国产 AI Infra 规模化落地实践:软硬协同与极致加速
同时,LoongForge 内置 20 + 标准化组件,新模型仅需通过 YAML 极简配置,即可快速接入上线,直接把原本要数周的适配周期,压缩到几天,高效解决了全模态模型在国产算力上的训练适配难题。我们的目标就是要把百度深耕多年的 AI 基础设施能力,真正开放给每一家企业,让国产算力用得起、用得稳、用得好,让更多企业轻松搭上 AI 发展的快车道,实现效率提升、业务升级、高质量增长。一旦发生异常,系
本文整理自 2026 年 5 月 14 日 Create2026 百度 AI 开发者大会 - AI Infra 专题论坛,百度智能云混合云部总经理杜海的同名主题演讲。
当前,AI 技术正在高速迭代,而算力作为核心支撑,也迎来了关键发展阶段。在这一背景下,国产算力的规模化落地,已经不再是简单的技术问题,更是一个关乎产业未来的战略议题。
我非常荣幸能在这样一个时间点,跟大家分享百度智能云在国产算力规模化落地方面的实践和探索,通过软硬协同和极致的优化,让国产算力真正成为千行百业的生产力。也希望和大家一起,为国产算力的发展贡献力量。

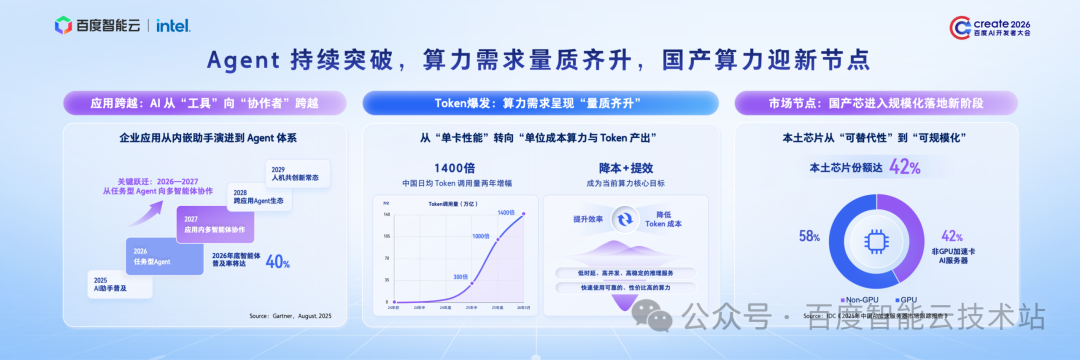
当前,人工智能正迎来一次质的跨越—— 它不再只是被动响应的「工具」,正加速进化为主动参与、深度协同的「业务伙伴」。
按 Gartner 的预测,到 2026 年底,40% 的企业级应用都将集成智能体。从单一任务型 Agent 到多 Agent 协同作业,AI 正在快速融入各行业的核心业务。
这一深刻变革,直接推动 Token 用量迎来指数级爆发。根据国家数据局发布的数据,从 2024 年初到 2026 年 3 月,短短两年时间,我国日均 Token 调用量增长超过了 1400 倍。
这反应在算力的市场需求上,呈现出了「量质齐升」的态势:不仅要「更多」的算力,还要「更快、更稳、更省」,高性价比的算力成为客户的核心诉求。
与此同时,国产算力也迎来了关键节点。2025 年,本土 AI 芯片的市场份额达到了 42%,这标志着国产芯具备了「可替代性」与「可规模化」的双重能力。
在这一历史性时期,作为 AI 基础设施提供者,我们面临的的核心命题也很明确:如何让企业快速用上更可靠、性价比更高的算力;以及如何基于国产算力,提供低成本、高稳定、低时延的推理服务。
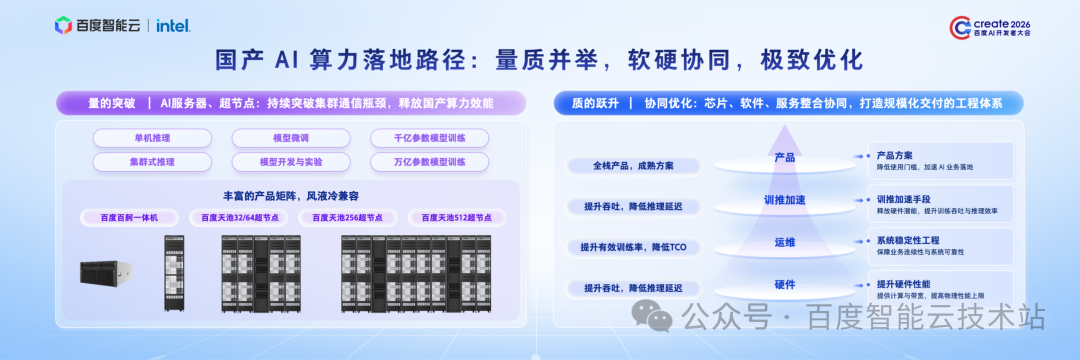
我们认为,国产算力的规模化落地,必须践行「量质并举、软硬协同、极致优化」 的系统化路径。
首先,要在算力底座上实现「量」的突破,拓展算力硬件的性能边界。
通过超节点高速互联技术,打破通信瓶颈,把成百上千颗芯片融合为统一的算力资源池,在有限空间内聚合更高的算力,从而支持集群规模跨越式增长。
百度智能云在这方面也一直在积极探索,已经构建了丰富的超节点产品矩阵,可以支撑从单机推理到万亿参数模型训练的全业务场景。
在夯实算力规模的基础上,更要通过软硬协同优化,来实现算力「质」的跃升。
这不仅指技术层面的软硬件协同,还包括稳定性工程、产品方案等多维度的能力建设。
-
在硬件层面:坚持深度适配、深度调优,打造性能更强、运行更稳的算力底座;
-
在运维层面:通过全栈可观测、故障自愈合,保障算力集群长期稳定、高效运行;
-
在训推层面:持续优化算子、框架与通信机制,全面提升算力利用效率;
-
在产品层面:以标准化、开箱即用的产品方案,大幅降低企业使用门槛,支撑规模化快速交付。
只有把硬件、软件、服务、产品真正打通、深度协同,我们才能具备大规模算力交付与规模化落地的核心能力。
接下来,我们具体看下这些方向上取得的最新进展。
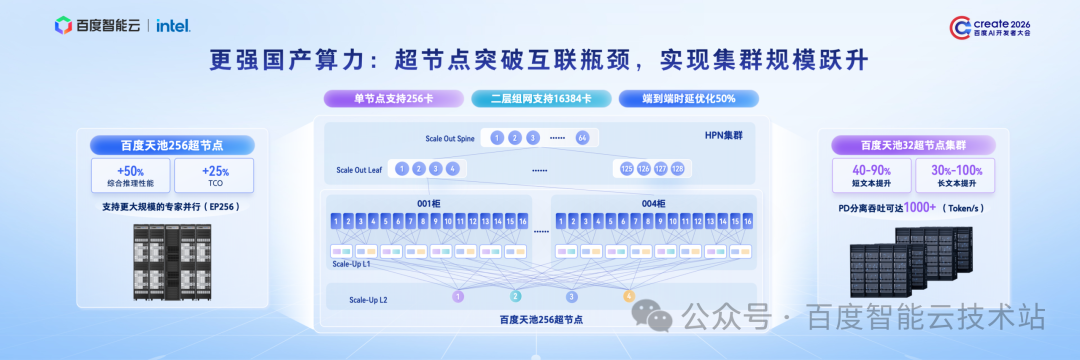
首先,在硬件算力底座上,我们持续迭代更高性能的超节点产品,全力支撑大规模 AI 集群建设。
今年 6 月,百度天池 2.0 超节点将正式上线,核心能力迎来全面升级:
-
单节点支持 256 卡高速互联;
-
基于 XPU Link 协议,卡间互联带宽提升 4 倍,端到端时延降低 50%;
-
在二层 HPN 组网下,可实现最大 16,384 卡规模化高速互联,为下一代超大规模集群筑牢坚实底座。
目前,我们已落地的超节点系列产品,已在金融、制造等行业客户的核心生产场景中稳定运行,尤其在长文本推理场景表现突出。
针对万亿参数大模型,我们也做了深度专项优化:
-
Prefill 阶段:采用更大规模的 TP+SP 并行策略,有效降低 TTFT 时延,大幅提升上下文长度上限;
-
Decode 阶段:依托 Scale-Up 高速互联能力,支持更大规模 EP 专家并行,显著降低单卡权重显存占用,释放更多 KV Cache 资源,进一步提升上下文长度与并发处理能力。
实测数据充分验证了它的实力:
-
在长文本推理场景下,天池超节点性能提升 30%—100%;
-
在 1P3D 的 PD 分离测试中,单卡吞吐突破 1000 Token/s,高效支撑客户业务高速增长。
超节点让我们实现了「量」的突破 ,而更关键的一步,是让海量算力真正释放价值,实现「质」的飞跃 。
当算力集群不断扩大,如果通信、调度等核心瓶颈无法打通,再大的规模也只是「虚胖」,难以发挥真正效能。
因此,全栈协同优化,成为我们破题的关键。这其中,既要从架构上大处着眼,也要在技术细节上小处着手,去精雕细琢。
为了让国产算力既可用、又好用,我们重点从生态适配和性能优化两大方向发力。
首先是生态适配。
我们基于业界主流的 vLLM 开源框架,推出了 vLLM-kunlun 项目。通过硬件抽象层统一设计,实现对昆仑芯的快速适配,大幅降低开发者的迁移与接入门槛。
到目前,我们已经完成了 50 多个主流大模型的适配,包括 DeepSeek、GLM、Kimi 等模型;同时,我们开源了算子库和工具链,与主流标准兼容,让开发者可以更便捷的使用。
其次是性能优化。
为了充分释放国产芯片的全部潜能,我们打造了端到端全链路优化体系:
一方面我们深度适配芯片核心加速特性,对前缀缓存、多词元预测、分块预填充等关键技术实现全面落地,配合自研的高性能昆仑算子库,让推理吞吐达到同代主流加速卡 80% 以上,部分场景甚至实现超越领先。
另一方面,面向万亿参数大模型的高效部署,我们构建了一套完整的端到端量化推理体系:
-
在模型层,通过自研量化工具链,集成前沿算法,做到高精度、高效率;
-
在框架层,凭借自研自适应推理能力,全面支持 INT8/INT4 量化模型,覆盖 Dense、MoE 全类型模型;
-
在硬件层,我们基于 XPU 架构,开发了专用的高性能量化算子,为量化推理提供底层支撑。
通过这一系列深度优化,我们最终实现:显存占用降至原来的 1/4,平均吞吐提升 1.5 倍,推理成本大幅下降,让国产算力在真实业务中更具竞争力、更具性价比。

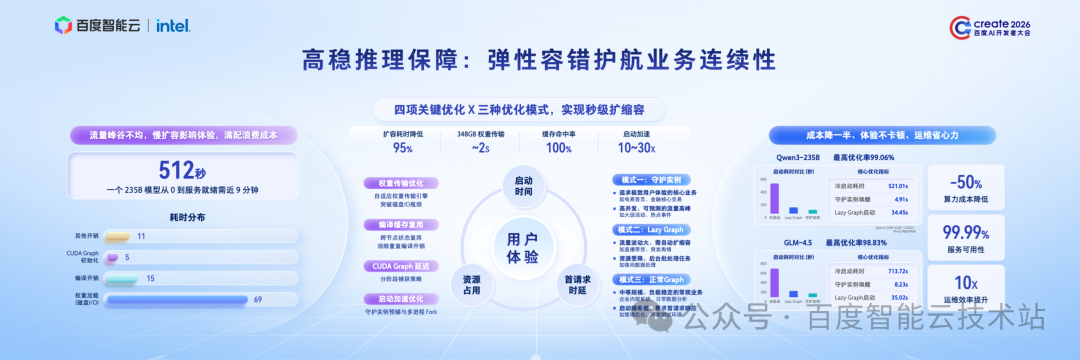
在生产环境中,推理服务不仅要快,更要稳,这直接决定用户体验,更关乎业务的连续与可靠。尤其在大规模集群下,流量突增、服务波动等挑战,随时可能影响系统稳定。
为此,我们构建了推理服务弹性扩缩容体系,通过全栈系统工程优化,为业务稳定运行保驾护航。
我们重点打造了自适应权重传输引擎,全面替代传统磁盘加载模式;同时最大化复用模型编译缓存,结合 Lazy CUDA Graph、守护实例预铺等核心技术,实现了千亿参数模型冷启动的跨越式优化:做到了启动时间从 8.5 分钟大幅缩短至 4.9 秒,优化幅度高达 99%,真正做到秒级扩容。既能从容应对突发流量洪峰,也能快速完成故障自动恢复。
同时,为适配多样化业务场景,我们还提供三大应用模式,分别面向快速恢复、资源受限、极速响应三大核心场景,客户可根据自身业务需求,灵活选择、最优匹配。
依靠这一系列关键技术优化,搭配三大灵活应用模式,我们真正实现了业务连续性与成本效益的双赢。最终达成成本减半、体验流畅、运维极简的目标,让企业用得放心、跑得安心。
前面,我重点分享了我们在推理侧的深度优化。接下来,让我们把目光转向训练侧。
当前,大模型正全面迈向全模态时代。据行业预测,到 2026 年,新发布模型中全模态占比将突破 50%。
但在实际落地中,国产算力在适配传统训练框架时,普遍面临三大行业痛点:
-
工程适配复杂,周期动辄数周,效率极低;
-
多模态训练损耗大,不同模态、不同规模模型训练时,性能损失明显;
-
跨平台迁移成本高,受芯片架构差异影响,迁移难度大、代价高。
针对这些行业难题,我们推出并开源了 LoongForge 全模态训练框架。
这套框架实现了一套代码、跨平台通用,只需简单切换环境变量,即可在 GPU 与昆仑芯 XPU 之间无缝迁移、无感切换;
在系统层面,我们对基座模型、多模态组件进行深度架构调优,并配合高效混合精度训练,让多模态训练效率达到业界领先水平;
同时,LoongForge 内置 20 + 标准化组件,新模型仅需通过 YAML 极简配置,即可快速接入上线,直接把原本要数周的适配周期,压缩到几天,高效解决了全模态模型在国产算力上的训练适配难题。

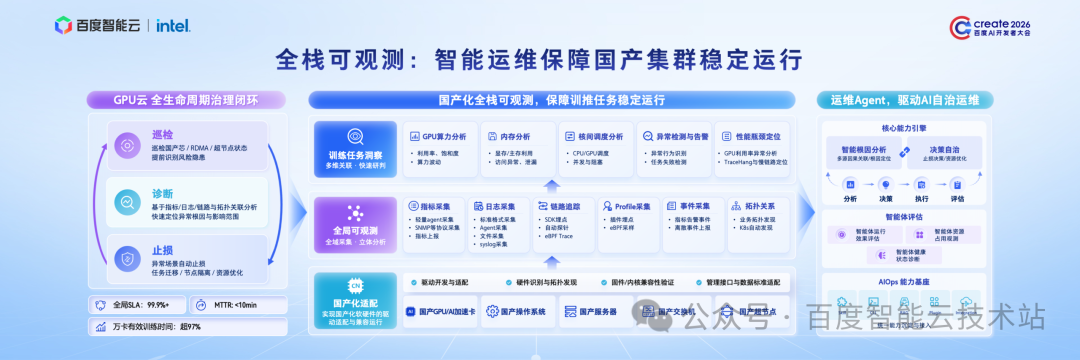
在国产集群的运维治理上,我们构建了「巡检 — 诊断 — 止损」的全生命周期闭环体系,真正做到万卡集群、稳定可靠。
我们会对芯片、超节点等核心基础设施进行常态化巡检,提前发现潜在风险。一旦发生异常,系统会结合可观测数据,快速定位根因,并自动执行任务迁移、节点隔离等智能止损操作,确保业务不受影响。
通过这套闭环管理方法,我们的万卡集群有效训练时间超过 97%,故障恢复时间 MTTR 小于 10 分钟。
而这套闭环的管理的运转,依赖于我们统一的数据底座 ,也就是全栈可观测体系。
我们适配了硬件的驱动接口、监控协议、数据标准,实现了对算网络、节点与任务的统一观测;针对训推核心场景,重点构建了指标、日志、链路等多维数据的互联分析能力,真正做到从应用到基础设施的全链路透明可视,为智能运维提供坚实的数据基础。
基于全栈可观测体系,我们进一步打造出智能运维 Agent。以 AIOps 为底座,实现异常智能检测、根因自动分析、决策自主执行;再结合运维知识库与能力插件,完成自动化诊断、自动化处置,实现分钟级定位、自动化止损,大幅缩短故障时间、降低运维成本。
同时,我们还建立了完善的智能体评估体系,推动整个运维体系从被动响应,走向主动预判、智能自治、无人化运维的新阶段。
俗话说「实战见真章」。前面我们分享了大量技术优化与协同方案,它们在真实的大规模生产环境中,究竟表现如何?
接下来,我用一场真实的万卡级训练实践,带大家看一下结果。
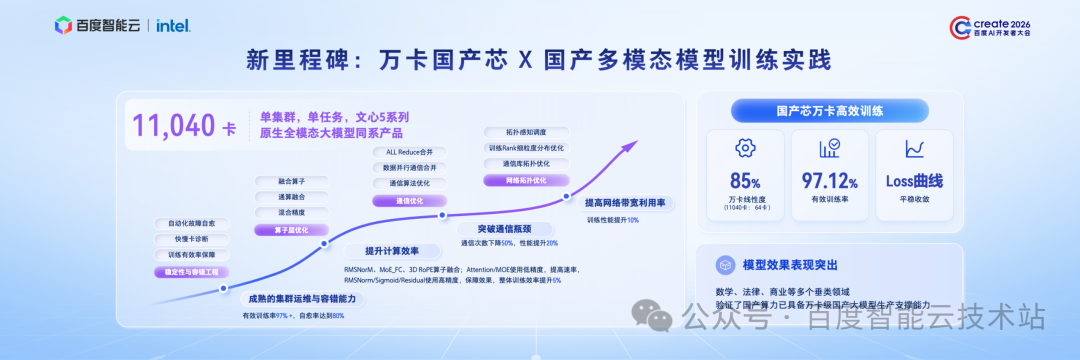
就在不久前,我们基于 11,040 颗昆仑芯,在单体万卡级国产算力集群上,以单任务训练模式,成功产出文心 5 系列原生全模态大模型的同系 MoE 模型,真正做到了全栈协同。
在整个训练过程中,我们从四大维度实现深度协同优化:
-
第一是稳定性与容错优化。我们通过自动化故障自愈、训练任务容错等手段,很好地保障了集群的稳定运行,实现了 97%以上的有效训练率,以及 80% 的故障自愈率。
-
第二是计算深度优化 。我们针对昆仑芯 XPU 硬件特点,通过算子融合和通算融合,大幅减少访存与内核开销;同时采用高精度混合精度训练,平衡效率与稳定性,整体训练效率再提升 5%,算力利用率达到极致。
-
第三是通信关键优化。在万卡规模训练中,通信占比超过 40%,是最大瓶颈之一。我们通过 All-Reduce 合并、数据并行通信合并等一系列关键手段,让通信次数下降 50%,显著降低算子启动开销,整体性能提升近 20%。
-
最后是网络拓扑优化。我们采用 TOR 拓扑感知调度、细粒度 Rank 布局优化,让高频通信尽可能「就近传输」,缩短路径、减少拥塞。优化后,训练性能再提升 10%,长距离网络风险大幅降低。
经过这一系列系统化优化,最终成果十分亮眼:万卡级训练线性度高达 85% ,这是基于11,040 卡与 64 卡基线的真实对比数据;有效训练率达到 97.12%。训练中的 Loss 曲线也实现了全程的平稳收敛。
这充分证明了我们的全栈优化方案,在真实大规模生产环境中的有效性。
最终训练出的模型,在数学、法律、商业等多个专业领域表现优异、达到业界一流水平。
这场万卡实战充分验证:国产算力,已经真正具备万卡级大模型原生生产能力!
我们可以自信的说:国产万卡集群,不仅能训练大模型,而且能训得稳、训得快、训出顶流效果。
正是在长期大规模落地实践中,我们不断打磨、沉淀了一整套成熟、可靠、可复用的技术能力。
今天,我们把这些核心能力全面整合,正式推出一款全新核心品 :百度百舸 AI Stack 轻量 GPU 云。我们将复杂的底层技术全部深度封装、极致简化,让企业不再需要投入巨大研发成本,就能以更低门槛、更低成本,轻松用好国产算力。
百度百舸 AI Stack 轻量 GPU 云,是一套轻量化、企业级 AI 算力基础设施,可随业务增长平滑扩展、按需扩容。
它具备三大核心优势:
-
极简部署,快速起步:最低只需 3 个节点,即可快速搭建专属 AI 算力底座;
-
训推一体,全域通用:同时支持大模型训练与高性能推理,一套平台满足全流程需求;
-
深度适配,统一调度:原生兼容昆仑芯等主流国产芯片,实现多芯统一调度、全栈性能优化,让每一分算力都发挥最大价值。
我们的目标就是要把百度深耕多年的 AI 基础设施能力,真正开放给每一家企业,让国产算力用得起、用得稳、用得好,让更多企业轻松搭上 AI 发展的快车道,实现效率提升、业务升级、高质量增长。

百度智能云一直在国产算力规模化落地方面持续探索,在不断的投入和实践中,我们的能力也在持续迭代升级:
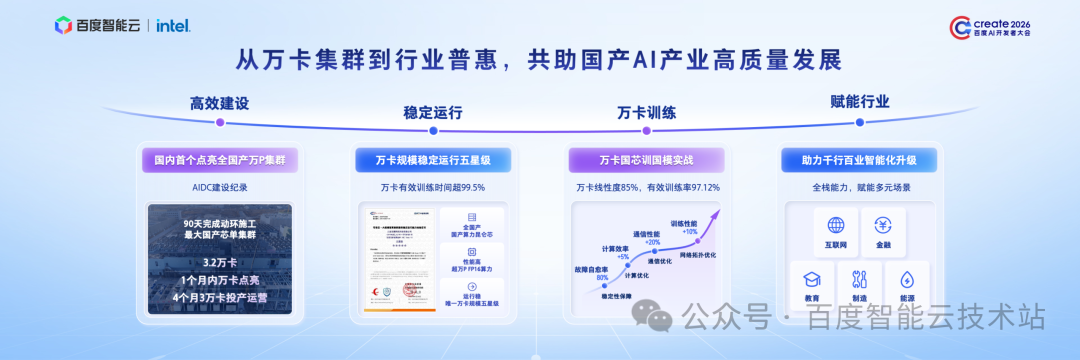
2024 年,我们建成了 3.2 万卡规模的全国产算力集群,创造国内首个全国产万 P 集群的交付记录:1 个月万卡点亮,4 个月 3.2 万卡投产。这背后离不开高效的工程交付和系统集成能力。
集群上线以来,始终保持稳定运行,万卡有效训练时长超过了 99.5%。2025 年,该集群成为了当时唯一通过中国信通院《大规模智算服务集群稳定运行》万卡规模五星级认证的集群。
今年,我们更进一步,成功在万卡国产芯片底座上完成了先进国产大模型的训练实战,有效训练率再攀新高,达到 97% 以上。
如今我们的国产算力已经在互联网、金融、到制造、能源、教育等多个关键行业规模化落地。
今天,我们不仅能承建超大规模国产算力集群,更具备基于国产底座自主训练大模型的完整能力。
未来,我们将坚守共筑生态、赋能行业的初心,持续开放共享技术积淀与实践经验,携手产业各界同行伙伴,一起加速国产算力规模化普及,共同助推中国 AI 产业迈向更高质量发展。
谢谢大家!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)