DeepSeek-V4-Flash 让 LLM Steering 重回主舞台:本地大模型时代的模型操控工程实战
DeepSeek-V4-Flash 让本地 LLM Steering 从炫技实验走向工程可用,重新打开 模型可控性 的新边界
DeepSeek-V4-Flash 让本地 LLM Steering 从炫技实验走向工程可用,重新打开 模型可控性 的新边界。
原文链接:AI 小老六
不只是提示词:本地大模型正在重新打开「脑内旋钮」
过去两年,控制大模型输出最常见的方法几乎只有一种:写更长、更细、更强硬的提示词。
你希望模型简洁一点,就写「请简洁回答」;希望它更像专家,就写「你是一名资深工程师」;希望它别胡说,就写「如果不知道请直接说不知道」。这种方式简单、通用,也足够有效,以至于很多人会自然地认为:既然提示词能改变模型行为,为什么还要用更复杂的方法?
但在模型研究和工程实践中,还有一条更底层的路线:不只是改变输入文本,而是在模型推理过程中直接修改它的内部激活。这就是 LLM Steering,直译可以叫「模型操控」或「激活操控」。
它的想象空间很大:如果模型内部真的存在某种「简洁」「谨慎」「更像代码审查专家」「更擅长定位 Bug」的方向,那么我们是否能把这些方向提取出来,在推理时像调音台一样拉动滑块?

图:Steering 想象中的样子——在调音台上拉动模型内部的隐藏方向
Steering 到底在控制什么
一个大语言模型在生成文本时,并不是简单地把提示词映射成答案。它会在多层神经网络中不断计算,形成一系列中间状态。可以粗略理解为:模型在每一层里都形成了一些「内部表征」,这些表征共同决定它下一步要说什么。
Steering 的核心思路是:找到某个概念在这些内部表征中的方向,然后在推理时人为增强这个方向。
举个简化例子。假设我们想让模型「回答更简洁」,可以准备一批相同问题,并分别构造两组输入:
| 输入组 | 示例 | 目的 |
|---|---|---|
| 普通提示 | 「解释一下 TCP 三次握手」 | 记录模型正常激活 |
| 带控制提示 | 「解释一下 TCP 三次握手,请非常简洁」 | 记录「简洁回答」时的激活 |
对同一批问题,比较两组激活之间的差异,就可能得到一个近似的「简洁方向」。之后,当模型回答其他问题时,把这个方向加回特定层的激活中,理论上就能让它更倾向于简洁回答。
这个过程可以用一个简化流程表示:
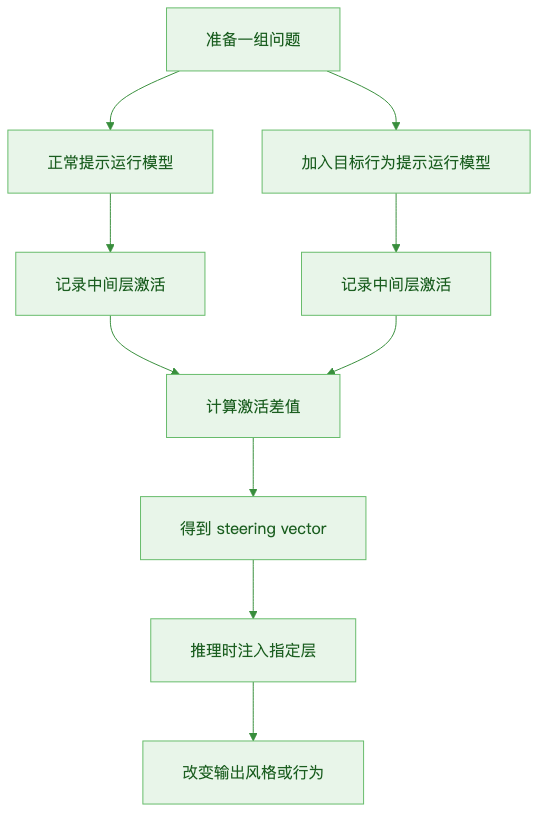
图:从「正常提示」与「带行为提示」的激活差值中提取 Steering Vector,并在推理时注入特定层
更复杂的做法会使用 稀疏自编码器 等方法,从大量激活中提取更稳定、更可解释的特征。它们不再只是比较两组提示,而是试图找出模型内部反复出现的行为模式,再把这些模式映射回人类能理解的概念。
为什么过去 Steering 没有流行起来
这个方向听起来像是给模型装了控制面板,但现实里一直没有成为主流,原因并不神秘。
- 大模型公司并不太需要它。 OpenAI、Anthropic、Google 这类机构如果希望模型改变行为,最直接的方法是训练、后训练、强化学习或系统提示词工程。它们拥有模型权重、训练数据和算力,没有必要在推理中做「脑外科手术」。
- 普通开发者很难使用它。 绝大多数人通过 API 使用模型,拿不到权重,也看不到中间激活。你无法对一个黑盒 API 说「请把第 23 层 MLP 输出沿这个方向加 0.8」。模型供应商不开放这些接口,Steering 就无从谈起。
- 早期本地模型能力不够强。 对一个能力明显落后于云端前沿模型的开源模型做 Steering,即使实验成功,实际价值也有限。开发者真正关心的是:它能不能帮我写代码、读仓库、做分析、完成复杂任务。如果模型本身做不到,操控它的风格意义不大。
- 很多基础 Steering 目标可以被提示词轻松替代。 想让模型更短、更礼貌、更结构化,直接写进提示词通常就够了。提示词本身就是一种强大的行为控制方式,而且成本低、可移植、无需访问权重。
DeepSeek-V4-Flash 改变了什么
这次值得重新讨论 Steering,是因为环境发生了变化。
DeepSeek-V4-Flash 这类模型让本地运行一个能力足够强的 LLM 变得更现实。配合 DwarfStar 4 这样专门面向某个模型做优化的 本地推理项目,开发者不仅能在本地跑模型,还可能直接接触它的内部计算过程。
这带来一个重要变化:Steering 不再只是大厂研究员和论文作者能玩的东西,而开始接近普通工程师的实验台。
过去的本地模型实验像是在玩遥控玩具车:你能控制方向,但车跑不快,也跑不远。现在的局面更像是普通开发者第一次拿到一辆性能还不错、引擎盖也能打开的车。

图:DeepSeek-V4-Flash 这类本地模型,让普通开发者第一次能直接接触模型内部计算
你可以不只踩油门和刹车,还能研究发动机内部某些调校参数是否会改变驾驶体验。
这并不意味着 Steering 已经成熟。当前很多示例仍然非常粗糙,比如调整回答长短,效果也常常可以用提示词复现。但它重要的地方在于打开了 工程试错空间。
真正有价值的方向:控制那些「提示词很难控制」的东西
如果 Steering 只是让模型「更啰嗦」或「更简短」,它很难成为刚需。真正值得期待的是那些提示词难以表达,或者表达成本极高的目标。
第一类目标是「不可提示」的能力。
早期模型时代,大家喜欢在提示词里写「你是一位世界级专家」。那时这句话有时真能改善输出,因为模型的默认行为没那么稳定。现在的前沿模型已经默认表现得像专家,再继续写「请更聪明」通常不会有明显效果。
问题是,模型内部是否存在某种可被增强的「更聪明」方向?如果存在,Steering 也许能让模型在不重新训练的情况下提升某些任务表现。
第二类目标是「上下文压缩」。
比如一个 AI 编程助手读完整个代码仓库后,是否能把「理解这个仓库」的状态压缩成某种激活方向?如果能,之后就不必每次都塞入大量上下文,而是通过 Steering 让模型进入「熟悉该仓库」的状态。
这同样很难,但比「提取智能」更像一个工程问题。它的价值也更明确:节省上下文窗口、减少重复读取、提高长任务稳定性。
可以把几种控制方式做个对比:
| 方法 | 控制位置 | 优点 | 局限 |
|---|---|---|---|
| 提示词 | 输入文本 | 简单、便宜、可跨模型迁移 | 对深层行为控制有限 |
| 系统提示词 | 对话框架 | 稳定约束角色和边界 | 仍然占上下文,容易被任务冲淡 |
| 微调 | 模型参数 | 行为改变更稳定 | 成本高,更新慢,需要数据 |
| Steering | 推理中激活 | 可动态调节,不必改权重 | 需要权重和激活,效果不稳定 |
对 AI Agent 的潜在意义
如果 Steering 未来成熟,最先受益的可能不是聊天机器人,而是 AI Agent。

图:Agent 在规划、实现、调试、审查等阶段切换不同的内部状态信号
Agent 场景里,模型需要在不同模式间切换:有时要快速规划,有时要保守执行;有时要大胆搜索,有时要严格验证;有时要写代码,有时要做审查。今天这些切换主要靠提示词、工具说明和上下文管理完成。
但提示词控制存在一个问题:任务越长,上下文越复杂,控制信号越容易被淹没。一个 Agent 跑了几十轮之后,最初那句「请谨慎修改代码」可能已经不再足够强。
Steering 提供了另一种想象:在执行不同阶段时,直接切换模型内部状态。
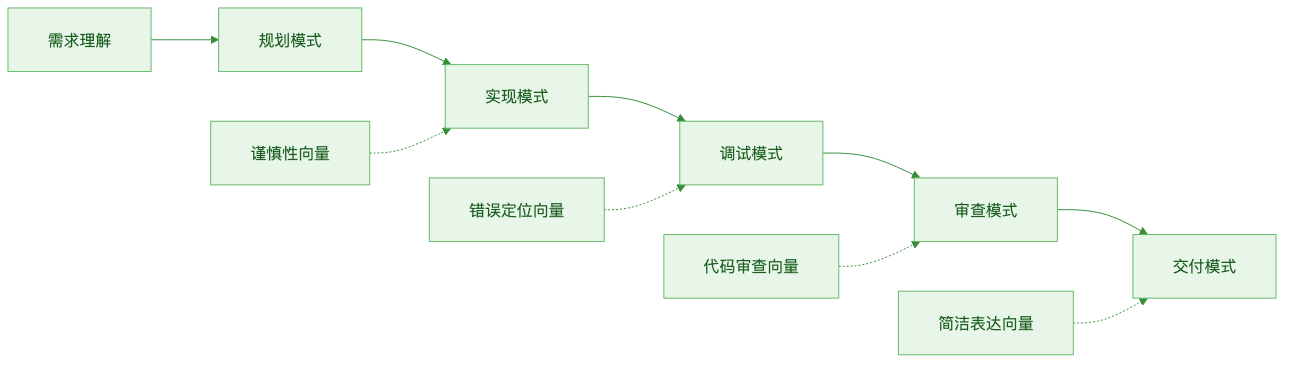
图:在 Agent 不同阶段切换 Steering Vector,让模型内部状态随任务模式动态变化
这当然还只是想象。现实中,我们还不知道这些向量是否稳定、是否跨任务有效、是否会引入副作用。但如果本地模型社区开始系统性提取、测试和共享这些控制向量,AI Agent 的工程形态 可能会出现新分支。
不要高估它,也不要忽视它
对 Steering 最合理的态度,是既不过度兴奋,也不直接忽视。
它很可能不会取代提示词。提示词太便宜、太通用、太符合人类工作流。只要一句话能解决,就没必要动模型内部激活。
它也不太可能成为「免费提升模型智商」的捷径。真正复杂的能力大概率仍然来自数据、训练、架构和推理算力。
但在某些边界场景里,Steering 可能提供 提示词和微调之间的第三种选择:比提示词更贴近模型内部,比微调更轻量、更动态。
未来半年值得观察几个问题:
| 观察点 | 关键问题 |
|---|---|
| 开源模型社区 | 是否会围绕热门模型提取可复用 Steering 向量 |
| 本地推理框架 | 是否会把激活注入做成稳定 API |
| Agent 工程 | 是否能用 Steering 改善长任务一致性 |
| 模型解释性 | Steering 是否能反过来帮助理解模型内部概念 |
如果答案逐渐变成「是」,那么大模型控制方式会从「写提示词」进入「写提示词加调内部状态」的新阶段。
这不是魔法,也不是 AGI 的捷径。它更像是工程师终于能摸到模型仪表盘背后的几根线。真正的问题不再是「能不能拧动旋钮」,而是「拧动以后,模型到底会变得更可靠,还是只是以新的方式失控」。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)