10分钟搞定本地AI:Ollama 零成本接入你的OpenClaw
核心价值:手把手教你在自己的电脑上跑一个真正可用的AI模型,断网也能用、数据不上云、反应飞快
文章信息:
字数:约4200字 | 阅读:12分钟 | 难度:⭐(小白友好,无需技术基础)
核心价值:手把手教你在自己的电脑上跑一个真正可用的AI模型,断网也能用、数据不上云、反应飞快
还记得第一次用 ChatGPT / DeepSeek 的时候吗?
打字进去,等它转圈圈,然后一段话回来——挺酷的。
但问题也很明显:
你永远在别人的服务器上。
网断了,没了。
高峰期,排队。
聊到隐私话题,心里打鼓。
我当时就想:有没有AI是装在我自己电脑里的?不用联网,不用等,什么东西问它都行?
之前折腾过docker部署DeepSeek,但因下载的模型太小,真正运行起来并不理想,但是现在....
有的,兄弟,包的。而且已经非常简单了。
并且好用!
 把你电脑变成一个人工智能
把你电脑变成一个人工智能
我打个比方你就明白了。
你现在的电脑是一间毛坯房。
CPU是地基,内存是房间大小,硬盘是储物间。
装修需要请施工队(装软件)。
Ollama就是这个施工队。
它干一件事:
让你的电脑能跑AI模型。
装好了,你就像在毛坯房里铺了地板、刷了墙——可以住人了。
Qwen3(通义千问3)是通义家的开源模型,相当于你买的家具。
Ollama负责把家具搬进来摆好,你要做的就是选这套家具里的哪一件。
为什么是Qwen3不是ChatGPT?
因为它免费、不联网、数据不上云、还支持中文。
不是ChatGPT太贵,是Ollama+Qwen3你装一次就一辈子是自己的。
 第一步:选对设备(决定你的体验)
第一步:选对设备(决定你的体验)
Ollama不挑电脑,但不同配置决定了你选哪个模型。
如果你是Mac用户
关键看内存,不是CPU。
| 内存 | 推荐模型 | 体验 |
| 8GB | qwen3:4b(2.5GB) | 能用,轻度聊天 |
| 16GB | qwen3:8b(5.2GB) | ⭐ 推荐,完美跑 |
| 24GB | qwen3:14b(9.3GB) | 高质量,写作翻译很强 |
| 32GB+ | qwen3:32b(20GB) | 接近GPT的水平 |
一句话:16GB以上选qwen3:8b,24GB以上选qwen3:14b。别一上来冲最大模型,先跑通再升级。
MacBook Pro > MacBook Air。因为Air没有风扇,跑模型时间长了会发热降频。但短时间试用完全没问题。
如果你是Windows用户
关键看显存(VRAM),不是内存。
Windows和Mac最大的区别:Mac用的是共享内存(RAM),Windows用独立显存(VRAM)。
| 显卡 | 显存 | 推荐模型 |
| 无独显(纯CPU) | — | qwen3:0.6b(523MB,纯CPU可跑) |
| GTX 1650 / RTX 3050 | 4GB | qwen3:4b(2.5GB) |
| RTX 4060 / 4070 | 8GB | qwen3:8b(5.2GB)⭐ 甜点模型 |
| RTX 4080 / 4090 | 16GB+ | qwen3:14b(9.3GB)或qwen3:32b(20GB) |
纯CPU也能跑,9B模型约10个token/秒(大约一秒蹦几个字),慢但能用。
硬核知识(内行看的):
Mac用统一内存架构(UMA),CPU和GPU共用同一块RAM。
Windows用独立显存,模型必须完全或部分加载到VRAM里才能用GPU加速。
所以8GB显存的Windows显卡(RTX 4060/4070)约等于Mac的16GB内存。
qwen3:8b的量化版本(q4_K_M)占用约5.2GB硬盘+6GB VRAM,是8GB显卡的完美甜点。
第二步:安装Ollama(3分钟)
Mac安装
方法一:官网下载(推荐)
- 打开 https://ollama.com
- 点一下 Download,会自动下载Mac版安装包
- 打开 .dmg 安装包,把Ollama拖到Applications里
- 打开启动台,点一下Ollama——顶部状态栏会多一个小羊驼图标 ✅
不用跑终端、不用配路径、不用装依赖。双击就完了。
方法二:终端一行命令
适合喜欢用命令行的朋友:
Windows安装
方法一:下载安装包(推荐新手)
- 打开 https://ollama.com/download
- 下载 OllamaSetup.exe
- 双击运行,一路默认
- 安装完后,系统托盘会出现Ollama的羊驼图标 ✅
Windows版本无需管理员权限,默认装在用户目录下。如果C盘空间紧张,安装时可以指定路径。
方法二:一行命令安装
打开PowerShell(右键开始菜单 → Windows PowerShell),粘贴:
irm https://ollama.com/install.ps1 | iex如果提示执行策略被阻止,用这个:
powershell -ExecutionPolicy Bypass -Command "irm https://ollama.com/install.ps1 | iex"Windows用户注意:如果装了360/腾讯电脑管家,安装时可能会弹窗拦截。允许通过就行。
第三步:下载并运行你的第一个AI模型(2分钟)
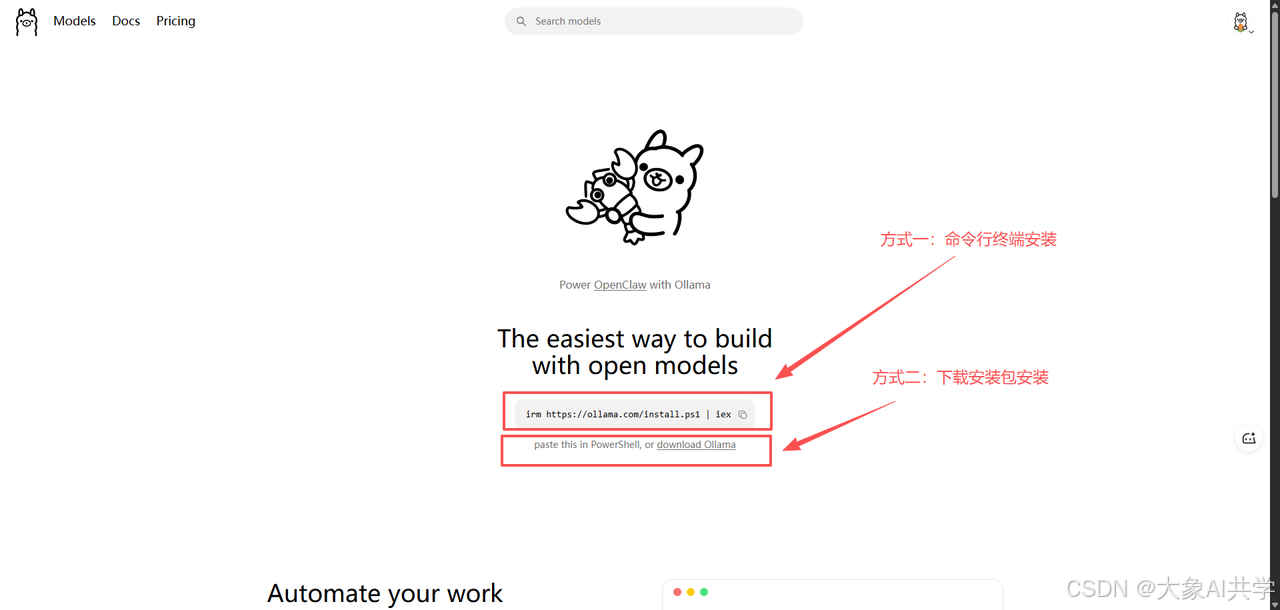
不管Mac还是Windows,安装好后打开终端(Mac用终端.app,Windows用PowerShell),输入:
ollama run qwen3:8b第一次运行它会自动下载模型(约5.2GB),取决于你的网速,等几分钟就好。
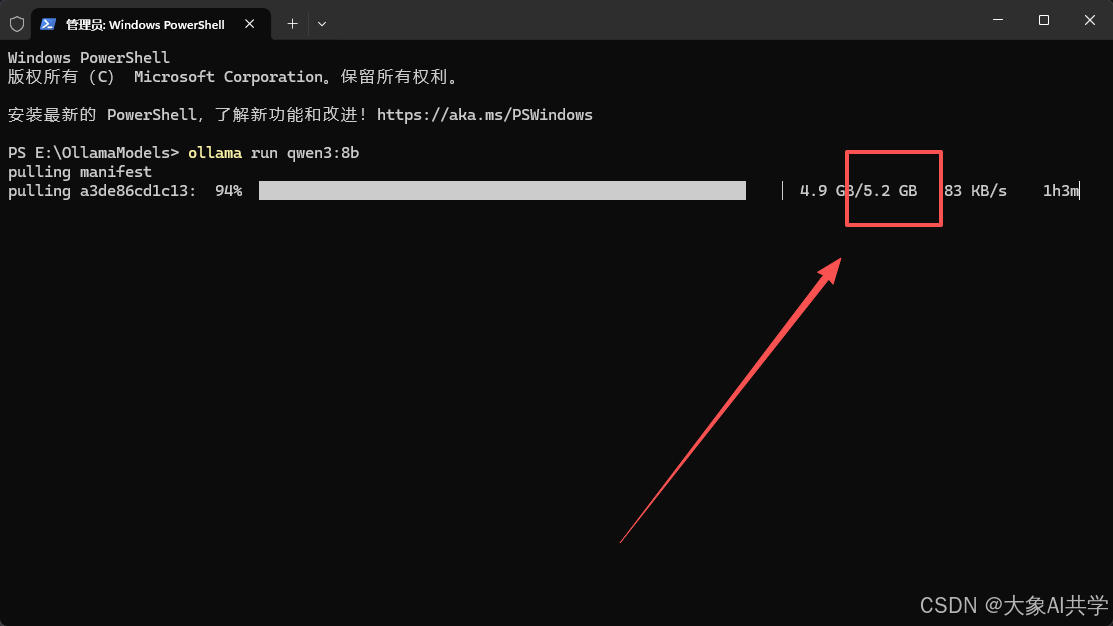 下载完你就看到这个:
下载完你就看到这个:
>>> Send a message (/? for help)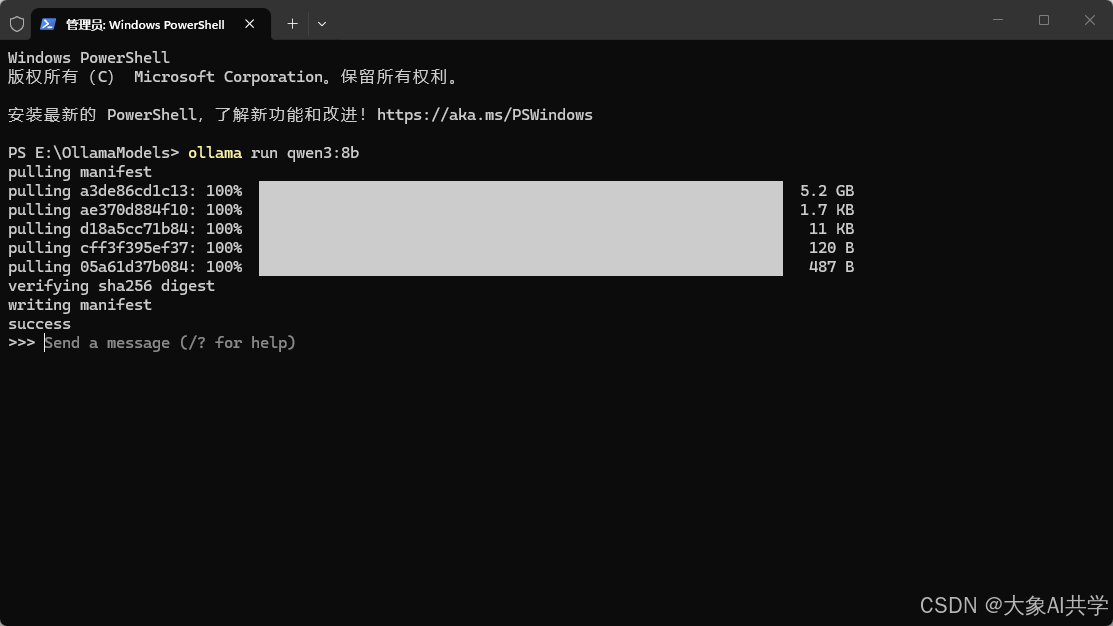 恭喜,你的电脑已经成了一个AI。 🎉
恭喜,你的电脑已经成了一个AI。 🎉
试着跟它聊两句:
>>> 用一句话解释为什么程序员喜欢半夜写代码?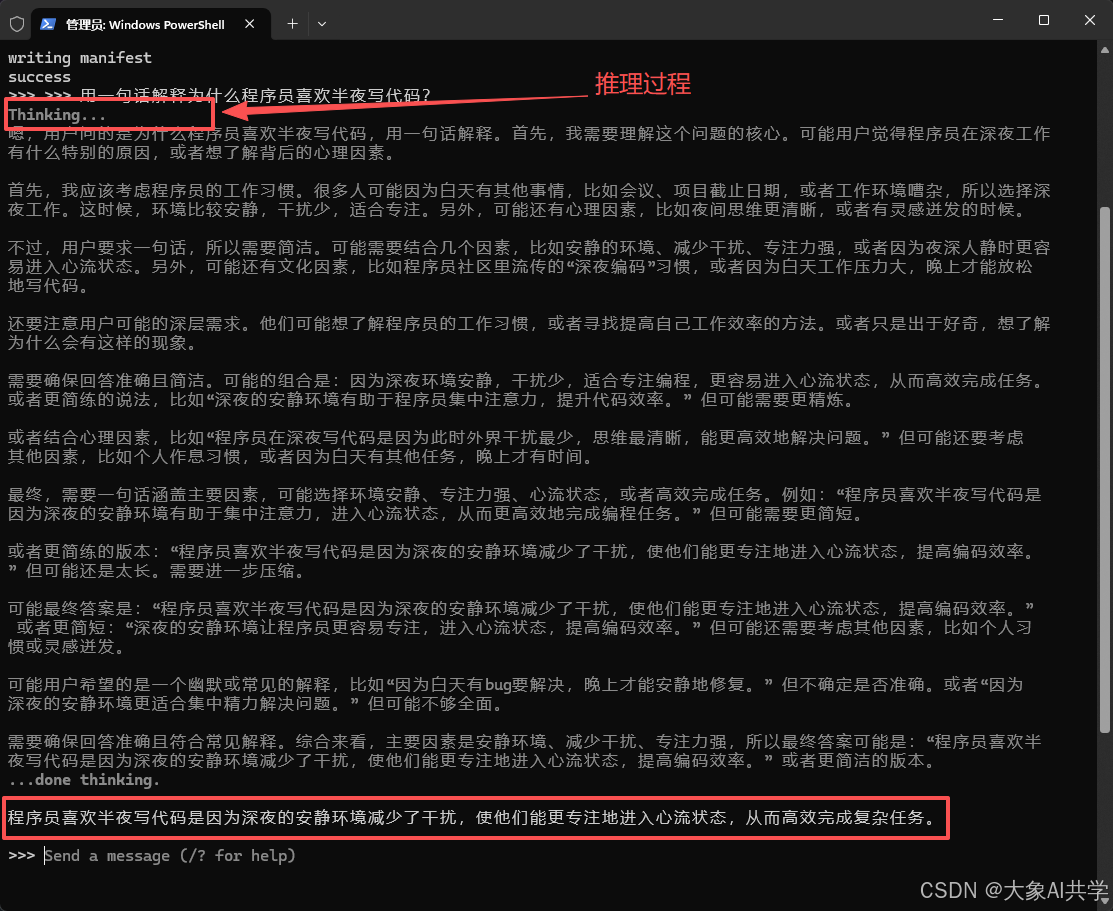 它会回答你。实时生成,逐字出现,没有加载转圈,没有任何「服务器繁忙」。
它会回答你。实时生成,逐字出现,没有加载转圈,没有任何「服务器繁忙」。
>>> /exit退出用 /exit 或 Ctrl+D。
下次再聊,输入同样的命令,
模型还在——不用重新下载。
第四步:给AI装个图形界面(3分钟)
终端聊天虽然很硬核,但确实不太方便。推荐装一个图形界面。
Open WebUI(推荐,功能最全)
Docker安装:
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main然后浏览器打开 http://localhost:3000,注册一个账号(存在本地),就能看到和ChatGPT一样的界面了。
Python安装(不用Docker):
pip install open-webui
open-webui serve浏览器打开 http://localhost:8080。
其他桌面客户端
不想折腾Docker的,这几个直接用:
| 工具 | 平台 | 一句话 |
| Chatbox | Win/Mac/Linux | 最好用的AI桌面客户端,支持Ollama |
| Cherry Studio | Win/Mac | 中国人的ChatGPT桌面版 |
| AnythingLLM | Win/Mac/Linux | 带知识库的AI应用 |
| Msty | Win/Mac | 极简多模型客户端 |
去各自官网下载安装,配置里填Ollama的API地址 http://localhost:11434 就行。
还有ollama原生的 Chat -UI
 模型怎么选?一张表说清楚
模型怎么选?一张表说清楚
推荐组合(按配置)
| 你的配置 | 首选模型 | 理由 |
| Mac 16GB / Win 8GB显存 | qwen3:8b | 完美适配,中文好,支持工具调用 |
| Mac 24GB / Win 16GB显存 | qwen3:14b | 高质量,写代码写文章都强 |
| Mac 32GB / Win 24GB显存 | qwen3:32b | 接近云服务水平 |
| 纯CPU低配 | qwen3:4b | 轻量级,基本够用 |
| 想要推理能力 | deepseek-r1:8b | 推理模型,逻辑分析强 |
模型管理命令
ollama list # 看我下载了哪些模型
ollama pull qwen3:8b # 手动下载一个模型
ollama run qwen3:8b # 运行一个模型
ollama ps # 看当前加载了哪些模型
ollama rm qwen3:8b # 删除一个模型
ollama stop qwen3:8b # 卸载模型释放内存国内模型全家桶
Ollama支持的通义系、DeepSeek、智谱GLM都在这里:
| 模型 | 大小范围 | 擅长 |
| Qwen3 | 0.6B-235B | 全面,中文好,推荐入门 |
| DeepSeek-R1 | 1.5B-671B | 推理能力强 |
| GLM-4/5 | 9B | 中文能力突出 |
| MiniMax-M2 | - | 编码和Agent工作流 |
五个技巧:
技巧1: "从 qwen3:8b 开始" "完美适配大多数配置"
技巧2: "显存不够?" "试试 qwen3:4b 或 0.6b"
技巧3: "需要推理?" "切换到 deepseek-r1:8b"
技巧4: "定期清理" "用 ollama rm 删除不用的模型"
技巧5: "内存不够?" "用 ollama stop 释放内存"
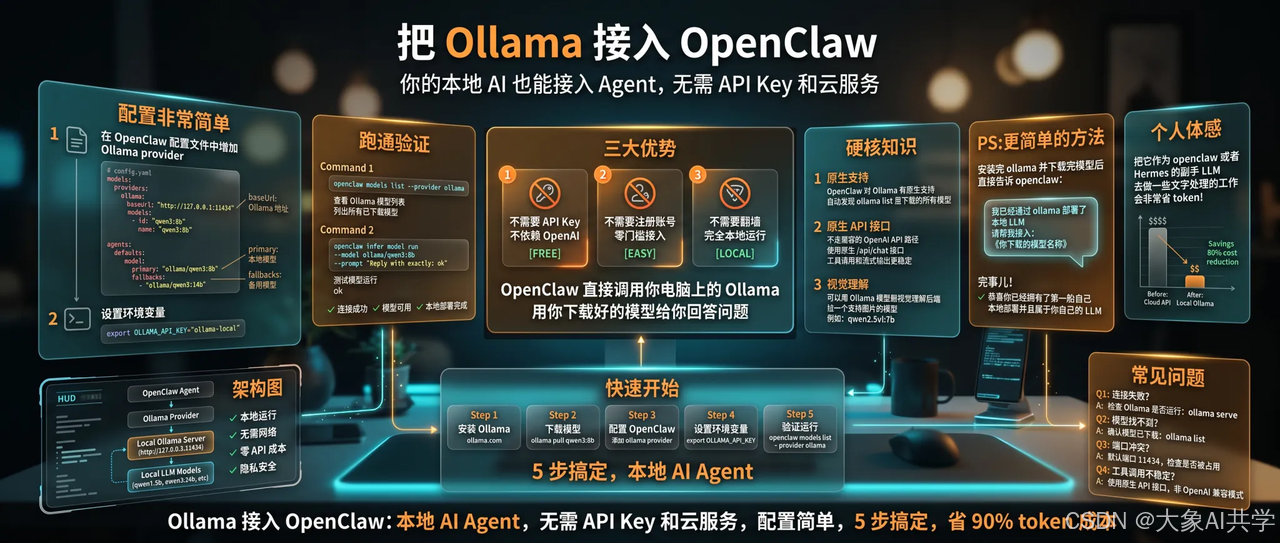 把Ollama接入OpenClaw:你的本地AI也能接入Agent
把Ollama接入OpenClaw:你的本地AI也能接入Agent
很多朋友把openclaw部署在云上,但如果你在本地用自己的OpenClaw搭AI助手,
Ollama可以作为模型后端直接接入——不需要任何其他的付费 API Key,不依赖云服务。
配置非常简单。
在OpenClaw的配置文件中,增加一个Ollama provider:
# config.yaml
models:
providers:
ollama:
baseUrl: "http://127.0.0.1:11434" # 你的Ollama地址
models:
- id: "qwen3:8b"
name: "qwen3:8b"
agents:
defaults:
model:
primary: "ollama/qwen3:8b" # 用本地模型
fallbacks:
- "ollama/qwen3:14b"
然后设置环境变量让OpenClaw知道用Ollama:
export OLLAMA_API_KEY="ollama-local"跑通验证:
openclaw models list --provider ollama
openclaw infer model run --model ollama/qwen3:8b --prompt "Reply with exactly: ok"不需要API Key、不需要注册账号、不需要翻墙——OpenClaw直接调用你电脑上的Ollama,用你下载好的模型给你回答问题。
硬核知识:
OpenClaw对Ollama有原生支持,自动发现你ollama list里下载的所有模型。
Ollama provider不走兼容的OpenAI API路径(/v1/chat/completions),而是使用原生/api/chat接口,工具调用和流式输出更稳定。
你甚至可以用Ollama模型做OpenClaw的视觉理解后端,只要拉一个支持图片的模型(比如qwen2.5vl:7b)就行。
PS:更简单的方法,你安装完ollama并下载完模型后,直接告诉openclaw:
我已经通过ollama部署了本地LLM,请帮我接入:
--
《你下载的模型名称》
--完事儿!恭喜你已经拥有了第一胎自己本地部署并且属于你自己的 LLM。
个人体感把它作为openclaw或者Hermes的副手LLM,去做一些文字处理的工作,会非常省token!
常见问题(踩坑记录)
Mac用户
发热正常吗?正常。Mac跑模型风扇会转起来,看活动监视器里的「内存压力」——绿色就安全。如果长期黄色或红色,说明模型选大了。
选MacBook Pro还是Air?长期跑模型选Pro。Air没风扇,模型跑久了会过热降频。偶尔玩一下Air没问题。
Windows用户
安装时提示执行策略被阻止?PowerShell默认限制执行远程脚本。用这个绕过:
powershell -ExecutionPolicy Bypass -Command "irm https://ollama.com/install.ps1 | iex"防火墙弹窗怎么办?
本地用localhost:11434一般不触发防火墙。
如果你设了OLLAMA_HOST=0.0.0.0(允许局域网访问),Windows Defender会弹窗——允许通过就行。
装好后怎么改模型下载路径?
默认下载到 C:\Users\你的用户名\.ollama。
想改到D盘:
- 打开系统环境变量
- 新增变量 OLLAMA_MODELS,值设 D:\ollama_models
- 保存后重启Ollama(托盘右键退出 → 重新启动)
命令行显示方块乱码?
Windows 10旧终端字体会把Ollama的进度图标显示成方块。
把终端字体改成 Cascadia Code 或 Consolas 就好。
通用问题
下载模型太慢?国内网络环境下下载5GB左右的文件可能要等一会儿。建议:
- 换个时间段试试(凌晨快一些)
- 先跑个小的(qwen3:0.6b只有523MB)
- 如果一直下载失败,可以用镜像站手动下载后放到 ~/.ollama/models/blobs/ 目录
Ollama和ChatGPT有什么区别?
| 本地AI(Ollama+Qwen3) | ChatGPT | |
| 费用 | 免费 | 免费版有额度,Pro版$20/月 |
| 联网 | 不需要 | 必须联网 |
| 隐私 | 数据在本地,不上云 | 提问会上传OpenAI服务器 |
| 速度 | 实时(没有排队) | 高峰期排队 |
| 能力 | 够用(写作/翻译/编码/答疑) | 更强(联网搜索/多模态/插件) |
所以不是本地AI比ChatGPT强,是本地AI是你的——不依赖任何人。
写在最后
做这件事其实起因特别简单——我一直觉得「AI应该装在自己电脑里」是一件理所当然的事。
但大部分人以为它很难。以为要懂编程。以为要有服务器。以为要花很多钱。
其实不需要。
你想写公众号文章的时候,可以让它帮你理思路。你想翻译一段英文的时候,不需要打开网页。你加班到半夜想找人说话,它就在那里,随叫随到。
本地AI的意义不是取代ChatGPT,是让你在任何时候都有一个AI队友。
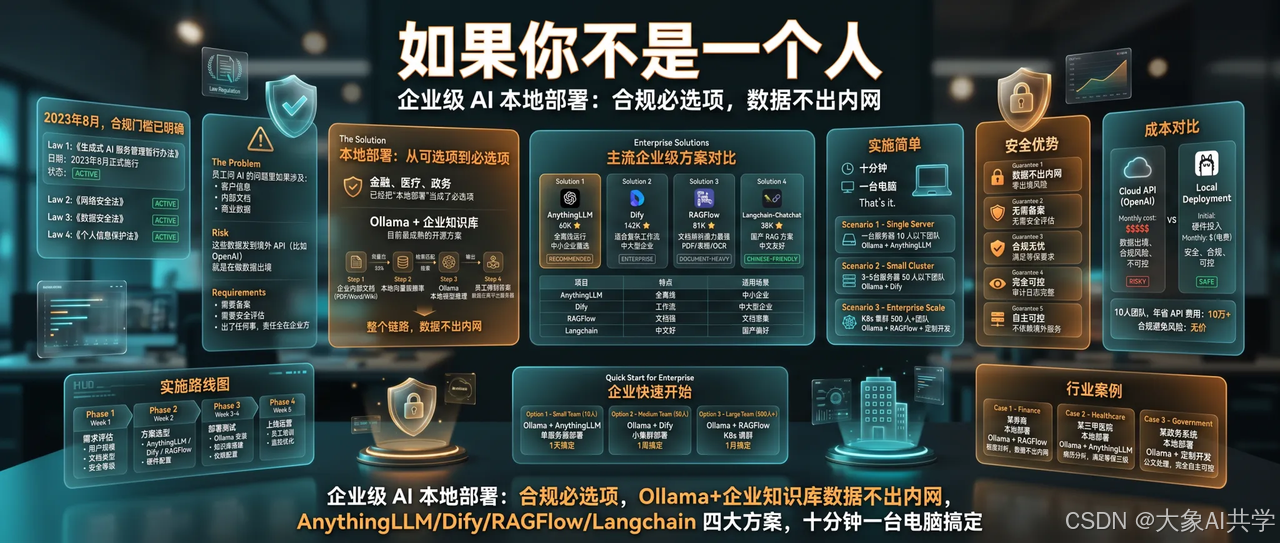 但如果你不是一个人用,而是在一家企业
但如果你不是一个人用,而是在一家企业
事情就不只是「方便」这么简单了。
2023年8月,《生成式AI服务管理暂行办法》正式施行。
加上《网络安全法》《数据安全法》《个人信息保护法》,企业使用AI的合规门槛已经非常明确:
员工问AI的问题里如果涉及客户信息、内部文档、商业数据,这些数据发到境外API(比如OpenAI),就是在做数据出境。
需要备案。需要安全评估。
出了任何事,责任全在企业方。
所以金融、医疗、政务这些行业,已经把「本地部署」当成了必选项,不是可选项。
Ollama + 企业知识库,是目前最成熟的开源方案。
核心思路很简单:
企业内部文档(PDF/Word/Wiki)
↓ 向量化
本地向量数据库
↓ 检索匹配
Ollama本地模型推理
↓
员工得到答案(数据没离开过服务器)整个链路,数据不出内网。
目前主流的方案里,几个值得关注的:
| 项目 | ⭐ | 一句话 |
| AnythingLLM | 60K | 全离线运行,中小企业首选 |
| Dify | 142K | 适合复杂工作流的中大型企业 |
| RAGFlow | 81K | 文档解析能力最强(PDF/表格/OCR) |
| Langchain-Chatchat | 38K | 国产RAG方案,中文友好 |
而你需要的,就是十分钟和一台电脑。
#Ollama #Qwen3 #本地AI #大模型部署 #AI教程
🪪 作者:大象 — 推动让普通人轻松上手AI
相关阅读:
https://wcnoxi4wqsvx.feishu.cn/wiki/Rg5ZwOEz0idCiCkuECNcRJi5n7b https://wcnoxi4wqsvx.feishu.cn/wiki/BrHOwhYSWiMkQTkZaQbcQRwYn0g
https://wcnoxi4wqsvx.feishu.cn/wiki/Lol3wF5QwiWeJUkGukqcWkMinWh

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)