【无标题】
回到开头那句话:大多数 AI 审查系统审 100 份文档和审 1 份,水平完全一样。不是因为模型不够大,是因为它们缺一个东西——反馈。给系统一个纠正自己的通道,它就活了。这不是什么高深的技术,是一个设计选择。项目效果。
审100份文档和审1份,水平完全一样,传统AI审查系统不会学习。我们做的这个,审得越多越聪明。
上个月我们交付了一个企业文档智能审查模块。客户把施工设计说明扔进去,几分钟后就能拿到一份结构化的审查报告——设计规范引用问题标红、专业间冲突列清单、合规风险点给等级。
更关键的是,用户纠正过的错误,系统下一次不会再犯。审得越多,和客户的审查标准对齐得越准。
我们没有自己整 harness 框架,也没有自己再去实现一套自进化逻辑。
那如何实现这一切呢 ,hacker news 上有句话说的非常贴切:
Claude Code Is All You Need 。 有claude code 就够了。
文档审查为什么这么难
先来说下,为何自动审查这个事情在传统的模式下难做,做过企业项目的都懂,文档审查是个"看起来简单、做起来吐血"的需求。
合同条款动不动几十页,法务逐条核对要花一整天;运维手册上千条规程,新来的工程师三个月都看不完;标书里的技术参数密密麻麻,漏一个关键项就可能废标。传统做法无非两条路:规则引擎写死校验逻辑,但规则一多维护成本比开发还高;人工审查靠专家逐条核对,效率低不说,不同专家的判断标准还不统一。
中间态方案也试过。Dify 拖拽工作流,审到第三页就忘了第一页的内容;做的知识库检索,召回的相关条款经常跑偏;LangChain 搭链式调用,debug 的时间比写代码还长。
这些方案的共同问题是什么?它们都是静态系统。 规则写死就不会变,流程拖好就不会改,知识灌进去就永远是那批文档。审一百份文档和审一份,系统本身毫无成长——这不是符合现在技术发展,他是缺"智能"本身。
“Agent Harness"这个概念我们在之前的文章里详细拆解过。简单说:Agent 是模型本身,不是框架、不是 Prompt Chain、不是拖拽工作流。Harness 是运行这个 Agent 的"环境”——给它工具、给它知识、给它观察能力、给它行动接口、给它权限边界。
Harness 做得好,Agent 就聪明。Harness 做得差,再好的模型也发挥不出来。
问题就在于,做一个好的、稳定的 Harness 对于团队的要求很高。因为模型的能力是在持续变化增强的,所以 Harness 也必须要动态调整,以适配 LLM 更好的协作。
所以对于做应用的团队来说,在理解这一切的基础上,找一个相对成熟且持续迭代的基础智能体,在这个基础上去构建自己的应用,在项目的前期阶段是一个理性的选择。
为什么 claude agent 就够了
在做这个项目之前,我们已经深度使用过 Claude Code。用起来最直观的感受是——它"懂"你。你改了一个函数签名,它自动去更新所有调用方;你描述一个 bug,它先翻日志再动手修;到了某个节点,它主动停下来问你确认,而不是闷头往下猜。
这种"懂"不来自更大的模型,而来自它底层的 Agent Harness。上下文管理不是简单的滑动窗口——它知道哪些信息该压缩、哪些该保留、什么时候该召回。Skill 引擎让它在不同场景加载不同行为——写代码时是一个专家,做 code review 时是另一个。MCP 引擎把它接到外部工具和数据源上,不是孤岛里的一个聊天窗口。ask_user 交互组件让它在模糊地带主动要澄清,而不是硬猜。
这四个组件只是 Claude Code Harness 的冰山一角,但已经足以说明问题——Claude Code 不是一个"更强的 ChatGPT",它是一个真正能让 Agent 干活的环境。而我们要做的,就是把这个环境的核心能力,应用到企业场景里去。
但 Claude Code 是一个终端工具,不能直接嵌入企业系统。我们需要的是一个能提供同样 Harness 质量的 Agent 平台——让它成为企业流程中的一个"数字员工",而不是开发者手边的一个命令行工具。
这里的选择很多,可以是 Claude Agent SDK, 也可以是 OpenAI Agents SDK ,还可以是其他提供 harness 基础设施的框架、或者项目,或者组件。 我们在这里选择一个带管理后台的 agent 平台,并在我们的服务器上搭建了这个 Agent 服务平台,它继承了 Claude Code Harness 的核心理念,但面向企业场景做了适配:
Session 管理——每个审查任务创建一个独立的 Session,上下文互不污染。一份文档的审查不会影响到另一份,就像每个任务分配了独立的"大脑"。
WebSocket 实时通信——审查过程不是"提交任务→等结果"的黑盒。Agent 的进度通过 WebSocket 实时推送到前端:正在下载文档、正在加载规范、已完成第三章审查……用户看到的是一个"在干活"的 Agent,不是一个转圈圈的加载动画。
Skill 行为定义——每个审查场景对应一个 Skill。审查施工设计说明的 Skill 定义了:审查流程、评判规则、输出格式、工具使用约定。用户发起审查时,触发 Agent 加载对应的 Skill,就知道自己这次是"施工设计审查专家"还是"运维手册审查专家"。
工具集——Agent 可以调用 execute_code 执行 Python 脚本下载文件、落盘;用 read 工具按审查条目语义检索文档中的相关段落;用 LLM 的大脑做规范判断。确定性的操作(下载、解析)交给工具,不确定的判断(合规性评估)交给模型。
这些能力合在一起,就是一个"会干活"的数字员工。
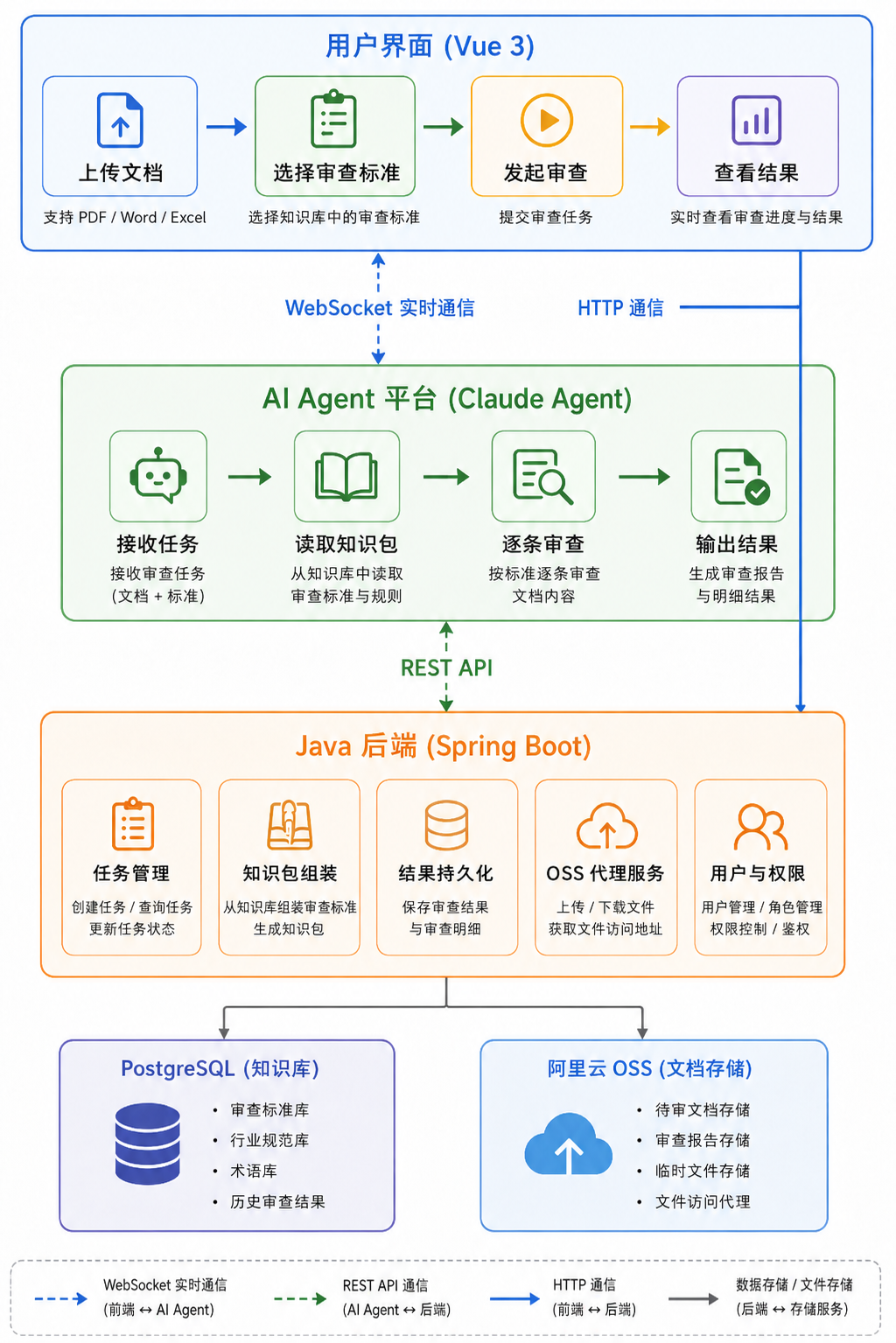
架构设计:三层 + 一条实时通道
不少所谓的"AI 审查系统"本质是套壳 ChatGPT——前端加个上传按钮,后端调个 API,Prompt 里写几句"请帮我审查"。结果可想而知:不稳定、不可控、不可信。
我们的设计思路不一样:不是让 LLM 审查文档,而是让一个完整的 Agent 来审查文档。 区别在于——Agent 有工具、有知识、有流程、能自我纠错。
系统分为三层,外加一条贯穿始终的 WebSocket 实时通道。
第一层,前端。 用户上传文档、选择审查维度、启动审查、实时查看进度和结构化报告。技术栈 Vue 3 + TypeScript,聚焦交互体验——重点是审查过程中的实时反馈,而不是一个"提交后干等"的黑盒。
第二层,Agent 平台。 系统的核心。提供 Session 隔离、WebSocket 通信、工具执行环境、Skill 加载。这层的核心认知是:**Agent 不是在"调 API",而是在"执行多步骤任务"**——它自己决定先下载什么、按什么条目审查、何时检索规范、如何输出结果。这是 Agent 和单次 LLM 调用的本质区别。
第三层,后端 + OSS + 数据库。 OSS 是文件的唯一事实源,数据库只存文件引用,不存在双写不一致的问题。后端通过 manifest 机制为 Agent 提供任务上下文和文件流,全部通过 token 鉴权。前端从 WebSocket 收到审查结果后写回数据库,Agent 不需要回调 HTTP。
整个架构的设计原则一句话:确定性的操作交给代码,不确定的判断交给 Agent。 文件上传下载、格式转换——确定的,后端处理。规范条款解读、合规性判断、模糊地带权衡——不确定的,交给 Agent 的大脑。
审查模块的框架如下图所示
反馈闭环:系统越用越聪明的秘密
前面说的三层架构解决了"能审"的问题。但真正让这套系统区别于传统方案的,是它能"越审越准"。
机制本身不复杂:用户看到审查结果,反馈审查的判定错误并给出理由、漏审了某个问题。这些标注不会存进数据库吃灰,而是在下一次审查时作为上下文喂给 Agent。
举个例子。第一次审某份施工设计说明时,Agent 判定"缺少抗震设计参数引用"为严重问题。但用户标注:根据项目实际情况,该建筑高度不足 24 米,按规范可不强制引用。这个纠正被记录下来。下一次再遇到类似情况,Agent 的上下文里就有了这条经验——它会先检查建筑高度再下判断,而不是机械地套用规范条文。
这跟人带新人的逻辑是一样的。不是一次性把所有规则灌进去,而是在实战中不断纠正、不断对齐。审十份文档之后,Agent 对你客户的审查标准的理解,和刚部署时已经是两个水平。
这个反馈数据本身就是客户的竞争壁垒。 同一套系统部署给 A 客户和 B 客户,三个月后它们是两个不同的审查专家。因为各自积累的反馈数据不同。系统本身成了一个活的、持续增值的资产,而不是一个买来就折旧的工具。
这也是为什么我们说"越用越聪明"了。
几个关键设计决策
回顾这个项目的设计过程,有几个决策事后证明是对的。
Skill 而不是代码
不同文档类型需要不同的审查逻辑。施工设计说明关注设计规范引用和专业间一致性,运维手册关注操作规范和安全条款,设计计算书关注结构参数和公式准确性。
我们把每个审查场景定义为一个 Skill 文件。一份 Markdown 格式的配置文件,用户触发不同的审查场景, Agent 按需加载 skill, 也就知道自己这次是"施工设计审查专家"还是"运维手册审查专家"。
新增一个审查场景就是加一个 Skill 文件。业务人员可以直接编辑,甚至都不需要开发介入。
Session 隔离:每个审查一个独立的"大脑"
做过 Agent 开发的人都知道一个坑:上下文污染。上一个任务的状态残留在下一个任务里,导致判断偏差。
我们的做法是每个审查任务分配一个独立的 Session,sessionId 持久化到数据库的审查记录上。一份文档审完,Session 就结束,不会把上一份文档的内容带到下一份里。就像给每个审查任务分配了一个临时工——任务完成,记忆清空。
OSS 单一事实源
源文件只存在 OSS 上,数据库只存一个 ossFileKey。后端不存文件副本,Agent 也不直接从数据库读文件。
这样做的好处很简单:不用操心 DB 和 OSS 数据是不是一致的——OSS 就是唯一的文件事实源,不存在不一致的可能。
Agent 下载文件,工具执行,模型判断
Agent 的工具分工明确:
execute_code负责确定性操作:执行 Python 脚本下载 manifest、源文件和规范包到本地目录read负责按需检索:根据审查条目语义检索文档中的相关段落,不把整份文档一把塞进上下文- LLM brain 负责不确定性判断:对照规范条文,评估合规性,给出判定理由
这不是"Agent 万能论",恰好相反,这是承认 Agent 和模型各有擅长,把合适的事交给合适的能力。
从"定制项目"泛化到“通用系统”
OpenSpec 上线运行后,一个有意思的发现是:这个架构的通用性远超预期。
最开始我们只做了施工设计说明审查。客户问:“运维手册能审吗?” 加了一个 Skill,能审了。又问:“设计计算书能审吗?” 再加一个 Skill,又能审了。
每一次新增场景,改的不是代码,是 Skill 和 数据库里的规范条文。Agent 的能力边界取决于你给它什么知识、什么工具、什么流程——不是取决于你写了多少代码。
企业 Agent 的核心壁垒不是模型、不是框架,而是 Harness 的质量。 Harness 决定了 Agent 能连接到什么数据、遵守什么流程、在什么边界内行动。模型在快速进化,但一个好的 Harness 设计能让你无缝切换模型而不重写系统。
这也是为什么我们选择成熟的 Agent 平台而不是自己从零搭建。把 Harness 工程交给最专业的人,把精力集中 Harness 中的业务流程建设以及数据知识处理。
写在最后
回到开头那句话:大多数 AI 审查系统审 100 份文档和审 1 份,水平完全一样。不是因为模型不够大,是因为它们缺一个东西——反馈。
给系统一个纠正自己的通道,它就活了。这不是什么高深的技术,是一个设计选择。
完整项目地址:https://github.com/zhuzhaoyun/OpenSpec
项目效果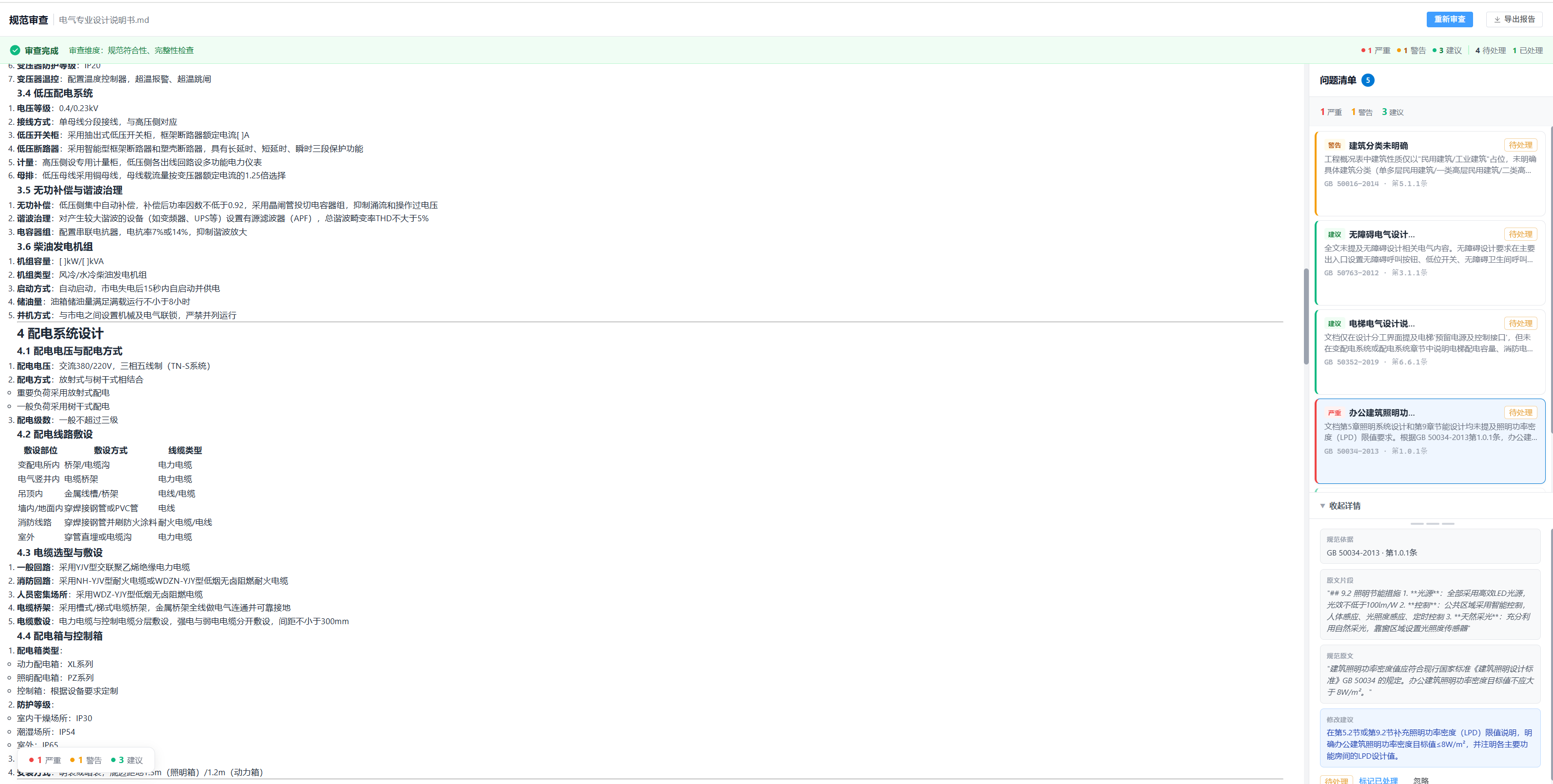
关于我们
我们是一个专注企业 AI 落地的技术团队,帮客户把 Agent 真正塞进业务流程里。如果你也在做类似的尝试,欢迎来聊聊——哪怕不合作,交流一下踩过的坑也值得。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)