【A Generalist Agent论文阅读】: 首次展示了单一模型可以执行数百种不同任务
Gato是通用智能体发展史上的一个重要里程碑。它证明了用一个统一的序列模型处理所有模态、所有任务是完全可行的。虽然Gato还不是真正的通用人工智能,但它向我们展示了一条清晰的道路:只要我们有足够多的多样化数据和足够大的模型,我们就可以训练出一个能完成各种任务的通用智能体。就像论文中所说的:“Transformer序列模型作为多任务多载体策略是有效的,包括真实世界的文本、视觉和机器人任务。未来,这样
论文信息
- 标题:A Generalist Agent
- 会议:Transactions on Machine Learning Research (TMLR) 2022
- 单位:DeepMind
- 代码:无公开官方代码
- 论文:https://arxiv.org/pdf/2205.06175
引言:一个AI,N种超能力
你能想象一个AI既能打《Pong》《Breakout》等经典Atari游戏,又能给图片写标题,还能和你聊天,甚至控制真实机器人手臂堆积木吗?DeepMind在2022年推出的Gato就做到了!
它用同一套神经网络权重,搞定了604个完全不同的任务,从文本对话到机器人控制,从图像理解到游戏通关,打破了传统AI“一个任务一个模型”的范式。就像人类一样,Gato可以根据不同的输入,输出完全不同类型的结果——看到游戏画面就输出按键,看到图片就输出描述,看到机器人传感器数据就输出关节力矩。
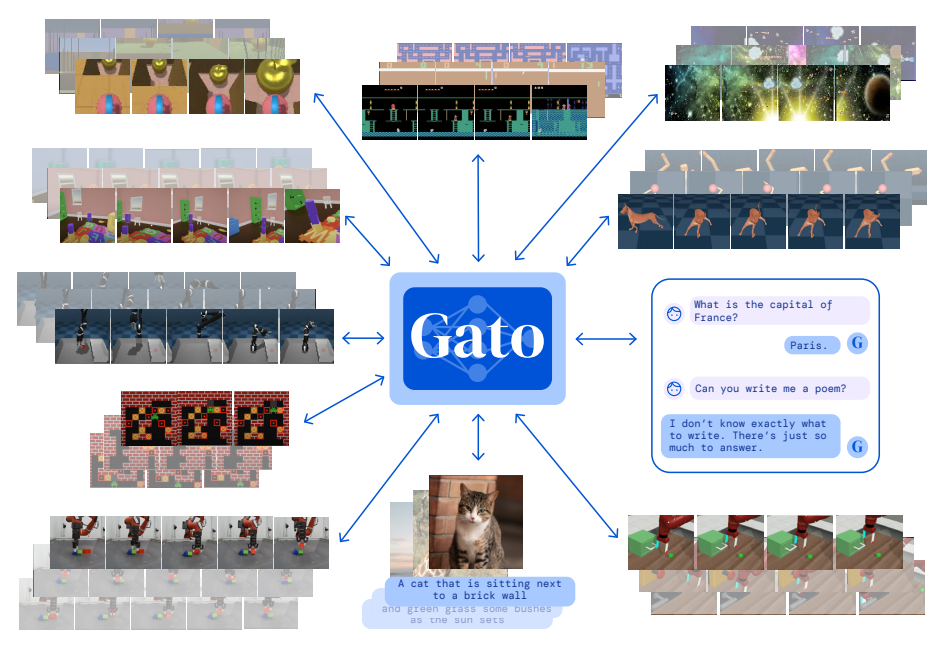
图1 Gato的多模态多任务能力(来源:论文Figure1)
从图1可以清晰看到,Gato可以无缝处理Atari游戏图像、文本对话、机器人本体感觉数据等完全不同的输入,输出对应的动作或文本。这是通用人工智能(AGI)道路上的重要一步。
一、Gato的核心设计:把所有东西都变成序列
Gato的设计灵感来自大语言模型(LLM)的成功。既然Transformer可以把文本变成序列来处理,那为什么不能把所有东西都变成序列呢?
Gato的核心思想就是:将所有模态的数据(图像、文本、传感器数据、动作等)都统一序列化,然后用一个标准的解码器-only Transformer来处理。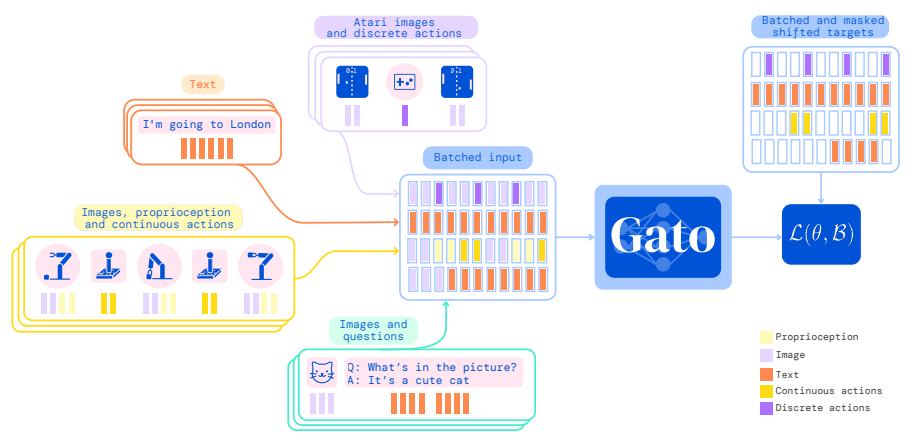
1.1 多模态数据的统一Token化
这是Gato最关键的一步。不管是什么类型的数据,都要先转换成一串整数token,然后输入到Transformer中。论文中设计了四种不同的token化方案:
| 数据类型 | Token化方法 | Token范围 |
|---|---|---|
| 文本 | 使用SentencePiece分词器,32000个子词 | [0, 32000) |
| 离散值(如Atari按键) | 直接展平为整数 | [0, 1024) |
| 连续值(如机器人关节角度) | 先进行mu-law编码,再离散化为1024个bin | [32000, 33024) |
| 图像 | 分成16×16的patch,用ResNet块嵌入 | 与其他token共享嵌入空间 |
通俗解释:这就像把不同语言的书都翻译成同一种语言,然后让同一个翻译官来读。不管是中文书、英文书还是图画书,都先转换成统一的“机器语言”,然后交给Transformer处理。
1.2 序列排序规则
所有数据token化后,还要按照固定的顺序排列成一个长序列:
- 文本token按原始顺序排列
- 图像patch token按光栅顺序(从左到右,从上到下)排列
- 张量数据按行优先顺序排列
- 每个时间步的结构是:观察token + 分隔符 + 动作token
- 整个episode按时间顺序排列
1.3 训练目标与损失函数
Gato采用自回归训练方式,和大语言模型完全一样。它的损失函数是:
L(θ,B)=−∑b=1∣B∣∑l=1Lm(b,l)logpθ(sl(b)∣s1(b),...,sl−1(b))\mathcal{L}(\theta, \mathcal{B})=-\sum_{b=1}^{|\mathcal{B}|} \sum_{l=1}^{L} m(b, l) log p_{\theta}\left(s_{l}^{(b)} | s_{1}^{(b)}, ..., s_{l-1}^{(b)}\right)L(θ,B)=−b=1∑∣B∣l=1∑Lm(b,l)logpθ(sl(b)∣s1(b),...,sl−1(b))
公式解释:
- L\mathcal{L}L:总损失函数
- θ\thetaθ:模型的可训练参数
- B\mathcal{B}B:训练批次(batch)
- ∣B∣|\mathcal{B}|∣B∣:批次大小
- LLL:序列长度(Gato中固定为1024)
- m(b,l)m(b,l)m(b,l):掩码函数,1表示该位置是文本或动作,需要计算损失;0表示是观察值(如图像、传感器数据),不计算损失
- pθ(sl(b)∣s1(b),...,sl−1(b))p_{\theta}(s_l^{(b)} | s_1^{(b)}, ..., s_{l-1}^{(b)})pθ(sl(b)∣s1(b),...,sl−1(b)):模型在给定前l-1个token的情况下,预测第l个token的概率
通俗解释:这个损失函数就是让模型学会“根据前面的内容预测下一个内容”。但我们只让它学习预测文本和动作,不用预测输入的图像或传感器数据。就像你学英语时,只需要背单词和句子,不用背课本上的插图一样。
1.4 模型架构
Gato使用标准的解码器-only Transformer架构,和GPT系列完全一致。最大的版本有1.2B参数,具体超参数如下:
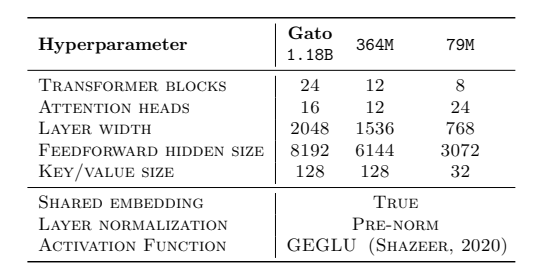
表1 Gato的Transformer超参数(来源:论文Table5)
为什么选择1.2B参数?
论文中明确说明,这个规模是为了能在真实机器人上实现20Hz的实时控制。如果模型太大,推理速度就会跟不上机器人的控制频率;如果太小,能力又不够。1.2B是一个很好的平衡点。
二、训练数据:604个任务的大杂烩
Gato的强大能力来自于它海量且多样化的训练数据。它在604个不同的任务上进行了训练,涵盖了以下几个大类:
- 模拟控制任务:包括Atari游戏、DM Control Suite、Meta-World、BabyAI等
- 真实机器人任务:RGB堆叠任务(真实和模拟)
- 视觉语言任务:图像字幕、视觉问答、文本对话等
- 纯文本任务:MassiveText数据集(网页、书籍、新闻、代码等)
不同数据集的采样权重如下:
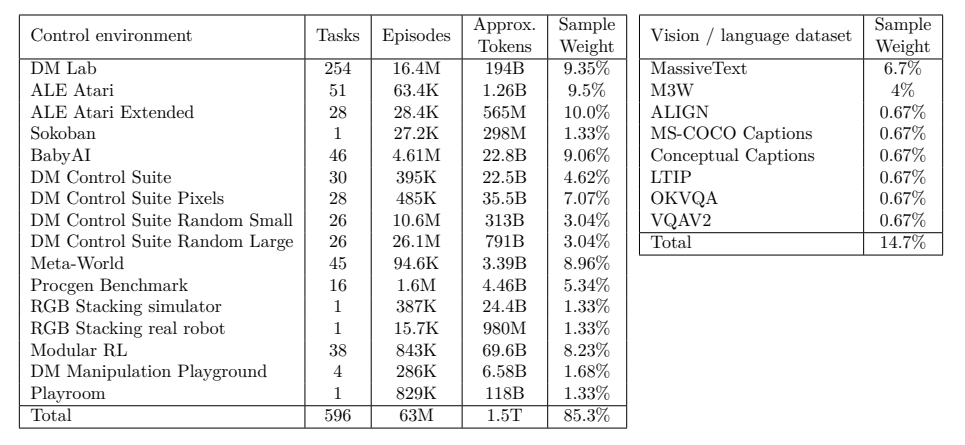
表2 视觉语言数据集的采样权重(来源:论文Table1)
有趣的细节:论文中提到,他们在训练时会过滤掉那些表现不好的episode,只保留专家水平80%以上的数据。这就像你学习时,只看学霸的笔记,不看学渣的作业一样。
三、惊人的实验结果:一个模型打天下
Gato的实验结果可以用“震撼”来形容。它用同一套权重,在数百个完全不同的任务上都取得了不错的表现。
3.1 模拟控制任务表现
Gato在超过450个模拟控制任务上达到了专家水平的50%以上:
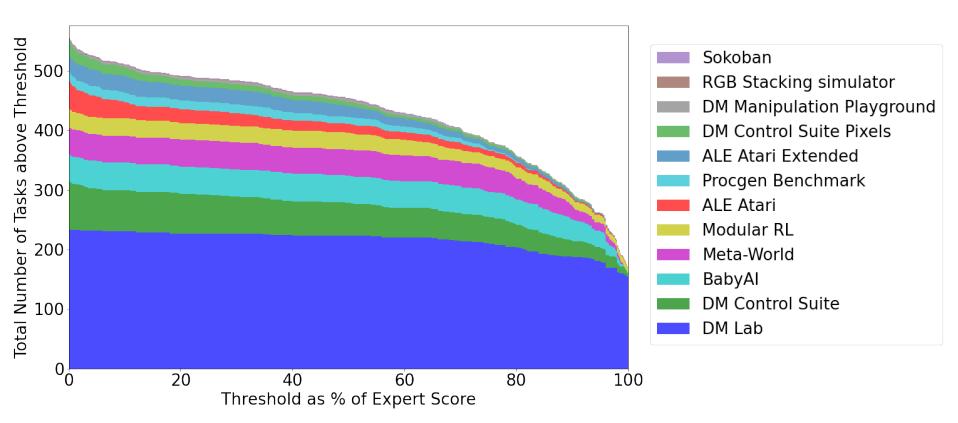
图2 Gato在模拟控制任务上的表现(来源:论文Figure5)
亮点:
- 在23个Atari游戏上达到了人类平均水平,在11个游戏上超过了人类两倍的分数
- 在BabyAI的几乎所有关卡上达到了专家水平的80%以上,最难的BossLevel也达到了75%
- 在Meta-World的45个任务中,44个达到了专家水平的50%以上,35个达到了80%以上
3.2 真实机器人任务:RGB堆叠
这是最令人印象深刻的实验之一。Gato被用来控制一个真实的Sawyer机器人手臂,完成堆叠不同形状积木的任务。
实验分为两个部分:
- Skill Generalization(技能泛化):训练时用的积木形状和测试时不同
- Skill Mastery(技能掌握):训练和测试用相同的积木形状
在Skill Generalization任务中,Gato的表现甚至超过了专门的BC-IMP基线:

表3 Gato在真实机器人RGB堆叠任务上的Skill Generalization表现(来源:论文Table2)
通俗解释:这意味着Gato学会了“堆叠”这个通用技能,而不是只会堆叠特定形状的积木。就像人类学会了搭积木后,不管是方形、圆形还是三角形的积木,都能搭起来一样。
3.3 文本与图像能力
Gato还展示了不错的文本和图像理解能力:
- 可以生成合理的图像字幕
- 可以进行简单的对话
- 可以回答视觉问题
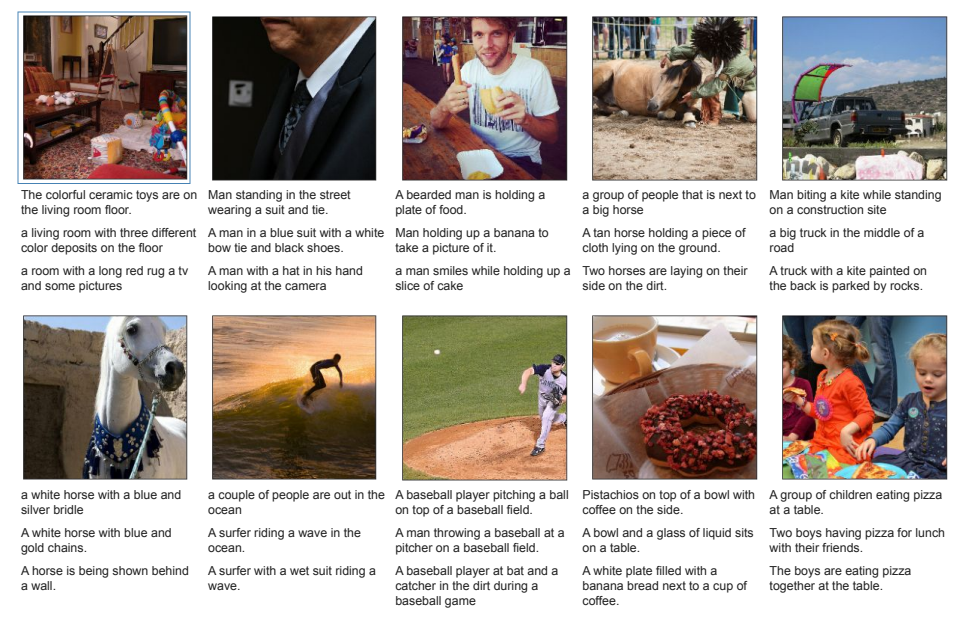
图3 Gato生成的图像字幕示例(来源:论文Figure6)
从图3可以看到,Gato生成的字幕虽然不是完美的,但基本都能准确描述图片的主要内容。
3.4 少样本泛化能力
Gato最强大的地方在于它的少样本泛化能力。它可以在只看到几个新任务的演示后,就学会完成这个新任务。
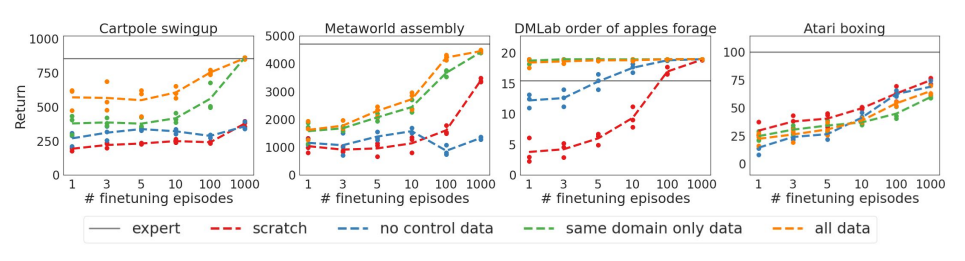
图4 Gato的少样本泛化能力(来源:论文Figure9)
从图4可以看到,在Cartpole Swingup、Assembly-v2等任务上,Gato只需要10-100个演示episode,就能达到接近专家的水平。这比从头训练一个模型要高效得多。
四、核心代码实现(简化版)
下面是一个极度简化的Gato实现,展示了它的核心思想:
import torch
import torch.nn as nn
from transformers import GPT2Model, GPT2Config
import numpy as np
class Gato(nn.Module):
"""
简化版Gato通用智能体
核心思想:用一个解码器-only Transformer处理所有模态的序列
"""
def __init__(
self,
num_tokens=33024, # 总token数:32000文本 + 1024连续值
embed_dim=2048, # 嵌入维度
num_layers=24, # Transformer层数
num_heads=16, # 注意力头数
patch_size=16 # 图像patch大小
):
super().__init__()
self.patch_size = patch_size
# 1. 配置GPT2模型(解码器-only Transformer)
config = GPT2Config(
vocab_size=num_tokens,
n_embd=embed_dim,
n_layer=num_layers,
n_head=num_heads,
activation_function="gelu_new",
n_positions=1024 # 上下文长度
)
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(embed_dim, num_tokens, bias=False)
# 2. 图像patch嵌入(简化版,用卷积代替论文中的ResNet块)
self.patch_embed = nn.Conv2d(
in_channels=3,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size
)
# 3. 位置编码
self.pos_embed = nn.Embedding(1024, embed_dim)
def tokenize_image(self, image):
"""
将图像转换为patch token序列
Args:
image: [batch, 3, H, W],归一化到[-1, 1]
Returns:
patches: [batch, num_patches, embed_dim]
"""
# 提取patch并嵌入
patches = self.patch_embed(image) # [batch, embed_dim, H/16, W/16]
# 展平为序列
patches = patches.flatten(2).transpose(1, 2) # [batch, num_patches, embed_dim]
return patches
def forward(self, tokens, attention_mask=None):
"""
前向传播
Args:
tokens: [batch, seq_len],已经token化的序列
attention_mask: [batch, seq_len],注意力掩码
Returns:
logits: [batch, seq_len, num_tokens],下一个token的预测logits
"""
batch_size, seq_len = tokens.shape
# 添加位置编码
positions = torch.arange(seq_len, device=tokens.device).unsqueeze(0).expand(batch_size, -1)
pos_emb = self.pos_embed(positions)
# 嵌入token并加上位置编码
token_emb = self.transformer.wte(tokens)
hidden_states = token_emb + pos_emb
# Transformer前向传播
outputs = self.transformer(
inputs_embeds=hidden_states,
attention_mask=attention_mask
)
# 预测下一个token
logits = self.lm_head(outputs.last_hidden_state)
return logits
# 测试代码
if __name__ == "__main__":
model = Gato()
# 测试文本输入
text_tokens = torch.randint(0, 32000, (1, 10))
logits = model(text_tokens)
print(f"文本输入输出形状: {logits.shape}") # 应该是 [1, 10, 33024]
# 测试图像输入(实际使用时需要先tokenize)
image = torch.randn(1, 3, 64, 64)
image_patches = model.tokenize_image(image)
print(f"图像patch形状: {image_patches.shape}") # 应该是 [1, 16, 2048]
代码说明:
- 这只是一个概念验证版本,实际的Gato还包含更复杂的多模态嵌入、位置编码和动作解码逻辑
- 核心思想就是用一个统一的Transformer处理所有模态的序列
- 图像被分成16×16的patch,每个patch被嵌入成一个向量,和文本token一起输入到Transformer中
五、局限性与未来展望
虽然Gato取得了令人瞩目的成就,但它仍然有很多局限性:
- 上下文长度有限:Gato的上下文长度只有1024个token,对于需要长序列记忆的任务(如长对话、复杂机器人任务)来说不够用
- 纯监督学习:Gato是纯监督学习训练的,没有使用强化学习。这意味着它只能模仿专家的行为,不能通过试错来改进
- 表现不如专门模型:在大多数任务上,Gato的表现都不如专门为该任务训练的模型
- 数据依赖严重:Gato的能力完全依赖于训练数据的质量和多样性。如果某个任务没有足够的高质量数据,它的表现就会很差
未来展望:
- 扩大模型规模和训练数据规模,进一步提升能力
- 引入强化学习,让Gato可以通过试错来学习
- 增加上下文长度,支持更长的序列
- 探索更好的多模态融合方法
六、总结
Gato是通用智能体发展史上的一个重要里程碑。它证明了用一个统一的序列模型处理所有模态、所有任务是完全可行的。
虽然Gato还不是真正的通用人工智能,但它向我们展示了一条清晰的道路:只要我们有足够多的多样化数据和足够大的模型,我们就可以训练出一个能完成各种任务的通用智能体。
就像论文中所说的:“Transformer序列模型作为多任务多载体策略是有效的,包括真实世界的文本、视觉和机器人任务。未来,这样的模型可以作为学习新行为的默认起点,而不是从头开始训练。”
这可能就是通用人工智能的未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)