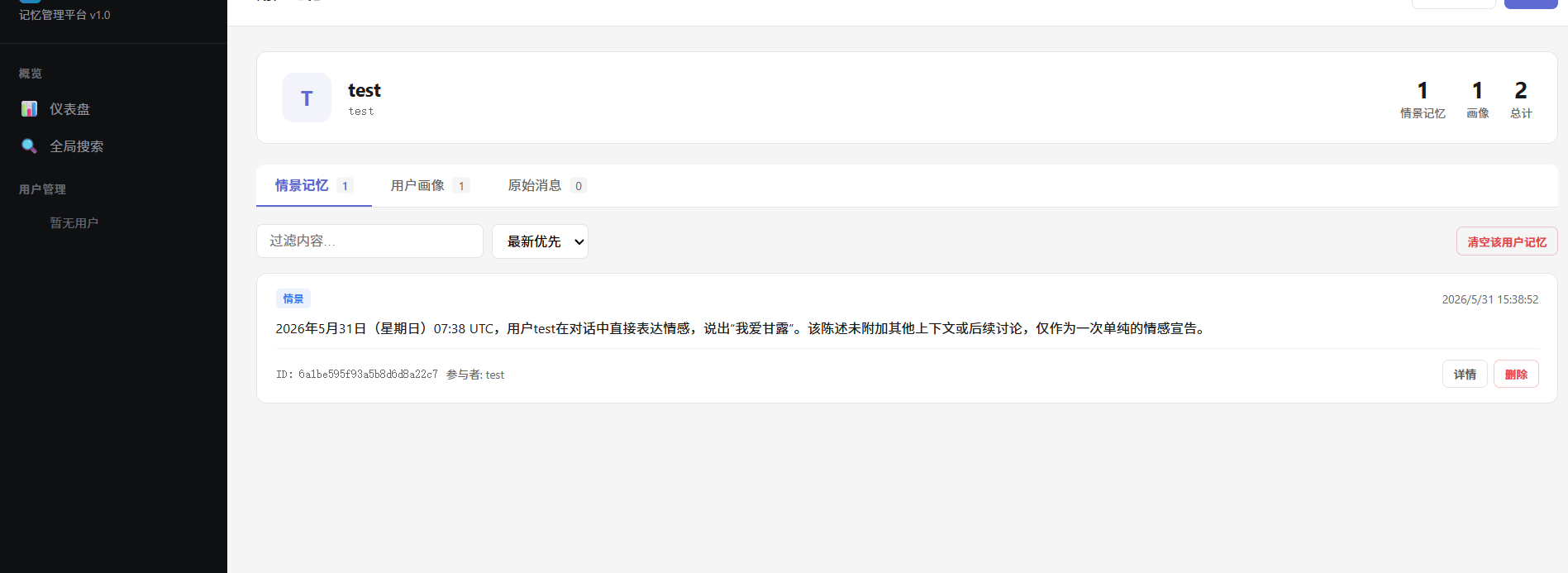
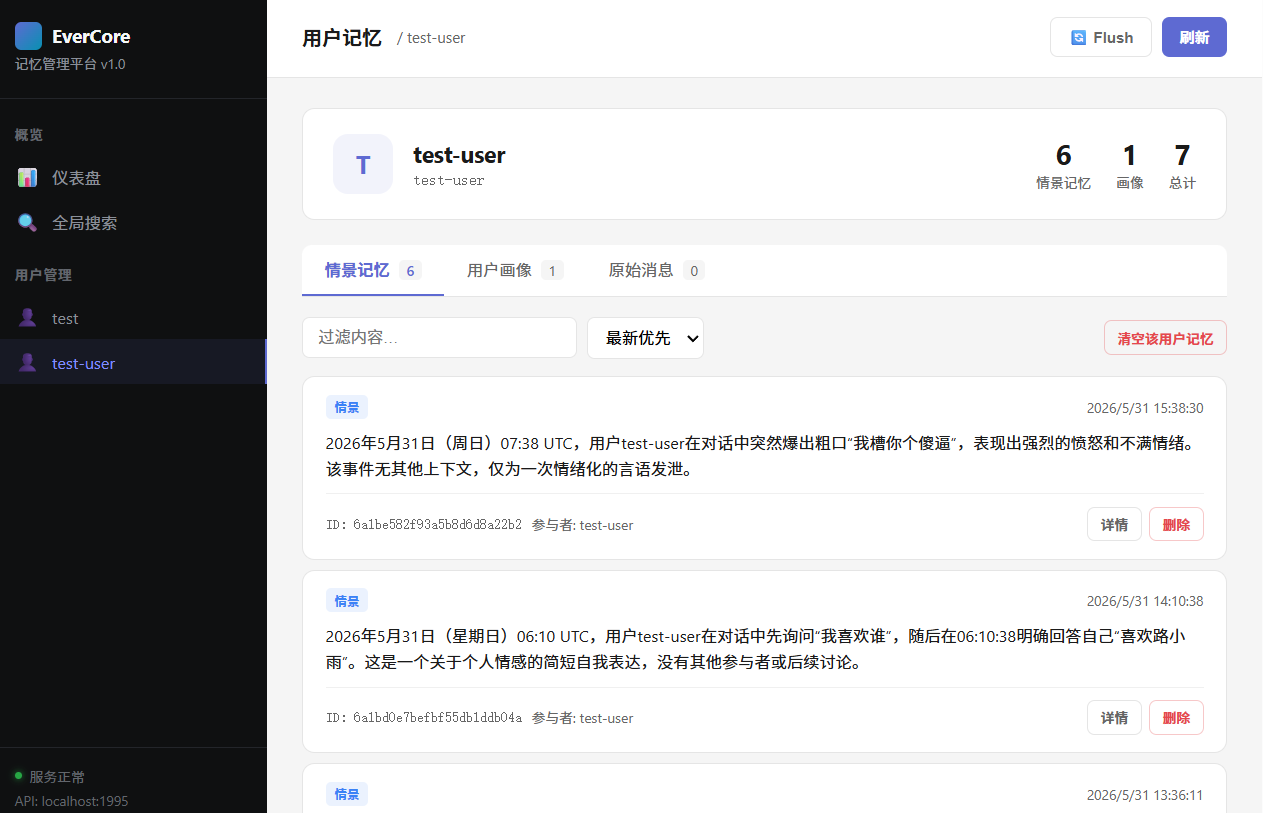
测试
一、项目概述
EverOS 是一个面向自进化智能体(Self-Evolving Agents)的长期记忆操作系统。其核心组件 EverCore 能够从对话中提取、结构化和检索持久化知识,使智能体能够跨会话记忆并随时间自适应进化。
与传统 RAG(检索增强生成)仅做"文档切片 → 向量检索"不同,EverCore 实现了一套认知级记忆系统,模拟人类记忆的编码、存储、巩固和检索过程。
1.1 与传统 RAG 的核心区别
| 维度 | 传统 RAG | EverCore |
|---|---|---|
| 记忆粒度 | 原文切片(chunk) | 结构化记忆单元(MemCell → Episode/Foresight/AtomicFact) |
| 处理方式 | 文档入库时一次性切分 | 实时对话流 → 边界检测 → LLM 深度理解 → 多维度提取 |
| 存储结构 | 单一向量库 | MongoDB(结构化) + ES(关键词) + Milvus(向量)三路存储 |
| 检索策略 | 单一向量相似度 | 关键词 / 向量 / 混合RRF / Agentic多轮召回 + Rerank 重排序 |
| 记忆演化 | 无 | 聚类 → 用户画像提取 → 成熟度评分 → 技能提炼 |
| 多租户 | 通常无 | 支持逻辑隔离(shared)和物理隔离(exclusive) |
二、系统架构
EverCore 采用六层分层架构,围绕两条核心认知轨道运行:
-
记忆构建轨道(Memory Construction):消息 → 边界检测 → 记忆提取 → 存储索引
-
记忆感知轨道(Memory Perception):查询 → 多策略检索 → Rerank → 上下文注入
┌───────────────────────────────────────────────────────────┐ │ API Layer (FastAPI) │ │ /api/v1/memories | /search | /flush | /get │ └─────────────────────────────┬─────────────────────────────┘ │ ┌─────────────────────────────▼─────────────────────────────┐ │ Agentic Layer(智能体层) │ │ MemoryManager: memorize() / retrieve_mem() / get_mem() │ │ ├── VectorizeService(向量化:Hybrid主备 + 自动故障转移) │ │ ├── RerankService(重排序:Hybrid主备 + 自动故障转移) │ │ └── AgenticUtils(充分性检查 + 多查询生成) │ └─────────────────────────────┬─────────────────────────────┘ │ ┌─────────────────────────────▼─────────────────────────────┐ │ Memory Layer(记忆层) │ │ ConvMemCellExtractor(边界检测) │ │ ├── EpisodeMemoryExtractor(情景记忆提取) │ │ ├── ForesightExtractor(前瞻性记忆提取) │ │ ├── AtomicFactExtractor(原子事实提取) │ │ ├── AgentCaseExtractor(智能体经验提取) │ │ └── ProfileExtractor(用户画像提取) │ └─────────────────────────────┬─────────────────────────────┘ │ ┌─────────────────────────────▼─────────────────────────────┐ │ Business Layer(业务层) │ │ memorize() → 预处理 → 边界检测 → 记忆提取 → 三路存储 │ │ ├── ClusterManager(聚类管理) │ │ ├── MemorySyncService(ES + Milvus 同步) │ │ └── ConversationStatus(会话状态管理) │ └─────────────────────────────┬─────────────────────────────┘ │ ┌─────────────────────────────▼─────────────────────────────┐ │ Infrastructure Layer(基础设施层) │ │ ├── MongoDB 7.0+(主存储:结构化记忆数据) │ │ ├── Elasticsearch 8.x(BM25 关键词索引) │ │ ├── Milvus 2.4+(向量索引:语义检索) │ │ └── Redis 7.x(缓存 + 分布式锁) │ └─────────────────────────────┬─────────────────────────────┘ │ ┌─────────────────────────────▼─────────────────────────────┐ │ Core Framework(核心框架) │ │ ├── DI Container(依赖注入) │ │ ├── Tenant System(多租户隔离) │ │ ├── Observability(Metrics + Tracing + Logging) │ │ └── Distributed Lock(Redis 分布式锁) │ └───────────────────────────────────────────────────────────┘
三、记忆类型体系
EverCore 定义了丰富的记忆类型,模拟人类多层次的记忆结构:
3.1 数据模型继承关系
BaseMemory(基础字段:user_id, timestamp, group_id, vector, score...) ├── MemCell(记忆单元 - 边界检测的产物,所有下游记忆的源头) ├── EpisodeMemory(情景记忆 - 叙事性摘要) ├── AtomicFact(原子事实 - 最小粒度的事实陈述) ├── Foresight(前瞻性记忆 - 对未来决策的预测) ├── AgentCase(智能体经验 - 任务执行记录) ├── AgentSkill(智能体技能 - 从经验聚类中提炼的可复用技能) └── ProfileMemory(用户画像 - 显式信息 + 隐式特征)
3.2 各类型详细说明
| 记忆类型 | 存储位置 | 说明 | 典型数量 |
|---|---|---|---|
| MemCell | MongoDB memcells |
边界检测产出的最小容器,包含原始消息列表 | 每次边界检测产生 1-N 个 |
| EpisodeMemory | MongoDB + ES + Milvus | 从 MemCell 提取的叙事摘要,分 Group(群体)和 Personal(个人)视角 | 每个 MemCell 1-N 个 |
| AtomicFact | MongoDB + ES + Milvus | 从 MemCell 直接提取的原子事实,每条独立向量化存储(仅 Solo 场景) | 每个 MemCell 5-15 条 |
| Foresight | MongoDB + ES + Milvus | 预测性记忆,描述对话对未来决策的潜在影响(仅 Solo 场景) | 每个 MemCell ~10 条 |
| AgentCase | MongoDB + ES + Milvus | 从智能体对话提取的经验记录,含质量评分 | 每个 MemCell 1-N 个 |
| AgentSkill | MongoDB + ES + Milvus | 从 AgentCase 聚类中派生的可复用技能,有成熟度评分 | 聚类后增量产生 |
| ProfileMemory | MongoDB + ES + Milvus | 用户画像,包含显式信息(兴趣/事实)和隐式特征(性格/偏好) | 每用户 1 个,持续更新 |
3.3 场景差异
| 场景 | Episode | Foresight | AtomicFact | Profile |
|---|---|---|---|---|
| Solo(1用户+N智能体) | 1个 Group Episode | ~10条 | 5-15条 | 通过聚类提取 |
| Team(多用户+智能体) | 1个Group + N个Personal | 不提取 | 不提取 | 通过聚类提取 |
| Agent 对话 | Episode + AgentCase | 不提取 | 可选跳过 | 通过聚类提取 |
四、记忆构建流程(Memorize Pipeline)
这是 EverCore 最核心的流程,将原始对话流转化为结构化记忆。
4.1 完整流程图
原始消息流 │ ▼ ┌───────────────────────┐ │ 1. 消息累积与预处理 │ │ (Accumulate & Preprocess) │ │ 消息暂存到缓冲区 │ │ status: "accumulated" │ └───────────┬───────────┘ │ 触发 Flush ▼ ┌───────────────────────┐ │ 2. 边界检测 │ │ (Boundary Detection) │ │ ┌─ Phase 1: 强制分割 │ ← 超过 token/消息数硬限制 │ ├─ Phase 2: LLM检测 │ ← LLM 识别话题边界 │ └─ Phase 3: Flush尾部 │ ← 剩余消息打包 └───────────┬───────────┘ │ 输出 MemCell 列表 ▼ ┌───────────────────────┐ │ 3. 记忆提取 │ │ (Memory Extraction) │ │ ├─ Episode 提取 │ ← LLM 生成叙事摘要 │ ├─ AgentCase 提取 │ ← 智能体经验记录 │ ├─ Foresight 提取 │ ← 预测性记忆 (Solo) │ └─ AtomicFact 提取 │ ← 原子事实 (Solo) └───────────┬───────────┘ │ ▼ ┌───────────────────────┐ │ 4. 三路存储与索引 │ │ (Storage & Indexing) │ │ ├─ MongoDB (主存储) │ │ ├─ Elasticsearch (BM25) │ │ └─ Milvus (向量索引) │ └───────────┬───────────┘ │ ▼ ┌───────────────────────┐ │ 5. 后台演化任务 │ │ (Background Evolution)│ │ ├─ 聚类 (Clustering) │ │ ├─ Profile 提取 │ │ └─ Skill 提炼 │ └───────────────────────┘
4.2 阶段一:消息累积与预处理
当用户发送消息时,系统不会立即处理,而是先累积到缓冲区:
-
消息暂存到
conversation_data_repo -
系统记录
last_memcell_time(上次记忆提取时间)标记当前窗口起点 -
新消息追加到当前窗口,等待 Flush 触发
-
返回
"status": "accumulated"表示消息已接收
4.3 阶段二:边界检测(Boundary Detection)
这是 EverCore 区别于传统 RAG 的关键创新——不是简单按固定长度切分,而是用 LLM 智能识别对话中的话题边界。
三阶段算法:
Phase 1 - 强制分割循环:当消息超过硬限制时(默认 65536 tokens 或 500 条消息),自动将前段切分为 MemCell,无需 LLM 判断。使用二分查找找到合适的分割点。
Phase 2 - LLM 批量边界检测:
-
将消息格式化为
[N] [2024-01-15 14:30:00+08:00] 张三: 消息内容 -
调用 LLM 一次性检测多个分割点
-
LLM 返回 JSON:
{"boundaries": [3, 7, 12], "should_wait": false} -
解析失败时最多重试 5 次
Phase 3 - Flush 尾部处理:flush=True 时,将剩余消息打包为最终 MemCell。
为什么边界检测很重要?
-
传统 RAG 按固定 token 数切分,会把一个完整话题切成碎片
-
EverCore 用 LLM 理解语义边界,确保每个 MemCell 包含一个完整的话题/事件
-
这使得后续的记忆提取质量大幅提升
4.4 阶段三:记忆提取(Memory Extraction)
边界检测产出 MemCell 后,系统并行启动多维度记忆提取:
MemCell ├── EpisodeMemoryExtractor │ ├── Group Episode(群体视角摘要) │ └── Personal Episodes(个人视角,Team场景每个参与者一个) │ ├── AgentCaseExtractor(智能体对话场景) │ └── 任务意图 + 方法步骤 + 质量评分 │ ├── [后台] ForesightExtractor(Solo场景) │ └── 预测性记忆(未来影响、证据、持续时间) │ └── [后台] AtomicFactExtractor(Solo场景) └── 5-15条原子事实,每条独立向量化
每种提取都通过 LLM 完成,使用精心设计的 Prompt(支持中英文),存储在 src/memory_layer/prompts/ 目录中。
4.5 阶段四:三路存储与索引
每条记忆同时写入三个存储系统,各自承担不同职责:
| 存储系统 | 写入内容 | 检索能力 |
|---|---|---|
| MongoDB | 完整记忆文档(所有字段) | 结构化查询、分页、排序 |
| Elasticsearch | 经过 Converter 转换的 ES 文档 | BM25 关键词搜索、全文检索 |
| Milvus | 向量化实体(Embedding) | 语义相似度搜索(余弦距离) |
4.6 阶段五:后台演化任务
记忆提取完成后,后台异步触发演化任务:
聚类(Clustering):
-
使用
ClusterManager基于相似度阈值和时间间隔进行聚类 -
通过 Redis 分布式锁防止并发冲突
-
聚类状态持久化,支持增量更新
用户画像提取(Profile Extraction):
-
基于聚类结果,定期触发 Profile 提取
-
两层过滤策略:组级过滤 → 用户级过滤
-
冷启动保护:新群组使用当前 MemCell 时间戳
-
失败容错:提取失败时仍然推进时间戳,避免卡在循环重试
技能提炼(AgentSkill Extraction):
-
从聚类的 AgentCase 中提炼可复用技能
-
包含成熟度评分(maturity_score),随使用反馈更新
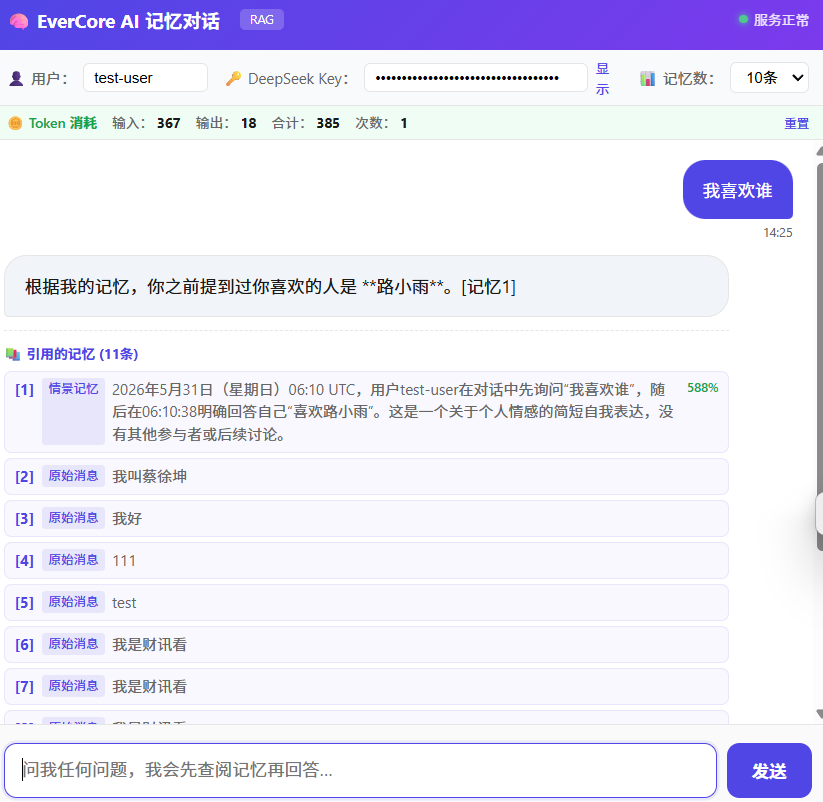
五、RAG 检索流程(Retrieve Pipeline)
EverCore 提供四种检索策略,从简单到复杂,精度逐步提升。
5.1 四种检索方法对比
| 策略 | 延迟 | Precision | Recall | F1 | 适用场景 |
|---|---|---|---|---|---|
| Keyword(关键词) | 50-100ms | 0.72 | 0.68 | 0.70 | 精确术语匹配、无需 Embedding 服务 |
| Vector(向量) | 200-500ms | 0.78 | 0.75 | 0.77 | 语义理解、模糊查询 |
| Hybrid / RRF(混合) | 200-600ms | 0.85 | 0.82 | 0.84 | 推荐默认策略,综合最优 |
| Agentic(智能体) | 2-5s | 0.91 | 0.89 | 0.90 | 复杂查询、需要多轮推理 |
5.2 关键词检索(Keyword Search)
用户查询 → jieba 分词 → 去除停用词 → ES BM25 搜索 → 返回结果
-
使用 jieba 中文分词器(
jieba.cut_for_search) -
通过停用词过滤器过滤短词(最短 2 字符)
-
基于 Elasticsearch 的 BM25 算法进行相关性评分
-
不需要 Embedding 服务,延迟最低
5.3 向量检索(Vector Search)
用户查询 → Embedding 模型 → 查询向量 → Milvus 余弦相似度搜索 → 阈值过滤 → 返回结果
-
使用 Embedding 模型(默认
Qwen/Qwen3-Embedding-4B,维度 1024)将查询文本转为向量 -
在 Milvus 中执行余弦相似度搜索
-
支持相似度阈值过滤(默认 0.6)
-
支持无限模式(
top_k=-1)返回所有超过阈值的结果
5.4 混合检索 / RRF(Hybrid Search)
这是 EverCore 推荐的默认策略,综合关键词和向量的优势:
用户查询 ──┬── 关键词搜索(ES BM25)──┐ │ ├── 按 ID 去重合并 → Rerank 重排序 → Top-K 结果 └── 向量搜索(Milvus)─────┘
流程:
-
并行执行关键词搜索和向量搜索(
asyncio.gather) -
按 ID 去重合并两个结果集
-
Rerank 重排序:使用 Reranker 模型(默认
Qwen/Qwen3-Reranker-4B)对合并结果进行精细化重排 -
截取 Top-K 结果返回
5.5 Agentic 检索(最复杂、最智能)
这是最复杂的检索模式,模拟人类的多步推理过程:
Round 1: Hybrid 检索(top_n=20) │ ▼ Rerank 重排序(top_n=10) │ ▼ LLM 充分性检查 ── 充足 ──→ 返回结果 │ 不充足 ▼ LLM 生成 2-3 个补充查询 │ ▼ Round 2: 并行 Hybrid 检索(每个查询 top_n=50) │ ▼ 合并 Round 1 + Round 2 结果(最多 40 条) │ ▼ 最终 Rerank → 返回结果
关键创新:
-
充分性检查(Sufficiency Check):让 LLM 判断已检索的记忆是否足够回答查询,返回
{is_sufficient, reasoning, missing_information} -
多查询生成(Multi-Query Generation):基于原始查询、已检索结果和缺失信息,LLM 生成 2-3 个互补查询,扩大召回范围
-
两轮检索:第一轮快速召回 → 判断是否充分 → 不充分则第二轮深度召回
5.6 Rerank 重排序
Rerank 是所有检索策略的最后一步,用于精细化排序:
-
使用专用 Reranker 模型(
Qwen/Qwen3-Reranker-4B) -
采用 HybridRerankService 混合策略 + 自动故障转移
-
支持批量并发处理 + 指数退避重试
-
支持阈值过滤(默认 0.6),低于阈值的结果被剔除
六、向量化服务(Embedding Service)
6.1 混合策略 + 自动故障转移
EverCore 的向量化和重排序服务都采用 Hybrid 混合策略:
主服务(Primary) ├── 成功 → 返回结果,重置失败计数 └── 失败 → 失败计数 +1 ├── fallback 未启用 → 抛出异常 └── fallback 已启用 → 尝试备用服务 ├── 成功 → 返回结果 └── 失败 → 两者都失败,抛出异常
6.2 配置项
# 主向量化服务 VECTORIZE_PROVIDER=vllm # vllm(自部署)或 deepinfra(云服务) VECTORIZE_BASE_URL=http://localhost:8000/v1 VECTORIZE_MODEL=Qwen/Qwen3-Embedding-4B # 备用向量化服务 VECTORIZE_FALLBACK_PROVIDER=deepinfra VECTORIZE_FALLBACK_BASE_URL=https://api.deepinfra.com/v1/openai VECTORIZE_FALLBACK_API_KEY=your-key # 主重排序服务 RERANK_PROVIDER=vllm RERANK_BASE_URL=http://localhost:12000/v1/rerank RERANK_MODEL=Qwen/Qwen3-Reranker-4B
七、多租户机制
EverCore 原生支持多租户隔离:
| 隔离模式 | 说明 | 适用场景 |
|---|---|---|
| shared(默认) | 所有租户共享表/索引,通过 tenant_id 逻辑隔离 |
SaaS 多用户共享部署 |
| exclusive | 每个租户使用独立的数据库/集合/索引,物理隔离 | 企业级私有部署 |
每个租户可独立配置 MongoDB、Redis、Elasticsearch、Milvus 连接。
八、典型使用流程
8.1 对话记忆流程
用户: "我今天去了上海博物馆,看到了青铜器展览" │ ▼ POST /api/v1/memories │ status: "accumulated" ← 消息暂存 │ ▼ 触发 Flush │ 边界检测 → 识别为一个完整话题 │ 提取 Episode: "用户于今日参观了上海博物馆,观看了青铜器展览" │ 提取 AtomicFact: ["用户今天去了上海", "用户参观了博物馆", "用户看了青铜器展览"...] │ 提取 Foresight: "用户对历史文化感兴趣,未来可推荐类似展览" │ 存储到 MongoDB + ES + Milvus │ ▼ 用户后续查询 │ "推荐一些文化活动" → Agentic 检索 → 找到青铜器展览记忆 → 推荐相关活动
8.2 API 调用示例
// 1. 发送消息(累积模式)
await fetch("http://localhost:1995/api/v1/memories", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
user_id: "user-001",
session_id: "session-001",
messages: [{ role: "user", content: "我今天去了上海博物馆", timestamp: Date.now() }]
})
});
// 响应: { status: "accumulated", message_count: 1 }
// 2. Flush 处理
await fetch("http://localhost:1995/api/v1/memories/flush", {
method: "POST",
body: JSON.stringify({ user_id: "user-001", session_id: "session-001" })
});
// 3. 搜索记忆
await fetch("http://localhost:1995/api/v1/memories/search", {
method: "POST",
body: JSON.stringify({
query: "博物馆",
method: "hybrid", // keyword | vector | hybrid | agentic
memory_types: ["episodic_memory", "profile"],
filters: { user_id: "user-001" },
top_k: 5
})
});
九、技术栈总览
| 组件 | 技术选型 | 用途 |
|---|---|---|
| Web 框架 | FastAPI + Python 3.10+ | REST API 服务 |
| 主数据库 | MongoDB 7.0+ (Beanie ODM) | 结构化记忆存储 |
| 关键词索引 | Elasticsearch 8.x | BM25 全文检索 |
| 向量数据库 | Milvus 2.4+ | 语义相似度搜索 |
| 缓存/锁 | Redis 7.x | 缓存 + 分布式锁 |
| LLM | OpenAI 兼容 API(DeepSeek/OpenAI 等) | 记忆提取 + 推理 |
| Embedding | Qwen3-Embedding-4B | 文本向量化 |
| Reranker | Qwen3-Reranker-4B | 检索结果重排序 |
| 中文分词 | jieba | 关键词搜索分词 |
| Token 计数 | tiktoken (o200k_base) | 边界检测中的 token 限制 |
十、核心设计理念
10.1 认知级记忆 vs 文档级 RAG
EverCore 的核心理念是将记忆从"文档切片"提升到"认知理解":
-
传统 RAG:文档 → 切片 → 向量化 → 检索(机械切分,丢失上下文)
-
EverCore:对话流 → 话题边界 → LLM 深度理解 → 多维度结构化提取 → 演化(模拟人类认知)
10.2 记忆的生命周期
编码(Encode) → 消息流经边界检测和 LLM 提取,转化为结构化记忆 存储(Store) → 三路持久化(MongoDB + ES + Milvus) 巩固(Consolidate)→ 聚类 + Profile 提取 + Skill 炼化 检索(Retrieve) → 多策略检索 + Rerank 精排 遗忘(Fade) → 成熟度评分驱动的记忆衰减(规划中)
10.3 两条认知轨道的协同
对话流 │ ┌───────────┴───────────┐ ▼ ▼ 记忆构建轨道 记忆感知轨道 (Memory Construction) (Memory Perception) │ │ │ 边界检测 │ 多策略检索 │ 记忆提取 │ Rerank 重排 │ 三路存储 │ 充分性检查 │ 聚类/演化 │ 上下文注入 │ │ └───────────┬───────────┘ │ ▼ 智能体响应 (更准确、更个性化的回答)
文档生成日期:2026-05-31 基于 EverCore 源码分析生成

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)