Transformer vs RNN 差距在哪?一个类比讲清自注意力本质
Transformer相比RNN的三大优势:1)自注意力机制实现任意位置直接交互,解决RNN长距离依赖问题;2)信息传递无损耗,保持原始语义完整性;3)并行计算能力大幅提升训练效率。这三个质变使Transformer在自然语言处理领域实现突破性进展,成为当前大模型的核心架构。文章通过"喝汤"的生动类比,形象解释了RNN的顺序处理缺陷和Transformer的全局视野优势,指出其
导读
几乎所有学AI的人都知道“Transformer比RNN好”,可面试时被追问“到底好在哪”,大多数人只会说“能并行计算”——这话其实只说对了三分之一。
RNN有三个致命短板,而Transformer的自注意力,一下就把这三个问题全解决了。用一个类比,帮你5分钟彻底搞明白。
要是你2016年用过Google翻译,肯定有印象——
翻译长句子的时候,前半句还挺顺,后半句就开始乱七八糟,两句之间更是没半点逻辑,跟俩不同的人翻的似的。
到了2017年底,Google翻译突然就“开窍”了:长句子能翻得通顺,上下文也能串起来了。
这背后的关键变化,就是Transformer把RNN给换掉了。
但要是有人问你:Transformer到底比RNN强在哪?
你大概会说:“Transformer能并行计算,RNN只能一步一步来。”
这话没毛病,但真就只说对了三分之一。

RNN的本质问题:用吸管喝汤
咱们想象一下,你面前放着一碗汤,汤里有十几种食材——香菇、虾仁、豆腐、玉米之类的。
RNN处理语言的方式,就跟用一根吸管喝这碗汤似的。
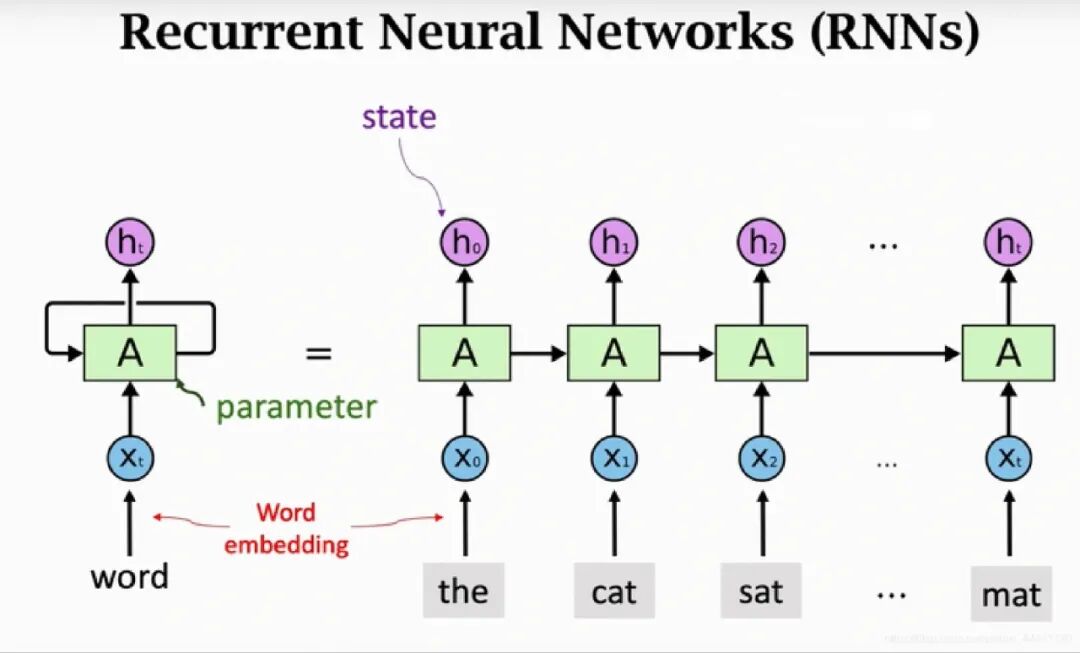
你只能从碗的一头开始,一口一口往前吸。每吸一口,都得记着前面喝过的味道,再把这个“记忆”和新喝到的味道混在一起,才算对这碗汤有个“当下的理解”。
问题来了:等你喝到第15口的时候,还记得第1口是什么味吗?
大概率是记不清了。因为每一口的记忆,都会被后面的味道稀释、盖过去,甚至变味。
这就是RNN处理长序列最致命的问题——梯度消失。离当前位置越远的信息,在传递过程中耗损得就越多。
虽说理论上LSTM和GRU靠“门控机制”稍微缓解了这个问题,但“缓解”和“解决”,那差得可太远了。
RNN注意力的尴尬:瓶颈上贴的补丁
你可能听过,“注意力机制”在RNN时代就有了。没错,2014年Bahdanau提出的注意力机制,本来就是给RNN用的。
但RNN的注意力,有个根本的尴尬——它就是在顺序编码的基础上,贴了个补丁而已。
打个比方:RNN先拿吸管把汤喝了一遍,留下一个模糊的记忆。然后注意力机制过来问:“你回想一下,刚才第3口和第7口是什么味?”RNN拼命去想,可它的记忆早就被顺序喝汤的过程给压缩、弄失真了。
你在一个已经失真的记忆上做注意力,精度能高到哪去呢?
这就是RNN+Attention的本质局限:底层的编码是按顺序来的,还会有损耗,上层的注意力再巧妙,也救不了一个模糊的底子。
Transformer的三个质变
2017年,Google那篇“Attention Is All You Need”,干了一件特别大胆的事——把RNN整个扔了,只留下注意力。
不是“在RNN上加点注意力”,而是“注意力就够了”。
这一下带来了三个质变,可不只是“能并行”这一个好处。
质变一:任意两个位置能直接“对话”。
在Transformer的自注意力里,句子里的每个词,都能直接和其他所有词算关联程度。第1个词和第100个词之间的距离?就一步。不用像RNN那样,信息得经过99个中间环节,一层一层传过去。
这就好比,把喝汤的方式从“用吸管一口一口吸”,改成“把汤倒进一个透明的浅盘子里,所有食材一眼就能看清”。你想知道香菇和虾仁的关系?直接看就行,不用先经过豆腐和玉米。
质变二:信息不会损耗。
因为不用经过中间节点传递,远距离的信息就不会有“传话式的损耗”。第1个词的信息传到第100个词的时候,保真度和传到第2个词是完全一样的。
RNN就像玩传话游戏——第一个人说“今天天气很好”,传到第十个人嘴里,可能就变成“今天买了蛋糕”。
Transformer则像开圆桌会议——每个人都能直接听到其他人说的话,不用经过中间人传话。
质变三:天生就能并行。
RNN必须等第t-1步算完,才能算第t步——因为第t步的输入,得靠第t-1步的输出。这就像一条单车道,再快的车也得排队等着。
而Transformer的自注意力计算里,每个位置的注意力权重都能同时算。一个句子有100个词?那就100个位置一起开工。这就好比把单车道,改成了100车道的高速公路。
这个区别在工程上意味着什么?意味着GPU的并行算力,终于能派上用场了。
RNN时代,你就算买再多GPU,速度也快不了多少,因为计算本身就是按顺序来的,没法并行。到了Transformer时代,算力多少,直接就能转化成速度。
要是没有这一点,今天的大模型根本不可能存在。GPT系列动辄上千亿参数的模型,要是用RNN来训练,说不定得花几十年。
回到那碗汤
所以,Transformer到底比RNN好在哪?
不是只有一个优势,而是三个质变叠在一起:信息能直达(不用传话)、记忆能保真(不会忘)、天生能并行(一起开工)。
而这三个质变的根源,都来自同一个设计选择——扔掉顺序处理,让每个位置都能直接和所有位置“对话”。
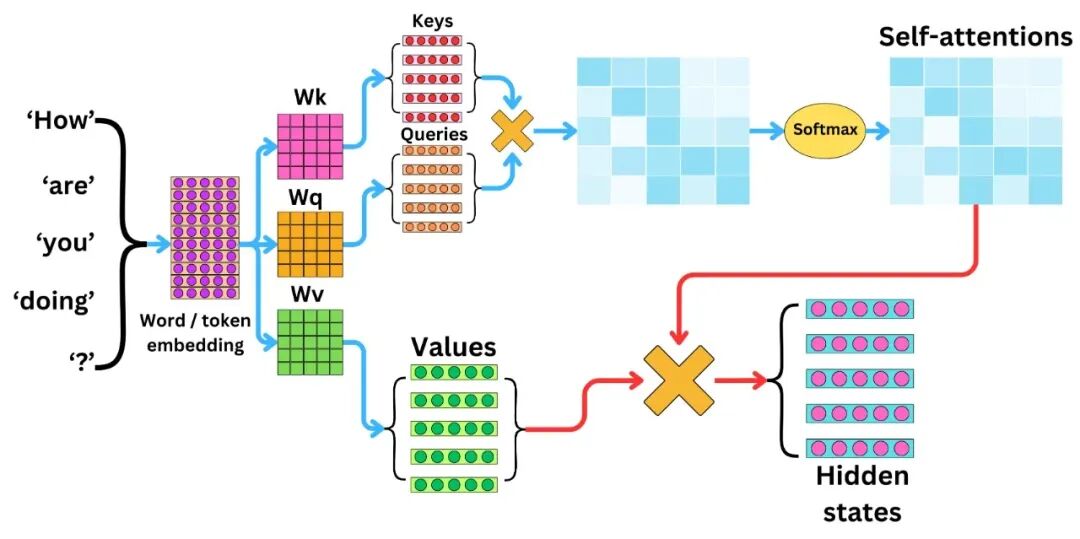
要是你之前看过我写的Q/K/V矩阵那篇,会发现一个有意思的点:Q/K/V讲的是自注意力“怎么算”,而这篇讲的是“为什么要这么算”。
Q是“我要找什么”,K是“我能提供什么”,V是“我实际拿到了什么”——这套机制之所以管用,正是因为它能让每个词,同时向所有词提问、回答。
RNN时代的注意力,就好比是让一个瞎子摸完大象,再问他“大象哪个部分最重要”。
Transformer的自注意力,是让你睁着眼看清整头大象,再自己决定该看哪里。
下次面试官再问这个问题,别只说“能并行”了。
那顶多只是冰山一角。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
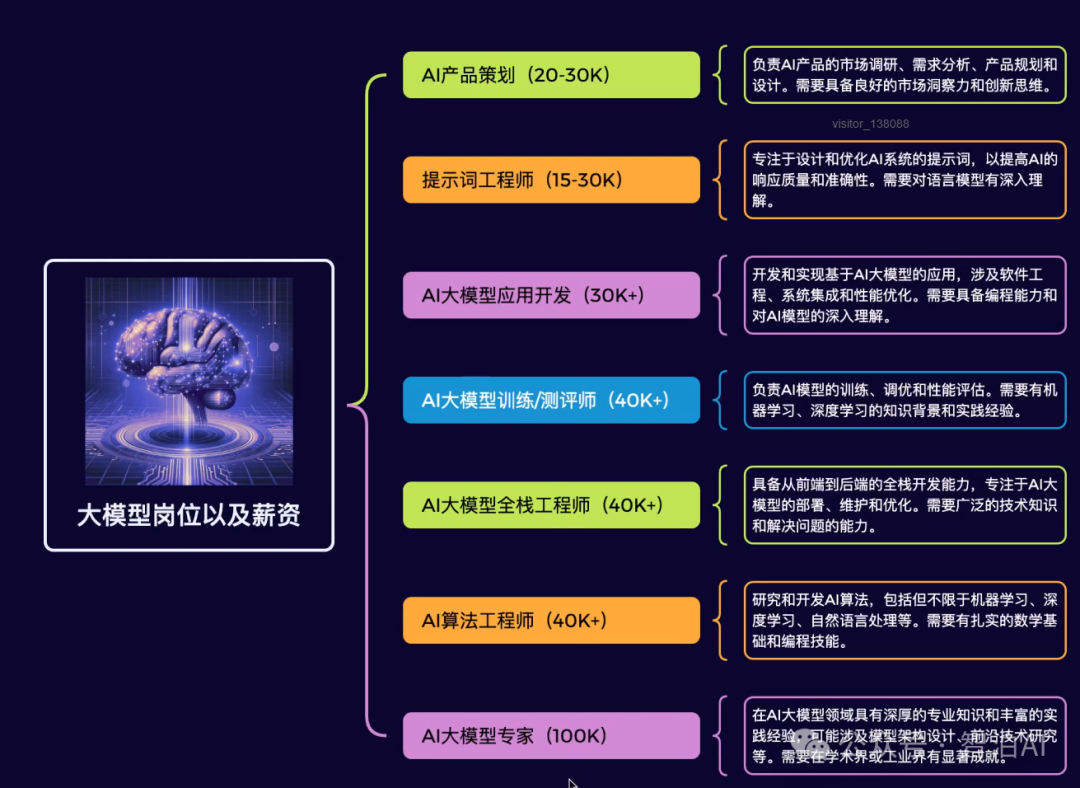
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

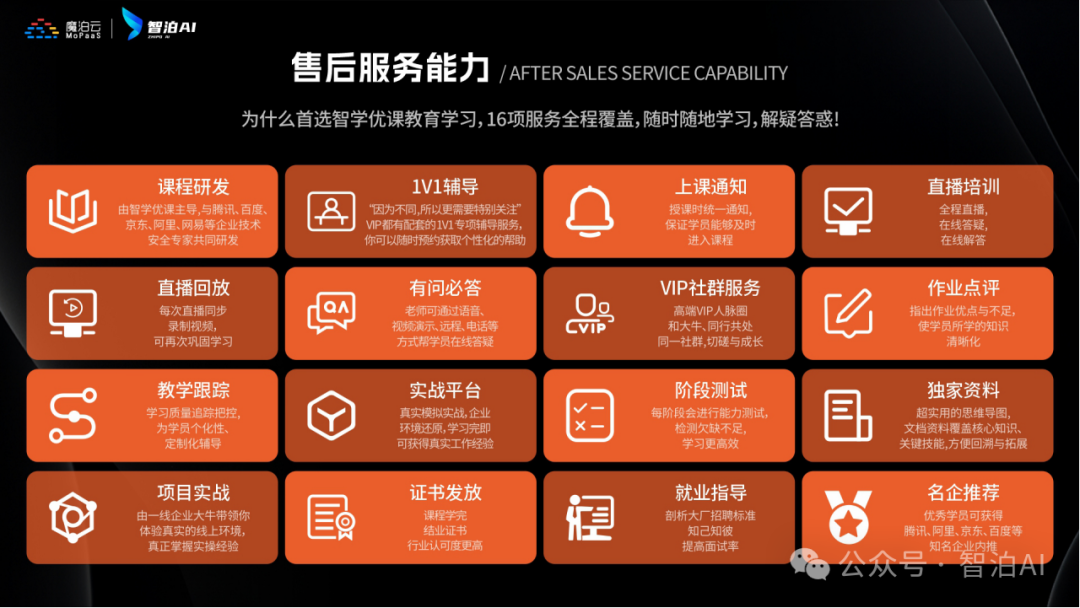
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献217条内容
已为社区贡献217条内容

所有评论(0)