Agent-World:LLM与环境的协同进化
Agent-World:LLM与环境的协同进化
这是一篇由中国人民大学高瓴人工智能学院与字节跳动(ByteDance Seed)合作发表的关于大语言模型(LLM)智能体训练的重磅前沿论文。
该论文提出了一种名为 Agent-World 的自进化训练框架,旨在解决当前通用智能体(General Agents)在复杂、真实工具环境中训练数据不足、缺乏持续学习机制的核心痛点。
以下是对这篇论文的详细深度解读:
一、 研究背景与当前痛点

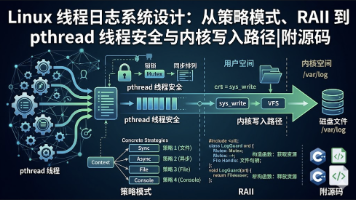
左侧为Agent-World整体框架概览,右侧为下游通用智能体性能对比。环境规模缩放分析给出了MCP-Mark、BFCL V4、τ²-Bench三大基准代表性子领域的平均分。
随着大语言模型能力的提升,人们期望它们能从“聊天助手”进化为能够调用外部工具、与真实世界交互的“通用智能体”。然而,当前的智能体训练面临两大瓶颈:
- 环境与任务构建难以扩展且缺乏真实感: 手工构建交互环境成本极高;而利用LLM模拟的环境(Simulators)容易产生幻觉,缺乏真实物理/软件世界的复杂状态转换逻辑。
- 缺乏持续自进化的训练机制: 现有的智能体训练大多是一次性的(在静态数据集上微调或RL),缺乏像人类一样“发现弱点→\rightarrow→针对性学习→\rightarrow→能力提升”的闭环终身学习机制。
二、 核心创新与解决方案:Agent-World
为了解决上述问题,论文提出了 Agent-World,这是一个集成了可扩展真实环境合成与持续自进化训练的通用智能体训练竞技场(Arena)。它包含两个核心组件:
组件 1:智能体驱动的环境与任务发现(Agentic Environment-Task Discovery)
这一步的目标是全自动地、大规模地构建出带有真实数据的环境和可验证的任务。
- 真实环境挖掘: 论文没有让LLM凭空捏造数据,而是以真实的Model Context Protocol (MCP) 服务器规范、开源工具文档和工业产品需求文档(PRDs)为锚点,派出“深度研究智能体(Deep-research agent)”去互联网上自动挖掘、抓取并构建真实的数据库(如JSON, CSV, SQL等格式)。
- 工具接口生成与验证: 利用编码智能体(Coding Agent)为这些数据库生成可执行的Python工具函数(API),并严格通过单元测试,最终保留了 1978个独立环境和19822个可执行工具。
- 可验证的复杂任务合成: 采用了两种互补的任务生成策略,并通过沙盒执行来生成Ground-truth(标准答案):
- 基于图的合成(Graph-based): 为工具之间的依赖关系建图,通过随机游走(Random Walk)生成长逻辑链条的任务(侧重多步顺序调用)。
- 程序化合成(Programmatic): 直接生成包含条件分支(if-else)、循环(for)的复杂Python解决方案代码,用于模拟非线性的复杂推理任务。

智能体环境-任务发现整体流程。研究从真实世界环境主题入手,从网络中挖掘与主题匹配的数据库,生成并验证可执行工具接口,最终合成难度可控、可验证的智能任务。
组件 2:持续自进化智能体训练(Continuous Self-Evolving Agent Training)
这一步是该论文的“灵魂”,它将多环境强化学习与自我诊断闭环结合在一起:
- 多环境强化学习(Agent RL): 在合成的沙盒环境中,让模型不断与数据库和工具交互(生成-执行-反馈),并使用 GRPO算法(组相对策略优化)进行强化学习。奖励信号(Reward)不是基于简单的字符匹配,而是基于可执行的验证脚本(代码执行结果)或基于规则的结构化Rubric。
- 自进化竞技场(Self-Evolving Arena): 这是一套自动化课程学习引擎。
- 动态评估: 在未见过的测试环境中动态生成新任务让当前智能体去解答。
- 智能体诊断(Agentic Diagnosis): 引入一个“诊断智能体”,分析当前模型失败的轨迹(Traces),找出模型当前的薄弱环节(如:特定工具不会用、状态更新错误等)。
- 环境-智能体协同进化: 根据诊断报告,指导上游的“任务发现”模块针对性地生成更复杂的数据或扩充弱项环境,然后进行下一轮RL训练。由此形成“越学越难、越难越学”的上升螺旋。

持续自进化智能体训练整体框架。上方:智能体基于可执行奖励,通过多环境强化学习完成训练;下方:在动态竞技场中开展能力评估、诊断能力短板,并通过定向拓展环境与任务实现智能体能力迭代提升。
三、 实验设计与惊艳结果
(注:论文的实验部分极其前沿,甚至使用了许多下一代/代号性质的模型作为Baseline,如 GPT-5.2 High, Claude Sonnet-4.5, DeepSeek-V3.2-685B, Qwen3等,这表明该研究面向的是未来极高水平的智能体基准测试)
论文在 23 个极具挑战性的智能体评测基准(涵盖工具调用、高级AI助手、软件工程、通用推理等)上进行了评估。
- 全面碾压现有基线:
Agent-World-8B 和 14B 模型在 MCP-Mark, BFCL V4, 和 τ2\tau^2τ2-Bench 上不仅大幅超越了现有的环境扩展方法(如EnvScaler-8B, Simulator-8B),甚至在某些复杂长周期任务上比肩或超越了极其庞大的闭源/开源模型(如对比几百B参数的模型)。 - 长周期复杂任务(Search & Coding)提升最大:
在 SWE-bench, WebWalkerQA, GAIA 等需要深度探索、多步规划和状态追踪的软件工程与搜索任务中,Agent-World 展现了极强的泛化能力。 - 通用推理能力未受损:
在注入强大智能体能力的同时,模型在 MATH500, GSM8K 等纯数学推理榜单上依然保持了顶尖水平,甚至略有提升。
四、 核心洞察与 Scaling Laws(缩放定律)
论文通过进一步分析,揭示了智能体训练中的几个重要规律:
- 环境数量与性能的 Scaling Law: 随着训练环境数量从 10 增加到 100、500、1000 甚至 2000,下游智能体的性能呈现出明显的对数线性上升趋势。这证明了“扩充真实环境的多样性”是通向通用智能体的必由之路。
- 自进化轮次的收益: “评估→\rightarrow→诊断→\rightarrow→定向生成→\rightarrow→再训练”的闭环非常有效。第一轮自进化能带来巨大的性能飞跃,第二轮在解决长尾、复杂困难交互上继续提供正向收益(收益边际递减但依然显著)。
- 探索与利用的平衡: 训练动态图表明,模型在学习过程中,动作的熵(Entropy)并没有迅速坍塌(没有死记硬背),而是随着接触新工具和新环境,维持了较高的探索空间。
五、 总结与启发
Agent-World 的核心贡献在于它将“数据合成”和“强化学习”无缝缝合在了一个动态闭环中。
以往的研究要么只关注如何用大模型造数据(造完就静态微调),要么只关注强化学习算法(在固定的几个环境里死磕)。Agent-World 提出:真正的通用智能体必须在一个不断扩大、且能针对自身弱点“定制考卷”的真实沙盒宇宙中进行终身强化学习。
这项工作为未来如何训练完全自动化的、能掌握数十万种真实世界API和软件工具的超级智能体(General Agent Intelligence)提供了一套具备极高落地价值的工业级技术路线图。从附录中展示的 Arxiv、邮件、日历、酒店、App商店等具体的沙盒环境可以看出,这套系统已经具备了极强的工程实现度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)